참고
https://data-marketing-bk.tistory.com/44
그래프 탐색
그래프 참고
https://m.blog.naver.com/k97b1114/140163248655
그래프 탐색 : 하나의 정점부터 시작하여 차례대로 모든 정점들을 한 번씩 방문하는 것
그 중 DFS와 BFS는 자주 등장하는 유형이다.
DFS
깊이 우선 탐색(DFS,Depth-First-Search) : 루트 노드(혹은 다른 임의의 노드)에서 시작해서 다음 분기(branch)로 넘어가기 전에 해당 분기를 완벽하게 탐색하는 방법
쭉쭉 내려가면서 탐색한다.
너비 우선 탐색(BFS)보다 간단하다.
대신 단순 검색 속도 자체는 BFS보다 느리다.
DFS의 특징
- 자기자신을 호출하는 순환 알고리즘 형태
- 전위 순회(뿌리를 먼저 방문)를 포함한 다른 형태의 트리 순회는 모두 DFS의 한 종류.
순회 종류
https://m.blog.naver.com/rlakk11/60159303809
- 어떤 노드를 방문했었는지 여부를 반드시 검사해야한다. 검사하지 않으면 무한루프에 빠질 수 있다.
과정은 찾아보자
DFS 구현 준비
일단 트리는 딕셔너리 형태로 생성한다.
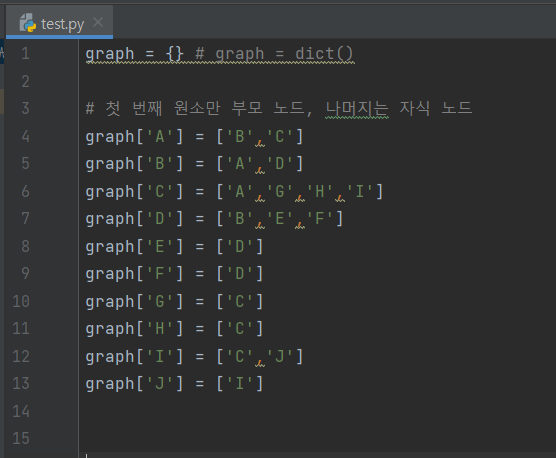
DFS에서 데이터를 찾을 때는 항상 "앞으로 찾아가야 할 노드"와 "이미 방문한 노드"를 기준으로 데이터를 탐색
위에서 아래로 탐색할 때 왼쪽으로 가냐 오른쪽으로 가냐는 상관없다.
특정 노드가
앞으로 찾아가야 할 노드 -> 계속 검색
이미 방문한 노드 -> 무시하거나 따로 저장
구현 방법엔 2가지가 있다.
1. 스택,큐 이용
2. 재귀함수 이용
스택/큐를 활요한 DFS 구현
스택을 이용한 구현
파이썬은 스택 자료구조를 따로 지원하지 않지만 list로 흉내낼 수 있다.
listName.extend(iterable)이면 리스트 끝에 요소들을 낱개로 추가해준다.
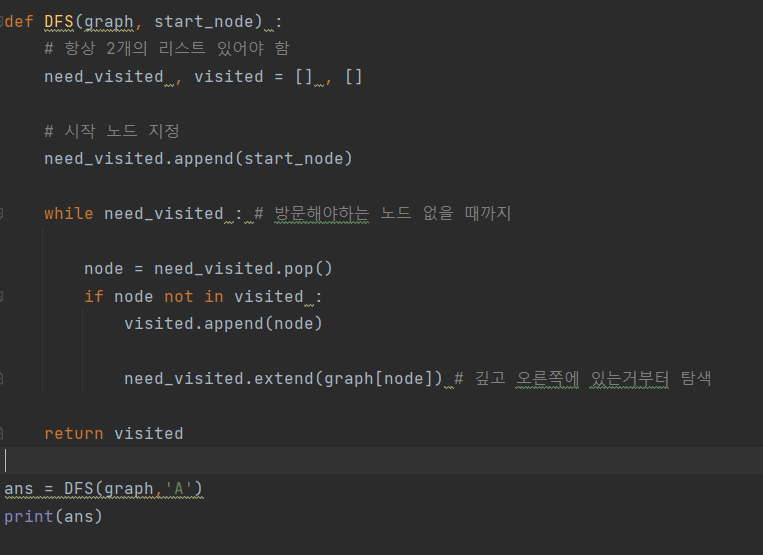
list에서 pop을 활용하면 다소 성능이 떨어진다.
