
1. Elastic Search란?

- Apache Lucene(아파치 루씬) 기반의
Java 오픈 소스 분산 검색 엔진 - 방대한 양의
비정형 데이터를 신속하게,거의 실시간(NRT, Near Real Time)으로 저장, 검색, 분석 가능 RESTful API기반 CRUD 처리- 요청/응답 데이터 포멧으로
JSON사용
(JSON 기반의 스키마 없는(스키마리스) 저장소 - 역색인 기반 데이터 탐색(검색) ⇒ 일반 DB보다 월등히 빠름
- scale out하여 분산 환경에서 사용 가능, shard 단위로 분산
- Elastic Search 단독으로 쓰이기도 하지만,
대부분 ELK(Elasticsearch/Logstatsh/Kibana) Stack으로 함께 쓰임
ㄴ RESTful API + JSON ⇒ search engine
ㄴ 대량의 데이터를 신속하게 저장, 검색, 분석
ㄴ 역색인 기반 검색(매우 빠름💨)
ㄴ 분산 구성 가능, shard 단위로 분산
2. ELK Stack이란?
1) ELK Stack 구성
⚡ E = Elasticsearch
- Apache Lucene에 구축되어 오픈 소스로 배포된 검색 및 분석 엔진
JSON기반의 분산형 검색 및 분석 엔진- Logstash로부터 받은 데이터를 검색 및 집계를 하여 필요한 관심 있는 정보를 획득
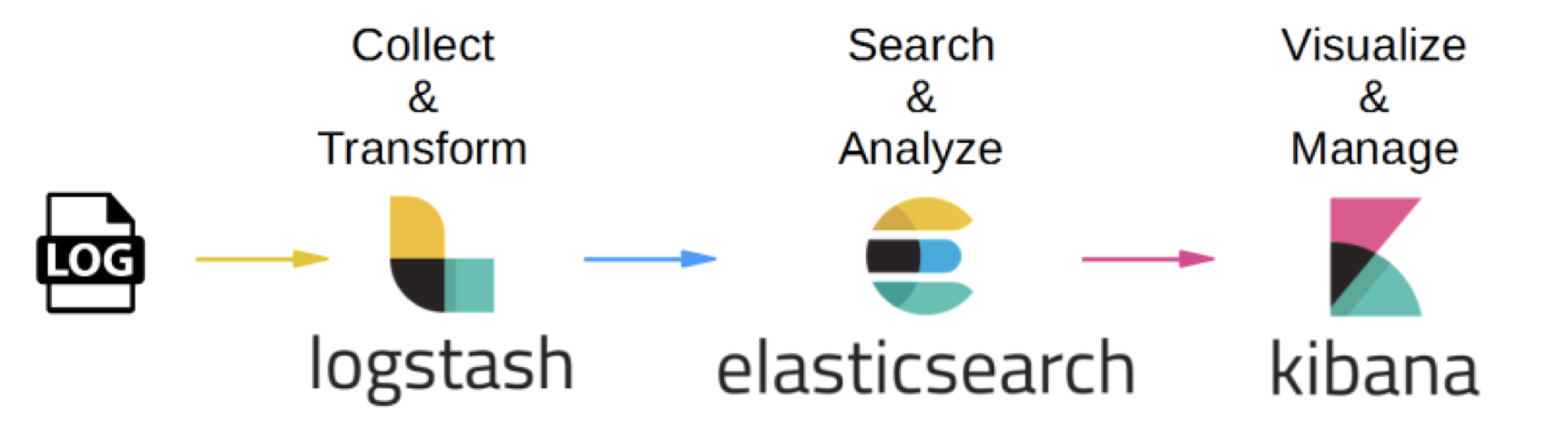
⚡ L = Logstash
- 다양한 소스로부터 데이터를 수집하고 전환하여 원하는 대상에 전송할 수 있도록 하는 오픈 소스 데이터 수집/변환 도구
- 사전 구축된 필터와 200개가 넘는 플러그인에 대한 지원으로 데이터 원본이나 유형에 관계 없이 데이터 수집 가능
- 다양한 소스(DB, csv 등)의 로그 또는 트랜잭션 데이터를 수집, 집계, 파싱하여 Elasticsearch로 전달
⚡ K = Kibana
- 로그 및 이벤트 검토에 사용하는 데이터 시각화 및 탐색 도구
- Elasticsearch의 빠른 검색을 통해 데이터를 시각화 및 모니터링
- 확장형 사용자 인터페이스로 데이터를 구체적으로 시각화
(≒ oracle db의 sqlplus와 흡사한 기능)
2) ELK Stack의 Flow

3. ES 기본 개념
< ES 특이점 >
NRT("Near" Real Time), 찐 realtime ❌
: 내부적으로commit과flush같은 복잡한 과정을 거치기 때문에 완전 실시간은 아님
색인된 데이터는 1초 가량 뒤에 검색 가능
Transaction Rollback 지원 ❌
: 전체적인 클러스터의 성능 향상을 위해
시스템적으로 비용 소모가 큰 롤백과 트랜잭션을 지원하지 않음
Data UPDATE ❌
