💡 본 포스팅은 니시다 케이스케의 ‘빅데이터를 지탱하는 기술’을 읽고 정리한 내용입니다. 이 페이지에서는 빅데이터의 주요 역사에 대해서 설명합니다.
- 2011년 이전 : Hadoop이나 NoSQL 데이터베이스 등 기반 기술의 발전
- 2012년 : 클라우드 방식의 데이터 웨어하우스와 BI 도구의 보급
- 2013년 : 스트림 처리와 애드 훅(Adhoc) 분석 환경의 확충
분산 시스템에 의한 데이터 처리의 고속화
빅데이터를 취급하기 위한 2가지 기술
‘빅데이터’라는 단어는 2011년도 후반에서 2012년에 걸쳐서 많은 기업들이 데이터 처리에 분산 시스템을 도입하면서 부터 많이 언급되는 키워드입니다.
빅데이터를 취급하기 어려운 이유는 크게 2가지가 있다고 합니다.
첫째 ‘데이터의 분석 방법을 모른다’
둘째 ‘데이터 처리에 수고와 시간이 걸린다’
이 책에서 첫째의 상황은 해결되었다고 가정하고
‘어떻게 효율적인 데이터 처리를 수행할 것인가?’에 초점을 두고 집필했다고 합니다.
빅데이터 기술의 요구
Hadoop과 NoSQL의 대두
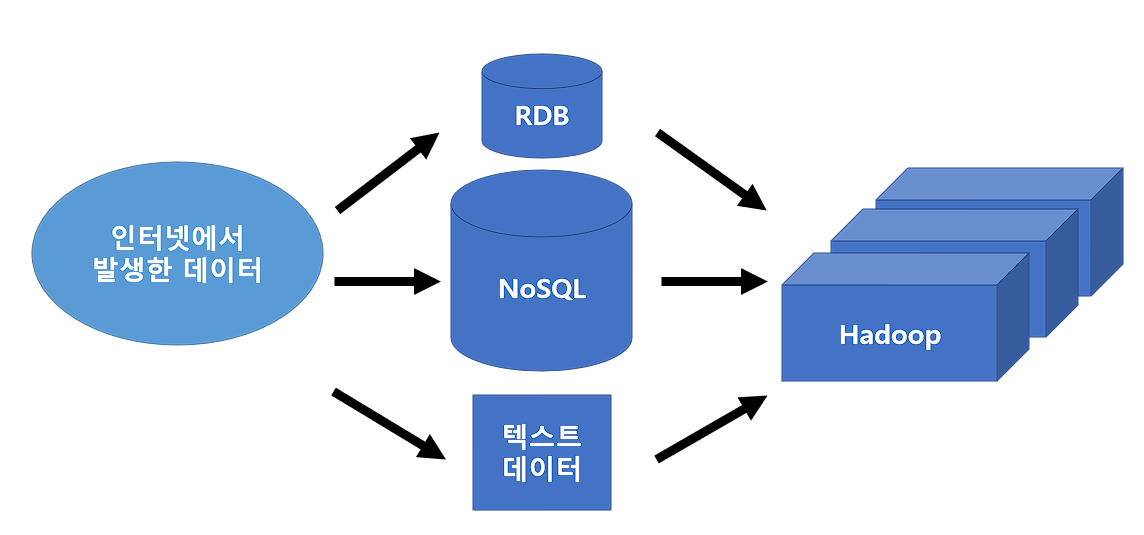
웹 서버에서 생성된 데이터는 RDB나 NoSQL에 텍스트 데이터 형태로 저장되고, 그 후 모든 데이터가 Hadoop에 모여서 대규모 데이터처리가 실행됩니다.
인터넷의 보급과 컴퓨팅 성능의 향상으로 예전과는 다르게 방대한 데이터가 쏟아지게 되어 기존의 RDB로는 취급할 수 없게되었다고 합니다.
이런 배경에서 등장한 것이 Hadoop과 NoSQL이라고 합니다.
Hadoop
다수의 컴퓨터로 대량의 데이터를 처리하기 위한 시스템입니다.