덱(deque)를 이용해서 구현하면 논리는 동일하지만 성능면에서 좋다.
from collections import deque
need_visited = deque()
로 수정하면 된다.
재귀함수를 활용한 DFS 구현
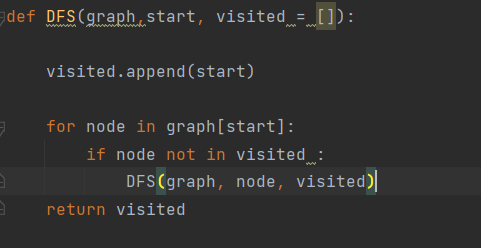
계속 start 인수를 넘겨주니까 visited 하나만 있으면 된다.
BFS
너비 우선 탐색(BFS,Breadth-First-Search) : 가까운 노드부터 탐색하는 알고리즘
동작 형태
1. 탐색 시작 노드를 큐에 삽입하고 방문 처리를 한다.
2. 큐에서 노드를 꺼내 해당 노드의 인접 노드 중에서 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리를 한다.(한번에 넣는다.)
3. 2번의 과정을 더 이상 수행할 수 없을 때까지 반복한다.
BFS의 특징
- 큐 자료구조에 기초한다.(재귀 x)
- 파이썬의 경우 deque 라이브러리를 사용하는 것이 좋다.
