
KOCW 컴퓨터구조 (최규상 교수님) 강의를 보고
-
중요하다고 생각되는 내용을 정리하였다.
-
컴퓨터 구조 및 설계 (David A. Patterson) 책도 빌려서 보긴 했는데 어려워서 거의 이해 못했다.
정리한 Chapter
-
컴퓨터 추상화 및 관련 기술
-
명령어: 컴퓨터 언어
-
프로세서
-
메모리 계층 구조
컴퓨터 추상화 및 관련 기술
포스트 PC 시대
-
PMD
- Personal Mobile Device
- 무선으로 인터넷에 연결되는 소형 기기
-
Cloud Computing
- Cloud Computing
- 구글과 아마존과 같은 회사들이 100000 개 이상의 서버들을 가진 WSC (Warehouse-scale computing) 를 구축하고 다른 회사들에게 서버를 임대하는 방식
- 회사들이 자체적으로 WSC를 구축하지 않고 소비자들에게 필요한 서비스를 제공할 수 있다.
- SaaS
- Software as a Service
- 서비스로서의 소프트웨어
- 로컬 기기에서의 설치과정없이, 브라우저에서 바로 실행되는 가벼운 프로그램
- 웹 검색, SNS와 같은 서비스들이 이에 해당
- Cloud Computing 에 의해, 회사들은 SaaS 개발에만 집중할 수 있다.
컴퓨터 계층화
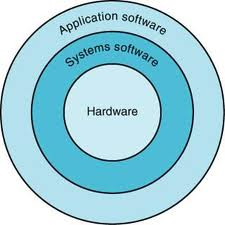
- 응용 소프트웨어
- 유저가 사용하는 응용 프로그램들
- 시스템 소프트웨어
- 운영체제
- 응용 소프트웨어와 하드웨어 간의 인터페이스 역할
- 각종 서비스와 감독 기능을 제공
- 기본적인 입출력 작업 처리
- storage와 메모리 관리
- 프로세스 스케줄링
- 하드웨어
- 실제 물리적인 컴퓨터 장치들
무어의 법칙
- Number of transistors that can be integrated on single chip would double about every two years.
성능의 척도
-
Response Time (Execution Time)
- 해당 작업을 처리하는 데 걸리는 시간
- 가장 기본적인 성능 척도
- Response Time 의 감소는 Throughput 도 증가시킨다.
-
Throughput
- 일정한 시간 동안 처리하는 작업 양
- Throughput 의 증가가 Response Time의 감소에 영향을 주진 않는다.
CPU 실행시간
-
프로세서가 순수하게 프로그램을 실행하기 위해 소비한 시간
-
Elapsed Time 과는 다르다. (프로그램을 끝내는데 걸린 모든 시간, I/O 와 작업시간등을 포함)
-
User CPU Time
- 사용자 프로그램 자체에 소비된 CPU 시간
-
System CPU Time
- 프로그램 수행을 위해 운영체제가 소비한 CPU 시간
- CPU Clock Cycles : 작업을 수행하는 데 필요한 클럭 개수
- Clock Cycle Time : 한 클럭당 수행 시간
- Clock Rate : 1초당 수행하는 클럭 수
CPU 실행시간 예제
문제 : 2GHz 클럭의 컴퓨터 A에서 10초 수행되는 프로그램이 있다. 이 프로그램을 6초 동안에 실행할 컴퓨터 B를 설계하고자 한다. 클럭 속도는 얼마든지 빠르게 만들 수 있는데, 이렇게 하면 CPU 다른 부분의 설계에 영향을 미쳐 같은 프로그램에 대해 A보다 1.2배 많은 클럭 사이클이 필요하게 된다고 한다. 컴퓨터 B의 클럭속도는 얼마로 해야 하겠는가?
풀이


성능 측정 요약
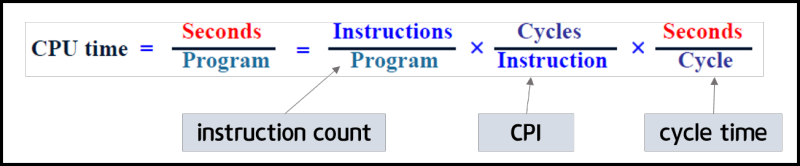
Cycle부분은Clock Rate로 해석하는 것이 자연스러워 보인다.
Power wall
-
새로운 공정기술이 나올 때마다 전압은 낮아지고, 이로인해 소비전력을 낮출 수 있었다.
- 성능을 높이는데 (Clock Rate를 올리면서) 큰 부담이 없었다.
-
오늘날에 이르러, 성능을 높이면서 더이상 전압을 낮출 수 없게되었다.
-
이로 인해 전력소모를 더이상 낮출 수 없고, CPU에서 발생하는 열을 낮출 수 없게 되었다.
-
이러한 배경에서 성능을 높이기 위해 도입한 것이 바로 Multi-Processor 방식이다.
- 이로 인해 Parallel Programming 이 대두
- Multi-Processor 에서는 Parallel Program 이어야 성능 향상 가능
암달의 법칙

-
일부의 성능 개선으로 전체의 성능을 개선하는데에는 한계가 있다.
-
컴퓨터의 한 부분만을 개선하였을 때, 개선한 만큼 컴퓨터의 전체 성능이 좋아지지 않는다.
- 따라서 어떤 부분을 개선하느냐가 성능에 큰 영향을 미친다.
- 가장 많이 사용되는 부분을 향상시킨다면 많은 성능 개선이 이루어진다.
명령어: 컴퓨터 언어
Instruction Set
-
다른 컴퓨터들은 다른 Instruction set을 가진다.
- 공통적인 특성들도 존재
-
초창기 컴퓨터들은 매우 단순한 Instruction set을 가진다.
-
최근 컴퓨터들 역시 단순한 Instruction set을 가진다.
ISA
-
Instruction Set Architecture
-
하드웨어와 가장 낮은 레벨의 소프트웨어 (시스템 소프트웨어) 간의 인터페이스
MIPS 에서의 Design Principle
-
Simplicity favours regularity
-
간단하게 하기 위해서는 규칙적인 것이 좋다.
-
ex) Arithmetic 연산은 모두 유사하다.
-
-
Smaller is faster
-
작은 것이 더 빠르다.
-
Register는 Main memory 보다 할당할 수 있는 크기가 작다.
- Register가 작지만 훨씬 빠르다.
-
-
Make the common case fast.
-
자주 생기는 일을 빠르게 하라.
-
ex) addi 와 같은 명령어 통해 자주 발생하는 작은 상수값 연산을 load 명령어 없이 빠르게 수행
-
-
Good design demands good compromises
- 좋은 설계에는 적당한 절충이 필요하다.
- ex) MIPS I-format Instructions 는 constant를 사용하는 addi 연산과 address offset 을 사용하는 load/store 명령어를 모두 커버한다.
Register
Byte Address
-
8-bit ➔ 1-Byte
-
워드
- 컴퓨터의 데이터 기본 처리 단위
- 32-bit 운영체제 ➔ 4바이트 = 워드
- 64-bit 운영체제 ➔ 8바이트 = 워드
-
Alignment restriction (정렬 제약)
-
메모리 내에서 데이터는 자연스러운 경계를 지키며 정렬된다.
