상속
클래스 간 상속에서 하위 클래스가 생성될 때, 그 전에 상위 클래스의 호출 과정이 필요하다.
class A{
public A(){
System.out.println("Constructor A");
}
}
class B extends A{
public B(){
System.out.println("Constructor B");
}
}
class C extends B{
public C(){
super();
System.out.println("Constructor C");
}
}
public class Test {
public static void main(String[] args) {
C c = new C();
//Constructor A
//Constructor B
//Constructor C 호출
}
}이처럼 상속을 받은 하위 클래스는 상위 클래스의 생성자 중 하나를 선택해서 호출해야 한다.
super()처럼 명시적으로 호출하지 않으면 컴파일러가 자동으로 상위 클래스의 기본 생성자인 super()를 추가해준다.
결과적으로 상위 클래스에서부터 차례대로 클래스들이 생성된다.
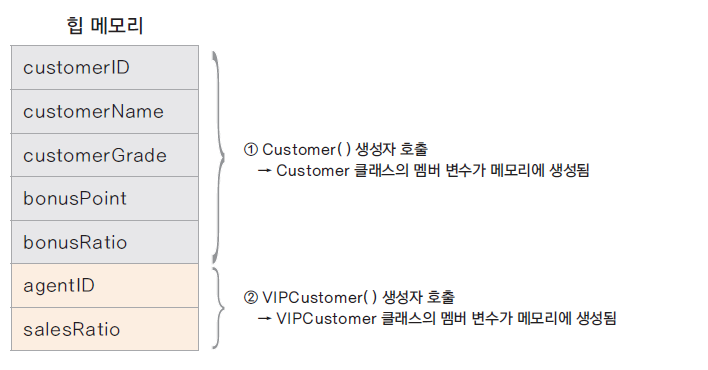
상위 클래스가 힙 메모리에 생성되기 때문에 super를 통해 상위 클래스의 멤버 변수나 메서드에도 접근할 수 있다.
class A{
String s;
public A(){
System.out.println("Constructor A");
}
public void exampleMethod(){
System.out.println("Hello");
}
}
class B extends A{
public B(){
System.out.println("Constructor B");
super.exampleMethod();
super.s = "Hello";
}
}JVM, Virtual method(가상 메서드)
먼저 JVM에 대해 간단히 알아보자.
JVM(Java Virtual Machine)
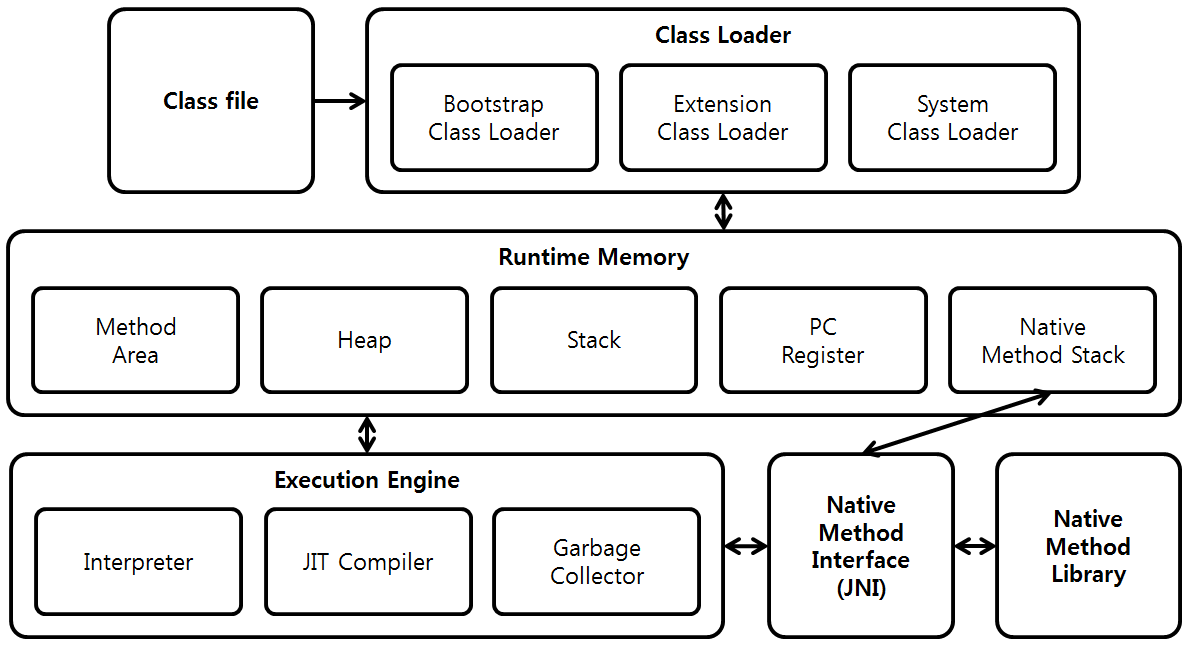
자바 파일(.java)을 컴파일하면 컴파일러에 의해 클래스 파일(.class)이 생성된다.
