
컴퓨터 네트워킹 하향식 접근을 읽고
- 책을 읽으며 중요하다고 생각되는 내용들을 정리하였다.
정리한 Chapter
- 1장 컴퓨터 네트워크와 인터넷
- 2장 애플리케이션 계층
- 3장 트랜스포트 계층
- 4장, 5장 네트워크 계층
컴퓨터 네트워크와 인터넷
회선 교환 vs 패킷 교환
-
네트워크를 통해 데이터를 이동시키는 방식에는 회선 교환 (circuit switching) 과 패킷 교환 (packet switching) 이 있다.
-
회선 교환 방식은 통신에 필요한 자원을 미리 예약한다.
- 따라서 보장된 전송률로 데이터를 일정하게 보낼 수 있다.
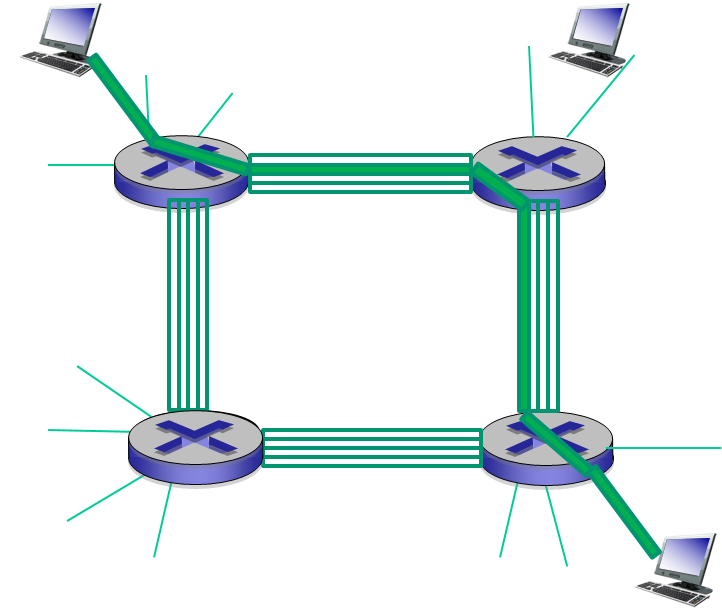
스위치간의 링크가 1Mbps 의 전송률을 갖는다면 각 호스트간의 회선 교환 연결은 지정된 전송률 250kbps 를 얻게 된다.
-
패킷 교환 방식은 통신에 필요한 자원을 예약하지 않는다.
-
따라서 특정 링크가 혼잡하다면 패킷은 특정 링크의 버퍼에서 대기해야 하므로 지연이 발생할 수 있다.
-
일정한 전송률이 보장되지 않는다.
-
-
회선 교환 방식은 할당된 회선이 비활용 기간에는 놀게되므로 비효율적이다.
-
1Mbps 전송률의 링크를 10명이 공유하는 경우, 각 사용자는 100kbps 회선이 예약된다.
-
만약 9명의 사용자가 링크를 사용하지 않고 1명만 사용한다 하면 900kbps 의 자원은 놀게된다.
-
-
패킷 교환 방식은 전송 용량을 공유하므로 더 효율적이다.
-
앞선 예에서 사용자 10명이 동시에 링크를 사용하는 경우, 회선 교환 방식과 패킷 교환 방식의 효율이 비슷하다.
-
그러나 사용자 10명이 동시에 링크를 사용하는 경우는 거의 없다.
-
또한 회선 교환 방식은 10명이 넘는 동시 사용자를 지원할 수 없다.
-
그러나 패킷 교환은 큐를 사용하여 회선 교환 방식 대비 3배 이상의 사용자 수를 허용한다.
-
-
동시 사용자 수가 10명 미만이면 회선 교환 방식보다 더 빠른 속도의 전송률을 할당할 수 있다.
-
오늘날엔 패킷 교환 방식이 주를 이루고 있다.
네트워크와 인터넷
-
네트워크
-
두 대 이상의 컴퓨터들을 연결하고 통신할 수 있는 환경
-
정보 공유가 주 목적이다.
-
-
인터넷
-
전 세계의 다수에 네트워크를 서로 연결한 통합된 네트워크 시스템
-
네트워크의 네트워크
-
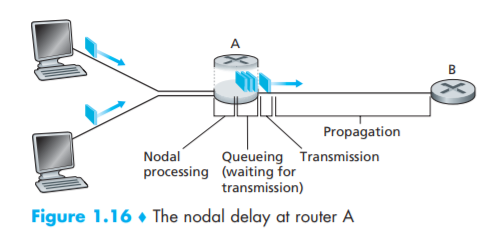
패킷 교환 네트워크에서의 지연
- 현실에선, 네트워크 통신상의 데이터 손실이나 지연이 발생한다.