-
따라서 데이터는 워드 단위로 정렬되고, 워드 단위로 접근할 수 있다.
-
-
워드에 데이터를 저장하는 방식
-
Big Endian
- 오른쪽 끝에 가장 큰 값(MSB)이 들어간다.
-
Little Endian
- 오른쪽 끝에 가장 작은 값(LSB)이 들어간다.
-
Registers vs Memory
-
Register 가 Memory 보다 빠르다.
- 따라서 Memory 에 접근하는 Load, Store 명령어는 느리다.
-
MIPS 프로세서에서 메모리에 있는 데이터에 연산을 하고 싶은 경우
- 연산을 직접 하지 못한다.
- Load 명령어를 통해 데이터를 Register 에 올리고 ➔ 연산을 수행하고 ➔ Store 명령어를 통해 데이터를 메모리에 다시 저장
- Load - Store Architecture
-
컴파일러에서 Register Optimization 이 매우 중요한 이유이다.
MIPS R-format Instructions

-
op : operation code
-
rs : first source register number
-
rt : second source register number
-
rd : destination register number
-
shamt : shift amount
-
funct : function code
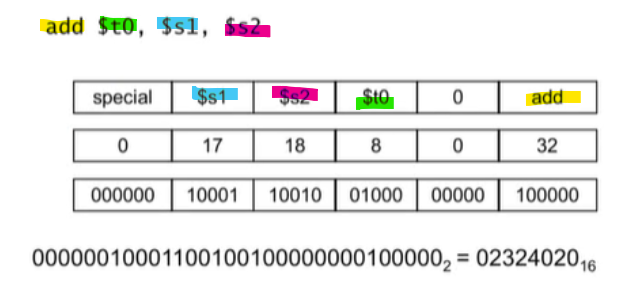
Example
MIPS I-format Instructions

-
rt : destination
-
immediate : constant (-2^15 ~ 2^15-1)
-
address : offset added to base address (rs)

Example,
$t0 = $s3[13]
Basic Blocks
-
중간에 브랜치 명령어가 없고
-
중간에 브랜치 타겟(Label)이 없는 명령어들의 집합
-
컴파일러는 이러한 Basic Blocks 를 찾아 성능 최적화
6 steps in Execution of a Procedure
-
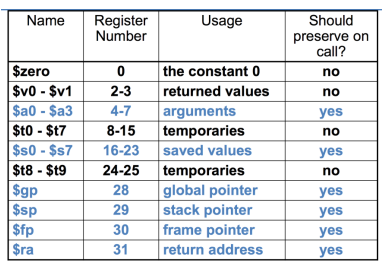
Caller 가 Callee 가 접근할 수 있는 곳에 인수를 넣는다.
$a0 ~ $a3: argument registers
-
Caller 가 Callee 에게 제어권을 넘긴다.
-
Callee 가 필요로 하는 메모리 자원을 획득한다.
-
Callee 의 작업을 수행한다.
-
Callee 작업의 결과값을 Caller가 접근할 수 있는 곳에 넣는다.
$v0 ~ $v1: result value registers
-
Callee 가 Caller 에게 제어권을 다시 넘긴다.
$ra: return address register
Procedure Call Instructions
-
Procedure call
jal ProcedureLabel- 그 다음 명령어의 주소를
$ra에 저장 ProcedureLabel로 이동
-
Procedure return
jr $ra$ra를 Program counter 에 저장- 따라서,
$ra로 이동
Leaf Procedure Example
- 다른 함수를 호출하지 않는 함수
int leaf_example (int g, h, i, j) {
int f;
f = (g + h) - (i + j);
return f;
}
- arguments
g, h, i, j➔$a0, $a1, $a2, $a3f➔$s0, 따라서$s0는 스택에 저장되어야 한다.- result in
$v0


$s0은 이전 내역이 지워지면 안되는 레지스터이므로 스택에 저장됨$t0, $t1은 지역변수이므로 스택에 저장됨leaf procedure이므로, 인수들은 스택에 저장 안해도 됨
Non-Leaf Procedure Example
- 함수 내에서 다른 함수를 또 다시 호출하는 함수
int fact (int n) {
if (n < 1) return f;
else return n * fact(n - 1);
}
- arguments
n➔$a0- result in
$v0
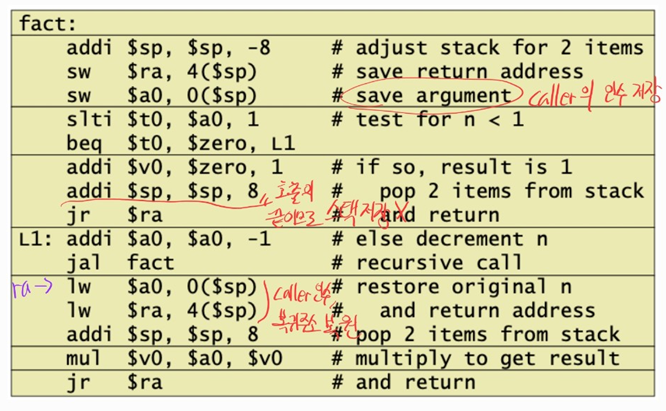
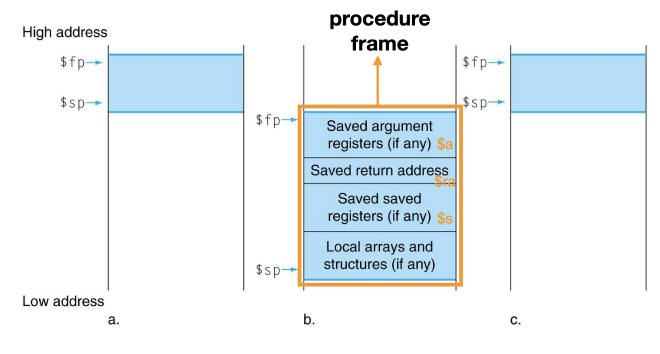
non-leaf procedure는 이전에 caller에서 사용한 인수($a0)와, callee 에서 사용한 인수가 중복사용될 수 있으므로, stack 에 저장해야한다.Local arrays and structures영역은, 함수내에서 사용되는 지역변수의 저장 영역$fp(시작주소) 와$sp(끝주소) 를 통해 각각의procedure frame을 구분할 수 있다.
Memory Layout
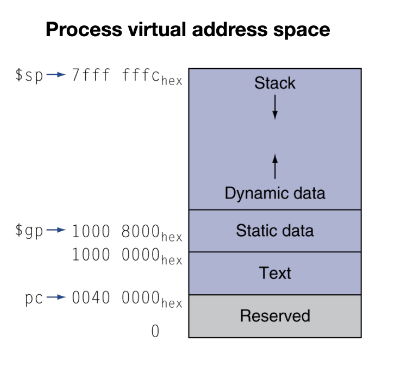
뒤집어서도 많이 표현한다.
-
Text segment
- 프로그램 코드 (기계어 코드)가 들어간다.
-
Static data segment
- 상수, 전역 변수, 배열등이 들어간다.
-
Heap
- 힙에 동적으로 공간을 할당하여 사용할 수 있다.
- 할당한 공간의 주소는 스택에 저장된다.
-
Stack
- 여러가지 변수와 주소들을 저장한다.
