문자열과 코드포인트 시퀀스 상호 변환
let str = String.fromCodePoint(0x48, 0x69, 0x20, 0x1F310, 0x21) // 'Hi 🌐!'
let codePoints = [0x48, 0x69, 0x20, 0x1F310, 0x21]
str = String.fromCodePoint(...codePoints)
let characters = [...str] // ['H', 'i', ' ', '🌐', '!']
codePoints = [...str].map(c => c.codePointAt(0)) // [72, 105, 32, 127760, 33]부분문자열
indexOf : 문자열에서 발견된 첫번째 문자열
startsWith, endsWith, includes : 블리언을 결과로 반환
substring : 두개의 오프셋 이용해 부분문자열 추출
slice : substring 과 비슷하나 더 많은 기능을 제공하여 더 사용을 권장
split : 구분자 기준으로 문자열 분리
기타 문자열 메서드
repeat : 주어진 만큼 문자열 반복
trim, trimStart, trimEnd : 앞뒤의 여백문자 제거
padStart, padEnd : 앞뒤의 패딩문자 추가
toUpperCase, toLowerCase : 문자열 전체를 대문자 또는 소문자로 변환
concat : 한 문자열로 변환
encodeURIComponent : utf문자열로 인코딩한 다음 각 바이트를 %hh 코드로 인코딩
encodeURI : 전체 url 을 인코딩한다.
태그된 템플릿 리터럴
태그함수 - 함수를 템플릿 리터럴를 통해 읽기 쉽게 호출할 있다.
HTML템플릿을 만들거나 숫자포맷을 정하거나 국제화 구현에 활용할 수 있다
const strong = (fragments, ...values) => {
let result = fragments[0]
for (let i=0; i< values.length; i++)
result += `<strong>${values[i]}</strong>${fragments[i+1]}`
return result
}
const person = { name: 'hanry', age: 44 }
strong`Next year, ${person.name} will be ${person.age + 1}.`
// 위 구분은 아래처럼 strong 함수를 호출하는 것이다.
strong(['Next year, ', ' will be ', '.'], person.name, person.age)정규표현식
정규표현식 문법

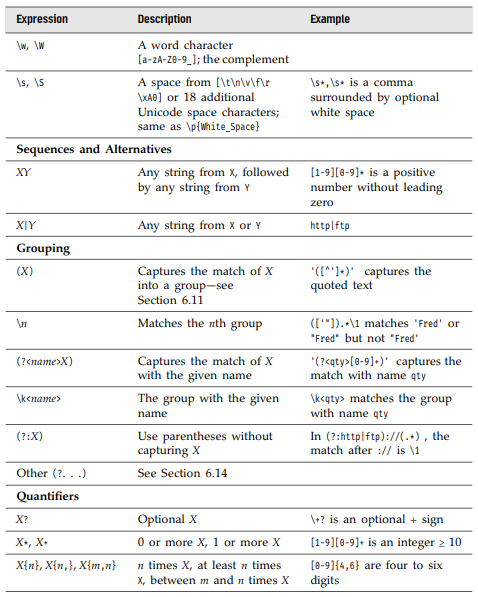
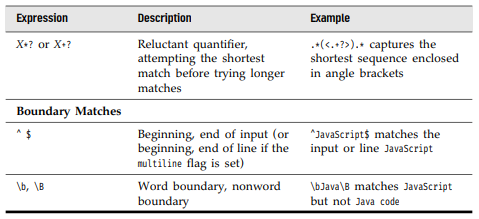
정규표현식 리터럴
정규표현식 리터럴은 앞뒤의 슬래시로 구분된다
const timeRegex = /^([1-9]|1[0-2]):[0-9]{2} [ap]m$/정규표현식내에서 특별한 의미를 갖는 문자를 이스케이프하려면 역슬래시를 사용한다.
const fractionalNumberRegex = /[0-9]+\.[0-9]*/플래그
| 한철자 | 프로퍼티 이름 | 설명 |
|---|---|---|
| i | ignoreCase | |
| m | multline | |
| s | dotAll | .는 새로운 행을 매치 |
| u | unicode | 코드유닛대신 유니코드문자을 매치 |
| g | global | 모든 매치를 찾음 |
| y | stiky | 반드시 regex.lastIndex 에서 매치를 시작해야함 |
정규표현식과 유니코드
정규표현식은 유니코드가 아닌 UTF-16 코드유닛으로 동작한다. .패턴은 한개의 UTF-16 코드유닛을 찾는다.
a = 'Hello 🌐'
a.match(/Hello .$/) // null
a.match(/Hello .$/u) // ['Hello 🌐', index: 0, input: 'Hello 🌐', groups: undefined]
a.match(/Hello \u{1F310}$/u) // ['Hello 🌐', index: 0, input: 'Hello 🌐', groups: undefined]RegExp 클래스의 메서드
/[0-9]+/.test('agent 007') // true
/[0-9]+/.exec('agent 007 and 009') // ['007', index: 6, input: 'agent 007 and 009', groups: undefined]
let digit = /[0-9]+/g
digit.exec('agent 007 and 009') // ['007', index: 6, input: 'agent 007 and 009', groups: undefined]
digit.exec('agent 007 and 009') // ['009', index: 14, input: 'agent 007 and 009', groups: undefined]
digit.exec('agent 007 and 009') // null
digit.exec('agent 007 and 009') // ['007', index: 6, input: 'agent 007 and 009', groups: undefined]
'agent 007 and 009'.match(/[0-9]+/g) // ['007', '009']그룹
괄호로 그룹이 지정되고 여는 괄호의 순서에 따라 그룹의 숫자가 정해진다. 그룹 0 번은 매치된 전체문자열을 가리킨다.
