전에 들어봤는데 2021년 추석 이벤트에 다시 나와서 또 무료수강함.
import dload
from bs4 import BeautifulSoup
from selenium import webdriver
import time
driver = webdriver.Chrome('chromedriver') # 웹드라이버 파일의 경로
driver.get("https://search.daum.net/search?w=img&nil_search=btn&DA=NTB&enc=utf8&q=%EB%A0%88%EB%93%9C%EB%B2%A8%EB%B2%B3")
time.sleep(5) # 5초 동안 페이지 로딩 기다리기여기까지 입력을 하면 아래와 같이 다음에서 '레드벨벳' 이미지를 검색하는 크롬 창을 띄운다.
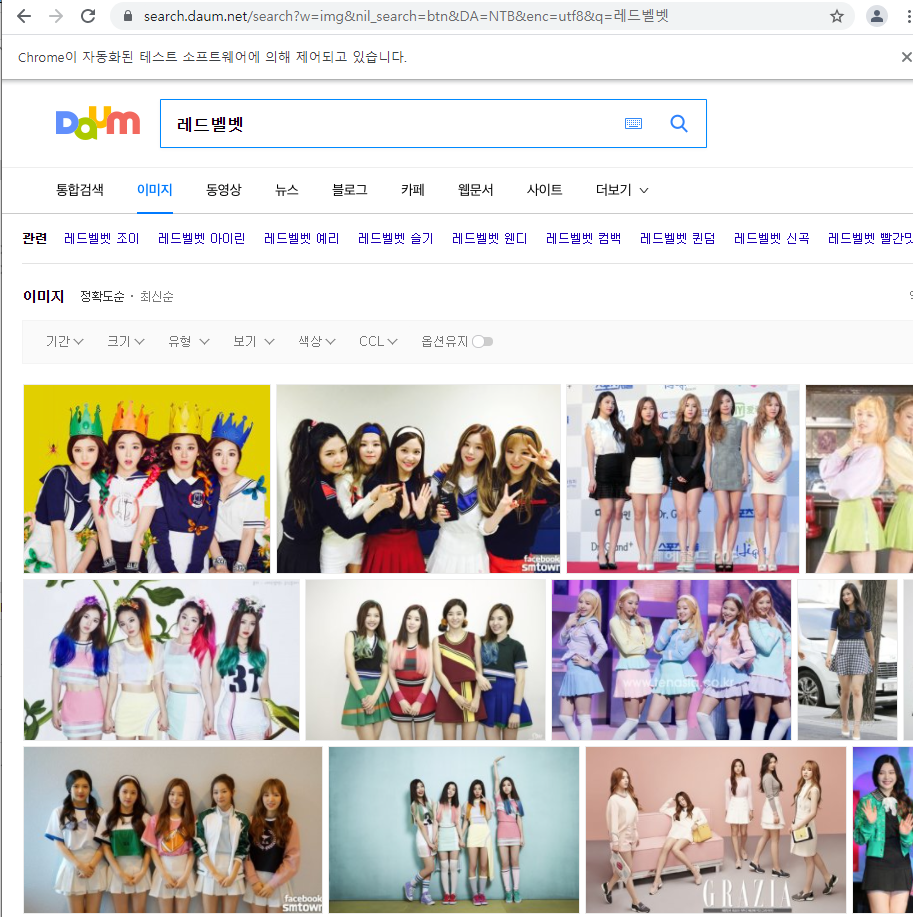
5초 동안 띄운다고 했는데 내 생각에는 그보다는 더 오래 떠 있는 것 같은데... 아마 주어진 명령은 다 실행하고 닫기 때문인 것 같기도 하고.
이 링크 화면을 별도로 내가 쓰는 웹브라우저에 불러서 개발자도구를 띄워보염 이미지 요소가 웹페이지에서 어떻게 뜨는지 나온다.