- 수행함에 있어 O(n)의 시간이 소요된다.
- 일반적인 경우 실제 수행 시간은 DFS보다 좋은 편이다.
BFS 구현
deque를 사용할 것이다.
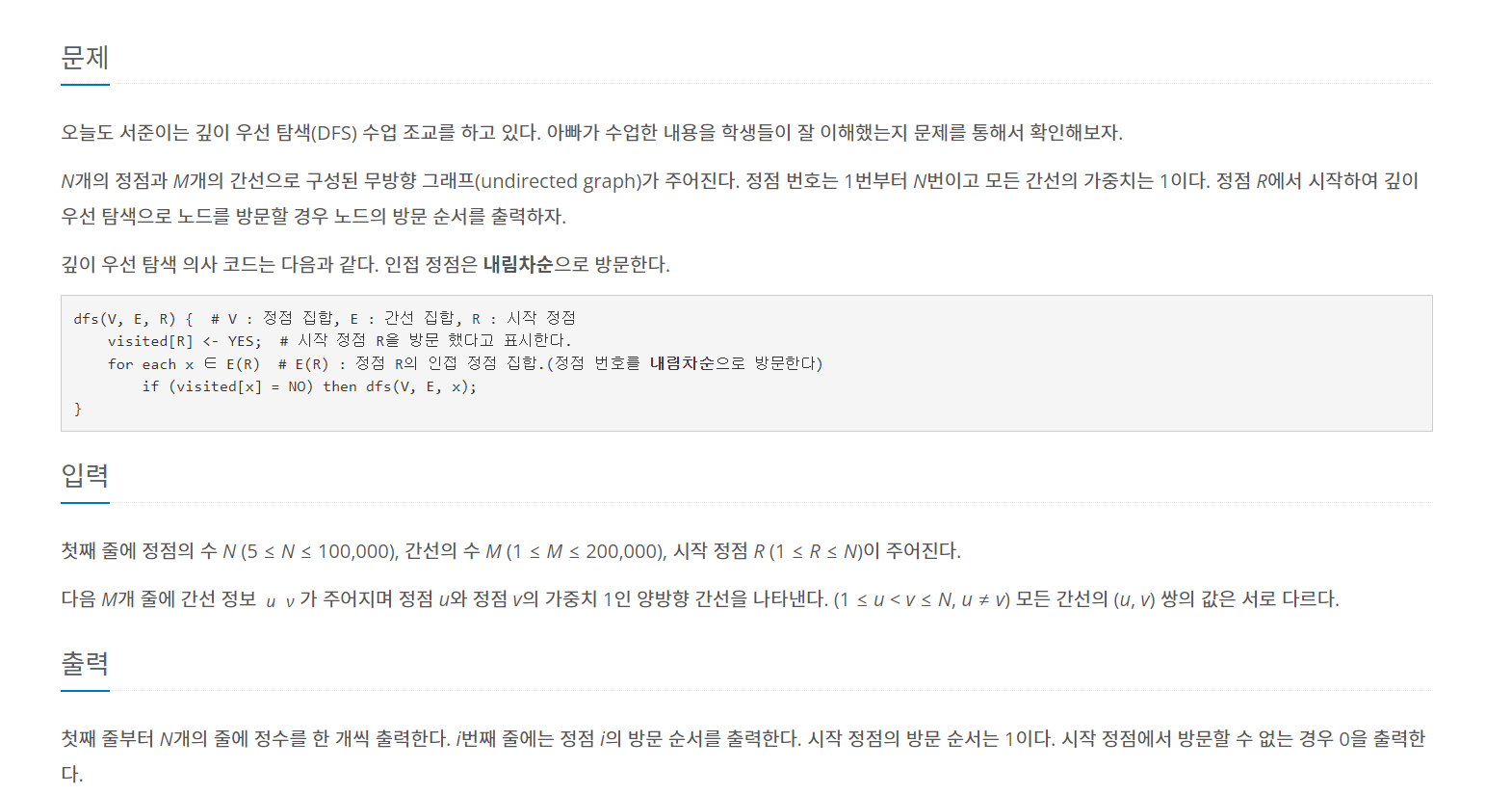
문제 풀어보기
백준 24480 깊이 우선 탐색 2

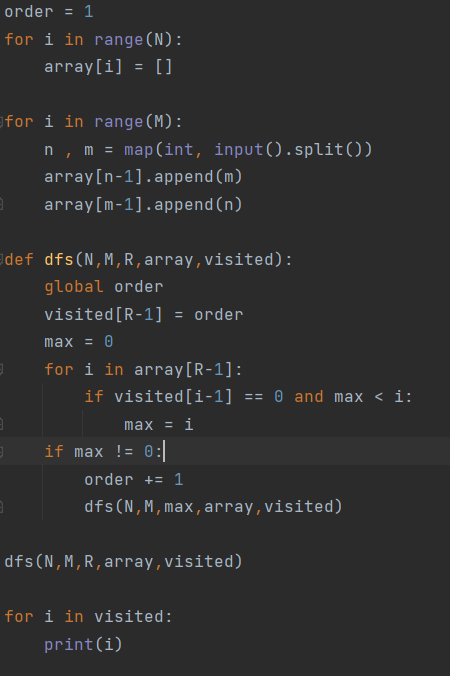
(틀린풀이)
아니 array 요소들을 sort하고 해야 작은 것도 나중에 방문하는데 max 어쩌구 난리를 쳐버렸다. 입력 예제가 하필 맞아가지고 한참 헤맸다..
뭐든지 max 써서 이러는거보다 정렬해서 푸는게 유연한 것 같다.
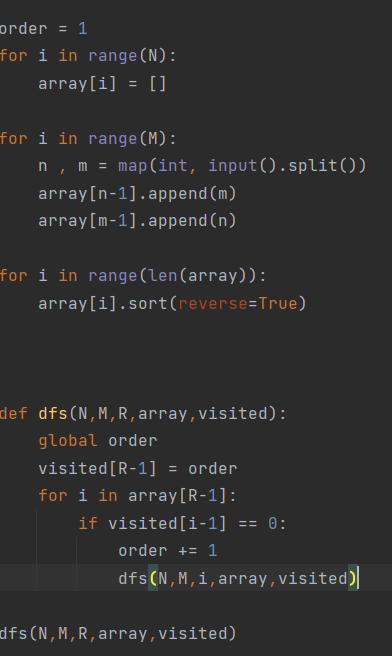
다시 했는데 ... 백준에서 런타임 에러가 났다.


그래서
import sys
sys.setrecursionlimit(10**6)를 넣어 최대 재귀 깊이를 늘렸다.
그랬더니 이제 시간초과가 뜬다. 코드가 문제인 것 같다.
