
서론
-
회사에서 이번에 온프로미스에서 클라우드로 전환을 생각하면서 AWS 오프라인 세미나 참석 기회를 얻어서 AWS Korea에 방문하여 간단한 세미나를 참석을 했습니다.
-
각 날짜마다 다른 컨셉의 강의가 진행이 되었는데 저는 AWS Aurora를 선택을 했습니다. ( 다른 내용은 너무 어려워서 선택하지 못했습니다. )
-
세미나는 10~ 18시까지 진행을 하였고, 2~3시간 실습이 있어서 재미있게 세미나를 즐기고 왔습니다. 일단 이번에 포스팅 내용은 같이 못같던 팀원에게 공유, 세미나에서 이해하지 못한 내용을 간단하게 정리하기 위해서 작성을 하였습니다.
본론
1. AWS Aurora Overview
1.1 Amazon Aurora
- 관리형 서비스로 제공되는 오픈 소스 가격의 엔터프라이즈 데이터베이스
특징
1. 상용 데이터베이스의 속도 및 가용성
2. 오픈 소스 데이터베이스의 단순성과 비용 효율성
3. MySQL, PostSQL과의 호환성
4. 사용한 만큼 지불하는 종량제 가격
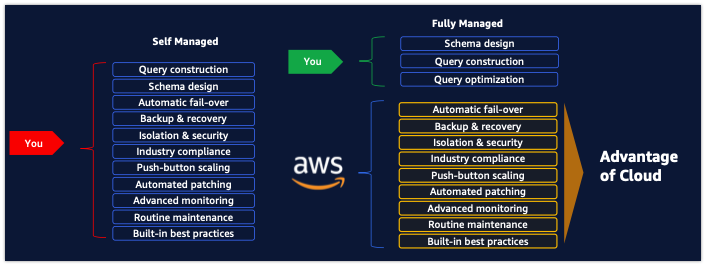
1.2 기존의 온프로미스 데이터베이스에서 클라우드로 변경을 하면 이점
-
기존에 온프로미스에서는 db의 운영하면서 많은 관리가 필요합니다.
- 예를 들어서 fail over 또는 보안, 백업, 많은 부화를 스케일업
-
온프로미스에서 클라우드로 변경을 하였을 때 운영적인 측면을 클라우드가 대체하고 스키마, 쿼리만 신경을 쓰면된다.
- AWS, Lambda, S3, IAM, Cloudwatch등 클라우드 에코시스템을 활용이 가능하다.
이러한 이점보다 제일 중요한 것은 Auora는 빠르다라고 말한다. 세미나에서 말하기로 다른 유사한 기능을 하는 DB는 일반적으로 1.5~2배정도 MySQL에 비해서 빠르다고 하지만 Auora는 최대 5배 빠르다고 말하였다.
1.3 Aurora Architecture (Decoupled Computing & Storage)
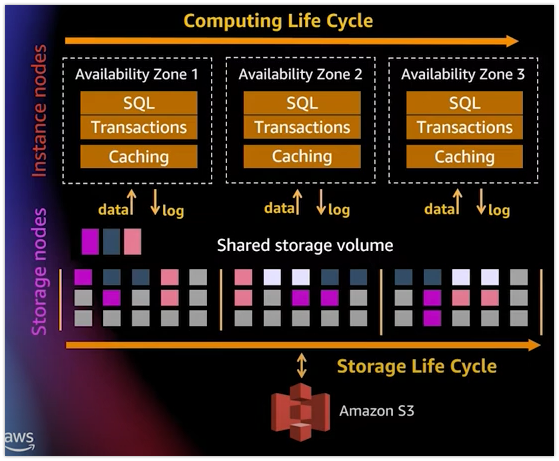
-
연산을 위한
computing 영역과 스토리지 영역은 서로 Life Cycle이 다르기 때문에서로 영향을 주면 빠르게 변화에 대응하기 힘들다.- 데이터가 많아져 스토리지 영역을 확장할 때 Computing 영역의 down time으로 이것을 방해하면 안된다. 두 개가 서로 분리되어져 있기 때문에 각 기능에만 포커싱하여 가용성과 확장성을 보장한다.
-
Aurora의 Computing zone은 AZ을 기반으로 Master-Relica구조를 통해 장애 및 확장성에 대응한다. 최대 15개 Replica을 통해 확장성을 확보한다.
