이번 학기에 캡스톤 프로젝트로 생성형 AI를 활용해서 가상 스타일링을 해볼 수 있는 프로젝트를 진행하게 되었다.
프로젝트를 진행하면서 새로운 기술들을 많이 사용해보면서 많은 시행착오를 겪었는데, 그 구현 과정을 블로그 글로 남겨보려고 한다.
실제 구현 화면
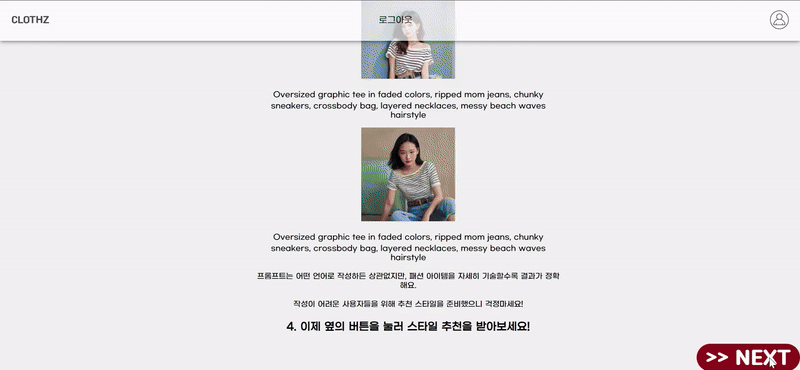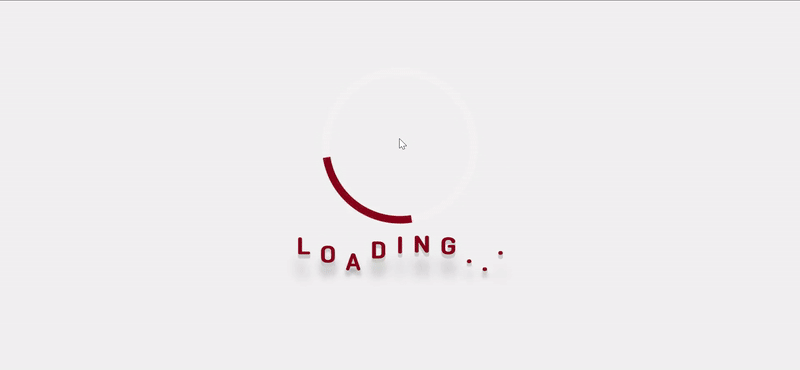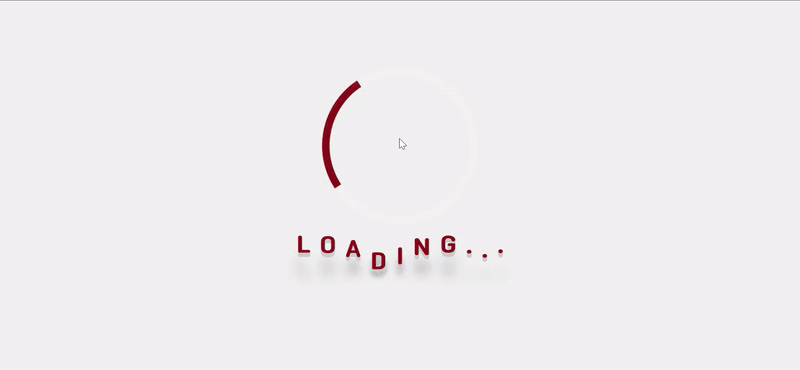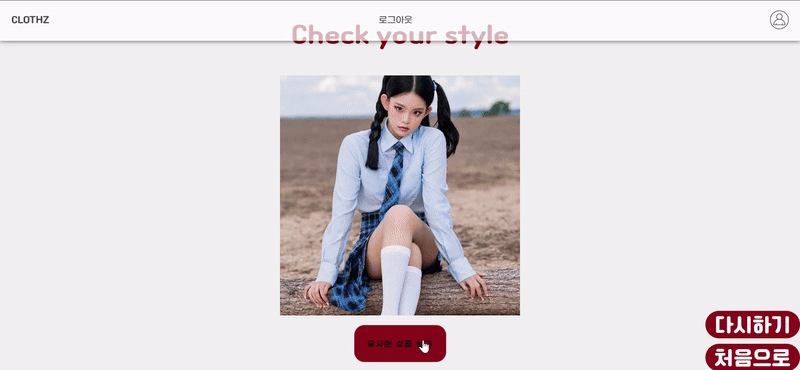
AWS Sagemaker를 사용한 이유?
서비스 기획 초기에는 간단하게 OpenAI API 등의 외부 API를 활용하여 간단하게 AI를 활용하는 방향으로 생각했었다.
