
모던 자바 인 액션을 읽고
-
책을 읽으며 중요하다고 생각되는 내용들을 정리하였다.
-
책을 정리해도 내용이 많아서 넘버링을 하였다.
정리한 Chapter
-
1장 자바 8, 9, 10, 11: 무슨 일이 일어나고 있는가
-
2장 동작 파라미터화 코드 전달하기
-
3장 람다 표현식
-
4장 스트림 소개
-
5장 스트림 활용
-
6장 스트림으로 데이터 수집
-
7장 병렬 데이터 처리와 성능
-
8장 컬렉션 API 개선
-
9장 리팩터링, 테스팅, 디버깅
자바 8, 9, 10, 11: 무슨 일이 일어나고 있는가
모던 자바의 새로운 기능
-
병렬 연산을 지원하는 스트림 API 제공
-
메서드에 코드를 전달할 수 있다.
-
동작 파라미터화
-
함수가 일급 시민이 된다.
-
익명함수 람다 도입
-
메서드에 코드 (동작) 전달하기
- 자바 8 이전
public static List<Apple> filterGreenApples(List<Apple> inventory) {
List<Apple> result = new ArrayList<>();
for (Apple apple : inventory) {
if ("grren".equals(apple.getColor())) {
result.add(apple);
}
}
return result;
}
public static List<Apple> filterHeavyApples(List<Apple> inventory) {
List<Apple> result = new ArrayList<>();
for (Apple apple : inventory) {
if (apple.getWeight() > 150) {
result.add(apple);
}
}
return result;
}
filterGreenApples(List<Apple> inventory)는 녹색 사과만 담는다.filterHeavyApples(List<Apple> inventory)는 150 이상 무거운 사과만 담는다.if조건문을 제외하고, 코드가 중복된다.
-
자바 8 메서드 전달
- 클래스의 메서드를 인수로 넘겨줄 수 있으므로, 필터링 메서드를 중복 구현할 필요가 없다.
public static List<Apple> filterApples(List<Apple> inventory, Predicate<Apple> p) {
List<Apple> result = new ArrayList<>();
for (Apple apple : inventory) {
if (p.test(apple)) {
result.add(apple);
}
}
return result;
}
public static boolean isGreenApple(Apple apple) {
return "green".equals(apple.getColor());
}
public static boolean isHeavyApple(Apple apple) {
return apple.getWeight() > 150;
}
isGreenApple(Apple apple),isHeavyApple(Apple apple)과 같은 동작을 필터링 메서드에 넘겨준다.
Predicate<Apple> p로 받는다.if (p.test(apple))를 통해 넘겨준 동작을 수행한다.
public static void main(String[] args) {
List<Apple> inventory = List.of(
new Apple(80, "green"),
new Apple(155, "green"),
new Apple(120, "red")
);
List<Apple> greenApples = filterApples(inventory, FilteringApples::isGreenApple);
System.out.println(greenApples); // [Apple{color='green', weight=80}, Apple{color='green', weight=155}]
List<Apple> heavyApples = filterApples(inventory, FilteringApples::isHeavyApple);
System.out.println(heavyApples); // [Apple{color='green', weight=155}]
}실행 결과
-
자바 8 람다 전달
-
클래스의 메서드를 매번 정의하지 않고, 익명 메서드를 만들어 파라미터로 전달할 수 있다.
-
자주 사용하지 않고, 동작이 간단한 메서드는 람다로 표현하는 것이 간결하다.
-
List<Apple> greenApples2 = filterApples(inventory, a -> "green".equals(a.getColor()));
System.out.println(greenApples2); // [Apple{color='green', weight=80}, Apple{color='green', weight=155}]
List<Apple> heavyApples2 = filterApples(inventory, a -> a.getWeight() > 150);
System.out.println(heavyApples2); // [Apple{color='green', weight=155}]스트림
-
기존의 컬렉션은
for-each루프를 이용해 외부 반복을 해왔다. -
스트림은 내부 반복을 통해 모든 데이터를 처리한다.
-
데이터 필터링, 추출, 그룹화와 같은 기능이 있다.
-
쉽게 병렬화 할 수 있다.
Default 메서드
-
구현 클래스에서 구현하지 않아도 되는 메서드를 인터페이스에 추가할 수 있다.
-
이를 통해 기존의 인터페이스 구현체들의 코드를 건드리지 않고도 인터페이스를 자유롭게 확장할 수 있다.
Optional<T> 클래스
-
NullPointer예외를 피할 수 있도록 도와준다. -
값이 없는 상황 (
null) 을 어떻게 처리할 지 명시적으로 구현하는 메서드를 포함한다.
동작 파라미터화 코드 전달하기
-
동작 파라미터화란 아직은 실행되지 않은 코드 블록을 의미한다.
-
나중에 프로그램에서 호출한다.
-
자주 바뀌는 요구사항에 효과적으로 대응할 수 있다.
-
사과 필터링 예제
- 전통적인 방식은 사용자의 요구가 달라지면 중복되는 코드가 발생했다.
public static List<Apple> filterApplesByColor(List<Apple> inventory, Color color) {
List<Apple> result = new ArrayList<>();
for (Apple apple : inventory) {
if (apple.getColor() == color) {
result.add(apple);
}
}
return result;
}
public static List<Apple> filterApplesByWeight(List<Apple> inventory, int weight) {
List<Apple> result = new ArrayList<>();
for (Apple apple : inventory) {
if (apple.getWeight() > weight) {
result.add(apple);
}
}
return result;
}
- 사과를 색으로 구분하는 메서드와
- 사과를 무게로 구분하는 메서드
- 만약 다른 구분 조건이 필요하다면, 또 다른 중복 메서드를 만들어야 한다.
-
필터링 조건마다 참 거짓을 반환하는
Predicate클래스를 구현하여 메서드에 전달-
하나의 메서드가 다른 동작을 수행하도록 재활용 할 수 있다.
-
클래스를 구현해야 하기에 로직과 관련없는 코드가 많이 추가된다.
-
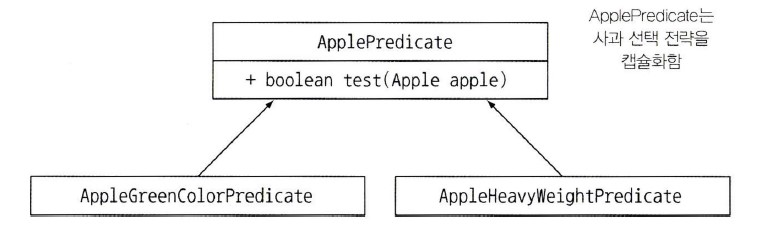
public interface ApplePredicate {
boolean test(Apple apple);
}
public class AppleGreenColorPredicate implements ApplePredicate {
@Override
public boolean test(Apple apple) {
return Color.GREEN == apple.getColor();
}
}
public class AppleHeavyWeightPredicate implements ApplePredicate {
@Override
public boolean test(Apple apple) {
return apple.getWeight() > 150;
}
}
전략 디자인 패턴
public static List<Apple> filterApples(List<Apple> inventory, ApplePredicate p) {
List<Apple> result = new ArrayList<>();
for (Apple apple : inventory) {
if (p.test(apple)) { // 사과 검사 조건을 캡슐화
result.add(apple);
}
}
return result;
}
public static void main(String... args) {
List<Apple> greenApples2 = filterApples(inventory, new AppleGreenColorPredicate());
}
ApplePredicate p를 파라미터로 받아 유연하게 필터링
-
Predicate을 익명 클래스로 구현하여 메서드에 전달-
클래스를 직접 구현하는 것보다 코드의 양을 줄일 수 있다.
-
그러나 여전히 많은 공간을 차지한다.
-
List<Apple> redApples2 = filterApples(inventory, new ApplePredicate() {
@Override
public boolean test(Apple apple) {
return Color.RED == apple.getColor();
}
});익명 클래스는 사용시 혼란스러운 부분이 있다.
public class MeaningOfThis {
public final int value = 4;
public void doIt() {
int value = 6;
Runnable r = new Runnable() {
public final int value = 5;
public void run() {
int value = 10;
System.out.println(this.value);
}
};
r.run();
}
public static void main(String[] args) {
MeaningOfThis m = new MeaningOfThis();
m.doIt(); // 출력 결과 : 5
}
}
run()메서드 내의System.out.println(this.value)의this는Runnable익명 클래스를 참조한다.
-
Predicate를 람다 표현식을 사용해 메서드에 전달- 가장 간결하게 동작을 전달한다.
List<Apple> redApples3 = filterApples(inventory, apple -> Color.RED == apple.getColor());람다 표현식
-
메서드로 전달할 수 있는 익명 함수를 단순화 한 것
-
특정 클래스에 종속되지 않으므로 메서드가 아니라 함수라고 부른다.
-
파라미터, 화살표, 바디로 이루어진다.

- 함수형 인터페이스를 사용하는 문맥에서 람다 표현식을 사용할 수 있다.
함수형 인터페이스
-
정확히 하나의 추상 메서드를 지정하는 인터페이스
-
람다 표현식으로 함수형 인터페이스의 추상 메서드를 구현할 수 있다.
- 람다 표현식은 함수형 인터페이스를 구현한 클래스 인스턴스로 취급된다.
-
@FunctionalInterface애노테이션을 인터페이스 레벨에 붙여 함수형 인터페이스임을 명시할 수 있다.
Execute Around Pattern 에서의 람다 활용
- 자원 처리와 같이 준비 작업과 정리 작업이 핵심 로직을 둘러싸는 패턴
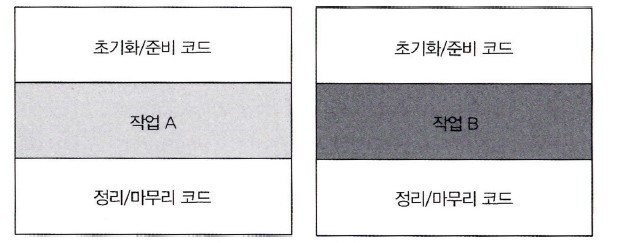
- 핵심 로직 동작을 파라미터화하여 기존의 준비, 정리 과정은 재사용하고, 핵심 로직 동작만 유연하게 변경할 수 있다.
@FunctionalInterface
public interface BufferedReaderProcessor {
String process(BufferedReader b) throws IOException;
}함수형 인터페이스 생성
Java
8
Lambdas
In
Action텍스트 파일 생성
public class ExecuteAround {
private static final String FILE = ExecuteAround.class.getResource("./data.txt").getFile();
public static void main(String[] args) throws IOException {
String oneLine = processFile((BufferedReader b) -> b.readLine()); // 한 줄만 읽는 동작 전달
System.out.println(oneLine); // Java
System.out.println();
String twoLines = processFile((BufferedReader b) -> b.readLine() + b.readLine()); // 두 줄을 읽는 동작 전달
System.out.println(twoLines); // Java8
}
public static String processFile(BufferedReaderProcessor p) throws IOException {
try (BufferedReader br = new BufferedReader(new FileReader(FILE))) { // 자원 준비, 정리과정
return p.process(br); // 핵심 로직 동작
}
}
}
processFile(BufferedReaderProcessor p)메서드의BufferedReaderProcessor p를 나타내는 람다를 전달하여 핵심 로직 동작을 유연하게 변경
이미 정의된 함수형 인터페이스들
- 자바 8은
java.util.function패키지에서 여러가지 함수형 인터페이스를 제공한다.
-
Predicate<T>-
(T t) -> boolean -
test추상 메서드를 정의 -
진위 여부를 판별하는 뉘앙스
-
public class PredicateExample {
public static void main(String[] args) {
List<String> strings = List.of("", "a", "b", "", "c");
List<String> nonEmptyStrings = filter(strings, s -> !s.isEmpty());
System.out.println(nonEmptyStrings); // "a", "b", "c"
}
public static <T> List<T> filter(List<T> list, Predicate<T> p) {
List<T> results = new ArrayList<>();
for (T t : list) {
if (p.test(t)) { // 전달받은 람다를 실행
results.add(t);
}
}
return results;
}
}-
Consumer<T>-
(T t) -> Void -
accept추상 메서드를 정의 -
특정 동작을 시키는 뉘앙스
-
public class ConsumerExample {
public static void main(String[] args) {
forEach(
List.of(1, 2, 3, 4, 5),
i -> System.out.println(i)
);
}
public static <T> void forEach(List<T> list, Consumer<T> c) {
for (T t : list) {
c.accept(t); // 전달받은 람다를 실행
}
}
}-
Function<T, R>-
(T t) -> (R r) -
apply추상 메서드를 정의 -
입력을 출력으로 매핑하는 뉘앙스
-
public class FunctionExample {
public static void main(String[] args) {
List<Integer> mapped = map(
List.of("lambdas", "in", "actions"),
s -> s.length()
);
System.out.println(mapped);
}
public static <T, R> List<R> map(List<T> list, Function<T, R> f) {
List<R> result = new ArrayList<>();
for (T t : list) {
result.add(f.apply(t)); // 전달받은 람다를 실행
}
return result;
}
}-
기본형 특화 함수형 인터페이스
-
제네릭 파라미터에는 참조형만 사용할 수 있다.
