코드카타 풀이
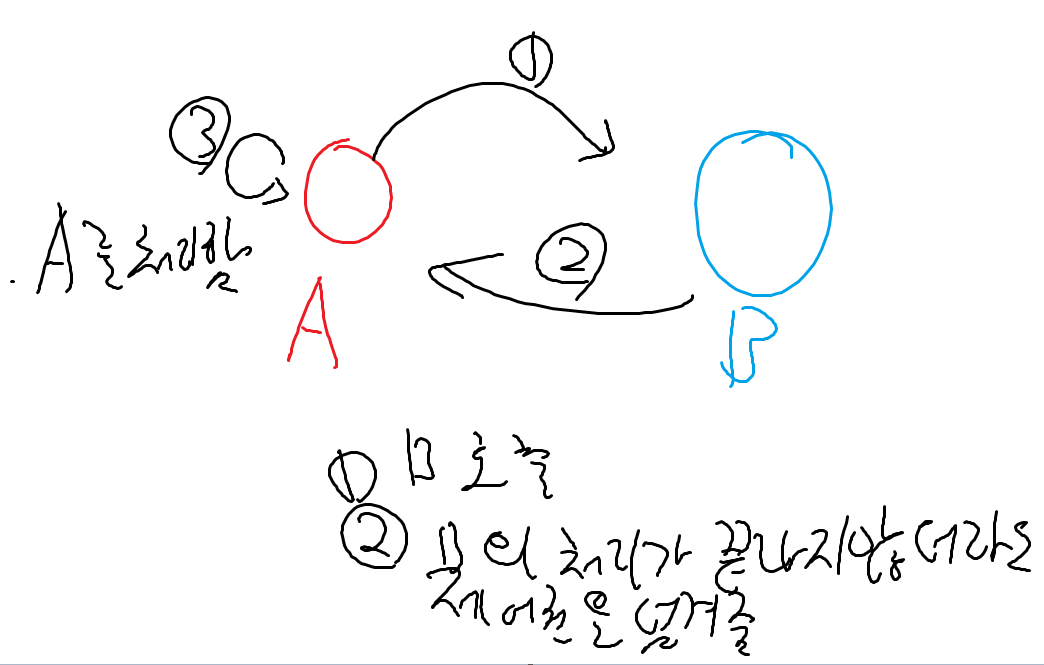
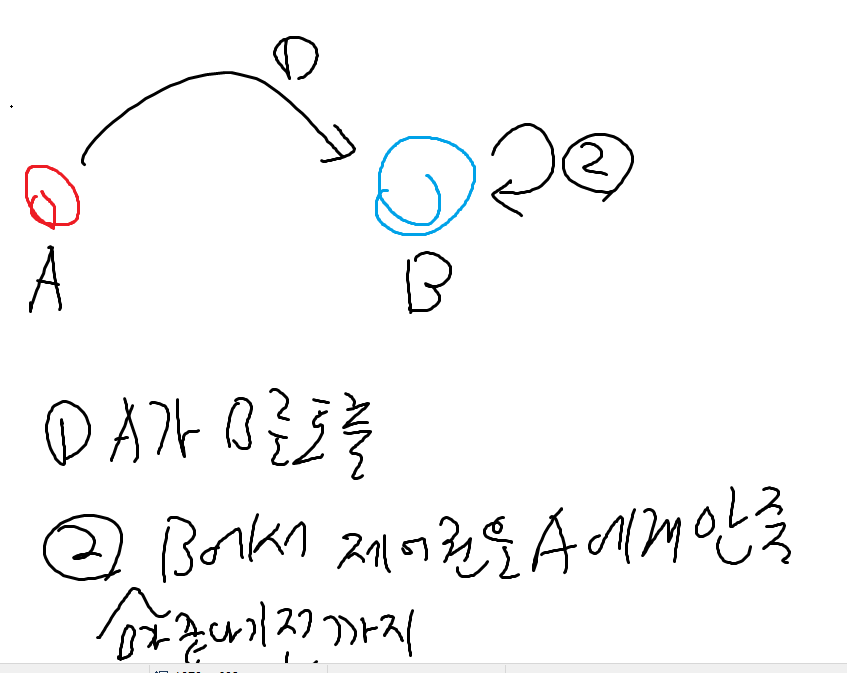
둘만이 아는 암호(67)
각 문자열을 index만큼 뒤의 알파벳으로 바꿔주는데 이때 skip되는 문자열들은 무시한다.(만약 z를 넘어갈 경우엔 다시 a로 돌아오게 된다.)