클래스 파일은 바이트 코드로 이뤄져있으며, JVM이 운영체제에 맞게 클래스 파일을 실행시켜서 자바는 운영체제로부터 독립적이다. (물론 자바는 플랫폼에 독립적이지만, JVM은 플랫폼에 종속적이다.)
클래스 로더(Class Loader)
클래스 로더(Class Loader)는 생성된 클래스 파일(.class)들을 묶어서 메모리(Runtime Memory)에 로드하는 역할을 한다.
실행 엔진(Execution Engin)
실행 엔진은 클래스 로더에 의해 JVM으로 로드된 클래스 파일(바이트코드)을 실행시킨다. 이때 바이트 코드를 명령어 단위로 읽어서 실행한다.
런타임 메모리(Runtime Memory)
런타임 메모리는 스레드를 기준으로 나눠서 분류해볼 수 있다.
- 모든 스레드가 공유해서 사용
- 힙 영역(Heap Area)
- new 키워드로 생성된 객체, 인스턴스 변수와 배열이 생성되는 영역
- Garbage Collection의 대상
- 메서드 영역(Method Area)
- 클래스 멤버 변수의 이름, 데이터 타입, 접근 제어자, 메서드 정보, static 변수, final class등이 생성되는 영역
- 힙 영역(Heap Area)
- 스레드마다 하나씩 생성
- 스택 영역(Stack Area)
- 지역변수, 파라미터, 리턴 값, 연산에 사용되는 임시 값
- PC 레지스터(PC Register)
- 현재 스레드가 실행하는 부분의 주소와 명령을 저장하고 있는 영역
- 네이티브 메서드 스택(Native Method Stack)
- 자바 이외의 언어(C, C++ 등)로 작성된 네이티브 코드를 실행할 때 사용되는 메모리 영역
- 스택 영역(Stack Area)
메서드의 작동 원리
public class TestMethod {
int num; // 인스턴스 변수, new 객체 생성 시 힙에 생성
void aaa() {
System.out.println("aaa() 호출");
}
public static void main(String[] args) {
TestMethod a1 = new TestMethod(); // a1 변수는 스택에 생성
a1.aaa(); // 메서드는 메서드 영역에 한번만 생성
TestMethod a2 = new TestMethod(); // a2 변수는 스택에 생성
a2.aaa();
}
}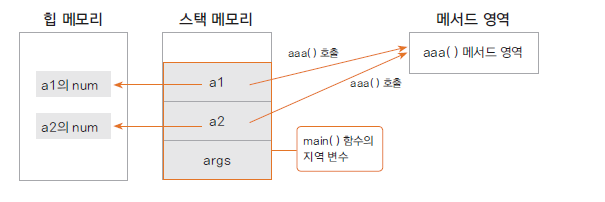
메서드는 프로그램이 메모리에 로딩될 때 메서드 영역(Method Area)에 처음 한번만 로드된다.
또 메서드의 이름은 주소값을 나타내고, 메서드 실행 시 이 주소값으로 가서 메서드를 실행한다. 이때 가상 메서드 테이블을 이용한다.
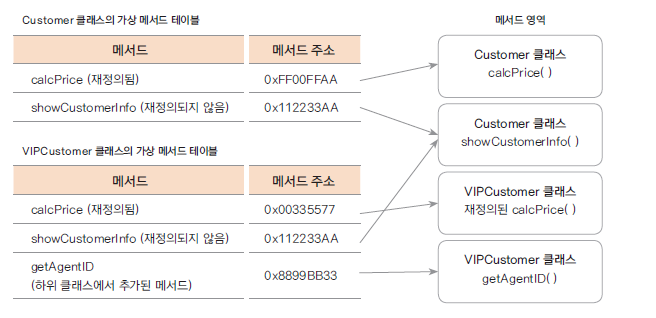
가상 메서드(Virtual Method)
자바는 기본적으로 모든 메서드들이 가상 메서드이므로(final 등 제외) 객체가 만들어질 때마다 각 객체 인스턴스마다 고유한 가상 메서드 테이블을 갖는다.
