
https://github.com/VSFe/Tech-Interview/blob/main/04-DATABASE.md 의 면접질문들에 대한 답을 나름대로 정리한 포스팅
Key
-
기본 키: 후보 키 중 하나를 선정하여 대표로 삼는 속성
-
후보 키: 기본 키로 사용할 수 있는 후보가 되는 모든 집합으로, 유일성과 최소성을 만족하며 각 행을 고유하게 식별할 수 있어야 한다.
-
대체 키: 기본 키로 선택되지 않은 후보 키
-
외래 키: 한 테이블에서 다른 테이블의 기본 키를 참조하는 속성
-
슈퍼 키: 각 행을 유일하게 식별할 수 있지만 최소성은 만족하지 못하는 집합
-
대리 키: 마땅한 기본 키가 없을 때 사용하는 일련번호와 같은 속성
기본키는 수정이 가능한가요?
-
MySQL의 기본 키는 수정할 수 있다.
-
InnoDB는 기본 키 값에 의해 레코드의 저장 위치가 결정되므로, 기본 키 값이 변경되면 레코드의 물리적인 저장 위치가 바뀌어야 한다.
- 그래서 수정을 하는 것이 성능 상 좋지는 않다.
사실 MySQL의 경우, 기본키를 설정하지 않아도 테이블이 만들어집니다. 어떻게 이게 가능한 걸까요?
-
MySQL의 경우 테이블마다 하나의 클러스터 인덱스(기본키)를 필수적으로 가져야한다.
-
만약 기본키를 정의하지 않았다면 NOT NULL 옵션의 UNIQUE 인덱스 중에서 첫 번째 인덱스를 클러스터 인덱스로 자동 정의한다.
-
만약 적절한 UNIQUE 인덱스마저 없다면, 숨겨진 클러스터 인덱스를 자동 생성한다.
-
GEN_CLUST_INDEX
-
새로운 row가 삽딥될 때마다 증가하는 6바이트 필드
-
이렇게 자동으로 추가된 기본키는 사용자에게 노출되지 않아 쿼리 문장에 명시적으로 사용할 수 없다.
-
클러스터 인덱스는 테이블 당 단 하나만 가질 수 있는 엄청난 혜택이므로 가능하다면 기본키를 명시적으로 생성하는 것이 좋다.
-
외래키 값은 NULL이 들어올 수 있나요?
- NULL이 들어갈 수 있다.
어떤 칼럼의 정의에 UNIQUE 키워드가 붙는다고 가정해 봅시다. 이 칼럼을 활용한 쿼리의 성능은 그렇지 않은 것과 비교해서 어떻게 다를까요?
-
유니크 인덱스를 사용하여 조회했을 때와 인덱스 없이 조회했을 때의 성능 차이는 있을 수 있지만
-
유니크 인덱스를 사용하여 조회했을 때와 일반 보조 인덱스를 사용해 조회했을 때의 성능 차이는 거의 없다.
-
다만, 동등 조건으로 찾는 경우 유니크 인덱스는 읽어야 할 레코드가 상대적으로 조회에 걸리는 시간이 짧다.
RDB와 NoSQL
-
RDB는 데이터를 행과 열로 이루어진 테이블로 구성하는 반면, NoSQL은 데이터를 다양한 형태로 구성한다.
-
RDB는 데이터 간의 관계를 명확하게 정의하는 반면, NoSQL은 관계를 명시하지 않는다.
-
RDB는 ACID 속성을 지원하여 데이터 무결성을 보장하는 반면, NoSQL은 BASE 특성을 가져 가용성과 성능을 중시한다.
-
BASE
-
Basically Available: 시스템이 항상 사용 가능하다는 것을 보장
-
Soft State: 데이터의 일시적인 불일치 허용
-
Eventually Consistent: 시간이 지나면 데이터는 결과적으로 일관성있는 상태가 된다.
-
-
NoSQL의 강점과, 약점이 무엇인가요?
-
강점
-
데이터 간의 관계를 정의하지 않기에 수평확장, 분산처리에 용이하다.
- 분산처리에 용이하기에 가용성이 좋다.
-
쓰기, 읽기 작업이 Non-Blocking이므로 성능이 좋다.
-
스키마가 없어 데이터의 수정, 추가가 쉽다.
-
데이터를 애플리케이션이 필요로 하는 형식으로 저장하기에 데이터를 읽어오는 속도가 빠르다.
-
-
단점
-
데이터 일관성이 깨질 수 있다.
-
참조 무결성이 깨질 수 있다.
-
Eventual Consistency 개념을 사용한다.
-
-
데이터가 여러 컬렉션에 중복되어 있는 경우, 수정 작업 시 모든 컬렉션의 데이터를 수정해야 한다.
-
RDB의 어떠한 특징 때문에 NoSQL에 비해 부하가 많이 걸릴 "수" 있을까요? (주의: 무조건 NoSQL이 RDB 보다 빠르다라고 생각하면 큰일 납니다!)
-
수평 확장이 어렵다.
-
여러 테이블간의 데이터를 결합하는 조인 연산이 큰 오버헤드가 될 수 있다.
-
강한 데이터 일관성을 보장하기 위한 트랜잭션과 ACID 속성은 단위 작업의 커넥션 소유 시간을 길게 함으로써, 여유 커넥션 개수가 줄어들게 하고 성능 저하를 일으킬 수 있다.