1.skip을 제외한 나머지 값을 가진 문자 배열(skip_words)을 생성하고, 바꿀 문자열도 역시 배열로 만들어준다.(s_copy)
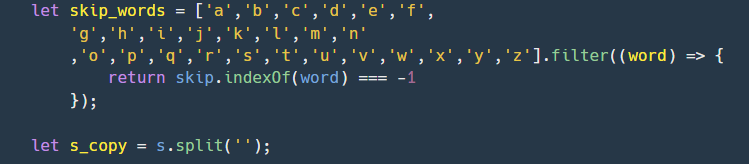
2.바꾼 문자 배열로 for문을 반복하여 만약 해당하는 문자가 skip_words(skip을 제외한 나머지 값을 가진 문자 배열)에 있는지를 indexOf로 체크하고 index의 값을 더하여 저장한다.
3.이후에 id의 값이 skip_words.length - 1 보다 클 경우(즉,z를 넘어섰을 경우엔), id의 값을 skip_words.length와 나머지 연산자로 연산하여 나온 값을 저장하는데 만약 id의 값이 22(17+index(5))에 skip_words.length의 값이 22라면 서로 나누어 떨어져 0을 가르키게 되므로 성립하게 된다.
이후 이렇게 저장한 id값을 기반으로 answer을 채우면 끝
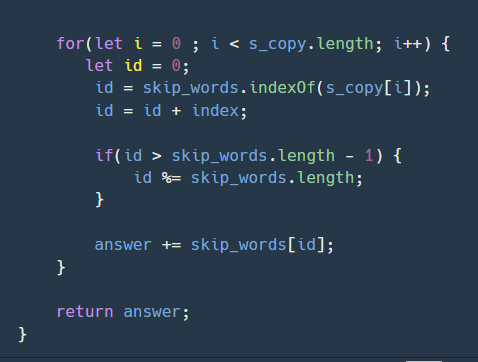
개인 과제(로그 라이크 게임)
1.코드 단축시키기
기존에 처리하고 있었던 choice나 pattern에 대한 코드들을 함수를 작성하여 넣음으로써 Battle()함수 내에서 최대한 보이지 않게끔 줄였다.


2.stage가 5의 배수에 도달했을때 보스몹을 출현시키도록 코드를 짰다.
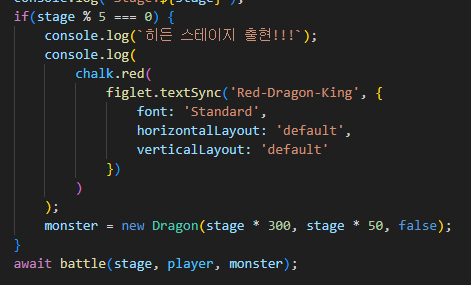
기존에 있던 monster 객체에 값을 덧씌워서 새롭게 출현하게끔 만들었고
보스몹인만큼 monster에 있던 superAttack()을 강화하여 데미지가 더 강해지게 만들었다.

Node.js 공부
1.웹 브라우저의 동작 방식
웹 브라우저란? => 웹 서버로부터 정보를 요청하고 받아 사용자에게 보여주는 소프트웨어이다.
사이트에 접속할 때 HTML,CSS,JavaScript 파일을 전달받아서 해석하고 이를 보여주게 되는데 이 과정에 정적인 파일과 동적인 파일 정보를 처리하게 된다.
정적인 웹 페이지: 서버에서 브라우저로 전송되는 내용이 그대로 표시됨(변경X)
동적인 웹 페이지: 서버에서 데이터를 받아 브라우저가 실시간으로 반영하는 것
웹 브라우저는 총 7가지 동작방식을 가지고 있다.