: 업데이트 명령 ⇒ 기존 문서 삭제, 업데이트 내용으로 새로운 문서 생성
단순 업데이트에 비해 많은 비용이 들지만, 위 방식을 통해데이터 불변성을 이점으로 취함
< Elastic search 용어 정리 >
| 용어 | 의미 |
|---|---|
| 인덱스(index, indices) | 색인 과정을 거친 결과 데이터가 저장되는 저장소(≒DB) Document들의 논리적 집합 단위 |
| 색인(indexing) | 원본 문서를 검색이 가능한 구조인 토큰들로 변환하여 저장하는 일련의 과정 이 과정에서 역색인 데이터 입력 |
| 검색(search) | 인덱스에 저장되어 있는 데이터 중 검색어 토큰을 포함하고 있는 문서를 찾아가는 과정 역색인을 통해 찾아냄 |
| 질의 | 사용자가 원하는 document를 검색하거나 집계 결과를 도출하기 위해 입력하는 검색어 또는 조건(쿼리query) |
3. ES 핵심 개념
1) 색인과 역색인
색인 : 책의 목차 개념
역색인 : 책 맨 뒷 부분의 키워드 검색
역색인 기능은 일반 DB에는 없고, ES에만 있는 기능
이 기능으로 인해서 ES가 일반 DB에 비해 월등히 빠름
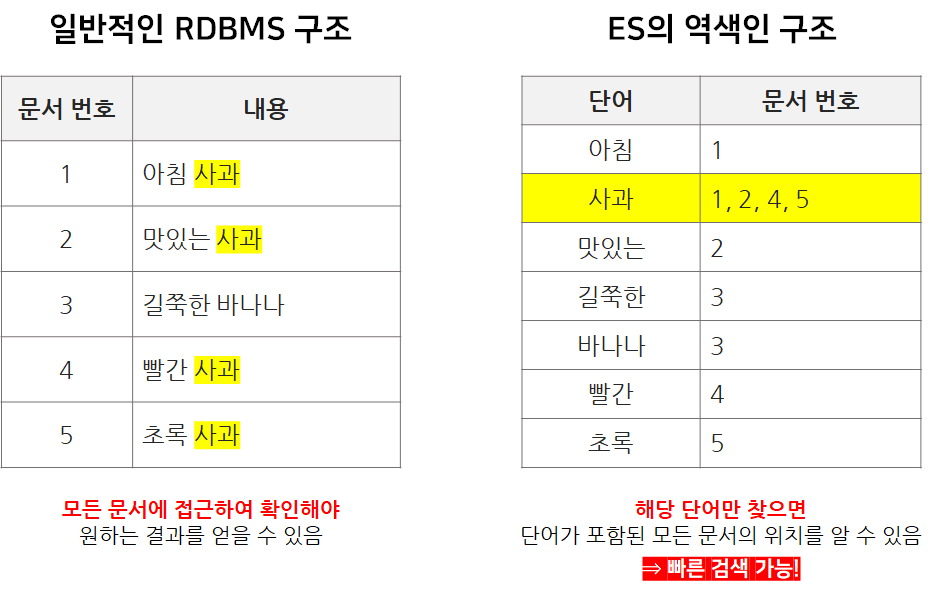
- 모든 문서(document)가 가지고 있는 고유 단어 목록
- 특정 단어가 어떤 문서에 속해 있는지에 대한 정보
- 전체 문서에 특정 단어가 몇 개 들어 있는지에 대한 정보
- 하나의 문서에 특정 단어가 몇 번씩 출현했는지에 대한 정보
👩🏫 데이터가 늘어날/새로 입력될 경우
- 일반 DB 구조에서처럼 검색해야 할 행이 늘어나는 것 X
- 역색인 내 문서 번호 배열값 추가
(새로 입력된 데이터 내 단어를 토큰화하여 어떤 단어를 포함하는지 해당 단어 포함 문서 번호에 값 추가)
⇒ 큰 속도 저하 없이 빠른 속도로 검색 가능- 역색인을 데이터 저장 과정에서 만들기 때문에, ES에서는 데이터 입력/저장을
색인한다고 표현
역색인 단계
1단계: 문서 토큰화(단어, term으로 분리)2단계: 토큰화된 단어에 대해 해당 단어 포함 문서 번호, 문서 상 위치, 출현 빈도 등 정보 확인
2) ES vs RDBMS
- 구조적 차이점
| 관점 | RDBMS | ES |
|---|---|---|
| 데이터 저장 | 정형 데이터 구조화 | 비정형 데이터 색인 |
| 스키마 | 정적 스키마 | 스키마리스(schemaless, 동적) |
| 검색 | sql문을 통해 검색텍스트 매칭을 통한 단순 검색만 가능 | RESTful API + JSON으로 검색역색인 구조를 바탕으로 빠른 검색 속도 보장 형태소 분석을 통해 자연어 처리 가능 전문(full-text) 검색과 구조 검색 모두 지원 |
