
💬 8일차 후기: 진도가 후루룩 나가서 조인문과 서브쿼리까지 배웠다. 한 번 배우고 나서 다시 배우는 것인데도 Outer 조인, 복잡한 서브쿼리 작성은 계속 헷갈린다😵 이론으로 외우는 것보다도 문제를 여러 개 풀어보면서 정리하는 게 좋을 것 같다! 오늘도 간단하게 실습 내용 정리 후 배울 점이 있었던 문제 풀이 소개 시작🙏
⛔ 오늘 문제 스압 주의 ⛔
[ 실습 내용 ]
3. 그룹 함수 사용
그룹 함수
: 행 집합 연산을 수행하여 그룹별로 하나의 결과를 산출하는 함수
COUNT: 속성 값의 개수
-COUNT(*): NULL 값도 포함해서 모든 튜플 개수 반환, 전체 튜플 수 파악에 용이
-COUNT(특정 속성): 특정 속성 안에 NULL 값 있으면 제외하고 개수 반환
-COUNT(DISTICT 특정 속성): 특정 속성 안 중복 제외 후 개수 반환
MAX: 속성 값의 최댓값MIN: 속성 값의 최솟값
SUM: 속성 값의 합계 / 숫자 데이터에만 사용 가능AVG: 속성 값의 평균 / 숫자 데이터에만 사용 가능 NULL 값 포함 ❌
NULL 값 포함 / 미포함
✅ AVG 함수는 NULL 값 포함하지 않고 평균 연산
✅ NULL 값을 포함해서 연산하고 싶다면,
SUM(특정 속성) / COUNT(*) 혹은 AVG(NVL(특정 속성, 0))
GROUP BY절

GROUP BY 키워드로 그룹을 나누는 기준이 되는 속성 지정, 그룹 함수랑 함께 쓰임
그룹에 대한 조건은 WHEREHAVING절에 표현
❌ GROUP BY절 주의사항 ❌
-
가독성을 위해 기준이 되는 속성(GROUP BY 대상)을 SELECT문에도 작성하는 것 권장 (SELECT문에 없어도 에러 아님)
-
그룹에 대한 조건은 HAVING절에 작성
-
그룹에 대한 조건은 WHERE절에 작성할 수 없지만, 그룹 외 추가 조건은 WHERE절에 우선 작성하여 연산 복잡도를 낮출 수 있음
-
그룹 함수(집계 함수) 외에 (SELECT절에 있는)분류 기준이 되는 속성은 모두 GROUP BY절에도 있어야 함
-
중복 값이 없는 GROUP BY는 의미 없음 (묶인 것이 없는 경우를 말함)
-
두 개 이상 값을 기준으로 그룹핑 할 수 있음, 우선순위대로 나열
HAVING절
특정 속성을 기준으로 묶어놓은 GROUP BY절에서 그룹에 대한 조건을 명시하는 절
= GROUP BY 전용 조건절
WHERE절을 대체하는 것이 아님, 용도가 다름
WHERE절은 그룹이 아닌 기존 속성에 대한 조건을 명시
HAVING절은 그룹에 대한 조건을 명시
SELECT deparment_id, SUM(salary)
FROM employees
WHERE hiredate < TO_DATE('2000/01/01','YYYY/MM/DD') -- 기존 속성에 대한 조건
GROUP BY department_id
HAVING SUM(salary) > 50000 -- 그룹별로 나누어 연산한 SUM값에 대한 조건
OVER() 함수
: GROUP BY나 서브쿼리를 사용하지 않고 그룹 함수(SUM,AVG,... & GROUP BY) 사용과 정렬(ORDER BY)을 가능하게 하는 함수
ORDER BY, GROUP BY 서브쿼리를 개선하기 위해 나온 함수
그룹 함수() OVER(PARTITION BY 컬럼 / ORDER BY 컬럼 / 세부 분할 기준)
-
PARTITION BY 컬럼: 어느 컬럼을 기준으로 나눌지 명시, GROUP BY와 동일한 기능 -
ORDER BY 컬럼: 정렬 시 기준을 설정, ORDER BY와 동일한 기능 -
세부 분할 기준(windowing_clause): PARTITION BY, ORDER BY로 충분히 분할하지 못했을 경우 사용, ORDER BY를 사용한 상태에서만 적용 가능
[참고] over() 함수 사용 예시 - 행복한 수지아빠님 블로그
