
자바의 정석2를 읽고
-
나름대로 정리하고 싶은 내용들을 내맘대로 정리하였다.
-
자바의 정석 1은 쉽게 읽었는데, 2는 정말 어려웠다.
-
디테일한 내용이 많아서 더 그랬던거 같다.
-
그래도 재밌게 읽었다.
정리한 Chapter
-
chapter 10 날짜와 시간 & 형식화
-
chapter 11 Collection Framework
-
chapter 12 Generics , Enums, Annotation
-
chapter 13 쓰레드
-
chapter 14 람다와 스트림
날짜와 시간 & 형식화
Time 패키지
-
가장 큰 특징은 불변
String클래스와 유사한 방식- 날짜나 시간을 변경하는 메서드들은, 기존 객체를 변경하지 않고 새로운 객체를 반환
- 멀티쓰레드 환경에서 안전하다.
-
이전의
Calendar,Date클래스는 기존 객체를 변경하였다.- 여러 쓰레드가 같은 객체에 접근하는 경우, 변경 가능 객체는 데이터가 잘못될 수 있다.
- 쓰레드에 안전하지 않다.
-
LocalDate,LocalTime,LocalDateTime를 핵심으로 사용
다양한 사용법
now
LocalDateTime now = LocalDateTime.now();현재 시점으로 생성
of
LocalDateTime of = LocalDateTime.of(2023, 4, 29, 0, 0, 1);설정한 시점으로 생성
get
int minute = now.getMinute();원하는 단위의 값을 가져온다
plus,with
LocalDateTime nowPlusDay = now.plusDays(1); // now 에 하루 더해진다.
LocalDateTime localDateTime = now.withDayOfMonth(31); // now 에서 일만 31로 변경한다.parse
LocalDate parse = LocalDate.parse("2023-04-29");문자를 파싱하여
Time패키지의 객체로 변환
- 비교
boolean b1 = date1.isAfter(date2); // date1 이 date2 보다 이후날짜면 true
boolean b2 = date1.isBefore(date2); // date1 이 date2 보다 이전날짜면 true
boolean equal = date1.isEqual(date2); // date1 과 date2 날짜가 같으면 true- 두 날짜, 시간차이 계산
LocalDate d1 = date1.toLocalDate(); // LocalDateTime -> LocalDate 변환
LocalDate d2 = date2.toLocalDate();
long dayDiff = d1.toEpochDay() - d2.toEpochDay();
LocalTime t1 = date1.toLocalTime(); // LocalDateTime -> LocalTime 변환
LocalTime t2 = date2.toLocalTime();
long timdDiff = t1.toSecondOfDay() - t2.toSecondOfDay();
d1.toEpochDay(): 날짜 객체의 모든 단위를 일로 변환t1.toSecondOfDay(): 시간 객체의 모든 단위를 초로 변환
TemporalAdjuster
-
이번 달의 3번째 금요일은 며칠이지?
-
지난 주 토요일이 며칠이지?
-
와 같은 날짜 계산들을 대신 해주는 메서드를 정의해놓은 클래스
-
LocalDate객체.with(TemporalAdjuster static 메서드)와 같은 방식으로 사용 -
반환값은
LocalDate객체API : https://docs.oracle.com/javase/8/docs/api/java/time/temporal/TemporalAdjusters.html
LocalDate today = LocalDate.now(); // 오늘
today.with(TemporalAdjusters.firstDayOfMonth()); // 이번달의 첫번째 날
today.with(TemporalAdjusters.firstDayOfNextMonth()); // 다음달의 첫번째 날
today.with(TemporalAdjusters.lastDayOfMonth()); // 이번달의 마지막 날
today.with(TemporalAdjusters.firstInMonth(DayOfWeek.TUESDAY)); // 이 달의 첫번째 화요일
today.with(TemporalAdjusters.lastInMonth(DayOfWeek.TUESDAY)); // 이 달의 마지막 화요일
today.with(TemporalAdjusters.previous(DayOfWeek.TUESDAY)); // 지난 화요일
today.with(TemporalAdjusters.previousOrSame(DayOfWeek.TUESDAY)); // 지난 화요일 (오늘 포함)
today.with(TemporalAdjusters.next(DayOfWeek.TUESDAY)); // 다음 화요일
today.with(TemporalAdjusters.nextOrSame(DayOfWeek.TUESDAY)); // 다음 화요일 (오늘 포함)
today.with(TemporalAdjusters.dayOfWeekInMonth(4, DayOfWeek.TUESDAY)); // 이 달의 4번째 화요일형식화
-
숫자, 날짜, 텍스트 데이터를 일정한 형식에 맞게 표현하는 방법,
-
형식화 클래스는 형식화에 사용할 패턴을 정의한다.
-
둘다 가능
- 원래 데이터 -> 형식화된 데이터
- 형식화된 데이터 -> 원래 데이터
DecimalFormat
-
숫자를 형식화
-
숫자 -> 형식화(문자열)
double number = 1234567.89;
DecimalFormat df1 = new DecimalFormat("0.000");
String format1 = df1.format(number); // format1 = 1234567.890
DecimalFormat df2 = new DecimalFormat("#.###");
String format2 = df2.format(number); // format2 = 1234567.89
DecimalFormat df3 = new DecimalFormat("#.#");
String format3 = df3.format(number); // format3 = 1234567.9
DecimalFormat df4 = new DecimalFormat("#,###");
String format4 = df4.format(number); // format4 = 1,234,568
0.000: 값이 없는경우 0을 채워넣는 방식으로 형식화#.###: 값이 없는경우 생략#.#: 소수점 자리가 부족할 경우 반올림 발생#,###: 단위 구분자를 넣어 형식화
- 형식화된 데이터(문자열) -> 숫자
DecimalFormat df4 = new DecimalFormat("#,###");
String format4 = df4.format(number); // format4 = 1,234,568
Number parse4 = df4.parse(format4); // parse4 = 1234568 (Number 타입)
format과 반대로 형식화된 데이터를parse메서드에 전달
DateTimeFormatter
-
Time패키지 객체들을 형식화API : https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html
-
Time패키지 객체 -> 형식화 (문자열)
LocalDateTime date = LocalDateTime.of(2020, 12, 24, 10, 30, 15); // 2020-12-24T10:30:15
DateTimeFormatter formatter1 = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
String form1 = date.format(formatter1); // 2020-12-24 10:30:15
DateTimeFormatter formatter2 = DateTimeFormatter.ofPattern("이 날은 이 달의 W번째 E요일입니다.");
String form2 = date.format(formatter2); // 이 날은 이 달의 4번째 목요일입니다.- 형식화된 데이터 ->
Time패키지 객체
DateTimeFormatter formatter1 = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
LocalDateTime parsedDate = LocalDateTime.parse("2020-12-24 10:30:15", formatter1); // 2020-12-24T10:30:15 Collection Framework
-
다수의 데이터 그룹을 저장하기 위한 클래스와 구조
-
핵심 인터페이스는
List,Set,Map -
List- 순서가 있는 데이터의 집합, 중복 허용
- 구현클래스 :
ArrayList,LinkedList,Stack
-
Set- 순서를 유지하지 않는 데이터의 집합, 중복 불가
- 구현클래스 :
HashSet,TreeSet
-
Mapkey와value의 쌍으로 이루어진 데이터 집합- 순서 유지 x,
key는 중복 불가,value는 중복 가능 - 구현클래스 :
HashMap,TreeMap
Collection 인터페이스
-
List,Set인터페이스의 조상 -
저장된 데이터를 읽고, 추가하고 삭제하는 기본적인 메서드들을 정의
ArrayList 클래스
-
데이터의 저장순서가 유지
-
중복을 허용
-
사이즈가 변하는 배열 구조
- 검색 속도가 빠르다.
