
search API 사용 결과를 통계 처리하는 Aggregation
출처:
김종민 님이 집필하신 Elastic 가이드북 (추천 ⭐⭐⭐⭐⭐)
감성코더 둥기, [ElasticSearch] 카디날리티 집계(Cardinality Aggregation)
1. Aggregation
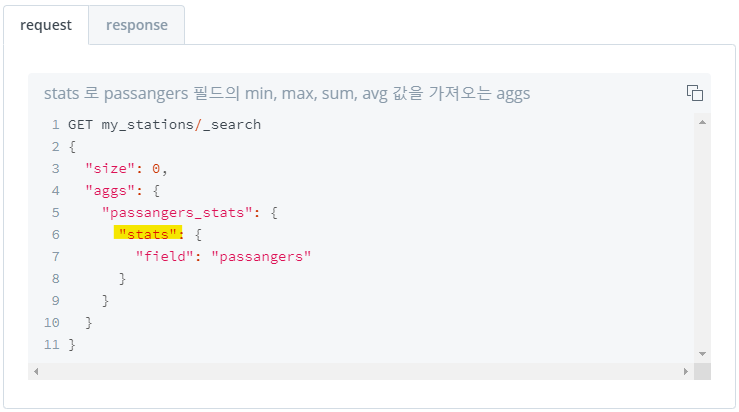
1) 기초 통계 일괄 집계 : stats
- 특정 field 값의 기초 통계 값 일괄 집계
count,min,max,avg,sum값 일괄 집계
2) 기초 통계 단일 집계 : count / min / max / avg / sum
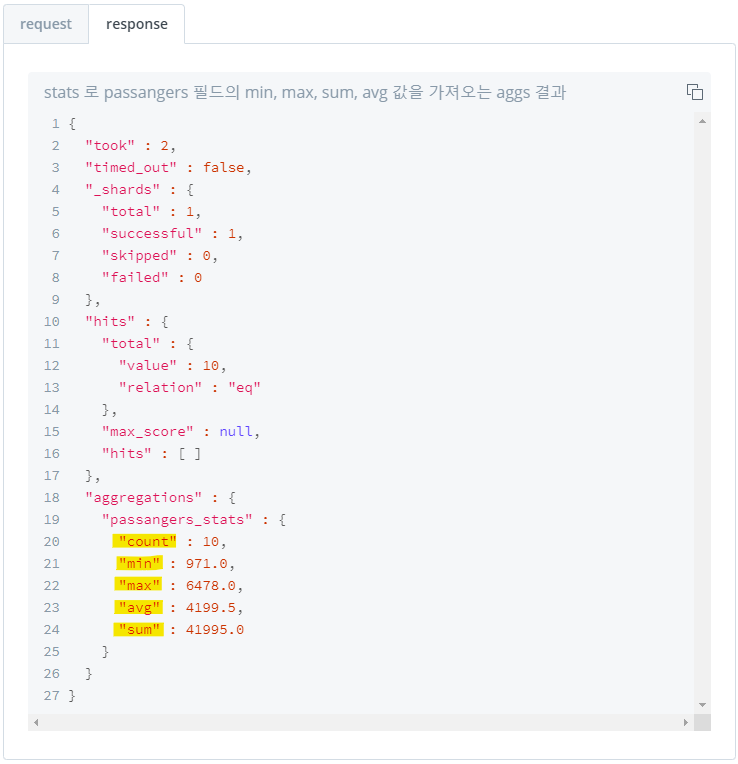
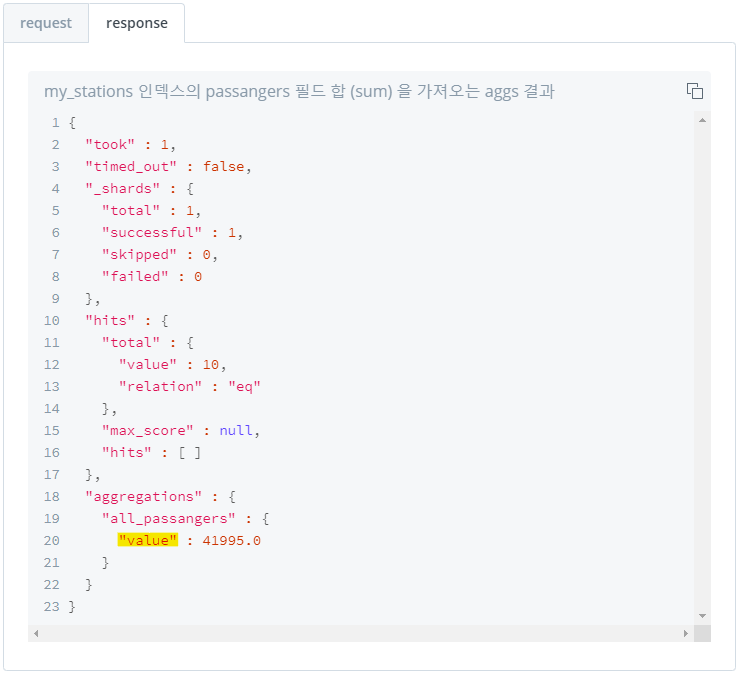
- 특정 field 값의
