대용량 시스템
데이터베이스의 병목 가능성
- 스케일 업(Scale-Up)
- 스케일 업은 단일 서버의 성능을 향상시켜 시스템의 처리 능력을 확장하는 방법
- 스케일 아웃(Scale-Out)
-
스케일 아웃은 여러 개의 서버 또는 머신을 추가하여 시스템의 처리 능력을 확장하는 방법
스케일 업 스케일 아웃 유지보수 및 관리 쉬움 여러 노드에 적절히 부하 분산 필요 확장성 제약이 있음 스케일 업에 비해 자유로움 장애 복구 서버가 1대, 서버 다운 타임 발생 가능 장애 탄력성이 있음
-
따라서 스케일 아웃이 대용량 시스템에서 더 유리하다.
스케일 아웃의 가장 중요한 전제조건은 상태가 없어야 한다.(Stateless)
하지만 데이터베이스의 경우 데이터라는 상태를 관리하고 있기 때문에 서버보다 훨씬 많은 비용이 필요함.
대용량 시스템의 이해
-
대용량 시스템이 어려운 이유?
- 하나의 서버로 감당하기 힘들어 대부분 여러 개의 서버 또는 데이터베이스를 사용
- 여러개의 서버에서 유입되는 데이터의 일관성을 보장해야 함
- 여러 서비스들이 얽혀있어, 시스템 복잡도가 상당히 높음
-
대용량 시스템의 특징
- 고가용성
- 확장성
- 관측 가능성
대용량 시스템 아키텍쳐
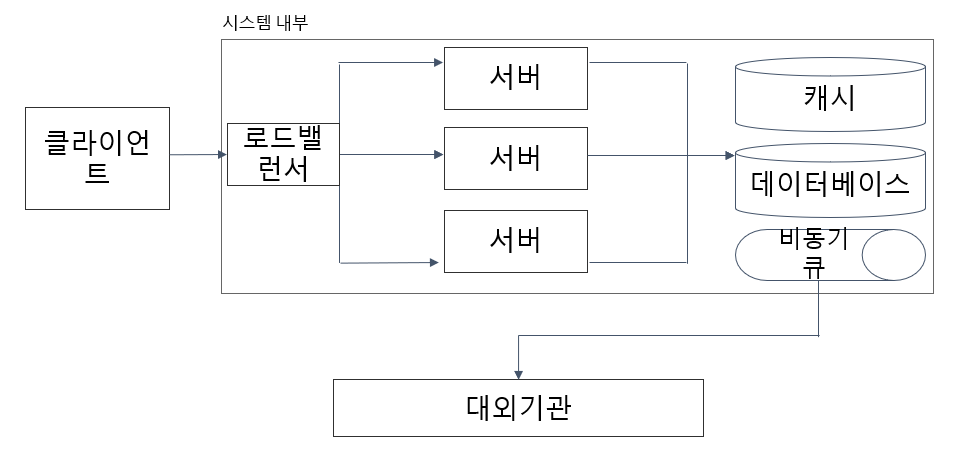
Nginx와 같은 로드밸런서가 먼저 클라이언트의 요청을 받고 서버에게 적절히 분배
데이터베이스는 캐시를 두어서 부하를 최소화하여 응답 속도 개선
이메일, 결제 시스템 같은 대외기관의 요청을 분리해서 비동기큐와 연결해서 응답 속도 개선
MySQL 아키텍쳐
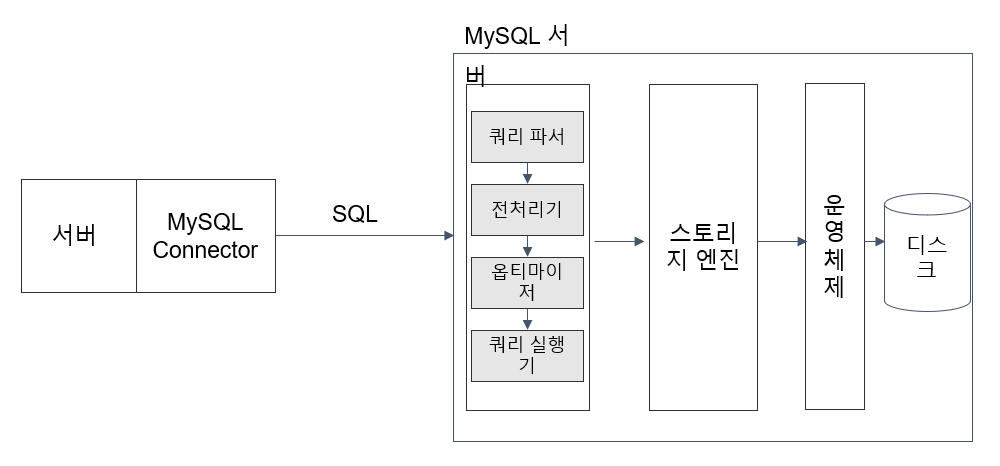
쿼리 파서(Query Parser)는 SQL을 파싱하여 Syntax Tree를 만듬, 컴파일러 과정과 유사하지만 동적으로 결정되는 경우 검증할 수 없기 때문에 매번 구문 평가를 진행(이 과정에서 문법 오류 검사)
