프로세스
실행중인 프로그램
하나의 프로세스는 실행을 위해 독립된 메모리 공간을 할당 받음
각 프로세스는 운영체제에 의해 독립적으로 관리되며 하나의 프로그램이 여러 프로세스를 생성할 수 있다.
프로세스 구조
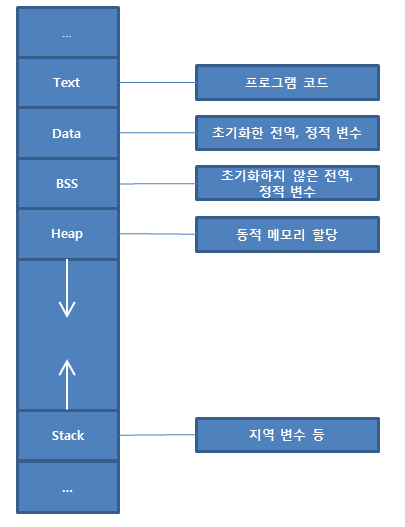
텍스트 세그먼트(코드 세그먼트)
프로그램의 실행 코드(CPU가 실행할 명령어들)를 저장한다.
텍스트 세그먼트는 읽기 전용(read only)으로 js로 작성된 코드가 기계어로 변환되어 텍스트 세그먼트에 저장된다.
기계어: CPU가 컴파일없이 바로 읽을 수 있는 프로그래밍 언어(CPU가 바로 해독할 수 있는 유일한 언어)
기계어는 CPU를 직접 제어한다. => 기계어 명령어로 CPU에 직접 동작을 내린다.이렇게 저장된 명령어들을 하나씩 호출하여 실행한다.
데이터 세그먼트
데이터 세그먼트는 초기화된 데이터와 되지않은 데이터로 나눌 수 있다.
초기화된 데이터 세그먼트(Initialized Data Segment): 초기화된 전역 변수나 정적 변수를 저장
JS에서는 전역 변수를 지원하나, 정적 변수는 함수 안에 존재하지 않는다.
그러나 모듈 내 상수(const), 전역 스코프에 정의된 값은 초기화된 데이터로 볼 수 있다.초기화되지 않은 데이터 세그먼트(BSS): 초기화되지 않은 전역 변수 또는 정적 변수를 저장한다.
JS에서는 변수를 선언과 동시에 초기화함으로써 중요하지 않다.
=> 초기화 되지 않는 경우에 undefined 값을 갖는다.스택 세그먼트
함수 호출시 생성되는 지역 변수와 매개 변수를 저장
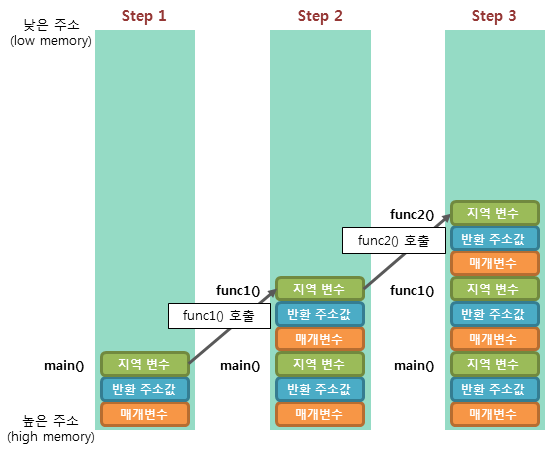
함수가 호출될 때마다 스택 프레임이 만들어지며 함수가 반환되면 스택에서 해당 프레임이 제거된다. => 스택은 함수 호출이 끝나면 메모리가 자동으로 해제된다.
스택 오버 플로우: 스택의 크기는 각 운영체제에 따라서 다르지만 제한적이다.
그렇기에 함수가 많이 중첩 호출되어 스택의 크기를 넘었을 떄 스택 오버 플로우 에러가 발생하여 데이터가 유실되는 등의 에러가 발생한다.힙 세그먼트
동적 메모리 할당이 이루어지는 공간,
객체/배열/함수 같은 참조 타입들이 힙에 저장된다.
=> map 함수 같은 경우, key값 - value 값이 매칭되는 식으로 실제 value 값을 메모리에 저장하는 것이 아닌 주소 값(key 값)을 저장하는 방식
스택은 함수 호출이 종료되면 자동으로 메모리가 삭제되지만
힙은 스택과 달리 관리되지 않기 떄문에 **메모리 누수 => 데이터가 쓸모 없어지는 시점에서 제거되지 못하는 현상**가 발생할 수 있다.프로세스 메모리 구조의 중요성
스택 vs Heap
스택 메모리: 빠르고 효율적이나 크기가 제한적임 => 빠르게 할당 및 해제가 되는 간단한 메모리 관리에 적합.
ex) [()] 괄호 순서 문제, [에서 ]을 만나기 전까지 스택에 임시 저장해두는 방식
힙 메모리: 큰 데이터 저장하는데 적합, 메모리 관리가 더 복잡하고 성능 비용이 스택보다 크다.
스택은 연속적이고 선입 선출이 되는 메모리인 반면,
힙 메모리는 주소를 저장하는 메모리는 연속적이나 값을 저장하는 메모리는 단편적이므로
메모리를 검색할 때 걸리는 시간이 스택보다 느릴수도 있다.가비지 컬렉션(JS 기준)
JS는 가비지 컬렉션을 통해 더이상 참조되지 않는 객체의 메모리를 자동으로 해제한다.
