Node.js와 Kafka를 활용한 데이터 스트리밍 시스템 구성하기
Apache Kafka는 LinkedIn이 개발하여 2011년 오픈소스로 공개한 분산형 이벤트(데이터) 스트리밍 플랫폼입니다. 혹은 메세지 브로커라고 표현하기도 하죠. 서비스 정의에서 알 수 있듯이 Kafka는 지속적으로 생성되는 스트리밍 데이터를 처리하는 데에 특화되어 있습니다. Kafka의 구조와 동작 원리를 이해하기 전에 스트리밍 데이터의 특징을 먼저 살펴보겠습니다.
스트리밍 데이터
스트리밍(Streaming)이라는 단어는 아마 유튜브나 멜론과 같은 미디어 관련 서비스를 이용해 본 분들이라면 한 번 쯤은 들어보셨을 텐데요, 영상이나 음악 데이터를 서버에서 실시간으로 내려받는 것을 가리키는 용어이죠.
우리가 다루게 될 스트리밍 데이터 역시 실시간으로 처리된다는 특징이 있습니다. 일상생활에서 많이 사용하고 있는 대중교통 모바일 앱을 떠올려 볼까요? 앱을 통해 버스가 어느 위치에 있는지, 잔여석은 얼마나 있는지 등 필요한 정보를 실시간으로 확인할 수 있습니다. 다수의 사람들에게 수많은 버스의 실시간 데이터를 안정적이고 효율적으로 제공하기 위해서는 이를 처리할 중개 역할이 필요하죠. 이 때, 메세징 큐나 이벤트 스트리밍 플랫폼을 도입을 검토하게 됩니다.
AWS에서 공개한 스트리밍 데이터란 무엇입니까? 페이지의 내용에 따르면 스트리밍 데이터는 다음과 같이 5가지의 특성을 지닙니다.
- 시간순 중요성(Chronologically significant)
- 지속적 흐름(Continuously flowing)
- 고유성(Unique)
- 비균질성(Nonhomogeneous)
- 불완전성(Imperfect)
Kafka

Kafka 소개
Kafka의 공식 홈페이지의 서비스 소개 페이지에 따르면 이벤트 스트리밍을 인체의 중추신경계에 해당하는 디지털 시스템이라고 설명하고 있습니다. 외부의 자극을 신체의 감각으로 수용하여 뇌로 전달하는 중추신경계와 같이 Kafka 역시 실시간으로 발생하는 다양한 이벤트를 전달 받아 적재적소에 맞게 활용할 수 있도록 하는 것이죠.
Kafka에서 이벤트를 수집하거나 Kafka에 수집된 이벤트에 접근할 때에는 TCP 프로토콜을 기반으로 통신이 일어나게 됩니다. 데이터가 모이는 Kafka 서버인 브로커는 단일 혹은 복수로 구성된 클러스터 형태를 띄고 있으며, 재해 혹은 기타 불가항력의 상황에 처해 특정 서버가 불능 상태에 빠지더라도 클러스터 내 다른 서버가 이를 처리할 수 있도록 구성할 수 있습니다.
Kafka 구성 요소 및 구조
이번 글에서 가장 중요하게 다뤄지는 것이 바로 앞에서 미리 설명드렸던 스트리밍 데이터 입니다. 개별 스트리밍 데이터를 보통 이벤트 혹은 메세지라고 하며, Kafka에서 다뤄지는 이벤트는 키, 값, 시간, 기타 메타데이터 등으로 구성됩니다. 다음은 json 형식의 이벤트 예시입니다.
{
"Key": "1234-1234-1234-1234",
"Value": "합정역 - 승차 태그",
"Timestamp": "2025. 3. 21. 목요일 15:26"
}이벤트를 게시하는 주체는 생산자(Producer), 구독하는 주체는 소비자(Consumer)라고 합니다. Kafka 설계의 핵심은 바로 이 두 주체가 완전히 독립적이며 영향을 서로 미치지 않는다는 데에 있습니다. 만약 이 둘의 주체가 강하게 결합되어 있다면 쉽게 시스템을 확장할 수 없었을 것입니다.
생산자가 게시한 이벤트는 Topic이라는 공간에 분리되어 저장됩니다. '지하철' 이라는 Topic에 위의 예시 이벤트를 저장한다고 생각하면 이해가 쉽습니다. 소비자는 Topic을 구독하여 필요에 따라 이벤트를 활용하게 되며, RabbitMQ와 같은 메세징큐와 달리 소비자가 이벤트를 사용하더라도 이를 바로 삭제하지 않습니다. 대신, Topic 별로 보관기간을 설정하여 만료된 데이터를 삭제하는 기능을 지원합니다.
이벤트가 시스템 내외의 영향으로 유실되거나 손실되지 않도록 Kafka는 하나의 Topic을 여러 브로커로 파티셔닝하는 전략을 취합니다. 클라이언트는 한 번에 여러 Kafka 브로커에 접근하여 이벤트를 읽고 쓰기 때문에 높은 확장성을 확보할 수 있게 되었습니다. 여기서 Kafka는 소비자가 요청하는 이벤트를 시간 순서에 맞게 정확히 제공하는 역할을 수행합니다.