전처리기(Preprocessor)는 쿼리 파서에서 만들어준 파싱 트리(Parsing Tree)로 쿼리의 테이블 및 열 이름, 사용자 변수 함수, 접근 권한 등을 확인하고 처리 후 완료된 파싱 트리를 옵티마이저에게 전달
옵티마이저(Optimizer)는 파싱 트리를 입력받아 가능한 실행 계획을 생성하는 단계로, 각 실행 계획 후보들의 비용(인덱스, 조인 순서, 조인 유형 등)을 평가하여 최적의 실행 계획을 선택
쿼리 실행기(Query Executor)는 옵티마이저가 선택한 최적의 실행 계획을 기반으로 실제로 SQL 문을 실행하는 단계
스토리지 엔진(Storage Engine)은 디스크에서 데이터를 가져오거나 저장하는 역할, MySQL 8.0에서는 InnoDB 엔진이 기본값
정규화, 비정규화
정규화란? 중복을 최소화하게 데이터를 구조화하는 프로세스
데이터 설계 관점에서 조회와 쓰기는 트레이드 오프(Trade-off) ****관계이다.
즉, 조회의 비용이 줄어들면 쓰기의 비용이 늘어나고 쓰기의 비용이 줄어들면 조회의 비용이 늘어나게 된다.
| 정규화 | 반(비)정규화 | |
|---|---|---|
| 중복 여부 | 중복을 제거하고 한 곳에서 관리 | 중복을 허용 |
| 데이터 정합성 | 데이터 정합성 유지 쉬움 (쓰기 비용 ↓) | 데이터 정합성 유지 어려움 (쓰기 비용 ↑) |
| 읽기 | 읽기 시 참조 발생 (읽기 비용 ↑) | 참조없이 읽기 가능 (읽기 비용 ↓) |
SNS 시스템 설계
SNS 시스템을 설계하는 과정을 차근차근 따라가보자.
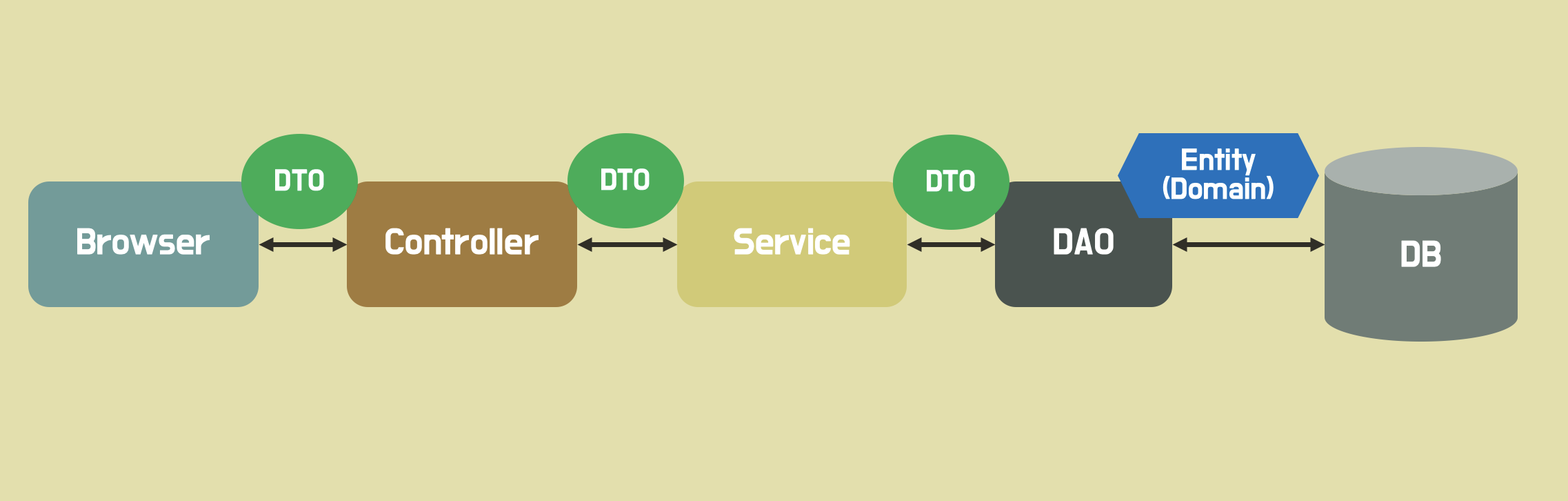
먼저 Service에서 create() 메서드에 RegisterMemberCommand 타입(record)의 객체를 제공 받는다고 가정한다.
