
안녕하세요.
저희 수강신청 프로젝트에서 Spring Cache 를 사용하여 성능 개선을 하기까지의 과정을 블로깅하려고 합니다.
기존의 비즈니스 로직
수강 바구니 신청 페이지나 수강 신청 페이지를 접속할 때, 반드시 첫 페이지 강의 목록을 받아오는 HTTP 요청을 보냅니다.
따라서 첫 페이지의 강의 목록들은 조회 빈도가 높습니다.
(이때의 첫 페이지는 아무런 필터링을 사용하지 않은 강의 목록 요청의 첫 페이지입니다.)
수강 바구니 신청 페이지
수강 신청 페이지
HTTP 요청을 통해 받아오는 강의 목록 API는 총 20개의 강의 정보로 구성되어 있습니다.
또한 강의 목록들은 수강 신청 기간동안 데이터가 변경되지 않습니다.
이렇게 고정된 크기의 고정된 내용을 갖는 데이터를 항상 DB에서 조회해오는 것은 큰 오버헤드라 생각하여 첫 페이지의 강의 목록들을 캐싱하기로 결정하였습니다.
Spring Cache + Redis 를 사용하기 위한 환경 설정
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
// ...
}
build.gradle
다음과 같이 spring data redis 의존성만 추가해주면 Spring Cache 를 사용할 수 있습니다.
@Configuration
@RequiredArgsConstructor
public class RedisConfig {
private final RedisProperties redisProperties;
@Value("${spring.data.redis.port}")
private int port;
@Bean
public RedisConnectionFactory redisConnectionFactory() {
return new LettuceConnectionFactory(redisProperties.getHost(), port);
}
// ...
@Bean
public CacheManager cacheManager(RedisConnectionFactory cf) {
RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig()
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer())) // key 는 String 직렬화
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer())) // value 는 Json 직렬화
.entryTtl(Duration.ofMinutes(30L)); // 캐시 지속 시간은 30 분으로 설정
return RedisCacheManager.RedisCacheManagerBuilder.fromConnectionFactory(cf).cacheDefaults(redisCacheConfiguration).build();
}
}
RedisConfig클래스
Spring Cache 에서 사용할 캐시를 Redis 로 선택하기 위해 다음과 같이 CacheManager 를 구현하고 스프링 빈으로 등록하였습니다.
캐싱하려는 데이터가 첫 번째 페이지 강의 목록 페이지이기 때문에 객체를 JSON 으로 직렬화해주는
GenericJackson2JsonRedisSerializer 를 value Serializer 로 채택하였습니다.
GenericJackson2JsonRedisSerializer 의 특징은 직렬화하려는 객체의 타입을 지정해주지 않아도 된다는 편리함이 있습니다.
객체의 타입을 지정해주지 않아도 역직렬화가 가능한 이유는 저장되는 데이터에 추가적인 필드 @class 덕분입니다. 해당 필드는 패키지 경로와 클래스 명을 포함하여 직렬화한 객체의 정보를 나타냅니다.
따라서 해당 필드와 역직렬화하려는 객체의 패키지 경로 + 클래스 명이 일치하고, 필드들이 일치한다면 성공적으로 역직렬화를 할 수 있습니다.
그러나 이러한 편리함은 단점이 될 수도 있습니다.
캐시에 데이터를 저장한 이후, 패키지 경로가 바뀌거나 클래스 명이 바뀌는 경우 @class 필드와 실제 역직렬화하려는 객체의 정보가 달라질 수 있습니다.
이 경우, 필드들이 일치하더라도 역직렬화에 실패하게 됩니다.
따라서 이런 불편함이 발생할 수 있는 상황이라면 Jackson2JsonRedisSerializer 와 같은 다른 Serializer 를 사용하는 것이 좋습니다.
그러나 저희 프로젝트는 마무리 단계에 접어들어 패키지 경로나 클래스명이 변할 가능성이 낮기 때문에 편의상 GenericJackson2JsonRedisSerializer 를 사용하였습니다.
@SpringBootApplication
@EnableCaching
public class CourseRegistrationSystemApplication {
public static void main(String[] args) {
SpringApplication.run(CourseRegistrationSystemApplication.class, args);
}
}마지막으로 SpringBoot 최상단에 @EnableCaching 을 붙여주면 Spring Cache 를 사용하기 위한 준비가 끝납니다.
