
JPA 소개
객체 vs RDB 패러다임의 불일치
-
상속
- RDB는 완전한 상속관계를 지원하지 않는다.
-
연관관계
-
객체는 참조를 사용하고, RDB는 외래키를 사용하여 연관관계를 표현한다.
-
객체가 외래키 값을 멤버변수로 갖는 것은 자연스러운 객체 설계가 아니다.
-
-
객체 그래프 탐색
-
객체는 참조를 사용해 자유롭게 연관된 객체들을 탐색할 수 있다.
-
RDB는 처음 실행하는 SQL에 따라 탐색 범위가 결정된다.
-
-
비교
- RDB에서 같은 튜플을 가져오더라도, 객체의 동일성 비교에서는 다르다는 결과를 반환한다.
String memberId = "100";
Member member1 = memberDAO.getMember(memberId);
Member member2 = memberDAO.getMember(memberId);
member1 == member2; // 결과 falseJPA (Java Persistence API)
-
자바 진영의 ORM 기술 표준
-
Object-Relational Mapping (객체 관계 매핑)
-
객체는 객체대로, RDB 는 RDB 대로 설계
-
-
JPA (ORM 프레임워크) 가 애플리케이션과 JDBC API 중간에서 패러다임의 불일치 해결
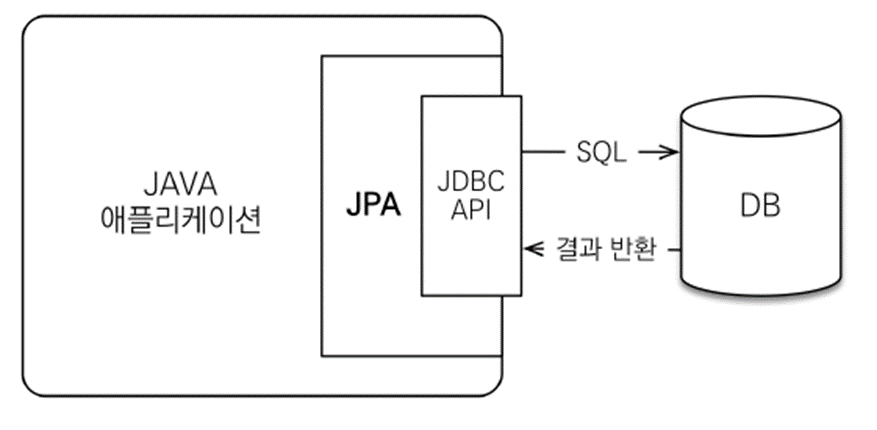
JPA의 위치

데이터 저장시의 JPA 동작
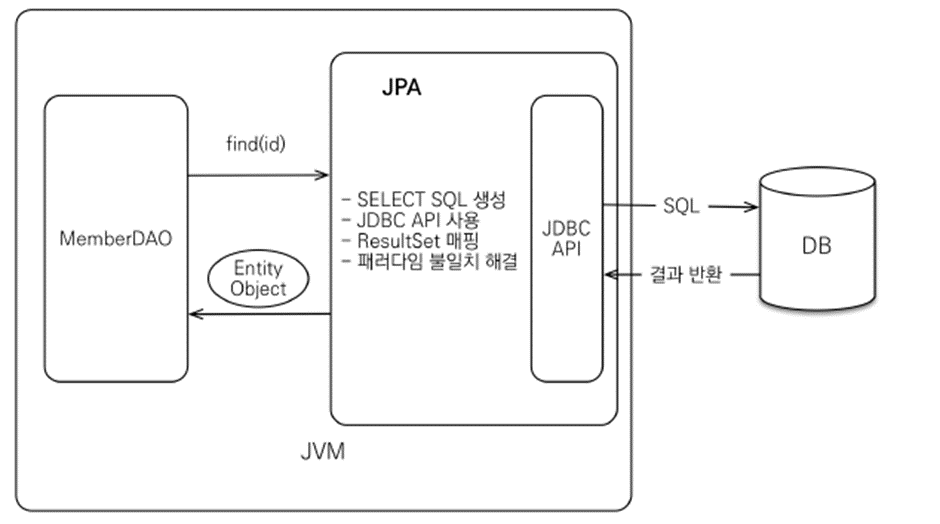
데이터 조회시의 JPA 동작
JPA 장점
-
SQL 중심 개발 ➔ 객체 중심 개발
-
생산성, 유지보수 증가
-
패러다임 불일치 해결
-
데이터 접근 추상화 & 벤더 독립성
- 특정 데이터베이스에 종속적이지 않도록 설계되어 있다.
JPA 성능 최적화 기능
-
1차 캐시와 동일성 보장
-
같은 트랜잭션 내에서 같은 엔티티를 두번 이상 조회하는 경우,
-
첫 번째엔 RDB에서 가져와 1차 캐시에 저장하고,
-
두 번째 이후 부턴, 1차 캐시에서 일치하는 엔티티를 찾아 반환한다.
-
-
트랜잭션을 지원하는 쓰기 지연
-
트랜잭션 커밋할 때 UPDATE, DELETE SQL 들을 한번에 실행
-
INSERT의 경우
identity전략 사용 시,em.persist(id 아직 없는 엔티티 객체)시 마다 INSERT 쿼리가 나간다.-
이를 통해, DB에 왔다갔다해야만, 엔티티의
id값을 알 수 있고, -
영속성 컨텍스트에 둘 수 있다.
-
즉, INSERT 를 모아서 한번에 실행하지 않는다.
-
-
-
지연 로딩
-
객체가 실제 사용될 때 로딩
-
즉시 로딩과 반대되는 방식이다.
-
주의점
-
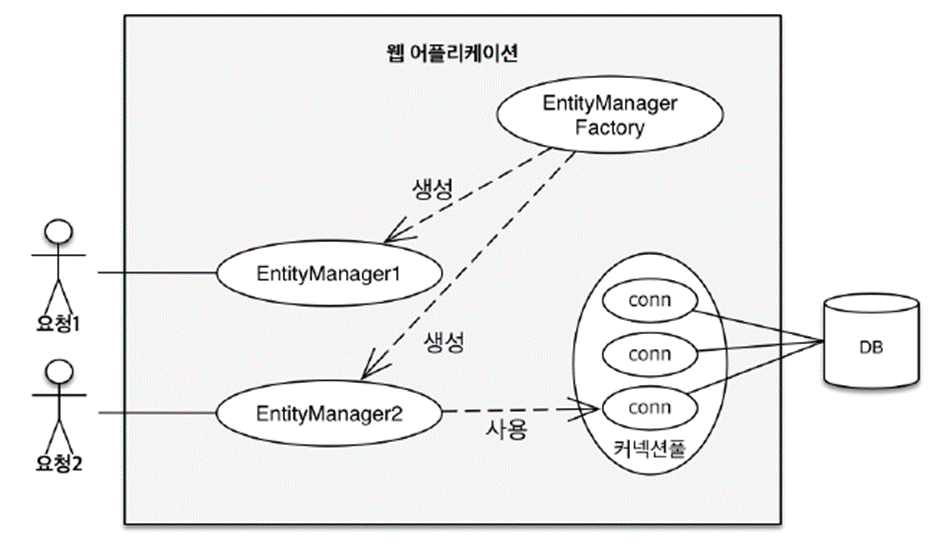
엔티티 매니저 팩토리는 하나만 생성 ➔ 애플리케이션 전체에서 공유
-
엔티티 매니저는 쓰레드간 공유하지 않는다.
- 일회용 (사용하고 버린다)
-
JPA 모든 데이터 변경은 트랜잭션 안에서 수행해야 한다.
영속성 관리
영속성 컨텍스트
-
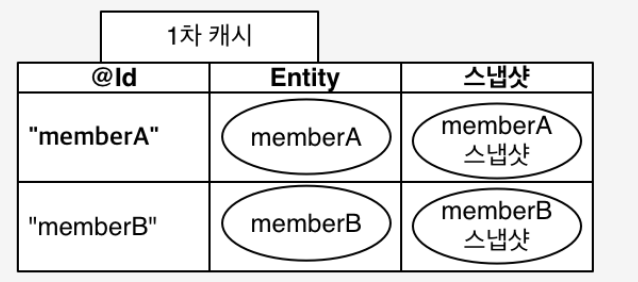
엔티티를 영구 저장하는 환경 (1차 캐시)
@Id가 key값이고, 엔티티 객체가 value 가 된다.
-
논리적인 개념
-
엔티티 매니저를 통해 영속성 컨텍스트에 접근
-
entityManager.persist(entity)는 엔티티를 영속성 컨텍스트에 저장하는 것 -
DB에 저장하는 것이 아니다.
-
엔티티의 생명주기
-
비영속 (new)
-
영속 (managed)
-
준영속 (detached)
-
삭제 (removed)
비영속
Member member = new Member();
member.setId("member1");
member.setUsername("회원1");
- 객체를 생성한 상태
- 영속성 컨텍스트에서 관리 X
영속
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
//객체를 저장한 상태(영속)
em.persist(member);
- 객체를 영속성 컨텍스트에 저장
- 영속성 컨텍스트에 관리 O
준영속
em.detach(member);
- 객체를 영속성 컨텍스트에서 분리
- 영속성 컨텍스트에서 관리 X
em.clear();
- 영속성 컨텍스트를 완전히 초기화
em.close();
- 영속성 컨텍스트를 종료
삭제
em.remove(member);
- 객체와 매핑되는 데이터를 DB에서 삭제
- 영속성 컨텍스트에서 관리 X
영속성 컨텍스트의 기능
-
1차 캐시 역할을 한다.