- 순차적인 데이터의 추가 삭제가 빠르다.
- 비순차적인 데이터의 추가 삭제가 느리다.
API : https://docs.oracle.com/en/java/javase/19/docs/api/java.base/java/util/ArrayList.html#method-summary
LinkedList 클래스
-
데이터의 저장순서가 유지
-
중복을 허용
-
링크드 리스트 구조 (doubly circular linked list)
- 각 노드는 데이터와
- 자신과 이웃한 노드들의 참조로 구성
- 검색속도가 느리다.
- 데이터의 추가 삭제가 빠르다
Queue자료구조에 데이터를 넣는 동작과 같은offer(),
데이터를 빼는 동작과 같은poll()
ArrayList vs LinkedList
| 컬렉션 | 읽기(접근시간) | 순차적인 추가/삭제 | 비순차적인 추가/삭제 | 특징 |
|---|---|---|---|---|
ArrayList | 빠름 | 빠름 | 느림 | 비효율적인 메모리 사용 |
LinkedList | 느림 | 비교적 느림 | 빠름 | 데이터가 많을수록 접근성 ↓ |
Stack & Queue
Stack은 구현 클래스가 있다.
API : https://docs.oracle.com/en/java/javase/19/docs/api/java.base/java/util/Stack.html#method-summary
Queue는 구현 클래스가 따로 없고LinkedList를 사용한다.offer()는 순차적으로 데이터를 저장poll()은 가장 앞부분 데이터를 꺼내서 반환
Comparable
-
클래스가
Comparable인터페이스의compareTo메서드를 구현하여 객체간의 대소비교 가능Integer,String,Date같은 클래스들은 기본적으로 구현되어 있음
-
Arrays.sort(),Collections.sort(),Tree자료구조의 기본정렬 조건으로 사용됨 -
compareTo는 반환값에 따라 교환이 발생한다.- 반환값이 양수인 경우 ➔ 교환 발생
- 반환값이 음수, 0인 경우 ➔ 가만 놔둠
class Student implements Comparable<Student> {
String name;
int ban;
int no;
int kor, eng, math;
Student(String name, int ban, int no, int kor, int eng, int math) {
this.name = name;
this.ban = ban;
this.no = no;
this.kor = kor;
this.eng = eng;
this.math = math;
}
int getTotal() {
return kor + eng + math;
}
float getAverage() {
return (int) ((getTotal() / 3f) * 10 + 0.5) / 10f;
}
public String toString() {
return name + "," + ban + "," + no + "," + kor + "," + eng + "," + math
+ "," + getTotal() + "," + getAverage();
}
@Override
public int compareTo(Student s) {
return this.name.compareTo(s.name);
}
}
Student클래스가Comparable<Student>인터페이스를 구현
compareTo()메서드 구현- 이를 통해
Student타입 객체들의 대소 비교 가능- 현재 정렬 기준은 학생의 이름을 오름차순으로 정렬
public static void main(String[] args) {
ArrayList<Student> list = new ArrayList<>();
list.add(new Student("홍길동", 1, 1, 100, 100, 100));
list.add(new Student("남궁성", 1, 2, 90, 70, 80));
list.add(new Student("김자바", 1, 3, 80, 80, 90));
list.add(new Student("이자바", 1, 4, 70, 90, 70));
list.add(new Student("안자바", 1, 5, 60, 100, 80));
Collections.sort(list);
for (Student student : list) System.out.println(student);
}출력결과
김자바,1,3,80,80,90,250,83.3
남궁성,1,2,90,70,80,240,80.0
안자바,1,5,60,100,80,240,80.0
이자바,1,4,70,90,70,230,76.7
홍길동,1,1,100,100,100,300,100.0
Collections.sort(list)를 사용하여 기본정렬 수행
Comparator
-
기본 정렬기준이 아닌 다른 기준으로 정렬하고 싶을 때 사용
-
외부에서
Comparator인터페이스를 구현한 새로운 정렬기준 클래스를 만든다.compare메서드를 구현한다.compare메서드의 반환값에 따른 교환여부는compareTo와 동일하다.
class BanAscending implements Comparator<Student> {
@Override
public int compare(Student s1, Student s2) {
return s1.ban - s2.ban;
}
}
BanAscending클래스가Comparator<Student>인터페이스를 구현
compare메서드 구현- 정렬기준은 반을 기준으로 오름차순 정렬
public static void main(String[] args) {
ArrayList<Student> list = new ArrayList<>();
list.add(new Student("홍길동", 7, 1, 100, 100, 100)); // 7반
list.add(new Student("남궁성", 2, 2, 90, 70, 80)); // 2반
list.add(new Student("김자바", 1, 3, 80, 80, 90)); // 1반
list.add(new Student("이자바", 3, 4, 70, 90, 70)); // 3반
list.add(new Student("안자바", 1, 5, 60, 100, 80)); // 1반
Collections.sort(list, new BanAscending());
for (Student student : list) System.out.println(student);
}출력결과
김자바,1,3,80,80,90,250,83.3
안자바,1,5,60,100,80,240,80.0
남궁성,2,2,90,70,80,240,80.0
이자바,3,4,70,90,70,230,76.7
홍길동,7,1,100,100,100,300,100.0
Collections.sort(list, new BanAscending())으로 정렬
HashSet
-
데이터의 저장순서 유지 x
- 순서 유지를 원할 경우
LinkedHashSet사용
- 순서 유지를 원할 경우
-
중복 허용 x
-
해싱을 이용한 구현
- 객체의 경우
equals,hashCode메서드를 목적에 맞게 오버라이딩하여야 중복 요소를 제거할 수 있다.