그리고 객체의 메서드를 호출하면 해당 객체의 가상 메서드 테이블을 참조하여 메서드의 실제 주소를 가져온다.
polymorphism(다형성)
다형성이란?
어떤 객체의 속성(변수)이나 기능(메서드)이 상황에 따라 여러 가지 형태를 가질 수 있는 성질을 의미한다.
다형성은 객체지향에서 핵심적인 특징으로 무척 유용한 개념이다.
다형성 덕분에 훨씬 유연하고 확장가능한 코드 작성이 가능하고 유지보수 측면에서도 편리하다.
예시를 통해 구체적으로 살펴보자.
class Animal{
public void move() {
System.out.println("동물이 움직입니다.");
}
public void eating() {
}
}
class Human extends Animal{
public void move() {
System.out.println("사람이 두발로 걷습니다.");
}
public void readBooks() {
System.out.println("사람이 책을 읽습니다.");
}
}
class Tiger extends Animal{
public void move() {
System.out.println("호랑이가 네 발로 뜁니다.");
}
public void hunting() {
System.out.println("호랑이가 사냥을 합니다.");
}
}
class Eagle extends Animal{
public void move() {
System.out.println("독수리가 하늘을 날아갑니다.");
}
public void flying() {
System.out.println("독수리가 날개를 쭉 펴고 멀리 날아갑니다");
}
}
public class Test {
public static void main(String[] args) {
Animal hAnimal = new Human();
Animal tAnimal = new Tiger();
Animal eAnimal = new Eagle();
ArrayList<Animal> animalList = new ArrayList<Animal>();
animalList.add(hAnimal);
animalList.add(tAnimal);
animalList.add(eAnimal);
for(Animal animal : animalList) {
animal.move();
// 사람이 두발로 걷습니다.
// 호랑이가 네 발로 뜁니다.
// 독수리가 하늘을 날아갑니다.
}
}
}위의 코드에서 각 인스턴스들은 상속을 통해 다형성이 이뤄졌고, 상위 타입으로 캐스팅(Casting)을 통해 각 인스턴스들을 move() 호출을 통해 일관성 있게 사용할 수 있게 되었다.
만약 if나 else if를 통해 구현했다면 유지보수 시 구현된 부분을 매번 수정해야 할 것이다.
반면에 다형성을 이용한다면 각 클래스나 객체만을 수정하는 식으로 훨씬 유지보수가 쉬워진다.
또 클래스나 객체를 추가하는 것만으로 쉽게 확장 가능해진다.
다형성을 구현하는 방법으로는 오버로딩, 오버라이딩이 있다.
오버로딩과 오버라이딩은 단어가 비슷해서 헷갈리기 쉬운데, 오버라이딩은 메서드가 올라탄다고(Overridding) 연상하면 좀더 구분하기 쉬워진다. (김영한님께 들었다.)
그래서 오버라이딩이 상위 클래스의 메서드를 재정의하는 것, 오버로딩은 한 클래스 내부에서 같은 메서드를 재정의하는 것이라고 간단하게 말할 수 있다.
Abstract Class(추상 클래스), Interface(인터페이스)
추상 클래스와 인터페이스
추상 클래스와 인터페이스는 처음 배울 때, 왜 사용하는지 이해하기 어려운 개념이다.
하지만 객체지향에 대한 경험이 쌓이면서 그 가치를 조금씩 이해하게 된다.
간단한 예시로 이해해보자.
abstract class Car { abstract void drive(); }
class Taxi extends Car { void drive() { System.out.println("택시가 부릉부릉"); } }
class Bus extends Car { void drive() { System.out.println("버스가 부릉부릉!"); } }
public class Test {
public static void main(String[] args) {
Car car = new Taxi();
car.drive();
// 택시가 부릉부릉!
}
}이렇게 Taxi와 Bus 클래스가 있다고 생각해보자.
