서론
- 일단 프로젝트에서 EC2에 DB를 설치하여 사용을 하고 있었습니다. 그런데 갑자기 DB 서버의 CPU가 100%가 되어서 시스템의 오류가 발생을 하였습니다.
- 시스템의 오류가 발생한 이유는 다음과 같다. CPU가 100%가 되며 서버가 다운이 되었습니다.
- 물론 서버가 다운이 되는 이유가 여러가지가 있지만 AWS 공식 사이트 해당 사이트를 보면서 CPU 및 메모리 소진으로 판단을 하였습니다.
-
그러면 왜 CPU가 100%가 되었는지 궁금하여 문제를 찾아봤습니다.
-
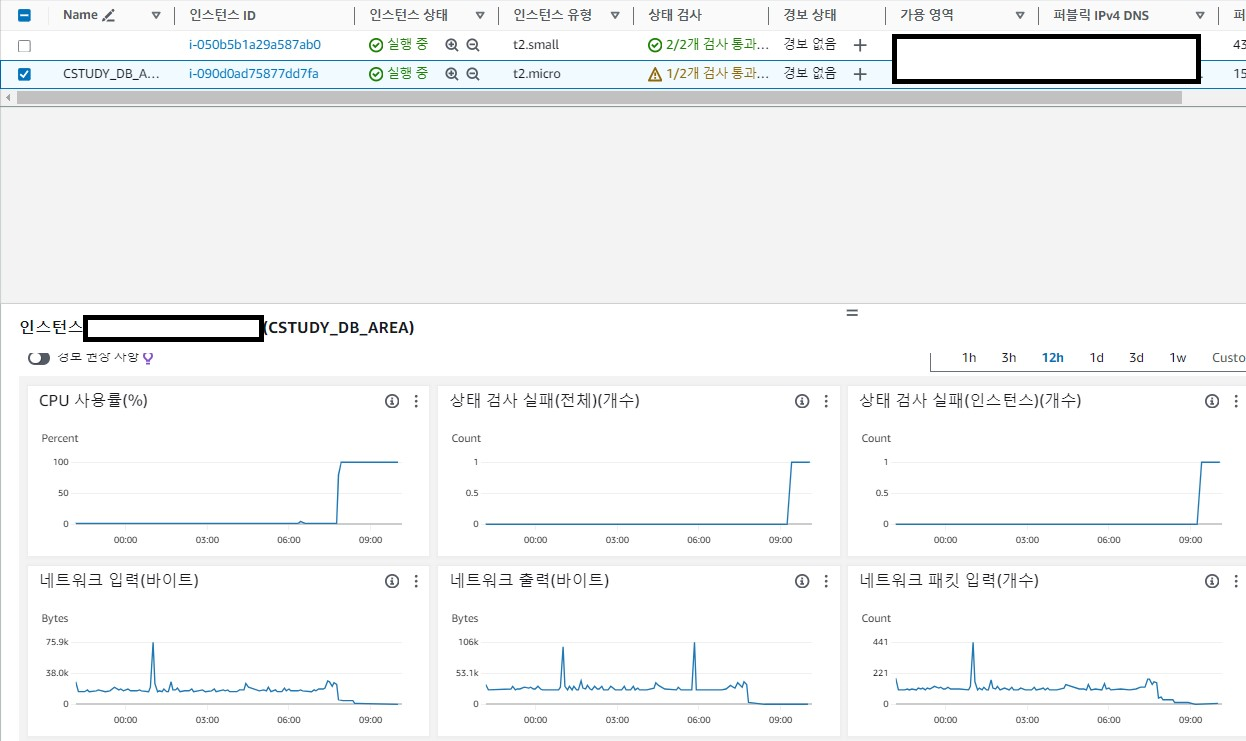
해당 EC2는 Micro로 설정하고 mysql, redis, mongodb를 설치를 하였습니다. 그런데 일반적으로 cpu는 평균 30~40을 유지를 하여 문제가 없다고 판단을 하였지만 갑자기 100%가 되었습니다.
-
해당 문제의 원인은
Burstable performance instances의 문제라고 생각을 하였습니다. 버스트 가능 성능 인스턴스에 대한 이해가 부족으로 인하여 서버의 오류가 발생을 하였습니다. -
이번에는 문제의 원인, 해결을 하기 위한 노력, CloudWatch을 이용한 모니터링에 대하여 설명하겠습니다.
본론
1. [ 서버 오류가 발생한 이유 ]
EC2 버스트
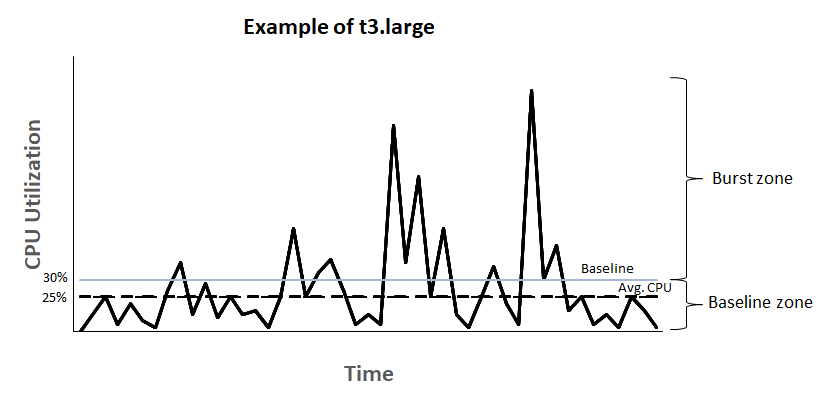
- 버스트란 주로 EC2 인턴스 유형에서 사용되는 용어입니다. 버스트 가능한 인스턴스는 일시적으로 추가 리소스를 얻을 수 있는 인스턴스를 의미합니다. 즉. 인스턴스가 특별한 작업을 처리하기 위해 더 많은 리소스가 필요한 경우 유용합니다.
-
서버를 운영하면 CPU가 갑자기 올라가는 버스트 현상을 볼 수 있다. 여기서 문제는 버스트 존만큼 CPU 사양을 높이게 되면 서버의 비용이 증가하고 평균 CPU 사용 범위로 지정을 하면 버스트 현상이 발생을 하였을 때 서버가 죽을 수 있는 문제가 있다.
-
이걸 해결하기 위해 버스트 가능 인스턴스의 개념을 나왔다.
-
EC2의 버스트 가능 인스턴스는 기본 CPU 사용율을 유지한다. 만약 많은 사용이 필요할 경우에 크레딧을 소모하여 문제를 해결하게 만들었습니다.