1.3.2 스토리지 영역

- Aurora의 스토리지는
공유 분산 스토리지 볼륨으로 구성되어져 있다. 이는 여러 개의 스토리지 노드가 하나의 스토리지 볼륨이 되어서 각 컴퓨팅의 노드가 된다.- 각 노드가 분리되어져 있기 때문에 스토리지에서 발생하는 I/O 작업이 분산되어 병렬처리가 된다.
1.3.3 6-way copy
- 각각의 스토리지 노드에 각각의 데이터가 위치 되어져 있기 때문에 데이터의 가용성 확보 ( 각 스토리지에 보면 빨간색 볼륨이 2개씩 * 3가 있다. )
- 이러한 volume의 집합을
protection Group이라고 말한다.
- 이러한 volume의 집합을
- 물리적으로 분리된 3가지 노드에 총 6개의 복제본을 통해 데이터의 가용성 확보는 스토리지 내에서 수행한다.
- 데이터의 I/O는 projectio Group에 있는 6개의 복제본을 이용 Quorum 방식을 통하여 안전성을 확보한다.
- 읽기의 경우에는 3개, 쓰기의 경우에는 4개의 블럭이 필요하다.
- 데이터의 I/O는 projectio Group에 있는 6개의 복제본을 이용 Quorum 방식을 통하여 안전성을 확보한다.
예를 들어서 하나의 AZ에 문제가 생겼다고 가정하겠다.
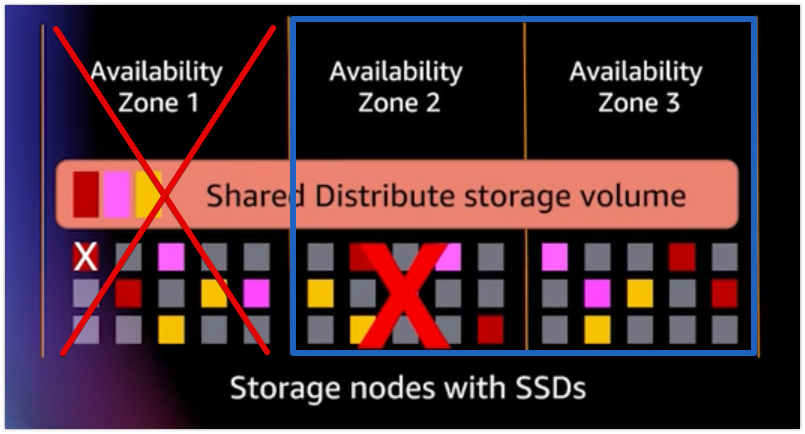
-
이렇게 되면 2개의 블록을 사용할 수 없다. 이 경우에는 읽기, 쓰기를 사용하기에 문제가 없다. ( 읽기의 경우에는 3개, 쓰기의 경우에는 4개가 필요하기 때문 )
-
하지만 총 2개의 A/Z에 문제가 생겼다고 가정하겠다.
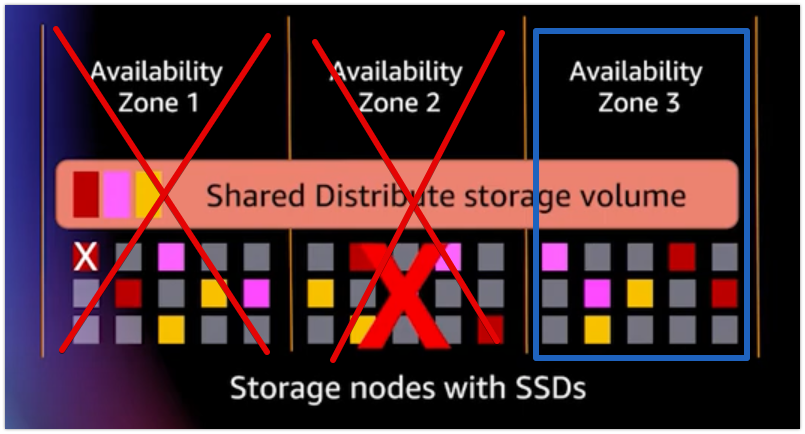
- 이렇게 된다면 읽기는 가능하지만 쓰기의 경우에는 불가능하게 된다.
- 이런 방식을 통하여 데이터의 유실을 방지하고 안전성을 확보할 수 있다.
Aurora 분산스토리지 제공
- redo log 처리, 내결함성, 자가 복구 스토리지, 빠른 데이터베이스 복제 , db backtrack, 스냅샷, 확장성등 스토리지 처리와 관련된 행동은 Decoupled이 되어져 있기 때문에 트랜잭션, SQL 쿼리에 영향 없이 처리할 수 있다.