-
영속성 컨텍스트에
@Id키 값이 없는 경우에만 DB에서 조회한다. -
DB에서 조회한 경우, 조회한 값을 영속성 컨텍스트에 저장한다.
-
-
동일성 보장
- 트랜잭션 내에서 같은 엔티티 조회 시, 두 엔티티의 동일성을 보장 (
== true)
- 트랜잭션 내에서 같은 엔티티 조회 시, 두 엔티티의 동일성을 보장 (
-
쓰기 지연
-
트랜잭션이 끝날때까지 쓰기 쿼리들을 날리지 않고 모아둔다.
-
트랜잭션이 끝나면 모아둔 쿼리들을 한번에 날린다.
-
-
변경 감지
-
Dirty Checking
-
엔티티가 최초로 영속성 컨텍스트에 저장될 때 스냅샷을 만든다.
-
flush할 때 엔티티가 최초의 스냅샷과 다른 경우, 변경사항을 UPDATE 하는 쿼리를 날린다.
-
플러시 flush
-
영속성 컨텍스트의 변경내용을 DB에 반영
-
쓰기 지연 SQL 저장소의 쿼리를 DB에 전송한다.
- 등록, 수정(변경 감지), 삭제 쿼리
-
영속성 컨텍스트를 비우지 않는다.
-
플러시 모드 옵션 설정 가능
-
em.setFlushMode(FlushModeType.AUTO)➔ 커밋, 쿼리 실행 시 플러시 (기본값) -
em.setFlushMode(FlushModeType.COMMIT)➔ 커밋시에만 플러시
-
-
3가지 방법으로 호출할 수 있다.
-
em.flush()(강제 호출) -
트랜잭션 커밋 (자동 호출)
-
JPQL 쿼리 실행 (자동 호출)
-
엔티티 매핑
데이터베이스 스키마 자동 생성
-
개발 초기 단계에서 쉽게 테이블들을 자동 생성할 수 있다.
-
spring.jpa.hibernate.ddl-auto=옵션-
create➔ 애플리케이션 부팅 시, 기존 테이블 삭제 후 다시 생성 -
create-drop➔drop-create-drop(애플리케이션 종료시점에 테이블들을 삭제 한다.) -
update➔ 엔티티에 테이블에는 없는 추가된 변경사항이 있으면 추가한다. -
validate➔ 부팅 시, 엔티티와 테이블이 정상 매핑되었는지만 확인 -
none➔ 기본값, 아무일도 안 일어남
-
-
운영 서버에서는
create,create-drop,update를 사용하지 않는 것이 좋다.
객체와 테이블 매핑
-
@Entity-
JPA 를 사용해 테이블과 매핑할 클래스에 부착 (해당 클래스는 엔티티라 한다.)
-
기본 생성자 필수
public또는protected접근 권한
-
final클래스,enum,interface,inner클래스는 엔티티로 사용할 수 없다.
-
@Entity
@Table(name = "MEMBER")
public class Member{
@Id @GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
// ...
}
@Table(name = "MEMBER")
- 매핑할 테이블 이름을 지정한다.
- 기본값은 클래스 이름 그대로 테이블을 매핑한다.
필드와 컬럼 매핑
-
@Column-
테이블의 컬럼이 될 클래스 내부 필드위에 부착
-
속성
-
name➔ 테이블 컬럼 이름을 매핑 -
insertable,updatable➔ 등록, 변경 가능 여부 -
nullable➔null값 허용 여부 -
unique➔ 유니크 제약 조건 걸기 -
length➔ 문자 길이 제약 조건 걸기 -
columnDefinition➔ 컬럼 정의를 String으로 직접하기
-
-
-
@Enumerated-
자바 enum 타입 필드위에 부착
-
속성
-
value=EnumType.ORDINAL➔ enum 순서를 DB에 저장, 기본값, 비권장 -
value=EnumType.STRING➔ enum 이름을 DB에 저장
-
-
-
@Transient-
주로 메모리상에서만 임시로 사용하고 싶은 클래스 내부 필드위에 부착
-
필드를 테이블 컬럼에 매핑 X ➔ DB에 반영 X
-
@Entity
public class Member {
@Id
private Long id;
@Column(name = "name")
private String username;
private Integer age;
@Enumerated(EnumType.STRING)
private RoleType roleType;
@Temporal(TemporalType.TIMESTAMP)
private Date createdDate;
@Lob
private String description;
@Transient
private int temp;
}
Long id➔id bigint
String username➔name varchar(255)
@Column(name = "name")에 의해 컬럼의 이름을name으로 설정된다.
Integer age➔age integer
RoleType roleType➔roleType varchar(255)
@Enumerated(EnumType.STRING)에 의해 enum이 String으로 저장된다.
Date createdDate➔createdDate timestamp
@Temporal(TemporalType.TIMESTAMP)에 의해 날짜 타입이TIMESTAMP로 설정된다.LocalDateTime이나LocalDate타입을 사용하면 날짜 타입 애노테이션을 생략할 수 있다.
String description➔description clob
@Lob에 의해clob으로 설정된다.
@Transient에 의해int temp는 테이블에 컬럼으로 생성되지 않는다.
기본키 매핑
-
@Id- 해당 필드를 PK로 사용
-
@GeneratedValue-
PK 필드위에 부착
-
기본키 생성 전략 설정
-
IDENTITY ➔ 기본 키 생성을 데이터베이스에 위임, ex) MySQL AUTO_INCREMENT
-
SEQUENCE ➔ 시퀸스 오브젝트 사용, ex) ORACLE
-
TABLE ➔ 키 생성 전용 테이블을 하나 만들어서 데이터베이스 시퀸스를 흉내내는 전략
-
AUTO ➔ DB 방언에 맞게 자동 생성
-
-
-
Long 형 + 대체키 + 키 생성전략사용을 권장- null 이 아니고, 유일하며 절대 변하면 안되는 자연키를 찾기는 어려우므로, 대체키를 사용하는 것을 권장한다.
연관관계 매핑
객체를 테이블에 맞추어 모델링
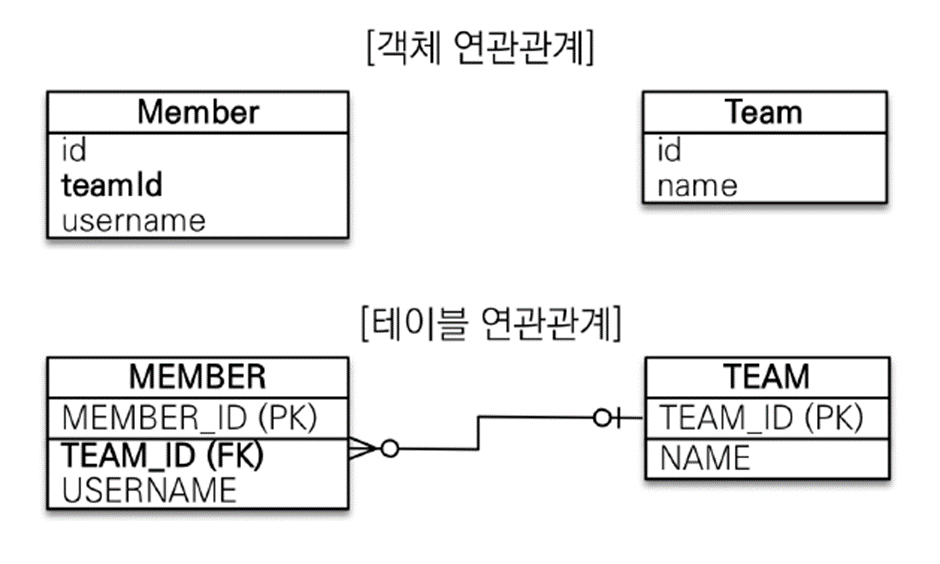
참조 대신 외래키를 사용
//팀 저장
Team team = new Team();
team.setName("TeamA");
em.persist(team);
//회원 저장
Member member = new Member();
member.setName("member1");
member.setTeamId(team.getId());
em.persist(member);
member.setTeamId(tema.getId())- 외래키 식별자를 직접 다뤄야 한다.
- 객체 지향적인 방법 X
-
객체를 테이블에 맞추면, 객체의 협력 관계를 만들 수 없다.
-
객체는 참조를 사용해 연관된 객체를 찾는다.
-
테이블은 외래키로 조인을 사용해 연관된 테이블을 찾는다.
