.png)
TDL
NOTE3
-
Web Scraping , 크롤링
웹 페이지에 있는 데이터를 모으는 작업 -
HTML, CSS, JavaScript 유튜브
HTML, CSS, JavaScript
가져다, 놓고, 꾸미고 시킨다. -
HTML
Hypertext Markup Language 웹 페이지가 어떻게 구성되는지 알려주는 마크업 언어
화면에 어느위치에 이정도 갖다 놓는 수단. 웹의 토대 -
HTML Element(요소)
head,body,div,li등
<br> : 빈 줄 추가
<hr> : 수평으로 줄 긋기 -
HTML Children
하나의 HTMI 요소 안에 다른 요소도 추가 가능

-
CSS
Cascading Style Sheets 시트. HTML이 한 것들을 이렇게 보여라! 하고 꾸며주는 문서
웹페이지 문서가 어떻게 표현되는지 알려주는 스타일시트 언어.
HTML에서도 태그 내에 스타일에 대해 알려줄 수 있지만, 스타일에 관한 내용이 많을수록 HTML이 복잡해지고 편의성도 떨어진다. -
CSS Selector
특정 요소를 선택할 수 있는 방법
이러한 셀렉터들을 활용해 더 쉽게 원하는 요소들을 선택해 접근할 수 있음
나중에 DOM에서도 이러한 셀렉터들을 이용해 원하는 용소들으 가지고 작업할 수 있다.
- 타입 선택자 (type selector) : CSS 타입에 따라 선택할 수 있다(ex.
pdiv등) - 아이디 선택자 (id selector) : id에 따라 선택할 수 있다.
- 클래스 선택자 (class selector) : class에 따라 선택할 수 있다.
- CSS 상속
스타일에 대한 문서를 작성할 때 주의할 점 중 하나이다. css는 요소의 위치에 따라 상위 요소의 스타일을 상속받도록 되어 있다.

p태그는 아무런 스타일이 적용이 되어 있지 않지만 상위 요소인 div의 영향을 받게 된다. 이러한 부분들을 통해 CSS는 반복 작업을 걸치지 않아도 되지만, 상속을 어떻게 받을지 잘 생각해야한다.
-
CSS 클래스
중요한 것 중 하나가 클래스 개념이다. 어떤 특정 요소들의 스타일을 정하고 싶을 때에 사용이 된다. 동시에 여러개의 요소들에 대한 스타일을 정할 때에는 보통 클래스를 지정해서 상속을 받도록 정한다.

위와 같은 방식으로 클래스를 지정하면 CSS에서는 따로 해당 클래스에 대한 정의를 내릴 수 있고 웹 브라우저를 통해 열었을 때도 적용이 되도록 할 수 있다.
.를 활용해 클래스 정의.

또한 여러개의 클래스를 부여할 수도 있다. CSS에서는 따로따로 클래스를 정의해 스타일을 지정할 수 있다. -
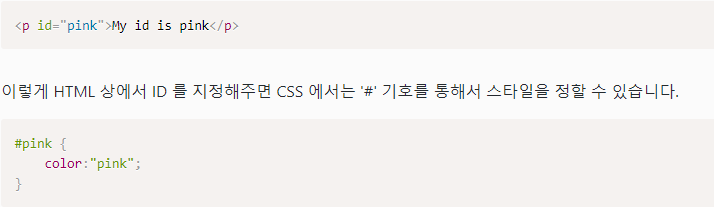
CSS ID
사실 ID도 여러 개의 HTML 요소에 부여할 수 있긴하지만 이름처럼 ID는 특정 HTML요소를 가리킬 때에만 사용이 된다.
- JavaScript
프로그래밍 언어. 원래는 브라우저에서 웹사이트를 돌리는 목적으로 만들어진 대우못받는 언어였지만, Node.js가 브라우저 바깥 세상으로 꺼내오면서 지금은 good
-
DOM (Document Object Model)
문서
자바스크립트는 Dom을 통해 HTML을 제어한다.
문서에 프로그래밍적으로 액세스하고 변형하기 위한 프로그래밍 인터페이스
DOM처리순서 1. 제어할 대상찾기 2.대상의 메소드 실행 또는 이벤트 핸들러 설치
돔을 제어해서 웹페이지를 제어한다. -
pip install requests
정보요청 -
pip install beautifulsoup4
내용 저장 -
F12 코드 불러오기
import requests
from bs4 import BeautifulSoup
req = requests.get("url")
req.text
soup = BeatifulSoup(req.content, "html.parser")
`req.content = byte형태`
print(soup) # 보기 좋게 정렬됨
span_list = soup.find("tbody").find_all("span")
soup.find("tbody").find_all("span")[0].text #모든 span 찾고 0번째 그리고 txt만 추출
span_list2 = []
for span in span-list:
span_list2.append(span.text)
print(span.text)