-
processing delay (처리 지연)
- 라우터가 upstream 으로 부터 받은 패킷을 조사하고, 어디로 보낼지 결정하는 데 걸리는 시간
-
queuing delay (큐잉 지연)
-
패킷이 큐에서 링크로 전송되기를 기다리는 지연
-
큐가 비어있고, 앞선 패킷이 전송중이 아니라면 큐잉 지연은 0
-
트래픽이 많아 많은 패킷이 큐에서 대기중이라면 큐잉 지연이 커진다.
-
큐가 가득 차있는 상태에서 도착한 패킷은 버려진다.
- 패킷 손실이 발생한다.
-
-
transmission delay (전송 지연)
- 라우터가 패킷의 모든 비트를 링크로 밀어내는데 걸리는 시간
-
propagation delay (전파 지연)
-
링크에서 이동하는 패킷이 목적지 라우터까지 이동하는데 걸리는 시간
-
빛의 속도와 같거나 약간 작다.
-
패킷 교환 네트워크에서의 처리율
-
평균 처리율이란 특정 시간동안 네트워크가 처리한 비트 수를 의미한다.
ex) bps, kbps, Mbps -
여러개의 링크로 구성된 네트워크의 처리율을 계산할 땐, 가장 작은 처리율을 가진 병목 링크의 전송률이 네트워크의 처리율이 된다.
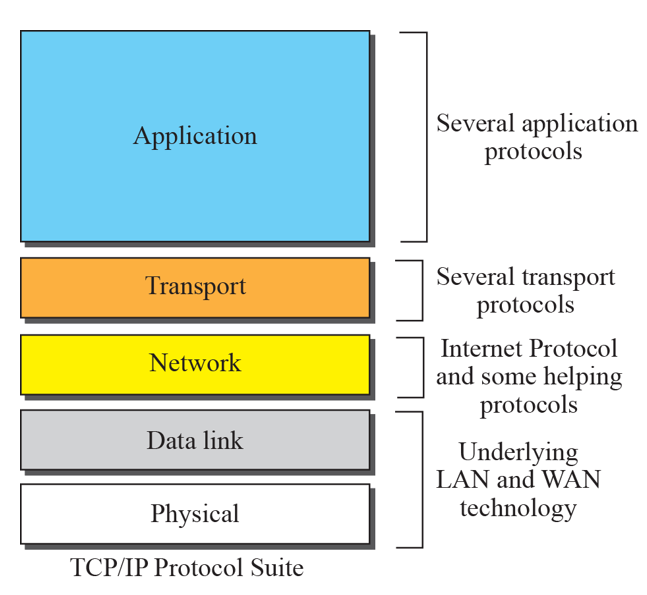
프로토콜 계층
-
인터넷의 구조는 매우 복잡하다.
- 한번에 통으로 이해하기 어렵다.
-
인터넷의 다양한 프로토콜을 계층화하여 특정 부분만을 논의하고 다른 부분을 단순화할 수 있다.
-
또한 특정 계층이 제공하는 서비스의 구현을 변경하는 것이 쉽다.
- 상위 계층에 같은 서비스를 제공하고 하위 계층의 같은 서비스를 이용한다면 특정 계층의 구현이 바뀌어도 시스템의 나머지 부분이 변하지 않는다.
-
인터넷 프로토콜 스택은 5개 계층으로 이루어진다.