- 기본형 값이 파라미터로 전달되면, 오토박싱이 발생한다.
-
박싱 (기본형 ➜ 참조형) 은 비용이 든다.
-
박싱한 값은 힙에 저장되므로, 메모리를 소비한다.
-
값을 가져올 때, 메모리를 탐색하는 과정이 추가로 필요하다.
-
-
이러한 오토 박싱을 막기 위해 기본형을 입출력으로 사용하는, 함수형 인터페이스가 존재한다.
-
IntPredicate,DoublePredicate,IntConsumer,IntFunction등이 있다.
-
기본 제공된 함수형 인터페이스 목록: https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/function/package-summary.html
형식 검사
-
람다 표현식 자체에는 람다가 어떤 함수형 인터페이스를 구현하는지의 정보가 없다.
- 람다의 시그니처와 메서드의 함수 디스크립터를 비교하여 현재 메서드의 파라미터로 올바른 동작이 전달되었는지 검사한다.
filter(inventory, (Apple a) -> a.getWeight() > 150); // 람다 전달
filter(List<Apple> inventory, Predicate<Apple> p) // 메서드 시그니처
- 메서드 시그니처의
Predicate<Apple> p는Apple -> boolean함수 디스크립터를 갖는다.- 람다 시그니처는
Apple -> boolean으로 메서드의 함수 디스크립터와 일치한다.- 따라서 형식검사가 성공적으로 완료된다.
- 동일한 함수 디스크립터를 갖는 메서드가 오버로딩된 경우엔 컴파일이 불가능하다.
public class TargetTypingExample {
public static void main(String[] args) {
execute(() -> System.out.println("ho")); // java: reference to execute is ambiguous, 컴파일 불가
execute((Walker) () -> System.out.println("ho")); // 컴파일 가능
execute((Runner) () -> System.out.println("ho")); // 컴파일 가능
}
public static void execute(Walker walker) {
walker.walk();
}
public static void execute(Runner runner) {
runner.run();
}
}
@FunctionalInterface
interface Walker {
void walk();
}
@FunctionalInterface
interface Runner {
void run();
}
execute메서드는 동일한 함수 디스크립터를 갖고, 메서드 오버로딩을 사용했다.- 첫 번째
execute실행의 경우, 어떤 메서드를 실행할 지 몰라 컴파일 에러 발생- 두 번째, 세 번째처럼 타입 캐스팅을 통해 컴파일 에러 해결 가능
람다 내에서의 자유 변수 사용
-
람다식에 파라미터로 넘겨지지 않고 외부에 정의된 지역 변수를 자유 변수라 한다.
-
자유 변수는
final이거나 한번도 변경되지 않아야만 사용할 수 있다.
int freeVariable = 1234;
Runnable r = () -> System.out.println(freeVariable); // 컴파일 에러 발생
freeVariable = 4321;
public Supplier<Integer> incrementer(int start) {
return () -> start++; // 컴파일 에러 발생
}- 인스턴스 변수는 아무런 제약 조건이 없다.
public class VariableExample {
int instanceVariable = 10000;
public Supplier<Integer> incrementer() {
return () -> instanceVariable++;
}
}-
인스턴스 변수는 힙에 저장되기 때문에 멀티쓰레드 환경에서도 람다가 가장 최신의 변수값에 접근할 수 있다.
-
지역 변수는 스택에 저장된다.
-
지역 변수가 존재하는 스레드가 사라져서 변수 할당이 해제되어도 람다는 살아남아 변수를 사용해야 한다.
-
이를 위해 람다는 지역 변수의 복사본을 만들어 사용한다.
- 복사본의 값과 원본 값의 차이가 발생하면 안되므로
final제약 조건이 필요하다.
- 복사본의 값과 원본 값의 차이가 발생하면 안되므로
-
메서드 참조
-
특정 메서드만을 호출하는 람다의 축약형
- 가독성을 높일 수 있다.
-
정적 메서드 참조, 객체의 인스턴스 메서드 참조, 생성자와 같은 특별한 형식의 메서드 참조등이 있다.
-
클래스명::메서드명,객체명::메서드명,클래스명::new와 같은 형식으로 사용한다.- 파라미터와 반환값은 표현에서 생략된다.
public static void main(String[] args) {
List<Apple> inventory = Arrays.asList(
new Apple(80, Color.GREEN),
new Apple(155, Color.GREEN),
new Apple(120, Color.RED)
);
// inventory.sort(Comparator.comparing(apple -> apple.getWeight())); // 람다 표현
inventory.sort(Comparator.comparing(Apple::getWeight)); // 메서드 참조 표현
// [Apple{color=GREEN, weight=80}, Apple{color=RED, weight=120}, Apple{color=GREEN, weight=155}]
System.out.println(inventory);
}기본 제공되는 함수형 인터페이스의 유틸리티 메서드
-
Comparator, Function, Predicate와 같은 함수형 인터페이스는 유틸리티 메서드를 제공한다.-
default method를 사용하여 함수형 인터페이스가 추가적인 메서드를 제공할 수 있다. -
유틸리티 메서드를 이용해 여러개의 람다 표현식을 조합할 수 있다.
-
-
Comparator- 역정렬
inventory.sort(Comparator.comparing(Apple::getWeight).reversed()); // 정렬결과를 역순으로 뒤집는다.
// [Apple{color=GREEN, weight=155}, Apple{color=RED, weight=120}, Apple{color=GREEN, weight=80}]
System.out.println(inventory);- 정렬 조건 추가
inventory.sort(Comparator.comparing(Apple::getWeight)
.reversed() // 무게를 내림차순으로 정렬
.thenComparing(Apple::getName)); // 두 사과의 무게가 같으면 이름순으로 오름차순 정렬
.thenComparing(차순위 정렬조건)을 통해 정렬조건을 추가할 수 있다.
-
Predicate조합- 단순한 람다 표현식의 조합으로 복잡한 람다 표현식을 만들 수 있다.
Predicate<Apple> redApple = apple -> apple.getColor() == Color.RED;
Predicate<Apple> notRedApple = redApple.negate();
Predicate<Apple> redAndHeavyApple = redApple.and(apple -> apple.getWeight() > 150);
Predicate<Apple> redAndHeavyAppleOrGreen = redApple.and(apple -> apple.getWeight() > 150)
.or(apple -> apple.getColor() == Color.GREEN);
.negate()로 특정Predicate반전.and(Predicate)로 두 개 이상의Predicate를 AND 로 연결.or(Predicate)로 두 개 이상의Predicate를 OR 로 연결
Function조합
Function<Integer, Integer> f = x -> x + 1;
Function<Integer, Integer> g = x -> x * 2;
Function<Integer, Integer> h = f.andThen(g); // f -> g
System.out.println(h.apply(1)); // 4
Function<Integer, Integer> i = f.compose(g); // f(g(x)), g -> f
System.out.println(i.apply(1)); // 3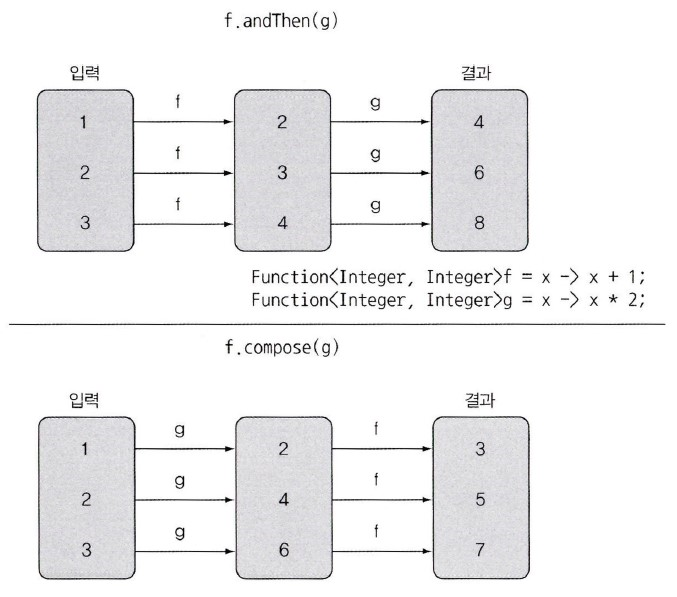
스트림 소개
-
데이터를 그룹화하고 처리하는데 사용하는 컬렉션은 두가지 한계점이 있다.
-
데이터를 처리, 가공할 때 가독성이 떨어진다.
-
병렬 처리 코드의 구현이 어렵다.
-
-
이러한 한계점을 극복하기 위해 자바8에 스트림 (Streams) API 가 추가되었다.
스트림의 정의
-
데이터 처리 연산을 지원하도록 소스에서 추출된 연속된 요소
- 데이터 소스에 적용할 수 있는 다양한 데이터 처리 연산 제공
-
대부분의 스트림 연산의 결과는 스트림 타입을 반환한다.
- 스트림 연산끼리 연결해 커다란 파이프라인을 구성할 수 있다.
-
내부 반복을 지원한다.
public static List<String> getLowCaloricDishesNamesInJava7(List<Dish> dishes) {
ArrayList<Dish> lowCaloricDishes = new ArrayList<>();
for (Dish dish : dishes) {
if (dish.getCalories() < 400) {
lowCaloricDishes.add(dish);
}
}
ArrayList<String> lowCaloricDishesName = new ArrayList<>();
Collections.sort(lowCaloricDishes, new Comparator<Dish>() {
@Override
public int compare(Dish d1, Dish d2) {
return Integer.compare(d1.getCalories(), d2.getCalories());
}
});
for (Dish dish : lowCaloricDishes) {
lowCaloricDishesName.add(dish.getName());
}
return lowCaloricDishesName;
}
public static List<String> getLowCaloricDishesNamesInJava8(List<Dish> dishes) {
return dishes.stream()
.filter(dish -> dish.getCalories() < 400)
.sorted(Comparator.comparing(Dish::getCalories))
.map(Dish::getName)
.collect(Collectors.toList());
}
- 요리 리스트에서 저칼로리 식단을 정렬한 후, 이름을 뽑아오는 예제
getLowCaloricDishesNamesInJava7(List<Dish> dishes)는 고전적인 방식getLowCaloricDishesNamesInJava8(List<Dish> dishes)는 스트림을 이용한 방식
스트림 API의 특징
-
선언형
- 간결하고 가독성이 좋다.
-
조립할 수 있음
- 유연성이 좋다.
-
병렬화
- 성능에 좋다.
컬렉션 vs 스트림
-
컬렉션은 DVD이고, 스트림은 인터넷 스트리밍이다.
-
DVD (컬렉션) 은 전체 영화가 저장되어 있다.
-
인터넷 스트리밍 (스트림) 은 비디오를 재생할 때 사용자가 시청하는 부분의 몇 프레임을 미리 내려 받는다.
-
다른 대부분의 값은 아직 처리하지 않았다.
-
모든 프레임을 저장할 수 없다.
-
-
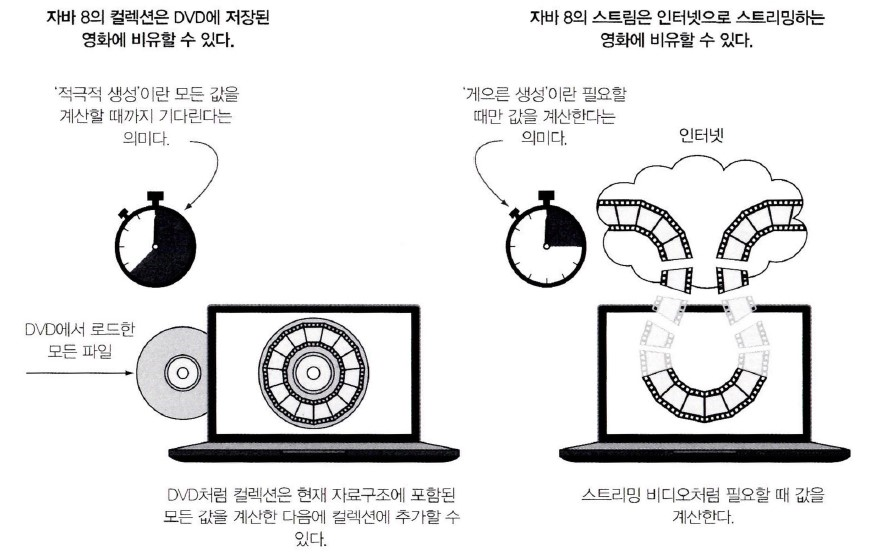
-
스트림은 딱 한번만 탐색할 수 있다.
-
컬렉션은 사용자가 직접
for문 등으로 요소를 반복해야 한다.- 외부 반복
-
반면 스트림은 반복을 알아서 처리한다.
-
내부 반복
-
스트림이 스스로 최적화를 수행한다.
-
스트림 연산
-
스트림 연산은 크게 두 가지로 구분한다.
-
중간 연산
-
스트림을 반환하므로 연결할 수 있다.
-
스트림 파이프라인을 만든다.
-
최종 연산을 연결하기 전까지는 아무런 연산도 수행하지 않는다. (게으르다)
-
filter,map,limit,sorted,distinct등이 있다.