-
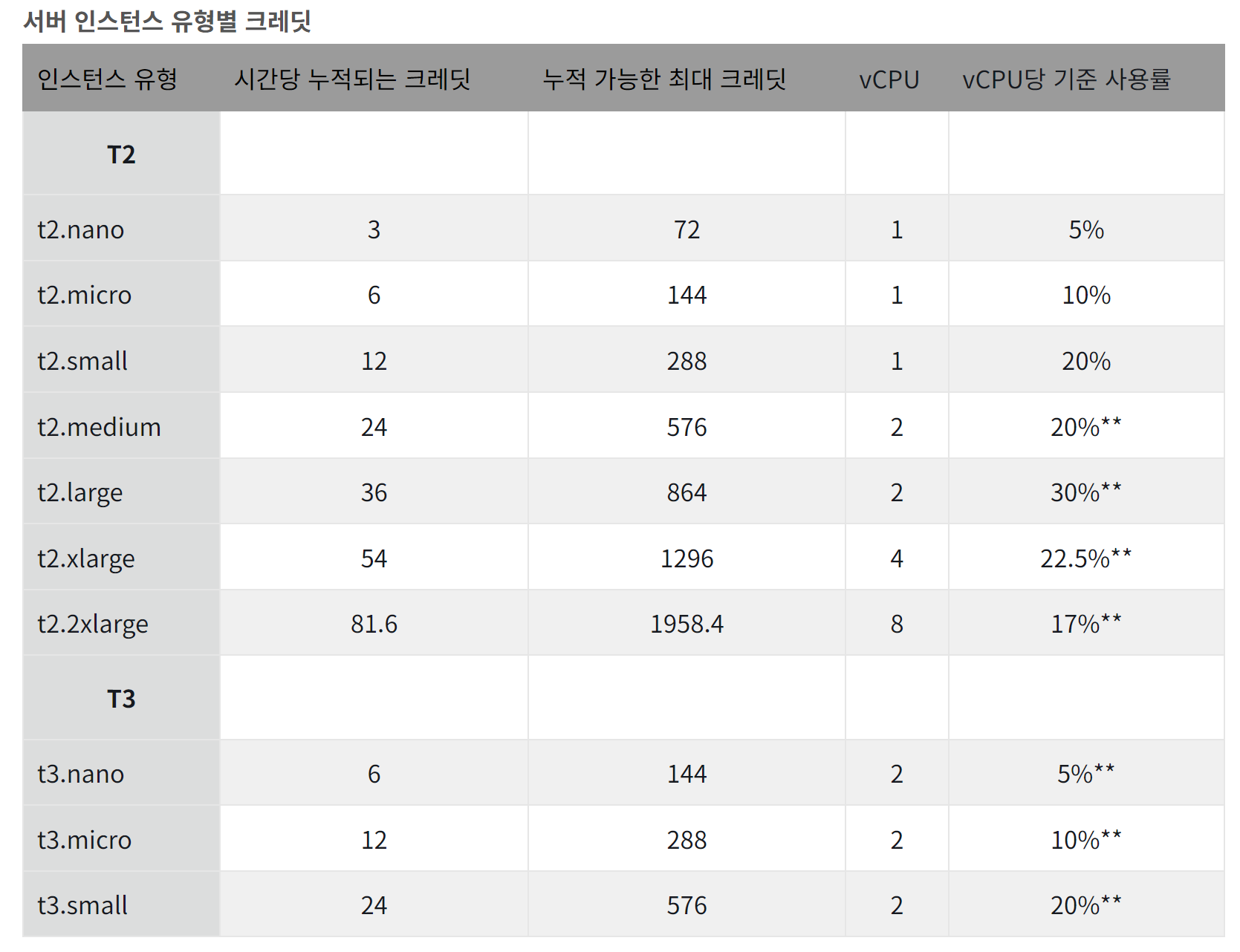
이때 인스턴스 유형에 따라 크레딧이 다르다.
-
예시로 현재 t3.small 타입의 인스턴스를 사용하게되면 AWS에서 시간당 24크레딧을 발급해준다. 그렇게 계속 누적되다가 일정 시간에 20%가 넘는 CPU 사용율이 발생할 경우 20% 넘었던 구간의 시간(ms)을 기준으로 크레딧을 일정량 소모하게 된다. 그리고 발급되고 있는 크레딧을 계속 누적되는 것이 아니라 특정 양만큼만 누적이 되고 더이상 누적이 안되기 때문에 크레딧 사용을 주의해야한다. 예시로 t3.small은 576의 크레딧만 누적할 수 있다. 그 이상 발급이 된 크레딧은 버려지게 된다.
-
여기서 조심해야 되는 부분은 공급보다 수요가 많아서 크레딧을 전부 사용하면 성능적으로 제약이 걸려서 서버의 장애를 일으킬 수 있다.
2. [ 문제를 해결하기 위하여 생각한 부분 ]
1. 메모리 스왑
-
메모리 스왑 (Memory Swap): 메모리 스왑은 시스템이 현재 사용하지 않는 메모리 페이지를 디스크의 스왑 공간에 저장하고, 필요한 경우에 다시 읽어와서 사용하는 메커니즘입니다. 이는 물리적인 RAM이 부족할 때 시스템의 성능을 유지하기 위해 사용됩니다.
-
메모리 스왑을 하는 이유
-
물리적 메모리 부족 : 현재 실행 중인 프로세스들이 사용하는 메모리 양이 물리적인 RAM의 용량을 초과하는 경우, 스왑을 사용하여 디스크의 공간을 활용해 추가 메모리를 확보할 수 있다.
-
프로세스 지속성 : 스왑은 메모리 부족 시 프로세스가 강제 종료되는 것을 방지하고, 시스템이 더 많은 메모리를 확보할 수 있도록 합니다.
-
유연성 : 스왑을 통해 더 많은 프로세스나 데이터를 메모리에 유지할 수 있어 시스템의 유연성이 증가합니다.
1-2. Ubuntu 20.04에서 메모리 스왑을 하는 방법
sudo dd if=/dev/zero of=/swapfile bs=128M count=32
# /dev/zero에서 128MB 크기의 블록을 32개 생성하여 /swapfile에 쓰기
sudo chmod 600 /swapfile
# /swapfile의 파일 권한을 소유자만 읽기 및 쓰기 가능하도록 변경
sudo mkswap /swapfile
# /swapfile을 스왑 파티션으로 초기화
sudo swapon /swapfile
# /swapfile을 활성화하여 스왑으로 사용
sudo swapon -s
# 현재 활성화된 스왑 파티션 목록 확인
sudo vi /etc/fstab
# /etc/fstab 파일을 편집
[ vi에 하단에 추가 ]
/swapfile swap swap defaults 0 0
# 부팅 시 자동으로 스왑을 마운트하기 위한 설정 추가
## 용량 확인
free
# 시스템의 메모리 및 스왑 사용량 확인
2. 인스턴스 스케일 업
-
서버의 오류가 발생하는 이유는 버스트의 수요와 공급이 맞지 않다고 판단하여 인스턴스를 micro -> small로 유형을 변경하여 크레딧의 수를 변경을 하였습니다.