트랜잭션과 ACID
-
트랜잭션이란 작업의 완전성을 보장해주는 기능
-
논리적인 작업 단위를 모두 완벽하게 처리하거나,
-
처리하지 못할 경우에는 원래 상태로 복구해서
-
작업의 일부만 적용되는 현상이 발생하지 않게 만들어준다.
-
-
Lock은 동시성을 제어하기 위한 기능이라면, 트랜잭션은 데이터의 정합성을 보장하기 위한 기능이라는 차이점이 있다.
-
ACID 속성
-
트랜잭션의 신뢰성을 보장하는 4가지 속성
-
Atomicity: 원자성
- 트랜잭션 내의 모든 명령이 하나의 단위로 취급되어 함께 성공하거나 실패하도록 보장한다.
-
Consistency: 일관성
- 트랜잭션 내에서 이루어진 변경 사항이 데이터베이스 제약 조건과 일치하도록 보장한다.
-
Isolation: 독립성
- 각 트랜잭션은 독립적으로 실행되어 다른 트랜잭션의 영향을 받지 않는다.
-
Durability: 영속성
- 트랜잭션이 완료되고 변경 사항이 데이터베이스에 기록되면 그 결과는 영구적으로 유지된다.
-
ACID 원칙 중, Durability를 DBMS는 어떻게 보장하나요?
-
ACID 원칙 중 Durability는 트랜잭션이 성공적으로 완료되면 시스템 장애가 발생해도 해당 트랜잭션의 결과가 지속적으로 보존되는 것을 의미한다.
-
MySQL에서 영속성을 보장하는 주요 방법은 Redo 로그를 사용하는 것이다.
-
트랜잭션이 수행될 때, 변경 내역을 Redo 로그에 기록한다.
-
Redo 로그는 비휘발성 저장소에 저장되어 시스템이 갑작스런 장애로 중단되더라도 유지된다.
-
이후 장애 발생 시 Redo 로그를 이용해 트랜잭션의 결과를 복원함으로써 Durability를 보장한다.
-
트랜잭션을 사용해 본 경험이 있나요? 어떤 경우에 사용할 수 있나요?
-
여러 작업을 하나의 단위로 묶어야 할 때 유용하게 사용할 수 있다.
-
한 학생이 수강신청을 하는 상황일 때,
-
자신의 수강 신청 내역에는 과목을 추가했지만 과목의 정원을 증가시키지 못하고 예상치 못한 오류로 종료되는 경우, 수강 정원에 대한 정합성 문제가 발생한다.
-
자신의 수강 신청 내역에 과목을 추가하는 것과 과목의 정원을 증가시키는 것을 하나의 트랜잭션으로 묶어 처리함으로써 하나의 요청만 처리되어 발생하는 정합성 문제를 예방할 수 있다.
-
읽기에는 트랜잭션을 걸지 않아도 될까요?
-
일반적인 단일 읽기 작업의 경우 트랜잭션을 생략해도 무방하나 상황에 따라 읽기 작업에도 트랜잭션이 필요할 수 있다.
-
복수의 읽기 작업이 일관된 데이터를 읽어야 할 때, 트랜잭션을 사용하여 중간에 다른 트랜잭션에 의해 데이터가 변경되는 것을 방지할 수 있다.
트랜잭션 격리 레벨
-
트랜잭션 격리 수준이란, 여러 트랜잭션이 동시에 처리될 때 특정 트랜잭션이 다른 트랜잭션에서 변경하거나 조회하는 데이터를 볼 수 있게 허용할지 말지를 결정하는 것이다.
-
4개의 격리 수준이 있으며, 격리 수준이 높아질수록 동시 처리 성능도 떨어진다.
이상현상
-
Phantom Read
- 다른 트랜잭션에서 수행한 변경 작업에 의해 레코드가 보였다 안보였다 하는 현상
-
Non-Repeatable Read
- 하나의 트랜잭션 내에서 똑같은 조회 쿼리를 여러번 실행했는데 서로 다른 결과를 가져오는 현상
-
Dirty Read
- 어떤 트랜잭션에서 처리한 작업이 완료되지 않았는데도 다른 트랜잭션에서 볼 수 있는 현상
-
Read Uncommitted
-
트랜잭션 내부에서 처리 중이거나, 아직 커밋되지 않은 데이터를 다른 트랜잭션이 읽는 것을 허용한다.
-
Phantom Read, Non-Repeatable Read, Dirty Read 발생 가능
-
거의 사용하지 않는 격리 수준
-
-
Read Committed
-
커밋이 완료된 트랜잭션의 결과만 조회할 수 있다.
-
Phantom Read, Non-Repeatable Read 발생 가능
-
-
Repeatable Read
-
MVCC를 이용해 한 트랜잭션내에서 동일한 읽기 결과를 보장한다.
-
트랜잭션은 자신보다 이전에 완료된 트랜잭션의 데이터 결과만을 참고한다.
-
SELECT .. FOR UPDATE 나 SELECT .. FOR SHARE 처럼 테이블의 잠금을 걸고 조회하는 경우, 언두로그를 살펴보지 않고 테이블 데이터를 직접 읽기에 Phantom Read가 발생할 수 있다.
- MySQL의 경우 범위락인 갭락을 사용하여 이를 어느정도 막는다.
-
-
Serializable
-
모든 트랜잭션들이 직렬화되어 작동한다.
-
동시성이 중요한 데이터베이스에서는 거의 사용하지 않는다.
-
만약 MySQL을 사용하고 있다면, (InnoDB 기준) Undo 영역과 Redo 영역에 대해 설명해 주세요.