- 객체의 경우
class Person {
String name;
int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age && Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
Person타입 객체의name과age가 같으면 같은 것으로 인식시키기 위한equals와hashCode오버라이딩
API : https://docs.oracle.com/en/java/javase/19/docs/api/java.base/java/util/HashSet.html#method-summary
Hash 코드의 성질
-
동일한 객체에 대해 동일한 해쉬코드값(
int)을 반환해야 한다. -
equals비교값이true인 두 인스턴스는 같은 해쉬코드값을 반환해야 한다. -
두 인스턴스가 같은 해쉬코드값을 갖더라도 꼭
equals비교값이true는 아니다.- 그러나 해싱을 사용하는 컬렉션의 성능을 향상시키기 위해서는 다른 해쉬코드값을 갖는것이 좋다.
TreeSet
-
정렬된 순서로 저장 ➔ 저장 순서 유지 x
-
중복 허용 x
-
이진 검색 트리 기반 (RB tree)
-
각 노드는
- 데이터와
- 왼쪽 자식노드 주소 (더 작은 데이터값)
- 오른쪽 자식노드 주소 (더 큰 데이터값) 로 구성
API : https://docs.oracle.com/en/java/javase/19/docs/api/java.base/java/util/TreeSet.html#method-summary
HashMap
-
key와value를 묶어 하나의entry로 저장key는 중복 xvalue는 중복 가능
-
해싱을 사용 ➔ 검색 성능이 뛰어남
API : https://docs.oracle.com/en/java/javase/19/docs/api/java.base/java/util/HashMap.html#method-summary
해싱과 해시함수
-
해싱
- 해시함수를 이용해 데이터를 해시테이블에 저장하고 검색하는 기법
-
해시테이블
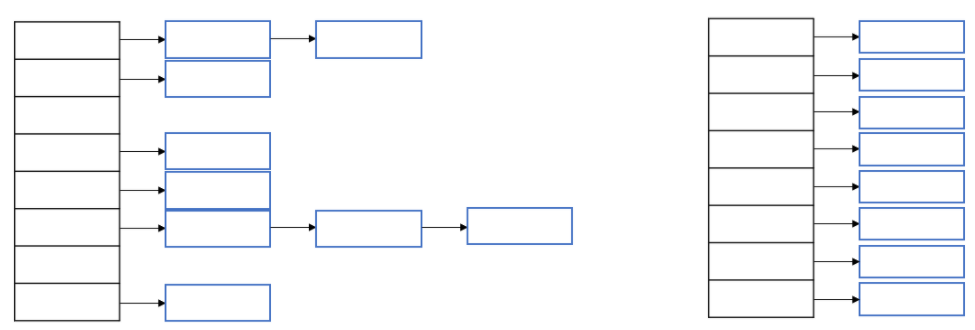
왼쪽 : 비효율적인 해시테이블
오른쪽 : 효율적인 해시테이블-
배열과 링크드리스트의 조합
-
키를 해시함수에 넣으면 해시코드를 얻게된다.
-
해시코드는 배열의 한 위치를 나타낸다.
-
해당하는 배열 위치에 링크드 리스트 형태로 데이터를 저장한다.
-
따라서 서로 다른 데이터의 해시코드값이 일치하는 해시충돌이 발생하면
-
링크드 리스트가 길어지므로 검색 효율이 떨어진다.
-
-
해시함수
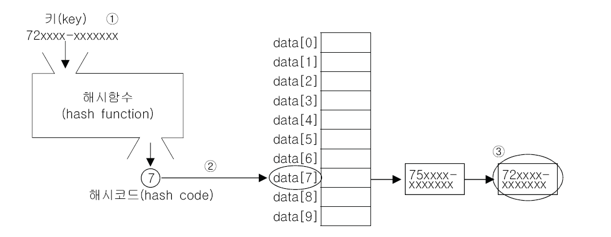
-
키를
input으로 집어넣으면,output으로 해시코드를 반환하는 함수 -
해시함수를 잘 정의하여 해시충돌을 최소화 하는것이 중요하다.
-
Object클래스에 정의된 해시함수는 객체의 주소를 이용하는 알고리즘으로 모든 객체에 대해 유일한 해시코드값을 반환한다. ➔ 해시충돌 x
-
TreeMap
-
key가 정렬되는Map -
이진 검색 트리와
Map의 짬뽕이라고 생각하면됨 -
일반적인 검색성능은
HashMap이 뛰어나다. -
정렬이 필요한 경우
TreeMap을 고려해볼 수 있다.
API : https://docs.oracle.com/en/java/javase/19/docs/api/java.base/java/util/TreeMap.html#method-summary
Collections
- 배열 관련 메서드들을 제공하는
Arrays처럼, 컬렉션 관련 메서드를 제공
Generics , Enums, Annotationk
Generics
-
컴파일 시에 타입 체크를 해주는 기능
- 컴파일 이후엔 사라진다.
.class파일엔 제네릭이 존재하지 않는다.
-
타입 안정성을 높인다.
-
번거로운 형변환을 제거한다.
-
의도하지 않은 타입이 사용되는 것을 막는다.
Generics 용어 정리
class Box<T> {
T item;
void setItem(T item) {
this.item = item;
}
T getItem() {
return item;
}
}
Box<T>: 지네릭 클래스T: 타입 변수Box: 원시 타입
public static void main(String[] args) {
Box<String> stringBox = new Box<>();
}지네릭 클래스 생성
Generics 한계
static멤버에 타입 변수T사용 불가
class Box<T> {
static T item; // 에러 발생
static int compare(T t1, T t2) {
// ...