하지만 우리 프로젝트의 요구사항은 사용자에게 개인화된 가상 스타일링 서비스를 제공하는 것이었다. 외부 API로는 이런 요구사항을 충족하기 어려웠기 때문에 결국 직접 AI 모델을 배포하고 API 서버를 구축하는 방향으로 바꾸게 되었다.
물론 AI 모델을 배포해보고 Python 기반 API 서버를 구축해본 경험은 없었지만, 재미있을 것 같아서 시작하게 되었다.😊
적합한 AI 모델 찾기
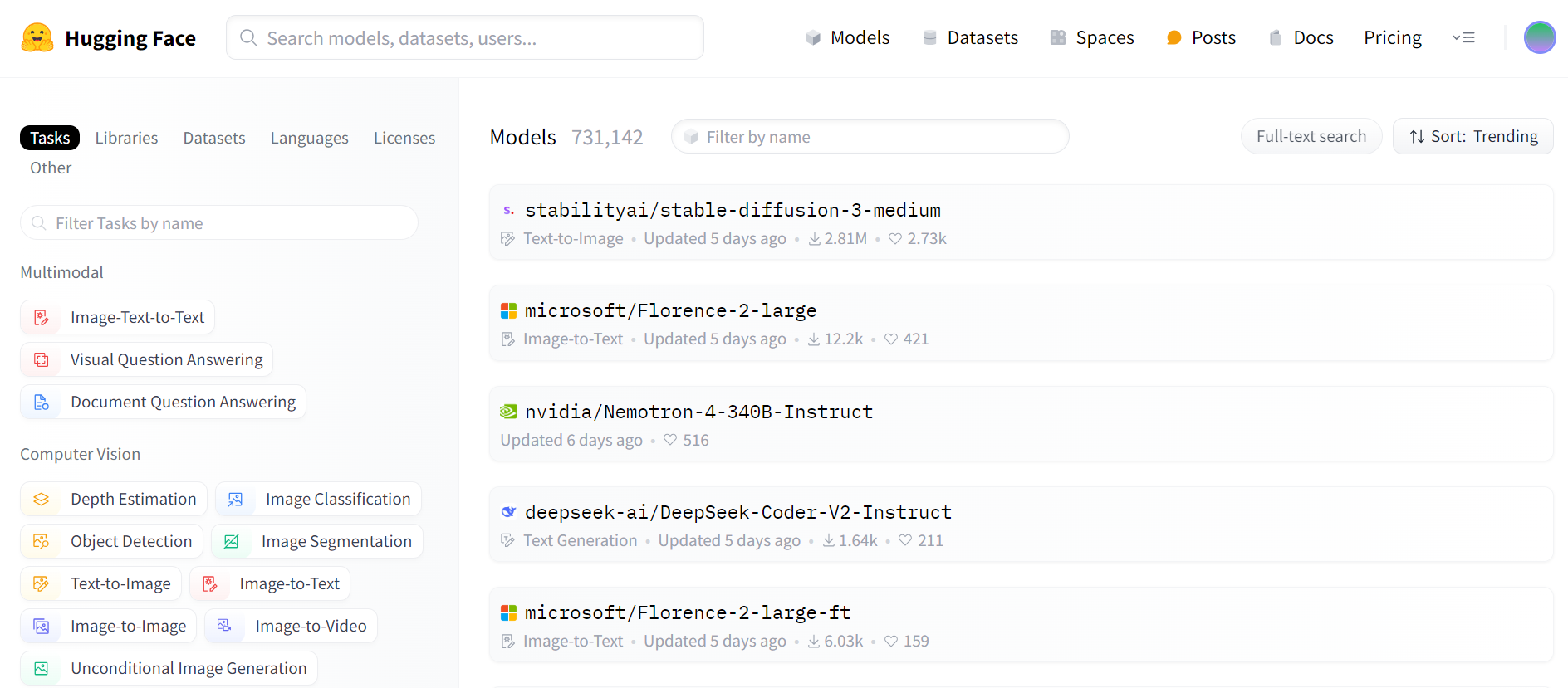
Hugging Face에서는 굉장히 다양하고 재미있는 AI 모델들이 배포되어있다. 그 중에서 TencentARC에서 배포한 PhotoMaker라는 모델을 선택하게 되었다. 이 모델의 특징은 사용자 사진과 텍스트 입력 값을 받아서 해당 이미지와 텍스트를 기반으로 이미지를 생성해주기 때문에 내가 생각했던 서비스에 적합하다고 판단했다.