Branch Addressing

16bits 영역이 offset 임
-
PC-relative addressing
-
Program Counter 에 offset 을 더하는 방식으로 주소 이동
-
-
Branch 명령어의 목적지는 대부분 근접한 위치에 있기 때문에 이런 간접적인 이동방식을 사용
-
Jump Addressing

-
Direct jump addressing
-
직접 이동방식
-
- address * 4 bits 는 총 28bits 임
- PC 상위 4bits + address*4 bits 로 주소를 설정
-
Addressing Example
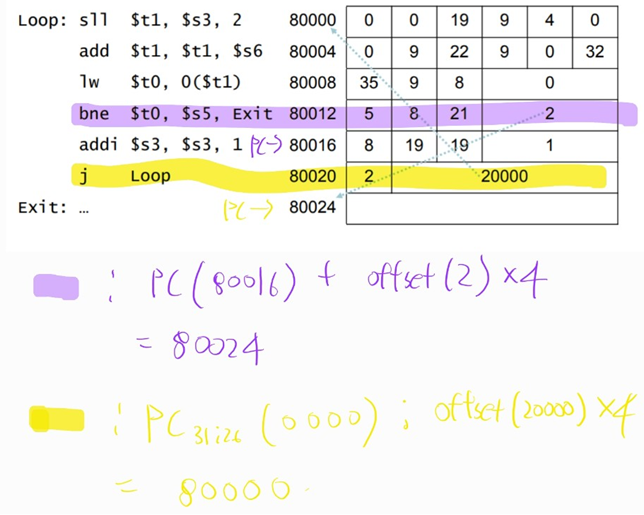
Addressing Mode Summary in MIPS
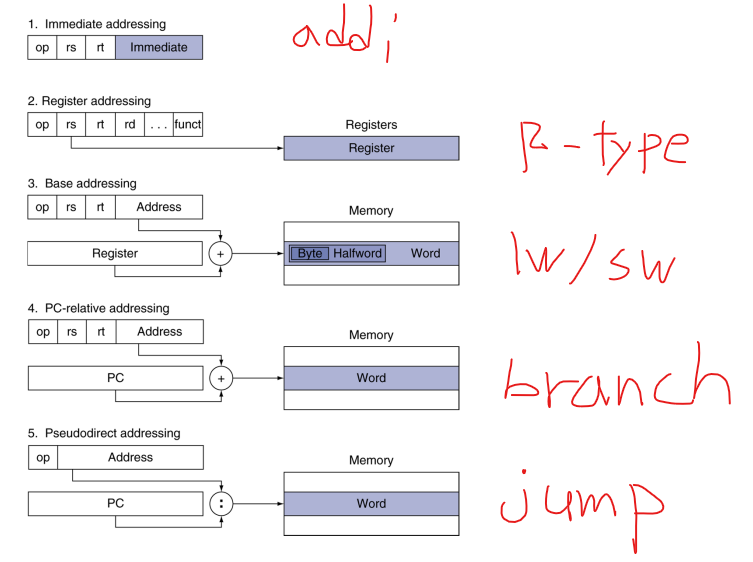
Addressing Mode(주소지정 방식)의 5가지 종류
Translation and Startup
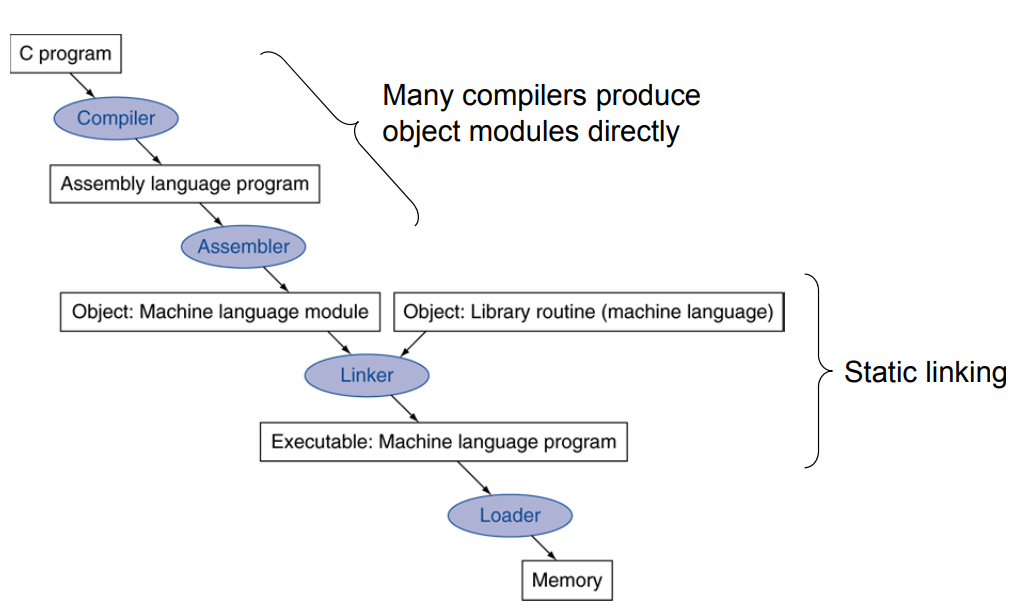
Static-linking방식
-
Compiler
- 프로그래머가 작성한 프로그램 ➔ 어셈블리 프로그램
-
Assembler
- 어셈블리 프로그램 ➔ 기계어 프로그램
-
Linker
-
Static Linking 방식
- 프로그램 실행에 필요한 라이브러리들을 합쳐서 실행파일을 만들어줌
- 라이브러리를 호출하는 가장 빠른 방법
- 라이브러리 루틴이 실행 코드의 일부가 되므로, 파일의 크기가 커진다.
-
Dynamic Linking 방식
- 프로그램 실행 전에는 라이브러리가 링크되지 않는다.
- 프로그램 실행 시에 라이브러리가 링크된다.
- 라이브러리 업데이트 사항이 반영된다.
- 파일의 크기가 작아진다.
- 첫 호출시 큰 오버헤드가 발생한다.
-
-
Loader
- 저장장치에 존재하는 실행파일 ➔ 메모리 위로 올려 프로그램을 실행
Loading a Program
Loader는 다음 순서로 일을 진행한다.
-
실행 파일 헤더를 읽어 텍스트와 데이터 세그먼트 크기를 파악
-
텍스트와 데이터가 들어갈 만한 가상의 주소 공간 확보
-
실행파일의 명령어와 데이터를 메모리에 복사(저장)
-
프로그램에 전달해야 할 인수가 있으면, 이를 스택에 복사(저장)
-
레지스터 초기화
-
프로그램의 시작 루틴을 호출
- ex)
main함수 - 시작 루틴이 끝나면 exit 시스템 호출 ➔ 프로그램 종료
- ex)
Intel 프로세서의 특징과 성능의 비결
-
Intel 프로세서는 CISC
- Complex Instruction Set Computer
- Complex Instruction 은 느린 Clock 을 필요로 한다. ➔ Simple Instruction 도 느린 Clock 에 맞추게 된다.
- 따라서 RISC 대비 성능이 떨어진다.
