1. 서론
- 프로젝트를 진행하면서 CS 문제를 풀면 랭킹이 증가하는 랭킹 시스템을 구현을 하였습니다. MySQL의 Score의 점수를 저장을 합니다. 점수를 기반으로 처음에 생각한 방식은 2가지가 있습니다.
- 만약에 MySQL에서 order By를 통해 정렬하여 조회
- 성능적인 이슈가 발생한다고 생각을 하였습니다. 왜냐하면 자주 변경되는 Score를 Order By를 하기 때문에 많은 리소스가 소모가 된다고 판단을 하였습니다.
- Spring에서 정렬을 한다면 정렬 알고리즘을 사용
- 버블, 선택, 퀵정렬을 하면 시간 복잡도 O(N^2)이 발생을 합니다. 만약에 사람들이 많아진다고 가정하면 서버에서 처리하는 방식은 서버에 부하를 많이 준다고 판단을 하였습니다.
- Redis Sorted Set 사용
- 랭킹 보드는 많은 사람들이 조회를 한다고 생각을 했습니다. Score의 점수를 정렬하여 보여주기 때문에 많은 사람들이 조회를 한다면 서버에 부하가 심하다고 판단하여 In-Memory DB를 고려함.
- In-Memory DB에 Memcached, Redis를 고려를 하였습니다. 개발의 효율성 관점에서 Redis를 선택을 하였습니다.
Memcached보다 Redis를 선택한 이유
- Redis는 다양한 자료구조를 제공합니다. Redis는 String, List, Set, Sorted Set, Hash ... 등 다양한 자료구조를 제공한다. Memcached는 String의 자료구조를 제공한다. 랭킹 시스템을 만들기 위해서는 Sorted Set으로 개발자의 구현 난이도를 낮추어주고 시간 복잡도가 O(log N)으로 성능적인 이점을 가질 수 있다고 판단.
2. 본론
2-2. 랭킹 시스템 구현
Sorted Set은 어떻게 구현이 되나?
-
Sorted Set은 내부적으로 두 가지 데이터 구조로 저장을 합니다. 레디스가 데이터 구조를 선택을 합니다.
-
보통은 Hash Talble과 {ZIP List / Skip List}로 구현을 합니다.
http://redisgate.kr/redis/configuration/internal_skiplist.php
-
하나는 멤버 수가 128개 까지 ZIP List 데이터 구조로 저장이 되고 129개부터는 데이터 구조가 변환이 되어 Skip List에 저장된다.
-
Value의 길이가 64바이트까지 Zip List로 저장되고 65바이트부터는 Skip List로 저장이 된다.
- 이 두 가지는 or 조건이다. 둘 중 하나라도 만족하면 레디스 서버가 자동으로 데이터 구조를 변환을 합니다.
Hash Table
- Hash Table이란
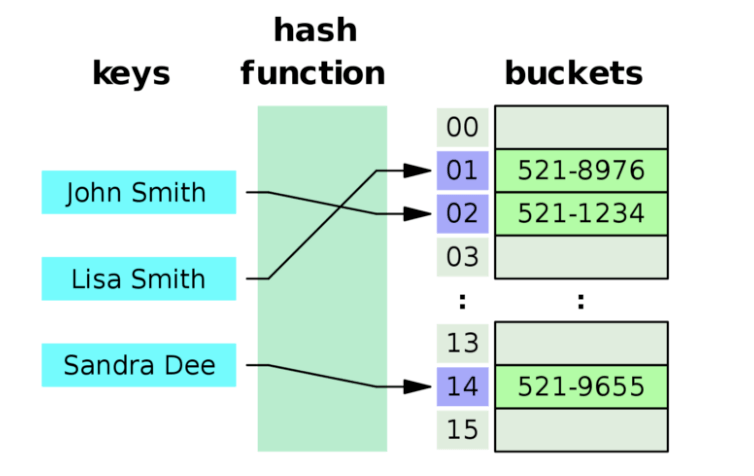
해시 테이블 (또는 해시 맵 이라고도 한다) 은 1950년대에 등장했지만, 아직도 많은 곳에서 유용하게 사용되는 자료구조이다. 해시테이블은 데이터를 Key-Value 쌍으로 저장하는 자료구조이다. 대표적으로 Python 의 딕셔너리가 해시 테이블로 구현되어 있다.
