들어가며
해당 시리즈는 오로지 개인 기록용이며, 코틀린 코루틴의 책 내용을 저만의 방식대로 요약합니다.
코루틴 빌더
중단 함수는 컨티뉴에이션 객체를 다른 중단 함수로 전달해야 합니다. 즉,
- 중단 함수 → 일반 함수 O
- 일반 함수 → 중단 함수 X
모든 중단 함수는 또 다른 중단 함수에 의해 호출되어야 합니다. 그렇다면 중단 함수의 시작되는 지점은 어디일까요? 코루틴 빌더가 바로 그 역할을 하며, 일반 함수와 중단 함수의 연결시키는 다리가 됩니다.
kotlinx.coroutines 라이브러리가 제공하는 세 가지 필수적인 코루틴 빌더는 다음과 같습니다.
- launch
- runBlocking
- async
이제부터 각 코루틴 빌더를 사용하는 방법을 하나씩 탐색하겠습니다.
launch 빌더
launch가 작동하는 방식은 thread 함수를 호출하여 새로운 스레드를 시작하는 것과 비슷합니다.
launch 함수는 CoroutineScope 인터페이스의 확장 함수입니다. CoroutineScope 인터페이스는 부모 코루틴과 자식 코루틴 사이의 관계를 정립하기 위한 목적으로 사용되는 구조화된 동시성의 핵심입니다.
아래의 launch 빌더 예제와, 동일한 로직의 스레드 예제를 살펴보도록 하겠습니다.
- launch 빌더 예제
fun main() {
GlobalScope.launch {
delay(1000L)
println("World!")
}
GlobalScope.launch {
delay(1000L)
println("World!")
}
GlobalScope.launch {
delay(1000L)
println("World")
}
println("Hello,")
Thread.sleep(2000L)
}
// Hello,
// (1초 후)
// World!
// World!
// World!- 동일 로직의 스레드 예제
fun main() {
thread(isDaemon = true) {
Thread.sleep(1000L)
println("World!")
}
thread(isDaemon = true) {
Thread.sleep(1000L)
println("World!")
}
thread(isDaemon = true) {
Thread.sleep(1000L)
println("World")
}
println("Hello,")
Thread.sleep(2000L)
}
// Hello,
// (1초 후)
// World!
// World!
// World!launch가 동작하는 방식은 데몬 스레드와 어느 정도 비슷하지만 훨씬 가볍습니다.
이때, main 함수의 끝에 Thread.sleep을 호출하지 않으면 main 함수는 코루틴을 실행하자 마자 끝나버리게 됩니다.
delay는 스레드를 블록시키지 않고 코루틴을 중단합니다. 스레드가 블로킹되지 않으면 할 일이 없어져서 그대로 종료되기 때문에 Thread.sleep을 사용해서 main 함수가 끝나는 것을 방지합니다. (구조화된 동시성을 사용하면 Thread.sleep이 필요 없습니다.)
💡 데몬 스레드: 백그라운드에서 돌아가며, 우선순위가 낮은 스레드
launch와 데몬 스레드 둘다 프로그램이 끝나는 것을 막을 수 없습니다.
runBlocking 빌더
코루틴이 스레드를 블로킹하지 않고 작업을 중단시키만 하는 것이 일반적인 법칙입니다. 하지만 블로킹이 필요한 경우도 있습니다. 메인 함수의 경우 프로그램을 너무 빨리 끝내지 않기 위해 스레드를 블로킹해야 합니다. 이때, runBlocking을 사용하면 됩니다.
runBlocking은 코루틴이 중단 되었을 경우, 중단 main 함수와 마찬가지로 시작한 스레드를 중단시킵니다. 따라서 runBlocking 내부에서 delay(1000L)을 호출하면 Thread.sleep(1000L)과 비슷하게 동작합니다.
dispatcher를 이용해 runBlocking이 다른 스레드에서 실행되게 할 수 있습니다. 그러나 이 경우에도 코루틴이 완료될 때까지 해당 빌더가 시작된 스레드가 블로킹됩니다.
fun main(){
runBlocking {
delay(1000L)
println("World!")
}
runBlocking {
delay(1000L)
println("World!")
}
runBlocking {
delay(1000L)
println("World!")
}
println("Hello")
}
// (1초 후》
// World!
// (1초 후》
// World!
// (1초 후》
// World!