} // 에러 발생
static멤버는 타입 변수와 무관하게 모든 인스턴스가 동일해야 하기 때문
T타입 배열 생성 불가
class Box<T> {
T[] itemArr; // T 타입 배열의 참조는 선언 가능
T[] toArray() {
T[] tmpArr = new T[itemArr.length]; // 에러 발생
return tmpArr;
}
new연산자는 컴파일 시점에 타입T를 정확히 알아야 한다.
그러나 지네릭을 사용하면Box<T>클래스를 컴파일하는 시점에는T를 정확히 알 수 없다.
와일드 카드
-
?로 표현한다. -
타입의 상한, 하한을 제한할 수 있다.
- 이런식으로 타입을 제한하면 지네릭 클래스가 아니거나,
static메서드에도 지네릭스를 적용할 수 있다.
- 이런식으로 타입을 제한하면 지네릭 클래스가 아니거나,
-
<? extends T>- 와일드 카드의 상한 제한
T와 그 자손들만 가능
-
<? super T>- 와일드 카드의 하한 제한
T와 그 조상들만 가능
-
<?>- 제한 없음
- 모든 타입 가능
지네릭 메서드
-
메서드 선언부에 지네릭 타입이 선언된 메서드
-
지네릭 클래스에 정의된 타입 변수
T와 지네릭 메서드에 정의된 타입 변수T는 연관관계가 전혀 없다.- 지네릭 클래스가 아니더라도 지네릭 메서드를 정의할 수 있다.
static메서드도 지네릭 메서드로 정의할 수 있다.
-
메서드 내에서만 지역적으로 사용되는 타입 매개변수를 선언
- 반환 타입 바로 뒤에 선언한다.
static Juice makeJuice(FruitBox<? extends Fruit> box){
// ...
}지네릭 메서드 사용 전
static <T extends Fruit> Juice makeJuice(FruitBox<T> box){
// ...
}지네릭 메서드 사용 후
<T extends Fruit>를 통해T를 선언- 메서드 내에서 지역변수처럼 사용
public static void printAll(ArrayList<? extends Fruit> list1, ArrayList<? extends Fruit> list2) {
// ...
}지네릭 메서드 사용 전
public static <T extends Fruit> void printAll(ArrayList<T> list1, ArrayList<T> list2) {
// ...
}지네릭 메서드 사용 후
<T extends Fruit>를 통해T를 선언- 메서드 내에서 지역변수처럼 사용
Enums
-
관련이 있는 상수들의 집합
-
정수 열거 패턴의 단점을 보완하는 타입
- 정수 열거 패턴은 타입이 달라도 값이 같으면 조건식 결과가 참
Enum은 타입이 다르면 값이 같아도 조건식 결과가 거짓typesafe
Enums 사용
- 생성
enum Direction {
EAST, SOUTH, WEST, NORTH
}-
사용
-
열거형이름.상수명으로 상수를 사용 -
==비교 가능 -
compareTo()비교 가능 ,<,>는 사용 불가
-
API : https://docs.oracle.com/en/java/javase/19/docs/api/java.base/java/lang/Enum.html#method-summary
public static void main(String[] args) {
Direction d = Direction.EAST;
System.out.println(d);
}출력
EAST-
멤버 추가
-
열거형 상수 이름 옆에 괄호를 통해 원하는 값을 추가할 수 있다.
-
변수와 생성자를 새로 추가해 주어야 한다.
- 생성자는
private제어자 이므로 외부에서 생성할 수 없다.
- 생성자는
-
enum Direction {
EAST(1, ">"), SOUTH(2, "V"), WEST(3, "<"), NORTH(4, "^");
private final int value;
private final String symbol;
Direction(int value, String symbol) {
this.value = value;
this.symbol = symbol;
}
public int getValue() {
return value;
}
public String getSymbol() {
return symbol;
}
}Annotation
-
프로그램 소스코드 안에 다른 프로그램을 위한 정보를 포함시킨 것
-
표준 애너테이션과 메타 에너테이션으로 나뉜다.
표준 애너테이션
-
컴파일러에게 유용한 정보를 제공
-
@Override -
@Deprecated -
@FunctionalInterface등등 ..
메타 애너테이션
- 애너테이션을 정의하는데 사용하는 애너테이션
- 애너테이션의 애너테이션
@Target- 애너테이션이 적용가능한 대상을 지정
- 적용할 대상이 복수인 경우 괄호 사용
@Target(ElementType.METHOD)
public @interface TestAnno {
}
@TestAnno애너테이션은 메서드 위에만 부착 가능
@Retention- 애너테이션이 유지되는 기간을 지정
- SOURCE : 소스 파일에만 존재, 클래스 파일에는 존재 x
- CLASS : 클래스 파일에 존재, 실행시에 사용 불가
- RUNTIME : 클래스 파일에 존재, 실행시에 사용 가능
- 애너테이션이 유지되는 기간을 지정
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface TestAnno {
}
@TestAnno애너테이션은 실행시에도 사용가능
@Documented등등..
애너테이션 요소
-
기본 규칙
-
요소의 타입은 기본형,
String,enum, 애너테이션,Class만 허용 -
매개변수 선언 x
-
예외 선언 x
-
요소를 타입 매개변수로 정의 x
-
public @interface TestAnno {
int id = 100; // 가능
String major(int i, int j); // 매개변수 x
String minor() throws Exception; // 예외선언 x
ArrayList<T> list(); // 타입변수 x
}에러 발생
- 각 요소는 기본값을 가질 수 있다.
public @interface TestAnno {
int count() default 1;
String text() default "Hi";
String[] textArray() default {"Hi", "EveryOne"};
}
@TestAnno그냥 사용시 기본값들이 사용됨
- 요소의 이름이
value인 경우 애너테이션을 적용할 때 요소의 이름을 생략할 수 있다.
@TestAnno("hello")
private static void testMethod() {
}
@TestAnno(value="hello")와 같다.
쓰레드
프로세스와 쓰레드
-
프로세스
- 실행중인 프로그램
- OS로부터 메모리를 할당받아 프로세스가 된다.
- 프로그램을 수행하는 데 필요한 데이터 + 메모리 + 쓰레드 로 구성되어 있다.