해시 테이블은 Key 를 받아 임의의 해시 함수를 통해 도출된 해시 값을 배열의 Index 로 사용한다. 이런 방식을 통해 O(1) 이라는 아주 빠른 속도로 데이터에 접근할 수 있다. 하지만, Index 가 순서대로 사용되어 차곡차곡 데이터가 적재되지 않아 빈 공간이 생기고, 이는 공간의 낭비로 이어진다. 즉, 해시 테이블은 공간과 시간이 Trade-Off 의 관계에 있다. 공간으로 시간을 사는 개념이라고 보면 좋다.
해시 테이블의 배열의 각 원소를 버킷 (Bucket) 이라고 한다. 버킷의 개수는 고정적이다. 후술할 해시 충돌 을 해결하기 위해 각 버킷에는 링크드 리스트 등을 사용하여 여러 데이터를 저장하게 되는데, 이를 슬롯 (Slot) 이라고 한다. 한 버킷에는 여러개의 슬롯이 저장될 수 있으며, 슬롯의 개수는 가변적이다. 쉽게 생각하면 버킷은 행, 슬롯은 열 이라고 봐도 괜찮다.
해시 충돌 대응
충돌을 대응하는 방식에는 아래와 같이 크게 두가지 방법이 있다.
Chaining
각 버킷에 대응하는 링크드 리스트를 생성하고, 버킷이 링크드 리스트의 가장 앞 노드를 바라보게끔 하여 충돌을 방지하는 방법이다. 해시 충돌이 발생했을 때 그저 같은 버킷 링크드 리스트의 마지막 노드로 해당 값을 추가해주기만 하면 된다. 열린 해시법이라고도 한다.
Open addressing
Chaining 방법과 다르게 한 버킷에는 하나의 Value 만 저장하며, 해시 충돌 시 Key 를 재해싱(rehasing) 하여 빈 버킷에 데이터를 저장하는 방법이다. 닫힌 해시법이라고도 한다.
ZIP List
- 두 개 이상의 리스트를 쌍으로 묶는 것을 의미하는 용어로 레디스는 Sorted Set을 내부적으로 Zset이라고 한다.
zset-max-ziplist-entries 128
zset-max-ziplist-value 64Skip List
-
스킵 리스트는 정렬된 상태를 유지하면서 Write 작업을 탐색할 수 있는 데이터 구조입니다. 스킵 리스트는 Linked List의 단점을 개선하기 위해 작성이 되었다. ( 정렬된 링크드 리스트 )
-
링크드 리스트는 n의 노드를 찾을려면 n 번의 비교가 필요하다.

- 이러한 문제를 해결하기 위해 레벨을 갖는 스킵 리스트가 생성이 되었다.
탐색 시간을 단축하기 위해 비교의 횟수를 줄이기 위해 생성이 되었다.
두개의 Point를 사용하여 1번 Point는 다음 노드를 탐색하고 2번 Point는 1개의 노드를 뛰어넘어 탐색을 합니다. 이렇게 하였을 때 n의 노드를 찾기 위한 탐색을 줄일 수 있습니다.

랭킹 시스템 코드
- 구현 코드는 Redis Config, Entity, Dto를 생략하고 랭킹을 조회하는 부분만 작성을 하였습니다.
