💡 Hadoop의 버전별 특징에 대해 소개합니다.
버전별 특징 개요
- v1
- 병렬처리는 잡트래커와 태스크트래커가 담당하고, 분산저장은 네임노드와 데이터노드가 담당하는 구조로 설정하였습니다. 하지만 병렬처리의 클러스터 자원 관리와 애플리케이션의 라이프사이클 관리를 모두 잡트래커가 담당하는 문제 때문에 병목현상이 발생하여 큰 latency가 발생했습니다.
- v2
- 잡트래커의 병목현상을 해결하고자 YARN이라는 리소스 관리 아키텍쳐를 도입하여 잡트래커의 기능을 분리 하였습니다. 클러스터 자원관리는 리소스매니저와 노드 매니저, 애플리케이션의 라이프 사이클 관리는 애플리케이션 마스터와 컨테이너에게 담당하도록 하였습니다.
- v3
- 이레이저 코딩을 도입해서 HDFS의 데이터 저장 효율성을 증가시켯습니다. YARN 타임라인 서비스를 개선하고 v1에서 제작된 쉘 스크립트를 재작성하여 안정성을 높였습니다. 맵리듀스에 처리에 네이티브 프로그램을 적용하여 성능을 높였습니다.
Hadoop version 1
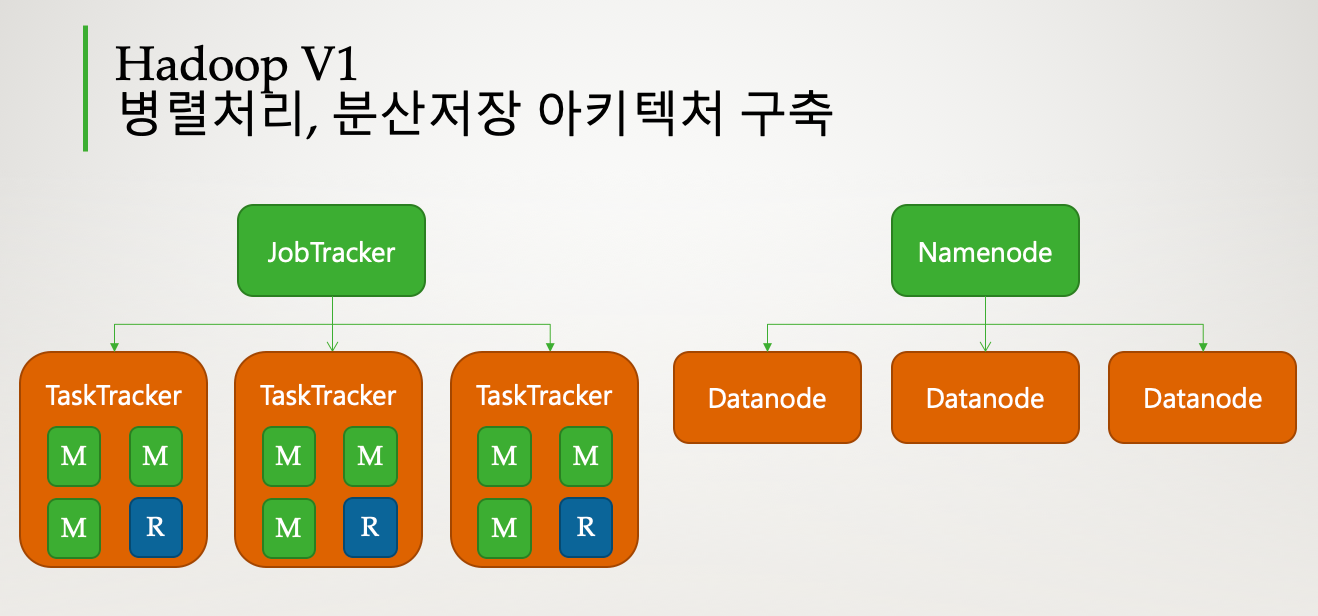
- 2011년 자바 프레임워크로 분산저장과 병렬처리를 목적으로 출시했습니다.
분산저장
네임노드(Name node)와 데이터 노드(Data node)로 나누어 처리됩니다.
네임노드는 블록정보(각 데이터가 저장된 노드의 주소 등등)를 가지고 있는 메타데이터와 데이터 노드를 관리합니다.