- 모든 프로세스는 하나 이상의 쓰레드가 존재
-
쓰레드
- 프로세스 내에서 작업을 처리하는 일꾼
- 별도의 메모리 공간 (호출스택) 을 가진다.
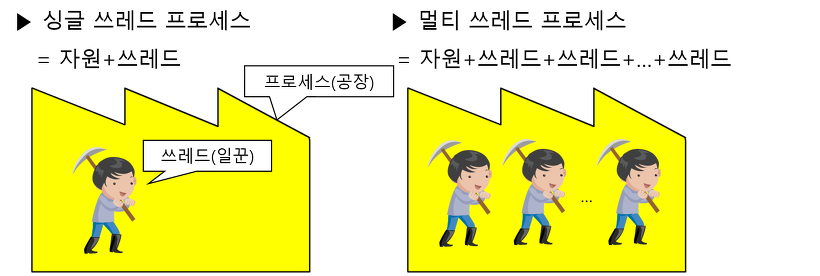
자원 = 데이터 + 메모리
쓰레드 구현
-
Thread클래스 상속 -
Runnable인터페이스 구현- 해당 인터페이스에는
run()만 정의되어 있다. run()을 원하는 동작으로 재정의Runnable을 구현한 인스턴스를Thread클래스의 생성자로 넣어준다.
- 해당 인터페이스에는
public static void main(String[] args) {
Runnable r = new MyThread();
Thread t = new Thread(r);
t.start(); // 쓰레드 실행
}
class MyThread implements Runnable {
@Override
public void run() {
System.out.println("야호");
}
}클래스 생성한 뒤
run()메서드를 재정의
Thread t = new Thread(() -> {
System.out.println("야호"); // 람다식 사용
});
t.start(); // 쓰레드 실행
Runnable인터페이스내의 메서드는run()하나 뿐이므로 람다식으로 대체 가능
쓰레드와 호출스택
-
쓰레드를 실행할 때
run()이 아닌start()를 사용하는 이유는 뭘까? -
run()메서드 호출 시, 새로운 쓰레드를 실행시키는 것이 아니다.- 메인 쓰레드가 단순히 클래스에 선언된 메서드를 호출
-
start()메서드 호출 시, 새로운 쓰레드가 작업을 실행하는데 필요한 호출스택을 생성- 그 다음에 새로운 쓰레드가
run()메서드를 호출
- 그 다음에 새로운 쓰레드가
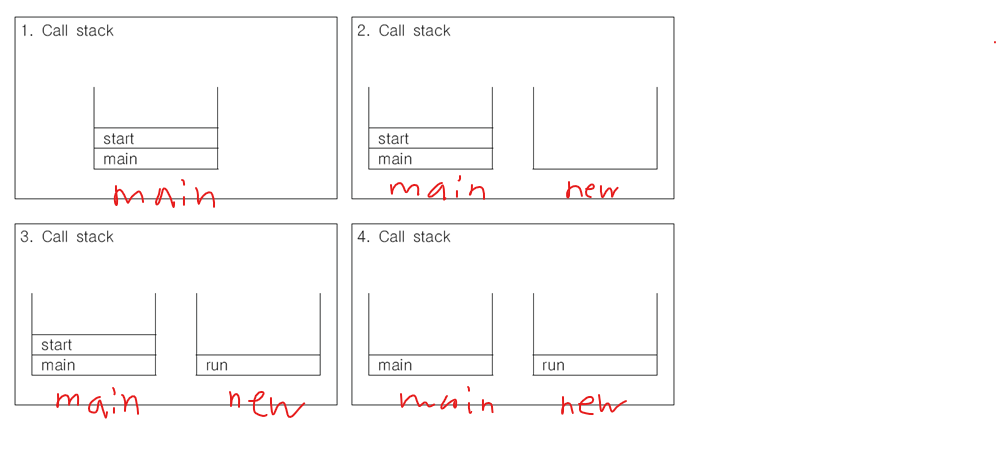
- 메인 쓰레드가
t.start()메서드 호출start()가 새로운 쓰레드를 생성하고, 쓰레드가 작업하는데 필요한 호출스택을 생성- 새로운 쓰레드의 호출스택에
run()메서드 호출 ➔ 독립된 공간에서 작업 수행- 스케줄러가 정한 순서에 의해 메인 쓰레드와 새로운 쓰레드를 번갈아 가면서 실행
싱글쓰레드 vs 멀티쓰레드
-
여러 개의 작업을 몇 개의 쓰레드로 처리하느냐에 따라 싱글쓰레드와 멀티쓰레드로 나뉜다.
-
단순히 CPU 만을 사용하는 계산작업이라면, 멀티쓰레드에서 성능이 떨어진다.
- 쓰레드간의
context switching에 시간이 소요되기 때문
- 쓰레드간의
-
사용자의 입력을 기다리거나, 네트워크로 파일을 주고받는 등의 외부와의 입출력을 필요로 하는 경우엔 효율적이다.