KRaft - Kafka Raft
기존 Zookeeper 방식
Zookeeper는 메타 데이터의 유지와 분산 서비스 동기화 등을 제공하는 중앙 집중식 서비스입니다. Kafka와 함께 사용하는 경우 외부에 독립적으로 구성되어 클러스터의 메타 데이터를 관리하고 각 브로커 들이 안정적으로 동작할 수 있도록 돕습니다. Kafka의 브로커 내에 생성된 토픽과 파티션에 대한 모든 정보를 Zookeeper가 수집하여 상태 정보나 동기화에 이상이 있는지를 체크하는 것이 주요한 역할이죠.
KRaft 방식으로의 변화
오랜 기간 동안 Zookeeper가 Kafka 클러스터를 안정적으로 운영하는 데에 기여하였으나, 시간이 지남에 따라 클러스터의 규모 및 데이터의 양이 거대해지면서 독립된 시스템을 함께 운영하고 모니터링 해야 하는 것에 점차 어려움을 겪게 되었습니다. 이에 따라 Kafka의 개발사 Confluent는 KIP-500 이라는 티켓을 발행하고 Zookeeper에 대한 의존성을 제거하는 작업에 착수하게 됩니다. 여기서 등장한 새로운 Kafka 클러스터 관리 프로토콜이 KRaft(Kafka Raft)입니다.
KRaft에서는 여러 브로커 중 하나의 컨트롤러를 선정했던 Zookeeper와 달리 세 개의 컨트롤러를 두고 이 중 하나를 Active 컨트롤러, 나머지를 Follwer 컨트롤러로 하여 장애 상황 등에 대비할 수 있도록 하였습니다. 또한 클러스터의 메타 데이터는 외부가 아닌 Kafka 클러스터 내부의 Topic에 저장하는 방식을 취했습니다.