// Hello,runBlocking은 주로 언제 사용할까요? 2가지의 사례가 있지만, 다른 방법들로 대체되었기 때문에 현재는 거의 사용되지 않고 있습니다.
- 프로그램이 끝나는 것을 방지하기 위해 스레드를 블로킹할 필요가 있는 main 함수
runBlocking대신 main 함수에 suspend를 붙여서 중단 함수로 만드는 방법으로 대체됨
- 스레드를 블로킹할 필요가 없는 유닛 테스트
- 코루틴을 가상 시간으로 실행시키는 runTest가 주로 사용됨
runBlocking을 사용하면 Thread.sleep(2000) 대신 delay(2000)을 사용하는 방식으로 대체할 수 있습니다.
async 빌더
async 코루틴 빌더는 launch와 비슷하지만 값을 생성하도록 설계되어 있습니다 .이 값은 람다 표현식에 의해 반환되어야 합니다. async 함수는 Deferred 타입의 객체를 리턴하며, 여기서 T는 생성되는 값의 타입입니다. Deferred에는 작업이 끝나면 값을 반환하는 중단 메서드인 await가 있습니다.
fun main() = runBlocking {
val resultDeferred: Deferred<Int> = GlobalScope.async {
delay(1000L)
42
}
// 다른 작업을 합니다
val result: Int = resultDeferred.await() // (1초 후)
println(result) // 42
// 다옴과 같이 간단하게 작성할 수도 있습니다
println(resultDeferred.await()) // 42
}launch 빌더와 비슷하게 async 빌더는 호출되자마자 코루틴을 즉시 시작합니다. 따라서 몇 개의 작업을 한번에 시작하고 모든 결과를 한꺼번에 기다릴 때 사용합니다. 반환된 Deferred는 값이 생성되면 해당 값을 내부에 저장하기 때문에 await에서 값이 반환되는 즉시 값을 사용할 수 있습니다. 하지만 값이 생성되기 전에 await를 호출하면 값이 나올 때까지 기다리게 됩니다.
fun main() = runBlocking {
val res1 = GlobalScope.async {
delay(1000L)
"Text 1"
}
val res2 = GlobalScope.async {
delay(3000L)
"Text 2"
}
val res3 = GlobalScope.async {
delay(2000L)
"Text 3"
}
println(res1.await())
println(res2.await())
println(res3.await())
}
// (1초 후)
// Text 1
// (2초 후)
// Text 2
// Text 3다시 정리하자면, async는 값을 생성할 때, launch는 값이 필요하지 않을 때 사용합니다.
구조화된 동시성
코루틴은 어떤 스레드도 블록하지 않기 때문에 프로그램이 끝나는 걸 막을 방법이 없습니다. 다음 예제에서 “World!”가 출력되는 걸 보려면 runBlocking의 마지막에 delay를 추가적으로 호출해야 합니다.
fun main() {
GlobalScope.launch {
delay(1000L)
println("World!")
}
GlobalScope.launch {
delay(1000L)
println("World!")
}
GlobalScope.launch {
delay(1000L)
println("World")
}
println("Hello,")
}
// Hello,예제에서 처음에 GlobalScope가 필요한 이유는 무엇일까요? 그 이유는 launch와 async가 CoroutineScope의 확장 함수이기 때문입니다. 그런데 이 두 빌더 함수와 runBlocking의 정의를 살펴보면 block 타입의 파라미터가 리시버 타입이 CoroutineScope인 함수형 타입이라는 것을 확인할 수 있습니다.
public actual fun <T> runBlocking(
context: CoroutineContext,
block: suspend CoroutineScope.() -> T
): T
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job
public fun <T> CoroutineScope.async(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> T
): Deferred<T> 즉, runBlocking의 리시버를 통해 launch를 호출하면 GlobalScope를 굳이 사용하지 않아도 됩니다.
이렇게 하면 launch는 runBlocking의 자식이 됩니다. runBlocking은 모든 자식 코루틴들이 작업을 끝마칠 때까지 중단하게 됩니다.
fun main() = runBlocking {
this.launch { // launch로 호출한 것과 같습니다
delay(1000L)
println("World!")
}
launch { // this.launch로 호출한 것과 같습니다
delay(2000L)
println("World!")
}
println("Hello,")
}
// Hello,
// (1초 후》
// World!
// (1초 후》
// World!
부모는 자식들을 위해 스코프를 제공하고, 자식들을 해당 스코프 내에서 호출합니다.