데이터 노드는 데이터를 블록 단위로 저장하면서 블록단위 데이터를 복제하여 데이터가 손상되거나 유실되는 경우에 대비합니다.
병렬처리
잡트래커(JobTracker)와 태스크트래커(TaskTracker)가 담당합니다. 잡트래커는 전체 진행상황을 관리하고 자원관리도 처리합니다. 태스크트래커는 실제 작업을 처리하는 일을 수행합니다.
잡트래커는 전체 진행상황과 자원을 관리합니다.
태스크트래커는 실제 작업을 처리하는 일을 수행합니다. 이때 병렬처리의 작업단위는 슬롯으로 맵 슬롯과 리듀스 슬롯이 있으며 병렬처리를 통해서 클러스터 당 최대 4000개의 노드를 등록할 수 있습니다.
그러나, 잡트래커가 분산 애플리케이션의 라이플사이클 관리도 담당하면서 병목현상이 발생한다는 단점이 있습니다.
Hadoop v2
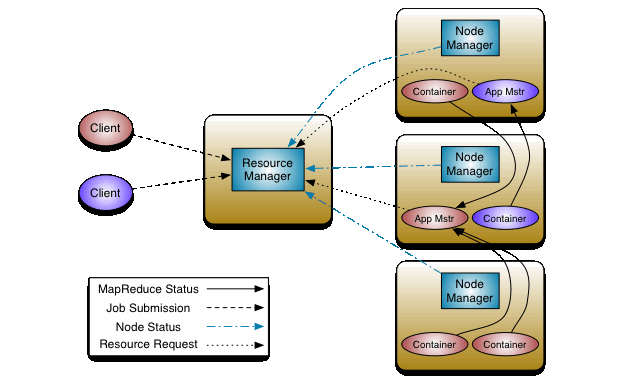
개요
2012년 Vesion v1의 단점을 개선하고 보안적인측면을 보완한 버전입니다.
병목현상을 제거하기 위해서 YARN이라는 리소스 관리 아키텍쳐를 도입했습니다. 잡트래커의 기능을 분리하여서 자원관리는 리소스매니저와 노드매니저가 담당하고, 애플리케이션의 라이프 사이클 관리는 애플리케이션 마스터가 담당하며, 작업의 처리는 컨테이너가 담당하게 되면서 자원관리와 애플리케이션의 관리를 분리하여 클러스터당 노드를 10,000개 까지 등록할 수 있게되었습니다.
컨테이너는 YARN 구조의 작업의 처리 단위입니다.
실행순서
작업이 요청되면 애플리케이션 마스터가 생성되고 애플리케이션 마스터가 리소스 매니저에 자원을 요쳥하여 실제 작업을 담당하는 컨테이너를 할당받아서 작업을 처리하게 됩니다. 컨테이너는 작업이 요청되면 생성되고, 작업이 완료되면 종료되기 때문에 클러스터를 효율적으로 사용할 수 있게 됩니다.
또한 YARN 구조에서는 MR(MapReduce)로 구현된 작업이 아니어도 컨테이너를 할당 받아서 동작할 수 있기 때문에, Spark, HBase, Storm등 다양한 컴포넌트를 실행할 수 있습니다.
YARN
YARN은 v1의 병목현상을 제거하기 위해 도입되었습니다.
잡트래커의 일부 기능을 받아서 자원관리와 애플리케이션의 라이프사이클 관리를 수행합니다.
YARN은 애플리케이션이 사용하는 CPU와 메모리를 컨테이너 단위로 관리하며 Hadoop에서 분산 애플리케이션을 실행하면 YARN은 클러스터 전체 부하를 보고 비어있는 호스트부터 컨테이너를 할당 해줍니다.
컨테이너 단위 작업이라고 해서 Docker를 떠올릴 수도 있는데, Docker는 OS 수준의 가상화 기술입니다. YARN은 어떤 HOST에서 어떤 Process를 진행할 것인지 결정하는 애플리케이션 수준의 기술입니다.
분산 애플리케이션은 동시에 여러 개가 실행되므로 애플리케이션간에 리소스 쟁탈이 발생합니다.
YARN은 어느 어플리케이션에 얼마만큼의 리소스를 할당할 지 관리함으로써 모든 애플리케이션이 정상적으로 작업을 수행하도록 관리합니다.
