OneLake 소개
-
Microsoft Fabric의 기반: 레이크하우스(Lakehouse)
1) 구축 기반: OneLake (확장 가능한 스토리지 계층)
2) 처리 엔진: Apache Spark, SQL -
레이크하우스 특징:
1) 데이터 레이크의 유연성 + 데이터 웨어하우스의 분석 능력 결합
2) 구조화/비정형 데이터 모두 처리 가능 -
회사 시나리오:
1) 기존: 구조화된 데이터(주문 내역, 재고, 고객 정보) -> 데이터 웨어하우스 저장
2) 문제: 비정형 데이터(소셜 미디어, 웹 로그) 분석 어려움
3) 해결: Microsoft Fabric 도입, 다양한 데이터 형식 통합 분석 -
Microsoft Fabric의 역할:
1) 유연하고 확장 가능한 데이터 저장소 제공
2) SQL을 사용한 파일/테이블 쿼리 가능
3) 빅데이터 처리 및 분석
OneLake 와 Lakehouse
- OneLake
-
정의: OneLake는 Microsoft Fabric의 확장 가능한 스토리지 계층입니다. 데이터를 저장하고 관리하는 데 사용되며, 다양한 형식의 데이터를 한곳에 통합하여 저장할 수 있는 기능을 제공합니다.
-
기능:
(1) 데이터 통합: 여러 소스(예: Azure, Microsoft 365, AWS)에서 데이터를 가져와 통합된 방식으로 저장할 수 있습니다.
(2) 확장성: OneLake는 클라우드 기반의 스토리지로, 대규모 데이터를 효율적으로 저장하고 관리할 수 있도록 확장 가능한 구조를 제공합니다.
(3) 유연성: 정형 데이터뿐만 아니라 비정형 데이터(예: 로그 파일, 이미지, 동영상 등)도 저장할 수 있는 유연한 저장소입니다.
요약하면, OneLake는 Microsoft Fabric에서 모든 데이터를 저장하는 중심 스토리지입니다.
- Lakehouse
-
정의: Lakehouse는 OneLake를 기반으로 데이터 분석 및 처리를 위한 통합 플랫폼입니다. 이는 데이터 레이크의 유연성과 데이터 웨어하우스의 분석 기능을 결합한 개념입니다.
-
기능:
(1) 데이터 처리 및 분석: Lakehouse는 Apache Spark와 SQL 엔진을 사용하여 저장된 데이터를 쿼리하고 처리할 수 있습니다. 데이터 과학자와 분석가는 이를 통해 구조화된 데이터뿐만 아니라 비구조화된 데이터도 처리할 수 있습니다.
(2) 통합된 데이터 환경: 데이터 레이크의 파일 저장 기능과 데이터 웨어하우스의 테이블 구조를 결합하여 데이터를 단일 환경에서 저장하고 분석할 수 있는 플랫폼을 제공합니다.
(3) 다양한 형식의 데이터 지원: Lakehouse는 다양한 형식의 데이터를 저장하고 SQL 쿼리로 분석할 수 있습니다. 이를 통해 비정형 데이터와 정형 데이터를 하나의 플랫폼에서 처리할 수 있습니다. -
차이점 요약:
(1) OneLake는 데이터 저장소 자체로, 다양한 형식의 데이터를 확장 가능하고 유연하게 저장할 수 있는 기반 스토리지입니다.
(2) Lakehouse는 OneLake 위에서 데이터를 처리하고 분석할 수 있는 플랫폼으로, 데이터 레이크와 데이터 웨어하우스의 기능을 통합한 것입니다.
(3) OneLake는 데이터를 저장하는 기본 계층이고, Lakehouse는 그 위에서 데이터를 분석하는 통합된 솔루션이라고 보면 됩니다.