-
Undo
-
INSERT, UPDATE, DELETE같은 DML로 데이터를 변경했을 때 변경되기 전의 데이터를 보관하는 곳
-
MVCC를 구현하는 데 사용되며, 트랜잭션 격리와 일관된 읽기를 지원한다.
-
트랜잭션의 롤백 대비용으로 사용되거나, 트랜잭션 격리 수준을 유지하면서 높은 동시성을 제공하는 데 사용한다.
-
-
Redo
-
커밋된 트랜잭션의 변경 내역을 저장하여 시스템 장애 발생 시 복구할 수 있게 한다.
-
트랜잭션이 커밋되면 즉시 디스크로 기록되도록 설정하는 것이 권장된다.
-
그런데, 스토리지 엔진이 정확히 무엇을 하는 건가요?
-
실제 데이터를 디스크에 저장하거나 디스크로부터 데이터를 읽어오는 역할을 수행한다.
-
각 스토리지 엔진마다 트랜잭션을 처리하는 방식의 차이가 있다.
-
InnoDB는 MySQL의 대표적인 스토리지 엔진이다.
인덱스
-
데이터베이스 데이터의 저장 성능을 희생하고, 데이터의 읽기 속도를 높이기 위해 사용하는 기능
-
책의 색인처럼 사용되며, 특정 값을 빠르게 찾을 수 있도록 도와준다.
-
일반적으로 B-Tree 또는 해시 테이블 구조로 구현된다.
일반적으로 인덱스는 수정이 잦은 테이블에선 사용하지 않기를 권합니다. 왜 그럴까요?
-
B-Tree 특성 상, 인덱스의 삽입 및 변경 작업은 많은 비용이 들기 때문에 수정이 잦은 컬럼에 사용하지 않는 것이 좋다.
-
수정 작업은 해당 인덱스를 삭제한 후 재삽입하는 과정이 필요하다.
ORDER BY 연산의 동작 과정을 인덱스의 존재여부와 연관지어서 설명해 주세요.
-
정렬 기준이 보조 인덱스인 경우, 보조 인덱스를 사용하여 정렬된 레코드의 기본 키값을 읽어올 수 있다.
-
보조 인덱스에서 얻은 기본 키값들을 사용하여 클러스터 인덱스에서 데이터를 읽어온다.
기본키는 인덱스라고 할 수 있을까요? 그렇지 않다면, 인덱스와 기본키는 어떤 차이가 있나요?
-
기본 키 또한 인덱스이다.
-
기본 키는 클러스터 인덱스로, 리프 노드에는 실제 레코드가 있다.
-
기본 키가 아닌 인덱스는 Secondary 인덱스로, 리프 노드에는 클러스터 인덱스의 키 값이 저장된다.
그렇다면 외래키는요?
- 외래 키가 참조하는 열과, 외래 키 모두 인덱스가 필요하다.
인덱스가 데이터의 물리적 저장에도 영향을 미치나요? 그렇지 않다면, 데이터는 어떤 순서로 물리적으로 저장되나요?
-
MySQL InnoDB의 경우, 기본 키는 클러스터 인덱스로 기본 키에 따라 정렬된 순서대로 데이터의 물리적인 저장 순서가 결정된다.
-
즉, 기본 키로 정렬한 순서대로 실제 디스크에 저장된다.
-
Secondary 인덱스는 물리적 저장에 영향을 미치지 않는다.
우리가 아는 RDB가 아닌 NoSQL (ex. Redis, MongoDB 등)는 인덱스를 갖고 있나요? 만약 있다면, RDB의 인덱스와는 어떤 차이가 있을까요?
-
대부분의 NoSQL도 인덱스를 사용할 수 있다.
-
RDB는 컬럼에 인덱스를 생성하는 반면, NoSQL은 문서와 키를 포함한 다양한 데이터 유형에 인덱스를 생성할 수 있다.
(A, B) 와 같은 방식으로 인덱스를 설정한 테이블에서, A 조건 없이 B 조건만 사용하여 쿼리를 요청했습니다. 해당 쿼리는 인덱스를 탈까요?
-
MySQL이 인덱스를 사용할 땐, 인덱스의 leading column이 포함된 조건을 필요로 하기 때문에 해당 쿼리는 인덱스를 타지 않는다.
-
A 조건만 사용하는 경우엔 인덱스를 타게 된다.
클러스터링과 레플리케이션
-
클러스터링이란 여러 데이터베이스 서버가 하나의 데이터베이스처럼 작동하도록 구성하는 방식을 말한다.
- 고가용성과 부하 분산을 위해 사용된다.
-
레플리케이션이란 복제본 데이터베이스를 운용하는 것을 말한다.
-
데이터의 백업, 읽기 부하 분산, 재해 복구를 위해 사용한다.
-
마스터 데이터베이스 서버가 슬레이브 데이터베이스 서버에게 자신의 데이터를 보냄으로써 데이터를 복제한다.
-
이러한 분산 환경에선, 트랜잭션을 어떻게 관리할 수 있을까요?
-
일관성을 유지하기 위한 여러 방법이 있지만, 구현 방법이 어려워 일관성을 약간 포기하는 Eventual Consistency 방법을 적용하는 것이 효율적이다.
-
사용자가 보기에 잠깐은 불일치하는 데이터가 있을 수 있지만, 결국에는 모든 데이터가 일치하게 되는 방법
-
CAP이론에 따르면 분산 시스템은 일관성과 가용성 중 하나를 선택해야 하는데, 최종 일관성은 가용성과 분할 허용성을 지향하는 방법이다.