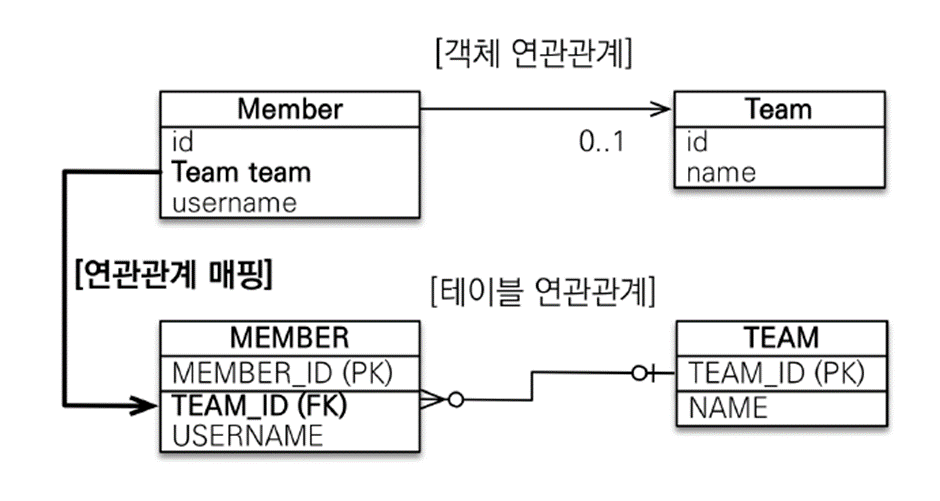
객체 지향 모델링 - 단방향 연관관계
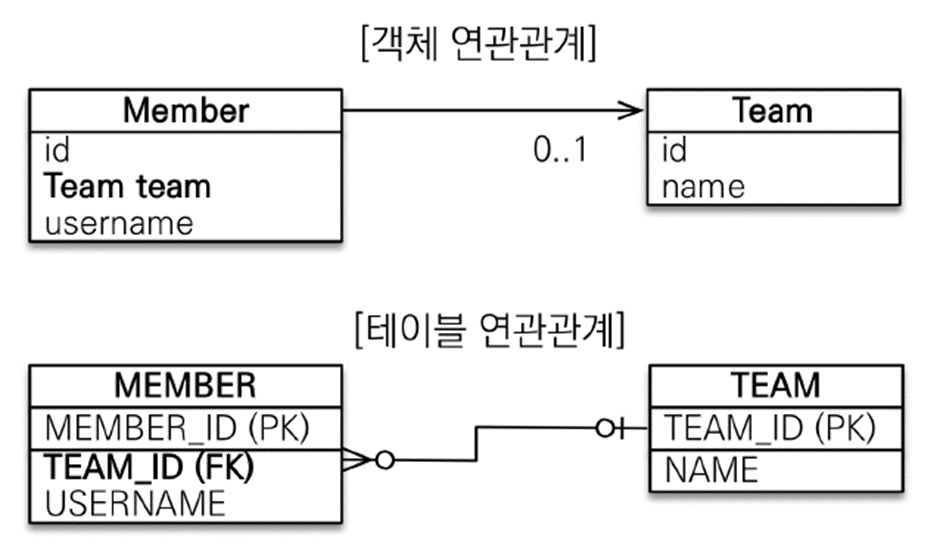
객체 연관관계는 참조를 사용 (
Team team)
@Entity
public class Member {
@Id @GeneratedValue
private Long id;
@Column(name = "USERNAME")
private String name;
private int age;
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
}
@ManyToOne
- 다대일 관계 설정
@JoinColumn(name="TEAM_ID")
- 해당 필드를 테이블의
TEAM_ID와 매핑private Team team
- 외래키대신 참조를 사용
//팀 저장
Team team = new Team();
team.setName("TeamA");
em.persist(team);
//회원 저장
Member member = new Member();
member.setName("member1");
member.setTeam(team); //단방향 연관관계 설정, 참조 저장
em.persist(member);
member.setTeam(team)
- 객체 지향적인 사용
객체 지향 모델링 - 양방향 연관관계
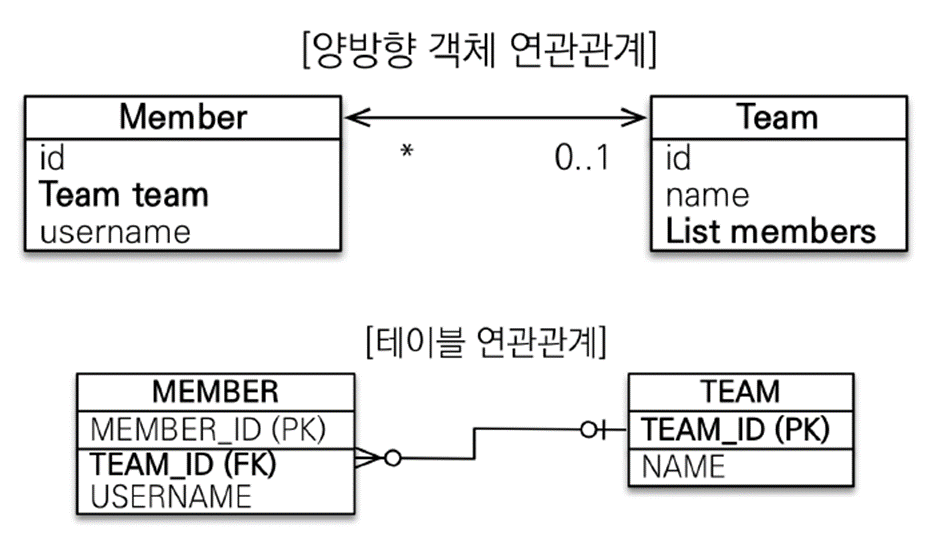
양방향의 객체 연관관계 모델링
-
Member엔티티는 단방향의 경우와 동일 -
Team엔티티에는@OneToMany필드가 추가된다.
@Entity
public class Team {
@Id @GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "team")
List<Member> members = new ArrayList<Member>();
// …
}
@OneToMany(mappedBy="team")
- readOnly
- 연관관계의 주인 X
Member엔티티의team필드가 연관관계의 주인임을 표시
Team findTeam = em.find(Team.class, team.getId());
int memberSize = findTeam.getMembers().size(); //역방향 조회
Team객체에서Member객체를 역방향 조회할 수 있다.
-
연관관계의 주인
-
객체의 양방향 연관관계 ➔ 객체 간 단방향 연관관계가 두개
-
따라서 한쪽 객체의 수정사항이 반대쪽 객체에 자동으로 반영되지 않는다.
-
테이블은 한쪽 테이블의 수정사항이 반대쪽 테이블에 반영되어야 한다.
-
연관관계 주인의 변경사항만 테이블에 반영되도록 설정
-
연관관계의 주인이 아닌쪽은 데이터 읽기만 가능
-
-
외래키를 관리하는 참조 (주로
@ManyToOne, 다 쪽 테이블) 를 연관관계의 주인으로 설정-
외래키의 위치를 기준으로 정한다.
-
외래키와 매핑되는 필드가 존재하는 객체에서 외래키에 대한 쿼리가 나가는 것이 자연스럽고 이해하기 쉽다.
-
-
-
양방향 연관관계 주의점
-
무한 루프를 주의
toString(),lombok,JSON 라이브러리
-
양방향 매핑은 역방향 조회가 필요할 때 하나씩 추가한다.
-
그러나
@OneToMany(일대다에서 일 쪽 테이블) 단방향조회가 필요한 경우, -
양방향 조회가 필요하지 않더라도,
@ManyToOne(일대다에서 다 쪽 테이블) 을 연관관계 주인으로하는 양방향 매핑을 하는 것이 낫다. -
그렇지 않으면 직관성이 떨어지고 추가적인
update쿼리가 나가게 된다.
-
-
연관관계 주인에는 반드시 값을 입력해야 한다.
- 연관관계 편의 메서드를 만들어, 양쪽 값을 동시에 설정하는게 제일 좋다.
-
@Entity
public class Member {
// ...
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
public void changeTeam(Team team) {
this.team = team;
team.getMembers().add(this); // team 객체의 members 리스트에 자기 자신(member) 추가
}
}
@Entity
public class Team {
// ...
@OneToMany(mappedBy = "team")
List<Member> members = new ArrayList<Member>();
public void addMember(Member member) {
members.add(member);
member.setTeam(this); // member 객체에 자기 자신(team) 설정
}
}
Member.changeTeam(Team team)과Team.addMember(Member member)는 연관관계 편의 메서드이다.
- 한쪽 객체의 변경사항이 반대쪽 객체에도 반영된다.
Self Referencing 관계
-
같은 테이블 내에서의 관계를 표현할 수 있다.
-
예를 들어,
Category엔티티가 하나의 상위 카테고리가 여러개의 하위 카테고리를 갖는다고 할 때
@Entity
public class Category {
@Id
@GeneratedValue
private Long id;
private String name;
@ManyToOne
@JoinColumn(name = "parent_id")
private Category parent;
@OneToMany(mappedBy = "parent")
private List<Category> child = new ArrayList<>();
}
private Category parent
- 하위 카테고리가 갖는 상위 카테고리의 참조
- 하위 카테고리는 일대다에서 다 쪽에 해당한다.
private List<Category> child
- 상위 카테고리가 갖는 하위 카테고리들의 참조
- 상위 카테고리는 일대다에서 일 쪽에 해당한다.