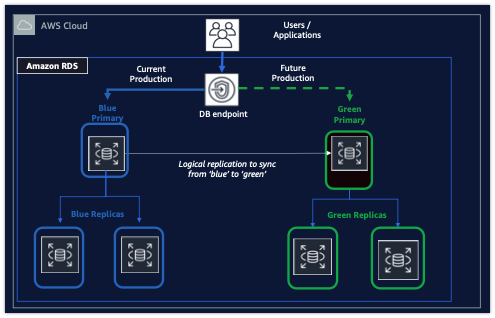
1.4 Blue/Green 배포
 |  |
|---|
-
배포를 해보면 blue, green에 대해서 한번 쯤 보았을 것이다. 세미나에서 듣기로는 B/G 배포를 더욱 Develop한다고 들었던 것 같다.
-
Blue/Green에 대해서 간단하게 설명하면 2개의 node를 만든다. 이때 blue노드는 기존의 디비를 의미하며 green노드를 만든다. green 노드는 미러링된 복사본 즉. 미래의 프로덕션을 의미한다.
-
만약에 데이터 구조를 마이그레이션을 하게 된다면 blue에서 복제된 Green 노드를 만들어 데이터를 마이그레이션을 하고 테스트를 수행을 한다. 이때 기존의 blue노드 (프로덕션 디비)는 정상적으로 운영되기 때문에 운영에는 상관없고 green에서 QA를 검증하고 green으로 변경한다면 안전성 높은 배포를 수행할 수 있다.
1.4.2 Blue/Green 과정
-
현재 운영 중인 DB 클러스터(예: mycluster-old1)가 있다고 가정합니다. 이 클러스터는 Aurora MySQL 2.10.2 (5.7) 버전을 사용하고 있습니다.
-
create-blue-green-deployment 명령을 사용하여 새로운 Target DB 클러스터(예: mycluster-green-x1234)를 생성합니다. 이 클러스터는 소스 클러스터와 동일한 버전 및 구성을 가집니다.
aws rds create-blue-green-deployment \
--source-db-cluster-identifier mycluster-old1 \
--target-db-cluster-identifier mycluster-green-x1234-
Target 클러스터가 생성되면 소스 클러스터의 데이터가 자동으로 복제됩니다. 이 과정에서 Target 클러스터는 읽기 전용(RO) 모드로 유지됩니다.
-
애플리케이션 트래픽을 새 Target 클러스터로 전환하기 위해 switchover-blue-green-deployment 명령을 사용합니다. 이 명령은 DB 클러스터 엔드포인트를 새 클러스터로 업데이트하고, 새 클러스터를 읽기/쓰기(RW) 모드로 전환합니다.
aws rds switchover-blue-green-deployment \
--blue-green-deployment-identifier mycluster-green-x1234-
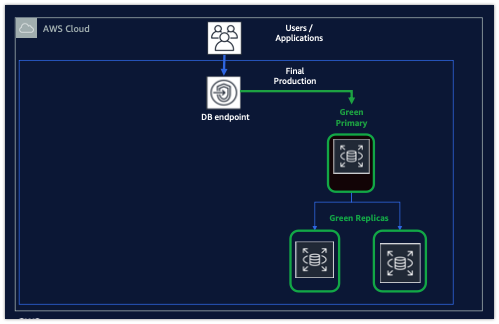
Switchover가 완료되면 애플리케이션 트래픽이 새 클러스터로 라우팅됩니다. 이제 mycluster-green-x1234가 프로덕션 트래픽을 처리하게 됩니다.
-
필요에 따라 이전 클러스터(mycluster-old1)를 삭제할 수 있습니다. 이는 delete-blue-green-deployment 명령을 사용하여 수행할 수 있습니다.
aws rds delete-blue-green-deployment \
--blue-green-deployment-identifier mycluster-old12. 백업 & 운영
2.1 Automated backups ( Point in time )
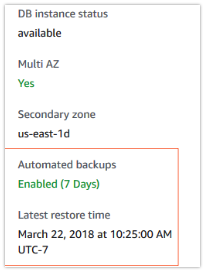
- 전체 인스턴스의 예약된 일일 볼륨을 백업한다.
아카이브 데이터베이스 변경 로그, 최대 보존 기간은 35일이다.
데이터베이스 성능에 미치는 영향을 최소화하며 다중 AZ실행 시 standby에서 수행한다.