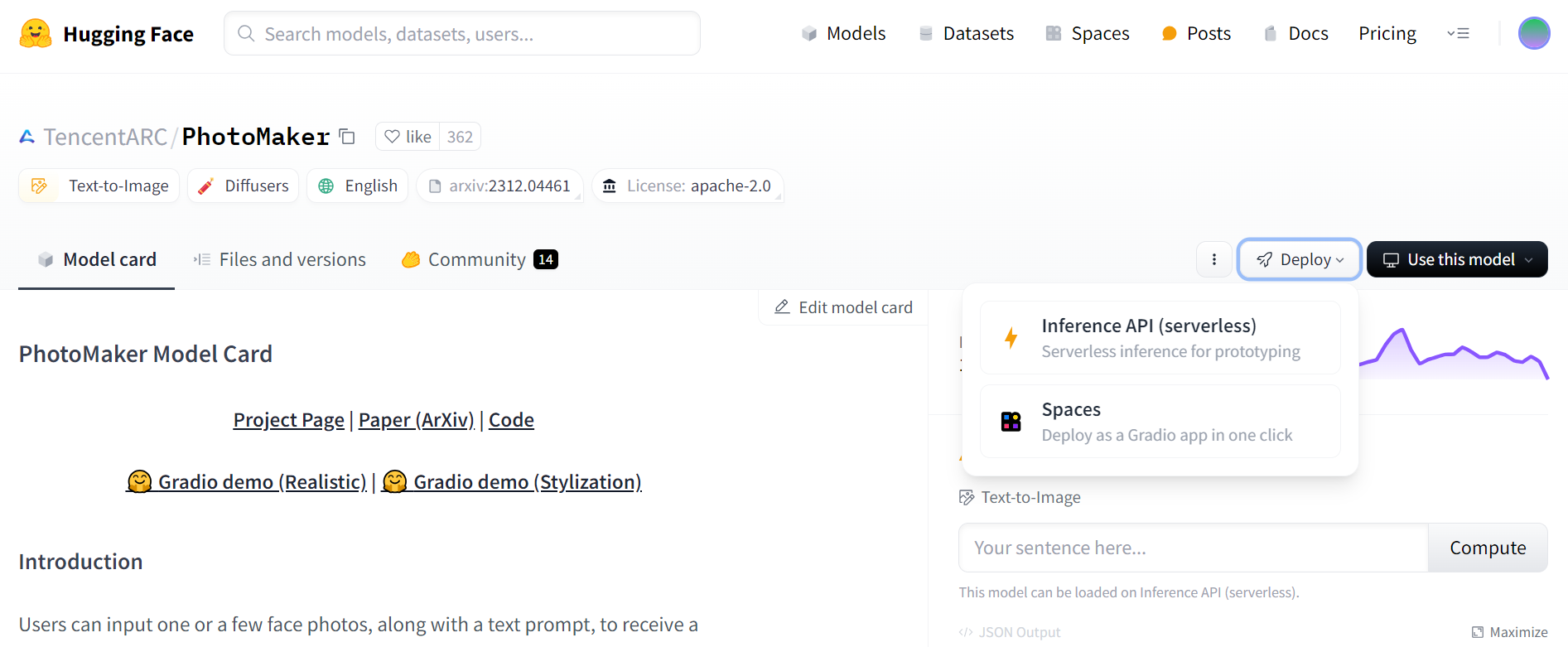
AI 모델 배포는 AWS를 통해 배포하는 방향으로 생각하고 있었다. 왜냐하면 AWS EC2를 통해 Spring 서버를 배포할 예정이었기 때문이었다. 그런데 화면의 Deploy을 보면 AWS로 배포하는 방식을 지원해주지 않았기 때문에 직접 배포하는 방법을 찾게 되었다.
그러다가 https://github.com/kyopark2014/stable-diffusion-api-server 이 링크에서 AI 모델 배포와 아키텍처에 대한 단서를 얻게 되었다.