고급 매핑
상속관계 매핑
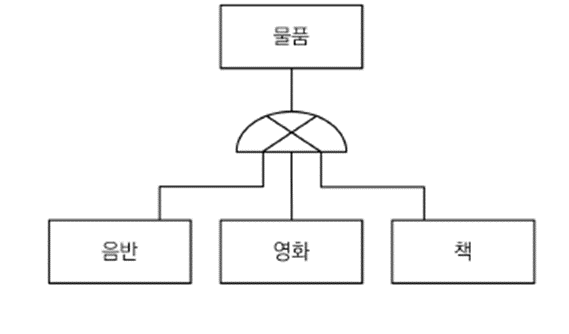
-
조인 전략
-
각각의 테이블로 변환
-
테이블 정규화
-
데이터 조회 시 조인을 필요로 함
-
데이터 저장 시 INSERT 를 두번 호출해야 한다.
-
조회 쿼리가 복잡하다.
-
@Inheritance(strategy=InheritanceType.JOINED)로 사용
-
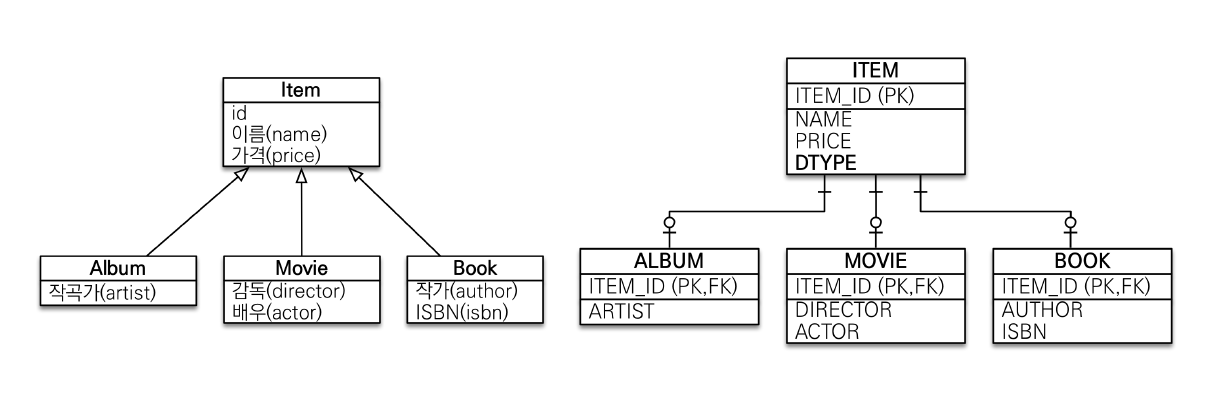
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
@DiscriminatorColumn
public abstract class Item {부모클래스
- 클래스를 직접 사용할 일이 없으므로
abstract클래스로 선언@Inheritance➔ 테이블 상속 관계 설정@DiscriminatorColumn➔ 자식 엔티티들 (서브타입) 을 구별하기 위한 컬럼이 생성된다.
- 구별 컬럼이름의 기본값은 DTYPE 이다.
@Entity
@DiscriminatorValue("A")
public class Album extends Item{
private String artist;
}
@Entity
@DiscriminatorValue("B")
public class Book extends Item{
private String author;
private String isbn;
}
@Entity
@DiscriminatorValue("M")
public class Movie extends Item{
private String director;
private String actor;
}자식 클래스들
@DiscriminatorValue(value=구별용 DTYPE값)
- 해당 엔티티를 저장할 때 구분용 컬럼에 저장할 값을 지정한다.
- 생략 시, 엔티티 이름(클래스 명) 을 값으로 저장
-
단일 테이블 전략
-
통합 테이블로 변환
-
데이터 조회 시 조인 필요 X
-
조회 쿼리가 단순하다.
- 비교적 성능이 좋다.
-
자식 엔티티가 매핑하지 않은 컬럼은 모두 null 처리
-
@Inheritance(strategy=InheritanceType.SINGLE_TABLE)로 사용 -
구별용 컬럼이 반드시 필요하다.
@DiscriminatorColumn를 생략해도 반드시 DTYPE 컬럼이 추가된다.
-
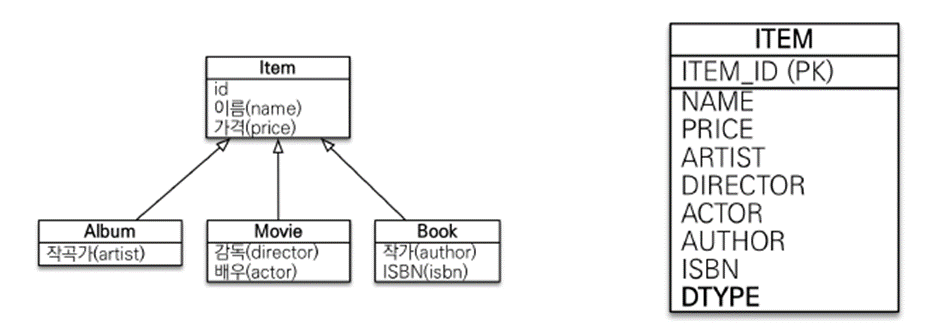
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn
public abstract class Item {-
서브타입 테이블로 변환
-
구현 클래스마다 테이블 생성
-
비권장 ➔ 조회 불편, 자식테이블 통합 어려움
- 부모테이블 조건들로 조회 시 자식테이블을 UNION으로 전부 합쳐야 한다.
-
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)로 사용
-
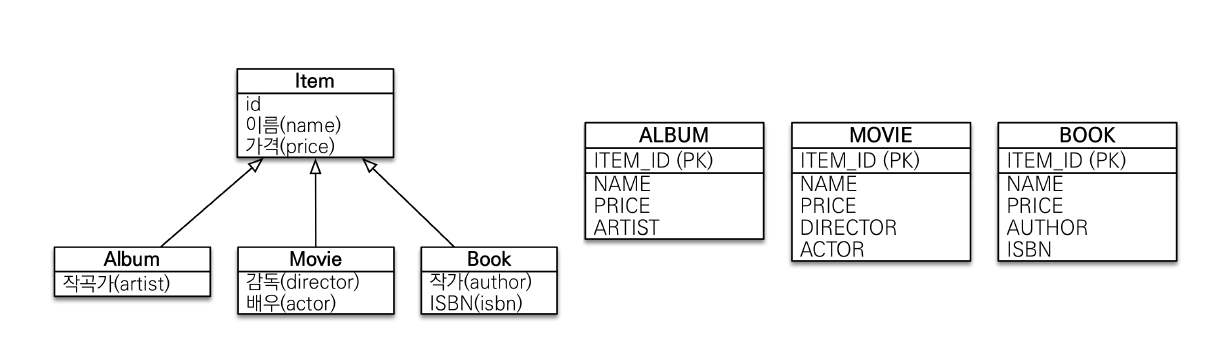
@Entity
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
@DiscriminatorColumn
public abstract class Item {@MappedSuperclass
-
공통 매핑 정보가 필요할 때 사용
-
엔티티 아님, 테이블 생성 X
-
부모 클래스를 상속받는 자식 클래스에 매핑 정보만 제공
-
조회, 검색 불가
-
직접 생성해 사용할 일이 없다 ➔ 추상 클래스 권장
-
@Entity클래스는@Entity클래스나@MappedSuperclass클래스만 상속 가능
@MappedSuperclass
public abstract class BaseEntity {
// ...
@Entity
public class Team extends BaseEntity{
Team엔티티에BaseEntity내의 매핑 정보를 추가
프록시와 연관관계 관리
프록시
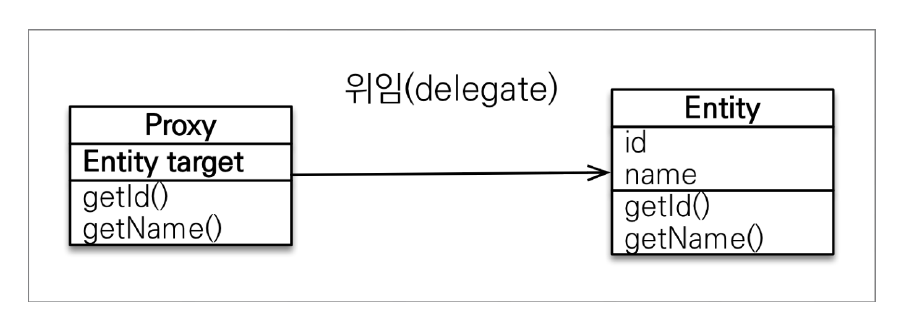
-
프록시 객체는 실제 객체의 참조(target)를 보관
-
entityManager.find()- 데이터베이스에서 바로 조회 쿼리를 날려 엔티티를 만든다.