2.2 snapshots

- 스냅샷을 만드는 방식은 증분 백업과 비슷하다. aws ebs -> 볼륨을 스냅샷을 만든다. 처음에는 전체를 백업하지만 이후에는 증분 백업을 수행하기 때문에 더 비용이 효율적이고, 더 빠르다.
2.3 Log Backup
- 소산 백업 및 각종 이유로 여러가지 log를 따로 보관해야 하는 경우 존재 다운로드 가능한 log 목록
- audit log(감사): MySQL에서 실행되는 쿼리와 사용자 활동을 추적하고 기록하는 로그입니다.
- slow log(느린 쿼리 로그):long_query_time 변수로 지정된 시간 이상 실행되는 쿼리를 기록합니다.
- error log(오류): MySQL 서버에서 발생하는 오류, 경고 및 중요한 이벤트를 기록하는 로그입니다.
- binlog(바이너리): 데이터 변경 이벤트(INSERT, UPDATE, DELETE 등)를 순서대로 기록하는 로그입니다.
2.3.1 console download
- https://console.aws.amazon.com/rds/에서AmazonRDS콘솔을엽니다.
- 탐색창에서데이터베이스를선택합니다.
- 보고자하는로그파일을보유한DB인스턴스의이름을선택합니다.
- 로그및이벤트탭을선택합니다.
- 아래로스크롤하여[Logs]섹션을찾습니다.
- 로그섹션에서다운로드할로그옆에있는버튼을선택한다음다운로드를선택합니다.
- 제공된링크에대한컨텍스트(마우스오른쪽클릭)메뉴를열고나서[SaveLinkAs]를선택합니다.
로그 파일을 저장할 위치를 입력한 다음 저장을 선택합니다
2.3.2 log backup – binlog download
mysqlbinlog 유틸리티를 사용하여 RDS for MySQL DB 인스턴스에서 이진 로그를 다운로드하거나 스트리밍 가능 이진 로그를 로컬 컴퓨터로 다운로드하면 mysql 유틸리티를 사용하여 로그 재생과 같은 작업을 수행 가능
Amazon RDS 인스턴스에 대해 mysqlbinlog 유틸리티를 실행하려면 다음의 옵션 사용
--read-from-remote-server
- 필수
--host – 인스턴스의 엔드포인트에서 DNS 이름
--port – 인스턴스에서 사용되는 포트
--user - REPLICATION SLAVE 권한이 부여된 MySQL 사용자
--password – MySQL 사용자의 암호. 또는 유틸리티에서 암호 입력을 요구하는 메시지가 표시되도록 암호 값을 생략 --raw - 파일을 이진 형식으로 다운로드
--result-file - 원시 출력을 수신할 로컬 파일
--stop-never - 이진 로그 파일 스트리밍
--verbose - ROW binlog 형식을 사용할 경우 행 이벤트를 유사 SQL 문으로 조회 가능
--verbose 옵션에 대한 자세한 내용은 MySQL 설명서의 mysqlbinlog 행 이벤트 표시 참조RDS는 보통 최대한 빨리 이진 로그를 제거하지만, mysqlbinlog가 액세스할 수 있도록 인스턴스에서 이진 파일을 여전히 사용할 수 있어야 합니다. RDS가 이진 파일을 보존할 시간을 지정하려면 mysql.rds_set_configuration 저장 프로시저를 사용하고 로그를 다운로드하기에 충분한 시간으로 기간을 지정합니다.
보존 기간을 설정한 후, DB 인스턴스의 스토리지 사용량을 모니터링하여 보존된 이진 로그가 너무 많은 스토리지를 차지하지 않도록 합니다. 다음 예제에서는 보존 기간을 1일로 설정합니다.
call mysql.rds_set_configuration('binlog retention hours', 24);
운영
2.4.1 Write-Intensive Performance_insight
parameter변경은 신중하게 해야된다. 사이드이펙트의 변화를 확인해야된다.
무수히 많은 파라미터가 다 true일 수 있는데 반드시 하나씩 테스트를 거쳐 의미있는 변화가 있을 때 고민을 해야된다.
Performance_schema를 On/Off 할 때에는 재부팅 필요 Performance_insight를 On/Off 할 때에는 재부팅 불필요하다.
두 옵션 모두 on을 하는 것을 권고한다.