이를 통해 구조화된 동시성이라는 관계가 성립합니다. 부모-자식 관계의 가장 중요한 특징은 다음과 같습니다.
- 자식은 부모로부터 Context를 상속받습니다(자식이 이를 재정의할 수 있습니다)
- 부모는 자식이 모든 작업을 마칠 때까지 기다립니다.
- 부모 코루틴이 취소되면 자식 코루틴도 취소됩니다.
- 자식 코루틴에서 에러가 발생하면, 부모 코루틴 또한 에러로 소멸합니다.
다른 코루틴 빌더와는 달리, runBlocking은 CoroutineScope의 확장함수가 아닙니다. runBlocking은 자식이 될 수 없으므로 root 코루틴으로만 사용될 수 있습니다.
coroutineScope 사용하기
레포지토리 메서드에서 비동기적으로 2개의 자원을 가져오는 경우를 떠올려 봅시다. 이런 경우 async를 호출하려면 스코프가 필요하지만 중단 메서드에는 스코프가 없습니다. 중단 함수 밖에서 스코프를 만들려면, coroutineScope 함수를 사용해야 합니다.
suspend fun getArtictesForUser(
userToken: String?,
): List<ArticleJson> = coroutinescope {
val articles = async { articleRepository.getArticles() }
val user = userService.getUser(userToken)
articles.await()
.filter { canSeeOnList(user, it) }
.map { toArticleJson(it) }
}coroutineScope는 람다 표현식이 필요로 하는 스코프를 만들어 주는 중단 함수입니다.
이 함수는 let, run, use 또는 runBlocking 처럼 람다식이 반환하는 것이면 무엇이든 반환합니다.
coroutineScope는 중단 함수 내에서 스코프가 필요할 때 일반적으로 사용합니다.
코루틴 컨텍스트
코루틴 빌더의 정의를 보면 첫 번째 파라미터가 CoroutineContext라는 사실을 알 수 있습니다.
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job {
// ...
}그렇다면 CoroutineContext가 무엇일까요?
CoroutineContext 인터페이스
CoroutineContext는 원소나 원소들의 집합을 나타내는 인터페이스입니다.
Job, CoroutineName, CoroutineDispatcher와 같은 Element 객체들이 인덱싱된 집합이라는 점에서 map이나 set과 같은 컬력센과 개념이 비슷합니다. 특이한 점은 각 Element 또한 CoroutineContext라는 점입니다. 따라서 컬렉션 내 모든 원소는 그 자체만으로 컬렉션이라 할 수 있습니다.
아래의 예제처럼 컨텍스트의 지정과 변경을 편리하게 하기 위해 CoroutineContext의 모든 원소가 CoroutineContext로 되어 있습니다.
launch(CoroutineName("Name1")) { .. }
launch(CoroutineName("Name2") + Job()) { .. }컨텍스트에서 모든 원소는 식별할 수 있는 유일한 Key를 가지고 있습니다. 각 키는 주소로 비교됩니다.
fun main() {
val name: CoroutineName = CoroutineName("A name")
val element: Coroutinecontext.Element = name
val context: Coroutinecontext = element
val job: Job = JobO
val jobElement: Coroutinecontext.Element = job
val jobContext: Coroutinecontext = jobElement
}CoroutineContext에서 원소 찾기
CoroutineContext는 컬렉션과 비슷하기 때문에 get을 이용해 유일한 키를 가진 원소를 찾을 수 있습니다. 원소에 컨텍스트가 있으면 반환되고, 없으면 null이 반환됩니다.
fun main() {
val ctx: CoroutineContext = CoroutineName("A name")
val coroutineName: CoroutineName? = ctx[CoroutineName]
// 또는 ctx. get (CoroutineName)
println(coroutineName) // CoroutineName (A name)
println(coroutineName?.name) // A name
val job: Job? = ctx[Job] // 또는 ctx. get (Job)
println(job) // nul
}CoroutineName을 사용하기 위해서는 CoroutineName을 사용하기만 하면 됩니다. CoroutineName은 타입이나 클래스가 아닌 컴패니언 객체입니다. 클래스의 이름이 컴패니언 객체에 대한 참조로 사용되는 코틀린 언어의 특징 때문에 ctx[CoroutineName]은 ctx[CoroutineName.key]가 됩니다.
public data class CoroutineName(
/**
* User-defined coroutine name.
