Garbage Collector
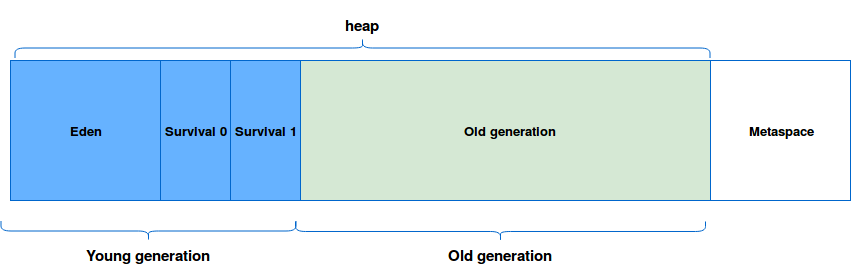
Garbage Collector(GC)
unreachable object를 Heap에서 비워주는 작업을 하는것이 GC인데 어떻게 작동하는지, 어떤 알고리즘을 이용해서 unreachable을 판단하는지 알아보자.
GC 일어나는 시점
일반적으로 언어 런타임은 힙이 소진 되고 mutator thread의 메모리 할당 요청을 충족하는 데 사용할 수 있는 메모리가 더 이상 없음을 발견하면 GC를 트리거한다.
def memory_allocator(n):
# Allocate and return 'n' bytes on the heap.
ref = allocate(n)
if not ref:
# Oops. We are out of memory. Invoke GC.
gc()
# Retry allocation
ref = allocate(n)
if not ref:
# Let's give caller a chance to do something about it.
# i.e. delete references, purge caches etc.
raise OutOfMemory
return ref
//참조: https://www.educative.io/courses/a-quick-primer-on-garbage-collection-algorithms/jy6vGC 알고리즘
- Reference Counting
설명
Reference Counting은 어떤 한 동적 단위(객체, Object)가 참조 카운터 필드를 가지고 이 단위 객체가 참조(참조 복사)되면 참조 카운터를 늘리고 참조한 다음 더이상 사용하지 않게 되면 참조 카운터를 줄이면 된다. 보통 참조 카운터가 0이 되면 더이상 유효한 단위 객체로 보지 않아 메모리에서 제거한다.
struct object
{
int ref;
};
struct object* object_new(void)
{
struct object* p=malloc(sizeof(struct object));
p->ref=1;
return p;
}
int object_ref(struct object* p)
{
return (p->ref++);
}
int object_unref(struct object* p)
{
if ((p->ref--)!=0)
return p->ref;
else
{
free(p);
return 0;
}
}다음 코드와 같이 참조가 늘어날때마다 참조 카운터를 증가 시키고 참조 필요 없게되면 해제 해야한다.
장점:
- 수동 메모리 관리와 마찬가지로 Reference Counting은 마지막 참조가 파괴되자마자 개체가 파괴되도록 보장하며 일반적으로 CPU 캐시, 해제할 개체 또는 직접 가리키는 메모리에만 액세스한다. 따라서 CPU 캐시 및 가상 메모리 작동에 심각한 부정적인 영향을 미치지 않는 경향이 있다.
- 구현 용이하다.
문제점
- 순환 참조 오류로 인해 잘못된 참조 파괴가 생기거나 또는 단위 객체가 고아(orphaned)가 될 수 있다. 이를 해결하기 위해서 순환관계의 참조관계는 약한 참조를 이용하기도 한다.
- 다중 스레드 환경 에서 사용될 때 이러한 수정(증가 및 감소)은 비교 및 교환과 같은 원자적 작업 이 필요할 수 있고 적어도 여러 스레드 간에 공유되거나 잠재적으로 공유되는 모든 개체에 대해 원자 연산은 다중 프로세서에서 비용이 많이 들어서 stop-world와 함께 사용 돼야한다.
- real-time 동작을 제공하지 않는다. 왜냐하면 포인터 할당으로 인해 스레드가 다른 작업을 수행할 수 없는 동안에만 할당된 총 메모리 크기에 의해서만 제한되는 많은 개체가 재귀적으로 해제될 수 있기 때문이다. 참조되지 않은 개체의 해제를 다른 스레드에 위임하여 추가 오버헤드를 대가로 이 문제를 피할 수 있다.
(4) 사용되는 곳
- Objective-C
- Swift programming
참조
https://en.wikipedia.org/wiki/Reference_counting
https://en.wikipedia.org/wiki/Garbage_collection_(computer_science)#Reference_counting
https://www.geeksforgeeks.org/types-references-java/
https://www.educative.io/courses/a-quick-primer-on-garbage-collection-algorithms/jR8ml
- Mark Sweep Collection
설명 및 원리
모든 가비지 수집 알고리즘은 2가지 기본 작업을 수행해야 합니다. 첫째, 도달할 수 없는 모든 개체를 감지할 수 있어야 하고 둘째, 가비지 개체가 사용하는 힙 공간을 회수하고 해당 공간을 프로그램에서 다시 사용할 수 있도록 해야 합니다. 위의 작업은 다음과 같이 나열되고 추가로 설명된 대로 Mark 및 Sweep 알고리즘에 의해 두 단계로 수행됩니다.