-
-
최종 연산
-
스트림을 닫는 연산으로 연결할 수 없다.
-
스트림 파이프라인을 실행하고 결과를 만들어 반환한다.
-
forEach,count,collect등이 있다.
-
-
스트림 활용
필터링
-
.filter(Predicate)Predicate를 인수로 전달하여 일치하는 요소들만 걸러낸 스트림 생성
Stream<Dish> vegetarianMenuStream = menu.stream()
.filter(Dish::isVegetarian);-
.distinct()- 중복을 걸러낸 스트림 생성
List<Integer> numbers = List.of(1, 1, 2, 2, 3, 3, 4);
Stream<Integer> distinctStream = numbers.stream()
.distinct();슬라이싱
-
.takeWhile(Predicate)-
Predicate를 불만족하면 반복작업을 중단하고 현재 작업 지점까지의 요소들을 스트림으로 반환 -
이후 남은 요소들에 대해 작업 수행 X
-
Stream<Dish> slicedMenu1 = menu.stream()
.takeWhile(dish -> dish.getCalories() < 320);-
.dropWhile(Predicate)-
Predicate를 불만족하면 반복작업을 중단하고 현재 작업 지점까지의 요소들을 모두 버리고 나머지 요소들을 스트림으로 반환 -
남은 요소들에 대해 작업 수행 X
-
Stream<Dish> slicedMenu2 = menu.stream()
.dropWhile(dish -> dish.getCalories() < 320);-
.limit(n)n개 이하의 요소를 갖는 스트림을 반환
Stream<Dish> limitedMenu = menu.stream()
.limit(3);-
.skip(n)- 처음
n개의 요소를 제외한 스트림을 반환
- 처음
Stream<Dish> skippedMenu = menu.stream()
.skip(3);매핑
-
.map(Function)- 각 요소에 변환 함수를 적용한 결과가 새로운 요소가 된다.
Stream<Integer> mappedNameLength = menu.stream()
.map(Dish::getName)
.map(String::length);
Dish객체 ➜Dish객체의 이름 ➜ 이름의 길이 로 각 요소들을 변환- Chaining 할 수 있다.
-
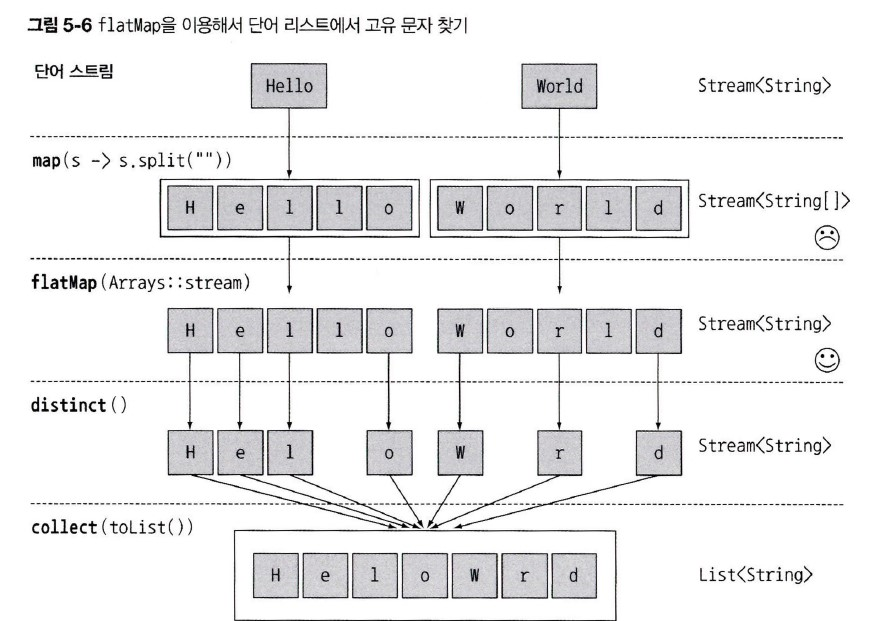
.flatMap(Function)-
변환 함수를 적용해서 생성된 각각의 스트림에서 콘텐츠만 남긴다.
map(Function)의 경우 각각의 스트림의 스트림이 만들어진다.
-
해당 콘텐츠들만 모아서 하나의 스트림으로 평면화한다.
-
{"Hello", "World"}➜{'H', 'e', 'l', 'o', 'W', 'r', 'd'}로 만들고 싶은 경우
-
List<String[]> collect = words.stream()
.map(word -> word.split(""))
.distinct()
.collect(Collectors.toList());
map의 결과는String배열 스트림이다.- 이 방식으로는 목적을 이룰 수 없다.
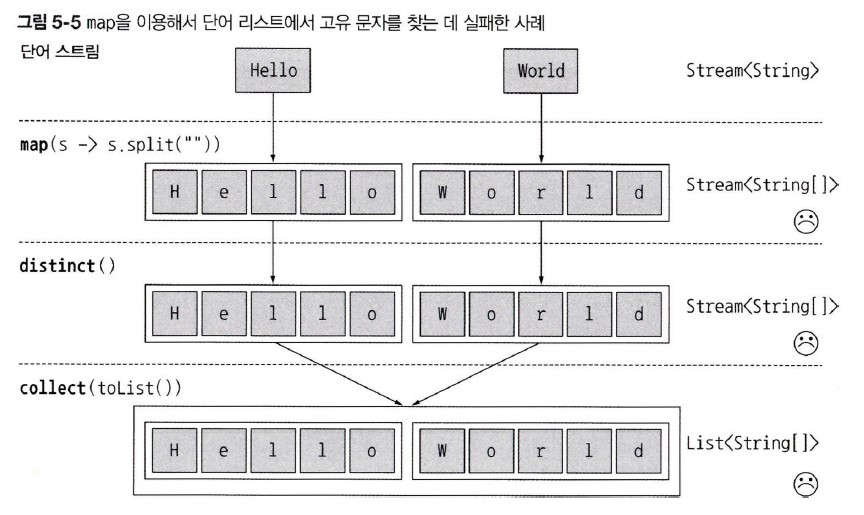
List<String> wanted = words.stream()
.map(word -> word.split(""))
.flatMap(array -> Arrays.stream(array)) // 각 배열을 각 스트림으로 변환하고, 하나의 스트림으로 합친다.
.distinct()
.collect(Collectors.toList());
flatMap의 결과는 하나로 평탄화된 스트림이다.- 이 방식으로 목적을 이룰 수 있다.
검색과 매칭
-
.anyMatch(Predicate)- 주어진 스트림에서 하나의 요소라도
Predicate를 만족하는 것이 있으면 true 반환
- 주어진 스트림에서 하나의 요소라도
if (menu.stream().anyMatch(Dish::isVegetarian)) {
// ...
}-
.allMatch(Predicate)- 주어진 스트림에서 모든 요소가
Predicate를 만족하면 true 반환
- 주어진 스트림에서 모든 요소가
if (menu.stream().allMatch(dish -> dish.getCalories() < 1000)) {
// ...
}-
.noneMatch(Predicate)- 주어진 스트림에서 모든 요소가
Predicate를 만족하지 않는다면 true 반환
- 주어진 스트림에서 모든 요소가
if (menu.stream().noneMatch(dish -> dish.getCalories() >= 1000)) {
// ...
}-
.findAny()-
임의의 요소 1개를 반환한다.
-
병렬 실행 시 제약이 적다.
-
Optional<Dish> any = menu.stream()
.findAny();-
.findFirst()-
스트림의 첫 번째 요소를 반환한다.
-
병렬 실행 시 첫 번째 요소를 찾기 어렵다.
-
Optional<Dish> first = menu.stream()
.findFirst();-
allMatch,noneMatch,findFirst,findAny,limit메서드들은 단락 평가 (쇼트 서킷) 를 수행한다.-
and 연산과 or 연산의 수행 방식과 유사하다.
-
결과가 이미 결정되면 나머지 요소들을 검사하지 않고 즉시 결과를 반환한다.
-
리듀싱
-
모든 스트림 요소를 처리해서 하나의 값으로 도출하는 연산
-
.reduce(초기값, BinaryOperator<T>)로 이루어진다.BinaryOperator<T>는 두 요소를 조합해서 새로운 값을 만든다.
- 모든 요소의 합
Integer total = numbers.stream()
.reduce(0, (sum, cur) -> sum + cur);
reduce(0, Integer::sum)으로 간소화할 수 있다.- 초기값을 설정하지 않으면
Optional객체를 반환한다.
- 스트림에 아무 요소도 없는 상황을 대비한다.
- 최대값, 최소값 찾기
Optional<Integer> maximum = numbers.stream()
.reduce((max, cur) -> Integer.max(max, cur));
Optional<Integer> minimum = numbers.stream()
.reduce((min, cur) -> Integer.min(min, cur));스트림 연산의 종류
-
내부 상태를 갖지 않는 연산
-
특별히 기억해야할 상태가 없다.
-
map,filter등
-
-
한정된 내부 상태를 갖는 연산
-
결과를 누적할 작은 크기의 내부 상태가 필요하다.
-
reduce,sum,max등
-
-
크기가 정해지지 않은 내부 상태를 갖는 연산
-
과거의 이력을 알고 있어야 한다.
- 모든 요소가 버퍼에 추가되어 있어야 한다.
-
데이터 스트림의 크기가 무한이라면 문제가 발생한다.
-
sorted,distinct등
-
기본형 특화 (숫자) 스트림
menu.stream()
.map(Dish::getCalories) // Stream<Integer>
.sum(); // 컴파일 에러
int calories = menu.stream()
.mapToInt(Dish::getCalories) // Stream<Integer> -> IntStream
.sum();
Stream<T>인터페이스는sum메서드가 없다.IntStream인터페이스는sum메서드를 지원한다.
-
박싱 비용을 피하고 숫자 스트림을 효율적으로 처리할 수 있도록 기본형 특화 스트림을 제공한다.
-
IntStream,DoubleStream,LongStream이 있다.-
.mapToInt(Function),mapToDouble(Function),mapToLong(Function)메서드를 사용해Stream<T>를 기본형 특화 스트림으로 반환한다. -
sum,max,min,average와 같은 자주 사용하는 유틸리티 메서드를 제공한다.max,min,average의 경우OptionalInt,OptionalDouble을 반환한다.
-
기본형 특화 스트림을 객체 스트림으로 복원하는 기능도 제공한다.
.boxed()메서드 사용
-
-
특정 범위의 숫자 생성
IntStream,LongStream의.range(시작, 끝),.rangeClosed(시작, 끝)메서드로 만들 수 있다.
IntStream.range(1, 5)
.forEach(System.out::print); // 1234
IntStream.rangeClosed(1, 5)
.forEach(System.out::print); // 12345무한 스트림 (unbounded stream)
-
크기가 고정되지 않은 스트림을 만들 수 있다.
-
.iterate(초기값, UnaryOperator<T>)-
람다를 만족하는 새로운 값을 끊임없이 생산
-
limit(n)메서드를 이용해 크기를 제한하여 사용해야 한다.
-
Stream.iterate(0, n -> n + 2)
.limit(5)
.forEach(System.out::print); // 02468-
.generate(Supplier<T>)-
람다를 실행하여 새로운 값을 끊임없이 생산
-
limit(n)메서드를 이용해 크기를 제한하여 사용해야 한다.
-
Stream.generate(() -> 1)
.limit(5)
.forEach(System.out::print); // 11111스트림 API: https://docs.oracle.com/en/java/javase/19/docs/api/java.base/java/util/stream/Stream.html
스트림으로 데이터 수집
-
collect최종 연산을 사용해 다양한 최종 결과를 도출할 수 있다.- 내부적으로 리듀싱 연산이 일어난다.
-
reduce연산으로도 동일한 작업을 수행할 수 있지만 가독성이 떨어진다.
private static Map<Currency, List<Transaction>> groupImperatively() {
Map<Currency, List<Transaction>> transactionsByCurrencies = new HashMap<>();
for (Transaction transaction : transactions) {
Currency currency = transaction.getCurrency();
List<Transaction> transactionsForCurrency = transactionsByCurrencies.get(currency);
if (transactionsForCurrency == null) {
transactionsForCurrency = new ArrayList<>();
transactionsByCurrencies.put(currency, transactionsForCurrency);
}
transactionsForCurrency.add(transaction);
}
return transactionsByCurrencies;
}명령형 버전의 통화별로 트랜잭션을 그룹화하는 코드
private static Map<Currency, List<Transaction>> groupFunctionality() {
return transactions.stream()
.collect(Collectors.groupingBy(Transaction::getCurrency));
}
collect를 사용해 통화별로 트랜잭션을 그룹화하는 코드- 더욱 간결하고 가독성 있게 표현한다.
컬렉터
-
.collect(Collector 인터페이스 구현)으로 원하는 스트림 결과물을 만든다.-
함수형 프로그래밍에서는 무엇을 원하는지만 명시한다.
-
어떤 방식으로 만들지는 신경쓸 필요없다.