Lakehouse 소개
- Lakehouse 개요
(1) 구성: 데이터 레이크 위에 델타 형식 테이블을 사용해 구축
(2) 특징: SQL 기반 분석 기능 + 데이터 레이크의 유연성 및 확장성 결합
(3) 데이터 저장: 모든 데이터 형식 지원, 다양한 분석 도구 및 프로그래밍 언어 사용 가능
(4) 클라우드 기반: 자동 확장, 고가용성, 재해 복구 기능 제공
-
Lakehouse의 주요 이점
(1) Spark 및 SQL 엔진: 대규모 데이터 처리 및 머신러닝/예측 분석 지원
(2) 스키마 온 리드(schema-on-read): 사전 정의된 스키마 없이 필요할 때 스키마 정의
(3) ACID 트랜잭션 지원: 델타 레이크 테이블을 통해 데이터 일관성 및 무결성 보장
(4) 단일 접근 지점: 데이터 엔지니어, 데이터 과학자, 데이터 분석가가 모두 동일한 장소에서 데이터 접근 가능
(5) 확장 가능한 분석 솔루션: 데이터 일관성을 유지하면서 분석 확장 가능 -
Microsoft Fabric에서의 Lakehouse
(1) 생성 위치: Microsoft Fabric의 프리미엄 워크스페이스에서 레이크하우스 생성 가능
(2) 데이터 로드: 로컬 파일, 데이터베이스, API 등 다양한 소스에서 데이터 로드 가능
(3) 데이터 자동 적재: Data Factory Pipelines, Dataflows(Gen2) 통해 데이터 적재 자동화 가능
(4) 외부 데이터 연결: Azure Data Lake Store Gen2, Microsoft OneLake 외부 위치에서 데이터 가져오기 지원
(5) Lakehouse Explorer: 파일, 폴더, 단축키, 테이블 탐색 및 내용 확인 가능 -
데이터 처리 및 변환
(1) Notebooks 또는 Dataflows(Gen2): 데이터 탐색 및 변환
(2) Dataflows(Gen2): Power Query 기반으로 Excel, Power BI 사용자에게 친숙한 시각적 변환 도구 제공
(3) Data Factory Pipelines: Spark, Dataflow 및 기타 활동을 오케스트레이션하여 복잡한 데이터 변환 프로세스 구현 가능 -
활용 가능 작업
(1) SQL 쿼리
(2) 머신러닝 모델 학습
(3) 실시간 인텔리전스
(4) Power BI를 통한 보고서 생성 -
데이터 거버넌스 적용
(1) 데이터 분류
(2) 접근 제어
Microsoft Fabric Lakehouse
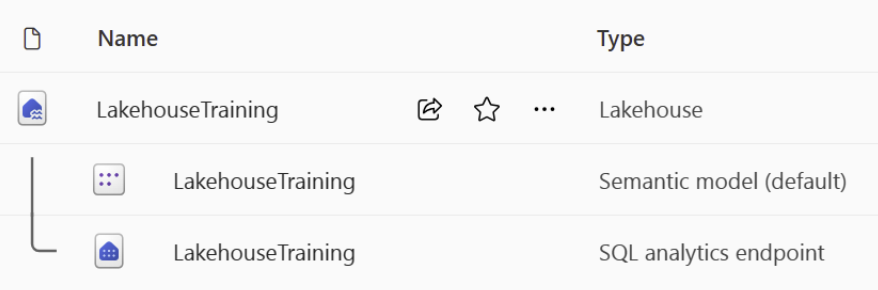
- Lakehouse 구성
1) 레이크하우스 : 파일, 폴더 및 테이블 데이터와 상호 작용할 수 있는 레이크하우스 스토리지 및 메타데이터.
2) 의미 모델(기본값) : 레이크하우스의 테이블을 기반으로 자동으로 생성된 의미 모델입니다. Power BI 보고서는 의미 모델에서 빌드할 수 있습니다.
3) SQL 분석 엔드포인트 : Transact-SQL을 사용하여 데이터에 연결하고 쿼리할 수 있는 읽기 전용 SQL 분석 엔드포인트입니다.
- Lakehouse 데이터 작업모드
1) Lakehouse : Lakehouse에서 테이블, 파일, 폴더를 추가하고 상호 작용 가능.
2) SQL 분석 엔드포인트 : SQL을 사용하여 레이크하우스의 테이블을 쿼리하고 해당 관계 의미 모델을 관리.