@Service
public class MemberWriteService {
@Transactional
public Member create(RegisterMemberCommand command) {
var member = Member.builder() // var는 타입이 명확할 때(여기서는 record로 불변성O), 사용
.email(command.email())
.nickname(command.nickname())
.birthday(command.birthday())
.build();
// ~
}일반적으로 Controller에서 클라이언트로부터 받은 데이터를 Service에 정의된 create() 메서드에 command(member)를 DTO로 전달한 것처럼 DTO를 데이터로 전달하는 방식으로 설계하는 경우가 많다.
- DTO란? DTO는 데이터 전송 객체(Data Transfer Object)로, 데이터를 전송하고 공유하기 위해 사용되는 객체이다. 주로 계층 간 데이터 교환(ex Controller → Service)에 활용되며, 비즈니스 로직을 포함하지 않고 순수하게 데이터를 담는 역할을 한다. 이와 함께 DAO, VO라는 개념도 있다.
내가 아는 DTO 예제는 @Getter만 사용하는 방식으로 구현했었는데, 여기에서는 record를 이용해서 구현하였다.(DTO에 record는 잘 어울린다. Record)
- 자바
record란? 자바 14부터 도입된record는 불변성을 가지는 데이터 객체를 생성하는 데 사용되는 특별한 클래스이다.record는 데이터 저장, 비교, 해시 등의 기능을 자동으로 제공한다.record클래스는final로 선언되며, 필드를private final로 선언한다. 필드는 생성자 매개변수로 전달되고, 자동으로 초기화된다. 또한, 필드의 값을 변경할 수 없기 때문에 불변성(immutable)을 보장한다.record클래스는 자동으로equals(),hashCode(),toString()메서드를 생성한다.
- 자바
record예제// 레코드 public record Book(String title, String author, String isbn) { } // 클래스 // 암시적으로 추상 클래스인 java.lang.Record를 상속받는다. public final class Book extends java.lang.Record { // 레코드의 각 컴포넌트는 내부에서 private final인 인스턴스 필드로 선언된다. private final String title; private final String author; private final String isbn; // 레코드 내부에서 표준 생성자(canonical constructor)가 만들어진다. // 암시적으로 선언된 표준 생성자의 접근 제어자는 레코드의 접근 제어자와 동일하다. public Book(String title, String author, String isbn) { super(); this.title = title; this.author = author; this.isbn = isbn; } // 기본 구현 toString(), hashCode(), equals()은 원하면 변경할 수 있다. @Override public final String toString() { // 내부 구현의 정확한 문자열 포맷은 향후 변경될 수도 있다. return "Book[" + this.title + ", " + this.author + ", " + this.isbn + "]"; } // 암시적 구현은 동일한 컴포넌트로부터 생성된 두 레코드는 해시 코드가 동일해야 한다. @Override public final int hashCode() { // 구현에 사용되는 정확한 알고리즘은 정해지지 않았으며 향후 변경될 수 있다. int result = title == null ? 0 : title.hashCode(); result = 31 * result + (author == null ? 0 : author.hashCode()); result = 31 * result + (isbn == null ? 0 : isbn.hashCode()); return result; } // 암시적 구현은 두 레코드의 모든 컴포넌트가 서로 동일하면 true를 반환한다. @Override public final boolean equals(Object o) { // 구현에 사용되는 정확한 알고리즘은 정해지지 않았으며 향후 변경될 수 있다. if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Book book = (Book) o; return Objects.equals(title, book.title) && Objects.equals(author, book.author) && Objects.equals(isbn, book.isbn); } // 컴포넌트명과 동일한 게터(getter)가 선언된다. public String title() { return this.title; } public String author() { return this.author; } public String isbn() { return this.isbn; } }
public record RegisterMemberCommand(String email, String nickname, LocalDate birthday) {}그럼 @Service에서 사용할 Domain의 Entity인 Member가 필요하다.
