도메인 주도 설계 (4) - Repository와 Model 구현
Repository와 Model 구현
JPA를 이용한 Repository 구현
- aggregate를 어떤 저장소에 저장하느냐에 따라 리포지터리(repository)를 구현하는 방법이 다르다.
- 도메인 모델과 리포지터리를 구현할 때 선호하는 기술을 꼽자면 자바의 ORM 표준인 JPA를 꼽을 수 있다.
- 데이터 보관소로 RDBMS를 사용할 때 객체 기반의 도메인 모델과 관계헝 데이터 모델 간의 매핑을 처리하는 기술로 ORM (Object Relational Mapping) 이 사용된다.
모듈의 위치
- repository interface는 domain 영역에 속하고
- repository 구현 클래스는 infrastructure 영역에 속한다.
- 인프라 영역에 위치시켜 인프라에 대한 의존을 낮춰야 한다.
repository 기본 기능 구현
-
기본 기능은 조회와 저장(업데이트)
- select (findById)
- save
-
인터페이스는 다음과 같은 형식을 갖는다.
public interface OrderRepository { public Order findById(OrderNo no); // id로 Order 엔티티 조회 public void save(Order order); }- 인터페이스는 aggregate 루트를 기준으로 작성한다.
- 예시에서는 Order 루트 엔티티를 기준으로 인터페이스가 작성되었다.
- 에그리거트를 조회하는 기능의 이름을 지을 때 특별한 규칙은 없지만 널리 사용되는 규칙은 findBy + property (property 값)의 형식을 사용하는 것.
findById()는 아이디에 해당하는 애그리거트가 존재하면 Order를 리턴하고, 존재하지 않으면 null을 리턴한다.- Java 1.8+ 의 Optional 객체를 이용해서 값을 return 하면 null을 그대로 참조하지 않아도 된다.
- save() 메서드는 전달받은 애그리거트를 저장한다.
-
인터페이스를 구현한 클래스는 JPA의
EntityManager를 이용해서 기능을 구현한다.package com.myshop.order.infra.repository; import com.myshop.order.command.domain.Order; import com.myshop.order.command.domain.OrderNo; import com.myshop.order.command.domain.OrderRepository; import org.springframework.stereotype.Repository; import javax.persistence.EntityManager; import javax.persistence.PersistenceContext; @Repository public class JpaOrderRepository implements OrderRepository { @PersistenceContext private EntityManager entityManager; // entityManager의 find 메서드를 이용해 aggregate를 검색한다. @Override public Order findById(OrderNo id) { return entityManager.find(Order.class, id); } // entityManager의 persist 메서드를 이용해 aggregate를 저장한다. @Override public void save(Order order) { entityManager.persist(order); } } -
aggregate를 수정한 결과를 저장소에 반영하는 메서드를 추가할 필요는 없다. (JPA 에서 transaction 범위에서 변경한 데이터를 자동으로 DB에 반영하므로)
public class ChangeOrderService { @Transactional public void changeShippingInfo(OrderNo no, ShippingInfo newShippingInfo) { Order order = orderRepository.findById(no); if (order == null) throw new OrderNotFoundException(); order.changeShippingInfo(newShippingInfo); } ... }- 해당 메서드는
@Transactional이 선언되어 Spring의 transaction 관리 기능을 통해 transaction 범위에서 실행된다. - 메서드 실행 완료 후 commit이 이뤄지는데, JPA는 transaction 범위에서 변경된 객체의 데이터를 DB에 반영하기 위해 UPDATE 쿼리를 실행한다.
- 해당 메서드는
-
ID가 아닌 다른 조건으로 aggregate를 조회해야 하는 경우 findBy 뒤에 조건 대상이 되는 property name을 붙인다.
- findByOrdererId
- findBySlipId 등
-
하나 이상의 엔티티 객체를 리턴할 수 있는 경우에는 컬렉션 타입을 사용하여 return값을 정의한다. (List 등)
-
ID 이외에 다른 조건으로 aggregate를 조회하는 경우에는 JPA의 Criteria나 JPQL을 사용한다.
-
JPQL 사용의 예
@Override public List<Order> findByOrdererId(String ordererId, int startRow, int fetchSize) { TypedQuery<Order> query = entityManager.createQuery( "select o from Order o " + "where o.orderer.memberId.id = :ordererId " + JpaQueryUtils.toJPQLOrderBy("o", "number.number desc"), Order.class); query.setParameter("ordererId", ordererId); query.setFirstResult(startRow); query.setMaxResults(fetchSize); return query.getResultList(); } ... public static String toJPQLOrderBy(String alias, String... orders) { if (orders == null || orders.length == 0) return ""; String orderParts = Arrays.stream(orders) .map(order -> alias + "." + order) .collect(joining(", ")); return "order by " + orderParts; }
-
-
aggregate 삭제 기능은 JPA entityManager의 remove() 메서드를 이용해 구현할 수 있다.
@Override public void remove(Order order) { entityManager.remove(order); }- 삭제는 Row Record를 완전 제거하는 방식과 status flag 값을 두어 논리적으로 제거하는 방식(사용안함 flag 설정) 이 있다.
Mapping 구현
Entity와 Value 기본 Mapping 구현
-
Aggregate와 JPA Mapping을 위한 기본 규칙
- aggregate 루트는 엔티티이므로 @Entity 로 매핑 설정한다.
- 한 테이블에 엔티티와 밸류 데이터가 같이 있다면,
- 밸류는 @Embeddable로 매핑 실정한다.
- 밸류 타입 프로퍼티는 @Embedded 매핑 설정한다.