-
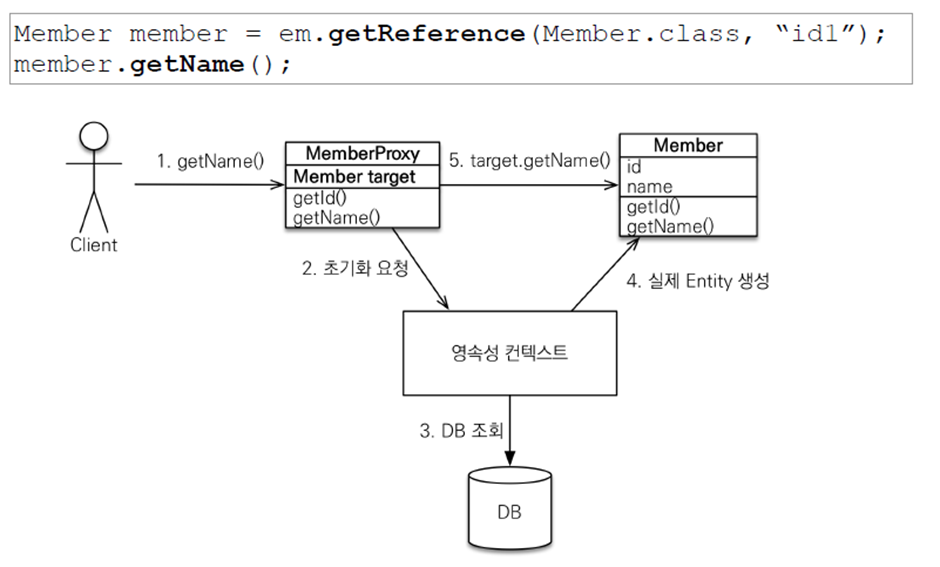
entityManager.getReference(엔티티 클래스, 엔티티 pk)-
데이터베이스에서 바로 조회 쿼리를 날려 데이터베이스를 조회하지 않고, 가짜 엔티티를 만든다.
-
실제 엔티티의 메서드 호출이 발생해야, 초기화 요청을 통해 DB에 조회 쿼리를 날린다.
-
이후 가짜 엔티티 (프록시 객체) 가 참조하는 실제 엔티티를 생성하고, 메서드를 호출한다.
-
-
프록시 객체는 한 번만 초기화된다.
-
프록시 객체의 초기화가 발생해도, 프록시 객체가 실제 엔티티로 바뀌는 것은 아니다.
- 프록시 객체를 통해 실제 엔티티에 접근 가능한 것이다.
-
-
프록시 객체는 실제 엔티티 타입을 상속받는다.
- 따라서 타입 체크시 주의해야 한다.
-
영속성 컨텍스트 안에서, 같은
id를 가진 두 엔티티의 동일성(==) 비교는 같음을 보장해야 한다.- 따라서 이를 만족하는 방식으로 조회 메서드가 동작한다.
Member findMember = em.find(Member.class, member1.getId());
Member refMember = em.getReference(Member.class, member1.getId());
System.out.println(findMember.getClass()); // class hellojpa.Member
System.out.println(refMember.getClass()); // class hellojpa.Member
System.out.println(findMember == refMember); // true
- 실제 엔티티가 먼저 조회된 경우
entityManager.getReference()는 프록시 엔티티가 아니라 실제 엔티티를 반환한다.
Member refMember = em.getReference(Member.class, member1.getId());
Member findMember = em.find(Member.class, member1.getId());
System.out.println(refMember.getClass()); // class hellojpa.Member$HibernateProxy$G3ahQIte
System.out.println(findMember.getClass()); // class hellojpa.Member$HibernateProxy$G3ahQIte
System.out.println(refMember == findMember); // true
- 프록시 엔티티를 먼저 생성한 경우
entityManager.find()는 실제 엔티티가 아닌 프록시 엔티티를 반환한다.
Member refMember = em.getReference(Member.class, member1.getId());
refMember.getName(); // 초기화
Member findMember = em.find(Member.class, member1.getId());
System.out.println(refMember.getClass()); // class hellojpa.Member$HibernateProxy$iSgLvZxC
System.out.println(findMember.getClass()); // class hellojpa.Member$HibernateProxy$iSgLvZxC
System.out.println(refMember == findMember); // true
- 프록시 엔티티를 먼저 생성한 뒤, 초기화 한 경우
entityManager.find()는 실제 엔티티가 아닌 프록시 엔티티를 반환한다.
-
이처럼 현재 다루는 엔티티가 프록시 엔티티인지 실제 엔티티인지 파악하기 쉽지 않다.
- 따라서, 프록시 엔티티인지, 실제 엔티티인지 신경쓰지 않아도 되도록 로직을 설계해야 한다.
-
객체가 영속성 컨텍스트에서 벗어난 준영속 상태일 때, 프록시 객체를 초기화하면
org.hibernate.LazyInitializationException예외가 발생한다.
지연 로딩
@Entity
public class Member {
@Id
@GeneratedValue
private Long id;
@Column(name = "USERNAME")
private String name;
@ManyToOne(fetch = FetchType.LAZY) //**
@JoinColumn(name = "TEAM_ID")
private Team team;
@ManyToOne(fetch = FetchType.LAZY)
- 지연로딩을 사용해 해당 엔티티를 프록시 조회
- 실제
team을 사용하는 시점에 조회 쿼리가 나간다.
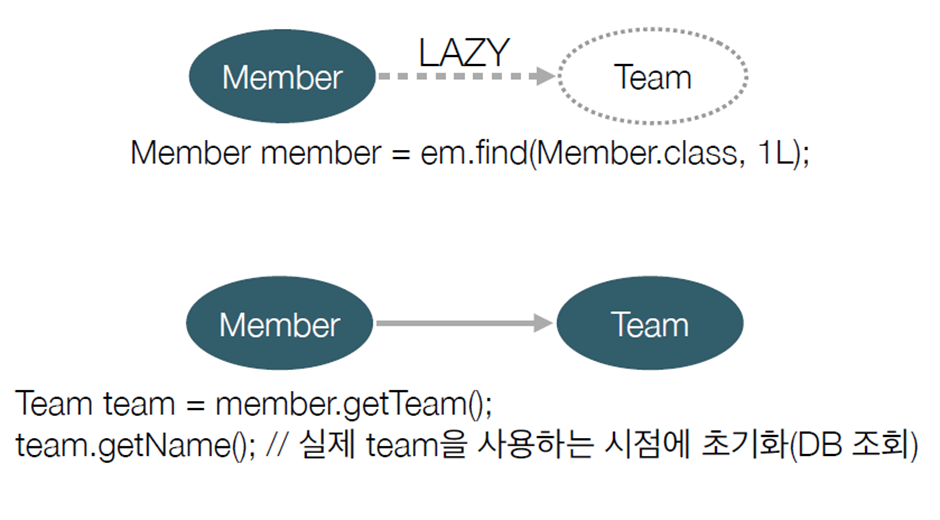
-
즉시 로딩은 사용을 지양한다.
-
예상하기 힘든 쿼리가 나간다.
-
JPQL 사용 시, N+1 문제가 발생한다.
-
@Entity
public class Member{
@Id @GeneratedValue
private Long id;
private String name;
@ManyToOne
@JoinColumn(name = "team_id")
private Team team;
}
Team team = new Team("teamA");
em.persist(team);
Member member = new Member("member1");
member.setTeam(team);
em.persist(member);
em.flush();
em.clear();
Member findMember = em.find(Member.class, member.getId());
Member가Team을 즉시 로딩하는 경우em.find()로Member엔티티 조회 시,Team엔티티까지 바로 가져오기 위해join쿼리 발생Hibernate: select member0_.id as id1_3_0_, member0_.name as name2_3_0_, member0_.team_id as team_id3_3_0_, team1_.id as id1_7_1_, team1_.name as name2_7_1_ from Member member0_ left outer join Team team1_ on member0_.team_id=team1_.id where member0_.id=?
Team team = new Team("teamA");
em.persist(team);
Member member = new Member("member1");
member.setTeam(team);
em.persist(member);
em.flush();
em.clear();
List<Member> members = em.createQuery("select m from Member m", Member.class)
.getResultList();
Member가Team을 즉시 로딩하는 경우em.createQuery("select m from Member m", Member.class)JPQL 사용 시,Hibernate: select member0_.id as id1_3_, member0_.name as name2_3_, member0_.team_id as team_id3_3_ from Member member0_
- 이때
Member엔티티의 필드 중 하나인Team엔티티의fetch옵션이 즉시 로딩인 경우,Team엔티티는 프록시 엔티티가 아닌 실제 엔티티로 이루어져 있어야 한다.
- 따라서 추가 조회 쿼리 발생
Hibernate: select team0_.id as id1_7_0_, team0_.name as name2_7_0_ from Team team0_ where team0_.id=?
- 만약
Member엔티티 리스트가 N 개라면 N 개의 추가 쿼리가 발생한다.
- N+1 문제 발생
- 지연 로딩 사용을 권장한다.
@Entity
public class Member{
@Id @GeneratedValue
private Long id;
private String name;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team_id")
private Team team;
}
Team team = new Team("teamA");
em.persist(team);
Member member = new Member("member1");
member.setTeam(team);
em.persist(member);
em.flush();
em.clear();
List<Member> members = em.createQuery("select m from Member m", Member.class)
.getResultList();
Member가Team을 지연 로딩하는 경우em.createQuery("select m from Member m", Member.class)JPQL 사용 시,Hibernate: select member0_.id as id1_3_, member0_.name as name2_3_, member0_.team_id as team_id3_3_ from Member member0_
- 이때
Member엔티티의 필드 중 하나인Team엔티티의fetch옵션이 지연 로딩인 경우,Team엔티티는 프록시 엔티티로 대체된다.
- 따라서 추가 조회 쿼리가 발생하지 않는다.
- 만약 즉시 로딩때처럼
Member엔티티와Team엔티티의join을 원한다면join fetch를 사용한다.