-
마스터, 슬레이브 데이터 동기화 전 까지의 데이터 정합성을 지키는 방법은 무엇이 있을까요?
-
비동기 복제
-
마스터의 데이터가 변경되면, 슬레이브가 데이터 변경 내용을 요청하고 반영한다.
-
마스터는 데이터 쓰기 작업을 완료한 후 바로 다음 작업을 수행할 수 있다.
-
성능적인 측면에서 좋지만, 슬레이브와 마스터가 완전히 동기화되지 않을 수 있다.
-
-
준동기 복제
-
마스터의 데이터가 변경되면, 슬레이브에게 데이터 변경 요청을 전송한다.
-
AFTER COMMIT 방식은 마스터가 먼저 변경을 수행한 뒤에 슬레이브에게 변경 요청을 보내는 방식
-
AFTER SYNC 방식은 마스터가 먼저 슬레이브에게 변경 요청을 보낸뒤에 슬레이브로부터 ACK를 받으면 마스터도 변경을 수행하는 방식
-
-
마스터는 슬레이브가 데이터 변경 요청을 잘 받았다는 확인 응답을 받고 나서 클라이언트의 요청에 응답한다.
-
슬레이브와 마스터가 비교적 데이터 일관성을 갖지만, 운영의 불안정성이 올라간다.
- 슬레이브에 문제가 발생하는 경우 마스터가 영향을 받는다.
-
샤딩 방식은 무엇인가요? 만약 본인이 DB를 분산해서 관리해야 한다면, 레플리케이션 방식과 샤딩 방식 중 어떤 것을 사용할 것 같나요?
-
샤딩은 데이터베이스 수평적 확장을 위한 기술로, 데이터를 여러 서버에 분산하여 저장하는 방식
-
데이터베이스를 샤드라고 부르는 작은 단위로 분할한다.
-
모든 샤드는 같은 스키마를 쓰지만 샤드에 보관되는 데이터 사이에는 중복이 없다.
-
파티션을 나누는 샤딩 키는 데이터를 고르게 분할 할 수 있도록 하는게 가장 중요하다.
- 샤딩 키는 하나 이상의 컬럼으로 구성된다.
-
읽기 작업을 분산하거나, 가용성을 높이고 시스템 일부가 장애가 나도 계속 서비스할 수 있는 것에 목적을 둔다면 Replication
-
대량의 데이터 처리, 확장성, 쓰기 작업의 처리량 향상에 목적을 둔다면 샤딩을 이용한다.
정규화
-
데이터베이스 설계에서 데이터를 효율적으로 저장하고 중복을 최소화하기 위해 테이블을 분해하는 과정
-
데이터 무결성을 유지하고, 데이터 저장 공간을 절약하며, 데이터 조작 작업의 이상 현상을 방지하는 것이 목적
정규화를 하지 않을 경우, 발생할 수 있는 이상현상에 대해 설명해 주세요.
-
삽입 이상
- 새로운 데이터를 삽입할 때 불필요한 데이터도 함께 삽입되는 현상
-
삭제 이상
-
데이터를 삭제할 때 필요한 데이터까지 함께 삭제되는 현상
-
학생 정보와 수강 과목 정보가 같은 테이블에 저장되어 있다면, 수강 과목 정보를 지우면 학생 정보도 사라진다.
-
-
갱신 이상
- 데이터를 수정할 때 여러 곳에서 중복된 데이터를 일일이 수정해야 하는 현상
정규화가 무조건 좋은가요? 그렇지 않다면, 어떤 상황에서 역정규화를 하는게 좋은지 설명해 주세요.
-
쓰기 성능을 일부 포기하고, 읽기 성능을 개선하기 위해 역정규화를 하기도 한다.
- 데이터를 묶거나, 복제 사본을 추가함으로써 읽기 성능 개선
-
읽기 성능 향상이 필요하거나 데이터 무결성보다 성능이 중요할 때, 단순화된 데이터 모델이 필요할 때 역정규화를 하면 좋다.
View
-
질의의 결과로 만들어지는 가상의 테이블
-
View를 생성할 때 사용한 SELECT 쿼리문을 DBMS가 저장한다.
-
View를 호출하는 순간 View를 생성할 때 작성한 SELECT문을 실행한다.
- 따라서 View는 테이블이 아니라, 저장된 질의를 실행하여 실시간으로 데이터를 조회하는 것이다.
그렇다면, View의 값을 수정해도 실제 테이블에는 반영되지 않나요?
-
단일 테이블에서 생성되고, 기본키를 포함하며 DISTINCT, GROUP BY, 서브쿼리 등을 사용하지 않는 등 복잡한 조건을 만족해야 View를 통해 실제 테이블을 수정할 수 있다.
-
따라서 View를 통한 실제 테이블 변경은 거의 불가능하며, 데이터 정합성을 위해서라도 권장되지 않는다.
DB Join
-
여러 테이블을 묶어서 하나의 테이블로 표현하는 것
-
INNER JOIN
-
조건이 일치하는 결과만 출력하는 동등 조인
-
가장 일반적인 조인
-
-
OUTER JOIN
- 기준이 되는 테이블의 결과는 모두 출력하고, 그 외의 테이블들은 조건이 일치하는 결과만 출력
-
NATURAL JOIN
-
두 테이블에서 같은 이름을 가지는 모든 attribute에 대해 동등 조인 수행
-
join 조건을 따로 명시하지 않는다.
-
-
CROSS JOIN
-
두 테이블의 tuple pair로 만들 수 있는 모든 조합을 반환한다.