-
mapping 예시 : 주문 aggregate의 mapping
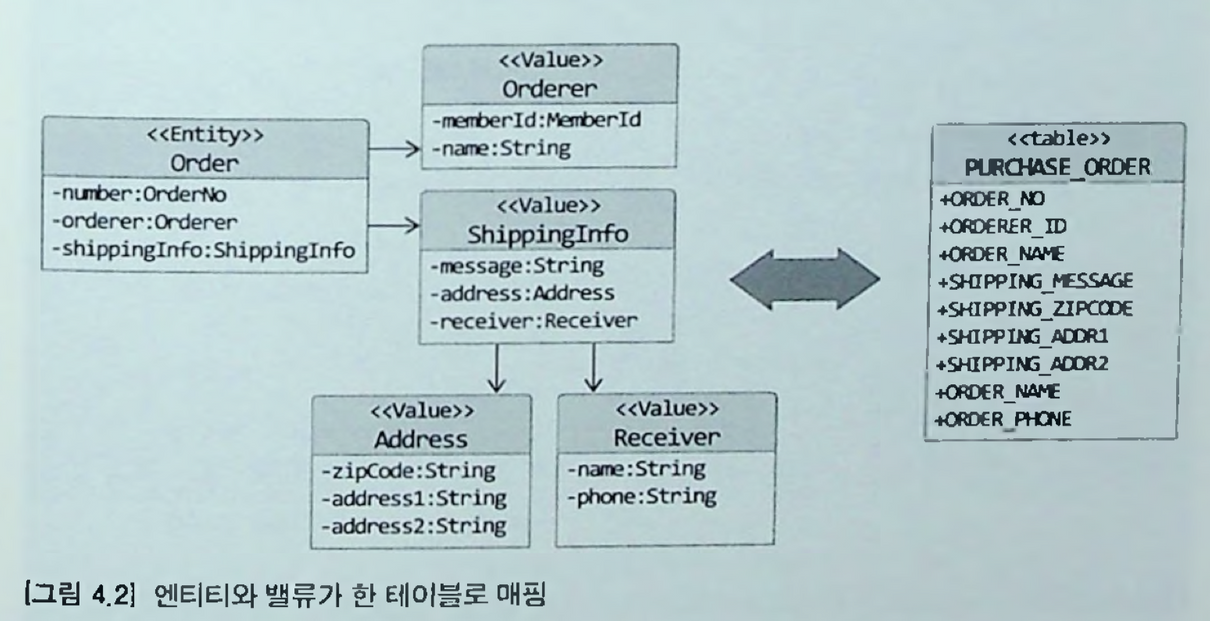
-
Entity : Order
import javax.persistence.Entity; @Entity @Table(name = "purchase_order") public class Order { @Embedded private Orderer orderer; @Embedded private ShippingInfo shippingInfo; ... }- root Entity인 Order는 @Embedded를 이용해서 value type Property를 설정한다.
-
Value :
-
Orderer
import javax.persistence.*; @Embeddable public class Orderer { // MemberId에 정의된 column 이름을 변경하기 위해 // @AttributeOverride Annotation 사용 @Embedded @AttributeOverrides( @AttributeOverride(name = "id", column = @Column(name = "orderer_id")) ) private MemberId memberId; @Column(name = "orderer_name") private String name; } @Embeddable public class MemberId implements Serializable { @Column(name = "member_id") private String id; ... }- Orderer의 memberId는 Member Aggregate를 ID로 참조한다.
- Orderer의 memberId 프로퍼티와 매핑되는 컬럼 이름은
orderer_id이므로 memberId 에 설정된member_id와 이름이 다르다. - @Embeddable 타입 에 설정한 컬럼 이름과 실제 컬럼 이름이 다르므로 Orderer의 memberId 프로퍼티 를 매핑할 때 @AttributeOverrides 애노테이션을 이용해서 매핑할 칼럼 이름을 변경했다.
- JPA 2부터 @Embeddable 은 중첩을 허용하므로 Value인 Orderer가 또 다른 Value인 MemberId를 포함할 수 있다.
-
ShippingInfo (Address, Receiver)
@Embeddable public class ShippingInfo { @Embedded @AttributeOverrides({ @AttributeOverride(name = "zipCode", column = @Column(name = "shipping_zip_code")), @AttributeOverride(name = "address1", column = @Column(name = "shipping_addr1")), @AttributeOverride(name = "address2", column = @Column(name = "shipping_addr2")) }) private Address address; @Column(name = "shipping_message") private String message; @Embedded private Receiver receiver; ... }- ShippingInfo Value도 또 다른 Value인 Address, Receiver 를 포함한다.
- Address 내 매핑 설정과 다른 컬럼 이름을 사용하기 위해 @AttributeOverride Annotation 을 시용한다.
-
-
root entity와 root에 속한 value 는 한 테이블에 매핑될 수 있다. (PURCHASE_ORDER)
-
기본 생성자
-
entity와 value의 생성자는 객체를 생성할 때 필요한 것을 전달받는다.
-
객체가 불변 타입이면 생성 시점에 필요한 값을 모두 전달받으므로 값을 변경하는 setter를 제공하지 않는다.
- 즉, param이 없는 기본 생성자를 추가할 필요가 없다.
- 그러나, JPA의 @Entity와 @Embeddable로 class를 매핑하려면 기본 생성자를 제공해야 한다.
-
기본 생성자는 JPA Provider가 객체를 생성할 때만 사용될 수 있도록
protected로 선언한다.@Embeddable @NoArgsConstructor(access = AccessLevel.PROTECTED) public class Receiver { } // 또는 @Embeddable public class Receiver { protected Receiver() {} }- 하이버네이트는 클래스를 상속한 프록시 객체를 이용해서 지연 로딩을 구현한다. 이 경우 프록시 클래스에서 상위 클래스의 기본 생성자를 호출할 수 있어야 하므로 지연 로딩 대상이 되는 @Entity와 @Embeddable 기본 생성자는
private이 아닌protected로 접근지시자를 지정해야 한다.
- 하이버네이트는 클래스를 상속한 프록시 객체를 이용해서 지연 로딩을 구현한다. 이 경우 프록시 클래스에서 상위 클래스의 기본 생성자를 호출할 수 있어야 하므로 지연 로딩 대상이 되는 @Entity와 @Embeddable 기본 생성자는
필드 접근 방식 사용
-
JPA는 필드와 메서드의 두 가지 방식으로 매핑을 처리할 수 있음.