Team team = new Team("teamA");
em.persist(team);
Member member = new Member("member1");
member.setTeam(team);
em.persist(member);
em.flush();
em.clear();
List<Member> members = em.createQuery("select m from Member m join fetch m.team", Member.class)
.getResultList();
Member가Team을 지연 로딩하는 경우- 페치 조인을 사용하여
Member엔티티 조회 시,Team엔티티까지 바로 가져오기 위해join쿼리 발생Hibernate: select member0_.id as id1_3_0_, team1_.id as id1_7_1_, member0_.name as name2_3_0_, member0_.team_id as team_id3_3_0_, team1_.name as name2_7_1_ from Member member0_ inner join Team team1_ on member0_.team_id=team1_.id
@ManyToOne,@OneToOne은fetch기본 설정이 즉시 로딩이므로 변경이 필요하다.
영속성 전이
-
특정 엔티티의 영속 상태를 관리할 때 연관된 엔티티들의 영속 상태도 함께 관리하고 싶을 때 사용한다.
-
만약 부모 엔티티가 일쪽 테이블이고 자식 엔티티가 다쪽 테이블이라면
-
자식 엔티티의 부모를 설정해주는 연관관계 메서드를 가져야한다.
- 연관관계의 주인은 자식 엔티티이기 때문이다.
-
자식 엔티티가 부모 엔티티에 완전히 종속적이고 lifecycle이 같을때만 사용하는 것이 좋다.
-
-
ex) 부모 엔티티를 영속 상태로 만들 때, 자식 엔티티들도 영속 상태로 저장된다.
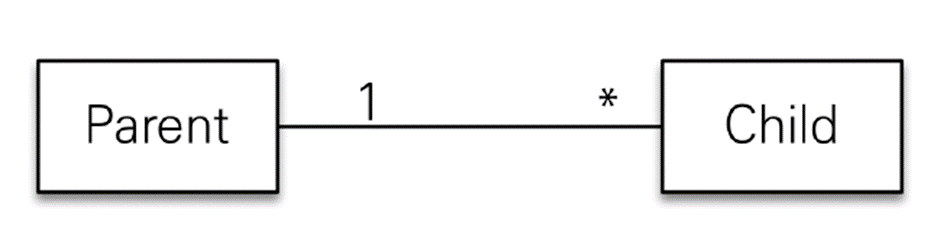
@Entity
public class Parent {
@Id @GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "parent")
private List<Child> childList = new ArrayList<>();
public void addChild(Child child) { // 자식 엔티티의 부모를 설정해주는 연관관계 메서드
childList.add(child);
child.setParent(this);
}
}
@Entity
public class Child {
@Id @GeneratedValue
private Long id;
private String name;
@ManyToOne
@JoinColumn(name = "parent_id")
private Parent parent;
}
Parent와Child엔티티
-
@OneToMany(cascade = CascadeType.ALL)-
ALL : 모두 적용
-
PERSIST : 영속
-
REMOVE : 영속성 컨텍스트에서 삭제
-
@Entity
public class Parent {
// ...
@OneToMany(mappedBy = "parent", cascade = CascadeType.ALL)
private List<Child> childList = new ArrayList<>();
}
Child child1 = new Child();
Child child2 = new Child();
Parent parent = new Parent();
parent.addChild(child1);
parent.addChild(child2);
em.persist(parent);
// em.persist(child1);
// em.persist(child2); parent 가 영속될 때 child1, child2 도 영속되므로 호출할 필요 없다.
parent가 영속될 때child1,child2도 영속된다.
고아 객체 제거
-
orphanRemoval = true로 설정 -
부모 엔티티와 연관관계가 끊어진 자식 엔티티를 자동으로 삭제
-
부모 엔티티에서 참조가 제거된 자식 엔티티는 DB에서 삭제됨
- 부모 엔티티가 삭제되면, 자식 엔티티들이 DB에서 모두 삭제됨
-
자식 엔티티가 부모 엔티티 단 한 곳에서만 참조될 때 사용해야 한다.
-
@OneToOne,@OneToMany만 가능-
부모 엔티티 여러개에 대응되는 자식 엔티티가 한개일 순 없다.
-
부모 엔티티 한개에 대응되는 자식 엔티티가 여러개여야 한다.
-
public class Parent {
// ...
@OneToMany(mappedBy = "parent", orphanRemoval = true)
private List<Child> childList = new ArrayList<>();
}
Child child1 = new Child();
Child child2 = new Child();
Parent parent = new Parent();
parent.addChild(child1);
parent.addChild(child2);
em.persist(parent);
em.persist(child1);
em.persist(child2);
em.flush();
em.clear();
Parent findParent = em.find(Parent.class, parent.getId());
em.remove(findParent); // parent, child1, child2 에 대한 delete 쿼리가 나간다.부모 엔티티
parent가 삭제되었으므로, 연관된 자식 엔티티child1,child2에 대한delete쿼리가 추가적으로 발생한다.Hibernate: delete from Child where id=? Hibernate: delete from Child where id=? Hibernate: delete from Parent where id=?
부모 엔티티의 생명 주기 관리
-
영속성 전이 + 고아 객체 제거 ➔ 부모 엔티티가 자식 엔티티의 생명주기 관리
-
오직 부모 엔티티만 자식 엔티티를 참조하는 경우 사용하는 것이 좋다.
-
자식 엔티티가 부모 엔티티에 비즈니스 로직 상 종속적인 경우 사용하는 것이 좋다.
@Entity
public class Parent {
@Id @GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "parent", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Child> childList = new ArrayList<>();
public void addChild(Child child) {
childList.add(child);
child.setParent(this);
}
// ...값 타입
JPA 데이터 타입 분류
-
엔티티 타입
-
@Entity로 정의하는 객체 -
데이터가 변해도 식별자로 지속해서 추적 가능
- 지속해서 값을 추적, 변경한다면 엔티티 사용
-
-
값 타입
-
int,Integer,String같은 단순 값으로 사용하는 기본타입이나 객체 -
식별자 X, 추적 불가
-
생명주기를 엔티티에 의존
-
기본값 타입, 임베디드 타입, 컬렉션 값 타입이 있음
-
임베디드 타입
-
기본 값 타입을 모아서 새로운 값 타입을 직접 정의
-
임베디드 타입 사용 여부와 상관없이 매핑하는 테이블은 같다.
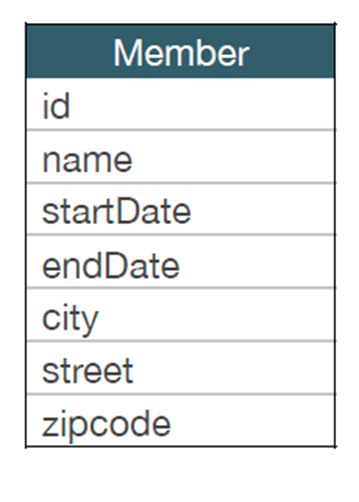
임베디드 타입 적용 전

임베디드 타입 적용 후
- (startDate, endDSate) ➔ workPeriod
- (city, street, zipcode) ➔ homeAddress
@Embeddable
public class Address {
//address
private String city;
private String street;
private String zipcode;
public Address() {
}
// ...
@Embeddable➔ 임베디드 타입을 정의하는 곳에 표시- 기본 생성자 필수
- 해당 값 타입만 사용하는 의미 있는 메소드를 만들 수 있다.
- 객체 지향적인 설계 가능
@Entity
public class Member{
@Id @GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@Embedded
private Address homeAddress;
// ...
@Embedded➔ 임베디드 타입을 사용하는 곳에 표시
값 타입 컬렉션
-
값 타입을 하나 이상 저장할 때 사용한다.
- 컬렉션을 저장하기 위한 별도의 테이블이 생성된다.
@Entity
public class Member {
@Id
@GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@ElementCollection
@CollectionTable(name = "FAVORITE_FOOD", joinColumns = @JoinColumn(name = "MEMBER_ID"))
@Column(name = "FOOD_NAME")
private Set<String> favoriteFoods = new HashSet<>();
}다음과 같이
FAVORITE_FOOD테이블이 생성된다.Hibernate: create table FAVORITE_FOOD ( MEMBER_ID bigint not null, FOOD_NAME varchar(255) )
-
값 타입 컬렉션은 값 변경 시 추적이 어렵다.
-
값 타입 컬렉션에 변경 사항이 발생하면, 주인 엔티티와 연관된 모든 데이터를 삭제하고, 값 타입 컬렉션에 있는 현재 값을 모두 다시 저장한다.
- 성능이 떨어진다.
-
값 타입 컬렉션 대신 엔티티를 만들어 일대다 관계를 고려하는 것이 좋다.
- 일대다 관계 엔티티 + 영속성 전이 (Cascade) + 고아 객체 제거 를 통해 값 타입 컬렉션과 유사하게 사용할 수 있다.
값 타입 주의점
-
공유 참조
-
객체형태의 값 타입은 공유 참조가 발생한다.
-
여러 엔티티에서 같은 값 타입을 공유하면 위험하다.
- 부작용이 발생한다.