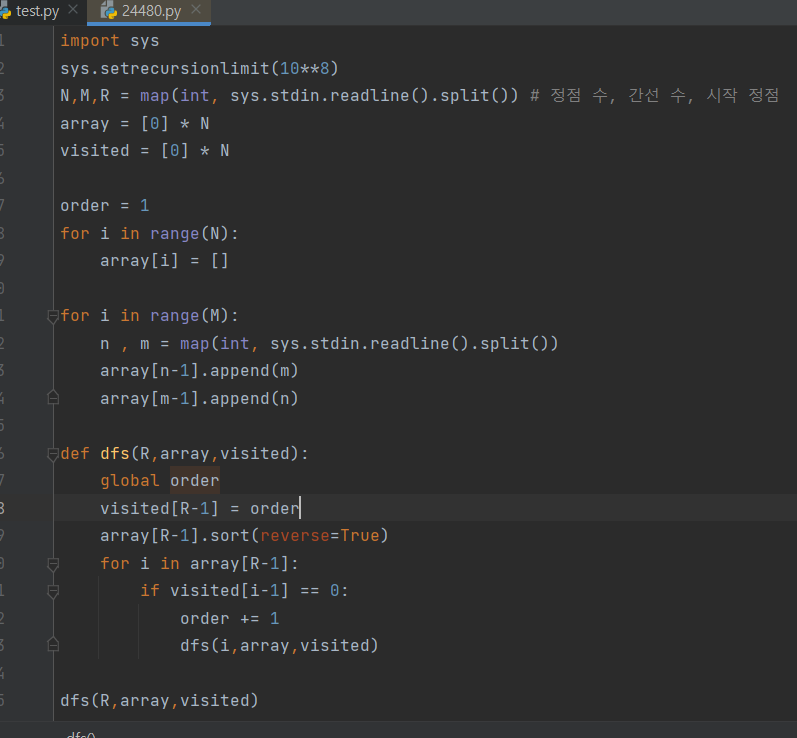
최종
input.split() 대신 sys 모듈을 import하고
sys.stdin.readline().split()로 바꿨더니 해결되었다.
sys.stdin.readline().split()이 input.split()보다 2배는 빨라서
파이썬으로 시간초과가 뜨면 이걸로 바꾸라고 한다.
이제 이걸 자주 사용해야겠다.