사용자가 도메인을 통해서 홈페이지를 요청하고 해당 DNS 서버는
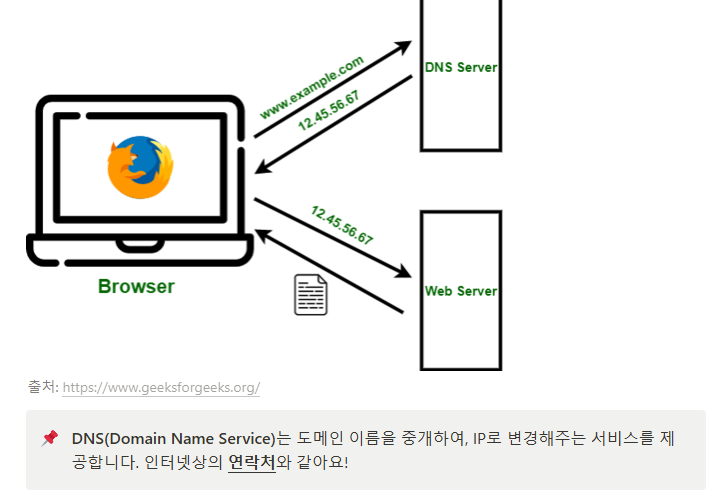
얻은 도메인을 특정 IP로 변경해주는데 이 해당 IP주소로 HTTP 요청을 전달한 다음 이 주소와 연결된 웹 서버가 요청을 받아 처리하고 이 결과를 요청한 쪽(사용자)에게 보내주는 시스템이다.
그렇다면 여기서 DNS로 얻게 되는 IP란 무엇일까?
IP는 각각의 네트워크에 연결된 장치들이 고유한 IP 주소를 가져 인터넷 상에 존재하는 해당 장치의 위치를 식별할 수 있게 해준다.
IP를 표현하는 방식에는 IPV4와 V6가 있는데
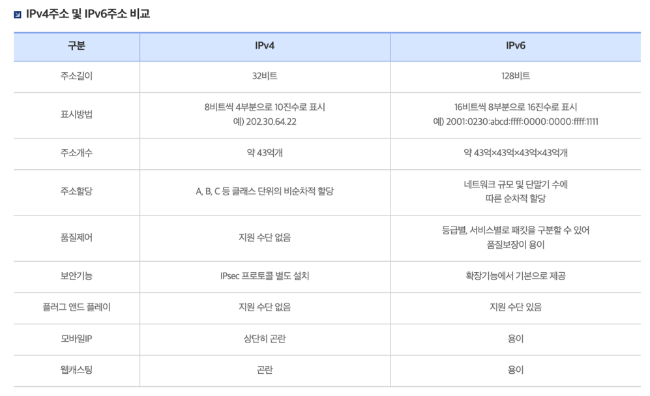
각각 이러한 차이점을 가지고 있다.
요약해서 설명해보면 IPv6는 IPv4보다 보안성이나 확정성에 대해서 더 좋아졌다는 점이다.
2.HTTP
데이터를 주고 받는 양식을 정의한 "프로토콜(protocol)" 중 하나이다.
프로토콜:컴퓨터끼리 데이터를 주고 받을때 정해둔 '약속'이다.
이를 기반으로 만들어진 HTTPS는 HTTP에서 암호화 기능이 추가되어 안정성이 높아진 것이다.

HTTP로 어떻게 데이터를 주고 받을까?
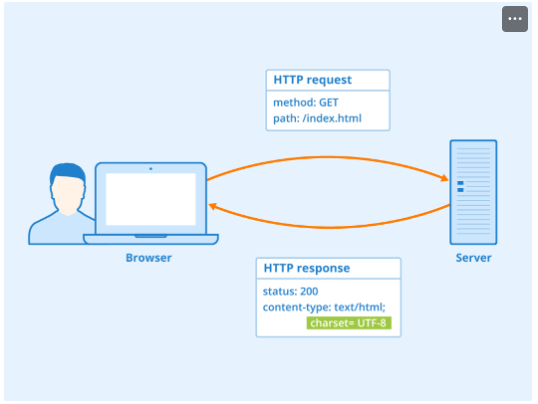
1.사용자가 브라우저에서 서버에게 자신이 원하는 페이지(URL 등)를 요구(Request) 한다.