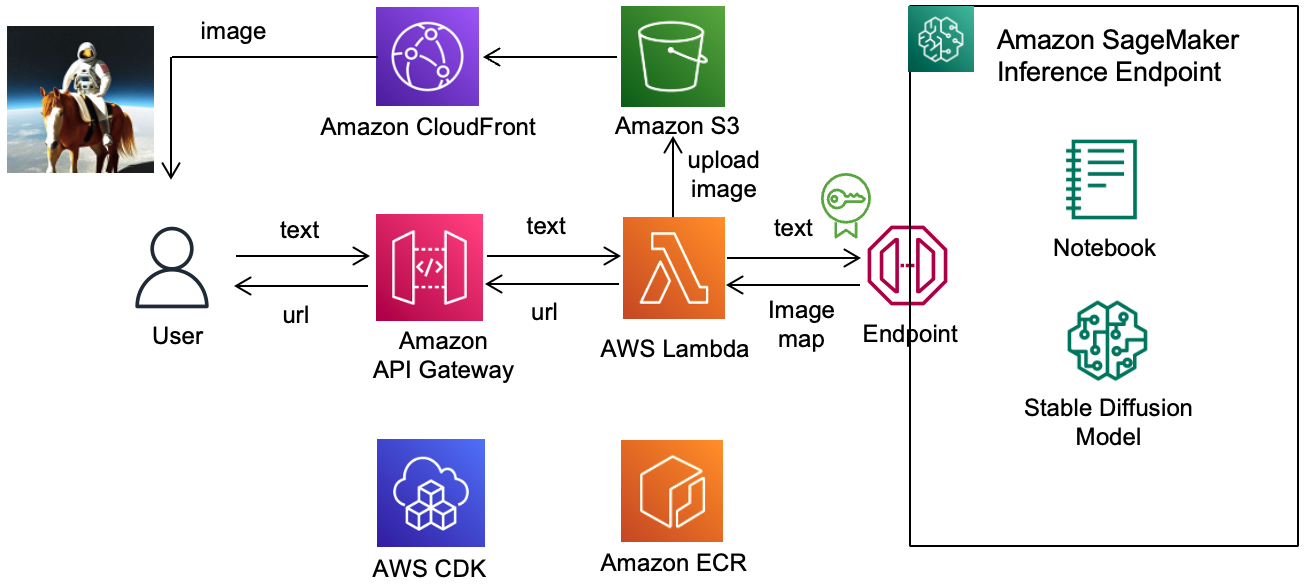
그래서 일단 해당 아키텍처로 인프라를 구성해보기로 결정하고 일단 SageMaker로 모델을 직접 배포 해보기로 결정하게 되었다.
여기저기 구글링해보면서 검색해보다가 Huggingface GitHub Repo에서 좋은 레퍼런스를 찾게 되었다.
AWS SageMaker로 모델 배포하기
Amazon SageMaker에 접속한 후 노트북 인스턴스로 이동하면 위와 같은 페이지가 나온다.
여기서 노트북 인스턴스 생성하기 버튼을 누르고 노트북 인스턴스를 생성해준다.
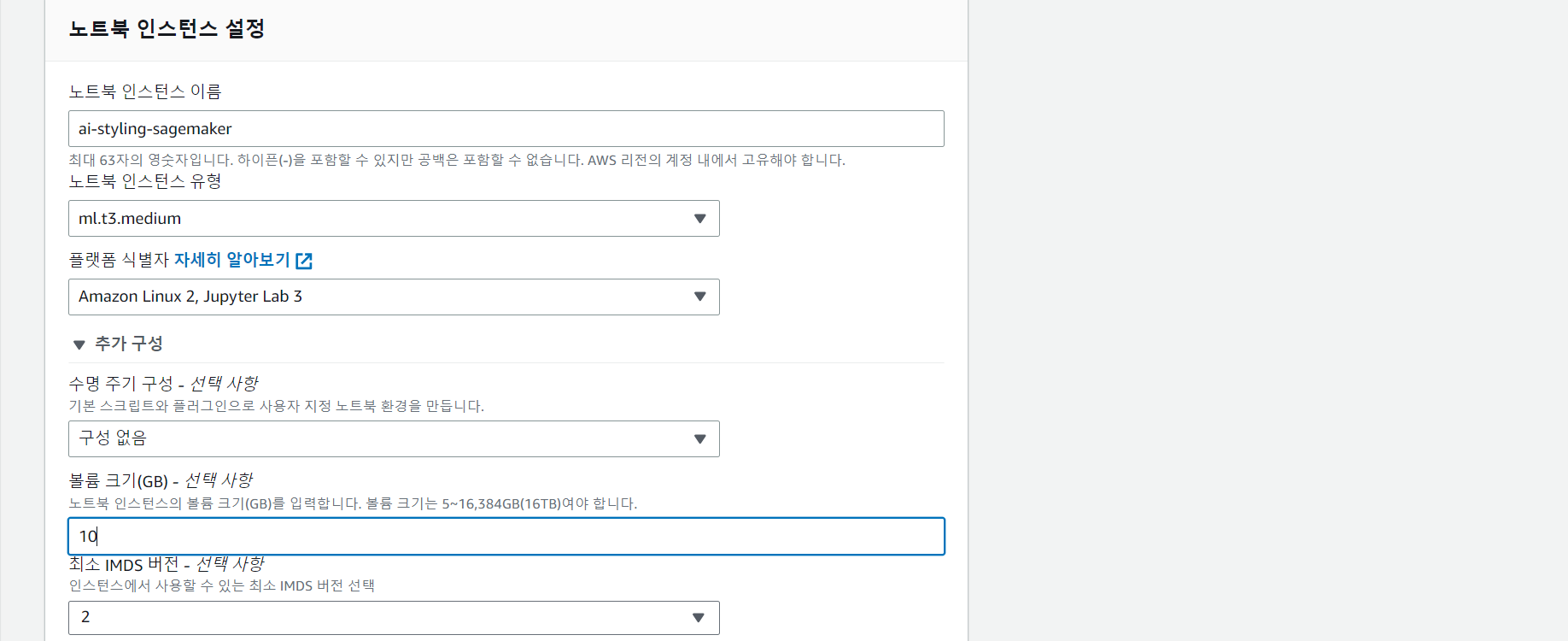
노트북 인스턴스 설정 페이지에서 인스턴스 이름을 적당히 만들어주고 노트북 인스턴스 유형을 선택하면 된다.