- 기다리는 동안 다른 쓰레드가 작업을 수행할 수 있음
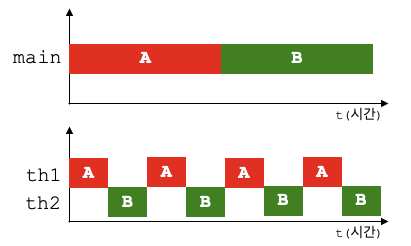
- 상단 : 싱글 쓰레드
- 하단 : 멀티 쓰레드
- 단순한 작업 수행
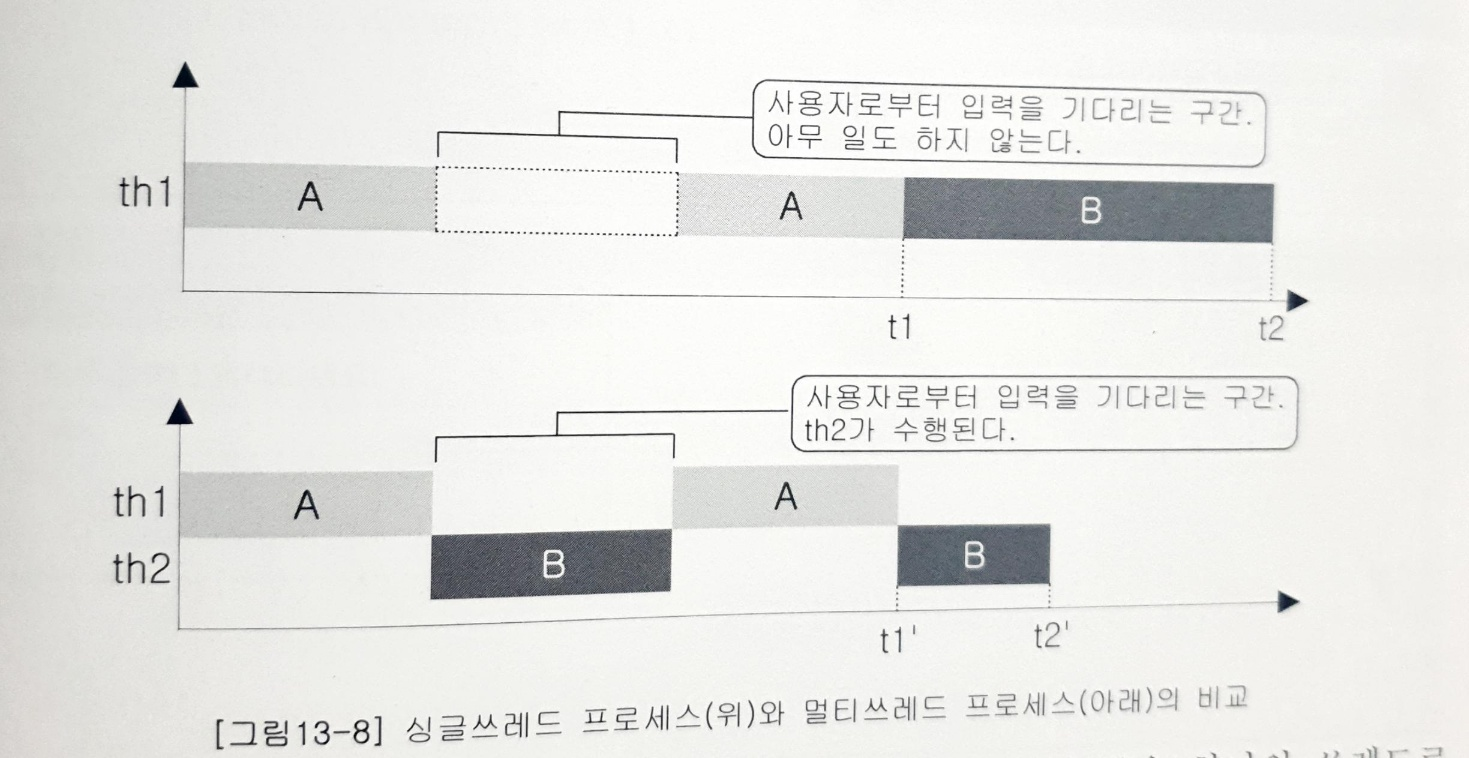
사용자의 입력을 기다리는 구간이 존재하는 작업 수행
멀티쓰레딩의 특징
-
장점
- CPU 사용률 향상
- 자원을 효율적으로 사용
- 사용자에 대한 응답성 증가
- 작업이 분리되어 코드가 간결
-
단점
- 여러 쓰레드가 같은 프로세스 내에서 자원을 공유하기 때문에 동기화, 교착상태 고려 필요
데몬쓰레드
-
일반 쓰레드의 작업을 돕는 보조적인 역할을 수행
-
일반 쓰레드가 모두 종료되면 데몬 쓰레드는 모두 자동 종료된다.
public static void main(String[] args) {
Thread t = new Thread(() -> {
System.out.println("야호"); // 람다식 사용
});
t.setDaemon(true); // 데몬 쓰레드 true 로 설정
t.start(); // 데몬 쓰레드 실행
}쓰레드 실행제어
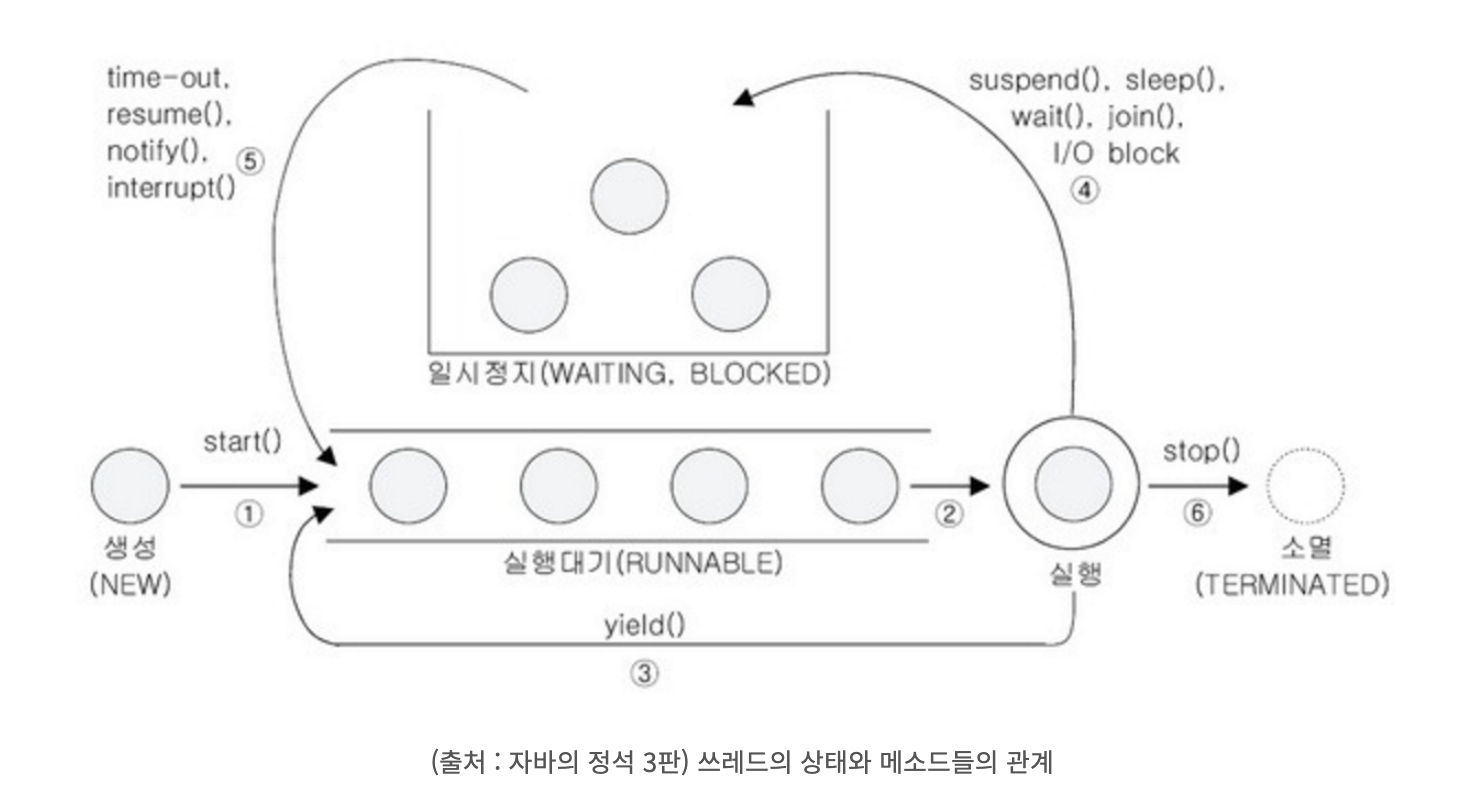
-
쓰레드를 생성하고
start()를 호출하면 실행대기열에 저장되어 자신의 차례가 될 때까지 기다린다. -
실행대기상태에 있다가 자신의 차례가 되면 실행상태가 된다.