-
Mark
객체가 생성될 때 해당 마크 비트는 0(거짓)으로 설정된다. Mark 단계에서 도달 가능한 모든 객체(또는 사용자가 참조할 수 있는 객체)에 대해 표시된 비트를 1(true)로 설정한다. 이제 이 작업을 수행하려면 그래프 순회만 수행하면 되며 깊이 우선 검색 접근 방식을 이용한다. 여기에서 우리는 모든 객체를 노드로 간주할 수 있으며 이 노드(객체)에서 도달할 수 있는 모든 노드(객체)를 방문하고 도달 가능한 모든 노드를 방문할 때까지 계속한다. -
Sweep
개체를 "소거"한다. 즉, 연결할 수 없는 모든 개체의 힙 메모리를 지운다. 표시된 값이 false로 설정된 모객체는 힙 메모리에서 지워지고 다른 모든 객체(도달 가능한 객체)에 대해서는 표시된 비트가 true로 설정된다. -
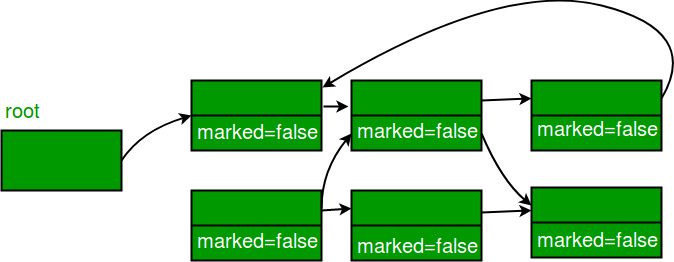
예시
1. 모든개체는 False로 되어있다.
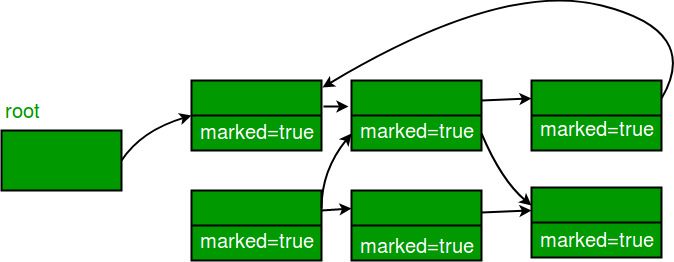
2. 도달가능한 개체는 true로 변환
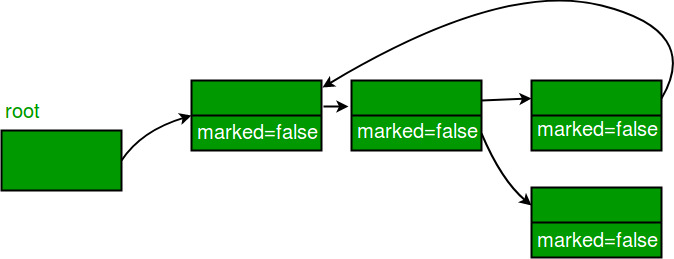
3. 도달할 수 없는 개체는 힙에서 지움(sweep)
장점
- 순환 참조의 경우를 처리하며 순환의 경우에도 이 알고리즘은 무한 루프로 끝나지 않습니다.
- 알고리즘을 실행하는 동안 발생하는 추가 오버헤드는 없습니다.
단점
- mark-and-sweep 접근 방식의 주요 단점은 가비지 수집 알고리즘이 실행되는 동안 정상적인 프로그램 실행이 일시 중단된다. 최적화 하기 힘들다.
- 또 다른 단점은 Mark and Sweep Algorithm이 프로그램에서 여러 번 실행된 후 도달 가능한 개체가 사용되지 않는 많은 작은 메모리 영역으로 분리된다.

다음 그림에서 회색영역은 할당된 메모리이고(지워지지 않은 부분), 휜색영역은 지워졌고, 할당 가능한 영역이라고 했을때, 그 크기를 차례대로 1,1,2,3,5 라고 하면 총 12 단위의 남는 메모리가 있지만 연속적이지 않기에, 6이상의 메모리를 할당할 수 없게 되고 OutOfMemory 발생한다. 이를 Fragmentation이라고 하고, compaction(압축)을 이용해서 위문제를 해결할 수 있다.
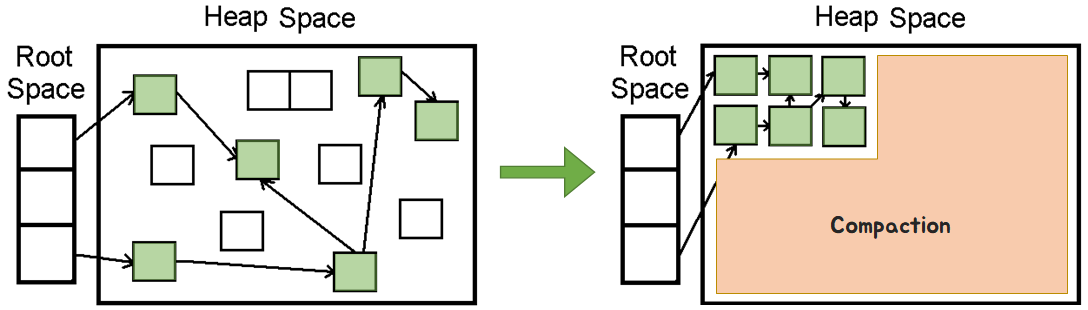
다음처럼 흩어져 있는 메모리 영역을 압축정렬 시켜서 공간을 정리할 수 있는데 이는 옵션으로 설정 가능하다.
참조
https://www.geeksforgeeks.org/mark-and-sweep-garbage-collection-algorithm/
https://joel-dev.site/94