count,min,max,avg,sum값 단일 집계 - 아래 이미지의 "sum" 자리에 구하고 싶은 값 명시하면 해당 값 집계

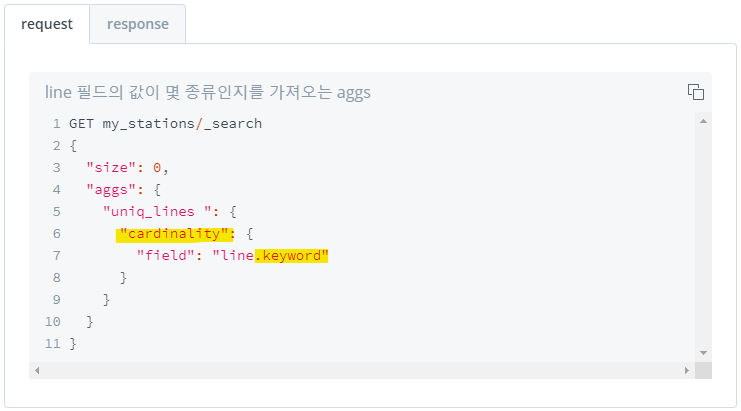
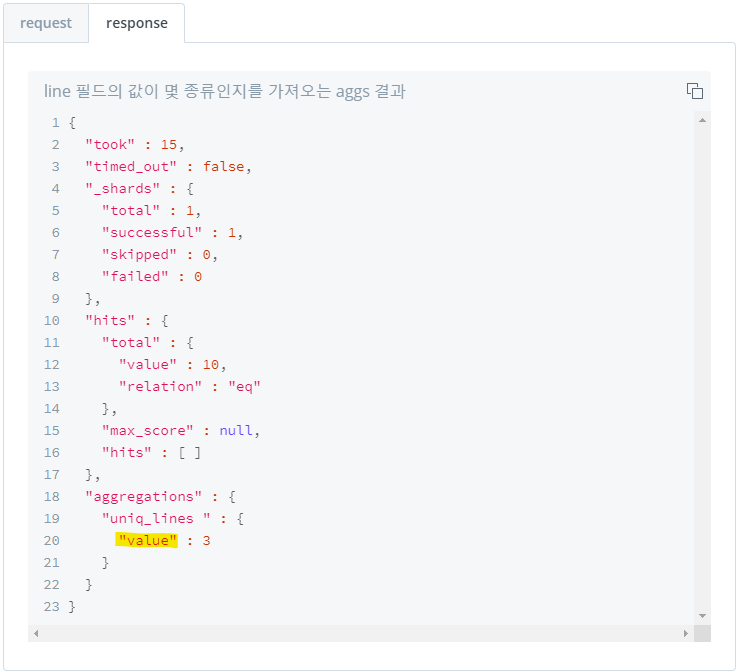
3) 필드 내 고유한 값의 대략적인 개수 집계 : cardinality
- Elasticsearch의 cardinality는 HLL 알고리즘 기반
- HLL 알고리즘 특징
- 정확도(percision) 설정 가능
- 정확도가 높을수록 메모리 사용량 증가
- cardinality가 낮을수록 정확도 높음 - text 타입 field에서 사용할 경우, 뒤에
.keyword붙여 keyword 타입으로 변환해주어야 함
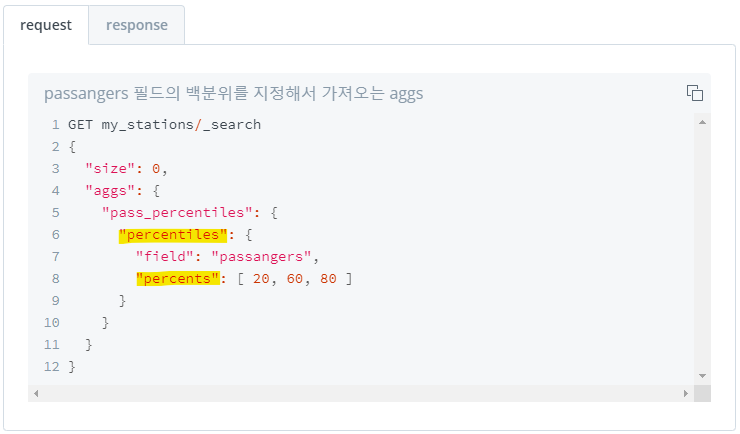