-
메서드 방식
@Entity @Table(name = "purchase_order") @Access(AccessType.PROPERTY) public class Order { private OrderState state; @Column(name = "state") @Enumerated(EnumType.STRING) public OrderState getState() { return state; } public void setState(OrderState state) { this.state = state; } }- 엔티티에 프로피터를 위한 공개 getter/setter 를 추가하면 도메인의 의도가 사라지고 객체가 아닌 데이터 기반으로 엔티티를 구현할 가능성이 높아진다.
- 특히 setter 는 내부 데이터를 외부에서 변경할 수 있는 수단이 되기 때문에 캡슐화를 깨는 원인이 될 수 있다.
- 엔티티가 객체로서 제 역할을 수행하려면 setter 대신 의도가 잘 드러나는 method를 제공해야 한다.
- setState() → cancel() : 주문 취소의 의도를 잘 표현한다.
- 밸류 타입을 불변으로 구현하고 싶은 경우 setter 자체가 필요 없는데 JPA의 구현 방식 때문에 공개 setter 를 추가하는 것도 좋지 않다.
-
엔티티를 객체가 제공할 기능 중심으로 구현하도록 유도하려면 JPA 매핑 처리를 property 방식이 아닌 field 방식으로 선택해서 불필요한 getter, setter 를 구현하지 말아야 한다.
@Entity @Table(name = "purchase_order") @Access(AccessType.FIELD) public class Order { @Column(name = "state") @Enumerated(EnumType.STRING) private OrderState state; ... // setter가 아닌 도메인에 필요한 기능 구현 (cancel(), changeShippingInfo() 등) ... // 필요한 getter 제공 }- JPA 구현체인 하이버네이트는 @Access를 이용해서 명시적으로 접근 방식을 지정하지 않으면 @Id 나 @Embeddedld 가 어디에 위치했느냐에 따라 접근 방식을 결정한다.
- 필드에 위치하면 필드 접근 방식을 선택하고
- getter에 위치하면 메서드 접근 방식을 선택한다.
- JPA 구현체인 하이버네이트는 @Access를 이용해서 명시적으로 접근 방식을 지정하지 않으면 @Id 나 @Embeddedld 가 어디에 위치했느냐에 따라 접근 방식을 결정한다.
AttributeConverter 를 이용한 밸류 매핑 처리
-
int, long, String, LocalDate 같은 타입은 DB 테이블의 한 개 칼럼과 매핑된다.
-
이와 비슷하게 value type의 property를 한 개 컬럼에 매핑해야 할 때도 있다.
- 두 개 이상의 프로퍼티를 가진 벨류 타입을 한 개 칼럼에 매핑해야 할 경우 @Embeddable 로는 처리할 수 없다.
-
JPA 2.0 버전에서는 이를 처리하기 위해 다음과 같이 컬럼과 매핑하기 위한 프로퍼티를 따로 추가하고 getter, setter에서 실제 벨류 타입과 변환 처리를 해야 했다.
public class Product { @Column(name = "WIDTH") private String width; public Length getWidth() { return new Width(width); // DB 컬럼 값을 실제 프로퍼티 타입으로 변환 } void setWidth(Length width) { this.width = width.toString(); // 실제 프로퍼티 타입을 DB 컬럼 값으로 변환 } ... } -
JPA 2.1에서는 DB 컬럼과 밸류 사이의 변환 코드를 모델에 구현하지 않아도 된다.대신 AttributeConverter를 사용해서 변환을 처리할 수 있다. (AttributeConverter 는 JPA 2.1에 추가된 인터페이스)
package javax.persistence; // type parameter X는 Value Type이고, Y는 DB 타입이다. public interface AttributeConverter<X, Y> { public Y convertToDatabaseColumn(X attribute); // Value Type -> DB Column 으로 변환 public X convertToEntityAttribute(Y dbData); // DB Column -> Value Type 으로 변환 } -
AttributeConverter 의 구현 예 : MoneyConverter
import javax.persistence.AttributeConverter; import javax.persistence.Converter; @Converter(autoApply = true) // 모델에 출현하는 모든 Money 타입의 property에 대해 MoneyConverter를 자동으로 적용한다. public class MoneyConverter implements AttributeConverter<Money, Integer> { @Override public Integer convertToDatabaseColumn(Money money) { if (money == null) { return null; } else { return money.getValue(); } } @Override public Money convertToEntityAttribute(Integer value) { if (value == null) { return null; } else { return new Money(value); } } }-
AttributeConverter 인터페이스를 구현한 클래스는 @Converter 애노테이션을 적용한다.
-
@Converter 의 autoApply 속성이 false 인 경우 (default 가 false), 값을 변환할 때 사용할 컨버터를 직접 지정할 수 있다.
-
예를 들어, Order의 totalAmounts 프로퍼티는 Money 타입 인데 이 프로퍼티를 DB total_amounts 컬럼에 매핑할 때 MoneyConverter를 사용한다.
@Entity @Table(name = "purchase_order") @Access(AccessType.FIELD) public class Order { @Column(name = "total_amounts") private Money totalAmounts; // MoneyConverter 를 적용해서 값 변환 /* @Converter(autoApply = false) 인 경우 */ @Column(name = "total_amounts") @Convert(converter = MoneyCustomConverter.class) private Money totalAmounts; // MoneyCustomConverter 를 적용해서 값 변환 }
-
벨류 컬렉션을 별도 테이블 매핑 처리
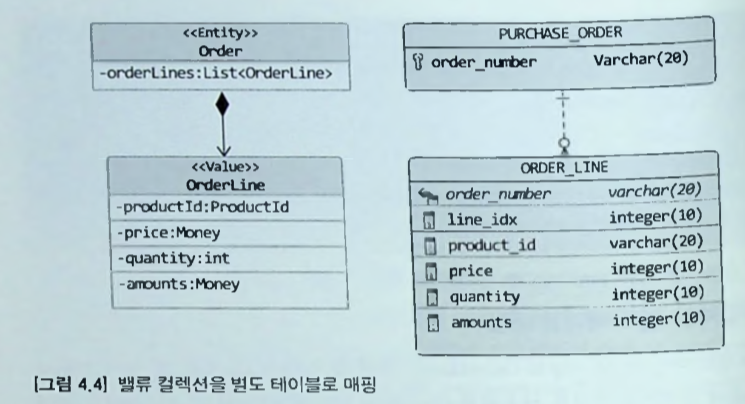
-
ORDER_LINE 테이블 (value collection 저장)은 외부키를 이용해서 엔티티에 해당 하는 PURCHASE_ORDER 테이블을 참조한다.