- 코드를 살펴보면
memberRepository.findAllWithQuestions()를 통하여 회원과 문제에 대한 정보를 List에 담고 Score를 Stream으로 분리한다. - 이후 redisTemplate.opsForZSet(): redisTemplate은 RedisTemplate<String, String> 타입으로 가정합니다. redisTemplate.opsForZSet()을 호출하여 Redis의 ZSet에 접근하는 ZSetOperations<String, String> 객체를 얻습니다. 이 객체를 통해 랭킹 정보를 저장하고 조회할 수 있습니다.
stringStringZSetOperations.reverseRangeWithScores는 Redis의 ZSet에 접근하여 스코어가 높은 순서대로 랭킹의 정보를 조회를 합니다. KEY,Start,End로 이루어져 있으며 메서드의 반환값은Set<ZSetOperations.TypedTuple<String>>형태로 표현을 합니다.
@Service
public class RankingServiceImpl implements com.CStudy.domain.ranking.application.RankingService {
private final RedisTemplate<String, String> redisTemplate;
private final MemberRepository memberRepository;
public RankingServiceImpl(RedisTemplate<String, String> redisTemplate, MemberRepository memberRepository) {
this.redisTemplate = redisTemplate;
this.memberRepository = memberRepository;
}
/**
* @return redis에 회원의 정보를 가져와 포인트를 1~10까지 가져온다.
*/
@Cacheable(key = "1", value = RedisCacheKey.Ranking, cacheManager = "redisCacheManager")
@Transactional(readOnly = true)
public List<ZSetOperations.TypedTuple<String>> getRanking() {
List<Member> memberList = memberRepository.findAllWithQuestions();
Map<Long, Long> memberSolveTimeMap = memberList.stream()
.collect(Collectors.toMap(Member::getId, this::calculateSolveTime));
ZSetOperations<String, String> stringStringZSetOperations = redisTemplate.opsForZSet();
memberList.forEach(member -> {
double rankingPoint = member.getRankingPoint();
stringStringZSetOperations.add("ranking", member.getName(), rankingPoint);
});
return new ArrayList<>(Objects.requireNonNull(stringStringZSetOperations.reverseRangeWithScores("ranking", 0, 9), "Ranking Board Data null"));
}
private long calculateSolveTime(Member member) {
return member.getQuestions().stream()
.mapToLong(MemberQuestion::getSolveTime)
.sum();
}
}2-3. 랭킹 시스템의 문제점 ( 캐싱 오버헤드)
- 기존에 랭킹을 조회를 할때 Cache Aside 전략으로 캐싱을 처리를 했습니다. 이후 문제를 풀었을 때
@CacheEvict를 통하여 캐싱의 정합성을 맞추었습니다. 하지만 많은 사람들이 문제를 푼다고 가정을 하였을 때@CacheEvict로 캐싱 정합성을 맞추게 되면 동기 방식이기 때문에 캐싱 오버헤드가 발생을 합니다. 이러한 방식을 우회하기 위하여 Redis Pub/Sub으로 비동기 방식으로 우회를 하여 프로젝트를 진행을 하였습니다.