-
기존의 유형보다 성능이 높은 small을 선택하여 cpu의 성능이 더 좋아졌습니다.
CPU Credit
-
정의 : AWS에서 CPU Credit은 1분동안 CPU Boost를 해줄 수 있는 갯수를 의미합니다.
-
크래딧은 1개의 CPU의 사용률이 100%가 되면, CPU는 BOOST 상태가 되며 1분에 1개의 크래딧을 소모를 합니다.
-
이때 크래딧이 없으면 성능 저하로 이어집니다.
-
이 부분은 마나와 비슷합니다. 적이 없을 때 적은 마나를 사용하기 때문에 마나가 충전이 되고, 적이 많으면 많은 마법을 사용하기 때문에 마나를 사용합니다. 크래딧도 똑같습니다. 트래픽을 적으로 생각하면 이해가 쉬울 거 같습니다.
3. Stop and Start
-
간단하게 인스턴스를 정지 & 시작을 의미합니다. (재실행 X) 이러한 방식으로 처리하면 크래딧이 재충전이 되기 때문에 문제를 해결할 수 있습니다.
-
간단하게 컴퓨터를 재부팅으로 생각하면 될거 같습니다.
-
현재 문제점에서 Stop and Start 방식을 사용을 하였지만 이 방식은 개발자, 관리자가 수동으로 해야되는 문제가 발생을 합니다.
-
또한 CPU가 증가를 하여 서버가 터지기 이전에 해야되기 때문에 지속적으로 모니터링을 해야됩니다.
-
그래서 CloudWatch를 통해 일정 CPU가 되었을 때 SLACK에 알림을 발송하는 방식으로 모니터링을 대체를 하
겠습니다.
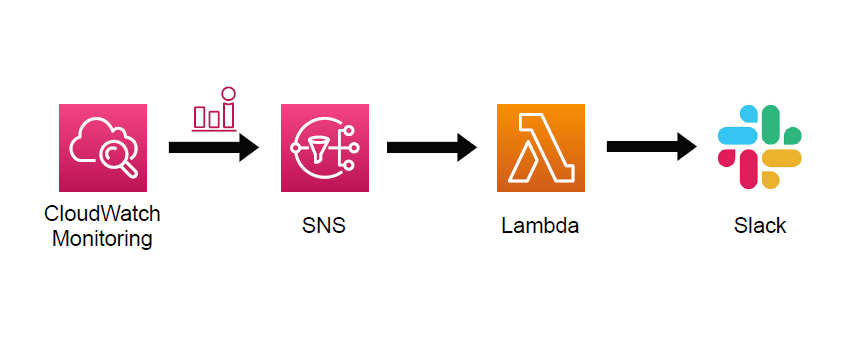
3. [ CloudWatch, Lambda의 경보를 Slack 알림 ]
왜 CloudWatch를 사용을 하였는지?
- 먼저 CloudWatch에서 경보를 등록하는 이유는 서버에 문제가 발생하기 이전에 문제를 대응할 수 있게 하기 위함입니다.
- 현재 프로젝트에서는 cpu의 사용률이 특정 기준을 넘는 문제를 해결하기 위해 선택을 하였습니다.
- 또한 이것을 알림으로 지속적인 모니터링이 없이 자동화를 하기 위하여 알림 방식을 채택을 하였습니다.
1. Simple Notification Service (SNS) 접속
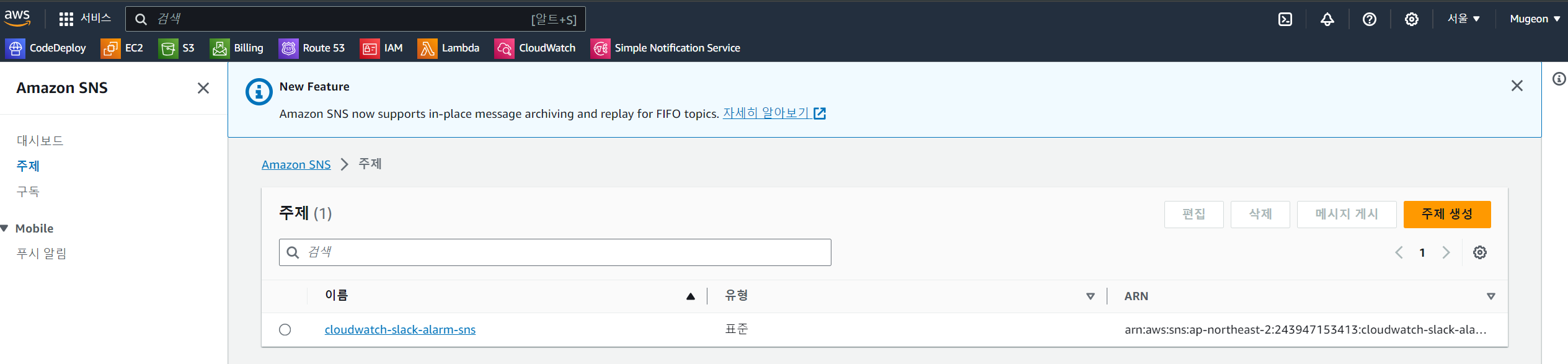
- 검색창에 Simple Notification Service을 입력을 하고 사이드 바에 주제 이후에 주제 생성을 클릭을 합니다.
