.png)
NOTE 2
- Image Segmentation (이미지 분석)
- Image Augmentation (이미지 증강)
- Object Recognition (물체 인식)
TDL
-
Computer Vision 컴퓨터 비전
: Deep Learning, CNN -
CNN
: Image Classification, Object Detection(물체감지), Image Generation(이미지 생성) 등 많은 분야에 쓰임. CNN을 이미지 분석에 사용할 경우, Output은 벡터보다는 이미지(2차원배열)이 된다. -
Image Segmentation
: 이미지의 각각의 픽셀들을 특정 클래스로 분류하는 것. -
Semantic Segmentation
: 이미지에 있는 객체를 픽셀 단위로 분류하는 것.
목표는 WH3 크기의 이미지를 받아서 전체 픽셀의 예측 클래스를 담고 있는 W*H 배열을 생성하는 것
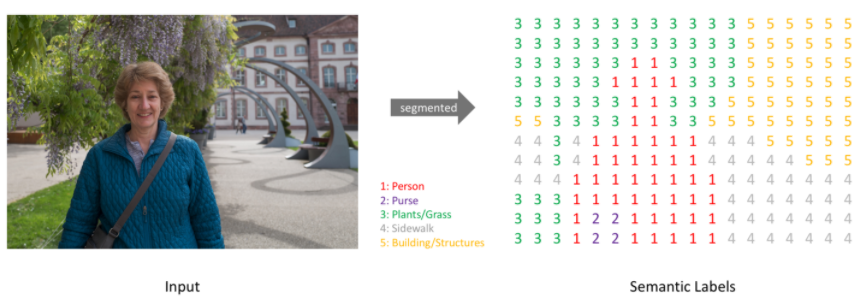
이미지에서 특정 픽셀이 어느 개체 종류에 속하는지. 예를 들어 야외 이미지에서 하늘, 땅, 나무, 사람 등을 분석할 수 있다.
Semantic Segmentation(이미지 분석)은 주변에 감싸는 박스를 생성하는 이미지 인식과 다른 문제이다. 같은 클래스에 속하는 서로 다른 개체들은 분류할 필요가 없음.
이미지를 분석하기 위해서, 이미지에 대한 더욱 높은 수준의 이해가 필요하다. 개체가 존재한다는 것 말고도, 어느 픽셀들이 어느 개체를 나타내는지 파악할 수 있어야 한다.
이미지 분석은 전체적인 이미지를 해석하는데 있어 가장 중요한 작업 중 하나라고 할 수 있다.
-
이미지 분석 적용분야
: 의학 사진 자동 분석 ( ex. 암 자동 감지), 자동주행차(자기가 운전할 수 있는 영역 인식), 위성 이미지 분석(지형분석) 등 -
FCN(Fully Convolutional Network)
: 이미지 분석의 가장 대표적인 모델
AlexNet, VGGNet 등 이미지 분류용 CNN 알고리즘들은 일반적으로 Convolution Layer와 Fully Connected 층들로 이루어져 있다. 항상 입력이미지를 네트워크에 맞는 고정된 사이즈로 작게 만들어 입력해준다. 그러면 네트워크는 그 이미지가 속할 클래스를 예측해서 알려준다.
입력된 고양이 이미지의 클래스를 tabby cat(얼룩무늬 고양이)라고 예측하였다.
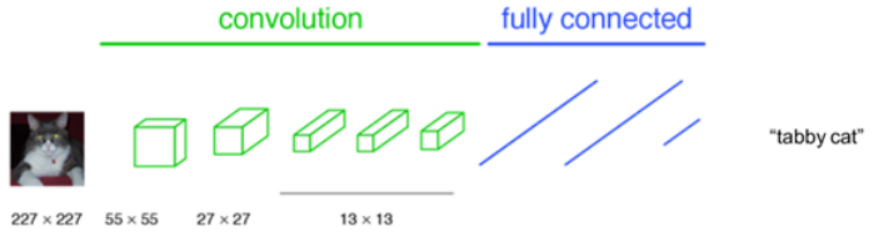
이 분류용 CNN 알고리즘들은 이미지에 있는 물체가 속하는 클래스를 예측해낼 수 있지만, 그 물체가 어디에 존재하는지 예측해낼 수 없다. 왜냐면 네트워크 후반부의 Fully connected 층에 오면서 위치정보가 소실되었기 때문이다. 따라서 AlexNet, VGGNet 등과 같은 알고리즘들을 수정 없이 이미지 분석 과제에 그대로 사용하는 것은 불가능하다.