예를 들면, 구글과 같은 검색엔진을 구축하려고 한다면 전 세계의 웹페이지를 모아야 하기 때문에 방대한 데이터를 저장할 스토리지와 이를 순차적으로 처리할 수 있는 구조가 필요하게 됩니다.
이 것을 가능하게 해주는 툴이 Hadoop이며 구글에서 개발된 분산 처리 프레임워크인 ‘MapReduce’를 기반으로 제작되었습니다.
초기 Hadoop의 경우 데이터 처리에 자바 언어로 작성되어 누구나 간단히 사용하지 못했습니다. 그런이유로 SQL과 같은 쿼리 언어를 Hadoop에서 사용하기 위한 소프트 웨어로 ‘Hive’가 개발되어 2009년에 출시하였고 ‘Hive’를 통해 좀 더 많은 사람들에게 Hadoop이 보급되기 시작했고 이로 인해 좀 더 많은사람들이 혜택을 받을 수 있게 되었다고 합니다.
- Hadoop의 역사
시기 사건 2004년 12월 구글에서 MapReduce 논문 발표 2007년 9월 Hadoop 최초버젼 배포 2009년 5월 Hive 최초버젼 배포 2011년 12월 Hadoop 1.0.0 배포
NoSQL
빈번한 읽기/쓰기 및 분산 처리에 강점
NoSQL은 기존의 RDB의 정형화된 데이터 형태에서 벗어난 데이터베이스의 총칭을 의미합니다.
어러 종류가 있으며 대표적인 3가지는 Key-Value, Document, wide-column 입니다.
Key-value는 문자 그대로 키값 밸류값이 한쌍으로 저장되어지는 데이터 베이스고
Document는 Json과 같은 복잡한 데이터 구조를 저장합니다.
wide-column은 여러 키를 사용하여 확장성에 장점이 있는 데이터베이스입니다.
-
주요 NoSQL 데이터베이스
시기 사건 종류 2009년 MongoDB 1.0 배포 Document 2010년 CouchDB 1.0 배포 Document 2011년 9월 Riak 1.0 배포 키밸류 2011년 10월 Cassandra 1.0 배포 와이드 컬럼 2011년 12월 Redis 1.0 배포 키밸류
Hadoop + Nosql
현실적인 비용으로 빅데이터 처리 실현
이 둘을 조합해서 데이터 저장은 읽고 쓰기에 용이한 NoSQL을 사용하고 Hadoop을 통해 분산 처리하여 현실적인 비용으로도 빅데이터를 처리할 수 있게 되었다고합니다.
2011년말 까지 정착하게 되어 2012년에는 아주 일반적으로 사용되는 방법이 되었습니다.
비즈니스 이용에서의 분산 시스템
데이터 웨어 하우스와의 공존
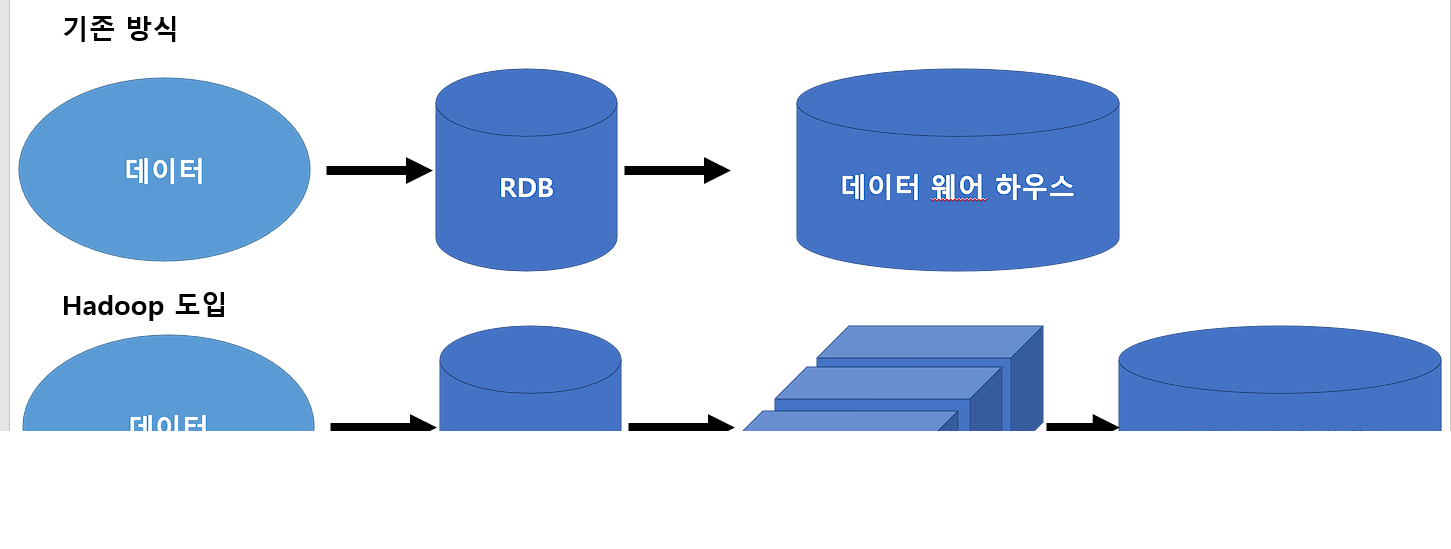