-
Collectors 유틸리티 클래스
-
자주 사용하는
Collector인스턴스를 손쉽게 생성할 수 있는 정적 팩토리 메서드를 제공한다. -
Collectors.toList()- 스트림의 모든 요소를 리스트로 수집한다.
-
Collectors.counting()- 스트림의 모든 요소 개수를 계산한다.
private static long calculateTotalCount() {
return Dish.menu.stream().collect(Collectors.counting());
}-
Collectors.summarizingInt(mapper)-
개수, 합계, 최대, 최소, 평균 정보를 수집하여 반환한다.
-
long, double 에 대응하는
summarizingLong(mapper),summarizingDouble(mapper)도 있다.
-
private static IntSummaryStatistics calculateMenuStatistics() {
return menu.stream().collect(Collectors.summarizingInt(Dish::getCalories));
}
public static void main(String[] args) {
System.out.println("통계: " + calculateMenuStatistics());
// 통계: IntSummaryStatistics{count=9, sum=4300, min=120, average=477.777778, max=800}
}-
Collectors.joining(구분자)- 스트림의 각 객체의
toString메서드를 호출해 추출한 모든 문자열을 하나의 문자열로 연결해서 반환한다.
- 스트림의 각 객체의
private static String getShortMenu() {
return menu.stream().map(Dish::getName).collect(Collectors.joining());
}
private static String getShortMenuCommaSeparated() {
return menu.stream().map(Dish::getName).collect(Collectors.joining(", "));
}
public static void main(String[] args) {
System.out.println(getShortMenu());
// porkbeefchickenfrench friesriceseason fruitpizzaprawnssalmon
System.out.println(getShortMenuCommaSeparated());
// pork, beef, chicken, french fries, rice, season fruit, pizza, prawns, salmon
}구분자를 넣지 않으면 모두 붙어서 출력된다.
-
Collectors.toCollection(컬렉션 supplier)- 스트림 결과물들을 특정 컬렉션 구현체에 담아 반환한다.
List<Integer> numbers = List.of(1, 2, 3, 4, 5);
ArrayList<Integer> collect = numbers.stream()
.collect(Collectors.toCollection(ArrayList::new));그룹화
-
하나 이상의 특성으로 데이터 집합을 분류해서 그룹화 할 수 있다.
-
Collectors.groupingBy(분류함수)-
스트림의 각 요소에 분류함수를 적용해
key를 만든다. -
앞서 만든
key에 매핑되는value는 분류함수 적용 전의 원래 요소이다. -
이렇게 그룹화된
Map을 반환한다.
-
private static Map<Type, List<Dish>> groupDishesByType() {
return menu.stream().collect(Collectors.groupingBy(Dish::getType));
}
private static Map<CaloricLevel, List<Dish>> groupDishesByCalorie() {
return menu.stream().collect(Collectors.groupingBy(dish -> {
if (dish.getCalories() <= 400) return CaloricLevel.DIET;
else if (dish.getCalories() <= 700) return CaloricLevel.NORMAL;
else return CaloricLevel.FAT;
}));
}복잡한 분류 기준이 필요한 경우
groupDishesByCalorie()메서드처럼 분류함수를 구현하면 된다.
-
Collectors.filtering(Predicate, downstream)-
우선 그룹화를 한 뒤, 그룹의 요소들을 필터링한다.
-
각 그룹별로 스트림이 생성된다.
-
필터링한 요소들을 downstream 에 넣어 반환한다.
-
-
예를 들어, 500 칼로리가 넘는 요리를 타입으로 그룹화하려고 한다.
-
private static Map<Type, List<Dish>> groupCaloricDishesByTypeUsingFilter() {
return menu.stream()
.filter(dish -> dish.getCalories() > 500)
.collect(Collectors.groupingBy(Dish::getType));
}
public static void main(String[] args) {
System.out.println(groupCaloricDishesByTypeUsingFilter());
// {OTHER=[french fries, pizza], MEAT=[pork, beef]}
}
filter메서드를 통해 500 칼로리가 넘는 요리가 제거되어,FISH타입 자체가 그룹에서 사라진다.
private static Map<Type, List<Dish>> groupCaloricDishesByType() {
return menu.stream().collect(Collectors.groupingBy(
Dish::getType,
Collectors.filtering(dish -> dish.getCalories() > 500, Collectors.toList())
));
}
public static void main(String[] args) {
System.out.println(groupCaloricDishesByType());
// {OTHER=[french fries, pizza], MEAT=[pork, beef], FISH=[]}
}
Collectors.groupingBy의 두 번째 파라미터로Collectors.filtering을 넘길 수 있다.- 이 경우 그룹화된 요소들을 필터링해 재그룹화 한다.
- 비어있는
FISH타입을 그룹에서 확인할 수 있다.
Collectors.mapping(mapper, downstream)-
우선 그룹화를 한 뒤, 그룹의 요소들을 변환한다.
-
각 그룹별로 스트림이 생성된다.
-
변환한 요소들을 downstream에 넣어 반환한다.
-
-
private static Map<Type, List<String>> groupDishNamesByType() {
return menu.stream().collect(Collectors.groupingBy(
Dish::getType,
Collectors.mapping(Dish::getName, Collectors.toList()) // List<Dish> -> List<String>
));
}Collectors.flatMapping(mapper, downstream)-
우선 그룹화를 한 뒤, 각 그룹내의 요소들을 변환한다.
-
각 그룹별로 그룹 스트림이 생성된다.
-
각 그룹내의 요소들의 변환 결과물이 스트림일 경우
-
그룹별로 변환된 요소들(스트림) 을 하나의 그룹 스트림으로 묶어 평탄화한다.
-
평탄화한 요소들을 downstream 에 넣어 반환한다.
-
-
private static Map<Type, Set<String>> groupDishTagsByType() {
Map<String, List<String>> dishTags = Map.of(
"pork", List.of("greasy", "salty"),
"beef", List.of("salty", "roasted"),
"chicken", List.of("fried", "crisp"),
"french fries", List.of("greasy", "fried"),
"rice", List.of("light", "natural"),
"season fruit", List.of("fresh", "natural"),
"pizza", List.of("tasty", "salty"),
"prawns", List.of("tasty", "roasted"),
"salmon", List.of("delicious", "fresh"));
return menu.stream().collect(Collectors.groupingBy(
Dish::getType,
Collectors.flatMapping(dish -> dishTags.get(dish.getName()).stream(), Collectors.toSet())
));
}
public static void main(String[] args) {
System.out.println(groupDishTagsByType());
// {OTHER=[salty, greasy, natural, light, tasty, fresh, fried],
// MEAT=[salty, greasy, roasted, fried, crisp],
// FISH=[roasted, tasty, fresh, delicious]}
}Collectors.groupingBy(분류함수, downstream)
downstream으로Collectors.groupingBy(...)를 사용하여 다수준으로 그룹화할 수 있다.
private static Map<Type, Map<CaloricLevel, List<Dish>>> groupDishByTypeAndCaloricLevel() {
return menu.stream().collect(Collectors.groupingBy(
Dish::getType, // 첫 번째 수준의 분류 함수
Collectors.groupingBy(dish -> { // 두 번재 수준의 분류 함수
if (dish.getCalories() <= 400) return CaloricLevel.DIET;
else if (dish.getCalories() <= 700) return CaloricLevel.NORMAL;
else return CaloricLevel.FAT;
})
));
}
public static void main(String[] args) {
System.out.println(groupDishByTypeAndCaloricLevel());
// {
// OTHER={NORMAL=[french fries, pizza], DIET=[rice, season fruit]},
// MEAT={NORMAL=[beef], DIET=[chicken], FAT=[pork]},
// FISH={NORMAL=[salmon], DIET=[prawns]}
// }
}
- 외부맵은 첫 번째 수준의 분류함수에서 분류한
key값FISH, MEAT, OTHER를 갖는다.- 내부맵은 두 번째 수준의 분류함수에서 분류한
key값NORMAL, DIET, FAT을 갖는다.
downstream으로Collectors.counting()을 사용하여 그룹별로 개수를 계산할 수 있다.
private static Map<Type, Long> countDishesInGroups() {
return menu.stream().collect(Collectors.groupingBy(
Dish::getType,
Collectors.counting()
));
}
public static void main(String[] args) {
System.out.println(countDishesInGroups());
// {OTHER=4, MEAT=3, FISH=2}
}downstream으로Collectors.maxBy(Comparator),Collectors.minBy(Comparator)를 사용해 각 그룹에서의 최대, 최소를 구할 수 있다.
private static Map<Type, Optional<Dish>> mostCaloricDishesByType() {
return menu.stream().collect(Collectors.groupingBy(
Dish::getType,
Collectors.maxBy(Comparator.comparingInt(Dish::getCalories))
));
}
public static void main(String[] args) {
System.out.println(mostCaloricDishesByType());
// {OTHER=Optional[pizza], MEAT=Optional[pork], FISH=Optional[salmon]}
}
Collectors.maxBy의 결과가Optional이므로, 출력 결과도 다음과 같다.
private static Map<Type, Dish> mostCaloricDishesByTypeWithoutOptionals() {
return menu.stream().collect(Collectors.groupingBy(
Dish::getType,
Collectors.collectingAndThen( // 컬렉터가 반환한 결과를 변환한다.
Collectors.maxBy(Comparator.comparingInt(Dish::getCalories)),
Optional::get
)
));
}
public static void main(String[] args) {
System.out.println(mostCaloricDishesByTypeWithoutOptionals());
// {OTHER=pizza, MEAT=pork, FISH=salmon}
}
Collectors.collectingAndThen은 컬렉터와 변환 함수를 파라미터로 받는다.
- 컬렉터의 각 요소들에 변환함수를 적용한, 새로운 컬렉터를 반환한다.
- 이를 통해
Optional을 제거할 수도 있다.
downstream으로Collectors.summingInt(mapper),Collectors.summingLong(mapper),Collectors.summingDouble(mapper)를 사용해 각 그룹에서의 총 합계를 구할 수 있다.
private static Map<Type, Integer> sumCaloriesByType() {
return menu.stream().collect(Collectors.groupingBy(
Dish::getType,
Collectors.summingInt(Dish::getCalories)
));
}
public static void main(String[] args) {
System.out.println(sumCaloriesByType());
// {OTHER=1550, MEAT=1900, FISH=850}
}분할
-
Predicate를 분류함수로 사용하는 특수한 그룹화 -
맵의
key형식은Boolean으로 최대 두 개의 그룹으로 분류된다. -
Collectors.partitioningBy(Predicate)
private static Map<Boolean, List<Dish>> partitionByVegetarian() {
return menu.stream().collect(Collectors.partitioningBy(Dish::isVegetarian));
}
public static void main(String[] args) {
System.out.println(partitionByVegetarian());
// {false=[pork, beef, chicken, prawns, salmon],
// true=[french fries, rice, season fruit, pizza]}
} private static Map<Boolean, Dish> mostCaloricPartitionedByVegetarian() {
return menu.stream().collect(Collectors.partitioningBy(
Dish::isVegetarian,
Collectors.collectingAndThen(
Collectors.maxBy(Comparator.comparingInt(Dish::getCalories)),
Optional::get
)
));
}
public static void main(String[] args) {
System.out.println(mostCaloricPartitionedByVegetarian());
// {false=pork, true=pizza}
}그룹화함수와 유사하게 사용가능하다.
커스텀 컬렉터 만들기
-
Collector인터페이스를 구현하여 직접 커스텀 컬렉터를 만들 수 있다. -
예를 들어, 소수를 찾아 분할하는 커스텀 컬렉터를 만들 수 있다.
public class PrimeNumbersCollector
implements Collector<Integer, Map<Boolean, List<Integer>>, Map<Boolean, List<Integer>>> {
// 수집될 항목, 중간 결과 누적자, 최종 연산 결과
@Override
public Supplier<Map<Boolean, List<Integer>>> supplier() { // 비어있는 컨테이너 만들기
return () -> new HashMap<>() {{
put(true, new ArrayList<Integer>());
put(false, new ArrayList<Integer>());
}};
}
@Override
public BiConsumer<Map<Boolean, List<Integer>>, Integer> accumulator() { // 누적자 컨테이너에 요소 추가하기
return (accumulator, candidate) -> {
List<Integer> primes = accumulator.get(true);
accumulator.get(isPrime(primes, candidate))
.add(candidate);
};
}
@Override
public BinaryOperator<Map<Boolean, List<Integer>>> combiner() { // 누적자 컨테이너들을 병합 (병렬 스트림의 경우 해당)
/* return (map1, map2) -> {
map1.get(true).addAll(map2.get(true));
map1.get(false).addAll(map2.get(false));
return map1;
};
*/ // 알고리즘이 순차적이기 때문에 실제 병렬로 사용할 수 없다.
return null;
}
@Override
public Function<Map<Boolean, List<Integer>>, Map<Boolean, List<Integer>>> finisher() { // 누적자 컨테이너를 최종 결과 컨테이너로 변환
return Function.identity();
}
/**
* 스트림을 병렬로 리듀스할 수 있는지,
* 스트림에 어떤 최적화를 할 수 있는지 힌트를 제공한다.
*
* UNORDERED: 리듀싱 결과는 스트림 요소의 방문 순서나 누적 순서에 영향을 받지 않는다.