마크 앤 스위프:
마크 앤 스위프 방법은 크게 2페이즈로 나뉘는데
1. 마크 페이즈: 객체가 생성되면 비트를 0(false)로 표시하고 모든 도달 가능한 객체, 사용자가 사용가능(참조 가능)한 객체에 1(true)를 표시한다.
이때 모든 노드에 깊게 방문해야하므로 DFS를 사용한다.
2. 스윕 페이즈: 마크가 1로 표시된 걸 제외한(도달 불가능한) 객체들을 전부다 지워버린다.
마크앤 스위프 방식의 장점은 DFS를 사용하기 때문에 순환 참조 문제(A->B 참조 / B->A 참조)를 해결할 수 있다.
이것이 가능한 이유는 객체의 접근 가능 여부를 가지고 메모리 해제를 결정하기 때문
단점으로는 가비지 컬렉션 수행중엔 프로그램의 실행이 잠시 중지되며 마크앤 스위프가 여러번 실행되었을 때 접근 가능한 메모리가 접근 불가능한 메모리들 사이에서 분리되는 단편화 현상이 일어나게 된다.
단편화: 기억장치의 빈 공간 또는 자료가 여러 개의 조각으로 나뉘게 되는 것
단편화의 종류 - 내부,외부
내부 단편화: 주 기억장치내 사용자 영역이 실행 프로그램보다 커서 프로그램을 할당한 후에도 사용되지 않고 남는 공간
외부 단편화: 할당된 메모리 내부에서 생기는 단편화가 아닌 외부에서 할당, 삭제를 반복하면서 사용되는 메모리 사이에 빈 메모리들의 공간이를 해결하기 위한 페이징,세그먼테이션 기법 등이 있지만 다음에 설명하는 걸로 하겠다.
세대별 가비지 컬렉션:
V8 엔진과 같은 최신 JS 엔진에서는 세대별 가비지 컬렉션을 사용한다.
세대별 가비지 컬렉션은 생성된 시기에 따라서 젊은 세대와 오래된 세대로 나누고, 각각 다른 기준으로 가비지 컬렉션을 수행하는 방식이다.
젊은 객체: 더 많이 가비지 컬렉션을 수행
오래된 객체: 더 적게 수행
프로세스의 특징
독립된 실행 단위: 각 프로세스는 독립적인 주소 공간을 갖는다.
즉, 하나의 프로세스가 다른 프로세스에 접근할 수 없다.
프로세스 간 통신(IPC): 프로세스 간 데이터를 주고받기 위해선 운영체제의 도움이 필요하며, 이를 프로세스 간 통신이라고 한다.
IPC의 방식: 파이프,메시지 큐, 공유 메모리 등이 있다.
컨텍스트 스위칭: 운영체제는 멀티태스킹을 지원하기 위해 여러 프로세스를 빠르게 전환한다.
각 프로세스의 상태를 저장,복원하는 과정에서 오버헤드가 발생할 수 있다.
스레드
스레드는 프로세스 내에서 실행의 흐름을 담당하는 단위
하나의 프로세스에는 하나 이상의 스레드가 존재할 수 있고, 이들은 같은 메모리 공간을 공유한다.
스레드 = 프로세스의 경량화된 실행 단위
스레드의 구조
스레드는 같은 프로세스 메모리 공간을 공유하나 각각 독립적인 스택을 가진다.
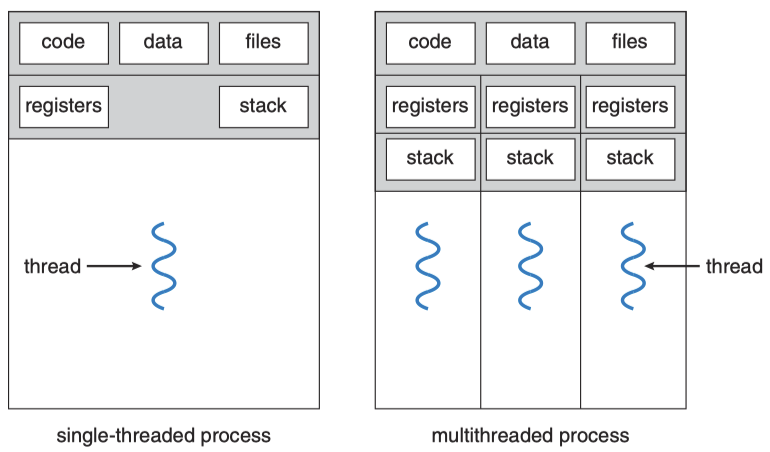
텍스트 세그먼트: 스레드는 프로세스의 코드를 공유한다.
데이터 세그먼트: 전역 변수와 정적 변수를 공유한다.
힙: 동적으로 할당된 메모리를 공유한다.
스레드의 특징
-
가벼운 실행 단위: 스레드는 같은 프로세스 내에서 자원을 공유하기 떄문에 스레드 간 전환은 프로세스 간 전환보다 오버헤드가 적다. => 컨텍스트 스위칭이 빠르다.
-
동기화 문제: 스레드들은 같은 메모리 공간을 공유하기에 동시성 문제가 발생할 수 있다.
동시성 문제: 동일한 하나의 데이터에서 2개 이상의 스레드 혹은 세션에서 가변 데이터를 동시에 제어할 떄 나타나는데,
제어 순서에 따른 원하는 데이터를 얻지 못하는 문제가 발생할 수도 있다.
이를 방지하는 방법은 여러가지 방법이 있다.
Lock걸기 , DB Lock 걸기 등과 같은 다양한 방법들이 있다.