-
주어진 실행시간이 다되거나
yield()를 만나면 다시 실행대기상태가 된다. -
해당하는 메서드들에 의해 일시정지상태가 될 수 있다.
-
일시정지 시간이 끝나거나, 해당하는 메서드들에 의해 일시정지를 벗어나 실행대기상태가 된다.
-
실행을 마치거나,
stop()이 호출되면 쓰레드는 소멸한다.
람다와 스트림
람다식
-
메서드를 하나의
식으로 표현- 메서드의 이름이 사라지므로
익명 함수라고도 한다.
- 메서드의 이름이 사라지므로
-
람다식으로 인해 메서드를 변수처럼 다룰 수 있다.
- 매개변수로 전달되거나, 반환값으로 반환될 수 있다.
- 실제로는 메서드를 주고받는 것이 아니라 익명의 객체를 주고받는 것이다.
- 매개변수로 전달되거나, 반환값으로 반환될 수 있다.
-
람다식 덕분에 코드가 간결하고 이해하기 쉬워진다.
public static void main(String[] args) {
List<String> list = Arrays.asList("a", "z", "b", "d", "c");
Collections.sort(list, new Comparator<String>() {
@Override
public int compare(String s1, String s2) {
return s1.compareTo(s2); // 오름차순 정렬
}
});
System.out.println(list); // [a, b, c, d, z]
}
Comparator익명클래스의compare메서드 구현
public static void main(String[] args) {
List<String> list = Arrays.asList("a", "z", "b", "d", "c");
Collections.sort(list, (s1, s2) -> (s1.compareTo(s2))); // 오름차순 정렬
System.out.println(list); // [a, b, c, d, z]
}람다식을 사용하여 위와 같은 동작을 간결하게 수행
람다식의 변수 취급
-
람다식 내에서 외부에 선언된 지역변수를 사용하는 경우
- 사용된 지역변수의 값은 변할 수 없다.
- 해당 지역변수를 상수 취급
-
즉, 람다식은 지역변수의 상태를 변경할 수 없다.
- 람다식이 사용된 메서드의 외부에 존재하는 변수들은 변경할 수 있다.
-
컬렉션 참조에 값을 추가하는 것은 가능하다.
-
람다식의 매개변수 이름은 외부 지역변수와 이름이 중복될 수 없다.
public class PlayGround14 {
private static int outerField = 5;
public static void main(String[] args) {
int val = 30; // 람다식 내부에서 사용하는 순간, 상수 취급
int i = 10; // 람다식 내부에서 사용하는 순간, 상수 취급
MyFunction function = (n) -> {
System.out.println(++n); // 가능
System.out.println(i); // 가능, 변경하지 않고 그냥 사용은 가능
System.out.println(++val); // 에러, 메서드 내부에 존재하는 지역변수는 변경 불가
System.out.println(++PlayGround14.outerField); // 가능, 메서드 외부에 존재하는 변수는 변경가능
};
function.f(i);
i = 15; // 에러, 람다식 내부에서 사용한 변수이기 때문에 변경 불가
}
}
@FunctionalInterface
interface MyFunction {
void f(int i);
}컬렉션 프레임워크와 함수형 인터페이스
-
stream()을 사용하지 않고도 바로 사용할 수 있는 함수형 인터페이스들이 존재한다. -
removeIf(),replaceAll(),forEach()등이 있다.
메서드 참조
-
람다식을 더욱 간결하게 표현하는 방법
-
람다식이 하나의 메서드만 호출하는 경우 사용가능
-
매개변수를 생략하고
클래스이름::메서드이름또는참조변수::메서드이름으로 바꾼다.
s -> s.length() // 람다식
String::length // 메서드 참조() -> new int[]{} // 람다식
int[]::new // 메서드 참조(String kind, int num) -> new Card(kind, num) // 람다식
Card::new // 메서드 참조스트림
-
데이터 집합군을 추상화
- 데이터 집합군이 무엇이던 간에 같은 방식으로 처리할 수 있게 만들었다.
- 코드의 재사용성을 높였다.
-
데이터를 다루는데 자주 사용되는 메서드들을 정의
스트림의 특징
-
스트림은 데이터 소스를 변경하지 않는다.
- 가공된 새로운 결과를 반환한다.
-
스트림은 일회용이다.
-
스트림은 작업을 내부반복으로 처리한다.
-
스트림은 중간연산과 최종연산이 있다.
- 중간 연산 : 연산 결과가 스트림, 계속해서 중간 연산을 덧붙일 수 있다.
- 최종 연산 : 연산 결과가 스트림이 아님, 스트림의 요소를 소모하므로 마지막으로 한번만 가능
-
스트림은 연산을 지연한다.
- 중간 연산은 최종 연산이 수행되기 전까지 수행하지 않는다.