@Getter
public class Member {
final private Long id;
private String nickname; // 바뀔 수도 있어서 final 선언 x
final private String email;
final private LocalDate birthday;
final private LocalDateTime createdAt;
final private static Long NAME_MAX_LENGTH = 10L;
@Builder
public Member(Long id, String nickname, String email, LocalDate birthday, LocalDateTime createdAt) {
this.id = id;
this.email = Objects.requireNonNull(email);
this.birthday = Objects.requireNonNull(birthday);
validateNickname(nickname);
this.nickname = Objects.requireNonNull(nickname);
this.createdAt = createdAt == null ? LocalDateTime.now() : createdAt;
}
private void validateNickname(String nickname) {
Assert.isTrue(nickname.length() <= NAME_MAX_LENGTH, "최대 길이를 초과했습니다.");
}
}Member 클래스의 멤버 변수는 nickname을 제외하곤 변경될 일이 없으므로 final private으로 선언했다.
@Builder 어노테이션은 객체 생성과정에서 필드 값을 설정하는 과정을 간소화하고 가독성을 향상시키기 위해서 사용한다.
일반적으로 객체의 필드를 설정하려면 각 필드에 대한 setter 메서드를 호출해야 한다.
그러나 @Builder 어노테이션을 사용하면 setter 메서드를 명시적으로 호출하지 않고도 필드 값을 설정할 수 있다.
또 위 코드에서 주의깊게 봐야할 부분이 Objects.requireNonNull() 와 Assert.isTrue()이다.
Objects.requireNonNull()의 경우에는 주어진 값이 Null이면 NullPointerException를 발생시킨다.
Assert.isTrue(**)**의 경우에도 조건식이 false이면 IllegalArgumentException를 발생시킨다.(Assert는 테스트 코드 작성시 많이 사용한다)
위와 같이 일부로 컴파일 에러를 발생시키는 이유는 프로그램 실행 중 발생할 수 있는 에러를 조기에 발견하기 위해서이다.(런타임 에러는 무척 위험하다..)
따라서 개발과정 중 컴파일 과정에서 발생하는 컴파일 에러가 가장 좋은 에러라고 할 수 있다.
NAME_MAX_LENGTH부분도 직접 값을 사용하지 않고,
final private static Long NAME_MAX_LENGTH = 10L;처럼 상수로 선언해서 조건식에서 사용하는 점도 주목할만하다.(가독성이 좋아짐, Enum 클래스로 만들어서 사용하기도 함)
이제 Controller를 살펴보자.
@RequiredArgsConstructor
@RestController
@RequestMapping("/members")
public class MemberController {
final private MemberWriteService memberWriteService;
//final private MemberReadService memberReadService;
@PostMapping("")
public MemberDto register(@RequestBody RegisterMemberCommand command) {
var member = memberWriteService.create(command);
// return memberReadService.toDto(member);
}@RequestMapping은 ~/members로 끝나는 URL 요청을 해당 Controller에서 처리하기 위해 사용되었다.
@RequiredArgsConstructor는 final로 선언된 필드의 객체를 주입받기 위해(생성자를 만들어서 초기화) 사용했다. 스프링에서 많이 사용되는 DI 패턴이다.
@RestController의 경우 해당 어노테이션의 내부를 살펴보면 @ResponseBody와 @Controller이 함께 사용되고 있다는 것을 확인할 수 있다.
@ResponseBody의 경우 Controller의 메서드가 반환하는 응답 데이터를 HTTP 응답의 본문(body)으로 사용하도록 지정하는 어노테이션이다. 최근에는 JSON으로 데이터를 주고받는 방식이 많이 사용되기 때문에 @ResponseBody로 자바 객체를 JSON 데이터로 변환해서 응답을 보내주기 위해 사용된다. 이 코드에서는 register() 메서드가 MemberDto 타입을 리턴한다는 것을 통해 알 수 있다.
@RequestsBody도 @ResponseBody와 비슷하게 클라이언트가 HTTP Body에 담긴 JSON 형식으로 데이터를 요청할 때, Controller에서 간단하게 자바 객체로 변환하기 위해 사용한다. 주로 위 코드처럼 파라미터에 사용된다.
이제 Repository를 살펴보자.
@RequiredArgsConstructor
@Repository
public class MemberRepository {
private final NamedParameterJdbcTemplate namedParameterJdbcTemplate;
private Member insert(Member member) {
SimpleJdbcInsert jdbcInsert = new SimpleJdbcInsert(namedParameterJdbcTemplate.getJdbcTemplate())
.withTableName(TABLE)
.usingGeneratedKeyColumns("id");
SqlParameterSource params = new BeanPropertySqlParameterSource(member);
var id = jdbcInsert.executeAndReturnKey(params).longValue();
return Member.builder()
.id(id)
.nickname(member.getNickname())
.email(member.getEmail())
.birthday(member.getBirthday())
.build();
}
@RequiredArgsConstructor로 private final NamedParameterJdbcTemplate 객체를 주입 받고 있다.