-
join 조건이 따로 없다.
-
-
EXCLUSIVE JOIN
- 특정 테이블에만 있는 결과만 출력하는 조인 (차집합 개념)
-
SELF JOIN
- 테이블 자기자신에 대해 다른 별칭을 사용하여 조인
사실, JOIN은 상당한 시간이 걸릴 수 있기에 내부적으로 다양한 구현 방식을 사용하고 있습니다. 그 예시에 대해 설명해 주세요.
-
Nested Loop Join
-
Outer Table을 순회하는 for문과 Inner Table을 순회하는 for문을 돌면서 만들 수 있는 모든 튜플에 대해 조합을 검사하는 방식이다.
-
테이블 랜덤 액세스가 발생한다.
-
소량의 데이터를 처리할 때 사용한다.
-
-
Sort Merge Join
-
Outer Table, Inner Table을 정렬한 다음 NL 조인처럼 중첩 for문을 돌며 Join한다.
-
정렬된 테이블들은 메모리 영역에 저장되므로 테이블 랜덤 액세스가 발생하지 않아 빠르다.
- 정렬된 테이블의 크기가 커 메모리 영역에 전부 들어가지 않는다면 디스크에도 저장된다.
-
Inner Table에 적절한 인덱스가 걸려있지 않거나 대량의 데이터를 해시 조인으로 처리할 수 없을 때 (범위로 JOIN 하는 경우) 사용한다.
-
-
Hash Join
-
작은 쪽 테이블을 읽어 해시 테이블을 생성하고, 반대 쪽 큰 테이블을 순회하면서 해시 테이블을 사용해서 조인하는 방식이다.
-
해시 테이블은 메모리 영역에 저장되므로 테이블 랜덤 액세스가 발생하지 않아 빠르다.
- 해시 테이블은 비교적 작기에 왠만하면 메모리 영역에 저장되므로, 디스크 I/O는 발생하지 않는다.
-
수행 빈도가 낮고, 대용량 테이블을 조인할 때 주로 사용한다.
- 해시 테이블은 쿼리를 실행하고 바로 삭제된다.
-
그렇다면 입력한 쿼리에서 어떤 구현 방식을 사용하는지는 어떻게 알 수 있나요?
- MySQL 기준으로는 쿼리 앞에 explain analyze 키워드를 붙여 쿼리 실행 방식을 살펴볼 수 있다.
JOIN의 성능도 인덱스의 유무의 영향을 받나요?
-
Nested Loop Join의 경우 인덱스 영향을 받기에, 인덱스 구성 전략이 중요하다.
-
일반적으로 Outer, Inner 테이블 모두 인덱스를 활용한다.
-
Outer 테이블이 작다면, Outer 테이블은 한 번만 읽기 때문에 Table Full Scan을 할 수도 있지만, Inner 테이블은 반드시 인덱스를 사용하는 것이 좋다.
- Inner 테이블이 인덱스를 사용하지 않는다면 Outer 테이블의 row 개수만큼 Table Full Scan이 발생한다.
-
-
Sort Merge Join의 경우, 조인 컬럼에 인덱스가 있다면 정렬 단계 없이 바로 조인할 수는 있지만 인덱스 유무의 영향을 크게 받지는 않는다.
- 두 테이블을 정렬한 뒤 Sort Area에 저장한 데이터 자체가 인덱스 역할을 하므로, 인덱스가 없어도 사용할 수 있는 조인 방식이다.
-
Hash Join의 경우, Sort Merge Join과 유사하게 인덱스를 사용해 해시 테이블을 만드는 데 참고할 수는 있지만 인덱스 유무의 영향을 크게 받지는 않는다.
- 작은 테이블로 만든 해시 테이블 자체가 인덱스 역할을 한다.
B-Tree와 B+Tree
-
B-Tree
-
자녀 노드의 최대 개수를 늘리기 위해서 부모 노드에 key를 하나 이상 저장한 뒤 오름차순으로 정렬한다.
-
정렬 순서에 따라 자녀 노드들의 key값의 범위가 결정된다.
-
BST는 자녀 노드의 최대 개수가 2개인데 반해, B-Tree는 자녀 노드의 최대 개수를 원하는 만큼 설정할 수 있다.
- B-tree는 BST를 일반화한 트리이다.
-
최대 자녀 노드 개수 M을 정하면, 노드의 최대 key 개수는 M-1, 노드의 최소 key 개수는 M//2 올림으로 정해진다.
- 이를 M차 B-Tree라 한다.
-
삽입은 항상 leaf 노드에서 일어나고, 노드의 최대 key 개수를 초과하게 되면 가운데 key를 위로 올리고, 좌우 key들은 분할한다.
- 모든 leaf 노드들은 같은 레벨에 있는 balanced tree이다.
-
-
B+Tree
-
B-Tree의 변형
-
B-Tree는 모든 노드가 실제 데이터를 가리키는 포인터를 가리키는데 반해, B+Tree는 leaf 노드만 실제 데이터를 가리키는 포인터를 가지고, internal 노드는 key로만 이루어져 있다.
-
따라서 하나의 internal 노드에 더 많은 key들을 저장할 수 있게되어 트리 높이가 더 낮아진다.
-
internal 노드를 index 노드, leaf 노드를 data 노드라 부르기도 한다.
-
-
B+Tree의 leaf 노드끼리는 서로 연결 리스트로 연결되어 있다.