FCN 개발자들은 위치정보가 소실되지 않기 위해 그리고 어떠한 크기의 입력이미지도 허용하기 위해 알고리즘을 발전시켰다. 먼저 고정된 크기의 인풋만을 허용하는 Fully connected층을 1*1 convolution layer로 바꿔준다.
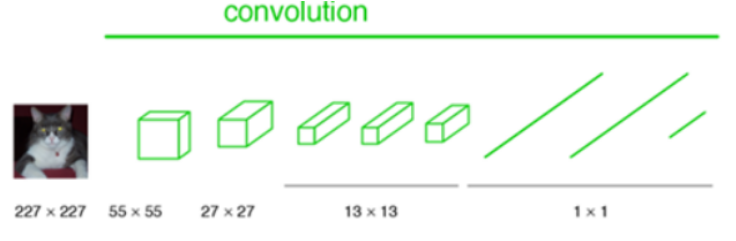
결과적으로 네트워크 전체가 Convolution Layer들로 이루어지게 된다. Fully Connected층이 없어졌으므로 이제 더이상 입력 이미지의 크기에 제한을 받지 않는다.
이제 어떠한 사이즈 H W의 이미지도 이 네트워크에 입력될 수 있다.
여러 층의 Convolution Layer들을 거치고 나면 특성맵(Feature Map)의 크기가 H/32 W/32가 되는데, 그 특성맵의 한 픽셀이 입력이미지의 32 * 32 크기를 대표한다. 즉, 입력이미지의 위치 정보를 대략적으로 유지하고 있는 것이다.
여기서 중요한 건 Convolution Layer들을 거치고 나서 얻게 된 마지막 특성맵의 갯수는 훈련된 클래스의 갯수와 동일하다는 것이다.
21개의 클래스로 훈련된 네트워크라면 21개의 특성맵을 산출한다. 그리고 각 특성맵은 하나의 클래스를 대표한다. 만약 고양이 클래스에 대한 특성맵이라면 고양이가 있는 위치의 픽셀값들이 높고, 강아지 클래서에 대한 특성맵이라면 강아지 위치의 픽셀값들이 높다.
그 다음, 대략적인 특성맵들의 크기를 다시 원래 이미지의 크기로 복원해주어야 한다.(Upsampling)
이미지의 모든 픽셀에 대해서 클래스를 예측하는 dense prediction을 해주는 것이 이미지 분석의 목적이기 때문이다.
- Upsampling
: 업샘플링을 통해 각 클래스에 해당하는 대략적인 특성맵들을 원래 사이즈로 크기를 키워준다. 그리고 Upsampling된 특성맵들을 종합해서 최종적인 segmentation map을 만들게 된다.
간단히 말해 각 픽셀당 확률이 가장 높은 클래스를 선정해주는 것이다. 만약 (1,1) 픽셀에 해당하는 클래스당 확률값들이 강아지 0.45, 고양이 0.94, 나무 0.02, 호랑이 0.21 이런 식이라면, 0.94로 가장 높은 확률을 산출한 고양이 클래스를 (1,1) 픽셀의 클래스로 예측하는 것이다. 이런식으로 모든 픽셀이 어느 클래스에 속하는지 판단한다.

그런데 단순히 upsampling을 시행하면, 특성맵의 크기는 원래 이미지 크기로 복원되고, 그것들로부터 원래 이미지 크기인 segmentation map을 얻게 되지만 여전히 대략적인, 즉 디테일 하지 못한 segmentation map을 얻게 된다.
1/32 만큼 줄어든 특성맵들을 단숨에 32배만큼 upsampling 했기 때문에 당연히 대략적일 수 밖에 없다. 이렇게 단숨에 32배 upsampling 하는 방법을 논문에서는 FCN-32s라고 소개하고 있다.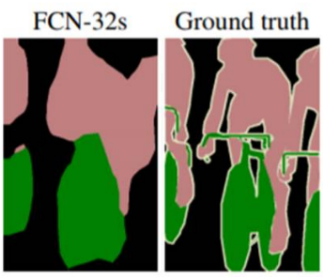
위 그림을 보면 실제상황과 비교해서 FCN-32s로 얻은 segmentation map은 많이 뭉뚱그려져 있고 디테일하지 못함을 알 수 있다.
여기서 더 디테일한 segmentation map을 얻기 위해서 skip combining이라는 기법이 나왔다.