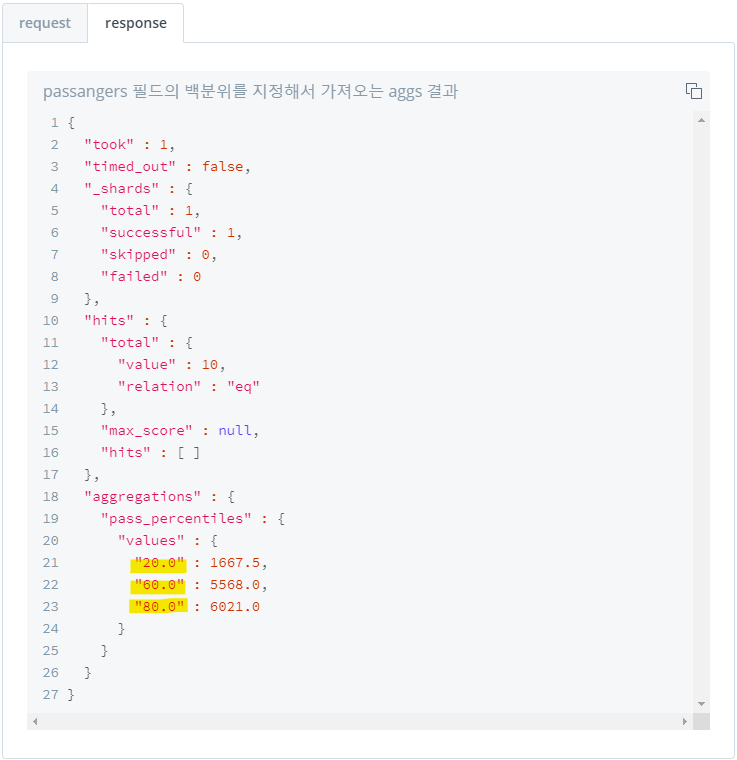
4) 백분위 구간 집계 : percentiles
- 백분위 구간 값 집계
- default는
1%,5%,25%,50%,75%,95%,99%구간에 위치 해 있는 값 집계 - "percents"로 백분위 구간 지정 가능
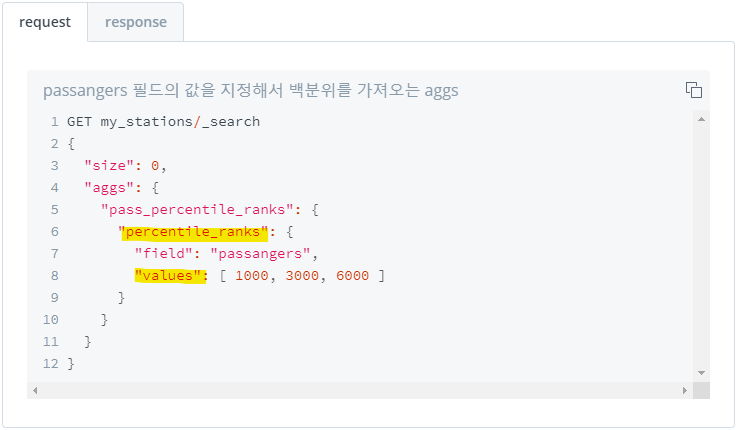
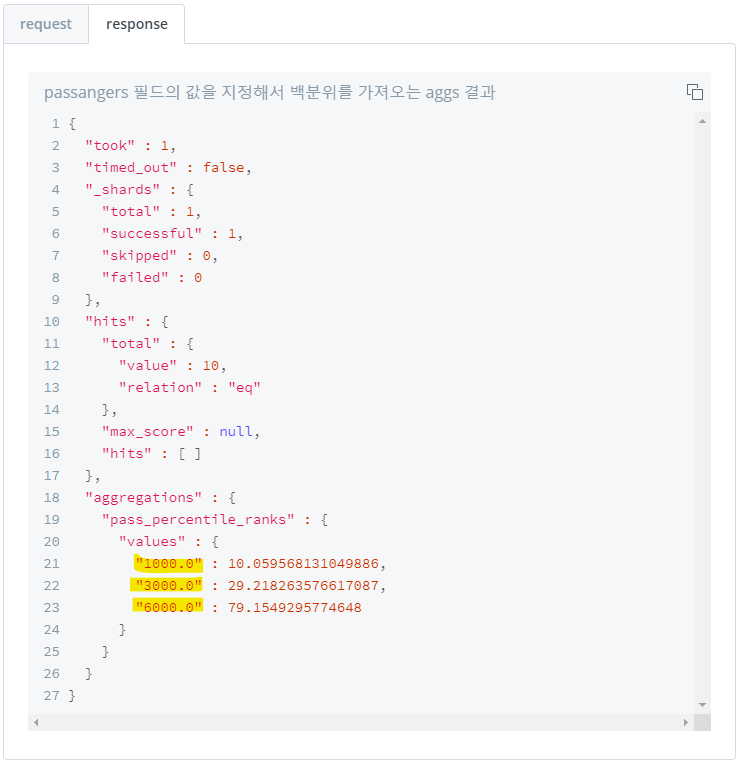
5) 특정 값의 백분위 수 집계 : percentile_ranks
- 값을 입력하여 해당 값의 백분위 수 집계
2. Bucket Aggregation
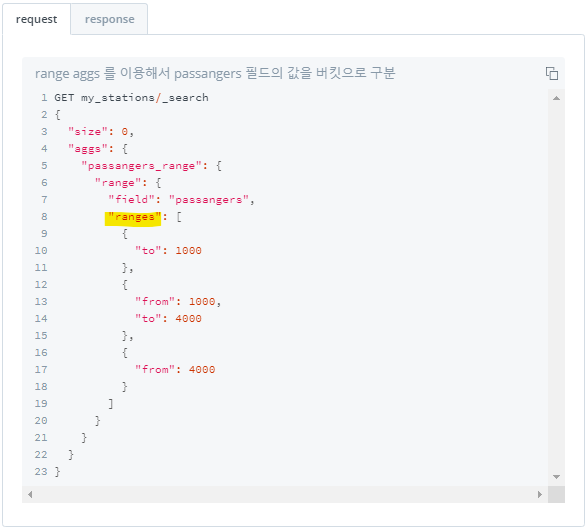
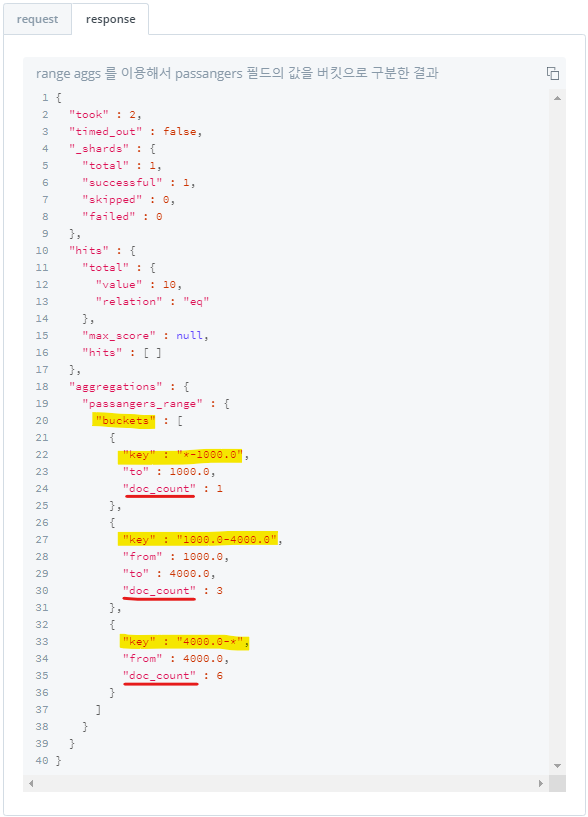
1) 범위 지정하여 버킷 나누기 : range