-
MIPS 프로세서는 RISC
- Reduced Instruction Set Computer
-
Intel 프로세서는 복잡한 명령어를 간단한 명령어 여러개로 내부적으로 나누어 실행
- 이를 통해 RISC와 비슷한 성능을 낼 수 있다.
- 즉, 내부적으로는 RISC와 유사하다.
프로세서
Combinational Element
- input을 조합하여 output을 만들어내는 함수
Sequential Element
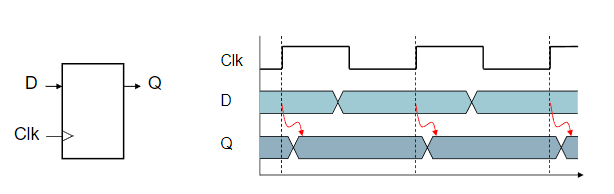
D = input,Q = output- Edge-triggered (rising-edge)
- 정보를 저장
- input 과 현재 상태에 따라서 값이 바뀐다.
- clock 에 맞춰 업데이트
Performance Issues
-
Clock period 는 가장 오래걸리는 명령어에 맞춰진다.
load instruction- 각각의 명령어 별로 다른 Clock period 를 갖출 수 없기 때문
-
이러한 성능 저하를 해결하기 위해 파이프라이닝을 사용한다.
Pipelining
-
여러 명령어가 중첩되어 실행되는 구현 기술
-
동시에 여러개의 명령어를 처리함으로써 처리량을 올리는 것
- 단일 명령어를 처리하는 시간이 빨라지진 않는다.
- 그러나 명령어가 많을 경우 처리량이 증가하므로, 전체 시간을 단축시킨다.
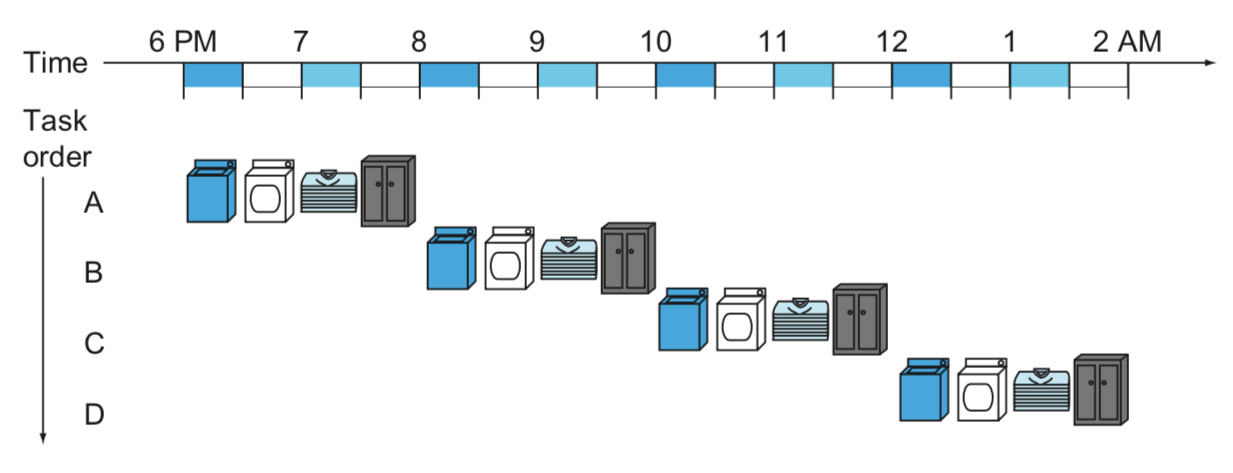
- 파이프라이닝을 적용하지 않은 세탁소
- 4묶음을 처리하는데 총 8시간 소요
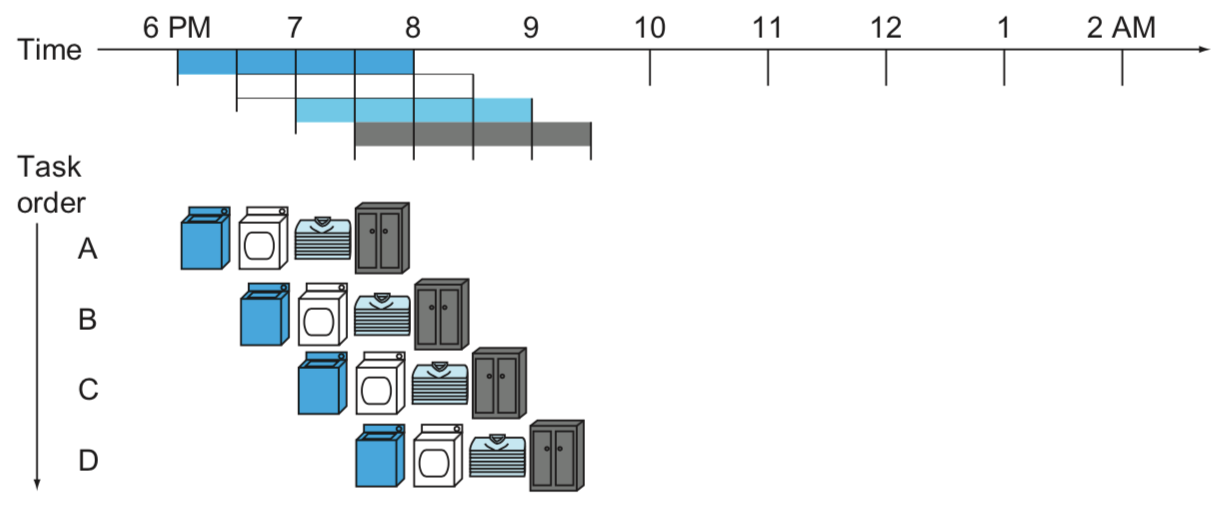
- 파이프라이닝을 적용한 세탁소
- 4묶음을 처리하는데 총 3.5시간 소요
MIPS Pipeline
MIPS 파이프라인은 다섯 단계를 가진다.