이번 실습에서는 KRaft 방식으로 구동되는 3.7 버전의 Kafka 클러스터를 클라우드타입에서 구동하고 Node.js의 Express로 구현된 API를 활용하여 간단한 데이터 스트리밍 시스템을 구성해보도록 하겠습니다.
실습
버전 정보
- Node.js v18
- Express v4.19.1
- Kafka 3.7
준비 사항
- Node.js 18
- GitHub 계정
- 클라우드타입 계정
- Talend API Tester - Free Edition 혹은 기타 API 테스팅 도구
GitHub 저장소
실습은 아래의 Node.js 어플리케이션을 통해 진행됩니다. 저장소를 clone 하거나 fork 해주세요.
따라하기
Kafka 배포
-
클라우드타입에 로그인 후 우측 네비바의 ➕ 버튼을 눌러 새 프로젝트 창을 띄우고 프로젝트 이름과 표시 이름을 입력한 뒤 생성하기 버튼을 누릅니다.
-
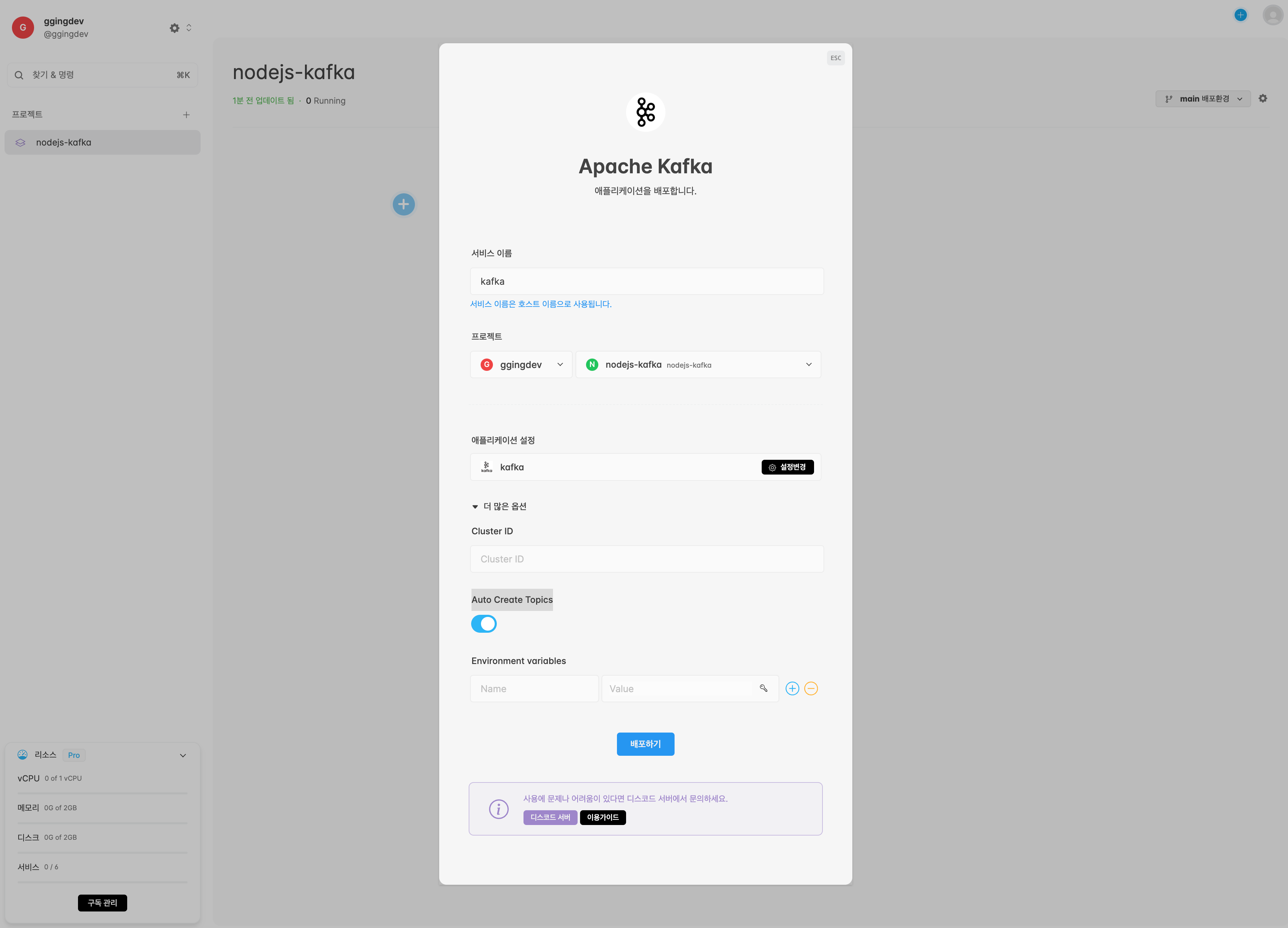
가운데 ➕ 버튼을 누르고 Apache Kafka 템플릿을 선택합니다. Cluster ID는 공란으로 두고 Auto Create Topics는 활성화 모드인지 확인한 후 배포하기를 클릭합니다.
-
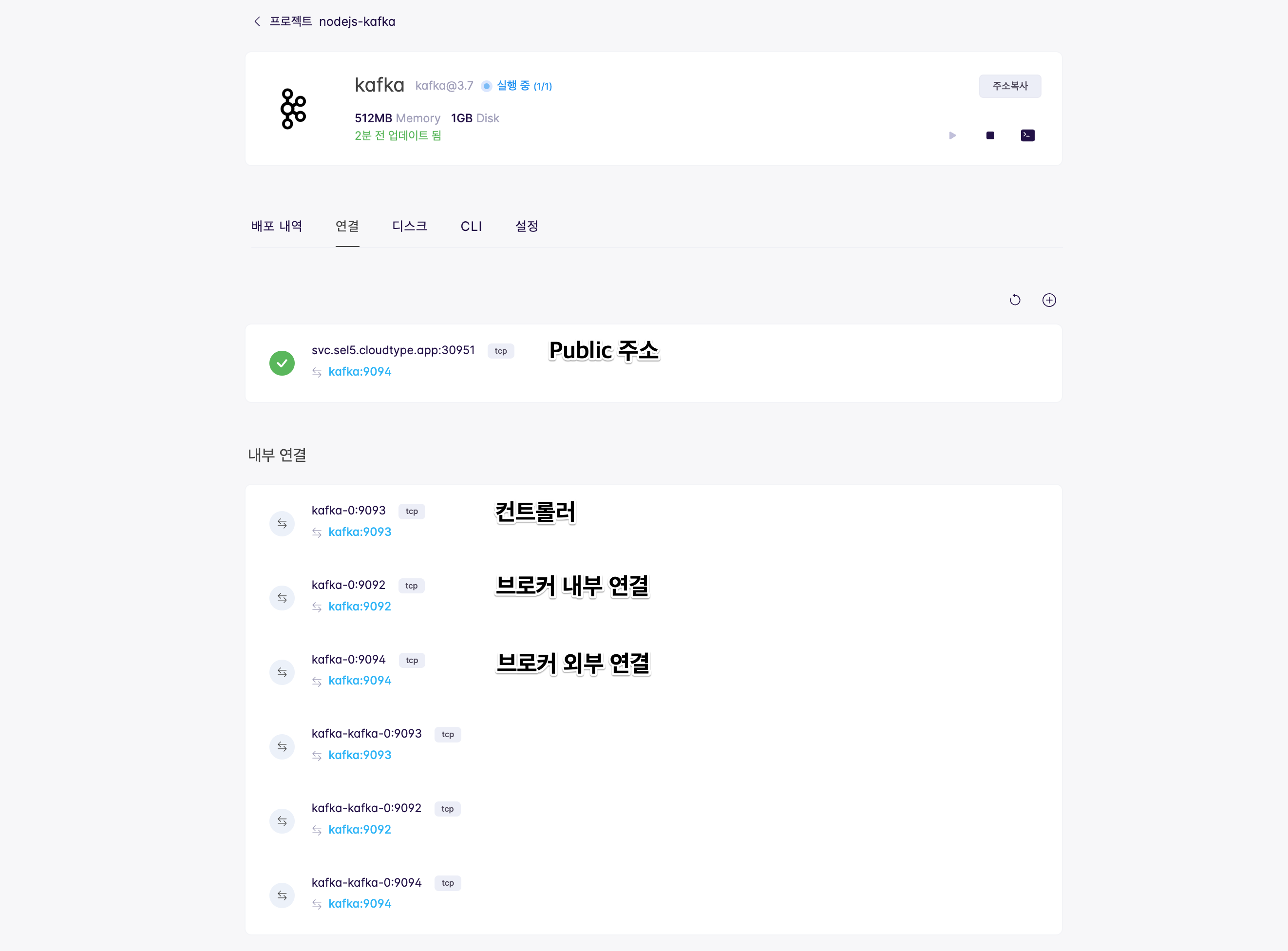
연결 탭에 생성된 주소 중
svc.sel5.cloudtype.app로 시작되는 주소는 내외부에서 모두 TCP 프로토콜로 통신이 가능한 Public address이며, 외부에서 연결을 하는 경우 프로젝트 설정에서 TCP 접근을 허용해 주어야 합니다. 방법은 여기를 참고해주세요. 프로젝트 내에 배포된 서비스는 같은 네트워크에 위치하므로 Kafka 접속을 위한 주소로kafka-0:9092를 사용하겠습니다.