from,to로 범위를 지정하여 버킷 나누기- 해당 버킷별로 몇 개의 document가 포함되어있는지 결과 출력
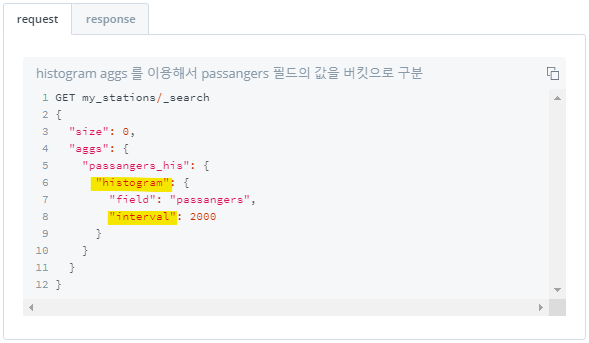
2) 인터벌 지정하여 버킷 나누기 : histogram
interval로 버킷 크기(구간 크기) 지정하여 버킷 나누기- 해당 버킷별로 몇 개의 document가 포함되어있는지 결과 출력

3) 날짜 필드 버킷 나누기 : date_range / date_histogram
- 날짜 기준 버킷 나누기
- 해당 버킷별로 몇 개의 document가 포함되어있는지 결과 출력
- 버킷 키 부분 format 지정 가능
(예:format: "yyyy-MM-dd"뒤에 시간 부분 빼고 날짜까지만 키로 지정)
>> date_range
from,to로 날짜 범위 지정하여 버킷 나누기
>> date_histogram