- NamedParameterJdbcTemplate이란? NamedParameterJdbcTemplate은 스프링 프레임워크에서 제공하는 JDBC (Java Database Connectivity) 기반의 데이터베이스 액세스 기술 중 하나이다. 이 클래스는 이름 기반의 매개변수 바인딩을 지원하여 SQL 쿼리를 안전하고 편리하게 실행할 수 있도록 도와준다. 일반적인 JDBC의 경우, 쿼리 문자열 내에
?와 같은 플레이스홀더를 사용하고,PreparedStatement객체의 인덱스를 이용하여 값을 바인딩한다.하지만 이 방식은 유지보수에 어렵기 때문에?대신 변수 이름을 사용해서 바인딩할 수 있도록 NamedParameterJdbcTemplate를 사용한다.
SimpleJdbcInsert는 JDBC로 SQL 쿼리를 실행하는 것보다 더 쉽고 간편하게 DB에 데이터를 추가할 수 있도록 도와준다.
SimpleJdbcInsert jdbcInsert = new SimpleJdbcInsert(namedParameterJdbcTemplate.getJdbcTemplate())
.withTableName(TABLE)
.usingGeneratedKeyColumns("id");위의 예제처럼 SimpleJdbcInsert 객체를 만들고 테이블 이름과 키로 사용할 컬럼의 이름을 체이닝으로 입력해준다.
SqlParameterSource params = new BeanPropertySqlParameterSource(member);
var id = jdbcInsert.executeAndReturnKey(params).longValue();BeanPropertySqlParameterSource는 입력받은 객체의 속성 값을 매개변수로 사용해서 SQL 쿼리를 실행할 수 있도록 도와준다. NamedParameterJdbcTemplate와 비슷하게 변수 기반의 매개변수 바인딩이 자동으로 이뤄진다고 생각하면 이해가 빠르다.
executeAndReturnKey는 Insert 문을 실행해서 DB에 데이터를 넣고 Key값을 반환하는 메서드이다.
@RequiredArgsConstructor
@Repository
public class MemberRepository {
public Optional<Member> findById(Long id) {
var sql = String.format("SELECT * FROM %s WHERE id = :id ", TABLE);
var params = new MapSqlParameterSource()
.addValue("id", id);
RowMapper<Member> rowMapper = (ResultSet resultSet, int rowNum) -> Member
.builder()
.id(resultSet.getLong("id"))
.email(resultSet.getString("email"))
.nickname(resultSet.getString("nickname"))
.birthday(resultSet.getObject("birthday", LocalDate.class))
.createdAt(resultSet.getObject("createAt", LocalDateTime.class))
.build();
var member = namedParameterJdbcTemplate.queryForObject(sql, params, rowMapper);
return Optional.ofNullable(member);
}
}findById()는 메서드 이름을 통해 알 수 있듯이 id로 DB를 조회하는 역할을 하는 메서드이다.
sql은 String.format을 이용해서 sql문의 형식을 만든 후 MapSqlParameterSource()를 이용해서 sql의 :id와 id 변수를 바인딩 시키고 있다.
그리고 처음 봤을 때 이해가 가지 않았던 부분이 바로 rowMapper였다.
RowMapper<Member> rowMapper = (ResultSet resultSet, int rowNum) -> Member
.builder()
// ...그래서 RowMapper 타입을 열어보니 다음과 같은 인터페이스를 확인할 수 있었다.
@FunctionalInterface
public interface RowMapper<T> {
@Nullable
T mapRow(ResultSet rs, int rowNum) throws SQLException;
}알고보니 람다식을 이용한 익명함수로 인터페이스를 구현한 코드였다.
- 함수형 인터페이스 다른 예제
@FunctionalInterface interface MyLambdaFunction { int max(int a, int b); } public class Lambda { public static void main(String[] args) { // 람다식을 이용한 익명함수 MyLambdaFunction lambdaFunction = (int a, int b) -> a > b ? a : b; System.out.println(lambdaFunction.max(3, 5)); } }
rowMapper은 Builder 패턴을 활용해서 ResultSet의 각 행을 Member Entity로 매핑하는 역할을 하고 있다.
namedParameterJdbcTemplate.queryForObject(sql, params, rowMapper)로 JDBC를 이용해서 DB에서 Member 객체를 조회할 수 있었다.
Resource Link