- 외부키는 컬렉선이 속할 entity를 의미한다.
- List 타입의 컬렉션은 인덱스 값이 필요하므로 ORDER_LINE 테이블에는 인덱스 값을 저장하기 위한 컬럼(line_idx)도 존재한다.
-
밸류 컬렉션을 별도 테이블로 매핑할 때는 @ElementCollection과 @CollectionTable을 함께 사용한다.
@Entity @Table(name = "purchase_order") @Access(AccessType.FIELD) public class Order { ... @ElementCollection @CollectionTable(name = "order_line", joinColumns = @JoinColumn(name = "order_number")) @OrderColumn(name = "line_idx") private List<OrderLine> orderLines; } @Embeddable public class OrderLine { @Embedded private ProductId productId; @Column(name = "price") private Money price; @Column(name = "quantity") private int quantity; @Column(name = "amounts") private Money amounts; ... }- OrderLine에는 List의 인덱스 값을 저장하기 위한 프로퍼티가 존재하지 않는다.
- 그 이유는 List 타입 자체가 인덱스를 갖고 있기 때문이다.
- JPA는 @OrderColumn 애노테이션을 이용해서 지정한 칼럼에 리스트의 인덱스 값을 저장한다.
- OrderLine에는 List의 인덱스 값을 저장하기 위한 프로퍼티가 존재하지 않는다.
-
@CollectionTable은 밸류를 저장할 테이블을 지정할 때 사용한다.
- name 속성으로 테이블 이름을 지정
- joinColumns 속성은 외부키로 사용하는 컬럼을 지정한다.
- 외부키로 사용하는 컬럼이 두 개 이상인 경우 @JoinColumn의 배열을 이용해서 외부키 목록을 지정한다.
벨류 컬렉션을 한 개 컬럼에 매핑
- 밸류 컬렉션을 별도 테이블이 아닌 한 개 칼럼에 저장해야 할 때가 있다.
- 예를 들어, 도메인 모델에는 이메일 주소 목록을 Set으로 보관하고 DB에는 한 개 컬럼에 콤마 로 구분해서 저장해야 할 때
- 이럴 때 AttributeConverter를 사용하면 밸류 컬렉션을 한 개 칼럼에 쉽게 매핑할 수 있다.
- 단, AttributeConverter를 사용하려면 밸류 컬렉션을 표현하는 새로운 밸류 타입을 추가해야 한다.
- 이메일 집합을 위한 벨류 타입 추가
// 이메일 집합 public class EmailSet { private Set<Email> emails = new HashSet<>(); private EmailSet() {} public EmailSet(Set<Email> emails) { this.emails.addAll(emails); } public Set<Email> getEmails() { return Collections.unmodifiableSet(emails); } }import javax.persistence.AttributeConverter; import java.util.Arrays; import java.util.Set; import java.util.stream.Collectors; import static java.util.stream.Collectors.toSet; // AttributeConverter public class EmailSetConverter implements AttributeConverter<EmailSet, String> { @Override public String convertToDatabaseColumn(EmailSet attribute) { if (attribute == null) return null; return attribute.getEmails().stream() .map(Email::toString) .collect(Collectors.joining(",")); } @Override public EmailSet convertToEntityAttribute(String dbData) { if (dbData == null) return null; String[] emails = dbData.split(","); Set<Email> emailSet = Arrays.stream(emails) .map(value -> new Email(value)) .collect(toSet()); return new EmailSet(emailSet); } }// EmailSet을 EmailSetConverter를 사용하도록 지정 @Column(name = "emails") @Convert(converter = EmailSetConverter.class) private EmailSet emailSet;
벨류를 이용한 아이디 매핑
- 식별자는 최종적으로 문자열이나 숫자와 같은 기본 타입이기 때문에 String이나 Long 타입을 이용해서 식별자를 매핑한다.
@Id private String number; // 또는 @Id private Long id; - 식별자라는 의미를 부각시키기 위해 식별자 자체를 별도 밸류 타입으로 만든 경우에는 벨류 타입을 식별자로 매핑하면 @Id 대신 @EmbeddedId 애노테이션을 사용한다.
@EmbeddedId private OrderNo number; // @Embeddable public class OrderNo implements Serializable { @Column(name="order_number") private String number; ... @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; OrderNo orderNo = (OrderNo) o; return Objects.equals(number, orderNo.number); } @Override public int hashCode() { return Objects.hash(number); } }- JPA에서 식별자 타입은 Serializable 타입이어야 하므로 식별자로 사용될 밸류 타입 은 Serializable 인터페이스를 상속받아야 한다.
- 식별자 구현 시 벨류 타입으로 구현할 때 얻을 수 있는 장점으로는 식별자에 기능을 추가할 수 있다는 점이 있다.
- JPA는 내부적으로 엔티티를 비교할 목적으로 equals() 메서드와 hashcode() 값을 사용하므로 식별자로 사용할 밸류 타입은 이 두 메서드를 알맞게 구현해야 한다.
별도 테이블에 저장하는 밸류 매핑
- 애그리거트에서 루트 엔티티를 뺀 나머지 구성요소는 대부분 밸류이다.
- 루트 엔티티 외에 또 다른 엔티티가 있다면 진짜 엔티티인지 의심해봐야 한다.