- internal 노드를 통하지 않고 형제 leaf 노드로 이동할 수 있기에, 순차 탐색 및 정렬에 용이하다.
-
그렇다면, B+Tree가 B-Tree에 비해 반드시 좋다고 할 수 있을까요? 그렇지 않다면 어떤 단점이 있을까요?
-
B+Tree는 데이터에 접근하기 위해 반드시 leaf 노드 (data 노드) 까지 내려가야 한다.
-
루트 노드의 key값을 가진 데이터를 원하는 경우, B-Tree는 한 번에 탐색을 끝내지만 B+Tree는 무조건 leaf 노드까지 내려가야 하는 단점이 있다.
- 레코드의 직접 접근이 필요하고, 점 쿼리가 주로 사용되는 환경에서는 B-Tree가 낫다.
DB에서 RBT를 사용하지 않고, B-Tree/B+Tree를 사용하는 이유가 있을까요?
-
각 노드의 자식 노드개수의 차이로 인한 depth차이 때문에 RBT대신 B-Tree/B+Tree를 사용한다.
-
RBT는 트리의 depth가 상대적으로 깊어 특정 key값을 갖는 데이터를 찾아오기 위해서 많은 디스크 I/O가 발생한다.
- B-Tree/B+Tree는 트리의 depth가 상대적으로 얕다
-
또한, 메모리는 디스크의 데이터를 효율성을 위해 block 단위로 읽어오기에, key값이 군집을 이루는 B-Tree/B+Tree의 저장 공간 활용도가 더 좋다.
오름차순으로 정렬된 인덱스가 있다고 할 때, 내림차순 정렬을 시도할 경우 성능이 어떻게 될까요? B-Tree/B+Tree의 구조를 기반으로 설명해 주세요.
-
innoDB 기준으로 성능이 떨어진다.
-
인덱스 레코드 (data 노드) 는 양방향으로 연결되어 있기 때문에 리프 노드 간의 내림차순 정렬은 성능에 영향이 없지만, 리프 노드를 이루는 하나의 페이지 안의 데이터들은 단방향으로 연결되어 저장되기 때문에 성능에 영향이 있다.
DB Locking
-
데이터베이스에서 동시성과 데이터 일관성을 보장하기 위해 사용되는 메커니즘
-
여러 트랜잭션 (사용자) 이 동시에 같은 데이터에 접근하려고 할 때, 트랜잭션들 간의 접근을 제어함으로써 충돌을 방지한다.
-
write-lock(exclusive lock)의 경우, write-lock을 취득한 트랜잭션만이 데이터에 접근할 수 있다.
-
read-lock(shared lock)의 경우, read-lock을 취득하지 못한 다른 트랜잭션이 읽기 목적으로 같은 데이터에 대한 read-lock 획득은 허용하나, 데이터의 변경을 위한 write-lock 획득은 허용하지 않는다.
-
하나의 트랜잭션에서 모든 locking operation이 unlocking operation 보다 먼저 수행되어야 Serializability가 보장된다.
-
2PL protocol (two-phase locking)
-
deadlock에 빠질 위험성이 존재한다.
-
-
Optimistic Lock/Pessimistic Lock에 대해 설명해 주세요
-
Optimistic Lock
-
트랜잭션간의 충돌이 거의 발생하지 않는다고 가정하고 사용하는 Lock 전략
-
데이터 수정 시 버전 번호나 타임스탬프를 사용하여 데이터의 변경 여부를 확인한다.
- 수정 과정에서 버전 번호나 타임스탬프가 변경되었다면 충돌이 발생했다고 판단하고 해당 트랜잭션을 롤백한다.
-
충돌이 자주 발생하는 환경에서는 트랜잭션 롤백이 자주 일어나 비효율적이다.
-
애플리케이션 Lock이라고도 한다.
-
-
Pessimistic Lock
-
트랜잭션간의 충돌이 빈번히 발생한다고 가정하고 사용하는 Lock 전략
-
트랜잭션이 시작될 때 shared lock이나 exclusive lock을 걸고 시작한다.
-
데이터에 대한 접근을 엄격하게 제어하기에 시스템 성능에는 부정적이다.
-
데이터베이스 트랜잭션 Lock이라고도 한다.
-
물리적인 Lock을 건다면, 만약 이를 수행중인 요청에 문제가 생겨 비정상 종료되면 Lock이 절대 해제되지 않는 문제가 생길 수도 있을 것 같습니다. DB는 이를 위한 해결책이 있나요? 없다면, 우리가 이 문제를 해결할 수 없을까요?
-
InnoDB 스토리지 엔진은 데드락 감지 스레드를 가지고 있다.
-
데드락 감지 스레드가 주기적으로 잠금 대기 그래프를 검사해 교착 상태에 빠진 트랜잭션들을 찾아서 그 중 하나를 강제 종료한다.
- 언두 로그 레코드를 더 적게 가진 트랜잭션이 종료된다.
-
혹은 Lock wait timeout을 설정하여 무한정 대기하지 않도록 할 수 있다.
DB와 대규모 트래픽
-
데이터베이스 트래픽을 분산시킨다.
-
데이터베이스 서버 스펙을 향상시킨다.
-
샤딩으로 데이터를 분산처리한다.
-
샤딩이란, horizontal partitioning으로 나눈 각 파티션들을 서로 다른 DB서버에 저장함으로써 트래픽을 분산시키는 것
-
이때 partition을 나누기 위해 사용되는 partition key를 shard key라 부르고, 각 파티션들을 shard라 부른다.
-
-
서비스별로 데이터베이스를 독립적으로 분리한다.