interval에day,month,year명시하여 버킷 나누기
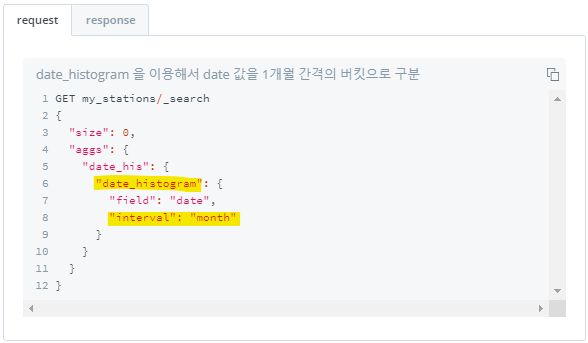
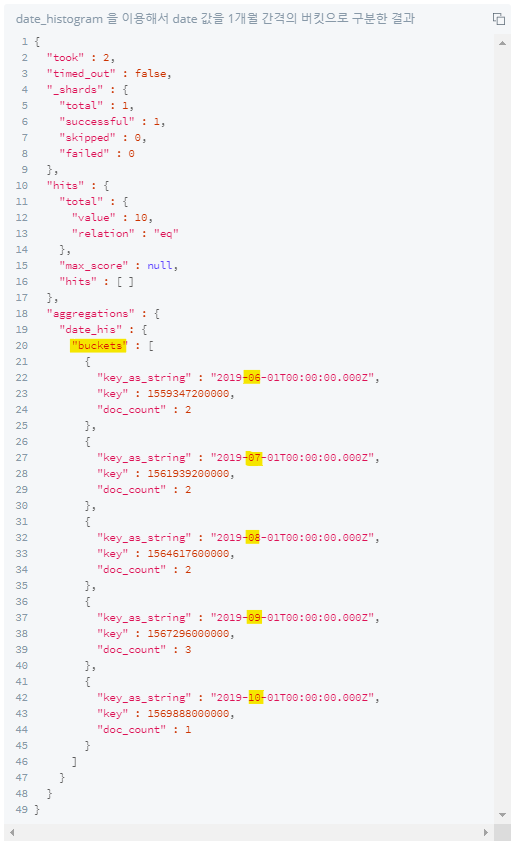
+) 나는 구버전 옵션으로 실습했지만..☆ 이렇다고 합니다..!
interval❌
calendar_interval⭕ (year, quarter, month, week, day, ...)
fixed_interval⭕ (1y, 30d, ...)

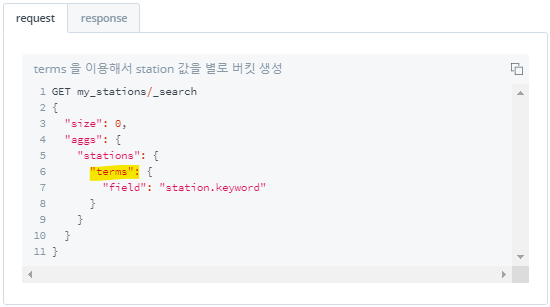
3) 키워드별 버킷 나누기 : terms
- 해당 field의 cardinality 기준 버킷 나누기
- text 타입 field에서 사용할 경우, 뒤에
.keyword붙여 keyword 타입으로 변환해주어야 함


사부작 사부작