-
IF: Instruction fetch from memory -
ID: Instruction decode & register read -
EX: Execute operation or calculate address -
MEM: Access memory operand -
WB: Write result back to register
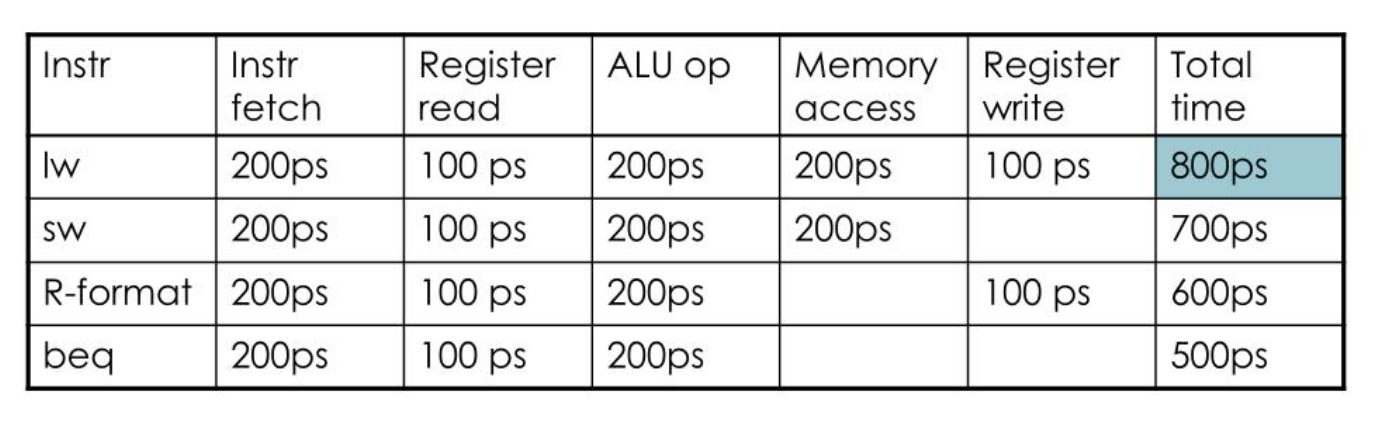
각 단계별로 걸리는 시간
Pipeline Speedup
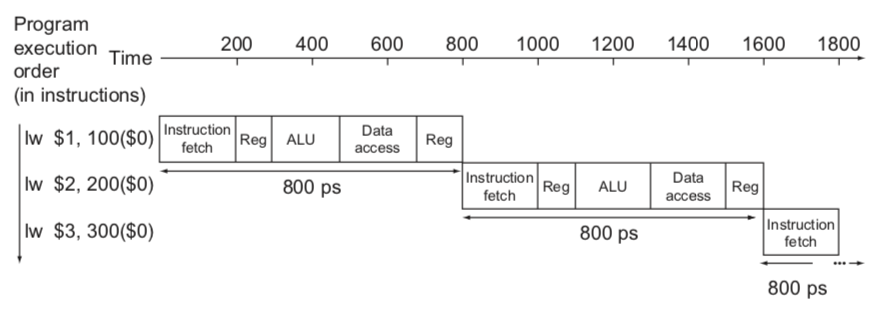
Tc = 800ps- Single-cycle 방식은 가장 긴 명령어 실행시간(800ps)에 clock period 가 맞춰진다.
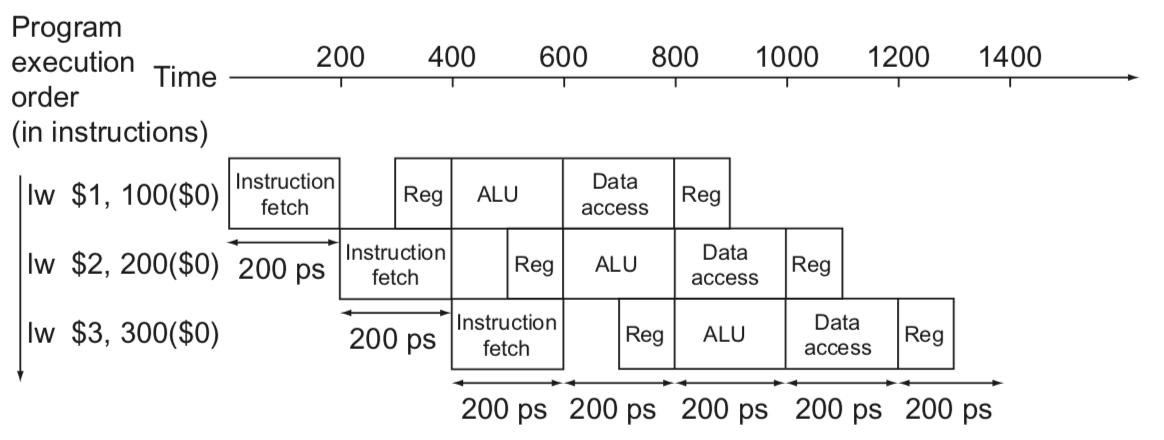
Tc = 200ps- Pipelined 방식은 가장 긴 단계 실행시간(200ps)에 clock period 가 맞춰진다.
- 만약 모든 단계들의 실행시간이 비슷하다면, 성능은 단계들의 개수만큼 향상된다.
- 실제로는 실행시간이 비슷하지 않으므로, 이보다는 성능이 향상되지 못한다.
Hazards
-
파이프라인 구조에서 발생하는 문제
-
다음 cycle 에 다음 명령어를 실행하지 못하는 경우를 말한다.
- 이렇게 기다리는 경우를 stall 이라 한다.
- 이 경우, 아무것도 하지 않는 bubble 을 발생시킨다.
-
3가지 종류가 있다.
- Structure hazards
- Data hazards
- Control hazards
Structure Hazards
-
리소스 사용의 충돌로 인해 발생
-
하나의 메모리에 두 개의 명령어가 동시에 접속할 수 없다.
MEM과IF가 동시에 이루어질 수 없다.
-
하나의 메모리를 instruction memory (
IF에서 접근) 와, data memory (MEM에서 접근)로 분리하여 해결할 수 있다. -
리소스를 추가하여 해결할 수 있다.
Data Hazards
-
데이터 종속성에 의해 발생
-
앞선 명령어의 결과가 바로뒤의 명령어에서 입력으로 필요할 때 발생
-
ex)
add $s0, $t0, $t1
sub $t2, $s0, $t3뒤의 명령어가, 앞의 명령어의 결과
$s0에 의존적이다.
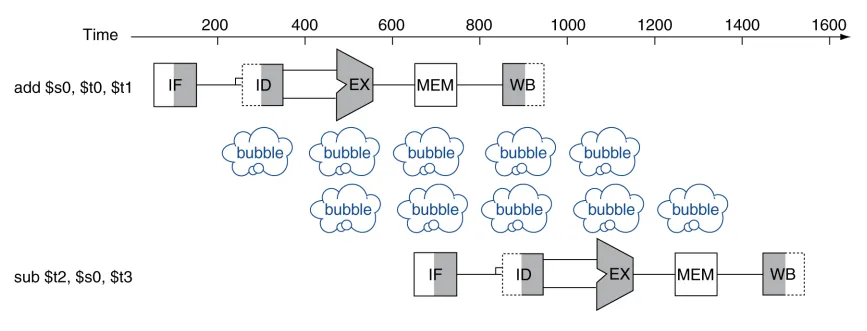
- 앞선 명령어의
WB 전반부에서 연산 결과를$s0레지스터에 저장- 뒷 명령어의
ID 후반부에서$s0레지스터를 읽기 위해 2 stalls 발생
Data Hazards - Forwarding
-
Data Hazards 의 대표적인 해결방법
-
어떤 Data의 연산 결과값이 나오면, 그 결과를 바로 사용한다.
- 레지스터에 저장 (
WB) 되는 것을 기다리지 않는다.
- 레지스터에 저장 (
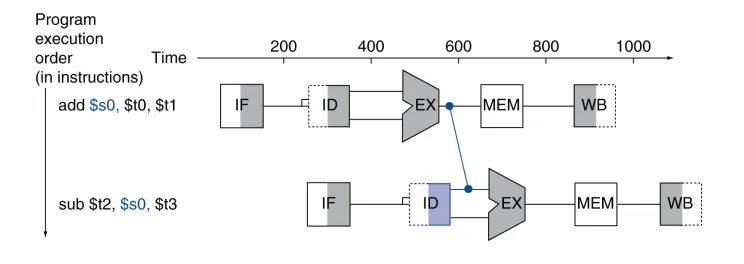
stall 이 사라진다.