-
CQRS 패턴을 적용해 Query용 데이터베이스와 Command용 데이터베이스를 분리시킨다.
DB 서버를 분산하지 않고, 트래픽을 감당할 수 있는 방법은 없을까요?
-
vertical partitioning
-
column을 기준으로 하나의 테이블을 여러개의 테이블로 나누는 방식
-
데이터 크기는 크지만, 조회 빈도가 높지 않은 column을 다른 테이블로 나눔으로써 디스크 I/O에 대한 부담을 줄일 수 있다.
-
-
horizontal partitioning
-
row를 기준으로 하나의 테이블을 여러개의 테이블로 나누는 방식
-
row의 특정 필드값을 해쉬 함수에 input으로 넣는다.
- 특정 필드값을 partition key라 한다.
-
식별자를 output으로 받는다.
-
식별자를 바탕으로 테이블을 나누고, 해당 row를 매핑되는 식별자를 가진 테이블에 저장한다.
-
-
하나의 테이블에 row가 너무 많아지지 않도록 테이블을 나눠 인덱스 크기를 줄임으로써 읽기/쓰기 시간을 줄인다.
-
Schema
-
데이터베이스의 구조와 제약조건에 관한 전반적인 명세
-
개체, 개체의 속성, 개체들간의 관계, 제약 조건들을 명세한 것
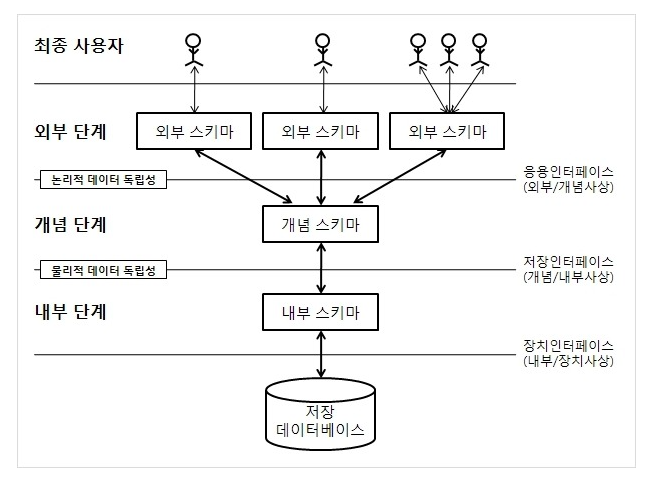
Schema의 3계층에 대해 설명해 주세요.
-
외부 스키마
-
사용자 입장에서 바라보는 스키마
-
사용자 뷰
-
-
개념 스키마
-
데이터베이스의 전체적인 논리 구조
- 데이터간의 관계, 제약 조건, 접근 권한, 보안 정책과 같은 명세를 정의
-
ER diagram 등을 사용해 논리적으로 표현한다.
-
-
내부 스키마
-
실제 물리적인 저장장치인 DB에 어떤 방식으로 저장되는지를 명세
-
내부 레코드의 타입, 물리적 순서, 인덱스 유무와 같은 개발자에게 필요한 구체적인 정보
-
DB의 Connection Pool
-
애플리케이션 서버와 DB가 쿼리 요청이 필요할때마다 커넥션을 직접 맺고 끊는다면, 커넥션 연결 및 해제 과정때문에 많은 비용이 발생한다.
-
이러한 문제를 해결하기 위해 애플리케이션 서버가 미리 DB와의 커넥션을 맺어놓은 후, 커넥션들을 모아서 관리, 대여, 반납하는 방식이 DBCP이다.
- DB에 쿼리 요청이 필요하다면, DBCP의 유휴 커넥션을 가져와서 쿼리 요청을 한 후, 다 사용한 커넥션을 DBCP에 반납한다.
-
이처럼 커넥션 재사용을 통해 커넥션 연결 및 해제과정에 필요한 비용을 절약할 수 있다.
-
MySQL 설정 파라미터
-
max_connections: client와 맺을 수 있는 최대 connection 수
-
wait_timeout: 사용되지 않는 커넥션이 다시 요청이 오기까지 얼마의 시간을 기다린 뒤에 커넥션을 닫을 것인지를 결정
-
-
HikariCP 설정 파라미터
-
minimumIdle: 풀에서 유지하는 최소한의 유휴 커넥션 수
-
maximumPoolSize: 풀이 가질 수 있는 최대 커넥션 수, 일반적으로 minimumIdle 설정값과 같게 함으로써 커넥션 수가 변경되지 않도록 한다.
-
maxLifetime: 커넥션의 최대 수명, 서버의 wait_timeout보다 조금 작게 설정하는 것이 좋다.
-
connectionTimeout: 스레드가 커넥션을 받기 위해 기다릴 수 있는 최대 대기 시간
-
DB와 Client가 Connection을 어떻게 구성하는지 설명해 주세요.
-
DB와 Client는 TCP/IP 연결을 통해 커넥션을 구성한다.
-
이후 커넥션 위에서 쿼리 요청 및 쿼리 응답을 받는다.
Table Full Scan, Index Range Scan
-
Table Full Scan
-
테이블을 처음부터 끝까지 전부 읽으며 필요한 레코드를 반환한다.
-
빠른 응답을 보내야 하는 웹 서비스에서는 적합하지 않다.
- 인접한 페이지가 연속해서 읽히는 경우, 한 번에 인접한 여러 페이지를 대용량으로 읽어들이는 Read Ahead 기능을 통해, 좀 더 빨리 처리할 수 있다.