*/
val name: String
) : AbstractCoroutineContextElement(CoroutineName) {
/**
* Key for [CoroutineName] instance in the coroutine context.
*/
public companion object Key : CoroutineContext.Key<CoroutineName>
/**
* Returns a string representation of the object.
*/
override fun toString(): String = "CoroutineName($name)"
}키는 CoroutineName과 같은 클래스나 Job과 SupervisorJob처럼 같은 키를 사용하는 클래스가 구현한 (Job과 같은) 인터페이스를 가리킵니다.
interface Job : CoroutineContext.Element {
companion object Key : CoroutineContext.Key<Job>
// ...
}컨텍스트 더하기
CoroutineContext의 정말 유용한 기능은 두 개의 CoroutineContext를 합쳐서 하나의 CoroutineContext로 만들 수 있다는 점입니다.
다른 키를 가진 두 원소를 더하면 만들어진 컨텍스트는 두 가지 키를 모두 가집니다.
fun main(){
val ctx1: CoroutineContext = CoroutineName("Name1")
println(ctx1[CoroutineName]?.name) // Name1
println(ctx1[Job]?.isActive) // null
val ctx2: CoroutineContext = Job()
println(ctx2[CoroutineName]?.name) // null
println(ctx2[Job]?.isActive) // 'Active' 상태이므로 true입니다
// 빌더를 통해 생성되는 잡의 기본 상태가 Active 상태이므로 true가 됩니다
val ctx3 = ctx1 + ctx2
println(ctx3[CoroutineName]?.name) // Name1
println(ctx3[Job]?.isActive) // true
}CoroutineContext에 같은 키를 가진 또 다른 원소가 더해지면 맵처럼 새로운 원소가 기존 원소를 대체합니다.
fun main() {
val ctx1: CoroutineContext = CoroutineContext("Name1")
println(ctx1[coroutineName?.name]) // Name1
val ctx2: CoroutineContext = CoroutineContext("Name2")
println(ctx2[CoroutineName]?.name) // Name2
val ctx3: ctx1 + ctx2
println(CoroutineName?.name) // Name2
}비어있는 코루틴 컨텍스트
CoroutineContext는 컬렉션이므로 빈 컨텍스트 또한 만들 수 있습니다. 빈 컨텍스트는 원소가 없으므로 다른 컨텍스트를 더해도 아무런 변화가 없습니다.
fun main(){
val empty: CoroutineContext = EmptyCoroutineContext
println(empty[CoroutineName]) // null
println(empty[Job]) // null
val ctxName = empty + CoroutineName("Name1") + empty
println(ctxName[CoroutineName]) // CoroutineName(Name1)
}원소 제거
minusKey 함수에 키를 넣는 방식으로 원소를 컨텍스트에서 제거할 수 있습니다.
fun main() {
val ctx = CoroutineName("Name1") + Job()
println(ctx[CoroutineName]?.name) // Name1
println(ctx[Job]?.isActive) // true
val ctx2 = ctx.minusKey(CoroutineName)
println(ctx2[CoroutineName]?.name) // null
println(ctx2[Job]?.isActive) // true
val ctx3 = (ctx + CoroutineName("Name2"))
.minusKey(CoroutineName)
println(ctx3[CoroutineName]?.name) // null
println(ctx3[Job]?.isActive) // true
}컨텍스트 폴딩
컨텍스트의 각 원소를 조작해야 하는 경우 다른 컬렉션이 fold와 유사한 fold 메서드를 사용할 수 있습니다.
fold는 다음을 필요로 합니다.
- 누산기의 첫 번째 값
- 누산기의 현재 상태와 현재 실행되고 있는 원소로 누산기의 다음 상태를 계산할 연산
fun main(){
val ctx = CoroutineName ("Name1") + Job()
ctx.fold("") { acc, element -> "$acc$element " }
.also(::println)
// CoroutineName(Name1) JobImpl{Active}@dbab622e
val empty = emptyList<CoroutineContext>()
ctx.fold(empty) { acc, element -> acc + element }
.joinToString()
.also(::println)
// CoroutineName(Name1), JobImpl{Active}@dbab622e
}코루틴 컨텍스트와 빌더
CoroutineContext는 코루틴의 데이터를 저장하고 전달하는 방법입니다. 부모-자식 관계의 영향 중 하나로 부모는 기본적으로 컨텍스트를 자식에게 전달합니다.