Node.js Producer 배포
-
저장소
producer디렉토리 내의index.js파일의 내용은 다음과 같습니다.const express = require('express'); const { Kafka, Partitioners } = require('kafkajs'); const app = express(); const port = 3000; const brokerUrl = process.env.KAFKA_BROKER_URL || 'kafka-0:9092'; const kafka = new Kafka({ clientId: 'client-1', brokers: [`${brokerUrl}`] }); const producer = kafka.producer({ createPartitioner: Partitioners.LegacyPartitioner }); const runProducer = async (message) => { await producer.connect(); console.log('connect to', brokerUrl); await producer.send(message); await producer.disconnect(); }; app.use(express.json()); app.post('/publish', async (req, res) => { try { const { topic, value } = req.body; if (!topic || !value) { return res.status(400).json({ error: '토픽 혹은 메세지 내용이 없습니다.' }); } const message = { topic: topic, messages: [{ value: value }] }; await runProducer(message); console.log('Sent message:', message); res.status(200).json({ message: '메세지가 성공적으로 전송되었습니다.' }); } catch (error) { console.error('메세지 전송 중 오류가 발생했습니다:', error); res.status(500).json({ error: 'Internal server error.' }); } }); app.listen(port, () => { console.log(`Server is running on port ${port}`); });- 환경변수
KAFKA_BROKER_URL은 접속할 Kafka 브로커 주소를 가리킵니다. /publish경로를 통해 메세지를 발행합니다.
- 환경변수
-
클라우드타입의 프로젝트 페이지에서 ➕ 버튼을 누르고 Node.js를 선택한 후, 미리 fork 해놓은 nodejs-kafka 를 선택합니다. 기타 설정은 아래를 참고하여 입력한 후 배포하기 버튼을 클릭합니다.
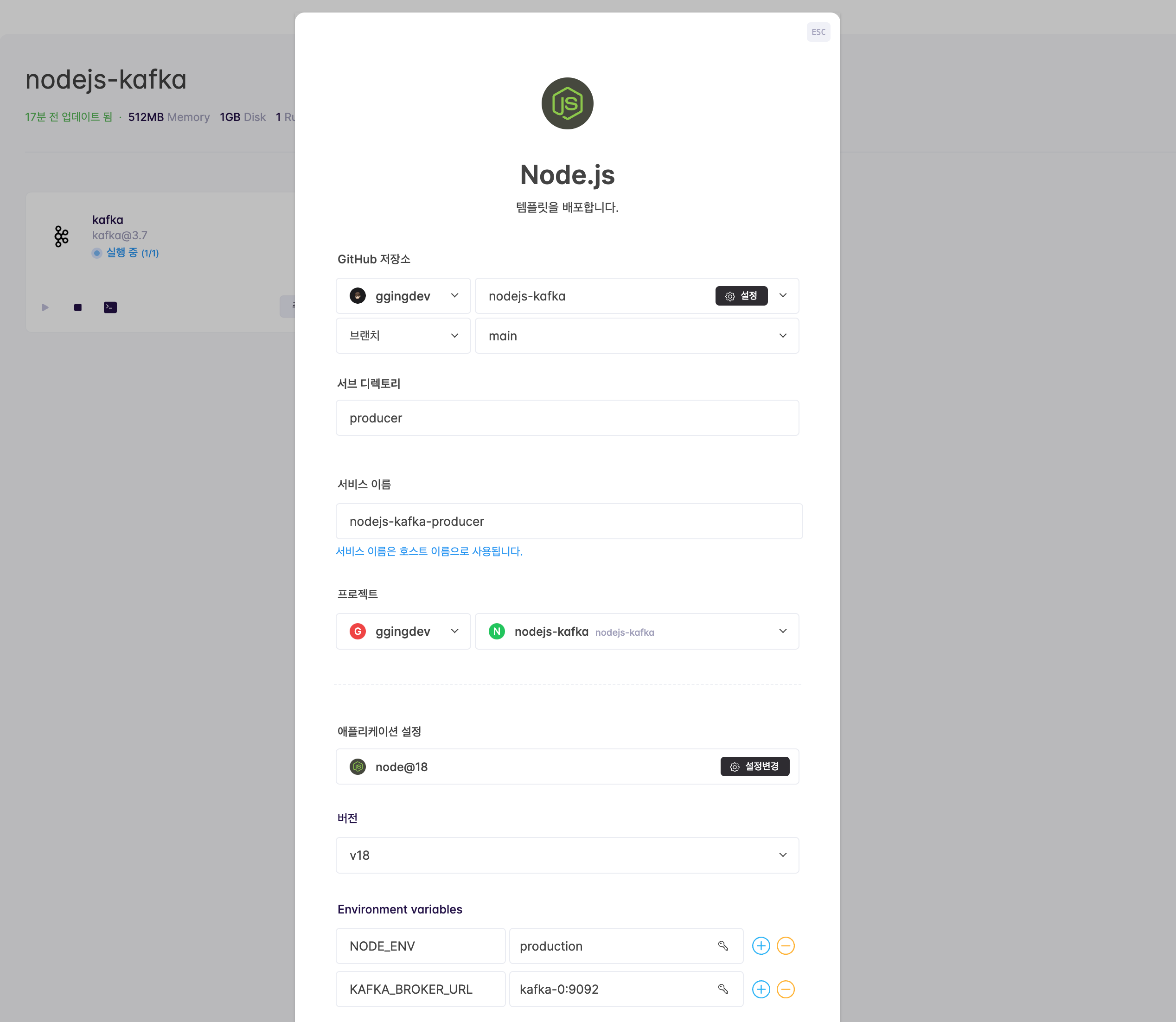
- 서브 디렉토리: producer
- 버전: v18
- 환경변수(Environment Variables)
NODE_ENV: productionKAFKA_BROKER_URL: kafka-0:9092
-
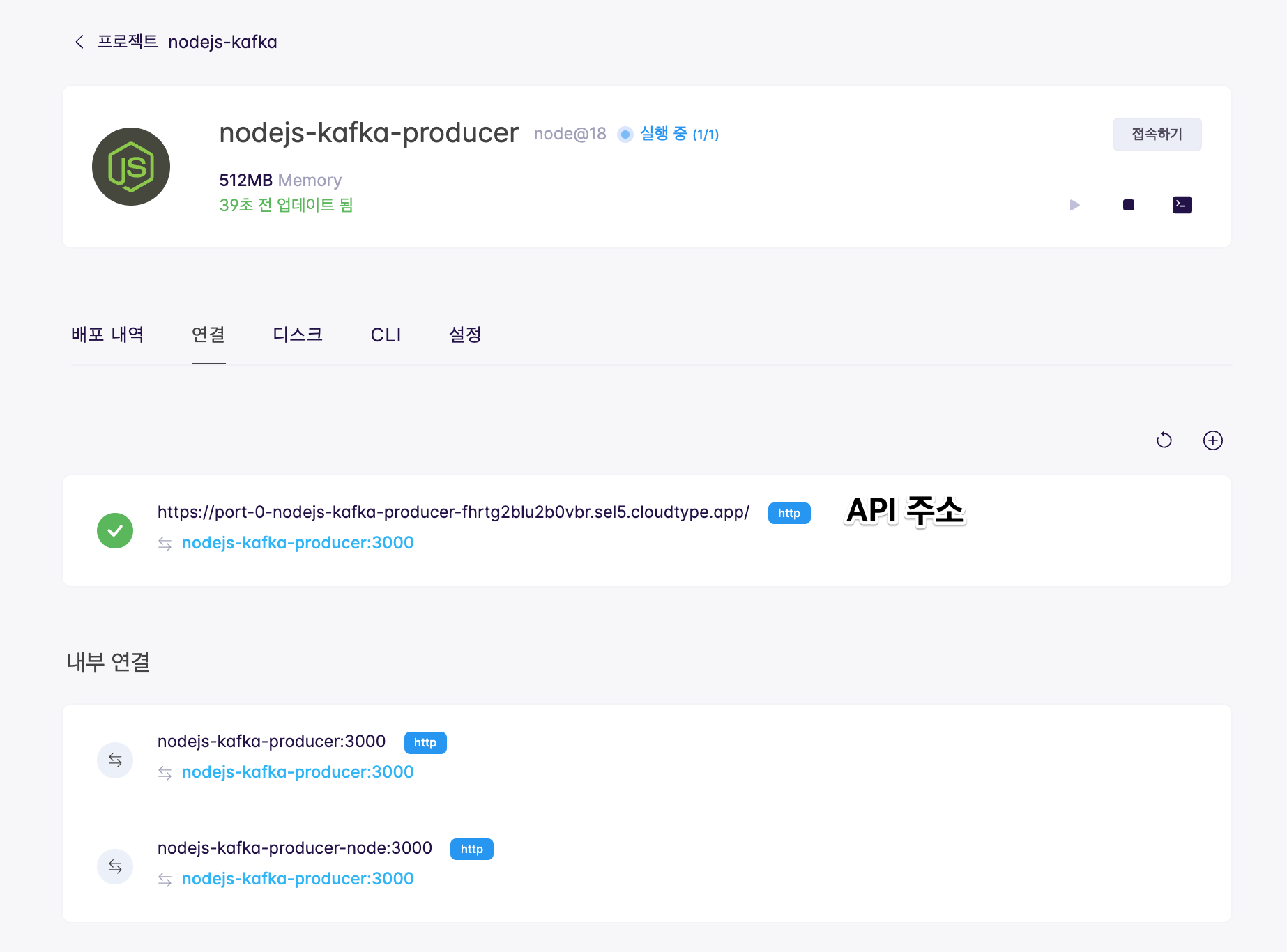
배포가 완료되면 Node.js Kafka Producer 어플리케이션 페이지의 연결 탭에서
https://로 시작되는 URL을 확인합니다. 추후 API를 호출하는 주소로 사용됩니다.