-
인덱스 풀 스캔은 테이블 풀 스캔과 읽는 레코드 수는 같지만, 인덱스에 포함된 컬럼만 가지고 쿼리를 처리하기 때문에 비교적 빠르다.
-
-
Index Range Scan
-
const, ref, range와 같은 접근 방법을 묶어서 지칭한다.
-
const: primary key나 unique key로 동등 조건 검색을 하여 단 1건의 레코드만 반환하게 되는 접근 방법
-
ref: 인덱스로 동등 조건 검색을 하는 접근 방법으로 1건의 레코드만 반환된다는 보장이 없다.
-
range: 인덱스로 범위 검색을 하는 접근 방법
-
-
인덱스를 효율적으로 사용하는 접근 방법
-
작업 범위 결정 조건으로 인덱스를 사용한다.
-
가끔은 인덱스를 타는 쿼리임에도 Table Full Scan 방식으로 동작하는 경우가 있습니다. 왜 그럴까요?
-
인덱스를 통해 테이블의 레코드를 읽는 것은 인덱스를 거치지 않고 바로 테이블의 레코드를 읽는 것보다 높은 비용이 든다.
- 일반적으로 인덱스를 통해 레코드 1건을 읽는 것은 테이블에서 직접 레코드 1건을 읽는 것보다 4~5배 정도 비용이 많이 든다.
-
따라서 검색하려는 레코드의 개수가 전체 테이블의 20 ~ 25%를 넘어서면 인덱스를 이용하지 않고 테이블 풀 스캔을 하면서 필요한 레코드만 필터링하는 것이 효율적이다.
COUNT (개수를 세는 쿼리) 는 어떻게 동작하나요? COUNT(1), COUNT(*), COUNT(column) 의 동작 과정에는 차이가 있나요?
InnoDB 기준
-
count(*)
-
사용 가능한 가장 작은 secondary 인덱스를 사용하여 개수를 센다.
-
secondary 인덱스를 사용할 수 없는 경우 clustered 인덱스를 스캔하여 처리한다.
- 따라서 인덱스 풀 스캔을 사용한다.
-
-
count(1)
- count(*)과 동일하게 동작한다.
-
count(column)
-
해당 column이 null이 아닌값들만 개수를 센다.
-
해당 column이 인덱스라면 인덱스 풀 스캔 사용
-
해당 column이 인덱스가 아니라면 테이블 풀 스캔 사용
-
SQL Injection
-
데이터베이스를 사용하는 웹 애플리케이션에서 공격자가 입력 폼에 조작된 쿼리문을 삽입함으로써
-
웹 서비스의 데이터베이스정보를 열람하거나 조작할 수 있는 보안상의 허점
그렇다면, 우리가 서버 개발 과정에서 사용하는 수많은 DB 라이브러리들은 이 문제를 어떻게 해결할까요?
-
Parameter Binding을 사용하는 PreparedStatement객체를 사용한다.
-
파라미터로 사용되는 문자열이 이스케이프가 필요한 문자열인지 검사한다.
-
조작된 쿼리문같은 문자열은 이스케이프 처리되어 방어할 수 있다.
-
출처
https://velog.io/@jduck1024/%EC%A1%B0%EC%9D%B8-%EA%B8%B0%EB%B3%B8-%EC%9B%90%EB%A6%AC
https://www.youtube.com/watch?v=SVD5ldwVYpo&t=344s
조인 알고리즘https://www.youtube.com/watch?v=bqkcoSm_rCs&t=3s
https://www.youtube.com/watch?v=H_u28u0usjA
https://www.youtube.com/watch?v=liPSnc6Wzfk
B-Treehttps://engineerinsight.tistory.com/336#%F0%9F%92%8B%C2%A0%EC%B0%B8%EA%B3%A0%EC%9E%90%EB%A3%8C-1
https://m.blog.naver.com/ya3344/221395287263
B+TreeReal MySQL 8.0 1권
MySQLhttps://shuu.tistory.com/88
https://www.youtube.com/watch?v=0PScmeO3Fig&list=PLcXyemr8ZeoREWGhhZi5FZs6cvymjIBVe&index=19
DB Lockinghttps://www.youtube.com/watch?v=LDi5muN2kgI
https://sabarada.tistory.com/175
https://f-lab.kr/insight/pessimistic-vs-optimistic-locking?gad_source=1&gclid=Cj0KCQjwj9-zBhDyARIsAERjds1cD5MKOpbyFk921Gq1MH4BrIp80XjfYFLlrWJPKfoLbHvi9UALSlMaAmD7EALw_wcB
Optimistic Lock, Pessimistic Lockhttps://incheol-jung.gitbook.io/docs/q-and-a/spring/db-feat.-routing-datasource
https://www.youtube.com/watch?v=P7LqaEO-nGU
DB와 대규모 트래픽https://press17.tistory.com/40
https://jwprogramming.tistory.com/47
https://www.youtube.com/watch?v=forbtwMZ9Xo
스키마https://www.youtube.com/watch?v=zowzVqx3MQ4&t=1721s
DBCPhttps://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html#function_count
count queryhttps://www.youtube.com/watch?v=FoZ2cucLiDs
https://www.youtube.com/watch?v=qzas_-u4Nxk
SQL Injectionhttps://p829911.tistory.com/11
PreparedStatementhttps://mangkyu.tistory.com/299
격리 수준https://da-nyee.github.io/posts/db-replication-data-consistency-issue/
DB Replication 데이터 정합성