나는 노트북 인스턴스 유형에서 ml.t3.medium을 선택했는데, 비용이 발생할 수도 있으므로 주의해야 한다.

나는 캡스톤을 진행하면서 사업단에서 비용을 지원 받긴 했지만, 최대한 효율적으로 사용하려고 했다.
그리고 IAM은 새로 생성해주고, 노트북 인스턴스 생성하기 버튼을 눌러서 노트북 인스턴스를 생성해주고 5분 정도 기다리면 된다.
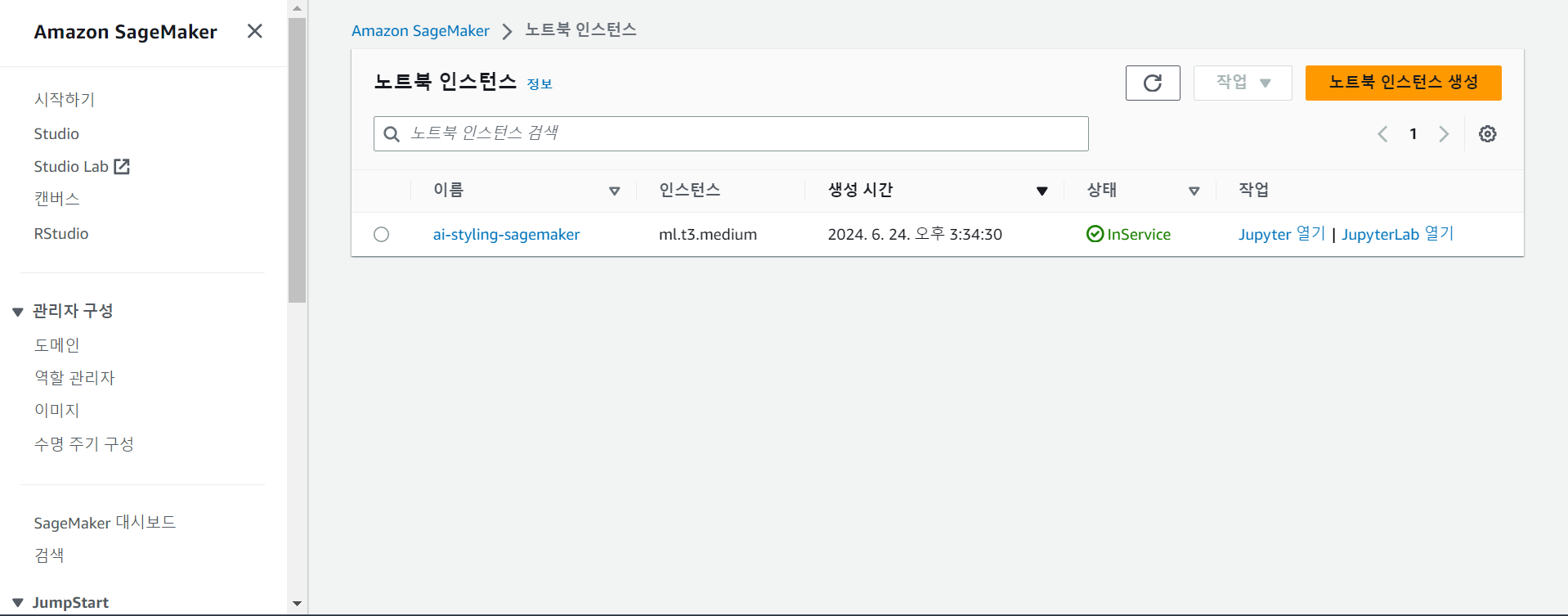
이렇게 인스턴스가 생성되면 Jupyter 열기를 클릭해서 클라우드 Jupyter 노트북으로 접속할 수 있다.