2. 주제 생성
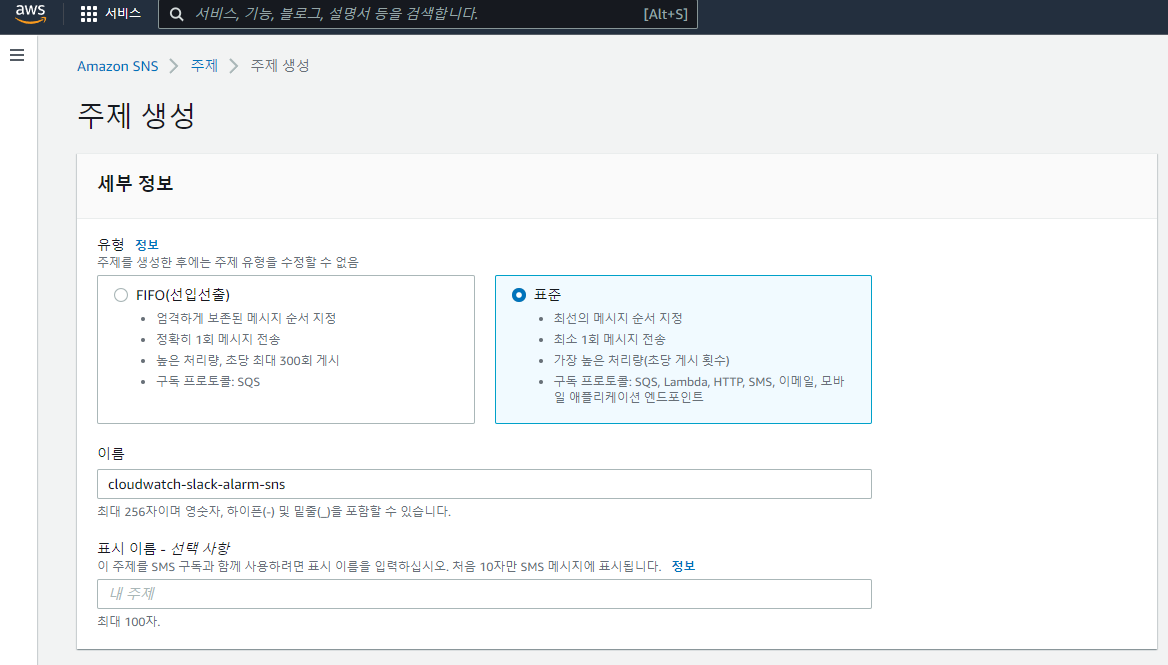
- 유형은 표준을 선택을 하고 이름을 입력을 합니다.
- 이후 주제 생성 버튼을 클릭하여 주제를 생성을 합니다.
3. CloudWatch 생성 (경보)

- 검색창에 Cloudwatch를 선택을 하고 이후 경보 생성을 누릅니다.
4. 지표 선택
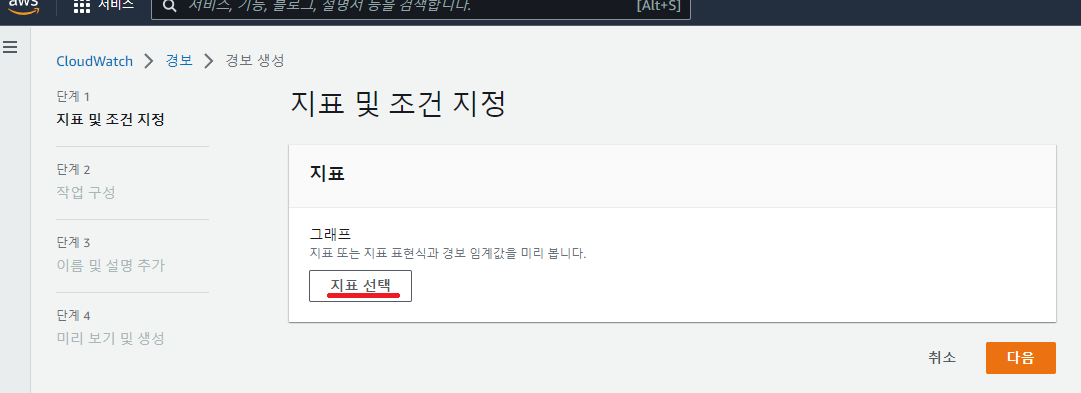
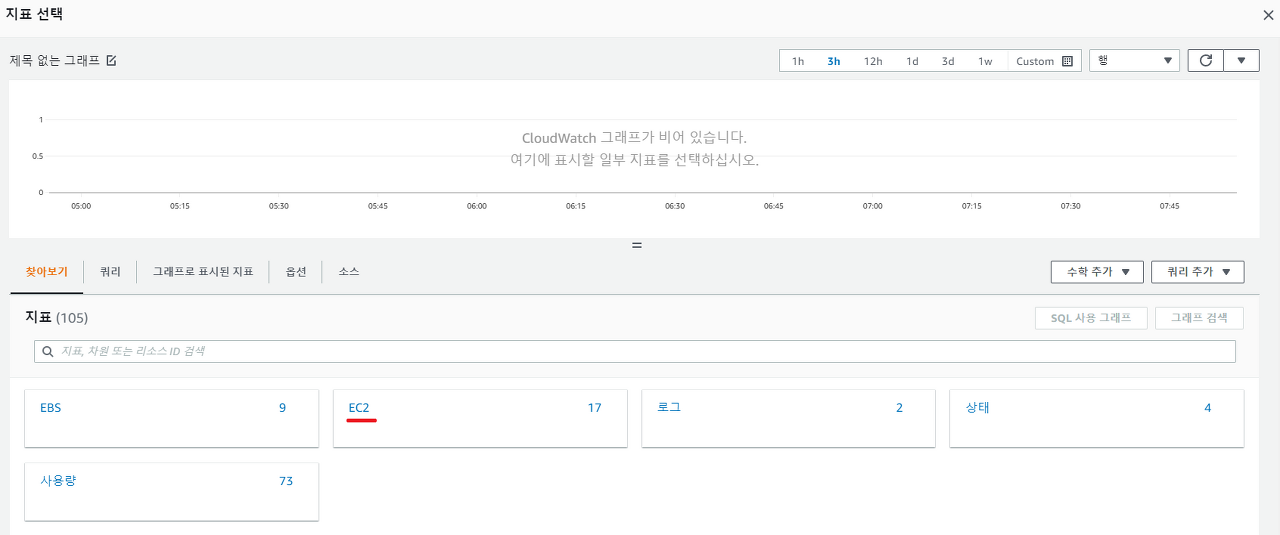
- 생성을 누르면 지표 및 조건 지정 페이지가 나옵니다. 이후 지표 선택을 누릅니다.
- 이후 EC2를 선택하고 이후 인스턴스별 지표를 선택을 합니다.
- 마지막으로 원하는 인스턴스의 CPUUtilization을 선택한 뒤 오른쪽 아래에 있는 지표 선택을 클릭해줍니다.