-
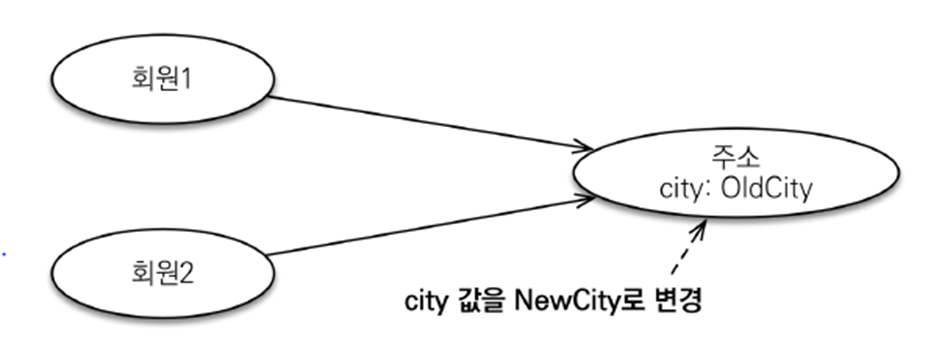
Address address = new Address("city", "street", "10000");
Member member1 = new Member("member1", address);
em.persist(member1);
Member member2 = new Member("member2", address);
em.persist(member2);
member2.getAddress().setCity("newCity"); // member2 의 Address.city 주소만 변경하려고 했는데..
member2의Address.city주소만 변경하려고 했는데member1도 같은Address주소를 참조하고 있으므로 (공유 참조)member1의Address.city주소도 변경된다.Hibernate: update Member set city=?, street=?, zipcode=?, name=?, team_id=? where id=? Hibernate: update Member set city=?, street=?, zipcode=?, name=?, team_id=? where id=?
update쿼리가 두번 나간다.
-
값 타입의
setter접근을 막아 불변 객체로 설계함으로써 문제를 해결할 수 있다.- 생성자로만 값을 변경하고 설정해야 한다.
Address address = new Address("city", "street", "10000");
Member member1 = new Member("member1", address);
em.persist(member1);
Address newAddress = new Address("newCity", address.getStreet(), address.getZipcode()); // 생성자로만 새로운 address 를 만들 수 있다.
Member member2 = new Member("member2", newAddress);
em.persist(member2);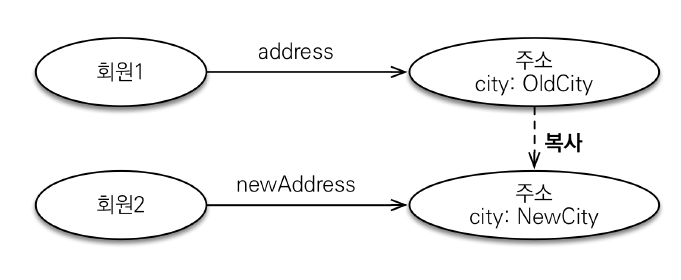
-
값 타입의 동일성 비교
-
값 타입 인스턴스는 동일성 비교시 그 안에 내용이 같아도 false 를 반환한다.
-
두 인스턴스의 주소가 다르기 때문이다.
-
int a = 10;
int b = 10;
System.out.println(a == b); // true
Address address1 = new Address("city", "street", "10000");
Address address2 = new Address("city", "street", "10000");
System.out.println(address1 == address2); // false-
값 타입의 동등성 비교
-
값 타입 인스턴스는 동등성 비교시 그 안에 내용이 같으면 true 를 반환해야 한다.
-
동등성 비교를 위해 값 타입의
equals()메소드를 적절하게 재정의해야 한다.- 값 타입의 모든 필드값들을 비교한다.
-
@Embeddable
public class Address {
private String city;
private String street;
private String zipcode;
// ...
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Address address = (Address) o;
return Objects.equals(getCity(), address.getCity()) && Objects.equals(getStreet(), address.getStreet()) && Objects.equals(getZipcode(), address.getZipcode());
}
}
Address address1 = new Address("city", "street", "10000");
Address address2 = new Address("city", "street", "10000");
System.out.println(address1 == address2); // false
System.out.println(address1.equals(address2)); // true
equals()메소드를 재정의하여 동등성 비교가 제대로 동작하도록 한다.- 필드 접근보다는
getXXX메서드로equals()를 구현하는 것이 좋다.
- getter 를 사용하는 것이 프록시 접근 문제에서 자유롭다.
객체지향 쿼리 언어 (JPQL)
-
JPA 는 다양한 쿼리 방법을 지원한다.
- JPQL 은 그 중 하나이다.
JPQL
-
필요한 데이터만 DB에서 불러오기 위해 검색 조건이 포함된 SQL이 필요하다.
- JPQL 을 사용하여 검색 조건을 넣고 데이터를 조회할 수 있다.
-
엔티티 객체를 대상으로 쿼리한다는 점이 SQL과 구별된다.
-
JPQL = 객체 지향 SQL
-
문법 자체는 SQL과 유사하다.
-
-
단순한 쿼리 문자열이기 때문에 동적 쿼리를 처리하기는 어렵다.
-
엔티티와 속성은 대소문자를 구분한다.
-
별칭은 필수 이다.
select m from Member m where m.age > 18TypeQuery, Query
TypeQuery➔ 반환 타입이 명확할 때 사용
TypedQuery<Member> query =
em.createQuery("SELECT m FROM Member m", Member.class);
Member.class반환 타입임이 명확
Query➔ 반환 타입이 명확하지 않을 때 사용
Query query =
em.createQuery("SELECT m.username, m.age from Member m");결과 조회 API
-
query.getResultList()-
결과를 리스트로 반환
-
결과가 없으면 빈 리스트 반환
-
List<Member> members = em.createQuery("select m from Member m", Member.class)
.getResultList();-
query.getSingleResult()-
결과를 정확히 하나, 단일 객체로 반환
-
결과 없으면 ➔
NoResultException -
결과가 둘 이상이면 ➔
NonUniqueResultException
-
Member member = em.createQuery("select m from Member m where m.id = 1", Member.class)
.getSingleResult();파라미터 바인딩
String sql = "select m from Member m where m.username=:username";
TypedQuery<Member> query = em.createQuery(sql, Member.class);
query.setParameter("username", usernameParam);
:username부분을query.setParameter("username", 넣고 싶은 값)방식으로 파라미터 바인딩
String jpql = “select m from Member m where m = :member”;
List resultList = em.createQuery(jpql)
.setParameter("member", member)
.getResultList();
m = :member와 같이 엔티티를 직접 사용 시, 해당 엔티티의 기본키 값을 사용 (m.id = memberId)
프로젝션
-
SELECT 절에 조회할 대상을 지정한다.
-
distinct키워드로 중복을 제거할 수 있다. -
프로젝션 대상
-
엔티티
select m from Member m
-
임베디드 타입
selet m.address from Member m
-
스칼라 타입
select m.username, m.age from Member m
-
-
여러 값 조회 시
-
ex)
SELECT m.username, m.age FROM Member m -
new명령어로 조회-
단순 값을 DTO로 바로 조회
-
ex)
SELECT new jpql.MemberDTO(m.username, m.age) FROM Member m -
java 하위 패키지 경로 + 클래스 명 입력
-
클래스내에 순서와 타입이 일치하는 생성자 필요
-
-
페이징 API
-
페이징을 두 API로 추상화하였다.
-
setFirstResult(int startPosition)-
조회 시작 위치
-
0부터 시작
-
-
setMaxResults(int maxResult)- 조회할 데이터 수
//페이징 쿼리
String jpql = "select m from Member m order by m.name desc";
List<Member> resultList = em.createQuery(jpql, Member.class)
.setFirstResult(10)
.setMaxResults(20)
.getResultList();
setFirstResult(int startPosition)
- 조회 시작 위치
- 0부터 시작
setMaxResults(int maxResult)
- 조회할 데이터 수
조인
-
내부 조인
SELECT m FROM Member m JOIN m.team t(FK-PK 조인)
-
외부 조인
SELECT m FROM Member m LEFT JOIN m.team t(FK-PK 조인)
-
연관관계 없는 엔티티 외부 조인
-
on절 사용 -
SELECT m, t FROM Member m LEFT JOIN Team t ON m.username = t.name
-
서브 쿼리
-
일반적으로 SQL 과 사용법 유사
-
JPA 표준은 WHERE 절, HAVING 절의 서브 쿼리만 지원한다.
- Hibernate 가 SELECT 절 서브 쿼리를 지원한다.
-
FROM 절의 서브 쿼리는 불가능하다.
-
조인으로 풀 수 있으면 풀어서 해결하거나
-
애플리케이션으로 가져와서 해결한다.
-
hibernate 6.1 부터는 가능해졌다.
-
경로 표현식
-
점을 찍어 객체 그래프를 탐색하는 것
- ex)
select m.username from Member m
- ex)
-
상태 필드 ➔
m.username같은 단순한 값을 저장하기 위한 필드 -
연관 필드 ➔ 연관관계를 위한 필드
-
단일 값 연관 필드
- 대상이 엔티티 (ex :
m.team)
- 대상이 엔티티 (ex :
-
컬렉션 값 연관 필드
- 대상이 컬렉션 (ex :
m.orders)
- 대상이 컬렉션 (ex :
-
경로 표현식 특징
-
상태 필드
-
경로 탐색의 끝
-
더 이상 탐색할 수 없다. (점을 찍을 수 없다.)
-
-
단일 값 연관 필드
-
묵시적 내부 조인 발생
-
경로 탐색을 더 할 수 있다. (점을 찍을 수 있다.)