Taxi와 Bus 클래스는 drive라는 공통적인 특성을 가지고 있지만 세부적인 특징은 다르다.
따라서 공통적인 Car 클래스를 상속한 후 각 클래스에 맞게 drive를 구현한다.
그리고 다형성을 결합해서 Car 타입으로 캐스팅(Casting) 해준다면 각 타입으로부터 독립성을 가지게 된다.
이때 car를 Taxi에서 Bus로 바꾸고 싶다고 생각해보자.
abstract class Car { abstract void drive(); }
class Taxi extends Car { void drive() { System.out.println("택시가 부릉부릉"); } }
class Bus extends Car { void drive() { System.out.println("버스가 부릉부릉!"); } }
public class Test {
public static void main(String[] args) {
Car car = new Bus();
car.drive();
// 버스가 부릉부릉!
}
}그럼 위의 car를 new Taxi에서 new Bus로 바꾸는 과정만으로 클래스를 바꿀 수 있게 된다.
즉 유지보수 측면에서 훨씬 편리해진다.
인터페이스도 크게 다르지 않다.
interface Car{ void drive(); }
class Taxi implements Car { public void drive() { System.out.println("택시가 부릉부릉"); } }
class Bus implements Car { public void drive() { System.out.println("버스가 부릉부릉!"); } }
public class Test {
public static void main(String[] args) {
Car car = new Taxi();
// Car car = new Bus();
car.drive();
}
}사실 이 코드는 new Taxi 나 new Bus 의 구현부가 계속 바뀌기 때문에 객체지향적으로 조금 아쉬움이 있다.
객체지향 설계의 5원칙인 SOLID에서는 이럴 때 DIP를 만족하지 못한다고 말한다.
SOLID란?
- SRP: 단일책임원칙, 변경이 있을때 파급효과가 적어야 함
- OCP: 확장에는 열려있고, 변경에는 닫혀있어야 함(인터페이스 활용)
- LSP: 다형성에서 하위 클래스는 인터페이스 규약을 다 지켜야 함
- ISP: 범용 인터페이스보다 여러개의 특정 인터페이스가 더 낫다
- DIP: 추상화에만 의존해야지, 구체화에 의존하면 안된다
이런 이유 때문에 IOC(Inversion of Control, 제어의 역전) 의 개념이 등장하는데 스프링에서는 DI(Dependency Injection, 의존성 주입)로 구현해서 자바를 훨씬 더 객체지향적 사용할 수 있도록 도와준다.
추상 클래스
객체의 공통적인 부분을 추상화한 클래스로, 구현되지 않은 추상 메서드를 가진 클래스
상속과 관련되어 있는 개념으로, abstract로 구현되지 않은 메서드를 가지고 있다. 물론 구현된 메서드도 가질 수 있다.
추상 클래스는 말 그대로 추상 클래스이므로 인스턴스 할 수 없다는 특징을 가지고 있다.
추상 클래스를 상속해서 사용할 경우 하위 클래스에서 추상 메서드를 구현하지 않으면 하위 클래스도 추상 클래스가 된다(이 때는 abstract로 선언해야 한다)
abstract class Computer {
abstract void display();
abstract void typing();
public void turnOn() {
System.out.println("전원을 켭니다.");
}
public void turnOff() {
System.out.println("전원을 끕니다.");
}
}
class DeskTop extends Computer{
@Override
void display() {
System.out.println("DeskTop display");
}
@Override
void typing() {
System.out.println("DeskTop typing");
}
}인터페이스
인터페이스는 모든 메서드가 추상 메서드(public abstract)로 선언된다.
또한 모든 변수들도 상수(public static final)로 선언된다.
메서드들이 전부 추상 메서드로 선언되기 때문에 형 변환되는 경우 추상 클래스에서와 마찬가지로 인터페이스에 선언된 메서드만 사용 가능하다.
default 키워드로 인터페이스 내부에 구현된 메서드를 가질 수 있다.
인터페이스 사이에도 상속이 가능하다.
이때 다중 상속이 가능하고, 구현 코드의 상속이 아니므로 타입 상속이라고 한다.
예를 들어 interface X와 interface Y를 구현한 클래스가 있다고 해보자.
이때 이 클래스는 interface X와 interface Y가 가지고 있는 메서드들을 전부 구현해야 한다.