4. 조인문 작성
SQL 조인의 종류
1) *(INNER) JOIN : 두 개의 테이블에서 컬럼값 비교 후 JOIN 조건에 맞는 행만 반환(기본 조인)
2) *OUTER JOIN(LEFT/RIGHT) : 두 개의 테이블에서 JOIN 조건에 LEFT, RIGHT 각각 매치되는 값이 없더라도 NULL값을 넣어 선택된 쪽의 결과를 반환
3) FULL OUTER JOIN : 매치되지 않은 LEFT, RIGHT 값 모두 반환
4) CROSS JOIN : 한 테이블의 모든 행을 다른 테이블의 모든 행과 조인(그닥 유용하지 않음) => Cartesian Product
5) **SELF JOIN : 테이블 하나를 두 개처럼 인식하고 자기 자신과 조인- Equi JOIN : =를 사용한 조건으로 JOIN
- Non-equi JOIN : =외에 다른 연산자(>,<,BETWEEN...)를 사용한 조건으로 JOIN
❌ 조인문 작성 주의사항 ❌
- 조인하는 두 테이블에 이름이 같은 컬럼이 있을 경우 컬럼 앞에 테이블명을 명시해주어야 함(별칭으로 명시해도 됨)
- SELF JOIN에서는 꼭 테이블 각각 별칭을 붙여주어야 함
- 조인 조건 외 일반 조건을 추가할 수 있음
Oracle JOIN과 ANSI JOIN
Oracle JOIN
- JOIN하는 테이블 FROM절에 한 번에 명시
- 추가 조건은 AND로 WHERE절에서 연결
- ⚡ OUTER JOIN은 LEFT, RIGHT만 가능
- ⚡ OUTER JOIN시
(+)가 붙지 않은 쪽 OUTER JOIN임 - CROSS JOIN은
SELECT *
-- 기본 형식
SELECT ___, ___, ___
FROM ___ a, ___ b
WHERE a._____ = b._____;
-- 조건 추가(AND만 가능)
SELECT ___, ___, ___
FROM ___ a, ___ b
WHERE a._____ = b._____
AND ________;
-- 여러 테이블 JOIN
SELECT ___, ___, ___
FROM ___ a, ___ b, ___ c
WHERE a._____ = b._____ AND b._____ = c._____;
-- OUTER JOIN(LEFT, RIGHT)
SELECT ___, ___, ___
FROM ___ a, ___ b
WHERE a._____ = b._____ (+); -- LEFT OUTER JOIN
SELECT ___, ___, ___
FROM ___ a, ___ b
WHERE a._____ (+) = b._____; -- RIGHT OUTER JOIN
-- CROSS JOIN(카티션 프로덕트)
SELECT *
FROM ___ a, ___ b;ANSI JOIN
- JOIN하는 테이블
테이블 1 JOIN 테이블2 ON으로 명시 - 추가 조건은 AND 혹은 WHERE로 연결
- 여러 테이블 조인 시에도
JOIN-ON형식 유지 - ⚡ OUTER JOIN은 LEFT, RIGHT, FULL 다 가능
- ⚡ OUTER JOIN시 키워드로 LEFT, RIGHT, FULL 명시
- CROSS JOIN도 키워드로 명시
-- 기본 형식
SELECT ___, ___, ___
FROM ___ a
JOIN ___ b ON a._____ = b._____;
-- 조건 추가(AND, WHERE 가능)
SELECT ___, ___, ___
FROM ___ a
JOIN ___ b ON a._____ = b._____
AND ________; 혹은 WHERE ________;
-- 여러 테이블 JOIN(JOIN-ON 형식 유지)
SELECT ___, ___, ___
FROM ___ a
JOIN ___ b ON a._____ = b._____
JOIN ___ c ON a._____ = c._____