.sorted() + Comparator.comparing()
-
중간 연산 스트림
-
스트림을 정렬
Comparator를 사용하여 스트림을 정렬Comparator를 사용하지 않으면 스트림 요소의Comparable정렬 기준으로 기본 정렬
strStream.sorted() // 기본정렬
strStream.sorted(Comparator.reverseOrder()) // 기본정렬의 역순
단순 비교
class StudentTest {
String name;
int ban;
int score;
public StudentTest(String name, int ban, int score) {
this.name = name;
this.ban = ban;
this.score = score;
}
String getName() {
return name;
}
int getBan() {
return ban;
}
int getScore() {
return score;
}
@Override
public String toString() {
return "StudentTest{" +
"name='" + name + '\'' +
", ban=" + ban +
", score=" + score +
'}';
}
}객체간의 비교를 위한
StudentTest클래스
List<StudentTest> students = List.of(
new StudentTest("김", 3, 100),
new StudentTest("이", 1, 50),
new StudentTest("박", 2, 100),
new StudentTest("황", 1, 90),
new StudentTest("황", 3, 90),
new StudentTest("김", 3, 90)
);
students.stream()
.sorted(Comparator.comparing((StudentTest s) -> s.getBan()) // 반으로 오름차순 정렬
.thenComparing(s -> s.getScore() * -1) // 점수로 내림차순 정렬
.thenComparing(s -> s.getName())) // 이름으로 오름차순 정렬
.forEach(System.out::println);
}
comparing,thenComparing을 사용한 중첩 비교s가 무엇인지 추론하지 못하기 때문에(StudentTest s)로 타입선언 필요
출력결과
StudentTest{name='이', ban=1, score=50}
StudentTest{name='황', ban=1, score=90}
StudentTest{name='박', ban=2, score=100}
StudentTest{name='김', ban=3, score=90}
StudentTest{name='황', ban=3, score=90}
StudentTest{name='김', ban=3, score=100}Optional
-
스트림의 최종 연산 중엔
Optional타입을 반환하는 것들이 있다.Optional은 무엇일까?
-
최종 연산의 결과를 그냥 반환하지 않고,
Optional객체에 담아서 반환하는 것- 반환 결과가
null인지 체크하지 않아도Optional메서드를 사용해 간단히 처리 가능 null체크를 하지 않아도NullPointerException이 발생하지 않음- 간결하고 안전한 코드 작성
- 반환 결과가
-
Optional객체 생성하기Optional.ofNullable()Optional.empty()
Optional<String> optStr = Optional.ofNullable("Hi");
Optional<String> optNull = Optional.ofNullable(null);
Optional<String> empty = Optional.empty();출력 결과
optStr = Optional[Hi]
optNull = Optional.empty
empty = Optional.empty
empty값 은null값과 같다.
-
Optional객체 값 가져오기-
get()- 값을 반환
-
orElse(반환값)- 만약 값이 null 인 경우 지정한 반환값을 반환
-
orElseGet(메서드)- 만약 값이 null 인 경우 메서드를 수행, 메서드의 반환값을 반환
-
orElseThrow()- 만약 값이 null 인 경우 지정하고 싶은 예외를 발생
-
String s1 = optStr.get();
String s2 = optStr.orElse("값없음");
String s3 = optNull.orElse("값없음");출력결과
s1 = Hi
s2 = Hi
s3 = 값없음=====주의사항=====
orElse()내부에 메서드를 넣어줄 경우,Optional객체의null여부 상관없이 메서드를 실행한다.
public T orElse(메서드()) {
return value != null ? value : 메서드();
}orElseGet()내부에 메서드를 넣어줄 경우,Optional객체가null이 아닌 경우 메서드를 실행하지 않는다.
public T orElseGet(Supplier<? extends T> other) {
return value != null ? value : other.get();
}- 따라서 메서드를 매개변수로 넣어주고 싶은 경우,
orElseGet()을 사용하는 것이 안전하다.
- 따라서 메서드를 매개변수로 넣어주고 싶은 경우,
=====주의사항 끝=====
Optional객체가 존재하는 경우 동작 수행ifPresent()
optStr.ifPresent(System.out::println); // 출력결과 Hi
optStr객체 내부에Hi가 존재하므로ifPresent내부의 메서드 수행
.collect() 와 Collectors 클래스
-
최종 연산 스트림
-
스트림 요소들을 수집하여 반환
-
Collectors클래스에 요소들을 어떻게 수집할 것인가에 대한 방법들이 정의되어 있다. -
스트림을 컬렉션과 배열로 변환
-
toList() -
toSet() -
toMap()- 객체의
key와value를 지정해주어야 한다.
- 객체의
-
toCollection()- 원하는 구현체의 생성자 참조를 매개변수로 넣어준다.
-
toArray()
-
List<String> names = students.stream().map(s -> s.getName())
.collect(Collectors.toList()); // List로 반환
ArrayList<String> list = students.stream().map(s -> s.getName())
.collect(Collectors.toCollection(ArrayList::new)); // ArrayList로 반환
Map<String, Person> map = persons.stream()
.collect(Collectors.toMap(p->p.getRegId(), p->p)); // Map으로 반환-
문자열 스트림 결합
-
joining() -
스트림의 모든 요소를 하나의 문자열로 연결해서 반환
-
구분자 지정 가능
-
String collectedNames = students.stream().map(s -> s.getName()).collect(Collectors.joining()); // 구분자 없음
String collectedNamesWithComma = students.stream().map(s -> s.getName()).collect(Collectors.joining(", ")); // 구분자 ", "
String collectWithFix = students.stream().map(s -> s.getName()).collect(Collectors.joining(", ", "[", "]")); // 구분자 ", " , prefix "[", suffix "]"students 이름 = 김제동, 이제동, 박제동, 황현, 황제동, 김밥
출력결과
구분자 없음 : 김제동이제동박제동황현황제동김밥
구분자만 있음 : 김제동, 이제동, 박제동, 황현, 황제동, 김밥
구분자와 접두사, 접미사 있음 : [김제동, 이제동, 박제동, 황현, 황제동, 김밥]출처
자바의 정석2 - 남궁성님
orElse,orElseGet차이: https://ysjune.github.io/posts/java/orelsenorelseget/


진짜로 재밋게 읽었나요??