! 백준에서 파이썬 사용할 때 시간 줄이는 법
1.pypy3 사용
2.sys.stdin.readline().split() 사용
백준 24444 너비 우선 탐색 1
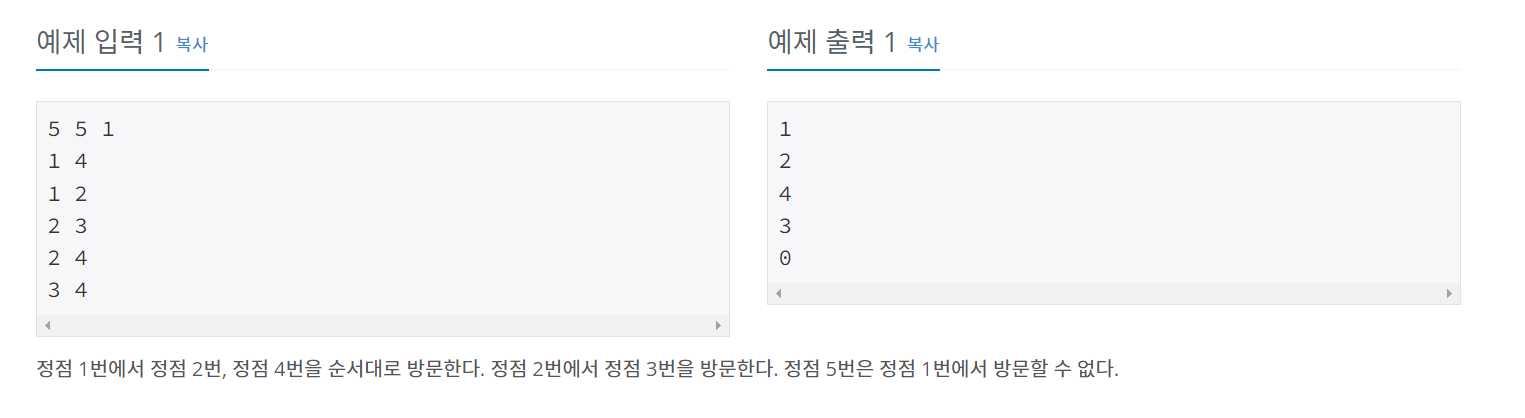
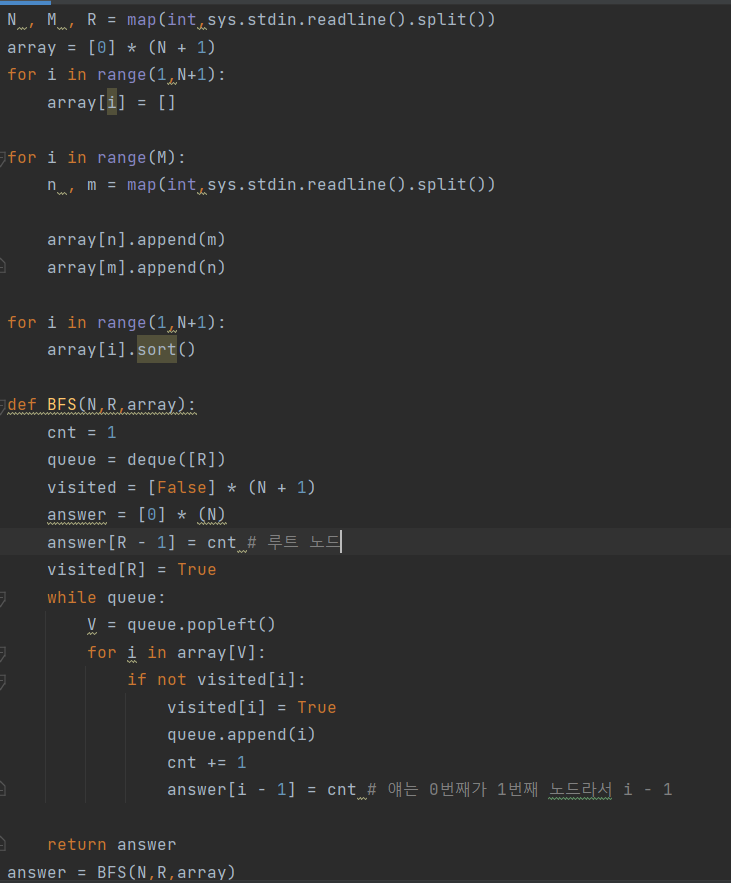
의사코드가 주어져서 좀 쉽게 짰다
백준 2606 바이러스
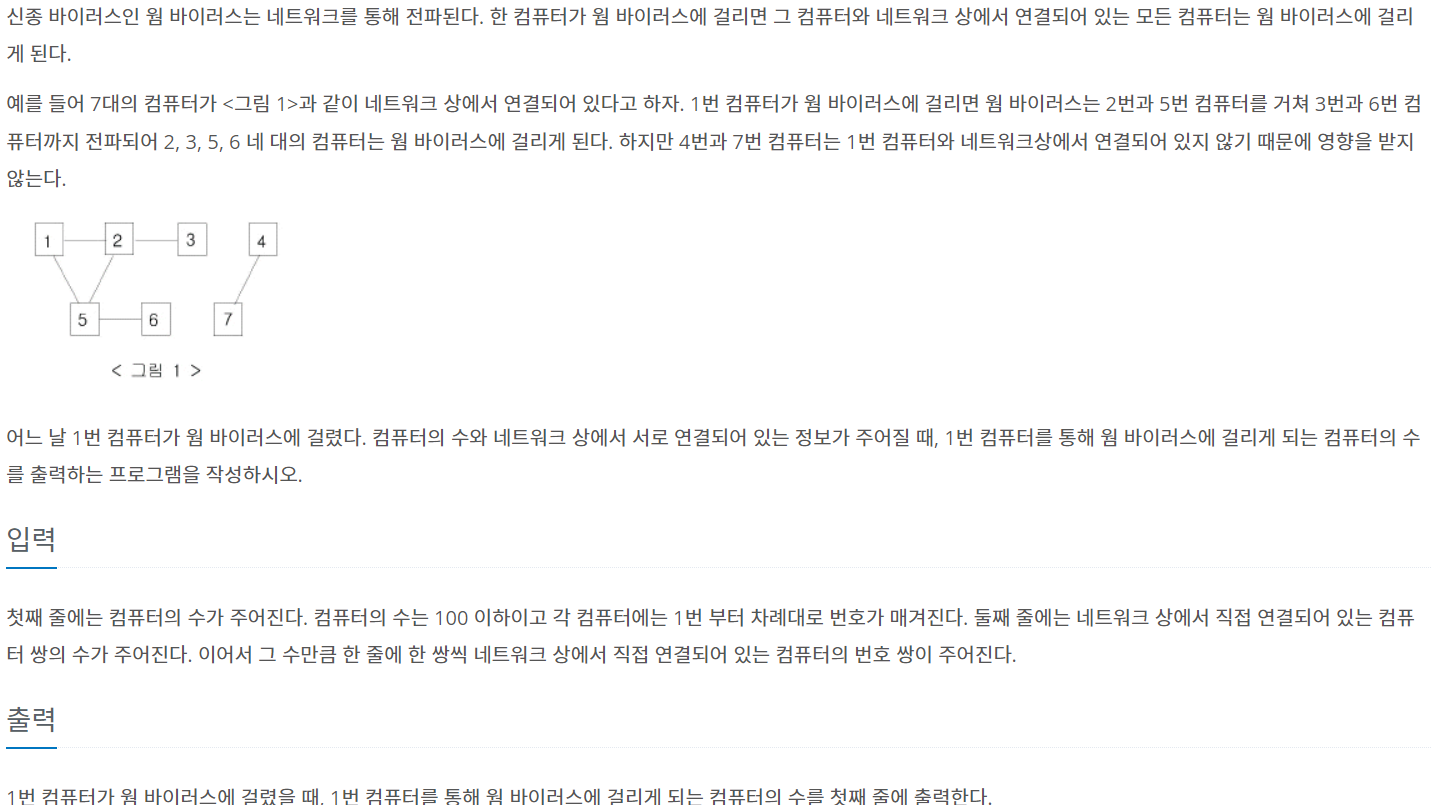