Node.js Producer 테스트
-
메세지를 Producer에서 생성한 후 Kafka로 전송하기 위해 API를 호출해 보겠습니다. 먼저 크롬 브라우저에서 Talend API Tester를 켭니다.
-
API를 호출하기 위한 설정 및 정보를 입력합니다.
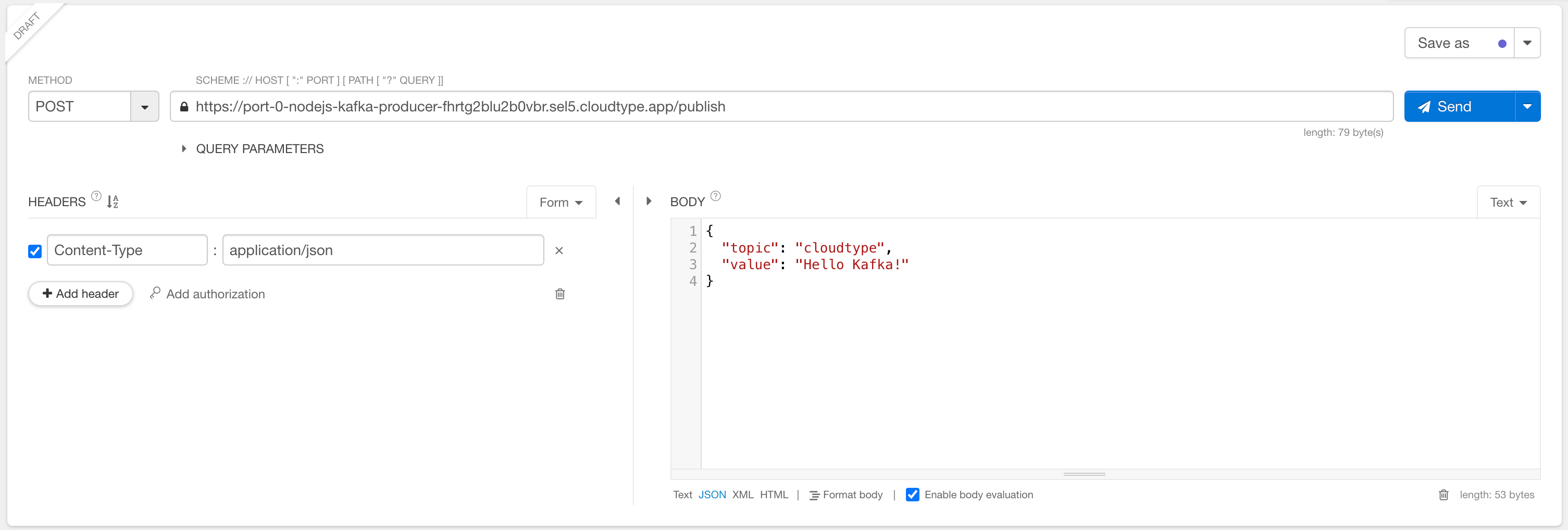
- METHOD: POST
- 주소:
<배포한 Node.js Producer의 URL>/publish - BODY
{ "topic": "cloudtype", "value": "Hello Kafka!" }
-
Send 버튼을 누르고 다음과 같이 정상 응답 코드 및 메세지가 표시되는지 확인합니다.