일부 기업에서는 이미 예전부터 데이터 분석을 기반으로 하는 ‘엔터프라이즈 데이터 웨어하우스’를 도입해서 전국 각지의 매출, 고객 정보들이 오랜 기간 축적되어 이 데이터를 분석함으로써 업무 개선과 경영 지표로 활용해왔습니다.
그러나 시간이 지남에 따라 데이터웨어 하우스를 사용했던 경우에도 Hadoop을 사용하게 되어야하는 경우가 증가하게 되었습니다.
이러한 움직임에 발 맞추어 데이터 분석 도구도 대용량 데이터를 보존하고 집계하기 위해 Hadoop과 Hive를 사용하게 되었고 그 결과 Hadoop을 도입하는 비즈니스가 성립하게 되었습니다. 이 때 부터 시작된 키워드가 ‘빅데이터’라고합니다.
전통적인 데이터 웨어하우스도 대량의 데이터를 처리할 수 있으며, 어떤 점은 오히려 Hadoop보다 우수한 성능을 보여줍니다.
하지만, 일부 데이터 웨어하우스 제품은 안정적인 성능을 위해 소프트웨어+하드웨어로 제공되는 경우도 있고 용량 확장을 위해서는 하드웨어를 교체해야하는 단점이 존재했습니다.
이러한 이유로 가속도적으로 발생되는 데이터의 처리는 Hadoop에 맡기고(Data lake) 중요한 데이터 혹은 작은 데이터는 데이터 웨어 하우스에 저장함으로써 사용을 구분하게 되었습니다.
예를 들면, 야간 배치나 심야에는 일 단위로 발생된 대용량 데이터의 처리가 이루어지는데 이를 확장성이 좋은 Hadoop에 맡기면 데이터 웨어하우스에 발생하는 부하를 줄일 수 있게 되는 것입니다.
직접할 수 있는 데이터의 분석 폭의 확대
클라우드 서비스와 데이터 디스커버리로 발전하는 빅데이터의 활용
이러한 빅데이터처리에 대해 변화의 바람이 부는 동시에 분산처리를 하는 하드웨어를 준비하고 관리하기 위하여 클라우드 서비스가 등장하였고 이를 활용하여 필요한 자원을 확보할 수 있는 환경이 마련되었습니다.
- 데이터 처리를 위한 클라우드 서비스의 종류
시기 이벤트 서비스의 특징 2009년 4월 Amazon Elastic MapReduce 클라우드를 위한 hadoop 2010년 5월 구글 BigQuery 발표 데이터 웨어하우스 2012년 10월 Azure HDInsight 발표 클라우드를 위한 Hadoop 2012년 11월 Amazon Redshift 발표 데이터 웨어하우스
아마존 레드시프트의 발표 이후 데이터 웨어하우스를 도입하는 것은 어렵지 않게 되어 작은 프로젝트 단위에서도 데이터 분석 기반을 구축하기위해 데이터 웨어하우스를 사용하는 것이 일반적인 상황이 되었다고 합니다.