fun CoroutineScope.log(msg: String) {
val name = coroutineContext[CoroutineName]?.name
println("[$name] $msg")
}
fun main() = runBlocking(CoroutineName("main")) {
log("Started") // [main] Started
val vl = async {
delay(500)
log("Running async") // [main] Running async
42
}
launch {
delay(1000)
log("Running launch") // [main] Running launch
}
log("The answer is ${vl.await()}")
// [main] The answer is 42
}모든 자식은 빌더의 인자에서 정의된 특정 컨텍스트를 가질 수 있습니다. 인자로 전달된 컨텍스트는 부모로부터 상속받은 컨텍스트를 대체합니다.
fun main() = runBlocking(CoroutineName("main")) {
log("Started") // [main] Started
val vl = async(CoroutineName("cl")) {
delay(500)
log("Running async") // [cl] Running async
42
}
launch(CoroutineName("c2")) {
delay(1000)
log("Running launch") // [c2] Running launch
}
log("The answer is ${vl.await()}")
// [main] The answer is 42
}
코루틴 컨텍스트를 계산하는 간단한 공식은 다음과 같습니다.
defaultContext + parentContext + childContext새로운 원소가 같은 키를 가진 이전 원소를 대체하므로, 자식의 컨텍스트는 부모로부터 상속받은 컨텍스트 중 같은 키를 가진 원소를 대체합니다.
디폴트 원소는 어디서도 키가 지정되지 않을 때만 사용됩니다.
현재 디폴트로 설정되는 원소는 ContinuationInterceptor가 설정되지 않았을 때 사용되는 Dispatcher.Default이며, 애플리케이션이 디버그 모드일 때는 CoroutineId도 디폴트로 설정됩니다.
중단 함수에서 컨텍스트에 접근하기
CoroutineScope는 컨텍스트를 접근할 대 사용하는 coroutineContext 프로퍼티를 가지고 있습니다. 일반적인
public interface CoroutineScope {
/**
* The context of this scope.
* Context is encapsulated by the scope and used for implementation of coroutine builders that are extensions on the scope.
* Accessing this property in general code is not recommended for any purposes except accessing the [Job] instance for advanced usages.
*
* By convention, should contain an instance of a [job][Job] to enforce structured concurrency.
*/
public val coroutineContext: CoroutineContext
}
CoroutineScope는 컨텍스트를 접근할 때 사용하는 coroutineContext 프로퍼티를 가지고 있습니다. 일반적인 중단 함수에서는 중단 함수 사이에 전달되는 컨티뉴에이션 객체가 컨텍스트를 참조하고 있습니다. 따라서 중단 함수에서는 부모의 컨텍스트에 접근이 가능합니다.
suspend fun printName() {
println(coroutineContext[CoroutineName]?.name)
}
suspend fun main() = withContext(CoroutineName("Outer")) {
printName() // Outer
launch(CoroutineName("Inner")) {
printName() // Inner
}
delay(10)
printName() // Outer
}컨텍스트를 개별적으로 생성하기
CoroutineContext.Element 인터페이스를 구현해서 코루틴 컨텍스트를 커스텀하게 만들 수 잇습니다. 이러한 클래스는 CoroutineContext.Key<*> 타입의 key 프로퍼티가 필요합니다. 키는 컨텍스트를 식별하는 키로 사용됩니다. 가장 전형적인 사용법은 클래스의 컴패니언 객체를 키로 사용하는 것입니다.
class MyCustomContext : CoroutineContext.Element {
override val key: CoroutineContext.Key<*> = Key
companion object Key :
CoroutineContext.Key<MyCustomContext>
}
class CounterContext(
private val name: String
) : CoroutineContext.Element {
override val key: CoroutineContext.Key<*> = Key
private var nextNumber = 0
fun printNext() {
println("$name: SnextNumber")
nextNumber++
}
companion object Key : CoroutineContext.Key<CounterContext>
}
suspend fun printNext() {
coroutineContext[CounterContext]?.printNext()
}
suspend fun main(): Unit =
withContext(
CounterContext("Outer1")
) {
printNext() // Outer: 0
launch {
printNext() // Outer: 1
launch {
printNext() // Outer: 2
}
launch(CounterContext("Inner")) {
printNext() // Inner: 0
printNext() // Inner: 1
launch {
printNext() // Inner: 2
}
}
}
printNext() // Outer: 3
}
테스트 환경과 프로덕션 환경에서 서로 다른 값을 쉽게 주입하기 위해 커스텀 컨텍스트가 사용되는 경우가 있습니다. 그러나 일반적으로 사용되지는 않습니다.