- 단지 별도 테이블에 데이터를 저장한다고 해서 엔티티인 것은 아니다. 별도로 테이블에 저장되는 데이터가 벨류 타입이 될 수도 있기 때문.
- 밸류가 아니라 엔티티가 확실하다면 다른 애그리거트는 아닌지 확인해야 한다.
- 특히, 자신만의 독자적인 라이프사이클을 갖는다면 다른 에그리거트일 가능성이 높다.
- 데이터가 변경될 때 다른 밸류 타입에 영향을 주지 않고 (변경 또는 생성) 반대로 다른 밸류타입의 변경이 영향을 주지 않는 경우 같은 애그리거트에 속한 엔티티가 될 수 없다. 아니다.
- 애그리거트에 속한 객체가 밸류인지 엔티티인지 구분하는 방법은 고유 식별자를 갖는지 여부를 확인하는 것.
- 하지만, 식별자를 찾을 때 매핑되는 테이블의 식별자를 애그리거트 구성요소의 식별자와 동일한 것으로 착각하면 안 된다.
- 별도 테이블로 저장되고 테이블에 PK가 있다고 해서 테이블과 매핑되는 애그리거트 구성요소가 고유 식별자를 갖는 것은 아니다.

> (*Address로 표기된 부분은 추측컨데 ArticleContent의 오타로 보인다.)- 게시글을 ARTICLE 테이블과 ARTICLE_CONTENT 테이블로 나눠 저장하는 경우에 ArticleContent 는 Article 내용을 담고 있는 벨류로 생각하는 것이 맞다.
- ARTICLE_CONTENT의 ID는 ARTICLE 테이블의 데이터와 연결하기 위한 식별자. 즉, 게시글의 특정 프로퍼티를 별도 테이블에 보관한 것으로 접근해야 한다.
- ArticleContent 를 벨류로 보고 접근하면 모델은 아래와 같이 바뀐다.
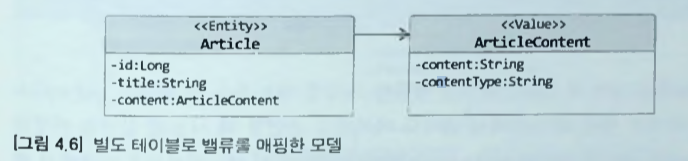
-
ArticleContent는 밸류이므로 @Embeddable 로 매핑.
-
ArticleContent 매핑되는 테이블은 밸류를 매핑한 테이블을 지정하기 위해 @SecondaryTable과 @AttributeOverrides, @AttributeOverride를 사용한다.
import javax.persistence.*; @Entity @Table(name = "article") @SecondaryTable( // 밸류를 저장할 테이블을 지정한다. name = "article_content", // 밸류 테이블에서 에티티 테이블로 조인할 때 사용할 컬럼을 지정한다. pkJoinColumns = @PrimaryKeyJoinColumn(name = "id") ) public class Article { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; private String title; // 해당 annotation을 사용해서 해당 밸류 데이터가 저장된 테이블 이름을 지정한다. @AttributeOverrides({ @AttributeOverride(name = "content", column = @Column(table = "article_content")), @AttributeOverride(name = "contentType", column = @Column(table = "article_content")) }) @Embedded private ArticleContent content; ... }import javax.persistence.Embeddable; @Embeddable public class ArticleContent { private String content; private String contentType; private ArticleContent() { } public ArticleContent(String content, String contentType) { this.content = content; this.contentType = contentType; } public String getContent() { return content; } public String getContentType() { return contentType; } }import javax.persistence.EntityManager; import javax.persistence.PersistenceContext; @Repository public class JpaArticleRepository implements ArticleRepository { @PersistenceContext private EntityManager entityManager; @Override public void save(Article article) { entityManager.persist(article); } // @SecondaryTable 에서 매핑된 article_content 테이블을 조인 // 게시글 목록을 보여주는 경우 article 테이블의 데이터만 필요하므로 조회 전용 기능을 구현하는 방법을 사용하는 것이 좋다. @Override public Article findById(Long id) { return entityManager.find(Article.class, id); } }
-
밸류 컬렉션을 @Entity 로 매핑하기
- 개념적으로 밸류인데 구현 기술의 한계나 팀 표준 때문에 @Entity를 사용해야 할 때도 있다.
-
예를 들어, 제품의 이미지 업로드 방식에 따라 이미지 경로와 썸네일 이미지 제공 여부가 달라지는 경우에 이를 위해 Image를 다음과 같이 계충 구조로 설계할 수 있다.
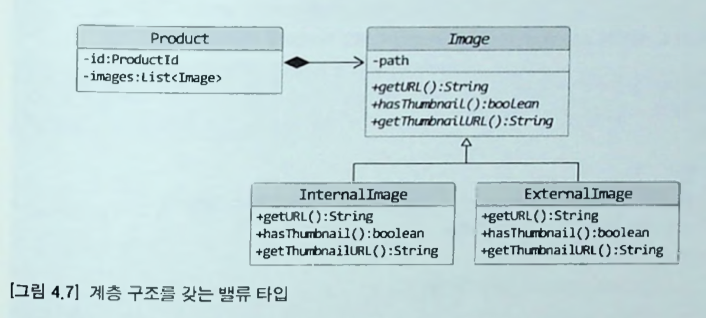
-
- JPA는 @Embeddable 타입의 클래스 상속 매핑을 지원하지 않는다. 따라서 상속 구조를 갖는 밸류 타입을 사용하려면 @Embeddable 대신 @Entity를 이용한 상속 매핑으로 처리해야 한다.
- 밸류 타입을 @Entity로 매핑하므로
- 식별자 매핑을 위한 필드도 추가해야 한다.
- 또한, 구현 클래스를 구분하기 위한 타입 식별 컬럼 (discriminator)을 추가해야 한다.
- Image 계층 구조를 저장하기 위한 테이블 구조는 아래와 같이 구성한다.