-- OUTER JOIN(LEFT, RIGHT, FULL)
SELECT ___, ___, ___
FROM ___ a
LEFT JOIN ___ b ON a._____ = b._____; -- LEFT OUTER JOIN
SELECT ___, ___, ___
FROM ___ a
RIGHT JOIN ___ b ON a._____ = b._____; -- RIGHT OUTER JOIN
SELECT ___, ___, ___
FROM ___ a
FULL JOIN ___ b ON a._____ = b._____; -- FULL OUTER JOIN
-- CROSS JOIN(카티션 프로덕트)
SELECT *
FROM ___ a
CROSS JOIN ___ b;ANSI JOIN에서 ON과 USING
ON: 조인 조건을 명시USING: 두 테이블 내 조인 기준 컬럼 이름이 같을 때,해당 컬럼을 기준으로 조인함을 명시 (USING 쓸 때는 alias 사용 ❌)
SELECT employee_id, salary, department_id
FROM employees e
JOIN departments d USING(department_id); [ 복습 문제 풀이 ]
문제 4-9) 부서번호, 부서번호별 토탈월급을 가로로 출력하시오 (부서번호를 모두 안다고 가정)
10 20 30
------ ------ ------
8750 10875 9400SELECT
SUM(DECODE(deptno, 10, sal)) AS "10",
SUM(DECODE(deptno, 20, sal)) AS "20",
SUM(DECODE(deptno, 30, sal)) AS "30"
FROM emp;- 가로로 출력해야할 경우, 각 컬럼별로 조건문을 사용하여 값 출력
문제 4-17) 직무, 부서번호, 직무별 부서번호별 토탈월급을 출력하시오
SELECT job,
SUM(DECODE(deptno, 10, sal)) AS "10",
SUM(DECODE(deptno, 20, sal)) AS "20",
SUM(DECODE(deptno, 30, sal)) AS "30"
FROM emp
GROUP BY job;- 그룹 함수 사용 시, SELECT절에 그룹 함수 외 다른 컬럼이 온다면 해당 컬럼을 GROUP BY절에 명시하여 그룹을 나누는 기준으로 지정
문제 4-19) 입사한 년도(4자리), 입사한 년도별 토탈월급을 가로로 출력하시오
1980 1981 1982 1983
------ ------ ------ ------
800 22825 4300 1100SELECT
SUM(DECODE(TO_CHAR(hiredate,'YYYY'), 1980, sal)) AS "1980",
SUM(DECODE(TO_CHAR(hiredate,'YYYY'), 1981, sal)) AS "1981",
SUM(DECODE(TO_CHAR(hiredate,'YYYY'), 1982, sal)) AS "1982",
SUM(DECODE(TO_CHAR(hiredate,'YYYY'), 1983, sal)) AS "1983"
FROM emp;Q8. EMP 테이블에서 DEPTNO, JOB 컬럼으로 Grouping 된 급여의 합계를 다음과 같이 검색하시오
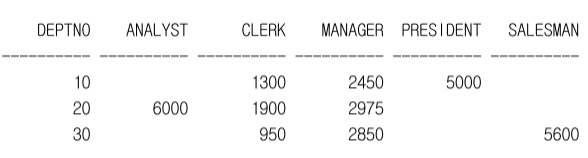
-- 배운 내용으로 푸는 방법
SELECT deptno,
SUM(DECODE(job, 'ANALYST', sal))
,SUM(DECODE(job, 'CLERK', sal))
,SUM(DECODE(job, 'PRESIDENT', sal))
,SUM(DECODE(job, 'SALESMAN', sal))
FROM emp
GROUP BY deptno;
-- PIVOT을 활용해 간결하게 푸는 방법
SELECT *