다음은 테스트 환경과 프로덕션 환경에서 서로 다른 값을 주입하는 예시입니다.
data class User(val id: String, val name: String)
abstract class UuidProviderContext :
CoroutineContext.Element {
abstract fun nextUuid(): String
override val key: CoroutineContext.Key<*> = Key
companion object Key :
CoroutineContext.Key<UuidProviderContext>
}
class RealUuidProviderContext : UuidProviderContext() {
override fun nextUuid(): String =
UUID.randomUUID().toString()
}
class FakeUuidProviderContext(
private val fakeUuid: String
) : UuidProviderContext() {
override fun nextUuid(): String = fakeUuid
}
suspend fun nextUuid(): String =
checkNotNull(coroutineContext[UuidProviderContext]) {
"UuidProviderContext not present"
}.nextUuid()
// 테스트하려는 함수입니다
suspend fun makeUser(name: String) = User(
id = nextUuid(),
name = name
)
suspend fun main() {
// 프로덕션 환경일 때
withContext(RealUuidProviderContext()) {
println(makeUser("Michal"))
// 예를 들어 User(id=d260482a-..., name = Michal)
}
// 테스트 환경일 때
withContext(FakeUuidProviderContext("FAKE_UUID")) {
val user = makeUser("Michal")
println(user) // User(id= FAKE_UUID, name=Michal
assertEquals(User("FAKE_UUID", "Michal"), user)
}
}
잡과 자식 코루틴 기다리기
구조화된 동시성의 특성은 다음과 같습니다.
- 자식은 부모로부터 컨텍스트를 상속받습니다.
- 부모는 모든 자식이 작업을 마칠 때까지 기다립니다.
- 부모 코루틴이 취소되면 자식 코루틴도 취소됩니다.
- 자식 코루틴에서 에러가 발생하면, 부모 코루틴 또한 에러로 소멸합니다.
이때, 코루틴을 취소하고 상태를 파악하기 위해 Job이 활용됩니다.
Job이란 무엇인가?
Job은 수명을 가지고 있으며 취소가 가능합니다. Job은 인터페이스이지만 구체적인 사용법과 상태를 가지고 있다는 점에서 추상클래스처럼 다룰 수도 있습니다.
Job의 수명은 상태로 나타냅니다. 다음은 잡의 상태와 상태 변화를 나타낸 도식도입니다.
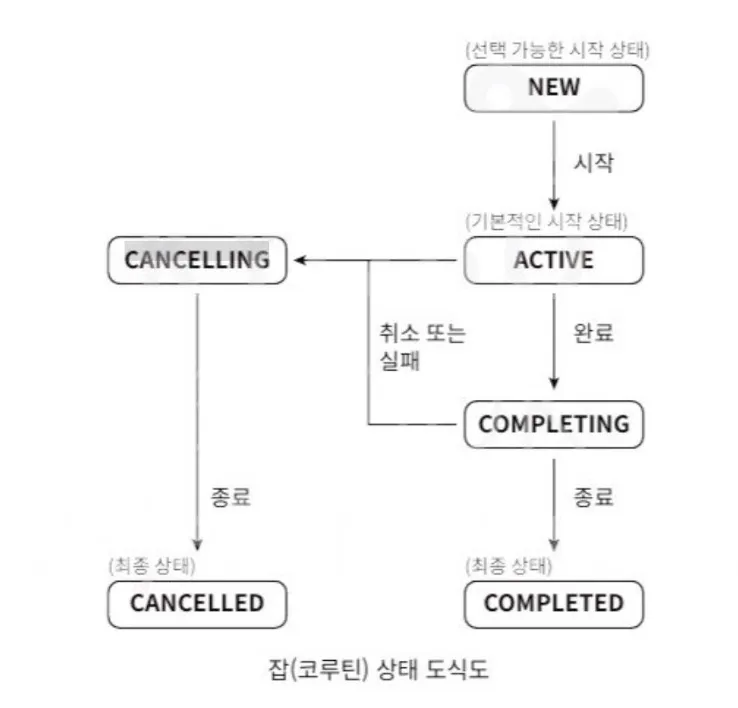
- New 상태
- 지연이 시작되는 코루틴만 New 상태에서 시작
- 작업을 실행해야 Active 상태로 전환 가능
- Active 상태
Job이 실행되고, 코루틴은Job을 수행합니다.Job이 코루틴 빌더에 의해 생성될 때- 코루틴의 본체가 실행되는 상태
- 해당 상태에서 자식 코루틴을 시작할 수 있음
- Completing
- Active에서 실행 완료되면 Completing으로 전환
- 해당 상태에서 자식들을 기다림
- Completed
- 자식들의 실행이 모두 끝난 상태
- Cancelling
- Job이 실행 도중(Active 또는 Completing) 취소되거나 실패된 상태
- 연결을 끊거나 자원을 반납하는 등의 후처리 작업 가능
- Cancelled
- 후처리 작업이 완료된 상태
Job의 여러 상태를 보여주는 예제는 다음과 같습니다.