-
-
컬렉션 값 연관 필드
-
묵시적 내부 조인 발생
-
경로 탐색의 끝
-
묵시적 조인
-
경로 표현식에 의해 묵시적으로 SQL 내부 조인 발생
-
ex)
select m.team from Member m (join m.team t) -
↔ 명시적 조인 :
join키워드 직접 사용
-
-
예상하지 못한 쿼리가 발생할 수 있어 권장하지 않는다.
- 경로 표현식을 사용할 때 가급적 명시적 조인을 사용하는 것이 좋다.
페치 조인
-
SQL 에서 제공하는 조인 종류는 아니다.
- JPQL 에서 성능 최적화를 위해 제공하는 기능
-
연관된 엔티티나 컬렉션을 SQL 한번에 함께 조회하는 기능
-
연관된 엔티티를 같이 가져오기 위한 JOIN 쿼리가 나간다.
-
따라서 지연 로딩 옵션이더라도, 연관된 엔티티를 프록시가 아닌 실제 엔티티로 채워넣는다.
-
진짜 엔티티이기 때문에, 추후에 사용할 때 추가적인 쿼리가 발생하지 않는다.
-
1+N 쿼리 ➔ 1 쿼리로 성능을 높인다.
-
-
-
글로벌 로딩 전략
@OneToMany(fetch = FetchType.LAZY)보다 우선한다.- 애노테이션으로 미리 설정하였더라도, 페치 조인 쿼리를 사용하면 지연 로딩이 발생하지 않는다.
페치 조인의 종류
-
엔티티 페치 조인
- 다대일, 일대일 페치 조인
-
컬렉션 페치 조인
-
일대다 페치 조인
-
데이터 중복이 발생할 수 있음
-
엔티티 페치 조인
select m from Member m join fetch m.team // jpql
SELECT M.*, T.* FROM MEMBER M
INNER JOIN TEAM T ON M.TEAM_ID=T.ID // 같은 의미의 sql팀의 모든 내부 필드들 (
t.*) 도 함께 조회
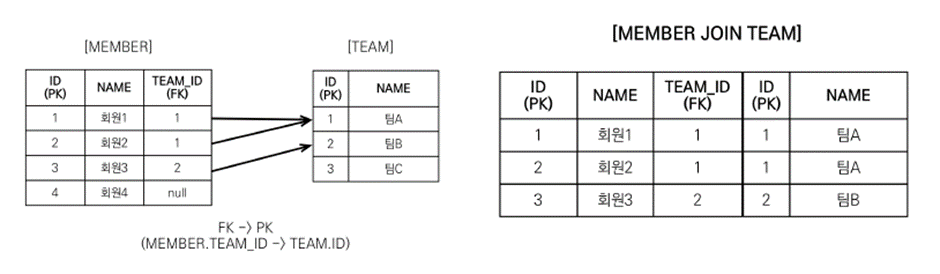
-
데이터 중복 발생 X
-
페이징 처리시 문제 발생 X
컬렉션 페치 조인
select t
from Team t join fetch t.members
where t.name = '팀A' // jpql
SELECT M.*, T.* FROM MEMBER M
INNER JOIN TEAM T ON M.TEAM_ID=T.ID
WHERE T.name = '팀A' // 같은 의미의 sql멤버들의 모든 내부 필드들 (m.*) 도 함께 조회
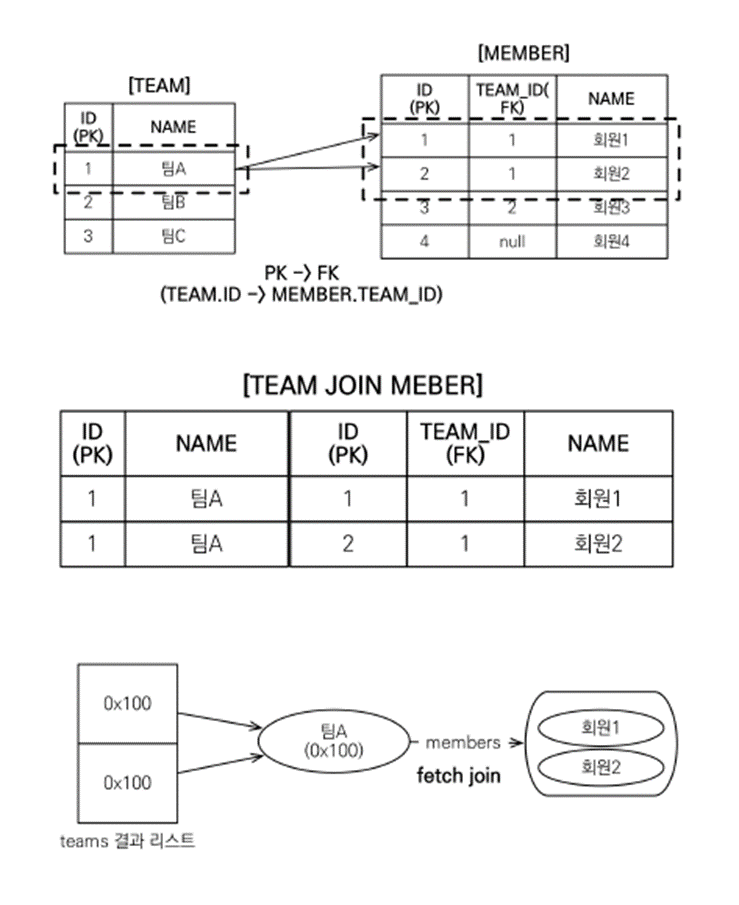
- 쿼리 결과 리스트에 팀 A 가 2개로 늘어난다.
- 같은 팀인 Member가 2개이기 때문
-
데이터 중복 발생 가능성이 있다.
-
distinct사용 시 애플리케이션에서 엔티티 중복을 제거할 수 있다. -
모든 속성들이 같아야 중복이 제거되는 SQL
distinct와 다르게, 식별자만 같아도 중복 엔티티로 간주해 제거된다. -
위의 예제의 경우, 결과 리스트에 팀 A 가 1개만 남는다.
-
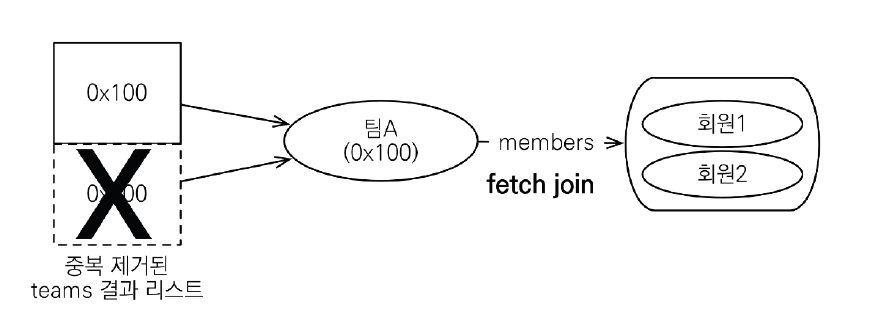
같은 식별자를 가진
Team엔티티를 결과 리스트에서 제거한다.
- 페이징 처리시 문제 발생 O
페치 조인 주의점
-
페치 조인 대상에는 가급적 별칭을 주어선 안된다.
- 페치 조인은 연관된 엔티티를 몽땅 가져오는 것이지, 연관된 엔티티에 조건을 걸어 몇 개의 연관된 엔티티만 가져오기 위한 기술이 아니다.
select t from Team t join fetch t.members m이처럼 페치 조인 대상에 별칭을 주는 것은 좋지 않다.
-
둘 이상의 컬렉션을 페치 조인할 수 없다.
-
데이터 뻥튀기 x 데이터 뻥튀기이므로 데이터가 너무 많아진다. -
따라서 자바에서 예외가 발생한다.
-
- 컬렉션을 페치 조인하면 페이징 API로 페이징을 할 수 없다.

- 컬렉션 페치 조인으로 데이터 중복 발생이 일어난 상황
- 다음과 같은 예제에서 페이지 사이즈가 1이라면
- 쿼리 결과 리스트에 담긴
팀A는members에회원1객체 하나만 갖고 있게된다.- 즉, 데이터 정합성에 문제가 발생한다.
-
-
Hibernate 의 경우엔 이를 해결하기 위해 메모리에 모든 쿼리를 올리고, 메모리에서 페이징을 수행하게 된다.
-
limit,offset쿼리가 나가지 않는다. -
전체 데이터를 메모리에 올리기 때문에 성능이 좋지 않고 위험하다.
-
-
벌크 연산
- 쿼리 한 번으로 여러 엔티티를 변경
String qlString = "update Product p " +
"set p.price = p.price * 1.1 " +
"where p.stockAmount < :stockAmount";
int resultCount = em.createQuery(qlString)
.setParameter("stockAmount", 10)
.executeUpdate();
executeUpdate()
- update, delete 실행
- 영향받은 엔티티 수 반환
-
영속성 컨텍스트를 무시하고 DB에 직접 쿼리
flush➔ 벌크 연산 수행 ➔ DB 반영
-
벌크 연산을 문제 없이 수행하려면
-
벌크 연산을 가장 먼저 실행하거나
-
벌크 연산 수행 후 영속성 컨텍스트 초기화
em.clear()
-
출처 : https://www.inflearn.com/course/ORM-JPA-Basic
자바 ORM 표준 JPA 프로그래밍 기본편 - 김영한 강사님