Data Hazards - Load-Use Data Hazard
-
Data hazards 는 다양한 이유로 발생한다.
-
그 중 하나인, Load-Use Data hazard의 경우엔 forwardingd 으로도 stall의 발생을 막을 수 없다.
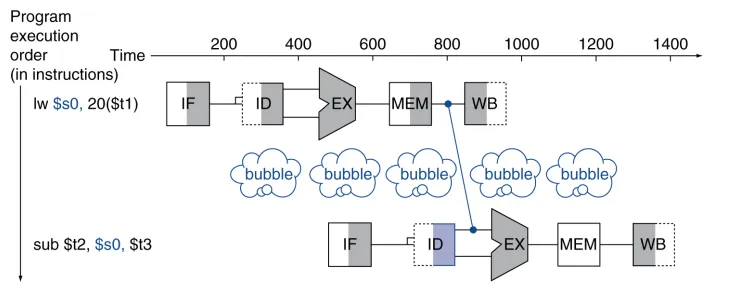
- 앞선 명령어의
MEM에서 불러온 결과를$s0레지스터에 저장- Forwarding을 하더라도, 1 cycle stall 발생
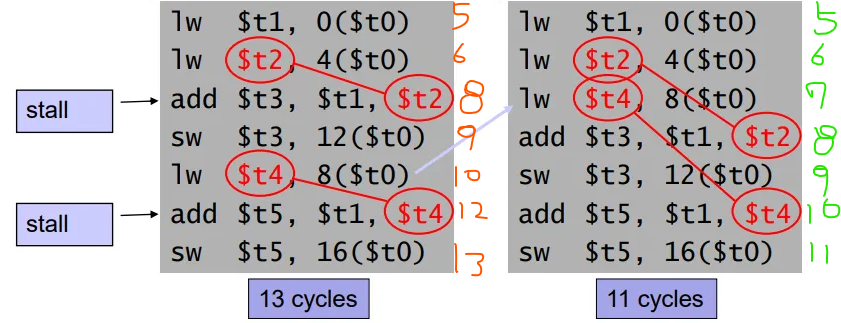
Data Hazards - Code Scheduling
- Load result 를 다음 명령어에서 사용하지 않도록 코드를 변경하면, stall 의 발생을 줄일 수 있다.
Control Hazards
- 브랜치에 의해 다음에 실행할 명령어가 바뀔 수 있다.
- 따라서 파이프라인은 항상 다음에 실행할 명령어를 맞출 수 없다.
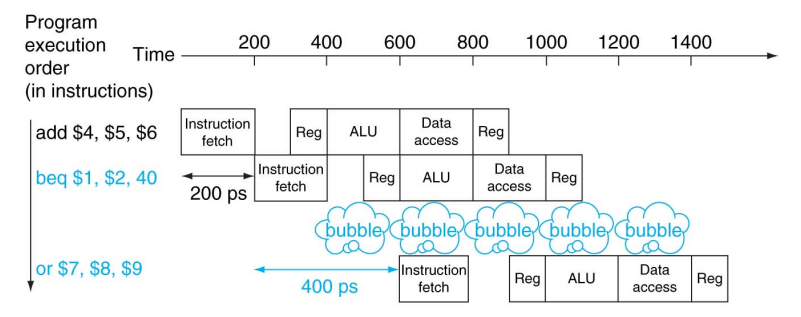
- 전 명령어의
ID단계가 끝나야 어디로 분기할지 알 수 있다.- 1 cycle stall 이 발생
Control Hazards - Branch Prediction
-
브랜치의 결과를 미리 예측할 수 있다.
- 예측이 맞으면 ➔ stall 이 발생하지 않는다.
- 예측이 틀리면 ➔ stall 이 발생한다.
-
MIPS의 경우 분기가 항상 발생하지 않는다고 예측한다.
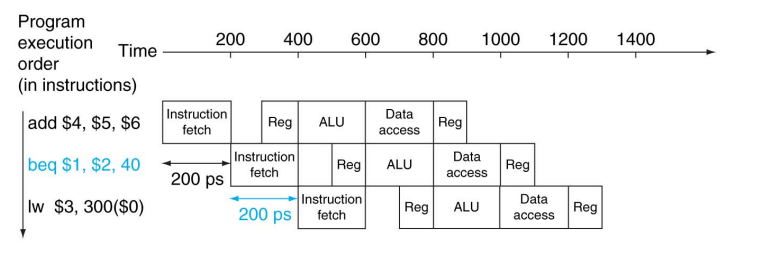
예측이 맞은 경우
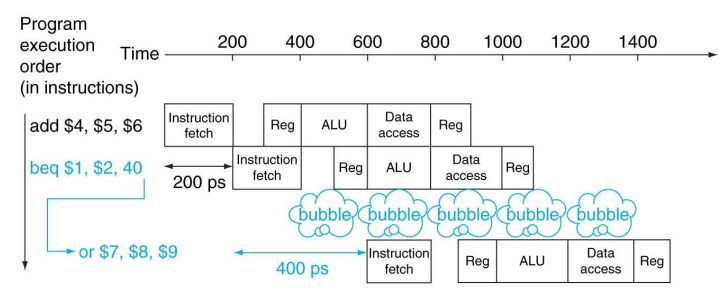
예측이 틀린 경우, stall 발생
메모리 계층 구조
메모리 계층 구조
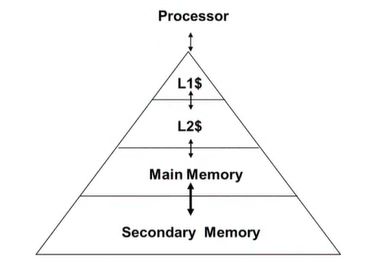
L1,L2는 캐시 (SRAM)- Main Memory 는 DRAM
-
위 계층일수록 접근속도 ⬆, 비트당 비용 ⬆
-
아래 계층일수록 사이즈 ⬆
Principle of Locality
-
지역성의 원칙
- 프로그램은 어떤 특정 시간에는 주소공간내의 비교적 작은 부분에만 접근한다.
- 자주 접근할 것 같은 정보들을 더 상위의 메모리 계층에 저장함으로써, 성능향상 가능
-
Temporal locality
- 시간적 지역성
- 최근 찾은 정보를 가까운 시간내에 다시 찾을 확률이 높다.
-
Spatial locality
- 공간적 지역성
- 최근 찾은 정보의 근처에 있는 정보들을 뒤이어 찾을 확률이 높다.
Caching
-
캐시는 CPU와 가장 근접한 메모리이다.
-
Direct mapped cache
- 직접 사상 캐시
- 메인 메모리를 적절한 크기로 나눈 각 블록들이 캐시 내의 정확히 한 곳에만 사상되는 구조
- 각 블록들은 캐시 내에 저장될 위치가 한 곳으로 정해져 있다.
-
Associative cache
- 연관 캐시
- 메인 메모리를 적절한 크기로 나눈 각 블록들은 캐시 내에서 n개의 배치 가능한 위치를 갖는다.