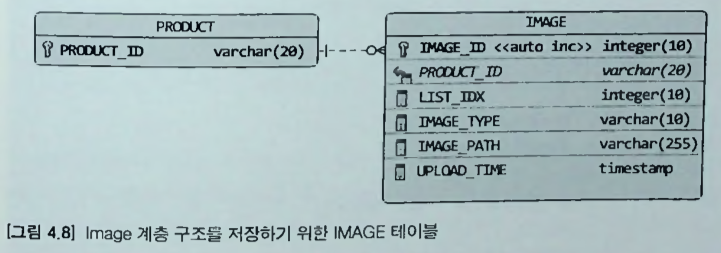
- 한 테이블에 lmage 및 하위 클래스를 매핑하므로
-
Image 클래스에 @Inheritance 적용하고 strategy 값으로 InheritanceType.SINGLE_TABLE 을 사용.
-
@DiscriminatorColumn 을 이용해서 타입을 구분하는 용도로 사용할 칼럼을 지정한다.
-
Image를 @Entity로 매핑했지만 모델에서 Image는 엔티티가 아니라 밸류이므로 상태를 변경하는 메서드는 추가하지 않는다.
import javax.persistence.*; import java.util.Date; @Entity @Inheritance(strategy = InheritanceType.SINGLE_TABLE) @DiscriminatorColumn(name = "image_type") @Table(name = "image") public abstract class Image { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "image_id") private Long id; @Column(name = "image_path") private String path; @Temporal(TemporalType.TIMESTAMP) @Column(name = "upload_time") private Date uploadTime; protected Image() {} public Image(String path) { this.path = path; this.uploadTime = new Date(); } protected String getPath() { return path; } public Date getUploadTime() { return uploadTime; } public abstract String getUrl(); public abstract boolean hasThumbnail(); public abstract String getThumbnailUrl(); }
-
- Image를 상속받은 클래스는 다음과 같이 @Entity와 @Discriminator를 사용해서 매핑을 설정한다.
import javax.persistence.DiscriminatorValue; import javax.persistence.Entity; @Entity @DiscriminatorValue("II") public class InternalImage extends Image { protected InternalImage() {} public InternalImage(String path) { super(path); } @Override public String getUrl() { return "/images/original/" + getPath(); } @Override public boolean hasThumbnail() { return true; } @Override public String getThumbnailUrl() { return "/images/thumbnail/"+getPath(); } }import javax.persistence.DiscriminatorValue; import javax.persistence.Entity; @Entity @DiscriminatorValue("EI") public class ExternalImage extends Image { private ExternalImage() {} public ExternalImage(String path) { super(path); } @Override public String getUrl() { return getPath(); } @Override public boolean hasThumbnail() { return false; } @Override public String getThumbnailUrl() { return null; } } - Image가 @Entity 이므로 목록을 담고 있는 Product는 같이 @OneToMany 를 이용해서 매핑을 처리한다.
@Entity @Table(name = "product") public class Product { @EmbeddedId private ProductId id; ... **@OneToMany(cascade = {CascadeType.PERSIST, CascadeType.REMOVE}, orphanRemoval = true, fetch = FetchType.EAGER)** @JoinColumn(name = "product_id") @OrderColumn(name = "list_idx") private List<Image> images = new ArrayList<>(); ... // 이미지 교체를 위해 clear() 메서드를 호출 public void changeImages(List<Image> newImages) { images.clear(); images.addAll(newImages); } }- Image는 밸류이므로 독자적인 라이프사이클을 갖지 않고 Product에 완전히 의존한다. 따라서, cascade 속성을 이용해서 Product 가 저장할 때 함께 저장되고(CascadeType.PERSIST), Product를 삭제할 때 함게 삭제되도록 설정(CascadeType.REMOVE)한다.
- 리스트에서 Image 객체롤 제거하면 DB에서 함께 삭제되도록 orphanRemoval도 true로 설정한다.
- @Entity 에 대한 @OneToMany 매핑에서 컬렉션의 clear() 메서드를 호출하면 삭제 과정이 효율적이지 않을 수 있다.
- 예를 들어, 하이버네이트의 경우 @Entity를 위한 컬렉션 객체의 clear() 메서드를 호출하면 select 쿼리로 대상 엔티티를 로딩하고 각 개별 엔티티에 대해 delete 쿼리를 실행한다.
- changeImages()가 실행 시에 Image 목록을 가져오기 위한 한 번의
selet * from image where product_id=?쿼리(이미 로딩했다면 select는 생략)와 각 Image를 삭제하기 위한 이미지 개수 만큼의delete from image where image_id=?쿼리를 실행한다. - 변경 빈도가 낮으면 괜찮지만 빈도가 높으면 전체 서비스 성능에 문제가 될 수 있다.
- 하이버네이트는 @Embeddable 타입에 대한 컬렉션의 clear() 메서드를 호출하면 컬렉션에 속한 객체를 로딩하지 않고 한 번의 delete 쿼리로 삭제 처리를 수행한다.
@Embeddable public class Image { @Column(name = "image_type") private String imageType; @Column(name = "image_path") private String path; @Temporal(TemporalType.TIMESTAMP) @Column(name = "upload_time") private Date uploadTime; ... public boolean hasThumbnail() { // 성능을 위해 다형을 포기하고 if-else로 구현 if (imageType.equals("II")) { return true; } else { return false; } } }- 애그리거트의 특성을 유지하면서 @Entity를 위한 컬렉션 객체의 clear() 메서드 호출 시 다중 delete 쿼리가 실행되는 문제를 해소하려면 결국 상속을 포기하고 @Embeddable로 매핑된 단일 클래스로 구현해야 한다.
- 물론, 이 경우 타입에 따라 다른 기능을 구현하려면 if-else로 구현해야 하는 단점이 발생한다.
- 애그리거트의 특성을 유지하면서 @Entity를 위한 컬렉션 객체의 clear() 메서드 호출 시 다중 delete 쿼리가 실행되는 문제를 해소하려면 결국 상속을 포기하고 @Embeddable로 매핑된 단일 클래스로 구현해야 한다.