잠깐🖐, 전문 검색이란?
• 여러 문서에서 특정의 문자열을 검색하는 것
• 여러 문서에 걸쳐 문서에 포함되는 전문을 대상으로한 검색
출처 : 사악미소의 현대마법사의 비술서, [MongoDB] 전문검색( Fulltext Search )
- 용어 비교
| RDBMS | ES |
|---|---|
| Database | Index |
| Table | Type |
| Row | Document (_doc) |
| Column | Field ("field": "value") |
| Schema (구조와 제약조건) | Mapping (JSON 포멧에 적합한 구조) |
| Index (빠른 검색이 가능한 옵션) | 모든 데이터가 인덱싱 되어있음 데이터 저장=인덱싱 |
| SQL | Query DSL |
3) Sharding & Shard
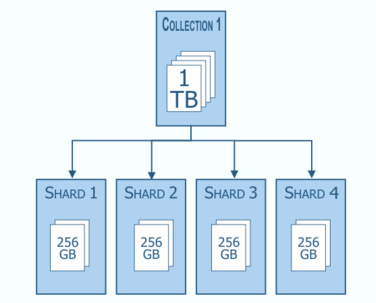
- 단일 데이터를 다수의 데이터베이스에 쪼개어 나누는 것
- Scale Out(수평 확장)을 위해 index를 여러 샤드로 쪼개어 저장
- 파티셔닝(Partitioning)이라고도 함
- 대용량 데이터를 안정적으로 보관할 때 샤딩하여 분산 저장
- 데이터가 급격히 증가하거나 트래픽이 특정 DB로 몰리는 상황 대비, 빠르고 유연한 DB 증설 및 분산 시스템 필요
- 분산된 DB에서 필요한 데이터만 빠르게 조회할 수 있기 때문에 쿼리 자체가 가벼움
샤딩(Sharding) = 데이터를 다수의 DB에 분산 저장하는 것
샤드(Shard) = 샤딩을 통해 나누어진 블록 구간
4) Replica
- index를 쪼개어 나눈 샤드에 대한 한 개 이상의 복사본
- 노드를 손실했을 경우를 대비하여, 데이터 신뢰성을 위해 샤드 복제
- replica는 원본과 다른 노드에 존재할 것 권장
Primary Shard - 처음 생성된 shard(원본)
Replica Shard - primary shard를 복제하여 다른 노드에 저장하는 샤드
- primary shard가 유실될 경우, replica shard가 primary shard로 승격되고, 복제본(replica shard)가 새로 생성됨
- replica shard는 운영 중 그 수를 변경할 수 있으나 primary shard는 수를 조정할 수 없음
출처
- 플레이데이터, 인공지능을 활용한 웹 서비스 개발자 양성 과정 12기, 김혜경 강사님 강의
- AWS, ELK 스택
- jaemunbro.medium, [Elastic Search] 기본 개념과 특징(장단점)
- victorydntmd.tistory, [Elasticsearch] 기본 개념 잡기
- 해시넷, 샤딩

사부작 사부작