Redis Pub/Sub이란
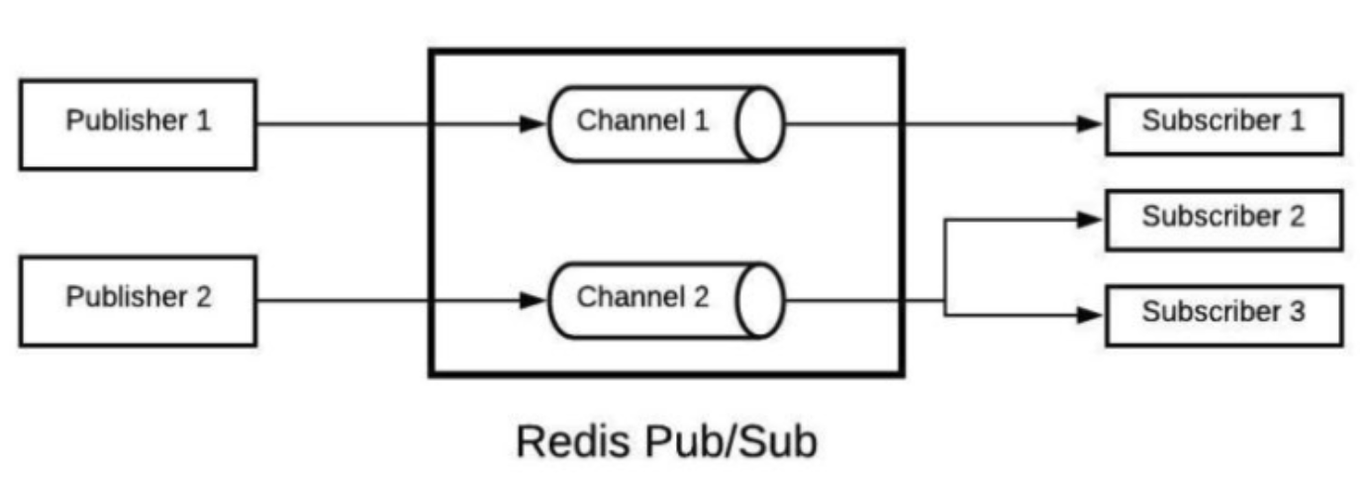
- Redis Pub/Sub 이란 특정 채널을 구독하는 구독자들에게 메세지를 브로드캐스트 하는 방법이다.
- 일반적으로 데이터베이스와는 다르게 레드스는 메시지를 주고, 받는 기능을 제공을 합니다. Publish 명령으로 보내고 Subscribe 명령을 받습니다. 통로는 채털을 이용을 합니다.
특징
-
Redis Pub/Sub은 메세지 큐와 다르게 특정 채널을 구독 신청한 모든 구독자에게 메세지를 전달을 한다. 이때 메세지는 보관하지 않는다.
-
비동기 메세징 : 발행한 메세지들은 실시간으로 구독자에게 전달되므로 발행자와 구독자들 간에 의존성이 느슨하게 변경한다.
-
다중 구독자 : 하나의 발행된 메세지를 여러 구독자가 동시에 받을 수 있습니다.
-
분산 환경 : Redis는 분산 환경에서도 쉽게 확장이 가능하다.Redis 클러스터링 기능을 활용하여 데이터와 Pub/Sub을 여러 노드에 분산시킬 수 있다.
기존의 @CacheEvict 방식에서 Redis Pub/Sub으로 변경한 이유
-
요구사항 : 랭킹 보드는 실시간으로 처리의 요구사항이 있었습니다. 성능을 고려하면 Redis를 이용하여 Write Back 전략을 이용하면 성능이 기존의 방식보다 좋다고 생각한다. 하지만 특정 시점을 기점으로 Batch로 Insert를 하기 때문에 실시간 처리를 할 수 없습니다.
-
비동기 :
@CacheEvict를 사용하여 캐싱 정합성을 맞추려면 동기 방식으로 실행이 되기 때문에 캐시를 지우는 작업이 실행될 때까지 해당 메서드를 호출하는 모든 요청을 Blocking을 합니다. 하지만 Redis Pub/Sub으로 구현을 한다면 비동기로 작업을 하기 때문에 빠른 응답 속도와 병렬 처리를 수행할 수 있어 성능의 이점을 가질 수 있습니다. -
분산 환경 :
@CacheEvict를 통하여 캐시 일관성을 맞추면 여러 서버가 실행을 하고 있다고 가정하면 단일 서버에만 캐시의 일관성을 생각합니다. 하지만 Redis Pub/Sub은 중앙 집중식 메세지 브로커를 통하여 모든 서버가 메시지를 주고 받을 수 있기 때문에 캐싱 정합성을 맞추기 적합하다.