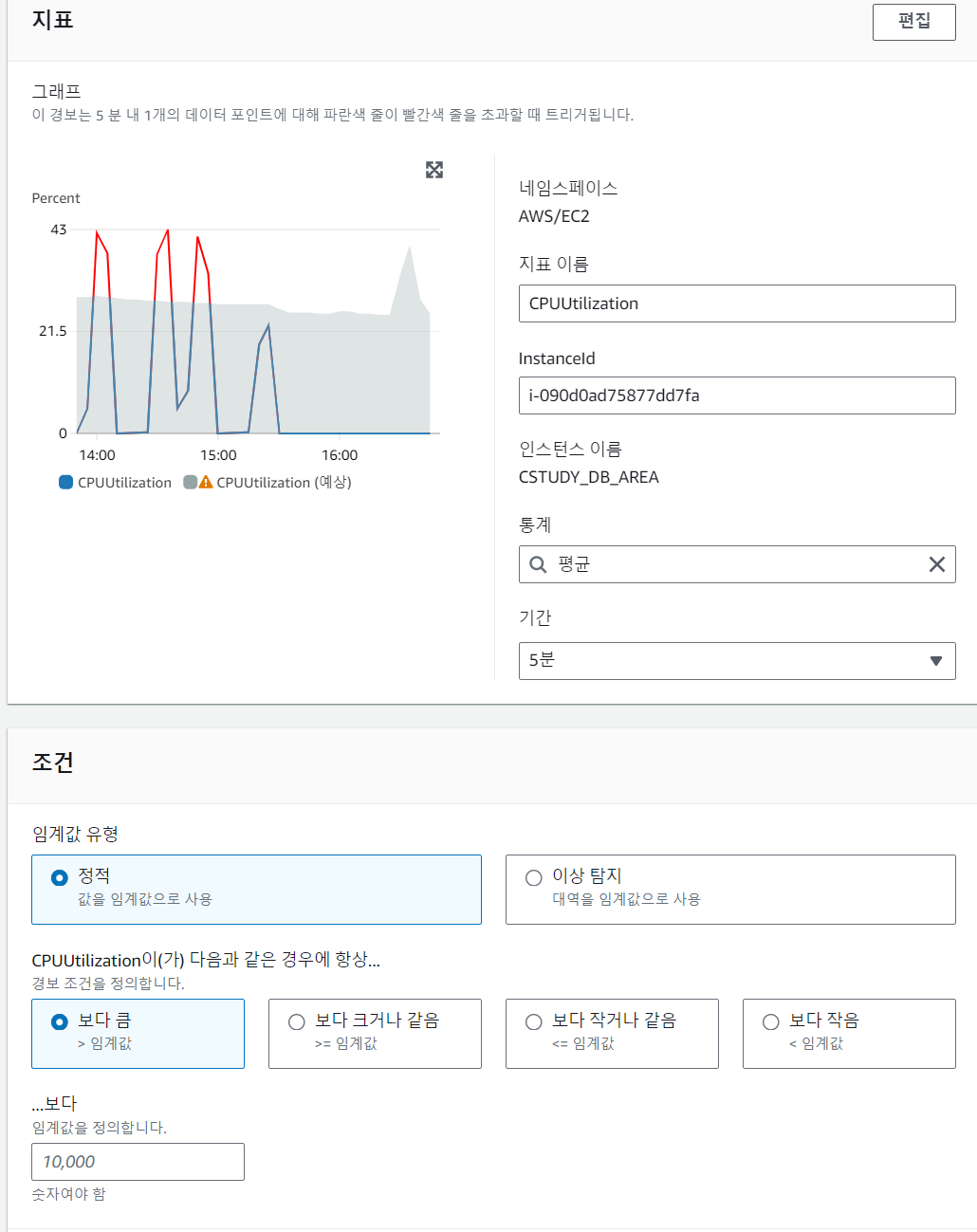
- 이후 지표에서 위에 조건을 그대로 설정하고 조건 부분에서 임계값 유형에 정적을 선택하고 보다 큼을 설정을 합니다. 이후 임계값에 원하는 cpu 조건을 입력을 합니다. 저는 70을 설정하여 CPU가 70프로 이상 올라가면 알림을 받을 수 있게 설정을 하였습니다.
5. 작업 구성
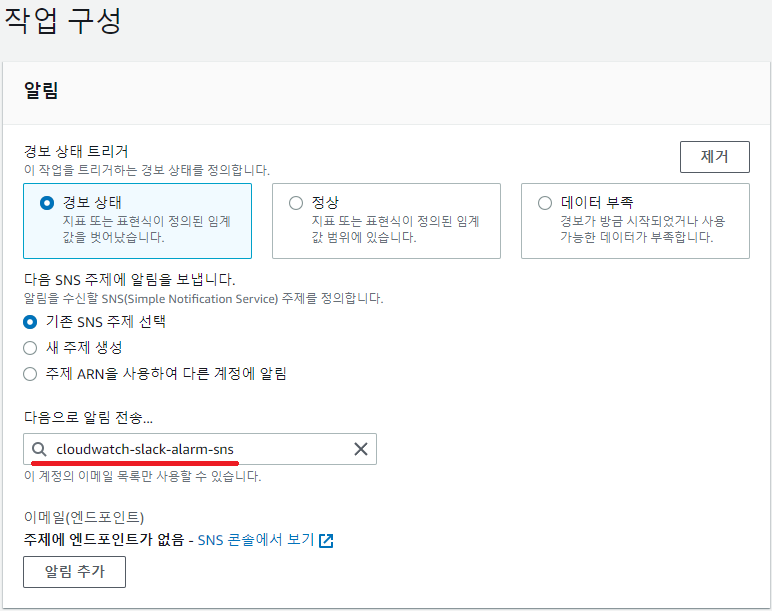
- 이후 경보 상태를 선택하고 기존의 SNS 주제 선택을 유지합니다. 이후 알림 발송 부분에 이전에 만들었던 SNS를 선택을 합니다.
- 알림 정보외에 아래에 있는 부가적인 정보들은 필요하시다면 추가 설정해주시고 다음을 클릭해주시면 됩니다.
6. Slack 연동하기 (webhook)
- 처음에 slack에 접속하여 원하는 채널을 하나 생성하고 상단 채널의 이름을 누릅니다. 누르면 설정 부분으로 넘어갑이다. 이후 통합을 눌러 앱 -> 앱 추가를 누릅니다.