* CONCURRENT: 다중 스레드에서 accumulator 함수를 동시에 호출할 수 있으며, 병렬 리듀싱을 수행할 수 있다.
* IDENTITY_FINISH: finisher 메서드가 반환하는 함수는 단순히 identity 적용이므로, 이를 생략할 수 있다.
*/
@Override
public Set<Characteristics> characteristics() {
return Collections.unmodifiableSet(EnumSet.of(Characteristics.IDENTITY_FINISH));
}
private static boolean isPrime(List<Integer> primes, Integer candidate) {
double candidateRoot = Math.sqrt(candidate);
return primes.stream()
.takeWhile(i -> i <= candidateRoot)
.noneMatch(i -> candidate % i == 0);
}
}소수를 찾아 분할하여 반환하는
PrimeNumbersCollector커스텀 컬렉터
public static Map<Boolean, List<Integer>> partitionPrimesWithCustomCollector(int n) {
return IntStream.rangeClosed(2, n).boxed()
.collect(new PrimeNumbersCollector());
}
public static void main(String[] args) {
System.out.println(partitionPrimesWithCustomCollector(10));
// {false=[4, 6, 8, 9, 10], true=[2, 3, 5, 7]}
}
.collect(new PrimeNumbersCollector())와 같이 커스텀 컬렉터 구현체를 넣어준다.
Collectors 클래스 API: https://docs.oracle.com/en/java/javase/19/docs/api/java.base/java/util/stream/Collectors.html
병렬 데이터 처리와 성능
- 스트림을 이용하면 데이터를 쉽게 병렬로 처리할 수 있다.
병렬 스트림
-
.parallel()을 통해 순차 스트림을 병렬 스트림으로 변환할 수 있다..sequential()로 병렬 스트림을 순차 스트림으로 변환할 수 있다.
-
여러개의 스레드에서 데이터를 처리할 수 있도록 스트림 요소를 여러 청크로 분할한 스트림이다.
- 모든 멀티코어 프로세서가 각각의 청크를 처리할 수 있다.
-
병렬 스트림이 순차 스트림이나 고전적인 반복 형식에 비해 무조건적으로 성능이 좋지는 않다.
- 항상 측정을 통해 비교해야 한다.
병렬 스트림 성능 측정 - 절망편
- 1부터 1000만까지의 숫자를 더하는 예제를 통해 고전적인 반복, 순차 스트림, 병렬 스트림의 성능을 비교한다.
public static long iterativeSum(long n) {
long result = 0;
for (long i = 0; i <= n; i++) {
result += i;
}
return result;
}
- 고전적인 반복 방식
- 2960 msecs 소요
public static long sequentialSum(long n) {
return Stream.iterate(1L, i -> i + 1)
.limit(n)
.reduce(0L, (sum, add) -> sum + add);
}
- 순차 스트림 사용
- 79371 msecs 소요
public static long parallelSum(long n) {
return Stream.iterate(1L, i -> i + 1)
.limit(n)
.parallel()
.reduce(0L, (sum, add) -> sum + add);
}
- 병렬 스트림 사용
- 135078 msecs 소요
- 병렬 버전이 멀티 코어 CPU를 활용하지 못하고 순차 버전보다 나쁜 성능을 보여준다.
병렬 스트림 성능 측정 - 희망편
-
2가지 문제점에 의해 병렬 버전이 나쁜 성능을 갖게 된다.
-
반복 결과로 박싱된 객체가 만들어지므로 숫자를 더하려면 언박싱을 해야 한다.
-
Stream.iterate같은 반복 작업은 병렬로 수행할 수 있는 독립 단위로 나누기 어렵다.iterate는 본질적으로 순차적이다.
- 스레드를 할당하는 오버헤드만 발생한다.
-
-
더욱 특화된
LongStream.rangeClosed메서드를 사용해 2가지 문제점을 해결한다.-
기본형
long을 직접 사용해 박싱 & 언박싱 오버헤드가 사라진다. -
쉽게 청크로 분할할 수 있는 숫자 범위를 생산한다.
-
public static long rangedSum(long n) {
return LongStream.rangeClosed(1, n)
.reduce(0L, (sum, add) -> sum + add);
}
LongStream.rangeClosed를 사용한 순차 스트림- 2966 msecs
public static long parallelRangedSum(long n) {
return LongStream.rangeClosed(1, n)
.parallel()
.reduce(0L, (sum, add) -> sum + add);
}
LongStream.rangeClosed를 사용한 병렬 스트림- 990 msecs
- 순차 실행, 고전적인 반복 방식보다 빠른 병렬 리듀싱을 만들었다.
병렬 스트림의 올바른 사용법
-
멀티 코어 간의 데이터 이동 비용은 생각보다 비싸다.
-
따라서 코어 간 데이터 전송 시간보다 훨씬 오래걸리는 작업만 병렬로 수행해야 한다.
-
소량의 데이터에서는 비효율적이다.
-
-
공유된 상태를 바꾸는 알고리즘은 병렬 스트림 사용 시 제대로 동작하지 않는다.
- 부작용이 없는 알고리즘을 사용해야 한다.
public class Accumulator {
private long total = 0;
public void add(long value) {
total += value;
}
public long getTotal() {
return total;
}
}상태를 갖는 누적자 클래스
public static long sideEffectSum(long n) {
Accumulator accumulator = new Accumulator();
LongStream.rangeClosed(1, n)
.forEach(accumulator::add);
return accumulator.getTotal();
}
- 순차 스트림 사용
- 2967 msecs 소요
- 50000005000000 결과 반환
public static long sideEffectParallelSum(long n) {
Accumulator accumulator = new Accumulator();
LongStream.rangeClosed(1, n)
.parallel()
.forEach(accumulator::add);
return accumulator.getTotal();
}
- 병렬 스트림 사용
- 787 msecs 소요
- 17020621348761 결과 반환
- 다수의 스레드에서 동시에 데이터에 접근하는 데이터 레이스 문제가 발생한다.
total += value는atomic연산이 아니다.
-
limit나findFirst처럼 요소의 순서에 의존하는 연산은 순차 스트림보다 병렬 스트림에서 성능이 떨어진다.-
findAny()를 사용하거나 -
순서가 상관없다면
.unordered()를 먼저 호출한 뒤 순서에 의존하는 연산을 사용하여 성능을 높일 수 있다.
-
public static long findFirst(long n) {
return LongStream.rangeClosed(1, n)
.parallel()
.findFirst()
.getAsLong(); // 느리다.
}
public static long findAny(long n) {
return LongStream.rangeClosed(1, n)
.parallel()
.findAny()
.getAsLong(); // 상대적으로 빠르다.
}
public static long findUnorderedFirst(long n) {
return LongStream.rangeClosed(1, n)
.parallel()
.unordered()
.findFirst()
.getAsLong(); // 상대적으로 빠르다.
}- 병렬 스트림에 효율적인 자료 구조를 사용한다.
-
LinkedList보다ArrayList를 효율적으로 분할할 수 있다.-
LinkedList는 분할하기 위해 모든 요소를 탐색해야 한다. -
ArrayList는 모든 요소 탐색없이 분할할 수 있다.
-
-

포크/조인 프레임워크
-
병렬 스트림은 내부적으로 포크/조인 프레임워크를 사용한다.
-
RecursiveTask의 추상 메서드compute()를 구현하여 병렬 처리를 수행한다.-
태스크를 서브 태스크로 분할하려는 로직과
-
각 서브태스크의 결과를 합치는 로직으로 이루어진다.
-

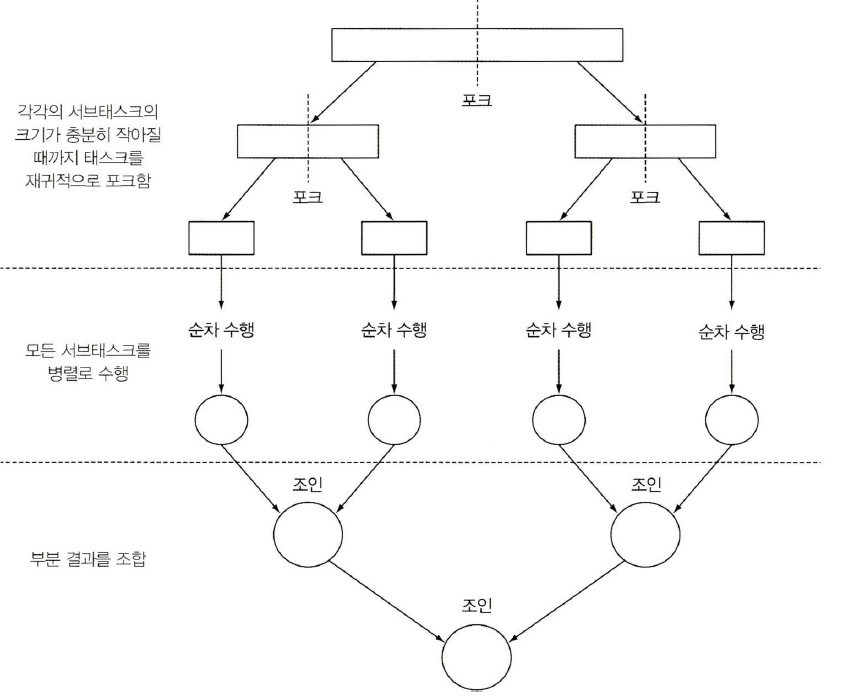
포크/조인 프레임워크 예제
- 1부터 1000만 까지의 숫자를 더하는 예제 코드를 작성
public class ForkJoinSumCalculator extends RecursiveTask<Long> {
// RecursiveTask<R> 을 상속하여 스레드 풀을 이용한다.
private static final long THRESHOLD = 10_000;
private final long[] numbers;
private final int start;
private final int end;
public ForkJoinSumCalculator(long[] numbers) {
this(numbers, 0, numbers.length);
}
public ForkJoinSumCalculator(long[] numbers, int start, int end) {
this.numbers = numbers;
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
int length = end - start;
if (length <= THRESHOLD) { // 서브 태스크가 작아지면, 더 이상 쪼개지 않고 순차 실행
return computeSequentially();
}
ForkJoinSumCalculator leftTask = new ForkJoinSumCalculator(numbers, start, start + length / 2);
leftTask.fork(); // ForkJoinPool 의 다른 스레드로 비동기 실행
ForkJoinSumCalculator rightTask = new ForkJoinSumCalculator(numbers, start + length / 2, end);
Long rightResult = rightTask.compute(); // 현재 스레드로 동기 실행
Long leftResult = leftTask.join(); // 왼쪽 서브 태스크의 결과를 읽어온다. (없으면 기다림)
return leftResult + rightResult; // 왼쪽, 오른쪽 서브 태스크의 결과를 합쳐서 반환한다.
}
private long computeSequentially() { // 순차 실행
long sum = 0;
for (int i = start; i < end; i++) {
sum += numbers[i];
}
return sum;
}
}
RecursiveTask<R>의 서브 클래스인ForkJoinSumCalculator- 스레드 풀을 사용할 수 있다.
public class ForkJoinSumRunner {
public static void main(String[] args) {
long result = forkJoinSum(1000_0000L);
System.out.println(result);
}
public static long forkJoinSum(long n) {
long[] numbers = LongStream.rangeClosed(1, n).toArray();
ForkJoinTask<Long> task = new ForkJoinSumCalculator(numbers);
return new ForkJoinPool().invoke(task); // 새로운 ForkJoinPool 을 만들고, invoke 메서드로 task를 전달
}
}
ForkJoinSumCalculator를 실행하는Main클래스forkJoinSum(long n)메서드를 통해 1 ~ n 까지의long배열을 만들고 새로운ForkJoinPool에task를 전달한다.
포크/조인 프레임워크 주의점
-
join메서드는 태스크의 결과를 얻을 때까지 호출자를 블록시킨다.- 따라서 두 서브 태스크가 모두 시작된 다음에
join을 호출해야 병렬성을 누릴 수 있다.
- 따라서 두 서브 태스크가 모두 시작된 다음에
-
ForkJoinPool의invoke메서드는 병렬 계산을 시작할 때 한 번만 사용해야 한다.RecursiveTask내에서invoke메서드를 호출해선 안된다.
-
양쪽 작업 모두
fork를 호출하는 것보단 한 쪽 작업엔compute를 호출하는 것이 효과적이다.-
이를 통해 두 서브 태스크 중 한 서브 태스크는 같은 스레드를 재사용할 수 있다.
-
불필요한 태스크 할당 오버헤드를 제거한다.
-
-
포크/조인 프레임워크를 사용하여 병렬 처리하는 것이 순차 처리보다 무조건적으로 빠르지 않다.
- 따라서 성능 측정이 중요하다.
작업 훔치기
-
가장 효율적인 최소 서브 태스크 크기를 결정하는 것은 경험의 산물이다.
-
이론상으로는 코어 개수만큼 서브 태스크를 분할하면 불필요한 태스크 할당 오버헤드를 줄이고 효율적일 것 같다.
-
그러나 실제 현업에서는 같은 크기로 분할된 서버 태스크가 같은 시간에 종료되지 않는다.