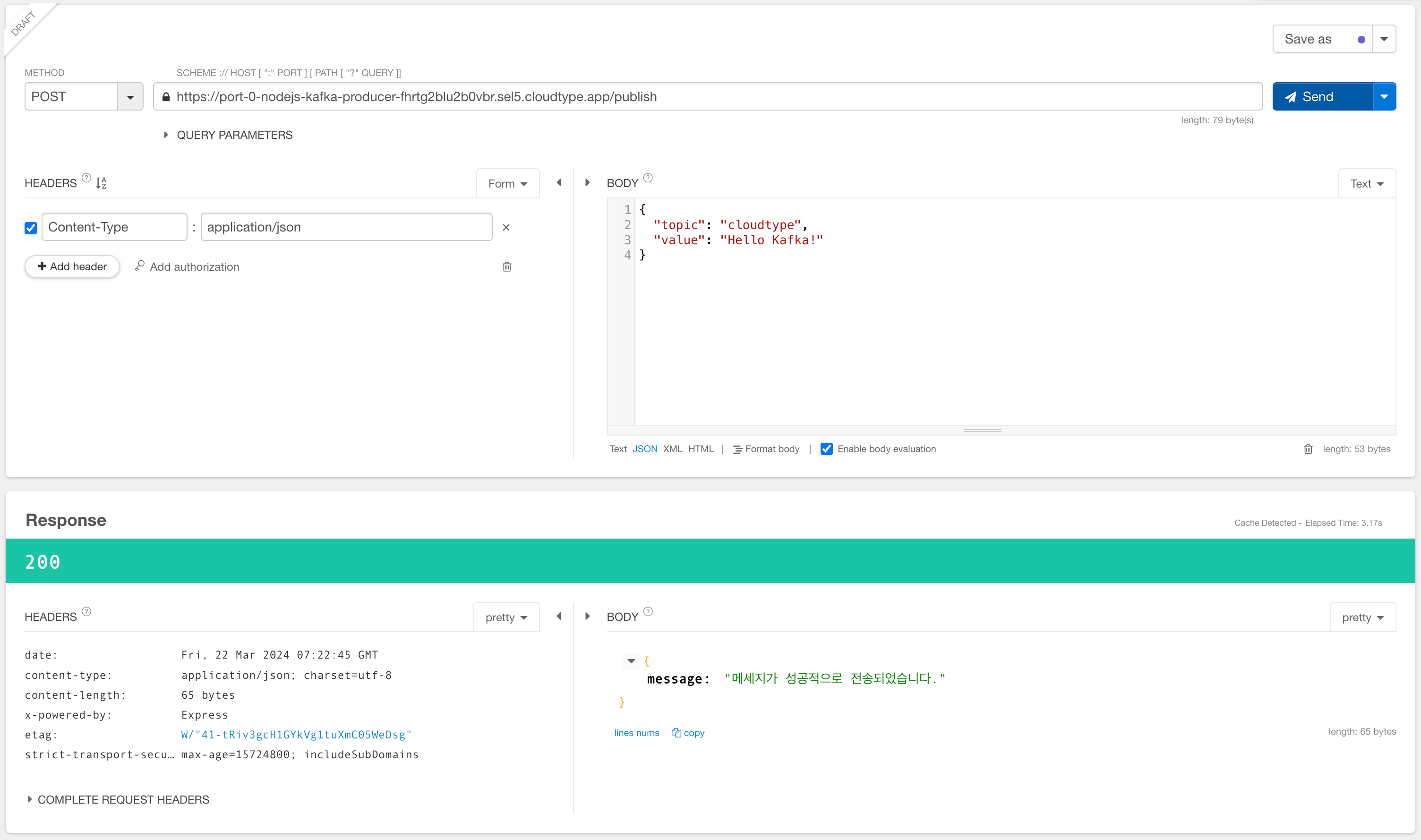
Node.js Consumer 배포
-
저장소
consumer디렉토리 내의index.js파일의 내용은 다음과 같습니다.const express = require('express'); const { Kafka } = require('kafkajs'); const app = express(); const port = 3000; const brokerUrl = process.env.KAFKA_BROKER_URL || 'kafka-0:9092'; console.log('connect to', brokerUrl); const kafka = new Kafka({ clientId: 'client-2', brokers: [`${brokerUrl}`] }); const consumer = kafka.consumer({ groupId: 'test-group' }); const runConsumer = async (res) => { await consumer.connect(); await consumer.subscribe({ topic: 'cloudtype', fromBeginning: true }); await consumer.run({ eachMessage: async ({ topic, partition, message }) => { console.log({ topic: topic.toString(), partition: partition.toString(), value: message.value.toString(), }); }, }); }; runConsumer().catch(console.error); app.listen(port, () => { console.log(`Server is running on port ${port}`); });- 환경변수
KAFKA_BROKER_URL은 접속할 Kafka 브로커 주소를 가리킵니다. - producer에서 생성된 동일한 토픽을
subscribe()의 파라미터로 넘깁니다.
- 환경변수
-
클라우드타입의 프로젝트 페이지에서 ➕ 버튼을 누르고 Node.js를 선택한 후, 미리 fork 해놓은 nodejs-kafka 를 선택합니다. 기타 설정은 아래를 참고하여 입력한 후 배포하기 버튼을 클릭합니다.