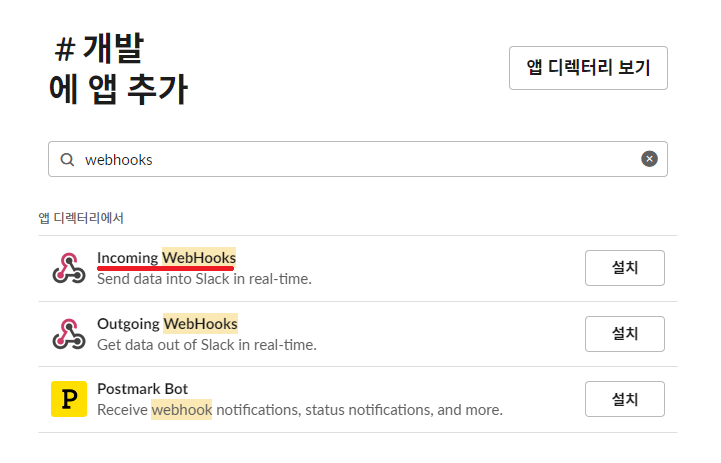
- 이후 webhooks를 검색창에 입력하면 다음과 같이 나오는데 여기에 보이는 Incoming Webhooks를 설치해줍니다.
- 페이지가 넘어가면 아래쪽에 적용을 원하는 채널을 선택하고 수신 웹후크 통합 앱 추가를 선택하고 url을 확인을 할 수 있습니다.
URL은 람다에서 변수로 사용을 하기 때문에 다른 파일에 저장
7. Lambda 함수 생성

- 이후 AWS 사이트의 검색창에 람다 -> 함수 -> 함수 생성을 누릅니다.
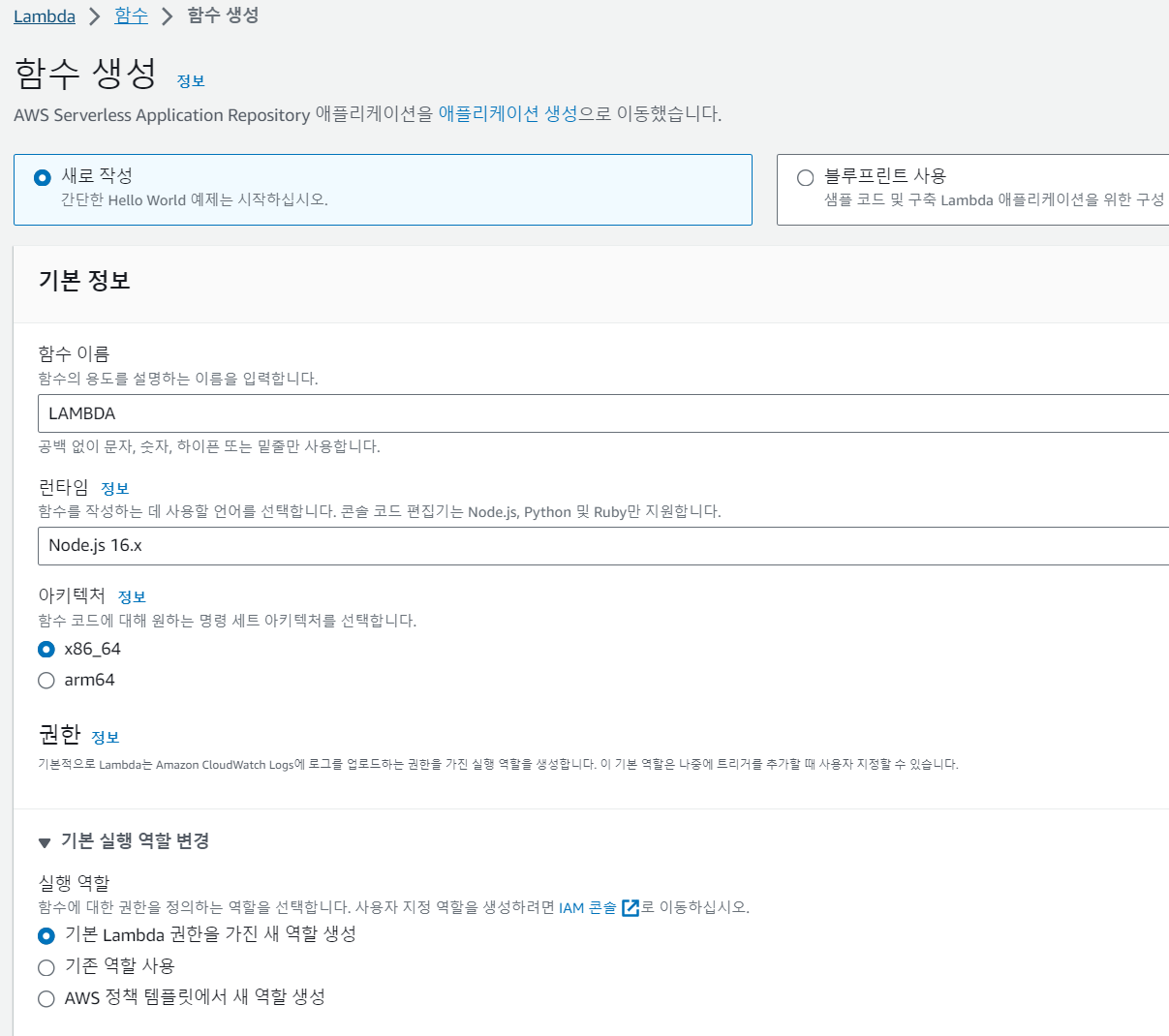
- 이후 새로 작성을 누르며 함수 이름 -> 런타임은 노드 16을 선택하고 -> 기본 람다 권한을 선택을 합니다.
- 람다가 생성이 되면 코드를 선택을 합니다. 이후 index.js에 다음과 같은 코드를 입력을 합니다.