- 예기치 않은 변수가 발생할 수 있다.
-
따라서 작업이 일찍 끝난 스레드는 놀게되어 병렬성이 떨어진다.
-
-
포크/조인 프레임워크는 작업 훔치기를 통해 이러한 문제점을 해결한다.
-
작업이 모두 끝난 스레드는 작업이 쌓여 있는 스레드의 작업을 훔쳐온다.
-
이러한 작업 훔치기를 통해 스레드간 작업 부하를 비슷한 수준으로 유지한다.
-
최소 서브 태스크 크기가 너무 크면 작업 훔치기의 효과를 보지 못한다.
-
이미 실행하고 있는 작업은 훔칠 수 없기 때문이다.
-
따라서 최소 서브 태스크 크기를 작게 나누어야 한다.
-
-
Spliterator 인터페이스
-
Iterator처럼 요소 탐색 기능을 제공한다. -
병렬 작업에 특화되어 있다.
- 예를 들어, 문장에서 단어의 개수를 세서 반환하고 싶을 때
public static int countWordsIteratively(String s) {
int counter = 0;
boolean lastSpace = true;
for (char c : s.toCharArray()) {
if (Character.isWhitespace(c)) {
lastSpace = true;
} else {
if (lastSpace) counter++;
lastSpace = Character.isWhitespace(c);
}
}
return counter;
}
private static final String SENTENCE =
" Nel mezzo del cammin di nostra vita "
+ "mi ritrovai in una selva oscura"
+ " che la dritta via era smarrita ";
public static void main(String[] args) {
System.out.println(countWordsIteratively(SENTENCE)); // 19
}고전적인 방식의 반복
public class WordCounter {
private final int counter;
private final boolean lastSpace;
public WordCounter(int counter, boolean lastSpace) {
this.counter = counter;
this.lastSpace = lastSpace;
}
public WordCounter accumulate(Character c) {
if (Character.isWhitespace(c)) {
return lastSpace ?
this : // 공백이 연속되는 경우
new WordCounter(counter, true); // 단어 다음 공백인 경우, 공백 상태로 변경
} else {
return lastSpace ?
new WordCounter(counter + 1, false) : // 공백 다음 단어가 시작되는 경우, 단어 개수 증가
this; // 단어가 계속 유지되는 경우
}
}
public WordCounter combine(WordCounter wordCounter) {
return new WordCounter(counter + wordCounter.counter, false); // 두 WordCounter의 counter (단어 개수) 를 더한다.
// 합치기만 수행하므로, lastSpace는 아무값이나 상관없다.
}
public int getCounter() {
return counter;
}
}단어 개수를 세기위한 불변 클래스
public static int countWords(String s) {
Stream<Character> stream = IntStream.range(0, s.length())
.mapToObj(i -> s.charAt(i));
WordCounter wordCounter = stream.reduce(new WordCounter(0, true), // identity(초기값)
WordCounter::accumulate, // accumulator
WordCounter::combine); // combiner
return wordCounter.getCounter();
}
private static final String SENTENCE =
" Nel mezzo del cammin di nostra vita "
+ "mi ritrovai in una selva oscura"
+ " che la dritta via era smarrita ";
public static void main(String[] args) {
System.out.println(countWords(SENTENCE)); // 19
}
- 순차 스트림 사용
.reduce(초기값, accumulator, combiner)로 리듀싱할 수 있다.
accumulator는 요소들을 처리하는 방식이다.combiner는 병렬 처리 시, 각각의 스레드에 나뉘어져 있는 스트림들을 합치는 방식이다.
public static int countWordsParallel(String s) {
Stream<Character> stream = IntStream.range(0, s.length())
.mapToObj(i -> s.charAt(i));
WordCounter wordCounter = stream.parallel()
.reduce(new WordCounter(0, true), // identity(초기값)
WordCounter::accumulate, // accumulator
WordCounter::combine); // combiner
return wordCounter.getCounter();
}
private static final String SENTENCE =
" Nel mezzo del cammin di nostra vita "
+ "mi ritrovai in una selva oscura"
+ " che la dritta via era smarrita ";
public static void main(String[] args) {
System.out.println(countWordsParallel(SENTENCE)); // 25
}
- 병렬 스트림 사용
- 제대로 동작하지 않는다.
- 순차 스트림을 병렬 스트림으로 바꿀때 스트림 분할 위치에 따라 잘못된 결과가 나올 수 있다.
- 하나의 단어를 둘로 계산하는 상황이 발생할 수 있다.
-
따라서 예제를 병렬로 올바르게 처리하고 싶다면 문자열을 임의의 위치에서 분할하지 말고, 단어가 끝나는 위치에서만 분할해야 한다.
- 단어 끝에서 문자열을 분할하는 커스텀
Spliterator를 만들어야 한다.
- 단어 끝에서 문자열을 분할하는 커스텀
public class WordCounterSpliterator implements Spliterator<Character> {
private final String string; // 초기에 주어진 전체 문자열
private int currentChar = 0; // 현재 Spliterator 의 문자열 시작 위치
private WordCounterSpliterator(String string) {
this.string = string;
}
@Override
public boolean tryAdvance(Consumer<? super Character> action) { // 순차적으로 요소를 소비하며 탐색할 요소가 남아있으면 true 반환 (Iterator 동작과 동일)
action.accept(string.charAt(currentChar++));
return currentChar < string.length();
}
@Override
public Spliterator<Character> trySplit() { // Spliterator 를 분할하여 두 번째 Spliterator 를 생성한다.
int currentSize = string.length() - currentChar;
if (currentSize < 10) {
return null; // 문자열이 충분히 작으므로, 더 이상 쪼개지 않고 null 반환
}
for (int splitPos = currentSize / 2 + currentChar; splitPos < string.length(); splitPos++) { // splitPos 를 문자열의 중간으로 일단 이동한 뒤,
if (Character.isWhitespace(string.charAt(splitPos))) { // 공백을 만날때까지 한 칸씩 이동
Spliterator<Character> spliterator = new WordCounterSpliterator(string.substring(currentChar, splitPos)); // 현재 Spliterator 의 시작 위치 부터 splitPos 까지를 담당하는 두 번째 Spliterator 생성
currentChar = splitPos; // 현재 Spliterator 의 시작 위치를 분할 위치로 변경
return spliterator;
}
}
return null; // 단어의 길이가 문자열 중간부터 끝까지 인 경우 분할 x
}
@Override
public long estimateSize() { // 탐색해야 할 요소 개수 정보를 제공
return string.length() - currentChar;
}
/**
* Spliterator 특성 집합 제공
*
* ORDERED: 요소에 정해진 순서가 있다.
* DISTINCT: 다른 위치의 두 요소는 항상 같지 않다.
* SORTED: 탐색된 요소는 정의된 정렬 순서를 따른다.
* SIZED: 정확한 크기 값을 반환한다.
* NONNULL: 탐색하는 모든 요소는 null 이 아니다.
* IMMUTABLE: 소스는 불변으로, 요소 탐색 동안 요소를 추가, 삭제, 변경할 수 없다.
* COUCURRENT: 소스를 여러 스레드에서 동시에 고칠 수 있다.
* SUBSIZED: 현재 소스와 분할되는 모든 소스들은 SIZED 특성을 갖는다.
*/
@Override
public int characteristics() {
return ORDERED + SIZED + SUBSIZED + NONNULL + IMMUTABLE;
}
}커스텀
Spliterator인WordCounterSpliterator
tryAdvance(Consumer<? super Character> action)
- 현재 인덱스에 해당하는 요소를
Consumber에 제공한 다음 인덱스 증가- 증가된 인덱스 위치가 소스의 전체길이보다 작으면 참을 반환한다.
- 참이면 반복 탐색할 요소가 남아있음을 의미
trySplit()
- 자료구조를 분할하는 로직으로 가장 중요한 메서드
- 더 이상 분할할 수 없으면
null을 반환- 분할할 수 있다면 새로운
Spliterator를 만들어 반환
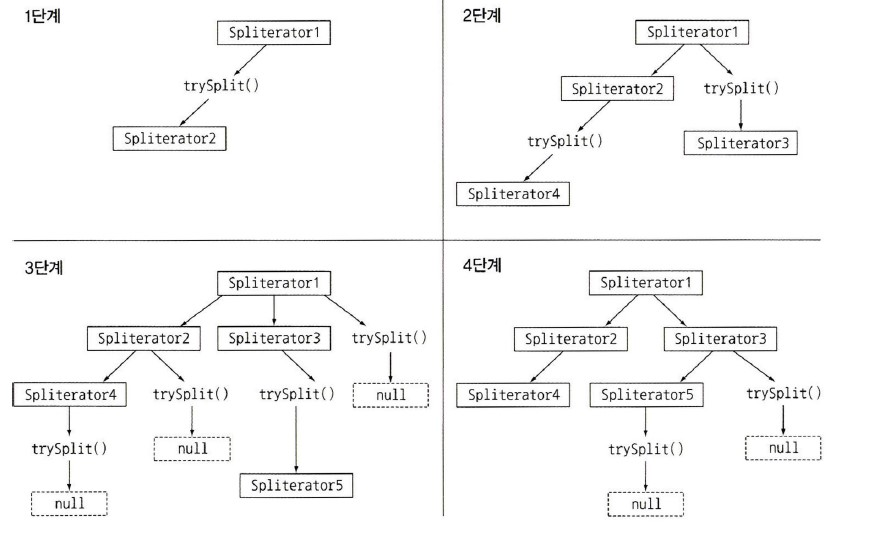
public static int countWordsParallelUsingSpliterator(String s) {
Spliterator<Character> spliterator = new WordCounterSpliterator(s);
Stream<Character> stream = StreamSupport.stream(spliterator, true);
WordCounter wordCounter = stream.reduce(new WordCounter(0, true),
WordCounter::accumulate,
WordCounter::combine);
return wordCounter.getCounter();
}
private static final String SENTENCE =
" Nel mezzo del cammin di nostra vita "
+ "mi ritrovai in una selva oscura"
+ " che la dritta via era smarrita ";
public static void main(String[] args) {
System.out.println(countWordsParallelUsingSpliterator(SENTENCE)); // 19
}
StreamSupport.stream(spliterator, 병렬처리 여부)
- 커스텀
Spliterator로 자료구조를 분할하고 병렬 스트림을 만든다.
컬렉션 API 개선
컬렉션 팩토리
-
작은 컬렉션 객체를 쉽게 만들 수 있는 방법을 제공한다.
-
리스트 팩토리
-
List.of(요소1, 요소2, ...)를 통해 불변리스트 생성 -
요소를 추가하거나 제거할 수 없다.
-
.set(인덱스, 변경내용)으로 요소를 수정할 수 없다. -
그러나 요소가 참조인 경우, 참조가 가리키는 데이터의 변경은 막을 수 없다.
-
of메서드는 인수를 1개부터 10개까지 받을 수 있도록 10개의 오버로드 버전이 존재한다.- 배열을 할당하는 오버헤드 비용 제거
-
인수가 10개를 초과하면
of(E... elements)메서드를 사용해 가변인수로 받는다.
-
-
집합 팩토리
-
Set.of(요소1, 요소2, ...)를 통해 불변 집합 생성 -
중복된 요소로 집합을 만드려고 하면 예외 발생
-
이외의 성질은 리스트 팩토리와 동일하다.
-
-
맵 팩토리
-
Map.of(key1, value1, key2, value2, ...)를 통해 불변 맵 생성 -
중복된
key로 맵을 만드려고 하면 예외 발생 -
이외의 성질은 리스트 팩토리와 동일하다.
-
리스트 처리 API
-
List인터페이스에서 사용할 수 있다. -
새로운 결과를 만드는 스트림과 다르게 기존 컬렉션을 변경한다.
-
.removeIf(Predicate)Predicate를 만족하는 요소를 전부 제거한다.
ArrayList<String> example = new ArrayList<>(List.of("hyun", "yoon", "yeon", "hyun"));
for (String each : example) { // 예외 발생
if (each.equals("hyun")) {
example.remove("hyun");
}
}
System.out.println(example);
ConcurrentModificationException이 발생한다.
ArrayList<String> example = new ArrayList<>(List.of("hyun", "yoon", "yeon", "hyun"));
for (Iterator<String> iterator = example.iterator(); iterator.hasNext();) {
String each = iterator.next();
if (each.equals("hyun")) {
example.remove("hyun");
}
}
System.out.println(example);
- 위에서 사용한
for-each루프는Iterator객체를 사용하므로 내부적으로는 위와 같은 코드이다.
- 두 개의 기본 객체가 컬렉션을 관리한다.
Iterator객체를 통해 소스 탐색Collection객체를 통해 요소 제거
- 따라서
Iterator와Collection의 상태가 서로 동기화되지 않아 예외 발생
ArrayList<String> example = new ArrayList<>(List.of("hyun", "yoon", "yeon", "hyun"));
for (Iterator<String> iterator = example.iterator(); iterator.hasNext(); ) {
String each = iterator.next();
if (each.equals("hyun")) {
iterator.remove();
}
}
System.out.println(example); // [yoon, yeon]
Iterator객체의remove()를 호출함으로서 문제를 해결할 수 있다.- 그러나 코드 가독성이 떨어진다.