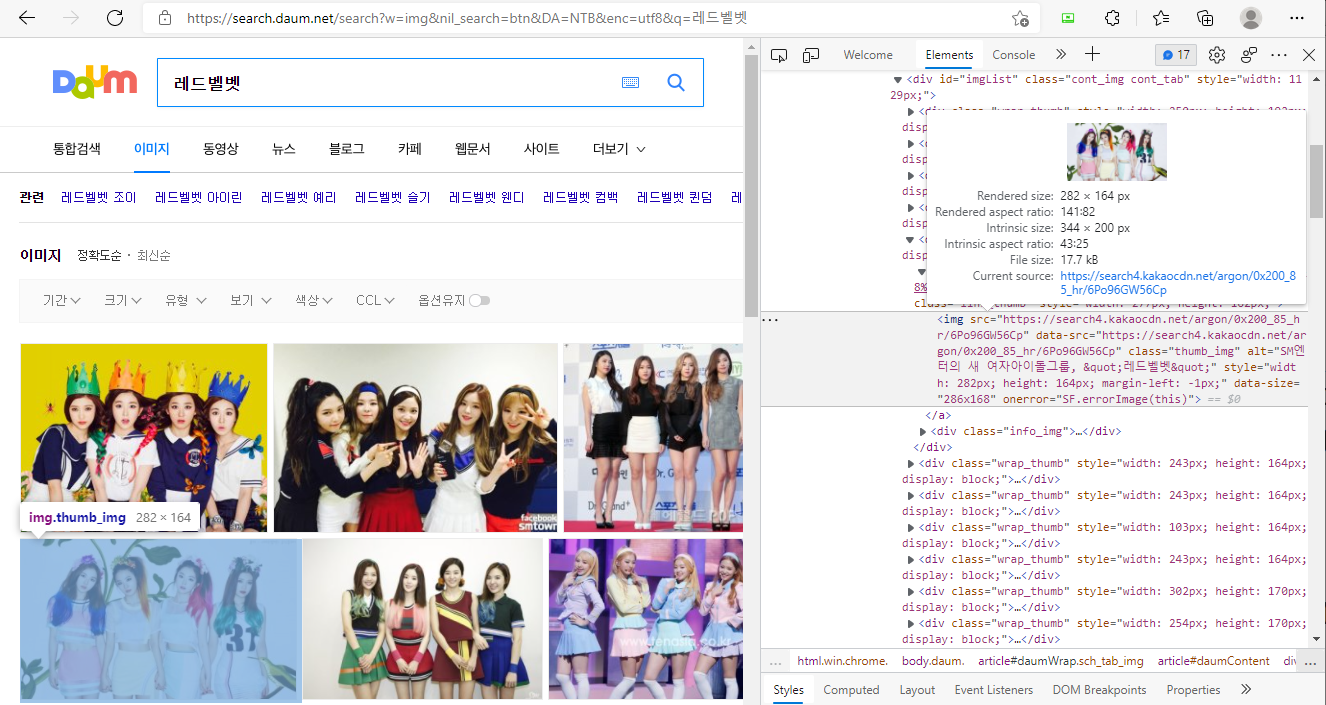
이 부분에서 'copy element'를 하면...
<img src="https://search4.kakaocdn.net/argon/0x200_85_hr/6Po96GW56Cp"
data-src="https://search4.kakaocdn.net/argon/0x200_85_hr/6Po96GW56Cp"
class="thumb_img"
alt="SM엔터의 새 여자아이돌그룹, &quot;레드벨벳&quot;"
style="width: 282px; height: 164px; margin-left: -1px;"
data-size="286x168"
onerror="SF.errorImage(this)">그리고 'copy selector'를 하면...
#imgList > div:nth-child(5) > a > img...어쨌든 그래서 저 url들을 모두 긁어서 출력하려면 이렇게 하면 된다고 한다.
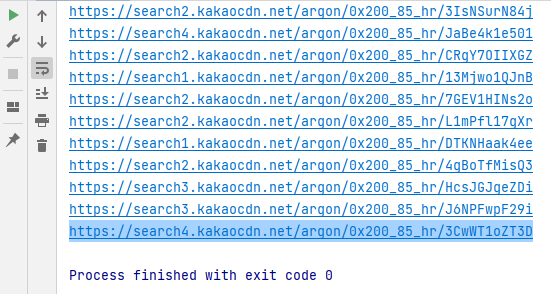
thumbnails = soup.select("#imgList > div > a > img")
for thumbnail in thumbnails:
src = thumbnail["src"]
print(src)그러면 이런 식으로 뜨고
그 링크 중 하나를 가져오면 출력 결과는 이렇고
저 링크를 모두 내 컴퓨터에 저장하려면 위 코드에서 반복문만 이렇게 수정한다.
파일명은 겹치면 안 되니까 계속 1씩 증가하는 값으로 저장하고.
i=1
for thumbnail in thumbnails:
src = thumbnail["src"]
dload.save(src, f'imgs_homework/{i}.jpg')
i+=1이렇게 해서 80장의 이미지가 저장되었다.
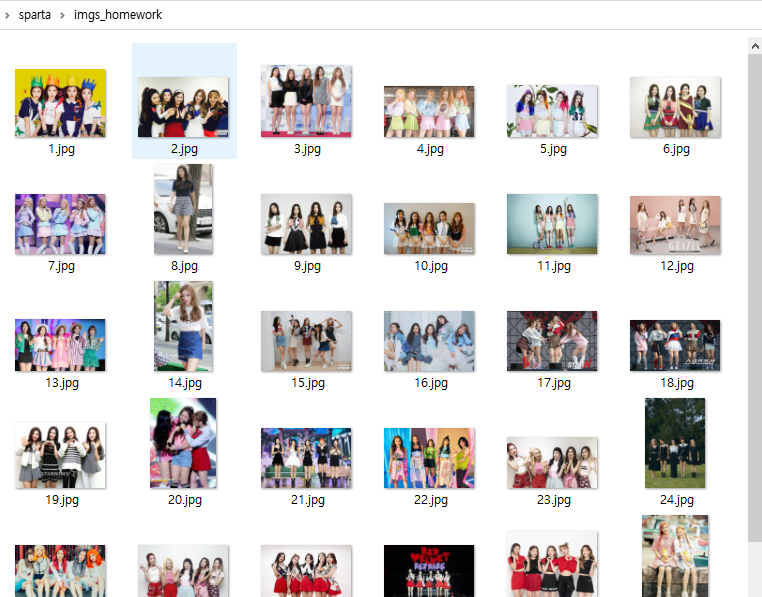

매일 공부하며 살고 있구나