Fabric Lakehouse에 데이터 적재하기
-
업로드
1) 설명: 로컬 파일이나 폴더를 직접 lakehouse로 업로드.
2) 사용 사례: 업로드 후 파일 데이터를 탐색하고 처리한 후 결과를 테이블에 로드할 수 있음. -
데이터플로우 (Gen2)
1) 설명: Power Query Online을 사용하여 다양한 소스로부터 데이터를 가져와 변환.
2) 사용 사례: 변환된 데이터를 lakehouse 테이블에 직접 로드. -
노트북
1) 설명: Fabric에서 노트북을 사용해 데이터를 적재하고 변환.
2) 사용 사례: 처리된 데이터를 테이블이나 파일에 로드. -
Data Factory 파이프라인
1) 설명: 데이터를 복사하고 처리 작업을 조정.
2) 사용 사례: 결과를 테이블이나 파일로 로드.
Shortcut을 사용한 데이터 접근
-
Shortcut 개요
1) 설명: 외부 저장소에 있는 데이터를 이동하지 않고 lakehouse에 통합할 수 있는 Shortcut 기능.
2) 사용 사례: 다른 스토리지 계정이나 클라우드 제공자에 있는 데이터를 lakehouse에 Shortcut으로 통합 가능. -
권한 및 자격 증명
1) 설명: OneLake가 원본 데이터 권한을 관리하며, 사용자의 신원이 데이터 접근 권한을 인증.
2) 사용 사례: Shortcut을 통해 데이터에 접근하려면 사용자가 대상 스토리지에 적절한 권한을 가지고 있어야 함. -
다른 도구와의 통합
1) 설명: Shortcut은 Lakehouse 및 KQL 데이터베이스에서 생성되며 폴더로 표시됨.
2) 사용 사례: Spark, SQL, Real-Time Intelligence, Analysis Services 등은 모두 이 Shortcut을 통해 데이터를 쿼리 가능.
Lakehouse에서 데이터를 탐색하고 변환하는 방법
-
Apache Spark
: 각 Fabric lakehouse는 Spark 풀을 사용하여 파일과 테이블의 데이터를 처리할 수 있음. Scala, PySpark, 또는 Spark SQL을 사용하여 데이터를 변환. -
노트북
: 인터랙티브 코딩 인터페이스로, 코드를 통해 데이터를 읽고 변환하며 lakehouse에 테이블 또는 파일로 직접 기록 가능. -
Spark 작업 정의
: 필요에 따라 또는 예약된 스크립트를 사용하여 lakehouse 내 데이터를 Spark 엔진으로 처리. -
SQL 분석 엔드포인트
: 각 lakehouse는 SQL 분석 엔드포인트를 제공하며, 이를 통해 Transact-SQL 명령어로 데이터를 쿼리하고, 필터링하고, 집계하는 등의 작업 수행 가능. -
데이터플로우 (Gen2)
: 데이터를 적재할 뿐만 아니라, 데이터 변환을 위해 Power Query를 사용해 추가적인 변환을 수행하고, 변환된 데이터를 lakehouse에 다시 적재 가능. -
데이터 파이프라인
: 데이터플로우, Spark 작업, 기타 제어 흐름 로직 등을 이용해 lakehouse에서 복잡한 데이터 변환 논리를 오케스트레이션.
Lakehouse에서 데이터를 분석 및 시각화
1) lakehouse 테이블의 데이터는 관계형 모델을 정의하는 의미 체계 모델(semantic model)에 포함됨. 이 의미 체계 모델을 편집하거나 새로 만들어 사용자 정의 측정값, 계층 구조, 집계 등을 정의할 수 있음. 2) 사용 사례: Power BI를 데이터 시각화 도구로 사용하여 lakehouse의 중앙 저장소 및 테이블 형식의 스키마를 기반으로 데이터를 분석 및 시각화할 수 있으며, 이를 통해 단일 플랫폼에서 종단 간 분석 솔루션 구현 가능.Lakehouse 실습
https://learn.microsoft.com/en-us/training/modules/get-started-lakehouses/5-exercise-lakehouse
참조문서 : https://learn.microsoft.com/en-us/training/modules/get-started-lakehouses/1-introduction