ArrayList<String> example = new ArrayList<>(List.of("hyun", "yoon", "yeon", "hyun"));
example.removeIf(each -> each.equals("hyun"));
System.out.println(example); // [yoon, yeon]
removeIf를 사용하여 가독성있게 문제를 처리할 수 있다.
-
.replaceAll(UnaryOperator)- 각 요소를
UnaryOperator인수로 전달하여 얻은 결과물이 새로운 요소가 된다.
- 각 요소를
ArrayList<String> example = new ArrayList<>(List.of("hyun", "yoon", "yeon", "hyun"));
example.replaceAll(each -> each + "2");
System.out.println(example); // [hyun2, yoon2, yeon2, hyun2]-
.sort(Comparator 구현체)Comparator구현에 맞게 리스트를 정렬한다.
ArrayList<String> example = new ArrayList<>(List.of("hyun", "yoon", "yeon", "hyun"));
example.sort((s1, s2) -> s1.compareTo(s2));
System.out.println(example); // [hyun, hyun, yeon, yoon]알파벳순으로 정렬하는
Comparator를 전달하였다.
맵 처리 API
-
Map인터페이스에서 사용할 수 있다. -
.forEach(BiConsumer)- 키와 값을
BiConsumer인수로 전달하여 반복 처리한다.
- 키와 값을
Map<String, Integer> example = Map.of("hyun", 27, "yoon", 26, "yeon", 26);
example.forEach((k, v) -> System.out.println(k + " is " + v + " years old")); // yeon is 26 years old
// yoon is 26 years old
// hyun is 27 years old
-
Map요소 정렬-
Map을Set<Entry>로 변환한 뒤 정렬할 수 있다. -
Map.Entry.ComparingByKey()Set<Entry>를key값을 기준으로 정렬
-
Map.Entry.ComparingByValue()Set<Entry>를value값을 기준으로 정렬
-
Map<String, Integer> example = Map.of("hyun", 27, "yoon", 26, "yeon", 25);
example.entrySet() // Map<..> -> Set<Entry<..>>
.stream() // Set<Entry<..>> -> Stream<Entry<..>>
.sorted(Map.Entry.comparingByKey())
.forEach(System.out::println); // hyun=27
// yeon=25
// yoon=26
example.entrySet() // Map<..> -> Set<Entry<..>>
.stream() // Set<Entry<..>> -> Stream<Entry<..>>
.sorted(Map.Entry.comparingByValue())
.forEach(System.out::println); // yeon=25
// yoon=26
// hyun=27
.entrySet()을 통해Map을Set<Entry>로 변환한다.
-
.getOrDefault(key, 기본값)- 만약 찾으려는
key가 존재하지 않으면null대신 기본값을 반환한다.
- 만약 찾으려는
Map<String, Integer> example = Map.of("hyun", 27, "yoon", 26, "yeon", 25);
Integer hyunAge = example.getOrDefault("hyun", -1);
System.out.println(hyunAge); // 27
Integer ayaanAge = example.getOrDefault("ayaan", -1);
System.out.println(ayaanAge); // -1-
.computeIfAbsent(key, Function)-
만약
key에 해당하는value가 있으면value를 반환한다.Function실행 X
-
만약
key에 해당하는value가 없거나null이면key를Function에 인수로 전달한다.-
Function실행의 결과물이 입력으로 넣은key의value가 된다. -
key와value를Map에 저장한다. -
앞서 구한
value를 반환한다.
-
-
Map<String, Integer> example = new HashMap<>() {{
put("hyun", 27);
put("yoon", 26);
put("yeon", 25);
put("ayaan", null);
}}; // {yeon=25, ayaan=null, hyun=27, yoon=26}
// key 에 대응되는 value 가 존재하는 경우
Integer hyunAge = example.computeIfAbsent("hyun", (key) -> {
System.out.println(key + "가 없으므로 계산중!");
return key.length() * 10;
});
System.out.println(hyunAge); // 27
System.out.println(example); // {yeon=25, ayaan=null, hyun=27, yoon=26}
// key 가 존재하지 않는 경우 (value 가 존재하지 않는 경우)
Integer sullyAge = example.computeIfAbsent("sully", (key) -> {
System.out.println(key + "가 없으므로 계산중!");
return key.length() * 10;
}); // sully가 없으므로 계산중! 출력
System.out.println(sullyAge); // 50
System.out.println(example); // {yeon=25, ayaan=null, hyun=27, sully=50, yoon=26}
// key 가 존재하나 대응되는 value 가 null 인 경우
Integer ayaanAge = example.computeIfAbsent("ayaan", (key) -> {
System.out.println(key + "가 없으므로 계산중!");
return key.length() * 10;
}); // ayaan가 없으므로 계산중! 출력
System.out.println(ayaanAge); // 50
System.out.println(example); // {yeon=25, ayaan=50, hyun=27, sully=50, yoon=26}
-
.remove(key, value)-
key에 대응되는value가 일치하는 경우에만Map에서 요소를 삭제한다. -
key가 존재하더라도value가 다르면 삭제하지 않는다.
-
Map<String, Integer> example = new HashMap<>(Map.of("hyun", 27, "yoon", 26, "yeon", 25));
example.remove("hyun"); // key가 존재하면 바로 삭제
System.out.println(example); // {yeon=25, yoon=26}
example.remove("yoon", 25); // key에 대응되는 value 가 일치하지 않는다.
System.out.println(example); // {yeon=25, yoon=26}
example.remove("yoon", 26); // key에 대응되는 value 가 일치한다.
System.out.println(example); // {yeon=25}-
.replaceAll(BiFunction)-
key와value를 인수로 받는BiFunction을 파라미터로 갖는다. -
모든
value가BiFunction의 결과물로 변경된다.
-
Map<String, Integer> example = new HashMap<>(Map.of("hyun", 27, "yoon", 26, "yeon", 25));
example.replaceAll((key, value) -> key.length() * 100 + value);
System.out.println(example); // {hyun=427, yeon=425, yoon=426}-
.replace(key, 변경할 value)-
Map에key가 존재하면value를 바꾼다. -
변경 성공 시, 변경 전의 값을 반환한다.
-
-
.replace(key, 이전 value, 변경할 value)Map에key가 존재하고 이전value도 일치하면value를 바꾼다.
Map<String, Integer> example = new HashMap<>(Map.of("hyun", 27, "yoon", 26, "yeon", 25));
Integer hyunAge = example.replace("hyun", 26);
System.out.println(hyunAge); // 27 (변경 전의 값을 가져온다.)
System.out.println(example); // {hyun=26, yeon=25, yoon=26}
boolean changed = example.replace("yoon", 10, 100);
System.out.println(changed); // false
System.out.println(example); // {hyun=26, yeon=25, yoon=26}
boolean changed2 = example.replace("yoon", 26, 100);
System.out.println(changed2); // true
System.out.println(example); // {yeon=25, hyun=26, yoon=100}-
.entrySet().removeIf(Predicate)-
List와 동일하게 동작한다. -
Predicate를 만족하는Map의 요소들을 제거한다.Set<Entry>의 변경사항은Map에 반영되고, 반대의 경우도 성립한다.
-
리팩터링, 테스팅, 디버깅
- 람다 표현식을 통해 기존의 코드를 유연하고 간결하게 리팩터링 할 수 있다.
익명 클래스 ➔ 람다 표현식
-
하나의 추상 메서드를 구현하는 익명 클래스는 대부분의 경우 람다 표현식으로 리팩터링 할 수 있다.
-
그러나 익명 클래스와 람다 표현식의 다음 3가지 차이점을 주의해야 한다.
-
익명 클래스의
this는 익명 클래스 자신을 가리키지만, 람다에서의this는 람다를 감싸는 클래스를 가리킨다.
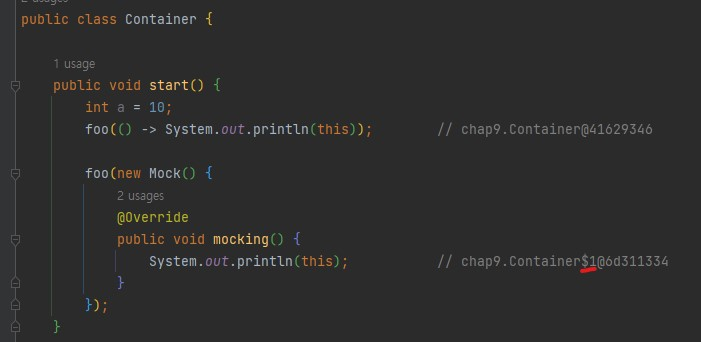
-
익명 클래스는 자신을 감싼 클래스의 변수를 가릴 수 있지만 (shadow variable) 람다는 가릴 수 없다.
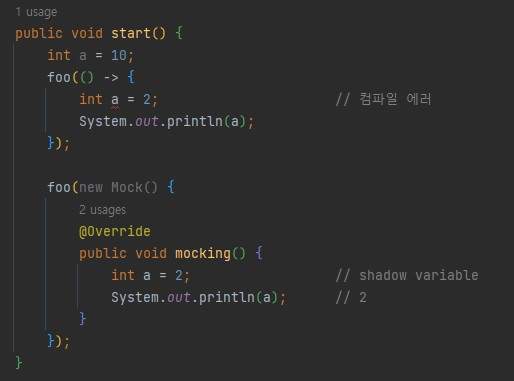
-
익명 클래스는 인스턴스화 할 때 명시적으로 형식이 정해지는 반면, 람다의 형식은 콘텍스트에 의존한다.
- 함수 디스크립터가 같은 콘텍스트가 여러 개인 경우, 람다는 모호함 때문에 컴파일 에러가 발생한다.
-
@FunctionalInterface
public interface Mock {
void mocking();
}
- 함수형 인터페이스인
Mockmocking()은() -> ()함수 디스크립터를 갖는다.
public class Container {
public void start() {
int a = 10;
foo(() -> System.out.println("ho")); // 콘텍스트 오버로딩에 의한 모호함 -> 컴파일 에러 발생
foo(new Mock() {
@Override
public void mocking() {
System.out.println("ho"); // 실행 잘됨
}
});
}
public void foo(Mock mock) {
mock.mocking();
}
public void foo(Runnable r) {
r.run();
}
}
- 람다는 콘텍스트 오버로딩에 의한 모호함 때문에 컴파일 에러가 발생한다.
- 명시적 형변환을 통해 모호함을 제거해야 한다.
foo((Mock) () -> System.out.println("ho"));- 익명 클래스는 클래스를 명시하기 때문에 모호함 없이 잘 동작한다.
코드 유연성 개선
-
조건부 연기 실행
- 특정 조건에서만 특정 동작을 수행하도록 동작을 연기한다.
// 클라이언트
logger.log(Level.FINER, () -> "문제 발생: " + generateErrorReport()); // 로그 레벨과 메시지 생성 동작을 전달
// Logger 내부 동작
public void log(Level level, Supplier<String> msgSupplier) {
if (logger.isLoggable(level)) { // 만약 log의 level 이 적절한 경우
logger.log(level, msgSupplier.get()); // 연기된 메시지 생성 동작을 수행하여 메시지 전달
}
}
public void log(Level level, String message) {
logPrint(level, message); // 레벨과 메시지를 받아 로그 출력
}
- 로그 메시지의 레벨이 적절한 경우에만 메시지 생성 동작을 수행한다.
- 로그 메시지의 레벨이 적절하지 않은 경우, 아무런 동작도 하지 않는다.
-
실행 어라운드
-
자주 변하는 핵심 동작이 변하지 않는 준비, 종료과정 사이에 있다면
-
자주 변하는 핵심 동작을 람다로 변환한다.
-
public class ExecuteAround {
private static final String FILE = ExecuteAround.class.getResource("./data.txt").getFile();
public static void main(String[] args) throws IOException {
String oneLine = processFile((BufferedReader b) -> b.readLine()); // 한 줄만 읽는 동작 전달
System.out.println(oneLine);
System.out.println();
String twoLines = processFile((BufferedReader b) -> b.readLine() + b.readLine()); // 두 줄을 읽는 동작 전달
System.out.println(twoLines);
}
public static String processFile(BufferedReaderProcessor p) throws IOException {
try (BufferedReader br = new BufferedReader(new FileReader(FILE))) { // 자원 준비, 정리과정
return p.process(br); // 핵심 로직 동작
}
}
}
BufferedReaderProcessor p가 자주 변하는 핵심 동작이다.