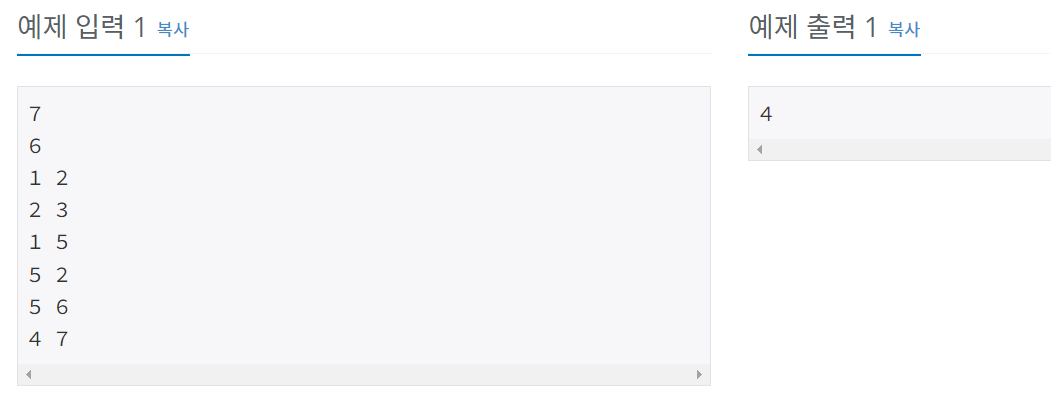
! 파이썬에서 array = [] * N은 안됨. 상식적으로 리스트 선언하는데 여러개가 어떻게 나와

위에 구현했던 BFS랑 거의 똑같아서 복습 느낌으로 안 보고 짜봤다.
백준 2667 단지번호붙이기

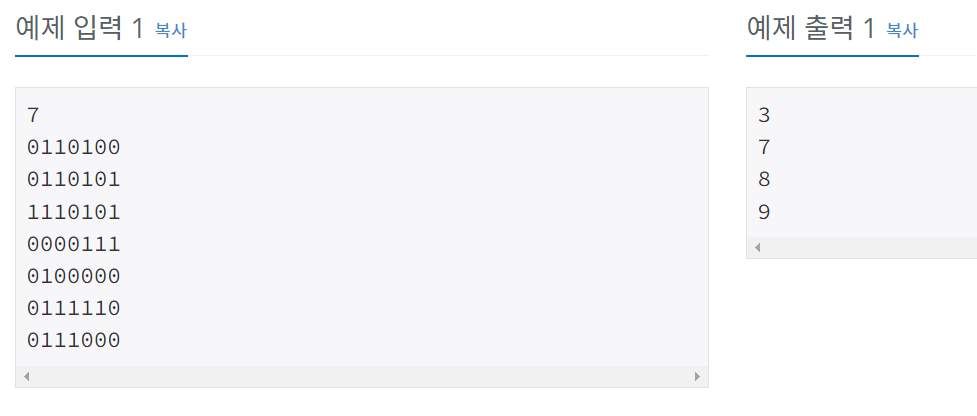
이 문제는 DFS로 풀었다.