- n-way set associative 캐시
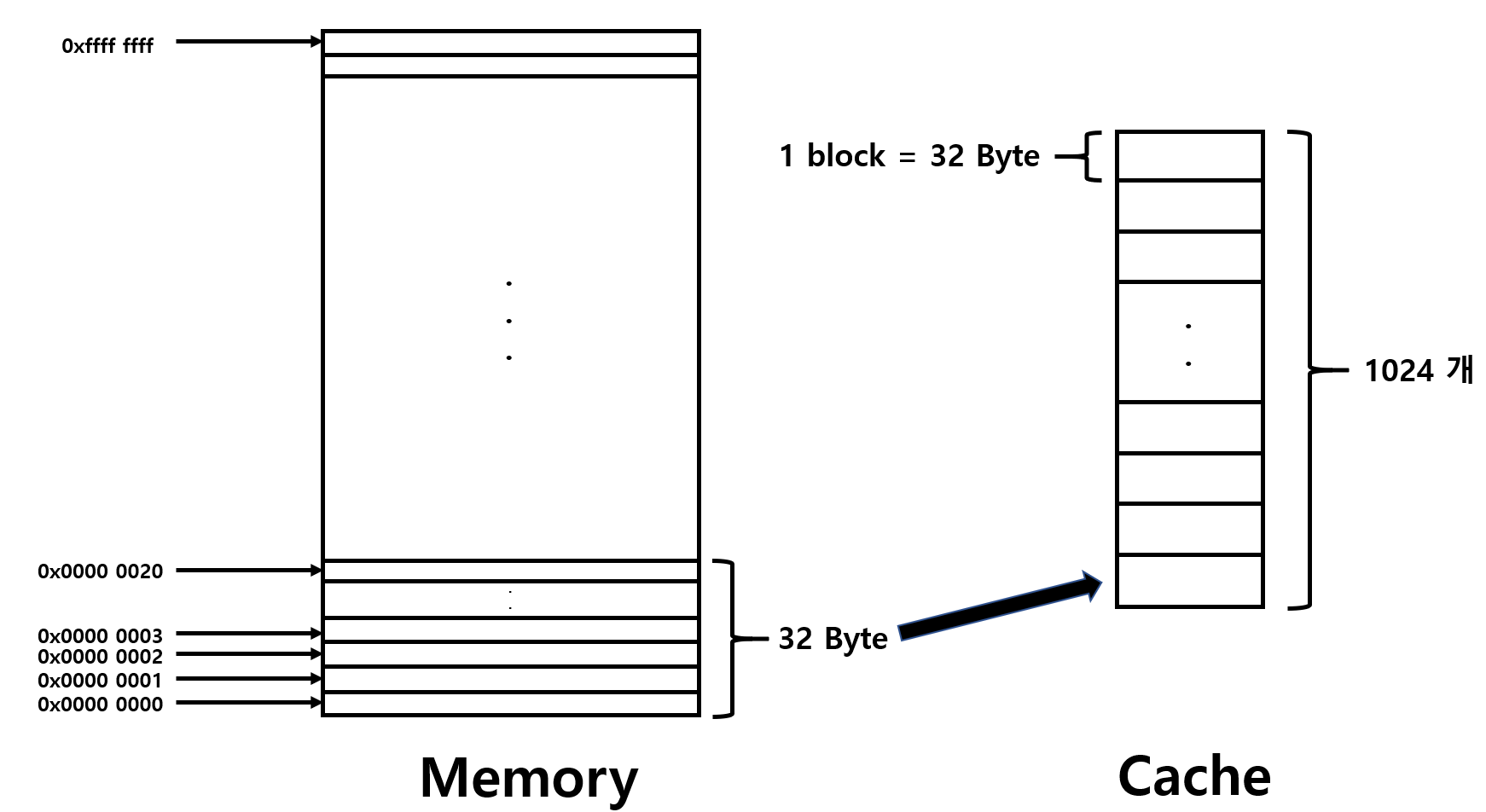
연속된 메모리 주소를 블락단위로 가져와 캐시에 저장
- Spatial locality 활용
Direct mapped cache

-
Index를 사용해 캐시 저장위치를 정한다. -
찾는 데이터의
Index가 캐시내에 존재할 때Tag를 검사해 실제 찾는 데이터와 동일한 지 검사한다.- 같으면
hit, 가져다쓰면 된다. - 틀리면
miss, 실제 메모리에 접근하여 캐시를 바꿔친다.
- 같으면
-
찾는 데이터의
Index가 캐시내에 존재하지 않는다면, 실제 메모리에 접근하여 캐시를 저장한다.- 이미 한번 찾은 데이터여야만, 캐시에 저장된다.
- Temporal locality 활용
- 이미 한번 찾은 데이터여야만, 캐시에 저장된다.
Block Size Considerations
-
블락 크기를 키우면, miss rate ⬇
-
캐시 크기가 그대로인데, 블락 크기를 키우면
- 캐시 라인 수 ⬇, miss rate ⬆
-
블락 크기를 키우면, miss 가 발생할 경우 더 많은 블락 정보를 읽어와야 한다.
- miss penalty ⬆
Cache miss
-
Cache hit 의 경우, CPU는 정상적으로 수행
-
Cache miss 발생 시,
-
CPU pipeline 에 stall 발생
-
하위 메모리 계층에서 block(데이터)를 찾아 읽어와야 한다.
-
Instruction cache miss 의 경우
- Instruction fetch 를 다시 수행
-
Data cache miss 의 경우
- data 탐색을 계속해서 수행
-
Associative cache
- Fully associative
- 블록이 캐시의 어느 곳에나 위치할 수 있는 방식

- n-way set associative
- Direct mapped 와 Fully associative 의 중간 방식
- 각 블록당 n개의 배치 가능한 위치를 갖는 방식

2-way
<-> Direct mapped cache
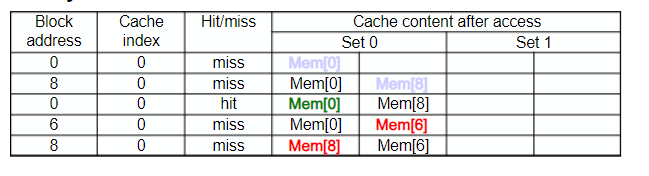
Associativity Example
- Block access 순서 : 0, 8, 0, 6, 8
<-> Direct mapped cache
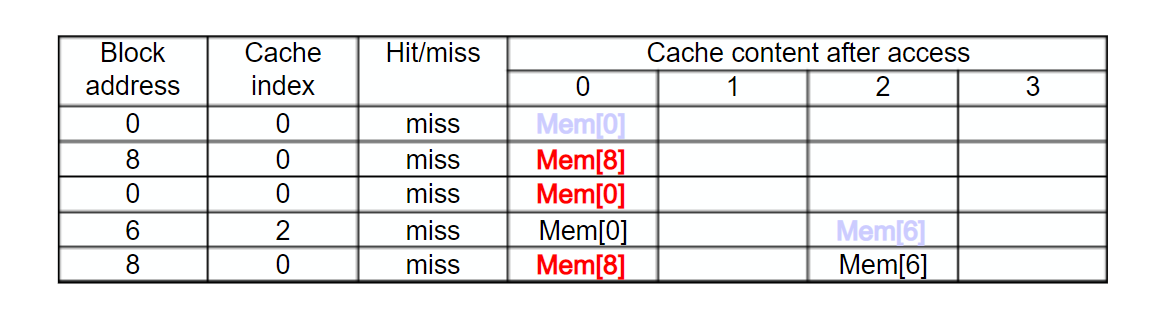
5 miss 발생
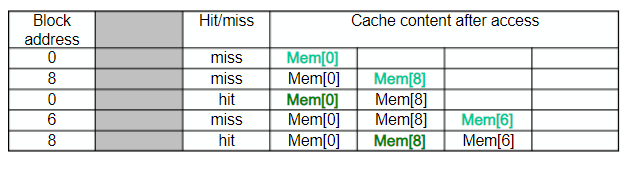
- 2-way set associative
- 4 miss 발생
- 교체 규칙은 LRU (Least-recently used)
- Fully associative
3 miss 발생
Replacement Policy
- set에 모든 블록들이 저장되어 있는 상태에서 cache miss 가 발생했을 때, 어떤 블록을 교체할 것인지에 대한 정책
<-> Direct mapped : 교체 정책 x , 무조건 교체
-
Least-recently used (LRU)
- 가장 오랫동안 사용되지 않은 블록을 교체 대상으로 정한다.