Spring Cache 적용하기 - 절망편
@Cacheable(value = "lecture", condition = "#lectureFilterOptions.fetchNoOption() && (#pageable.getPageNumber() == 0)")
public LectureSchedulePage fetchLectureSchedule(Pageable pageable, LectureFilterOptions lectureFilterOptions) {
return new LectureSchedulePage(
lectureRepository.findMatchedLectures(
pageable,
lectureFilterOptions.getOpeningYear(),
lectureFilterOptions.getSemester(),
lectureFilterOptions.getSubjectDivision(),
lectureFilterOptions.getDepartmentId(),
lectureFilterOptions.getSubjectName())
.map(LectureDetail::new));
}모든 준비를 마치고 강의 목록을 조회하는 서비스 메서드에 다음과 같이 Spring Cache를 위한 애노테이션을 사용합니다.
@Cacheable 은 value::key 를 key 값으로 하는 데이터가 캐시에 존재하지 않는다면 해당 메서드를 실행한 후, 결과물을 value::key 를 key 값으로 하여 저장해둡니다.
반면 value::key 를 key 값으로 하는 데이터가 이미 캐시에 존재한다면 해당 메서드를 실행하지 않고, 캐시에 저장된 value::key 에 대응되는 value 값을 반환합니다.
따라서 최초의 첫 강의 목록 페이지 요청 한번에 대해서만 DB에 조회하고, 후속 요청들은 DB 조회없이 캐시에 저장된 데이터를 제공받을 수 있습니다.
@Cacheable 의 condition 필드는 캐싱이 동작할 조건을 설정합니다.
아무런 필터링이 없는 첫 페이지 강의 목록을 조회할 때만 캐싱이 동작하도록 하였습니다.
@Getter
public class LectureFilterOptions {
@NotNull
private final Year openingYear;
@NotNull
private final Semester semester;
private final SubjectDivision subjectDivision;
private final Long departmentId;
private final String subjectName;
@Builder
@Jacksonized
private LectureFilterOptions(Year openingYear, Semester semester, SubjectDivision subjectDivision,
Long departmentId,
String subjectName) {
this.openingYear = openingYear;
this.semester = semester;
this.subjectDivision = subjectDivision;
this.departmentId = departmentId;
this.subjectName = subjectName;
}
public boolean fetchNoOption() {
return (subjectDivision == null) && (departmentId == null) && (subjectName == null);
}
}
LectureFilterOptions클래스의fetchNoOption메서드는 아무런 필터 조건이 없을 경우 true 를 반환한다.
이렇게 준비를 마쳤다고 생각해 서버를 돌려보았는데, DB 조회 로그가 매 요청마다 발생하였습니다.
그래서 캐싱이 제대로 되고있나 확인하기 위해 redis 에 저장된 key 들을 확인해보았습니다.

매 요청마다 새로운 key 값으로 데이터를 캐싱한다.
Spring Cache 적용하기 - 희망편
제가 @Cacheable 의 key 가 저장되는 방식을 제대로 이해하지 못해 다음과 같은 문제가 발생한 것이었습니다.
저는 @Cacheable 에서 key 필드를 생략하면 key가 생기지 않을거라 생각했습니다.
그러나 실제로는 key 필드를 생략하면 @Cacheable 의 default key generator인 SimpleKeyGenerator 가 동작하여 자동으로 key를 생성하였습니다.
SimpleKeyGenerator 는 파라미터들의 정보를 바탕으로 toString() 을 호출해 key를 생성하기 때문에 LectureFilterOptions 와 같이 객체가 파라미터로 넘어오는 경우, 조건이 같아도 객체가 달라 생성된 key 값이 달라지게 됩니다. 따라서 저장되는 value 는 같지만 key 값이 달라 매 요청마다 DB 조회 발생 및 캐시 저장이 이루어지게 된 것입니다.
따라서 이러한 문제를 해결하기 위해선 모든 필터링 없는 첫 페이지 강의 목록 요청 이 같은 key 값을 만들도록 설정해주면 됩니다.
여러가지 해결 방법이 있습니다.
1. Custom Key Generator 를 생성하고, 해당 Key Generator 가 동일한 key 값을 만들도록 설정한다.
2. LectureFilterOption 의 ToString 값을 필드값에 따라 생성되도록 재정의한다.
3. key 필드에 상수를 넣는다.
가장 간단한 방법은 3번이라고 생각해 key 필드에 상수를 넣는 방식으로 문제를 해결하였습니다.