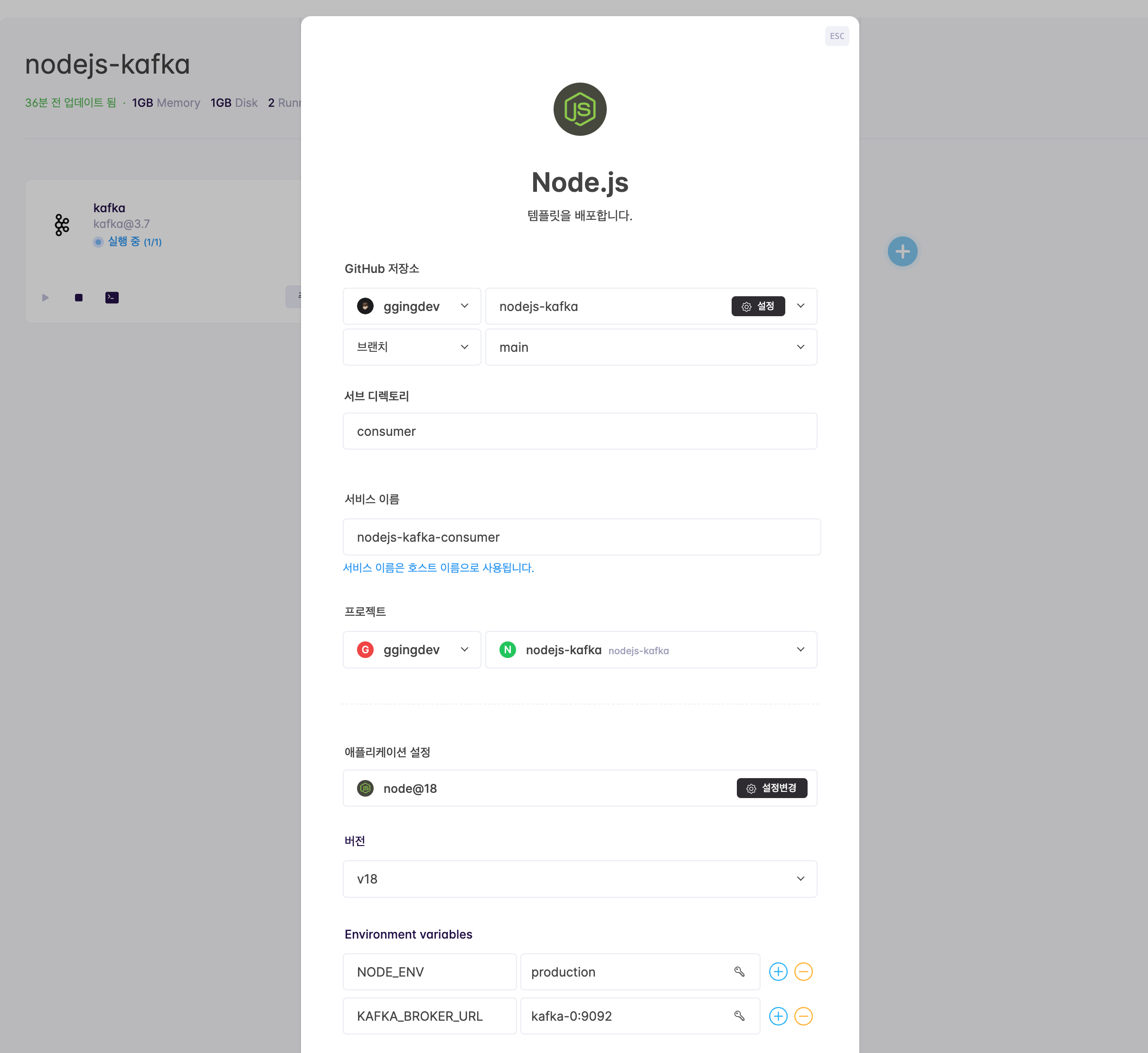
- 서브 디렉토리: consumer
- 버전: v18
- 환경변수(Environment Variables)
NODE_ENV: productionKAFKA_BROKER_URL: kafka-0:9092
-
배포가 완료되면 터미널 아이콘을 눌러 실행 로그 창을 켭니다. 정상적으로 Topic이 구독되었다면 앞서서 API 호출로 생성된 메세지가 로그 창에 표시됩니다.
{"level":"INFO","timestamp":"2024-03-22T07:30:21.066Z","logger":"kafkajs","message":"[ConsumerGroup] Consumer has joined the group","groupId":"test-group","memberId":"client-2-45db9a3c-51a9-404e-bb65-150bb3758183","leaderId":"client-2-45db9a3c-51a9-404e-bb65-150bb3758183","isLeader":true,"memberAssignment":{"cloudtype":[0]},"groupProtocol":"RoundRobinAssigner","duration":15925}
{ topic: 'cloudtype', partition: '0', value: 'Hello Kafka!' }Reference
- https://kafka.apache.org/
- https://zookeeper.apache.org/
- https://aws.amazon.com/ko/what-is/streaming-data/
- https://aws.amazon.com/ko/compare/the-difference-between-rabbitmq-and-kafka/
- https://www.ibm.com/kr-ko/topics/apache-kafka
- https://devocean.sk.com/blog/techBoardDetail.do?ID=165711&boardType=techBlog
- https://developer.confluent.io/learn/kraft/