suspend fun main() = coroutineScope {
// 빌더로 생성된 잡은
val job = Job()
println(job) // JobImpl{Active}@ADD
// 메서드로 완료시킬 때까지 Active 상태입니다
job.complete()
println(job) // JobImpl{Completed}^ADD
// launch는 기본적으로 활성화되어 있습니다
val activeJob = launch {
delay(1000)
}
println(activeJob) // StandaloneCoroutine{Active}@ADD
// 여기서 잡이 완료될 때까지 기다립니다
activeJob.join() // (1초 후)
println(activeJob) // StandaloneCoroutine{Completed}@ADD
// launch는 New 상태로 지연 시작됩니다
val lazyJob = launch(start = CoroutineStart.LAZY) {
delay(1000)
}
println(lazyJob) // LazyStandaloneCoroutine{New}@ADD
// Active 상태가 되려면 시작하는 함수를 호출해야 합니다
lazyJob.start()
println(lazyJob) // LazyStandaloneCoroutine{Active}@ADD
lazyJob.join() // (1초 후)
println(lazyJob) // LazyStandaloneCoroutine{Completed}@ADD
}| 상태 | isActive | isCompleted | isCancelled |
|---|---|---|---|
| New(지연 시작될 때 시작 상태) | false | false | false |
| Active(시작 상태 기본값) | true | false | false |
| Completing(일시적인 상태) | true | false | false |
| Cancelling(일시적인 상태) | false | false | true |
| Cancelled(최종 상태) | false | true | true |
| Completed(최종 상태) | false | true | false |
코루틴 빌더는 부모의 잡을 기초로 자신들의 잡을 생성한다.
코틀린 코루틴 라이브러리의 모든 코루틴 빌더는 자신만의 잡을 생성합니다.
launch의 명시적 반환 타입이 Job이라는 사실을 통해 확인할 수 있습니다.
fun main(): Unit = runBlocking {
val job: Job = launch {
delay(1000)
println("Test1")
}
}async 함수에 의해 반환되는 타입은 Deferred<T> 이며, Deferred<T> 또한 Job 인터페이스를 구현하고 있기 때문에 똑같은 방법으로 사용할 수 있습니다.
fun main(): Unit = runBlocking {
val deferred: Deferred<String> = async {
delay(1000)
"Test"
}
val job: Job = deferred
}Job은 코루틴 컨텍스트이므로 coroutineContext[job]을 사용해 접근하는 것도 가능합니다. 하지만 Job을 좀 더 접근하기 편하게 만들어주는 확장 프로퍼티 job도 있습니다.
// 확장 프로퍼티
val CoroutineContext.job: Job
get() = get(Job) ?: error("Current context doesn't...")
// 사용 예
fun main(): Unit = runBlocking {
print(coroutineContext.job.isActive) // true
}Job은 코루틴이 상속하지 않는 유일한 코루틴 컨텍스트이며, 이는 코루틴에서 아주 중요한 법칙입니다. 모든 코루틴은 자신만의 Job을 생성하며 인자 또는 부모 코루틴으로부터 온 Job은 새로운 Job의 부모로 사용됩니다.
fun main(): Unit = runBlocking {
val name = CoroutineName("Some name")
val job = Job()
launch(name + job) {
val childName = coroutineContext[CoroutineName]
println(childName == name) // true
val childJob = coroutineContext[Job]
println(childJob == job) // false
println(childJob == job.children.first()) // true
}
}부모 Job은 자식 Job 모두를 참조할 수 있으며, 자식 또한 부모를 참조할 수 있습니다. Job을 참조할 수 있는 부모-자식 관계가 있기 때문에 코루틴 스코프 내에서 취소와 예외 처리 구현이 가능합니다.