FROM (SELECT deptno, job, sal FROM emp)
PIVOT(SUM(sal) FOR job IN ('ANALYST' AS analyst,
'CLERK' AS cleark,
'PRESIDENT' AS president,
'SALESMAN' AS salesman))
ORDER BY deptno;
-- ROLLUP을 활용해 총계를 구하는 방법
SELECT deptno,
SUM(DECODE(job, 'ANALYST', sal))
,SUM(DECODE(job, 'CLERK', sal))
,SUM(DECODE(job, 'PRESIDENT', sal))
,SUM(DECODE(job, 'SALESMAN', sal))
FROM emp
GROUP BY ROLLUP(deptno);🔍 PIVOT 함수
: 그룹함수와 함께 사용되어 행으로 표현되던 값을 열로 변환
PIVOT(그룹합수(집계컬럼) FOR 피벗대상컬럼 IN ([피벗컬럼값] ... ) AS pivot_result
🔍 ROLLUP과 CUBE
-ROLLUP(): GROUP BY절과 함께 사용되어 소계, 총계를 구해줌
-CUBE(): GROUP BY 항목들 간 모든 경우의 수로 그룹을 생성하게 집계, ROLLUP()보다 더 세세하게 나올 수 있는 모든 소계와 총계를 구해서 반환
Q9. EMP 테이블에서, 'JONES' (ENAME)보다 더 많은 급여(SAL)를 받는 사원을 검색하시오 (단, JONES의 급여도 함께 검색합니다.) ⭐서브쿼리 활용
SELECT e.empno, e.ename, e.sal, s.sal AS "Jones's salary"
FROM emp e, (SELECT sal
FROM emp
WHERE ename = 'JONES') s
WHERE e.sal > s.sal;- SELECT절과 WHERE절에서 JONES의 salary값을 활용해야하므로 FROM절에 서브쿼리를 만들어 인라인뷰 생성
Q10. DEPT, EMP 테이블을 사용하여 부서별 급여의 합계를 다음과 같이 검색하시오. 근무하는 사원이 없는 부서도 함께 표시합니다.
-- 조인 풀이
SELECT d.deptno, d.dname, SUM(e.sal)
FROM dept d, emp e
WHERE d.deptno = e.deptno(+)
GROUP BY d.deptno, d.dname;- 근무하는 사원이 없는 부서도 표시해야하기 때문에 LEFT OUTER JOIN 실행
- SELECT절에 그룹 함수를 사용했기 때문에 GROUP BY절에 그 외 기준 컬럼 명시
Q11. DEPT, EMP 테이블을 사용하여 각 부서의 소속 사원 유무를 확인하는 검색 결과를 만드시오. EMP 컬럼은 소속 사원이 존재할 때 'YES', 아니면 'NO'를 검색합니다.
SELECT d.deptno, d.dname, d.loc,
CASE WHEN COUNT(e.empno) > 0 THEN 'YES'
ELSE 'NO' END AS EMP
FROM dept d, emp e
WHERE d.deptno = e.deptno(+)
GROUP BY d.deptno, d.dname, d.loc;- 부서별로 GROUP BY해서 해당 부서별 사원을 COUNT(e.empno)로 카운트
- 사원이 없는 부서도 출력해야하기 때문에 LEFT OUTER JOIN 실행
- COUNT(e.empno)의 값이 숫자이기 때문에, 0보다 크면 'YES' 그렇지 않으면 'NO'를 출력하는 조건문 생성
- SELECT문에 있는 컬럼 중 그룹 함수를 사용하지 않은 컬럼 모두 GROUP BY에 명시
Q12. COUNTRIES, EMPLOYEES 테이블을 이용하여, 'Canada'에서 근무 중인 사원 정보를 다음과 같이 검색하시오. 만약 추가적으로 필요한 테이블이 더 있다면 함께 사용합니다.