sys.stdin.readline()으로 입력받으면 \n까지 입력받는 것 같다. 주의하자

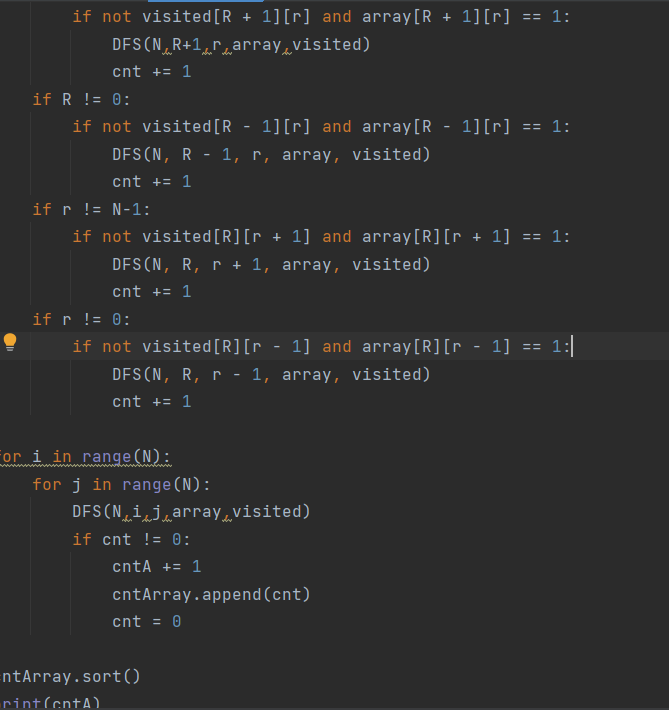
나오긴 하는데 메모리 초과가 뜬다... 내가 생각해도 뭔가 비효율적이긴 하다.
visited를 따로 만들지 않고 그 자리의 1을 0으로 바꾸어버리면 메모리를 절약할 수 있다. 다시 코드를 짜 보았다.
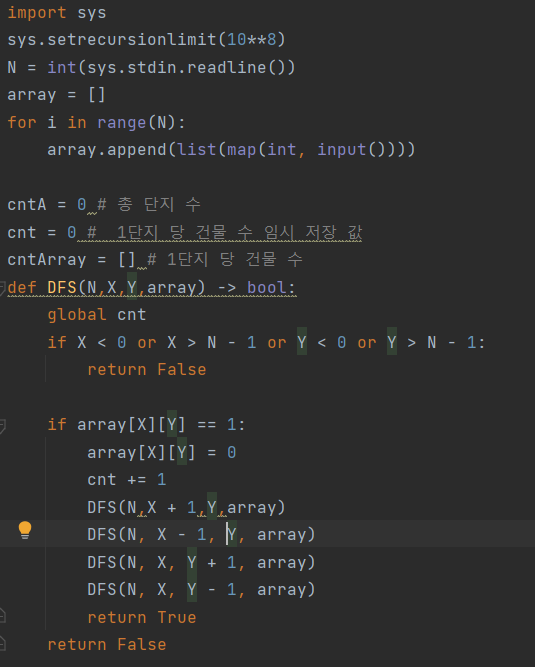
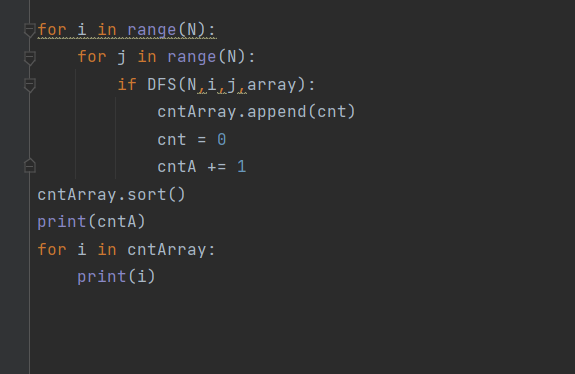
일단 코드를 고쳐서 다시 냈는데도 메모리 초과가 떴다.
그래서 pypy3이 아닌 python3으로 제출했더니 되었다.
pypy3은 빠른 대신에 메모리를 더 잡아먹나보다.
전에 짰던 코드도 python3으로 했으면 돌아갔을지도...?
남은 문제는 다음에 풀어보도록 하자