- 코드 유지보수와 성능의 두 가지 측면을 고려해서 구현 방식을 선택해야 한다.
ID 참조와 조인 테이블을 이용한 단방향 M:N 매핑
- 애그리거트 간 집합 연관은 성능상의 이유로 피해야 한다
-
그럼에도 불구하고 요구사항을 구현하는 데 집합 연관을 사용하는 것이 유리하다면 ID 참조를 이용한 단방향 집합 연관을 적용해 볼 수 있다.
@Entity @Table(name = "product") public class Product { @EmbeddedId private ProductId id; // Product에서 Category로의 단방향 M:N 연관을 ID 참조 방식으로 구현. @ElementCollection @CollectionTable(name = "product_category", joinColumns = @JoinColumn(name = "product_id")) private Set<CategoryId> categoryIds; ... } -
ID 참조를 이용한 애그리거트 간 단방향 M:N 연관은 밸류 컬렉션 매핑과 동일한 방식으로 설정한 것을 확인할 수 있다.
-
차이점이 있다면, 집합의 값에 밸류 타입 대신 연관을 맺는 식별자가 온다는 점이다.
-
@ElementCollection 을 이용하기 때문에 Product 를 삭제할 때 매핑에 사용한 조인 테이블의 데이터도 함께 삭제된다.
-
- 얘그리거트를 직접 참조하는 방식을 사용했다면 영속성 전파나 로딩 전략을 고민해야 했을 것이다.
애그리거트 로딩 전략
- JPA 매핑을 설정한 때 항상 기억해야 할 점은
애그리거트에 속한 객체가 모두 모여야 완전한 하나가 된다는 것이다.-
즉, 애그리거트의 루트를 로딩(조회)하면 속해있는 모든 객체가 완전한 상태여야 하는 것.
-
조회 시점에서 애그리거트를 완전한 상태가 되도록 하려면 애그리게트 루트에서 연관 매핑의 조회 방식을 즉시 로딩(
FetchType.EAGER)으로 설정한다. -
컬렉션이나 @Entity 에 대한 매핑의 fetch 속성을 즉시 로딩으로 설정하면 EntityManager#find() 메서드로 애그리거트 루트를 구할 때 연관된 구성요소를 DB에서 함께 읽어온다.
// @Entity 컬렉션에 대한 즉시 로딩 설정 @OneToMany(cascade = {CascadeType.PERSIST, CascadeType.REMOVE}, orphanRemoval = true, fetch = FetchType.EAGER) @JoinColumn(name = "product_id") @OrderColumn(name = "list_idx") private List<Image> images = new ArrayList<>(); // @Embeddable 컬렉션에 대한 즉시 로딩 설정 @ElementCollection @CollectionTable(name = "order_line", joinColumns = @JoinColumn(name = "order_number")) @OrderColumn(name = "line_idx") private List<OrderLine> orderLines;
-
- 즉시 로딩 방식으로 설정하면 애그리거트 루트를 로딩하는 시점에 에그리거트에 속한 모든 객체를 함께 로딩할 수 있는 장점 이 있지만...
- 이 장점이 항상 좋은 것은 아니다. 특히 컬렉션에 대해 로딩 전략을 FetchType.EAGER로 설정하면 (left outer) join 쿼리 실행 시 중복된 결과과 조회된다.
-
product의 image, option을 함께 조회하는 경우 product 테이블의 각 unique row만 조회되는 것이 아니라 join된 테이블의 row와 함께 조회된다.
(product1-image1-option1, product1-image1-option2 product1-image2-option1, ...)
-
물론, 하이버네이트가 중복된 데이터를 알맞게 제거해서 실제 메모리에는 1개의
Product 객체에 설정된 밸류만큼의 객체로 변환해 주지만 애그리거트가 커지면 문제가 될 수 있다.
-
- 이 장점이 항상 좋은 것은 아니다. 특히 컬렉션에 대해 로딩 전략을 FetchType.EAGER로 설정하면 (left outer) join 쿼리 실행 시 중복된 결과과 조회된다.
- 애그리거트는 개념적으로 하나여야 한다. 하지만, 루트 엔티티를 로딩하는 시점에 에그리거트에 속한 객체를 모두 로딩해야 하는 것은 아니다.
- 애그리거트가 완전해야 하는 이유는 두 가지 정도로 생각해 볼 수 있다.
- 첫 번째 이유는 상태를 변경하는 기능을 실행할 때 애그리거트 상대가 완전해야 하고,
- 두 번째 이유는 표현 영역에서 애그리거트의 상태 정보를 보여줄 때 필요하기 때문이다. (해당 경우에는 별도의 조회 전용 기능을 구현하는 방식을 사용하는 것이 유리할 때가 많다.)
- 애그리거트의 완전한 로딩과 관련된 문제는 상태 변경과 더 관련이 있다. 상태 변경 기능을 실행하기 위해 조회 시점에 즉시 로딩을 이용해서 애그리거트를 완전한 상태로 로딩할 필요는 없다.
-
JPA는 트랜잭션 범위 내에서 지연 로딩(
FetchType.LAZY)을 허용하기 때문에 실제로 상태를 변경하는 시점에 필요한 구성 요소만 로딩해도 문제가 되지 않는다.// product에 image정보, option정보가 함께 조회되어야 구성 @Transactional public void removeOptions(ProductId id, int optIdxToBeDeleted) { // product를 로딩. 컬렉션은 지연 로딩(Lazy)으로 설정했다면 Option은 로딩하지 않음 Product product = productRepository.findById(id); // transaction 범위이므로 지연 로딩으로 설정한 연관 로딩 가능 product.removeOption(optIdxToBeDeleted); }@Entity @Table(name = "product") public class Product { ... @ElementCollection(fetch = FetchType.LAZY) @CollectionTable(name = "product_option", joinColumns = @JoinColumn(name = "product_id")) @OrderColumn(name = "list_idx") private List<Option> options = new ArrayList<>(); ... public void removeOption(int optIdx) { // 실제 컬렉션에 접근할 때 로딩. this.options.remove(optIdx); } } -
일반적인 애플리케이션은 상태를 변경하는 기능을 실행하는 빈도보다 조회 하는 기능을 실행하는 빈도가 휠씬 높다.