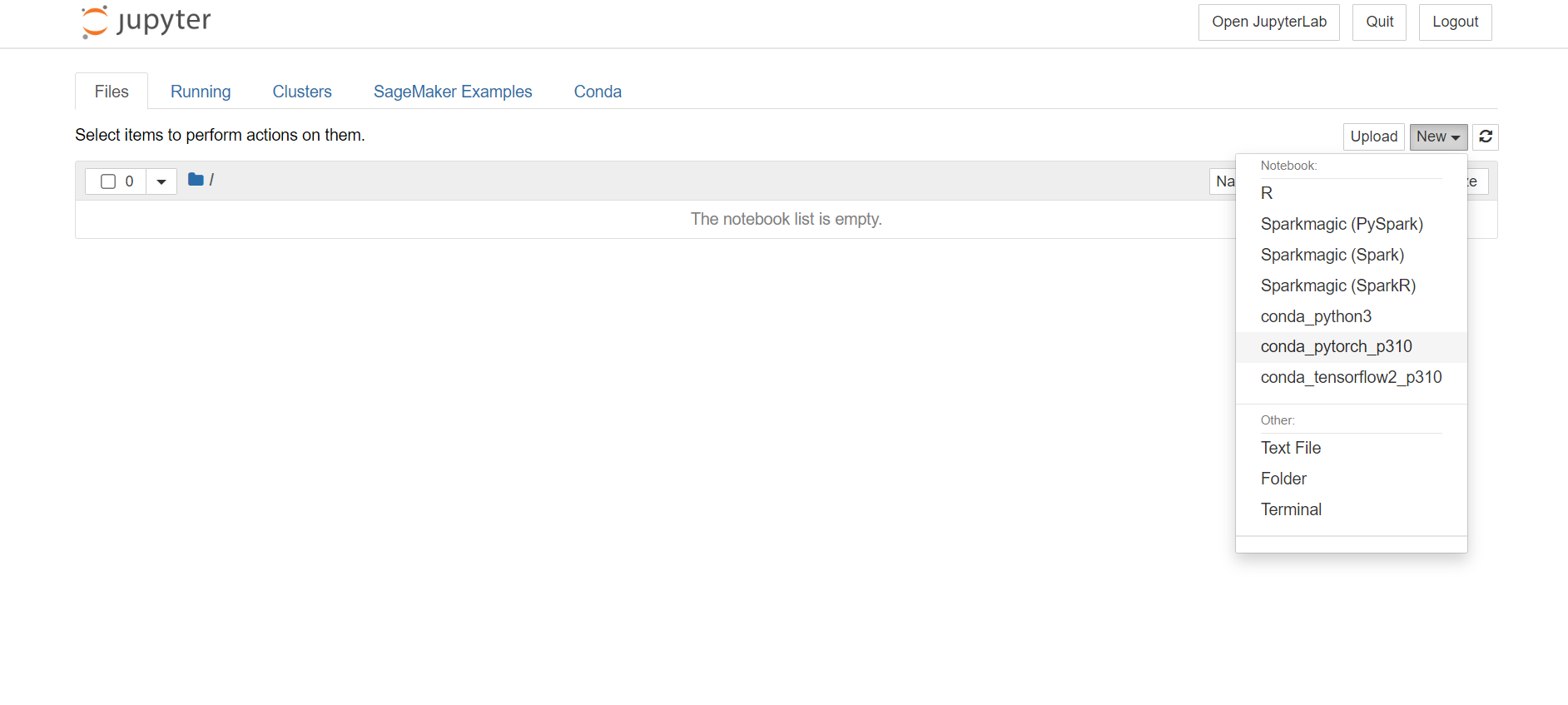
오른쪽 상단 메뉴에 New를 클릭하면 Notebook 파일을 생성할 수 있는데 각자 프레임워크에 맞도록 파일을 생성해주면 된다.
내가 배포하려는 모델은 PyTorch 기반이라서 conda_pytorch_p310으로 파일을 생성해주었다.
이제 Huggingface GitHub Repo이 코드를 그대로 참고하면서 모델을 배포해주면 된다.
코드에서 중요했던 부분들만 언급하면 가장 먼저 자신이 배포하고 싶은 모델의 requirement.txt에서 필요한 dependency를 파악해야 한다.
PhotoMaker 모델은 아래와 같은 dependency들을 필요로 했다.