- Skip combining
컨볼루션과 풀링 단계로 이뤄진 이전 단계의 컨볼루션층들의 특성맵을 참고해 upsampling 해주면 좀 더 정확도를 높일 수 있지 않을까 생각하게된다. 왜냐하면 이전 컨볼루션층들의 특성맵들이 해상도 면에서는 더 낫기 때문이다. 이렇게 바로 전 convolution layer들의 특성맵(pool4)와 현재 층의 특성맵(conv7)을 2배 upsampling한 것을 더한다. 그 다음 이것을 16배 upsampling으로 얻은 특성맵들로 segmentation map을 얻는다.
이 방법을 FCN-16s라고 부른다.
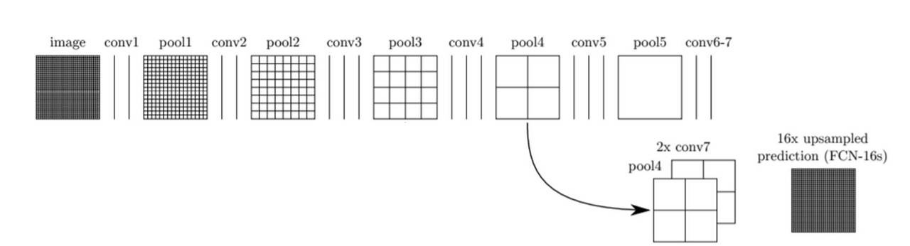
또 더 나아가 convolution layer의 결과도 참고해 특성맵들을 얻고, 또 그 특성맵들로 segmentation map을 구할 수도 있다. FCN-8s라고 한다.
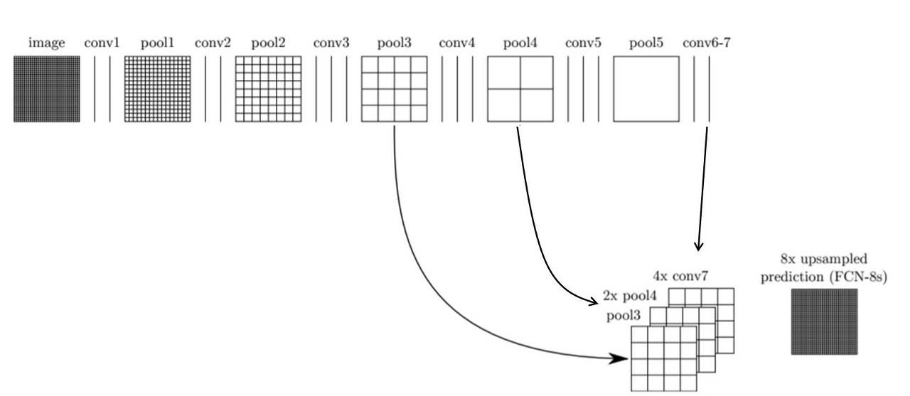

갈수록 점점 더 세밀하고 정교해졌음을 알 수 있다. 다른 논문에서, 또는 웹상에서 누군가 FCN을 말할때는 보통 FCN-8s를 의미한다고 해도 무방하다.
#encoder
img_input = Input(shape=(input_height,input_width , 3 ))
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same')(img_input)
conv1 = Dropout(0.2)(conv1)
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same')(conv1)
pool1 = MaxPooling2D((2, 2))(conv1)
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same')(pool1)
conv2 = Dropout(0.2)(conv2)
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv2)
pool2 = MaxPooling2D((2, 2))(conv2)
#decoder
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same')(pool2)
conv3 = Dropout(0.2)(conv3)
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv3)
up1 = concatenate([UpSampling2D((2, 2))(conv3), conv2], axis=-1)
conv4 = Conv2D(64, (3, 3), activation='relu', padding='same')(up1)
conv4 = Dropout(0.2)(conv4)
conv4 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv4)
up2 = concatenate([UpSampling2D((2, 2))(conv4), conv1], axis=-1)
conv5 = Conv2D(32, (3, 3), activation='relu', padding='same')(up2)
conv5 = Dropout(0.2)(conv5)
conv5 = Conv2D(32, (3, 3), activation='relu', padding='same')(conv5)
: con1과 con2는 decoder layer에서 skip combining용도로 쓰일 중간 결과를 지니고 있다.
pool2에서는 encoder 층의 최종 결과가 나온다.
- 손실함수 (Loss Function)
: 모델의 출력의 각각의 픽셀들은 실제 입력 이미지의 각 픽셀과 비교되고, 이에 standard cross-entropy 손실함수를 적용하게 된다.