2.서버는 사용자가 요청한 페이지가 있는지 없는지를 확인하고 있다면 해당 페이지의 데이터를 반환(Response) 한다.(없다면 없는 페이지를 반환)
3.브라우저는 서버에게 전달 받은 데이터를 기반으로 홈페이지를 브라우저에 그려준다.
여기서 '데이터'는 어떠한 데이터든 주고 받는게 가능하다.
홈페이지에서 개발자 도구 열기
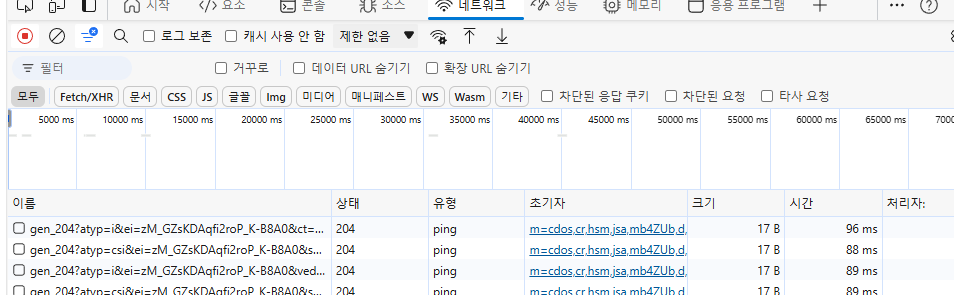
개발자 도구를 열어서 안에 있는 네트워크를 클릭하면 나오는 창이다.
여기서 리스트에 있는 값들중 아무것이나 하나를 클릭해보면,
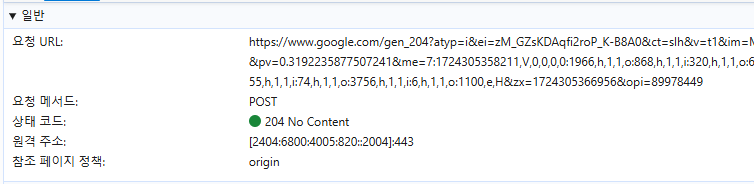
이런식의 창이 나오게 되는데 이것은 요청(Request)이 어떻게 처리되었는지에 대해서 볼 수 있다.
GET과 POST(Method)
GET: 어떤 리소스를 얻을 때 사용한다.
홈페이지를 눌렀을 때 해당 홈페이지의 정보를 얻어올 때 사용
POST: 웹 서버에 데이터를 게시할 때 사용한다.
회원가입을 할때, 글을 게시할 때 등에 사용
Header(추가데이터,메타데이터)
- 브라우저가 어떤 페이지를 원하는지
- 요청 받은 페이지를 찾았는지
- 성공적으로 찾았는지 등과 같이
다양한 의사표현을 위한 데이터들이 모두 Header필드에 넣어서 보내진다.(메서드도 마찬가지)
Payload
서버가 응답을 보낼 때 항상 Payload를 보낼 수 있다. => JSON과 같이 다양한 방식으로 처리한다.
3.웹 서버 이해
웹서버란
HTTP(프로토콜)을 이용하여 인터넷 상에 클라이언트의 요청을 처리하고 응답해주는 컴퓨터/프로그램
(클라이언트의 HTTP 요청을 받아 정적인 컨텐츠 - HTML,CSS,이미지 등을 제공한다.)
필요한 경우엔 웹 어플리케이션 서버(AWS)에 클라이언트의 요청을 전달하여 처리할 수도 있다.
대표적인 웹 서버:Apache,Nginx
웹 어플리케이션 서버(AWS)란
웹 서버와 협력하여 동적인 컨텐츠를 제공한다. => 데이터베이스(DB) 조회, 복잡한 계산과 같은 비즈니스 로직을 처리
클라이언트의 요청을 웹 서버로부터 전달받아 처리,결과를 다시 웹서버에 반환 ,클라이언트가 응답을 받을 수 있다.