!pip install torch==2.0.1 torchvision==0.15.2 diffusers==0.25.0 transformers==4.36.2 huggingface-hub==0.20.2 spaces==0.19.4 numpy accelerate safetensors omegaconf peft "gradio>=4.0.0"
!pip install git+https://github.com/TencentARC/PhotoMaker.git
그리고 나서 이후 s3 세션 접근에 필요한 세션을 아래처럼 얻을 수 있다.
import sagemaker
import boto3
sess = sagemaker.Session()
sagemaker_session_bucket=None
if sagemaker_session_bucket is None and sess is not None:
sagemaker_session_bucket = sess.default_bucket()
try:
role = sagemaker.get_execution_role()
except ValueError:
iam = boto3.client('iam')
role = iam.get_role(RoleName='sagemaker_execution_role')['Role']['Arn']
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session region: {sess.boto_region_name}")그리고 각자 모델과 추론 부분을 참고해서 아래처럼 적절하게 변경해주면 된다.
import base64
import torch
import numpy as np
import random
import os
import pathlib
import textwrap
import sagemaker
from io import BytesIO
from datetime import datetime
from IPython.display import display
from IPython.display import Markdown
from PIL import Image
from diffusers.utils import load_image
from diffusers import EulerDiscreteScheduler, DDIMScheduler
from huggingface_hub import hf_hub_download
from photomaker import PhotoMakerStableDiffusionXLPipeline
from sagemaker.s3 import S3Uploader
def model_fn(model_dir, context=None):
photomaker_ckpt = hf_hub_download(repo_id="TencentARC/PhotoMaker", filename="photomaker-v1.bin", repo_type="model")
pipe = PhotoMakerStableDiffusionXLPipeline.from_pretrained(
'SG161222/RealVisXL_V3.0',
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
).to("cuda")
pipe = pipe.to("cuda")
pipe.load_photomaker_adapter(
os.path.dirname(photomaker_ckpt),
subfolder="",
weight_name=os.path.basename(photomaker_ckpt),
trigger_word="img"
)
pipe.id_encoder.to("cuda")
pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
pipe.fuse_lora()
return pipe
def predict_fn(data, pipe):
prompt = data.pop("inputs", data)
images = data.pop("input_id_images", 1)
input_id_images = []
for image_path in images:
input_id_images.append(load_image(image_path))
negative_prompt = "(asymmetry, worst quality, low quality, illustration, 3d, 2d, painting, cartoons, sketch), open mouth"
generator = torch.Generator(device="cuda").manual_seed(42)
## Parameter setting
num_steps = 50
style_strength_ratio = 20
start_merge_step = int(float(style_strength_ratio) / 100 * num_steps)
if start_merge_step > 30:
start_merge_step = 30
images = pipe(
prompt=prompt,
input_id_images=input_id_images,
negative_prompt=negative_prompt,
num_images_per_prompt=1,
num_inference_steps=num_steps,
start_merge_step=start_merge_step,
generator=generator,
).images
encoded_images = []
for image in images:
buffered = BytesIO()
image.save(buffered, format="JPEG")
encoded_images.append(base64.b64encode(buffered.getvalue()).decode())
# create response
return {"images": encoded_images}
이후에 model을 model.tar.gz로 압축해야 하는데, 자신의 HuggingFace 계정의 토큰을 발급 받고, 허깅 페이스 모델 ID를 입력해서 필요한 snapshot을 다운 받아주면 된다.
from distutils.dir_util import copy_tree
from pathlib import Path
from huggingface_hub import snapshot_download
from photomaker import PhotoMakerStableDiffusionXLPipeline
import random
HF_MODEL_ID="TencentARC/PhotoMaker"
HF_TOKEN="hf_OqkPekcvFJKI" # your hf token: https://huggingface.co/settings/tokens
assert len(HF_TOKEN) > 0, "Please set HF_TOKEN to your huggingface token. You can find it here: https://huggingface.co/settings/tokens"
# download snapshot
snapshot_dir = snapshot_download(repo_id=HF_MODEL_ID,use_auth_token=HF_TOKEN)
# create model dir
model_tar = Path(f"model-{random.getrandbits(16)}")
model_tar.mkdir(exist_ok=True)
# copy snapshot to model dir
copy_tree(snapshot_dir, str(model_tar))그리고 아래처럼 model.tar.gz로 압축하면 된다.