전략 (Strategy) 패턴에서의 람다 활용

- 전략 ➔ 인터페이스
ConcreteStrategyA,ConcreteStrategyB➔ 알고리즘 (전략 인터페이스 구현체)- 런타임에 적절한 알고리즘을 선택하는 기법
public interface ValidationStrategy {
boolean execute(String s);
}전략 인터페이스
public class IsAllLowerCase implements ValidationStrategy {
@Override
public boolean execute(String s) {
return s.matches("[a-z]+");
}
}
public class IsNumeric implements ValidationStrategy {
@Override
public boolean execute(String s) {
return s.matches("\\d+");
}
}전략 인터페이스를 구현한 알고리즘
public class Validator {
private final ValidationStrategy strategy;
public Validator(ValidationStrategy strategy) {
this.strategy = strategy;
}
public boolean validate(String s) {
return strategy.execute(s);
}
}전략 객체를 사용하는 클라이언트
public class StrategyMain {
public static void main(String[] args) {
Validator numericValidator = new Validator(new IsNumeric());
System.out.println(numericValidator.validate("aaaa")); // false
Validator lowerCaseValidator = new Validator(new IsAllLowerCase());
System.out.println(lowerCaseValidator.validate("aaaa")); // true
}
}실행 결과
-
ValidationStrategy는 함수형 인터페이스며Predicate(String)과 동일한 함수 디스크립터를 갖는다.(String s) -> boolean
-
따라서 전략을 구현하는 클래스를 만들 필요없이 람다 표현식을 전달하여 간결하게 표현할 수 있다.
public class StrategyMain {
public static void main(String[] args) {
Validator numericValidator2 = new Validator((s) -> s.matches("\\d+"));
System.out.println(numericValidator2.validate("aaaa")); // false
Validator lowerCaseValidator2 = new Validator((s) -> s.matches("[a-z]+"));
System.out.println(lowerCaseValidator2.validate("aaaa")); // true
}
}Template method 패턴에서의 람다 활용
- 알고리즘의 골격이 존재하고, 골격의 일부만을 고칠 수 있는 유연함이 필요할 때 사용하는 기법
public abstract class OnlineBanking {
public void processCustomer(int id) { // 알고리즘 템플릿
Customer c = Database.getCustomerWithId(id);
makeCustomerHappy(c); // 유연하게 고치고 싶은 부분
}
protected abstract void makeCustomerHappy(Customer c); // 유연하게 고치고 싶은 부분
}
processCustomer(int id)➔ 알고리즘 템플릿makeCustomerHappy(c)➔ 유연하게 고치고 싶은 부분
public class HyunOnlineBanking extends OnlineBanking {
@Override
protected void makeCustomerHappy(Customer c) {
System.out.println(c.getName() + "님, 현 은행에 오신걸 환영합니다");
}
}
public class YoonOnlineBanking extends OnlineBanking {
@Override
protected void makeCustomerHappy(Customer c) {
System.out.println(c.getName() + "님, 윤 은행에 오신걸 환영합니다");
}
}각 은행 지점마다
OnlineBanking클래스를 상속받아makeCustomerHappy(Customer c)메서드가 원하는 동작을 수행하도록 구현한다.
public static void main(String[] args) {
HyunOnlineBanking hyunOnlineBanking = new HyunOnlineBanking();
hyunOnlineBanking.processCustomer(1); // yeon님, 현 은행에 오신걸 환영합니다
YoonOnlineBanking yoonOnlineBanking = new YoonOnlineBanking();
yoonOnlineBanking.processCustomer(1); // yeon님, 윤 은행에 오신걸 환영합니다
}- 람다를 파라미터로 전달하면, 추가적인 템플릿 상속 클래스를 만들지 않고 알고리즘 템플릿에 원하는 기능을 유연하게 추가할 수 있다.
public class OnlineBankingLambda {
public void processCustomer(int id, Consumer<Customer> makeCustomerHappy) { // 알고리즘 템플릿
Customer c = Database.getCustomerWithId(id);
makeCustomerHappy.accept(c); // 유연하게 고치고 싶은 부분
}
}
processCustomer(int id, Consumer<Customer> makeCustomerHappy)➔ 알고리즘 템플릿Consumer<Customer> makeCustomerHappy파라미터
- 유연하게 고치고 싶은 부분을 람다로 받아 원하는 시점에 실행한다.
public class OnlineBankingMain {
public static void main(String[] args) {
OnlineBankingLambda onlineBanking1 = new OnlineBankingLambda();
onlineBanking1.processCustomer(1, (c) -> System.out.println(c.getName() + "님, 제1은행에 오신걸 환영합니다."));
// yeon님, 제1은행에 오신걸 환영합니다.
OnlineBankingLambda onlineBanking2 = new OnlineBankingLambda();
onlineBanking2.processCustomer(1, (c) -> System.out.println(c.getName() + "님, 제2은행에 오신걸 환영합니다."));
// yeon님, 제2은행에 오신걸 환영합니다.
}
}템플릿 클래스를 상속 받지 않고 직접 람다 표현식을 전달하여 다양한 동작 추가
Observer 패턴에서의 람다 활용

-
한 객체 (
Subject) 가 -
다른 객체들 (
Observer) 에게 자동으로 알림을 보내야 하는 상황에 사용하는 기법
public interface Observer {
void notify(String tweet);
}
public class NYTimes implements Observer {
@Override
public void notify(String tweet) {
if (tweet != null && tweet.contains("money")) {
System.out.println("Breaking news in NY! " + tweet);
}
}
}
public class Guardian implements Observer {
@Override
public void notify(String tweet) {
if (tweet != null && tweet.contains("queen")) {
System.out.println("Yet more new from London..." + tweet);
}
}
}
public class LeMonde implements Observer {
@Override
public void notify(String tweet) {
if (tweet != null && tweet.contains("wine")) {
System.out.println("Today cheese, wine and news! " + tweet);
}
}
}
Observer인터페이스와 구현체들tweet의 특정 단어에 반응한다.
public interface Subject {
void registerObserver(Observer o);
void notifyObservers(String tweet);
}
public class Feed implements Subject {
private final List<Observer> observers = new ArrayList<>();
@Override
public void registerObserver(Observer o) {
this.observers.add(o);
}
@Override
public void notifyObservers(String tweet) {
observers.forEach(o -> o.notify(tweet));
}
}
Subject인터페이스와 구현체Observer들을 등록, 관리한다.Observer들에게 특정 이벤트 (tweet) 가 발생했음을 알린다.
public class ObserverMain {
public static void main(String[] args) {
Feed feed = new Feed();
feed.registerObserver(new NYTimes());
feed.registerObserver(new Guardian());
feed.registerObserver(new LeMonde());
feed.notifyObservers("The queen said her favourite book is Java 8 & 9 in Action!"); // Guardian Observer 가 반응
feed.notifyObservers("Give me money!!!"); // NYTimes Observer 가 반응
feed.notifyObservers("boola boola foo"); // 아무도 반응 x
feed.notifyObservers("The queen likes wine~"); // LeMonde Observer 와 Guardian Observer 가 반응
}
}실행 결과
Yet more new from London...The queen said her favourite book is Java 8 & 9 in Action! Breaking news in NY! Give me money!!! Yet more new from London...The queen likes wine~ Today cheese, wine and news! The queen likes wine~
-
Observer인터페이스는 하나의 메서드notify만을 가진다.-
함수형 인터페이스이다.
-
구현 클래스를 만들지 않고 람다 표현식을 전달해
Observer가 실행할 동작을 지정할 수 있다.
-
-
Observer가 상태를 가지거나, 여러 메서드를 정의하거나, 복잡한 내부로직을 갖는다면 기존 클래스 구현방식이 낫다.
public class ObserverMain {
public static void main(String[] args) {
Feed feedLambda = new Feed();
feedLambda.registerObserver(tweet -> {
if (tweet != null && tweet.contains("money")) {
System.out.println("Breaking news in NY! " + tweet);
}
});
feedLambda.registerObserver(tweet -> {
if (tweet != null & tweet.contains("queen")) {
System.out.println("Yet more new from London..." + tweet);
}
});
feedLambda.registerObserver(tweet -> {
if (tweet != null && tweet.contains("wine")) {
System.out.println("Today cheese, wine and news! " + tweet);
}
});
feedLambda.notifyObservers("The queen said her favourite book is Java 8 & 9 in Action!");
feedLambda.notifyObservers("Give me money!!!");
feedLambda.notifyObservers("boola boola foo");
feedLambda.notifyObservers("The queen likes wine~");
}
}실행결과
Yet more new from London...The queen said her favourite book is Java 8 & 9 in Action! Breaking news in NY! Give me money!!! Yet more new from London...The queen likes wine~ Today cheese, wine and news! The queen likes wine~
- 앞선 실행결과와 동일하다.
Chain of Responsibility 패턴에서의 람다 활용
-
A 객체가 어떤 작업을 처리한 다음 B 객체에게 결과를 전달하고
-
B 객체가 어떤 작업을 처리한 다음 C 객체에게 결과를 전달하는 방식으로
-
여러 작업 처리 객체의 동작 체인을 만들 때 사용하는 기법
public abstract class ProcessingObject<T> {
protected ProcessingObject<T> successor; // 후임자
public void setSuccessor(ProcessingObject<T> successor) {
this.successor = successor;
}
public T handle(T input) {
T r = handleWork(input);
if (successor != null) {
return successor.handle(r); // 후임자가 있으면 현재 객체가 처리한 작업 결과를 후임자 객체에게 넘긴다.
}
return r; // 후임자가 없으면 현재 객체가 처리한 작업 결과를 반환한다.
}
abstract protected T handleWork(T input); // 실제 작업 처리
}
- 작업 처리 추상 클래스로 Chain of Responsibility 패턴을 구성한다.
T는 작업 처리 결과물의 타입
handle(T input)
- 작업 처리 객체가 자신의 작업을 끝내면 다음 작업 처리 객체 (
successor) 로 결과 전달- 다음 작업 처리 객체가 없으면 자신의 작업 결과물을 반환
handleWork(T input)
- 실제 작업 처리 내용
- 해당 메서드를 구현하여 다양한 작업 처리 객체를 만든다.
public class HeaderTextProcessing extends ProcessingObject<String> {
@Override
protected String handleWork(String input) {
return "From Hyun: " + input;
}
}
public class SpellCheckerProcessing extends ProcessingObject<String> {
@Override
protected String handleWork(String input) {
return input.replaceAll("labda", "lambda");
}
}
HeaderTextProcessing
input텍스트에 Header 를 부착하는 작업 수행SpellCheckerProcessing
input텍스트의labda(오타) 를lambda로 전부 고치는 작업 수행
-
람다 표현식으로 작업들을 정의하고,
-
람다 표현식을 조합하여 Chain of Responsibility 패턴을 구현할 수 있다.
andThen메서드 사용
public class ChainOfResponsibilityMain {
public static void main(String[] args) {
UnaryOperator<String> headerProcessing = text -> "From Hyun: " + text;
UnaryOperator<String> spellCheckerProcessing = text -> text.replaceAll("labda", "lambda");
Function<String, String> pipeline = headerProcessing.andThen(spellCheckerProcessing);
String result = pipeline.apply("Aren't labdas really sexy?!");
System.out.println(result); // From Hyun: Aren't lambdas really sexy?!
}
}peek 연산
-
스트림의 파이프라인 연산을 디버깅하기 위해 사용
-
forEach는 최종 연산이므로 파이프라인 중간에 디버깅 용도로 사용할 수 없다. -
peek는forEach와 유사하게 동작하지만 요소를 소비하지 않는다.- 자신이 확인한 요소를 파이프라인의 다음 연산으로 그대로 전달한다.
public class Peek {
public static void main(String[] args) {
List<Integer> result = Stream.of(1, 2, 3, 4, 5, 6, 7, 8)
.peek(i -> System.out.println("origin stream: " + i)) // 소스의 처음 요소 출력
.map(i -> i + 20)
.peek(i -> System.out.println("after map: " + i)) // map 동작 후 요소 출력
.filter(i -> i % 2 == 0)
.peek(i -> System.out.println("after filter: " + i)) // filter 동작 후 요소 출력
.limit(3)
.peek(i -> System.out.println("after limit: " + i)) // limit 동작 후 요소 출력
.collect(Collectors.toList());
System.out.println(result); // [22, 24, 26]
}
}실행결과 분석
origin stream: 1 after map: 21 (필터 통과 못함) origin stream: 2 after map: 22 after filter: 22 after limit: 22 (전부 통과) origin stream: 3 after map: 23 (필터 통과 못함) origin stream: 4 after map: 24 after filter: 24 after limit: 24 (전부 통과) origin stream: 5 after map: 25 (필터 통과 못함) origin stream: 6 after map: 26 after filter: 26 after limit: 26 (전부 통과) (limit 3을 채웠으므로 연산 종료) [22, 24, 26]
- 이를 통해 스트림은 요소를 하나씩 하나씩 전체 파이프라인을 통과시키며 처리함을 알 수 있다.
출처
모던 자바 인 액션 (라울-게이브리얼 우르마, 마리오 푸스코, 앨런 마이크로프트)
람다의 자유 변수 사용 (cksdnr066 님)
https://velog.io/@cksdnr066/Java-%EC%99%9C-%EB%9E%8C%EB%8B%A4%EA%B0%80-%EC%82%AC%EC%9A%A9%ED%95%98%EB%8A%94-%EC%A7%80%EC%97%AD%EB%B3%80%EC%88%98%EB%8A%94-Effectively-Final-%EC%9D%B4%EC%96%B4%EC%95%BC-%ED%95%98%EB%8A%94%EA%B0%80

모던 개발자 현..,.,, 탄생 ✨