문제 링크
https://www.acmicpc.net/problem/17298
풀이 전 계획과 생각
크기가 N인 수열 A = A1, A2, ..., AN이 있다. 수열의 각 원소 Ai에 대해서 오큰수 NGE(i)를 구하려고 한다. Ai의 오큰수는 오른쪽에 있으면서 Ai보다 큰 수 중에서 가장 왼쪽에 있는 수를 의미한다. 그러한 수가 없는 경우에 오큰수는 -1이다.
예를 들어, A = [3, 5, 2, 7]인 경우 NGE(1) = 5, NGE(2) = 7, NGE(3) = 7, NGE(4) = -1이다.
A = [9, 5, 4, 8]인 경우에는 NGE(1) = -1, NGE(2) = 8, NGE(3) = 8, NGE(4) = -1이다.
우선 그냥 아무 계획도 생각도 없이 저 조건들로 반복문을 구성해서 하나하나 비교를 시켰더니 시간 초과가 떴다. 그 때부터 뒤늦게 계획이 시작되었다.
반드시 직접 구현을 해보겠다는 생각에 풀이 코드가 눈에 보이지 않도록 유의하면서 구글에 검색해 풀이 힌트들을 훑어보니 스택을 활용해야 시간복잡도가 줄어든다고 했다.
도움이 되었던 참고문헌들을 여기에 기록해둔다.
https://hooongs.tistory.com/329
https://developmentdiary.tistory.com/240
(구글 검색결과 첫 페이지를 모두 읽었는데 아예 이런 상황에서 스택을 왜 쓰는지에 대해 아무 생각이 없는 상태로 보니 위의 둘 말고는 아예 이해할 수가 없었다! ㅋㅋㅋ)
솔직히 스택을 활용하면 시간복잡도가 줄어든다는 말이 무슨 말인지도 이해할 수가 없어서 한참을 살펴봤더니 대략 이런 내용이었다.
- 예를 들어
t=[9,5,4,8]이라는 배열이 있다. - 오큰수를 못 찾은 인덱스의 결과값은
-1이니까output=[-1,-1,-1,-1]로 초기화한 출력값 배열을 만들어둔다. - 일단 첫째 원소의 인덱스인 0을 스택에 넣는다.
- 스택의 탑과
t[1]을 비교한다. 9보다 5가 작으니t[1]은t[0]의 오큰수가 아니다. 1도 스택에 넣는다. - 스택의 탑과
t[2]를 비교한다. 5보다 4가 작으니t[2]는t[1]의 오큰수가 아니며 당연히t[0]보다도 작으니 스택에 있는 인덱스의 원소들의 오큰수가 될 수 없다. 2도 스택에 넣는다. - 스택의 탑과
t[3]를 비교한다.t[3]는t[2]즉t[stack.pop()]의 오큰수가 된다. 그러므로output[stack.pop()]=t[3]이 된다. - 스택의 다음 탑과
t[3]를 계속 비교하고 오큰수에 해당되면output[stack.pop()]=t[3]를 계속한다 - 이제
output=[-1,8,8,-1]이 되었고stack에는0만 남아 있다.t[0]과t[3]을 비교해보면 9보다 8이 작으니output[]은 업데이트가 되지 않고3도 스택에 넣는다. - 만약에
t[4]가 있다면 스택에 남은 값과 계속 비교해보겠지만 없으니까 반복을 종료한다.
여러 가지 설명을 보아도 스택이 왜 반복을 줄인다는 것인지, 그리고 저런 스택을 어떻게 구현한다는 것인지 잘 이해가 되지 않아서 그림으로 그려보면서 계속 생각해 보았는데 굳이 내 악필을 인터넷에 널리 공개할 필요는 없으니 윈도우즈 그림판에 그림으로 다시 그린 이미지로 대체하겠다.