import tarfile
import os
# helper to create the model.tar.gz
def compress(tar_dir=None,output_file="model.tar.gz"):
parent_dir=os.getcwd()
os.chdir(tar_dir)
with tarfile.open(os.path.join(parent_dir, output_file), "w:gz") as tar:
for item in os.listdir('.'):
print(item)
tar.add(item, arcname=item)
os.chdir(parent_dir)
compress(str(model_tar))그리고 그 압축파일을 아래처럼 s3 인스턴스를 새로 만들어서 s3로 업로드해주면 된다.
from sagemaker.s3 import S3Uploader
# upload model.tar.gz to s3
s3_model_uri=S3Uploader.upload(local_path="model.tar.gz", desired_s3_uri=f"s3://{sess.default_bucket()}/photomaker")
# s3_model_uri="s3://sagemaker-ap-northeast-2-59018366/photomaker/model.tar.gz"
print(f"model uploaded to: {s3_model_uri}")그리고 자신의 모델에 필요한 Dependency에 맞게 아래 버전들을 변경해주고 적절한 instance_type을 선택해주면 된다.
참고로 ml.g4dn.xlarge은 1시간에 0.7364 USD이다. (대충 900 ~ 1000원 정도)
그리고 predictor로 모델을 배포해주면 된다.
from sagemaker.huggingface.model import HuggingFaceModel
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
model_data=s3_model_uri, # path to your model and script
role=role, # iam role with permissions to create an Endpoint
transformers_version="4.37.0", # transformers version used
pytorch_version="2.1.0", # pytorch version used
py_version='py310', # python version used
)
# deploy the endpoint endpoint
predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type="ml.g4dn.xlarge"
)그러면 아래처럼 Sagemaker 엔드 포인트가 생성된다.
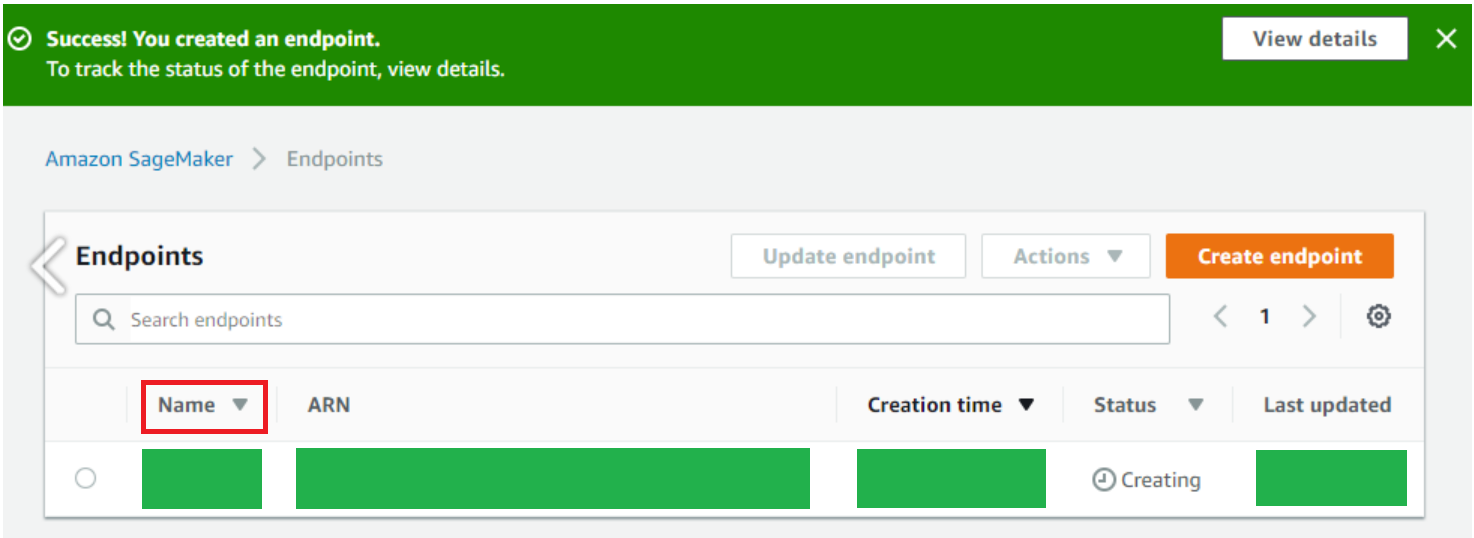
이제 이 엔드 포인트로 Lambda 배포된 모델에 접근할 수 있다.
여기서 주의해야할 점은 엔드 포인트가 남아있는 동안 계속 비용이 발생하기 때문에 배포된 모델을 사용하지 않는다면 꼭 삭제해줘야 한다.
AWS Lambda로 AI API 서버를 구축한 과정은 AWS SQS와 AWS Lambda로 서버 간 통신 구현하기 글에서 계속 된다!