- 2-way는 구현이 쉽지만, set가 커질수록 구현이 어렵다.
-
Random
- 랜덤하게 교체 대상을 선택
- 구현이 LRU 보다 훨씬 쉽다.
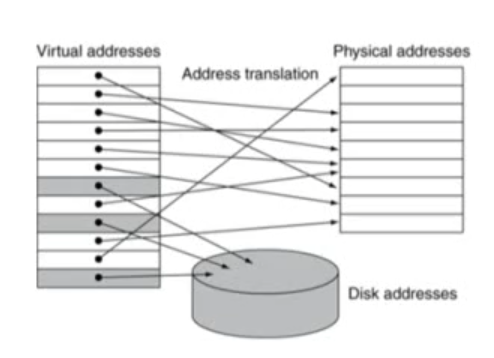
Virtual Memory
-
Secondary storage (disk) 입장에서, main memory 는 캐시와 유사하다.
-
main memory 를 disk 를 위한 캐시로 사용하는 기술을 Virtual Memory 라 한다.
- 이를 통해, 다수의 프로그램들이 main memory를 효율적으로 공유할 수 있다.
-
VM block ➔ page
-
VM translation 의 miss 발생 ➔ page fault
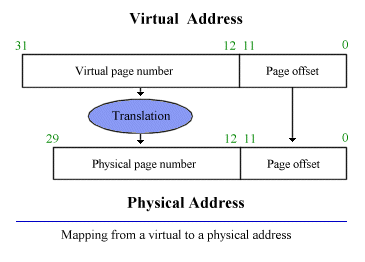
Address Translation
-
Virtual Address ➔ 프로그램이 사용하는 주소
-
Physical Address ➔ 실제 컴퓨터가 사용하는 메모리 주소
-
Address Translation 을 거쳐, Virtual 메모리는 실제 메인 메모리나 disk로 매핑
Virtual Addressing with a Cache
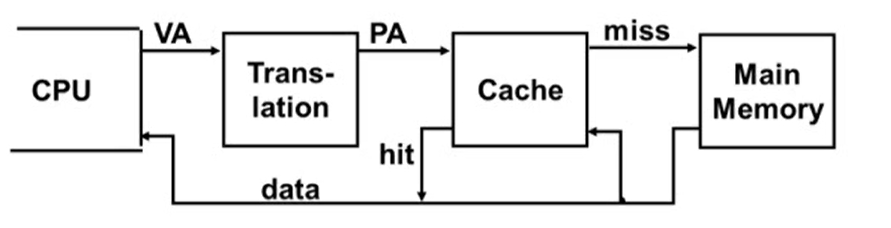
- VA : Virtual Address
- PA : Physical Address
-
Translation 정보는 main memory 에 저장되어 있다.
-
따라서 캐시에 access 할 때마다 main memory 에 access 하는 것은 큰 낭비이다.
-
TLB(Translation Lookaside Buffer) 를 추가하여 이런 낭비를 줄일 수 있다.
-
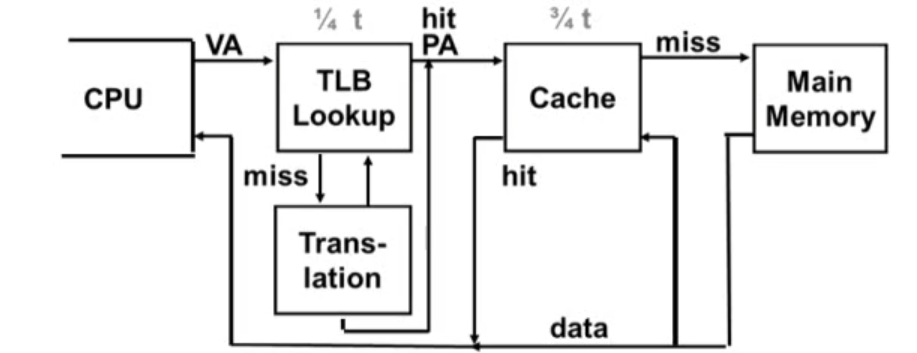
TLB사용
TLB에서 translation 정보를 먼저 찾아봄으로써, main memory 접근 횟수를 줄일 수 있다.
Page Fault Penalty
-
millions of clock cycles 발생
- 오버헤드가 굉장히 크다.
-
따라서 page fault rate 을 줄이는 것이 중요하다.
- Fully associative placement 사용
- 더욱 정교하고 좋은 replacement 알고리즘 사용
Miss의 원인
-
Compulsory misses (cold start misses)
- 해당 블록을 처음 access 하기 때문에 발생하는 miss
- 피할 수 없다.
-
Capacity misses
- 상위 메모리 계층은 하위 메모리 계층보다 용량이 작다.
- 이러한 용량 차이에 의해 발생하는 miss
- 만약 상위 메모리와 하위 메모리의 크기가 같다면 발생하지 않는다.
-
Conflict misses
- 하나의 집합에 대해 다수의 블록들이 경쟁을 벌일 때 발생하는 miss
- 즉, 이미 replacement가 발생한 블록을 다시 접근하려고 할때 발생하는 miss
- Fully associative 에서는 발생하지 않는다.
출처
KOCW 컴퓨터구조 강의 (영남대학교 - 최규상 교수님)
http://www.kocw.net/home/search/kemView.do?kemId=1125218
컴퓨터 구조 및 설계 (David A. Patterson, 존 헤네시)
암달의 법칙
https://luv-n-interest.tistory.com/419
바이트 어드레싱
https://eine.tistory.com/entry/64%EB%B9%84%ED%8A%B8-32%EB%B9%84%ED%8A%B8-CPU%EC%99%80-%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C-%EC%97%90-%EB%8C%80%ED%95%98%EC%97%AC
프로시저 호출
https://scarletbreeze.github.io/articles/2018-04/%EC%BB%B4%ED%93%A8%ED%84%B0%EA%B5%AC%EC%A1%B0%EB%A1%A0%285%29.md
메모리 레이아웃
https://gofo-coding.tistory.com/entry/2-MIPS-Non-Leaf-Procedure
캐시
https://inyongs.tistory.com/134