- Performance_schema의 사용은 추가 Memory와 성능에 영향
- Performance_schema는 여러가지 옵션이 있으며 옵션 추가 마다 Memory 사용량과 워크로드 변화
- 장애 상황과 각종 이슈에 대하여 기본적인 대응을위해서는 기본 옵션으로 사용 가능
- Deep한 이슈 분석 혹은 장애 분석을 위해서는 추가적인 옵션을 켜고 사용 가능. 예) event, memory
• innodb_max_dirty_pages_pct : default 75 / 버퍼 풀에서 더티 페이지의 최대 백분율
• innodb_page_cleaners : default 4 / 버퍼 풀 인스턴스에서 더티 페이지를 플러시하는 페이지 클리너 스레드 수입니다.
• innodb_purge_threads : default 3 / InnoDB purge 작업에 할당된 백그라운드 스레드 수
• innodb_lru_scan_depth : default 1024 / InnoDB 버퍼 풀의 플러시 작업에 대한 알고리즘 및 휴리스틱에 영향을 미치는 매개변수입니다.
• Innodb_flush_log_at_trx_commit : default 1 / Innodb 트랜잭션 내구성 결정
• innodb_sync_spin_loops : default 30 / Thread가 일지 중지 되기 전 innoDB mutex가 해제 되기까지 기다리는 횟수2.4.2 DNS TTL

-
애플리케이션에서는 데이터베이스 접속을 위해 dns를 통해 도메인을 ip주소로 반환한다. 이때 얻은 ip주소를 캐시에 저장하여 일정 시간 동안 재사용하여 dns 조회의 비용을 줄인다.
-
하지만 ttl값이 너무 크게되면 데이터베이스가 fail over가 되었을 때 커넥션 문제가 발생할 수 있다.
자바에서 dns caching ttl 설정 변경
java에서는 java vm을 완전히 down을 시키고 was를 재구동을 해야된다. 이때 ttl을 사용하도록 securitymanager의 policy를 수정해야된다.
networkaddress.cache.ttl=60
private static void disableAddressCache() {
Security.setProperty("networkaddress.cache.ttl", "0");
Security.setProperty("networkaddress.cache.negative.ttl", "0");
}https://docs.aws.amazon.com/sdk-for-java/v1/developer-guide/jvm-ttl-dns.html
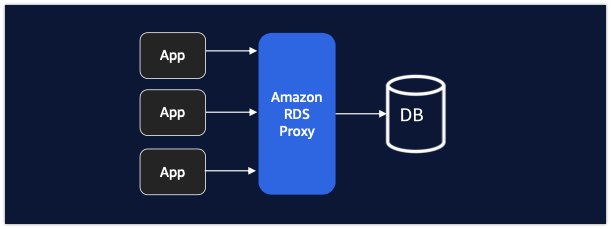
2.4.3 RDSProxy
-
Amazon RDS 프록시 는 말 그대로 RDS의 연결을 관리하는 프록시 서비스이다. 즉. 프록시이기 때문에 특정 db가 장애가 발생해도 예비 db로 서비스 장애 시간을 최소화할 수 있게 만들어준다.
-
이것은 멀티플렉싱으로 트랜잭션 간 데이터베이스 연결 공유를 할 수 있게 만드며, 수십만 개의 연결을 지원하도록 확정성을 보장한다.
만약에 failover가 발생을 하더라도 빠르게 복구할 수 있다.
- failover가 발생하면 유저가 요청한 것이 사라지는 것이 아니라 트랜잭션이 대기열에 추가된다.
- nds 캐시 및 다운스트림 ttl을 우회하여 장애를 감지하고 대기에 더 빠르게 연결할 수 있다.
2.4.4 RDSProxy 한계
-
proxy를 사용하면 장점이 있지만 트레이드 오프로 단점도 존재한다. 예를 들어서 spring의 경우에는 spring boot 2.x 버전부터 기본적으로 hikari cp를 사용하여 connection pool을 사용한다.
RDSProxy는 애플리케이션에 connection pool이 있는 경우에는 connectio issue가 발생한다. -
Failover로 connection이 옮겨가는 도중에 Query 수행이 아닌 대기상태로 된다.
2.4.5 Aurora에서 Connection 분산과 확장 팁
- DNS TTL을 가능한 작게
- Connection pool을 사용할 경우 Connection pool lifetime을 적정수치 이하로 축소
- Database에 접근하는 API(Client)는 작은 타입을 여러 대 사용하는 것이 유리. Min/Max pool 조절
- API level이 B/G로 분산하는 경우 switch over 전에 Green 환경에서 미리 connection 구성
출처
https://www.youtube.com/watch?v=7_VXMqYixS4&t=693s
https://docs.aws.amazon.com/ko_kr/AmazonRDS/latest/AuroraUserGuide/CHAP_AuroraOverview.html