SELECT e.first_name, e.last_name, e.salary, e.job_id, c.country_name
FROM employees e, departments d, locations l, countries c
WHERE c.country_id = l.country_id AND c.country_name = 'Canada'
AND l.location_id = d.location_id
AND d.department_id = e.department_id;- 여러 테이블을 조인할 때는 먼저 출력해야할 값과, 필요한 테이블을 각각 SELECT절과 FROM절에 명시
- 이후 각 테이블 사이를 연결하는 FK를 찾아 WHERE절에 조인 조건 명시
Q13. EMP 테이블에서 1981년도에 입사한 사원들을 입사 월별로 인원수를 검색하시오. 단, 사원이 없는 월도 함께 출력 ⭐⭐⭐
SELECT a.hire, NVL(b.cnt, 0) AS cnt
FROM (SELECT '1981/' || lpad(level,2,0) AS hire
FROM dual CONNECT BY level <= 12) a,
(SELECT TO_CHAR(hiredate, 'YYYY/MM') AS hire, COUNT(*) AS cnt
FROM emp
WHERE TO_CHAR(hiredate, 'YYYY') = '1981'
GROUP BY TO_CHAR(hiredate, 'YYYY/MM')) b
WHERE a.hire = b.hire(+)
ORDER BY a.hire;🔍 CONNECT BY LEVEL
: 연속된 숫자를 조회할 때 사용
SELECT level FROM dual CONNECT BY level <= n;의 형태로 사용
연속된 날짜 형식을 출력한다거나, 특정 구간의 날짜를 출력할 때 활용 가능
- 결과값을 출력하는데 필요한 테이블을 서브쿼리로 두 개 생성
- 연속된 날짜값이 필요한 부분에는
CONNECT BY LEVEL을 활용 - 월 부분을 두 자릿수 형식에 맞춰주기 위해
lpad(기존 값, 총 자릿수, 빈 부분을 채워줄 값)함수 사용 - 다른 테이블은 입사일자별 사원 수를 COUNT하도록 서브쿼리 생성
- 입사자가 없는 날짜 정보도 출력해야하기 때문에 LEFT OUTER JOIN 실행
- 입사자 NULL값은
NVL()함수로 0으로 변환
문제 5-7) 부서위치, 이름, 월급, 순위를 출력하는데 순위가 월급이 높은 순서대로 순위를 출 력하시오
SELECT d.loc, e.ename, e.sal, RANK() OVER (ORDER BY e.sal DESC)
FROM emp e, dept d
WHERE d.deptno = e.deptno;🔍 일련 번호, 순위를 구하는 함수
ROW_NUMBER() OVER(ORDER BY 정렬 필드): 같은 값은 무시, (1,2,3,4,5)RANK() OVER(ORDER BY 정렬 필드): 같은 값은 동등한 값으로 값을 반환, (1,2,2,4,5)DENSE_RANK() OVER(ORDER BY 정렬 필드): 같은 값을 동등한 값으로 반환, 다음 순위는 순차적으로 적용, (1,2,2,2,3,4)
문제 5-9) 부서위치, 해당 부서위치에 근무하는 사원들의 이름을 가로로 출력하시오
SELECT d.dname,
LISTAGG(e.ename,',') WITHIN GROUP (ORDER BY ename ASC)
FROM emp e, dept d
WHERE e.deptno=d.deptno
GROUP BY d.dname;🔍 LISTAGG() 함수
: 여러 행을 하나의 컬럼으로 보고 싶을 때 사용하는 함수
LISTAGG([합칠 컬럼명], [구분자]) WITHIN GROUP(ORDER BY [정렬 컬럼명])
LISTAGG( ) 함수는 그룹 함수이기 때문에 GROUP BY 또는 PARTITION BY 절과 함께 사용해야함
문제 5-27) 이름과 부서위치를 출력하는데 naturual 조인으로 수행하시오
SELECT ename, loc
FROM emp NATURAL JOIN dept;🔍 NATURAL JOIN(자연 조인)
: 자연 조인은 등가 조인하는 방법 중 하나로 동일한 타입과 이름을 가진 컬럼을 조인 조건으로 이용함
- 자연조인을 하기 위해서는 반드시 두 테이블 간 동일한 타입, 동일한 이름을 가진 조인 조건 컬럼이 있어야 함
- 조인 조건을 명시해주지 않아도 알아서 조인
- SELECT절에 두 테이블 간 이름이 겹치는 컬럼이 있더라도 별칭(alias) 사용 ❌