YARN을 통해서 애플리케이션마다 실행의 우선순위를 정할 수 있기 때문에 중요한 작업부터 우선적으로 처리하고 리소스가 남을 때 후순위 작업을 처리함으로써 리소스를 효율적으로 활용하여 데이터 처리를 할 수 있습니다.
Hadoop v3
개요
2017년 발표된 Hadoop v3는 이레이저코딩(Erasure Coding), YARN 타임라인 서비스 v2가 도입되었습니다.
v2 까지는 HDFS의 파일 복구를 위해 파일 복제방식을 사용했었습니다. 파일 1개당 2개의 복제본을 가지게 되어서 실질적으로 디스크 공간 효율성이 30%밖에 안되는 문제점이 있었습니다.
이를 해결하기 위해 패리티 블록을 활용해서 만약 데이터를 저장하기 위해 1GB의 용량이 필요하다면 1.5GB로 복구까지 해결할 수 있게되어 공간효율성이 증가했습니다.
그리고 YARN 타임라인 서버를 개선하고 v1부터 사용하던 쉘 스크립트를 재작성하여 안정성을 높였습니다. 네이티브 코드를 수정하여 셔플단계의 처리 속도를 증가시키고, JAVA8을 지원하도록 수정했습니다. 고 가용성을 위해서 네임노드를 2개 이상을 지원하는 등의 여러 성능개선이 이루어졌습니다.
Erasure Coding
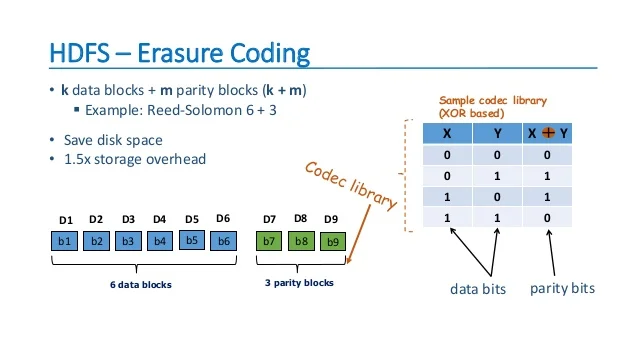
RAID 3(패리티 비트 오류검출방식 적용)에서 사용하는 Reed-Solomon 알고리즘을 사용한 ‘Erasure Coding’ 방식을 사용하여 기존의 파일의 복구 방식으로 용량의 3배가 필요했는데 이를 1.5배까지 줄이는 성과를 얻었습니다.
더욱 자세한 원리는 삼성SDS : 하둡 3.x과 이레이저 코딩 이 곳에서..
위 블로그 내용 요약하자면,
- Encoding Matrix로 파일 정보를 요약한 비트를 만들어서 디스크에 같이 기록한다. 이 과정에서 파일 복제를 안해도 되서 디스크 공간 효율성을 증대시켰음.
- 디스크가 손상 되었다면 Encoding Matrix를 Inverse하여 곱하여 원래의 블록정보를 복구할 수 있다.
- 위의 과정 처럼 인코딩/디코딩 과정이 필요하여 연산작업때문에 CPU 성능의 저하 우려되지만 Intel의 ISA-L 코더 덕분에 완화되었다.
특징
- 이레이져 코딩 도입
- 기존의 블록 복제(Replication)를 대체하는 방식으로 HDFS 사용량 감소
- YARN 타임라인 서비스 v2 도입
- 기존 타임라인 서비스보다 많은 정보를 확인 가능
- 스크립트 재작성및 이해하기 쉬운 형태로 수정
- 오래된 스크립트를 재작성하여 버그 수정
- 기본 포트 변경
- NameNode
- 50470 → 9871
- 50070 → 9870
- 8020 → 9820
- Secondary NameNode
- 50091 → 9869
- 50090 → 9868
- DataNode ports:
- 50020 → 9867
- 50010 → 9866
- 50475 → 9865
- 50075 → 9864
- NameNode
- JAVA8 지원
- 네이티브 코드 최적화 → 셔플 처리속도의 가속
- 고가용성을 위해 2개 이상의 네임노드 지원
- 하나만 추가할 수 있었던 스탠바이 노드를 여러개 지원가능 스탠바이 노드
- Ozone 추가
- 오브젝트 저장소 추가
지금 까지 하둡의 각 버전별 특징을 알아봤습니다.
모든 분야가 그렇겠지만 알면 알수록 알아야하는게 기하급수적으로 늘어나는 것 같습니다. ㅠ
참고