기본적으로 브라우저가 웹서버에 요청(Request)할 때 주로 GET 메서드를 사용하며 POST,PUT,DELETE와 같은 메서드들은 서버에 다른 타입의 요청을 보낼때 사용된다.
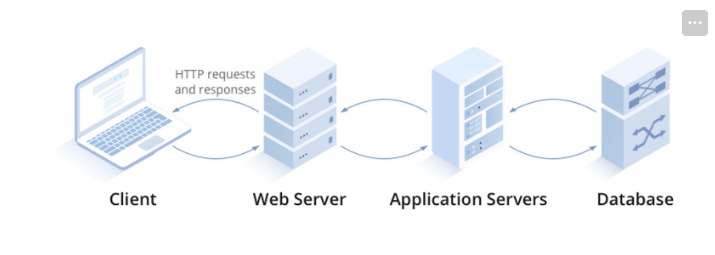
JavaScript란?
웹 브라우저는 보통은 정적인(Static) 문서이지만 이를 동적(Dynamic)으로 만들기 위해 만들어진 것이다.
동적인(Dynamic) 페이지란?
사전에서 동적인 이라는 것은 움직임이 있다는 뜻인데, 이 그대로다.
기존의 홈페이지에서 움직임을 추가한 것이고, 이 움직임은 사용자가 웹브라우저와 상호작용(interaction)을 할 수 있게끔 만들어 주는 것이다.
=> 즉 상호작용을 할 수 있다는 것은 홈페이지가 실시간으로 계속 변화할 수 있다는 것이다.
이런식으로 나와있는 카드들을 누름으로써 새롭게 홈페이지가 열리거나 하는 등 js를 이용하면 홈페이지와 상호작용을 할 수 있게 되었다.
Node.js란?
Node.js의 구성요소
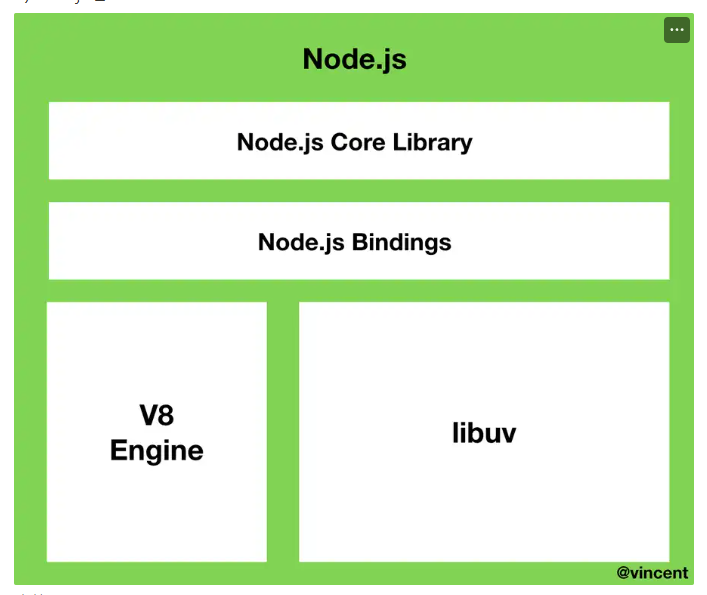
Node.js Core Library => 각종 라이브러리들을 저장하고 있다.
V8 Engine => js를 실행했을때 실제로 결과를 확인할 수 있는 엔진
libuv =>비동기 I/O, DB와 같은 데이터들을 불러내는 과정에서 비동기 처리를 위한 라이브러리다.(없을 경우 동기적으로 하나씩 불러와야 한다.)
Node.js Bindings=> libuv와 v8 Engine은 c나 c++로 구현되어있어서 js언어를 읽지못하지만 이 bindings가 js언어를 c나 c++로 바꾸어 넘겨주게 된다.
Node.js의 특징들
1.논블로킹 I/O
시스템 호출이 완료되기를 기다리지 않고 바로 다음 작업으로 즉시 넘어갈 수 있는 방식, 호출된 함수는 작업의 완료 여부와 상관없이 즉시 제어권을 호출한 함수에게 반환한다.
일반적인 블로킹의 처리 방식
논블로킹의 처리 방식