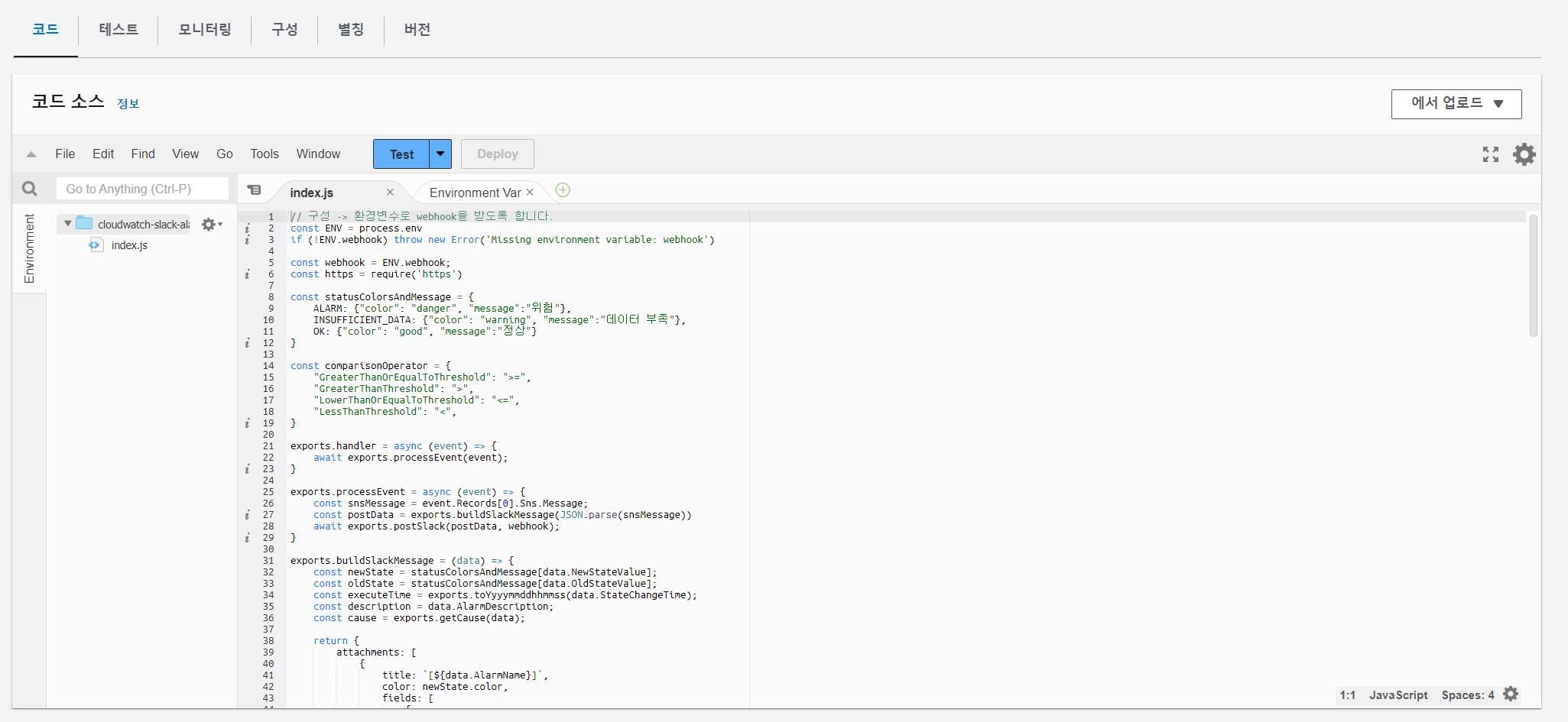
// 구성 -> 환경변수로 webhook을 받도록 합니다.
const ENV = process.env
if (!ENV.webhook) throw new Error('Missing environment variable: webhook')
const webhook = ENV.webhook;
const https = require('https')
const statusColorsAndMessage = {
ALARM: {"color": "danger", "message":"위험"},
INSUFFICIENT_DATA: {"color": "warning", "message":"데이터 부족"},
OK: {"color": "good", "message":"정상"}
}
const comparisonOperator = {
"GreaterThanOrEqualToThreshold": ">=",
"GreaterThanThreshold": ">",
"LowerThanOrEqualToThreshold": "<=",
"LessThanThreshold": "<",
}
exports.handler = async (event) => {
await exports.processEvent(event);
}
exports.processEvent = async (event) => {
const snsMessage = event.Records[0].Sns.Message;
const postData = exports.buildSlackMessage(JSON.parse(snsMessage))
await exports.postSlack(postData, webhook);
}
exports.buildSlackMessage = (data) => {
const newState = statusColorsAndMessage[data.NewStateValue];
const oldState = statusColorsAndMessage[data.OldStateValue];
const executeTime = exports.toYyyymmddhhmmss(data.StateChangeTime);
const description = data.AlarmDescription;
const cause = exports.getCause(data);
return {
attachments: [
{
title: `[${data.AlarmName}]`,
color: newState.color,
fields: [
{
title: '언제',
value: executeTime
},
{
title: '설명',
value: description
},
{
title: '원인',
value: cause
},
{
title: '이전 상태',
value: oldState.message,
short: true
},
{
title: '현재 상태',
value: `*${newState.message}*`,
short: true
},
{
title: '바로가기',
value: exports.createLink(data)
}
]
}
]
}
}
// CloudWatch 알람 바로 가기 링크
exports.createLink = (data) => {
return `https://console.aws.amazon.com/cloudwatch/home?region=${exports.exportRegionCode(data.AlarmArn)}#alarm:alarmFilter=ANY;name=${encodeURIComponent(data.AlarmName)}`;
}
exports.exportRegionCode = (arn) => {
return arn.replace("arn:aws:cloudwatch:", "").split(":")[0];
}
exports.getCause = (data) => {
const trigger = data.Trigger;
const evaluationPeriods = trigger.EvaluationPeriods;
const minutes = Math.floor(trigger.Period / 60);
if(data.Trigger.Metrics) {
return exports.buildAnomalyDetectionBand(data, evaluationPeriods, minutes);
}
return exports.buildThresholdMessage(data, evaluationPeriods, minutes);
}
// 이상 지표 중 Band를 벗어나는 경우
exports.buildAnomalyDetectionBand = (data, evaluationPeriods, minutes) => {
const metrics = data.Trigger.Metrics;
const metric = metrics.find(metric => metric.Id === 'm1').MetricStat.Metric.MetricName;
const expression = metrics.find(metric => metric.Id === 'ad1').Expression;