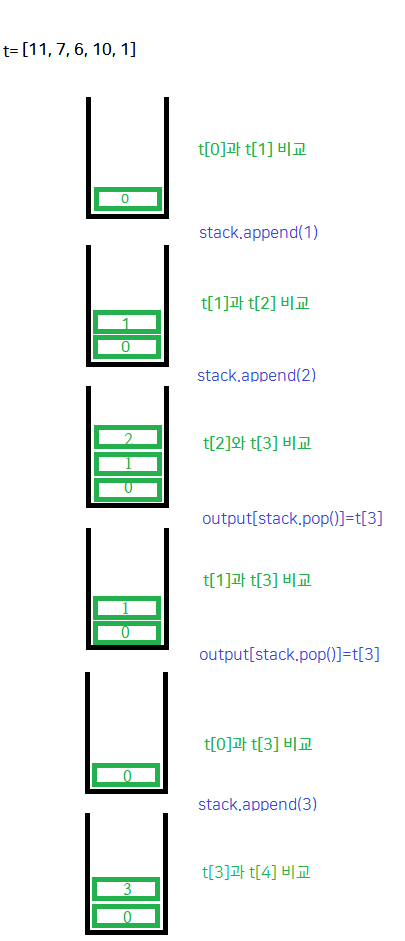
정리하자면 오큰수를 못 찾은(오른쪽의 수들보다 큰) 값들의 정보를 스택에 계속 넣어 두고, 그 다음에 더 작은 값이 나왔다면 당연히 앞의 값들보다 작으니까 비교할 필요가 없고 다음에 직전 값의 오큰수가 나왔다면 그때부터 비교해보면 되니까 반복을 줄일 수 있다는 것이다.
하지만 막연하게 저 그림을 반복문들과 조건문들이 너덜너덜하게 겹쳐진 코드로 그대로 표현했더니 예시 입력값들에 대해서는 올바른 출력값들이 나왔지만 백준 온라인 저지 사이트의 채점 결과는 틀렸습니다가 나왔다. ㅋㅋㅋ
그럼에도 불구하고 여전히 스스로 구현해 보겠다는 집념으로 구글 검색 결과에 나오는 풀이 코드를 안 보려고 주의하면서 해설만 계속 읽어보았다.
대략적으로 내가 이해한 바에 따르면 while문에 스택의 비교 조건이 모두 들어가게 해서 오큰수를 찾지 못했으면 이중 반복문 안에 아예 들어가지 않게 하는 방법이 있고, 그리고 논리적인 순서는 물리적인 코드 순서와 반드시 일치할 필요는 없는 것 같다...
풀이 (코드 블록 첨부)
# 백준 17298 오큰수 최종합격
import sys
counter=int(input(""))
table=[]
table=list(map(int,sys.stdin.readline().split()))
stk=[]
output=[]
for i in range(len(table)):
output.append(-1)
for i in range(len(table)):
while stk!=[] and table[stk[-1]]<table[i]:
output[stk.pop()]=table[i]
stk.append(i)
#print(output)
for no in output:
print(no,end=" ")
풀이하면서 막혔던 점과 고민
상술하였듯이 스택으로 반복을 줄인다는 개념 자체를 이해해서 그 상태를 스스로 구현할 수 있게 되기까지 엄청나게 오래 걸렸다. 내가 왜 중학교 때부터 수학을 싫어해서 문과인이 되었는지 잘 알 수 있는 시간이었고 정말로 나중에 시간을 내서 좀더 쉬운 문제를 조금씩 풀어봐야겠다는 생각이 들 따름이다. ㅋㅋㅋ
풀이 후 알게된 개념과 소감
스택은 last in first out 자료구조라고 외우기만 했고 '음식을 스택처럼 관리한다면 바닥에 오래된 음식이 남아서 신선하지 않겠군...' 이라고 막연하게 생각만 했지 그 자료구조를 어떤 경우에 어떻게 활용하는지에 대해서 자세히 생각해보고 구현해 보는 경험이 부족했던 것 같다.
다음에 시간을 내서 백준 온라인 저지 단계별 문제 목록에서 스택 코너의 조금 더 쉬운 문제들을 연습해봐야겠다. (전에 하던 코딩테스트 사이트에 오랜만에 들어가보니 정말 스택 나오는 문제는 열심히 피해다녔다는 것을 확인할 수 있었다.)

아무튼 너무 힘들었고 일단 좀 쉬었다가 해봐야겠다. ㅋㅋㅋ