@Cacheable(value = "lecture", key = "T(site.courseregistrationsystem.util.ProjectConstant).LECTURE_NO_OPTION_FIRST_PAGE",
condition = "#lectureFilterOptions.fetchNoOption() && (#pageable.getPageNumber() == 0)")
public LectureSchedulePage fetchLectureSchedule(Pageable pageable, LectureFilterOptions lectureFilterOptions) {
return new LectureSchedulePage(
lectureRepository.findMatchedLectures(
pageable,
lectureFilterOptions.getOpeningYear(),
lectureFilterOptions.getSemester(),
lectureFilterOptions.getSubjectDivision(),
lectureFilterOptions.getDepartmentId(),
lectureFilterOptions.getSubjectName())
.map(LectureDetail::new));
}
key = "T(site.courseregistrationsystem.util.ProjectConstant).LECTURE_NO_OPTION_FIRST_PAGE"를 추가함으로써 상수를 사용한다.
이때 SpringEL 문법에서는 상수 클래스 내의 상수를 가져오기위해 다음과 같이 패키지명을 작성해주어야 합니다.

최초의 요청만
lecture::firstPagekey 값으로 데이터를 캐싱한다.
성능 측정 결과
성능 측정은 1000명의 user 가 한 번의 첫 페이지 강의 목록 조회 요청을 하는 상황으로 스크립트를 작성하였습니다.
- 캐시 적용 전
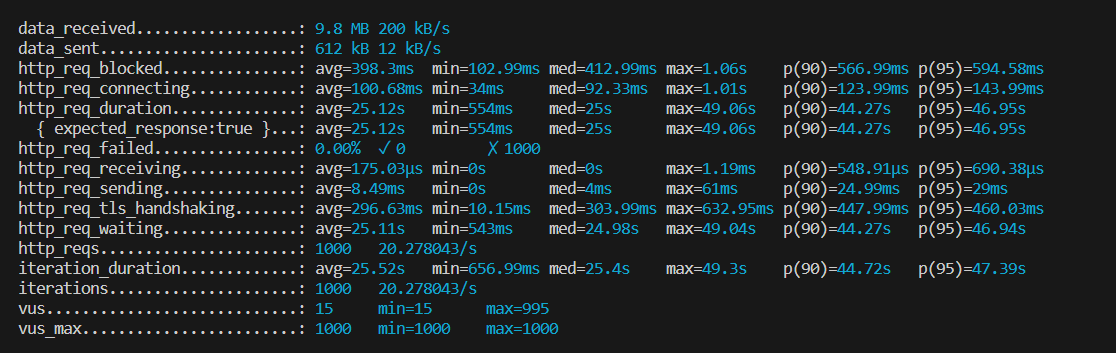
25.12 초의 평균 응답 시간
- 캐시 적용 후
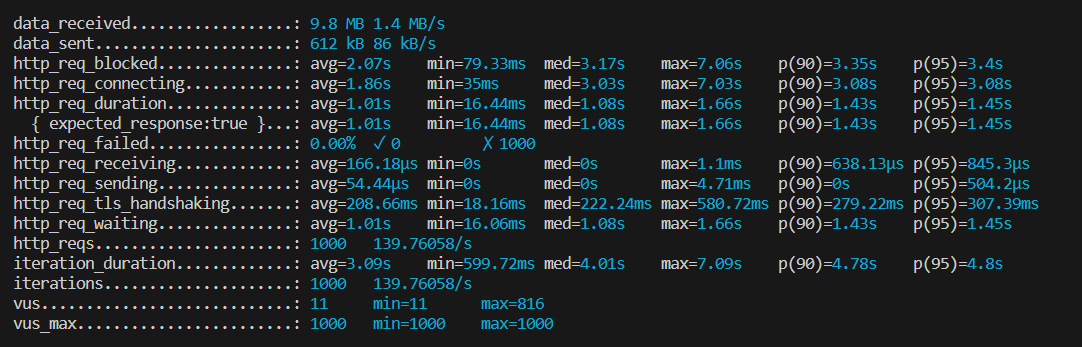
1.01 초의 평균 응답 시간
비록 필터링 없는 첫 페이지의 강의 목록 조회에 대한 성능 개선만 이루어졌다는 점이 아쉽지만, 해당 API 요청이 가장 많다는 점을 고려하면 엄청난 성능 개선임을 알 수 있습니다.
데이터의 변경이 없는 상황에서의 적절한 캐싱은 엄청난 성능 개선을 만들어 낼 수 있음을 배울 수 있었습니다.
성능 개선을 위한 캐싱은 선택이 아닌 필수임을 느꼈습니다.
작성자: Hyun
출처
https://hyeri0903.tistory.com/237
https://stackoverflow.com/questions/13381731/caching-with-multiple-keys
https://velog.io/@hkyo96/Spring-RedisTemplate-Serializer-%EC%84%A4%EC%A0%95
