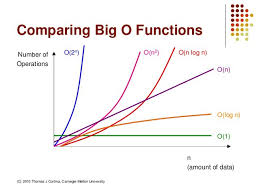
Time Complexity
빠른 시간안에 적은 자원을 사용하는 알고리즘/프로그램이 효율적이라 할 수 있다.
우리가 컴퓨터 연산 수를 추정할 수 있다면 더 효율적인 알고리즘과 프로그램을 찾을 수 있을 것이다.
시간복잡도 (BIG-O)방법은 최악의 상황을 고려하여 효율성을 계산한다.
// 보통 을 logN으로 작성
) // N과 M은 독립
본인이 작성한 프로그램의 시간 복잡도는 계산할 수 있어야 함
List
리스트 정의
-
Linear relationship
각 요소의 첫 번째와 마지막은 전임자와 후임자를 갖는다. -
리스트의 길이는 시간이 지남에 따라 변화할 수 있다.
Unsorted List
특정한 규칙없이 아이템들이 배치되어있는 형태
함수 선언
typedef int ItemType;
class UnsortedType{
Private:
ItemType data[MAX_SIZE];
int length
Public:
UnsortedType();
void appendItem(ItemType value);
void insertItem(int pos, ItemType value);
void removeItem(ItemType value);
void updateItem(int pos, ItemType new_value);
void clear();
int size();
bool isFull();
bool isEmpty();
bool findItem(ItemType item);
ItemType getItem(int pos);
};위는 unsorted list의 선언 부분이다.
순간 헷갈렸는데 배열 선언 부분 [n]은 n크기의 배열을 만든다는 것임 -> 0~n의 열을 가진 배열을 만든다는것이 아님
기본 함수 정의
#include "UnsortedType.h"
UnsortedType::UnsortedType(){
length=0
}
int UnsortedType::Size(){
return length;
}
bool UnsortedType::ifFull(){
return (length == MAX_SIZE);
}
bool UnsortedType::IsEmpty(){
return (length ==0);
}
void UnsortedType::appendItem(ItemType value){
if (isFull( )){
return;
}
data[length] = value;
length ++;
}기본적인 연산자들의 정의이다.
insetItem
그렇다면 insertItem은 어떻게 구현할 수 있을까?
첫 번째로 넣으려는 위치 뒤에 있는 모든 item을 뒤로 옮기는 것이다. 하지만 이는 시간 복잡도가 O(N)인 방법으로 효율적이지 못하다.
두 번째 방법은 넣으려는 위치에 있는 아이템을 뒤로 옮긴 뒤 그 자리에 그냥 넣는 것이다.
어차피 Unsorted List이기 때문에 어떻게 넣든 상관없다.
void UnsortedType::insertItem(int pos, ItemType value){
if (isFull( )){
return;
}
if (pos > length){
return;
}
data[length] = data[pos];
data[pos] = value;
length ++;
}위는 이를 구현한 코드이다.
removeItem
removeItem또한 개선할 수 있다. O(2N + 1) 에서 O(N + 2)로 개선 가능하다.
이론적으로는 동일하지만 실제로는 연산을 두배 적게 할 수 있다.
기존의 removeItem은 Item을 찾고 O(N) 없앤 뒤 O(1) 뒤에 있는 아이템들을 전부 한칸씩 옮긴다. O(N)
반면 개선된 improved_removeItem은 없애려는 Item 위치에 맨 뒤에 있는 Item을 넣은 뒤 length를 -1 해준다. (data 안에 값은 남아있지만 length를 -1 해줬으므로 append할 때 덮어 씌우는 효과를 내는 것이다.)
void UnsortedType::removeItem(ItemType value){
if (isEmpty( )){
cout << "[ERROR] List is EMPTY" << endl;
return;
}
for ( int i = 0; i < length; i++ ){
if (data[i] == value){
data[i] = data[length-1];
length--;
break;
}
}나머지 연산자들
void UnsortedType::updateItem(int pos, ItemType new_value){
if (pos >= length){
cout << "[ERROR] Invalid Position (pos >= length)" << endl;
return;
}
data[pos] = new_value;
}
void UnsortedType::clear( ){
length = 0;
}
ItemType UnsortedType::getItem(int pos){
if (pos >= length){
cout << "[ERROR] Invalid Position (pos >= length)" << endl;
return -1;
}
return data[pos];
}
bool UnsortedType::findItem(ItemType item){
int location = 0;
while(location < length){
if(data[location] == item){
return true;
}
location ++;
}
return false;
}각각 시간복잡도 O(1), O(1), O(1), O(N)이다.
SortedList
Item끼리 상관관계가 있는 리스트이다.
Key란 리스트의 순서를 좌우하는 속성이며, 복합적인 데이터를 어떤 기준으로 정렬할지 정한다.
예를 들어 이름, 생년월일, 학점, 학번으로 구성되어있는 자료가 있을 때 이름 순으로 자료의 순서를 정한다면 이때 key는 이름이 되는 것이다.
연산자
SortedList의 연산자는 UnsortedList에서 appendItem과updateItem을 없애고 InsertItem과 removeItem을 수정해주면 된다. 나머지 구성은 동일하다.
다음은 각각 InsertItem과 removeItem의 구현 코드이다.
void SortedType::insertItem(ItemType value){
if (isFull( )){
return;
}
int location = 0;
while (location < length){
if(value > data[location]){
location ++;
}
else{
break;
}
}
for ( int i = length; i > location; i-- ){
data[ i ] = data[i-1];
}
data[location] = value;
length ++;
}
void SortedType::removeItem(ItemType value){
if (isEmpty( )){
return;
}
int location = 0;
while (location < length){
if(value > data[location]){
location ++;
}
else{
break;
}
}
for ( int i = location + 1; i < length; i++ ){
data[i-1] = data[i];
}
length --;
}두 함수 모두 시간 복잡도는 O(N)이다.
findItem
SortedList에서 Item을 처음부터 찾는 건 비효율적으로 보인다.
처음 해볼 수 있는 생각은 찾는 Item이 안나왔는데 그보다 큰 값이 나오기 시작한다면 false를 return하는 것이다. 전보단 효율적이긴 하지만 여전히 비효율적이다.
Binary Search
두 번째 방법은 이진 검색을 사용하는 것이다.
이진 검색의 개념은 중간 값과 찾는 값을 비교하며 중간 값보다 클 시 중간 값을 포함한 이전을 전부 날리고 반대는 중간 값을 포함한 이상을 전부 날려가며 값을 찾는 것이다.
다음은 이진 검색 구현 코드이다.
int SortedType::BinarySearch(ItemType item){
int ret;
int mid;
int first = 0;
int last = length - 1;
while (first <= last) {
mid = (first + last) / 2;
if (item > data[mid]) { // 중간 값보다 클 시
first = mid + 1; // 앞 전부 날림
}
else if(item < data[mid]) { // 중간 값보다 작을 시
last = mid - 1; // 뒤 전부 날림
}
else {
ret = mid;
return ret;
}
}
ret = -1;
return ret;
}이진 검색의 시간 복잡도는 O(logN)이다.