fun main(): Unit = runBlocking {
val job: Job = launch {
delay(1000)
}
val parentJob: Job = coroutineContext.job
// coroutinecontext [Job]!!
println(job == parentJob) // false
val parentChildren: Sequence<Job> = parentJob.children
println(parentChildren.first() == job) // true
}새로운 Job 컨텍스트가 부모의 Job을 대체하면 구조화된 동시성의 작동 방식은 유효하지 않습니다.
fun main(): Unit = runBlocking {
launch(Job()) { // 새로운 잡이 부모로부터 상속받은 잡을 대체합니다
delay(1000)
println("Will not be printed")
}
}
// 아무것도 출력하지 않고, 즉시 종료합니다.위 예제에서는 부모와 자식 사이에 아무런 관계가 없기 때문에 부모가 자식 코루틴을 기다리지 않습니다. 자식은 인자로 들어온 Job을 부모로 사용하기 때문에 runBlocking과는 아무런 관련이 없게 됩니다.
자식들 기다리기
Job은 코루틴이 완료될 때까지 기다리는데 사용될 수 있다는 장점이 있습니다. 이를 위해 join 메서드를 사용합니다.
join은 지정한 Job이 Completed나 Cancelled와 같은 마지막 상태에 도달할 때까지 기다리는 중단 함수입니다.
fun main(): Unit = runBlocking {
val job1 = launch {
delay(1000)
println("Test1")
}
val job2 = launch {
delay(2000)
println("Test2")
}
job1.join()
job2.join()
println("All tests are done")
}
// (1초 후)
// Test1
// (1초 후)
// Test2
// All tests are done위의 예제에서 join을 사용하지 않는다면, All tests are done 이 출력된 이후 launch가 실행됩니다.
Job 인터페이스는 모든 자식을 참조할 수 있는 children 프로퍼티도 노출시킵니다. 모든 자식이 마지막 상태가 될 때까지 기다리는데 활용할 수 있습니다.
fun main(): Unit = runBlocking {
launch {
delay(1000)
println("Test1")
}
launch {
delay(2000)
println("Test2")
}
val children = coroutineContext[Job]
?.children
val childrenNum = children?.count()
println("Number of children: $childrenNum")
children?.forEach { it.join() }
println("All tests are done")
}
// Number of children: 2
// (1 초 후)
// Test1
// (1초 후)
// Test2
// All tests are done잡 팩토리 함수
Job은 Job() 팩토리 함수를 사용하면 코루틴 없이도 Job을 만들 수 있습니다.
팩토리 함수로 생성하는 Job은 어떤 코루틴과도 연관되지 않으며, 컨텍스트로 사용될 수 있습니다. 즉, 한 개 이상의 자식 코루틴을 가진 부모 Job으로 사용할 수 있습니다.
그러나 Job() 팩토리 함수로 Job을 생성하고 join을 호출할 때, 해당 Job은 여전히 active 상태라서 프로그램이 종료되지 않습니다.
suspend fun main(): Unit = coroutineScope {
val job = Job()
launch(job) { // 새로운 잡이 부모로부터 상속받은 잡을 대채합니다
delay(1000)
println("Text 1")
}
launch(job) { // 새로운 잡이 부모로부터 상속받은 잡울 대채합니다
delay(2000)
println("Text 2")
}
job.join()
// 여기서 영원히 대기하게 됩니다
println("Will not be printed")
}
// (1초 후)
// Text 1
// (1초 후)
// Text 2
// (영원히 실행됩니다.)프로그램을 종료시킬려면, 수동으로 complete를 실행해서 Job을 완료시켜야 합니다.
suspend fun main(): Unit = coroutineScope {
suspend fun main(): Unit = coroutineScope {
val job = Job()
launch(job) { // 새로운 잡이 부모로부터 상속받은 잡을 대채합니다
delay(1000)
println("Text 1")
}
launch(job) { // 새로운 잡이 부모로부터 상속받은 잡울 대채합니다
delay(2000)
println("Text 2")
}
job.complete()
job.join()
println("Will not be printed")
}
// Will not be printed가 출력됨