const width = expression.split(',')[1].replace(')', '').trim();
return `${evaluationPeriods * minutes} 분 동안 ${evaluationPeriods} 회 ${metric} 지표가 범위(약 ${width}배)를 벗어났습니다.`;
}
// 이상 지표 중 Threshold 벗어나는 경우
exports.buildThresholdMessage = (data, evaluationPeriods, minutes) => {
const trigger = data.Trigger;
const threshold = trigger.Threshold;
const metric = trigger.MetricName;
const operator = comparisonOperator[trigger.ComparisonOperator];
return `${evaluationPeriods * minutes} 분 동안 ${evaluationPeriods} 회 ${metric} ${operator} ${threshold}`;
}
// 타임존 UTC -> KST
exports.toYyyymmddhhmmss = (timeString) => {
if(!timeString){
return '';
}
const kstDate = new Date(new Date(timeString).getTime() + 32400000);
function pad2(n) { return n < 10 ? '0' + n : n }
return kstDate.getFullYear().toString()
+ '-'+ pad2(kstDate.getMonth() + 1)
+ '-'+ pad2(kstDate.getDate())
+ ' '+ pad2(kstDate.getHours())
+ ':'+ pad2(kstDate.getMinutes())
+ ':'+ pad2(kstDate.getSeconds());
}
exports.postSlack = async (message, slackUrl) => {
return await request(exports.options(slackUrl), message);
}
exports.options = (slackUrl) => {
const {host, pathname} = new URL(slackUrl);
return {
hostname: host,
path: pathname,
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
};
}
function request(options, data) {
return new Promise((resolve, reject) => {
const req = https.request(options, (res) => {
res.setEncoding('utf8');
let responseBody = '';
res.on('data', (chunk) => {
responseBody += chunk;
});
res.on('end', () => {
resolve(responseBody);
});
});
req.on('error', (err) => {
reject(err);
});
req.write(JSON.stringify(data));
req.end();
});
}8. 환경 변수 추가
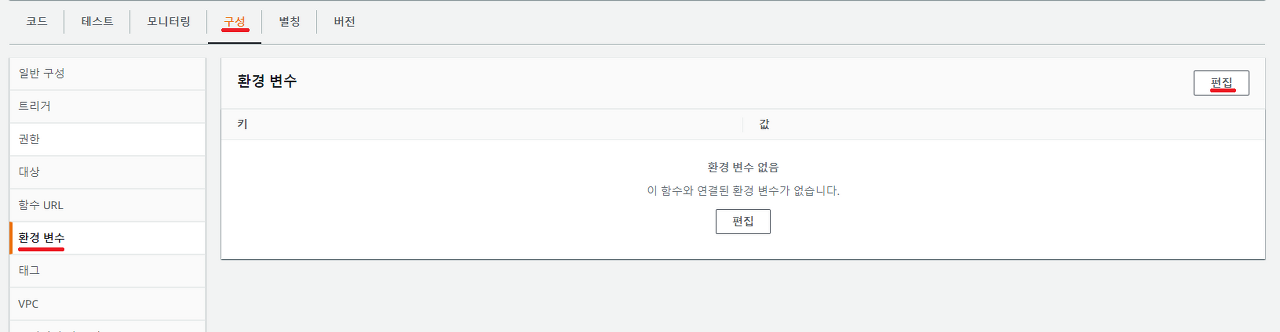
- 상단의 구성 탭 → 좌측 환경 변수 메뉴에서 편집 버튼을 클릭해줍니다. 그리고 다음과 같이 키에는 webhook, 값에는 위에서 만든 웹후크 url을 입력해준 뒤 아래 저장 버튼을 클릭해줍니다.
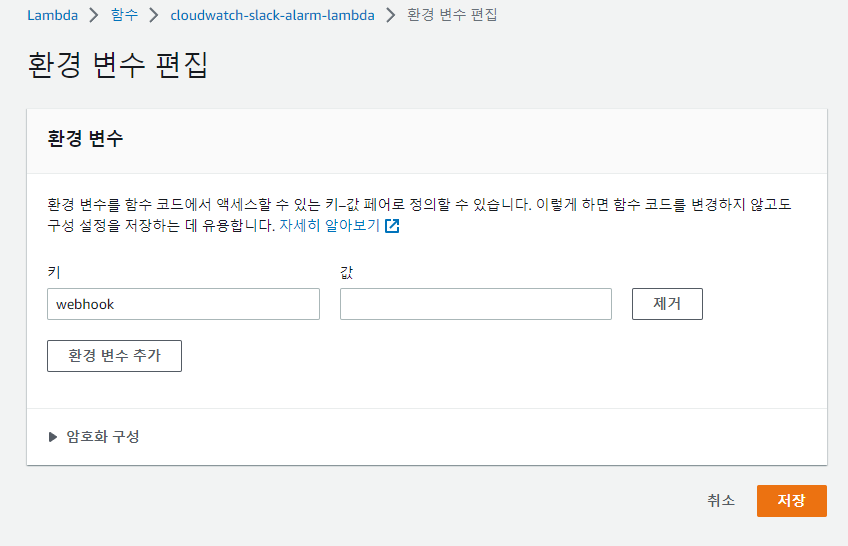
9. SNS 트리거 추가
- 상단에 트리거 추가를 클릭해줍니다. 트리거 대상으로 sns를 선택해주시고 sns 주제로는 위에서 만들어둔 sns 주제를 선택한 뒤 추가 버튼을 클릭해주시면 됩니다.
10. 테스트
- 해당 EC2에 부화를 만들어 CPU를 증가시켜 정상적으로 SLACK 알림을 발송하는지 확인을 하겠습니다.
sudo apt-get install stress
stress --cpu 1 --timeout 600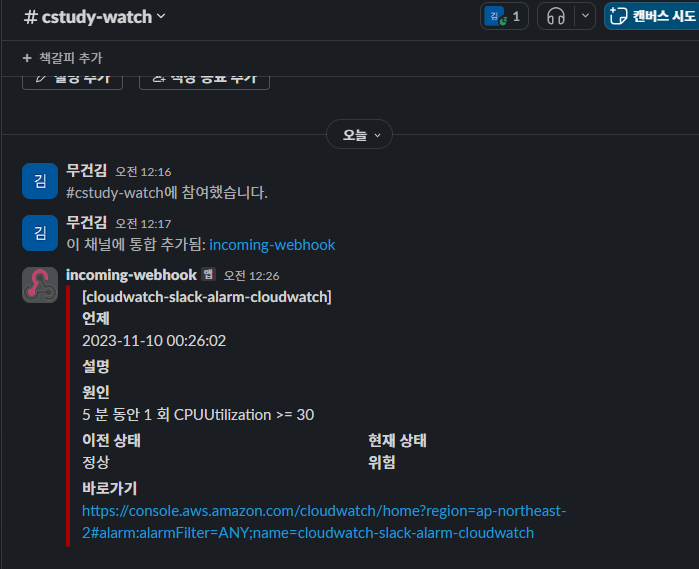
- 정상적으로 알림을 받을 수 있었습니다.
결론
- 현재 CPU가 100%가 되어서 서버의 오류가 발생하는 문제를 해결하기 위하여 STOP AND START 방식을 선택을 하였습니다.
- 이때 지속적인 모니터링의 문제점을 제거하기 위하여 알림 발송을 하기 위하여 Cloudwatch를 사용을 하여 자동화를 하였습니다.
- 서비스의 트래픽이 몰려서 CPU가 증가를 하였을 때 문제를 해결할 수 있지만 STOP AND START 방식에 대한 불편함을 아직도 남아있습니다.
[ 개선을 생각하는 부분 ]
- STOP AND START 방식을 유지하기 보다는 람다를 사용하여 Cloudwatch를 통해서 알림을 보낼 때 람다 트리거를 사용하여 서버를 자동적으로 stop and start를 하도록 명령을 하여 현재 문제점을 개선을 해야된다고 생각합니다.