여는 괄호뒤에 ?: 를 붙이면 그룹을 생략한다.
/(['"]).*\1/ // "Fred" 와 'Fred'
/(?<quote>['"]).*\k<quote>/ // "Fred" 와 'Fred'
let lineItem = /(?<item>\p{L}+(\s+\p{L}+)*)\s+(?<currency>[A-Z]{3})(?<price>[0-9.]*)/u
let result = lineItem.exec('Blackwell Toaster USD29.95')
let groupMatches = result.groups
// { item: 'Blackwell Toaster', currency: 'USD', price: '29.95' }
String 메서드와 정규표현식
전역플래그를 설정하지 않은 상태에선 str.match(regex) 결과는 regex.exec(str) 결과와 같지만 전역플래그를 설정하면 결과배열을 반환한다.
'agents 007 and 008'.match(/[0-9]+/) // ['007', index: 7, . . .]
'agents 007 and 008'.match(/[0-9]+/g) // ['007', '008']전역검색을 exec 를 통해 반복하지 않고 matchAll 메서드를 사용하면 편리하다. matchAll 메서드는 결과를 게으르게 반환한다.
search 메서드는 첫번째 매치인덱스 또는 결과가 없을때 -1 을 반환
replace 메서드는 처음 일치하는 문자열을 제공된 문자열로 바꾼다. 모두 바꾸려면 전역플래그를 설정한다.
'agents 007 and 008'.replace(/[0-9]/g, '?') // 'agents ??? and ???'split 메서드는 정규표현식을 인수로 받을수 있다
'aaa , bbb , ccc, ddd'.split(/\s*,\s*/) // ['aaa', 'bbb', 'ccc', 'ddd']정규표현식의 replace 메서드
교체문자열 패턴
| 패턴 | 설명 |
|---|---|
| $`,$' | 매치된 문자열의 앞부분 또는 뒷부분 |
| $& | 매치된 문자열 |
| $n | n번째 그룹 |
| $<이름> | 주어진 이름의 그룹 |
| $$ | 달러기호 |
'hello'.replace(/[aeiou]/g, '$&$&$&') // 'heeellooo'
'Harry Smith\nSally Lin'.replace(/^([A-Z][a-z]+) ([A-Z][a-z]+)/gm, "$2, $1")
// 'Smith, Harry\nLin, Sally'
'Harry Smith\nSally Lin'.replace(/^(?<first>[A-Z][a-z]+) (?<last>[A-Z][a-z]+)$/gm, "$<last>, $<first>")
// 'Smith, Harry\nLin, Sally
// $ 기호뒤의 숫자가 그룹번호보다 크면 그 문자 그대로 사용한다.
'Blackwell Toaster $29.95'.replace('\$29', '$19') // 'Blackwell Toaster $19.95'
문자열 대신 함수를 제공해서 더 복잡한 문자열 교체작업을 수행할 수 있다. 함수는 다음을 인수로 받는다.
- 정규표현식과 매치된 문자열, 모든 그룹의 매치, 매치의 오프셋, 전체문자열
'Harry Smith\nSally Lin'.replace(/^([A-Z][a-z]+) ([A-Z][a-z]+)/gm, (match, first, last) => `${last}, ${first[0]}.`)
//'Smith, H.\nLin, S.'특이한 기능
'"Hi" and "Bye"'.match(/".*"/g) // ['"Hi" and "Bye"']
'"Hi" and "Bye"'.match(/"[^"]*"/g) // ['"Hi"', '"Bye"']
'"Hi" and "Bye"'.match(/".*?"/g) // ['"Hi"', '"Bye"']미리보기 lookahead p(?=q) p 그리고 q 가 이어서 등장할때 p 를 매치하여 q 는 포함하지 않는다. 예를들어 다음은 시간 뒤에 콜론이 등장할때 시간을 찾는 코드다.
'10:30 - 12:00'.match(/[0-9]+(?=:)/g) // ['10', '12']역전된 미리보기 연산자 p(?!q) 는 p가 등장하지만 q는 뒤따르지 않을때 p를 매치한다.
'10:30 - 12:00'.match(/[0-9]{2}(?!:)/g) // ['30', '00']뒤돌아보기 lookbehind 연산자 (?<=p)q 는 p가 앞서 등장할때 q를 매치한다.
'10:30 - 12:00'.match(/(?<=[0-9]+:)[0-9]{2}/g) // ['30', '00']역전된 뒤돌아보기 연산자 (?<!p)q 는 p가 앞서 등장하지 않을때 q 를 매치한다.
'10:30 - 12:00'.match(/(?<![0-9:])[0-9]+/g) // ['10', '12']연습문제