@Override
@Transactional
public void choiceQuestion(LoginUserDto loginUserDto, Long questionId, ChoiceAnswerRequestDto choiceNumber) {
Question question = questionRepository.findById(questionId)
.orElseThrow(()->new NotFoundQuestionId(questionId));
List<Choice> choices = question.getChoices();
choices.stream()
.filter(Choice::isAnswer)
.forEach(choice -> {
if (choice.getNumber() == choiceNumber.getChoiceNumber()) {
memberQuestionService.findMemberAndMemberQuestionSuccess(
loginUserDto.getMemberId(),
questionId,
choiceNumber
);
} else {
memberQuestionService.findMemberAndMemberQuestionFail(
loginUserDto.getMemberId(),
questionId,
choiceNumber
);
}
});
redisPublisher.publish(ChannelTopic.of(ranking-invalidation), ranking);
}
@Override
@Transactional
public void findMemberAndMemberQuestionSuccess(Long memberId, Long questionId, ChoiceAnswerRequestDto choiceAnswerRequestDto) {
findByQuestionAboutMemberIdAndQuestionIdSuccess(memberId, questionId);
findByQuestionAboutMemberIdAndQuestionIdFail(memberId, questionId);
Member member = memberRepository.findById(memberId)
.orElseThrow(() -> new NotFoundMemberId(memberId));
Question question = questionRepository.findById(questionId)
.orElseThrow();
if (memberQuestionRepository.existsByMemberAndQuestionAndSuccess(memberId, questionId, choiceAnswerRequestDto.getChoiceNumber())) {
throw new existByMemberQuestionDataException(memberId, questionId, choiceAnswerRequestDto.getChoiceNumber());
}
member.addRankingPoint(choiceAnswerRequestDto);
memberQuestionRepository.save(MemberQuestion.builder()
.member(member)
.question(question)
.success(choiceAnswerRequestDto.getChoiceNumber())
.solveTime(choiceAnswerRequestDto.getTime())
.build());
}
@Override
@Transactional
public void findByQuestionAboutMemberIdAndQuestionIdSuccess(Long memberId, Long questionId) {
long count = memberQuestionRepository.countByMemberIdAndQuestionIdAndSuccessZero(memberId, questionId);
if (count != 0) {
Optional<MemberQuestion> questionOptional = memberQuestionRepository.findByQuestionAboutMemberIdAndQuestionId(memberId, questionId);
questionOptional.ifPresent(question -> memberQuestionRepository.deleteById(question.getId()));
questionOptional.orElseThrow(() -> new RuntimeException("MemberQuestion not found"));
}
}
@Override
@Transactional
public void findByQuestionAboutMemberIdAndQuestionIdFail(Long memberId, Long questionId) {
long count = memberQuestionRepository.countByMemberIdAndQuestionIdAndFailZero(memberId, questionId);
if (count != 0) {
Optional<MemberQuestion> questionOptional = memberQuestionRepository.findByQuestionAboutMemberIdAndQuestionId(memberId, questionId);
questionOptional.ifPresent(question -> memberQuestionRepository.deleteById(question.getId()));
questionOptional.orElseThrow(() -> new RuntimeException("MemberQuestion not found"));
}
}- 해당 문제를 해결을 하였을 때 MySQL의 Score가 변하게 됩니다. 그러면 캐싱의 접합성을 맞추기 위하여 기존의 캐시를 지워야 한다. 기존의
@CacheEvict방식에서 채널을 구독하는 Redis Pub/Sub으로 바꾸어 이벤트를 이용하여 캐싱의 정합성을 맞추도록 변경을 하였습니다.
3. 결론
-
기존의 요구사항이 실시간 랭킹을 보여주는 보드이고 많은 조회를 하기 때문에 캐싱을 설정했고 분산처리 및 많은 변경이 일어난다고 생각을 하였기 때문에 Redis pub/sub으로 캐싱의 정합성을 맞추었습니다.
-
추후에는 배포를 하여 분산 환경을 설정하고 캐싱의 정합성을 테스트를 하겠습니다.
참고
http://redisgate.kr/redis/command/pubsub_intro.php
http://redisgate.kr/redis/configuration/internal_skiplist.php