-
그러한 점에서 상태 변경을 위해 지연 로딩을 사용할 때 발생하는 추가 쿼리로 인한 실행 속도 저하는 문제가 되지 않는다고 한다.
-
- 따라서, 애그리거트 내의 모든 연관을 즉시 로딩으로 설정할 필요는 없다. 지연 로딩은 동작 방식이 항상 동일하기 때문에 즉시 로딩처럼 경우의 수를 따질 필요가 없는 장점이 있다.
- 즉시 로딩 설정은 @Entity, @Embeddable 대해 다르게 동작하고, JPA 프로바이더에 따라 구현 방식이 다를 수도 있다고 한다.
- 물론, 지연 로딩은 즉시 로딩보다 쿼리 실행 횟수가 많아질 가능성이 더 높다. 따라서, 무조건 즉시 로딩이나 지연 로딩으로만 설정하기보다는 애그리거트에 맞게 즉시 로딩과 지연 로딩을 선택해야 한다.
애그리거트의 영속성 전파
- 애그리거트가 완전한 상태여야 한다 = 애그리거트 루트를 조회할 때뿐만 아니라 저장하고 삭제할 때도 하나로 처리해야 함을 의미.
- 저장 메서드는 애그리거트 루트만 저장하면 안되고 애그리거트에 속한 모든 객체를 저장해야 한다.
- 삭제 메서드는 애그리거트 루트뿐만 아니라 애그리거트에 속한 모든 객체를 삭제해야 한다.
- @Embeddable 매핑 타입의 경우 함께 저장되고 삭제되므로 cascade 속성을 추가로 설정하지 않아도 된다.
- 반면에 얘그리거트에 속한 @Entity 타입에 대한 매핑은 cascade 속성을 사용해서 저장과 삭제 시에 함께 처리되도록 설정해야 한다.
- @OneToOne, @OneToMany 는 cascade 속성의 기본값이 없으므로 다음과 같이
PERSIST,REMOVE를 설정한다.cascade = {CascadeType.PERSIST, CascadeType.REMOVE}
- @OneToOne, @OneToMany 는 cascade 속성의 기본값이 없으므로 다음과 같이
식별자 생성 기능
- 식별자의 생성 방식
- 사용자가 직접 생성
- 도메인 로직으로 생성
- DB를 이용한 일련번호 사용 (AutoIncrement 또는 Sequence)
- 이메일 주소처럼 사용자가 직접 식별자를 입력하는 경우는 식별자 생성 주체가 사용자이기 때문에 도메인 영역에 식별자 생성 기능을 구현할 필요가 없다.
- 식별자 생성 규칙이 있는 경우 엔티티를 생성할 때 이미 생성한 식별자를 전달하므로 엔티티가 식별자 생성 기능을 제공하는 것보다는 별도 서비스로 식별자 생성 기능을 분리해야 한다.
-
식별자 생성 규칙은 도메인 규칙이므로 도메인 영역에 식별자 생성 기능을 위치시켜야 한다.
public class ProductIdService { public ProductId nextId() { // 정해진 규칙으로 식별자 생성 } public ProductOrderId createId(UserId userId) { return new ProductOrderId(userId.toString() + "-" + getTimeStamp()); } private String getTimeStamp() { return Long.toString(System.currentTimeMillis(); } } -
응용 서비스는 도메인 영역의 서비스를 이용해서 식별자를 구한 뒤 엔티티를 생성
@Service public class CreateProductService { @Autowired private ProductIdService idService; @Autowired private ProductRepository productRepository; public ProductId createProduct(ProductCreationCommand cmd) { // 응용 서비스는 도메인 서비스를 이용해서 식별자를 생성 처리 ProductId id = idService.nextId(); Product product = new Product(id, cmd.getDetail(), ...); productRepository.save(product); return id; } } -
특정 값의 조합으로 식별자가 생성되는 것 역시 규칙이므로 도메인 서비스를 이용해서 식별자를 생성할 수 있다.
-
- 식별자 생성 규칙을 구현하기에 적합한 또 다른 장소는 리포지터리이다. 다음과 같이 리포지터리 인터페이스에 식별자를 생성하는 메서드를 추가하고 리포지터리 구현 클래스에서 알맞게 구현하면 된다.
public interface ProductRepository { ... // 식별자를 생성하는 메서드 ProductId nextId(); } - 식별자 생성으로 DB의 자동 증가 칼럼을 사용할 경우 JPA의 식별자 매핑에서 @GeneratedValue 를 사용한다.
import javax.persistence.*; @Entity @Table(name = "article") @SecondaryTable( name = "article_content", pkJoinColumns = @PrimaryKeyJoinColumn(name = "id") ) public class Article { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; ... public Long getId() { return id; } ... }- 자동 증가 칼럼은 DB의 insert 쿼리를 실행해야 식별자가 생성되므로 도메인 객체를 리포지터리에 저장할 때 식별자가 생성된다. (저장된 뒤 식별자 확인 가능)
- JPA는 저장 시점에 생성한 식별자를 @Id로 매핑한 프로퍼티/필드에 할당한다. 따라서, 다음과 같이 저장 이후에 엔티티의 식별자를 사용할 수 있다.
public class WriteArticleService { private ArticleRepository articleRepository; Article article = new Article("제목", new ArticleContent("content", "type")); articleRepository.save(article); // EntityManager#save() 실행 시점에 식별자가 생성된다. // 저장 이후에 식별자를 사용할 수 있다. Long savedArticleId = article.getId(); }
- 자동 증가 컬럼 외에 JPA의 식별자 생성 기능을 사용하는 경우에도 마찬가지로 저장 시점에 식별자를 생성한다.