캡슐화
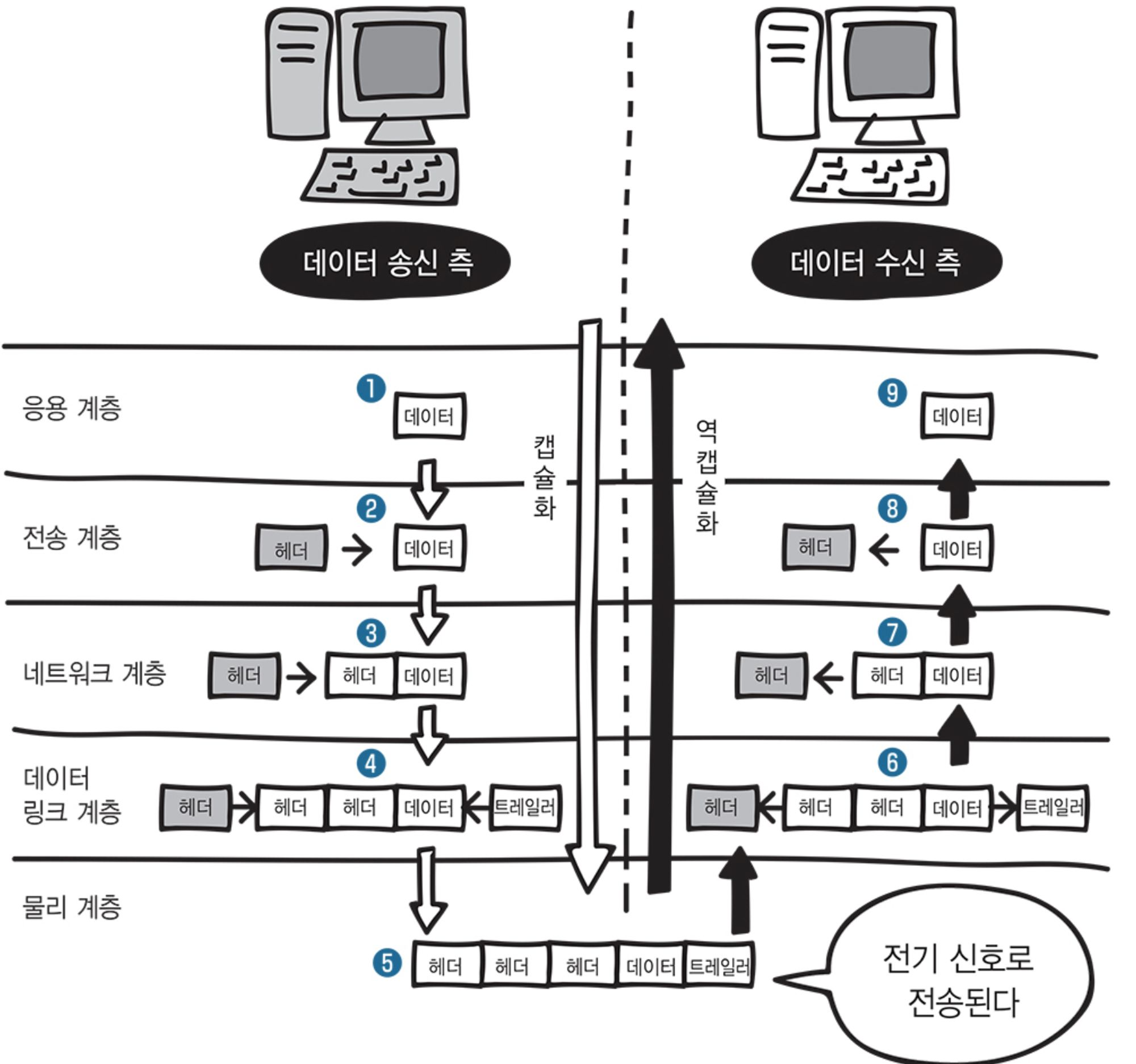
-
프로토콜 스택 아래로 데이터를 보내며 특정 계층에서 사용할 헤더 정보를 붙여가는 과정을 캡슐화라 한다.
-
상위 계층의 데이터가 편지지의 내용이고 하위 계층에서 붙이는 헤더가 편지지 봉투, 우표, 발신인, 수신인과 같다.
-
프로토콜 스택 아래에서 위로 올라가는 과정은 캡슐화의 반대 과정이다.
애플리케이션 계층
-
네트워크 애플리케이션과 애플리케이션 계층 프로토콜이 존재한다.
-
메시지를 사용해 서로 다른 위치에 있는 애플리케이션과 통신한다.
네트워크 애플리케이션
-
종단 시스템에서 동작하고, 네트워크를 통해 서로 통신하는 프로그램을 말한다.
-
네트워크 애플리케이션은 컴퓨터 네트워크의 핵심이다.
- 구글, 유튜브, 넷플릭스와 같은 서비스들 모두 네트워크 애플리케이션이다.
애플리케이션 구조
-
클라이언트 - 서버 구조
-
항상 동작하며 서비스를 제공하는 호스트 = 서버
-
서비스를 요청하는 호스트 = 클라이언트
-
서버는 고정 IP 주소를 갖는다.
-
클라이언트끼리 직접 통신하지 않는다.
-
서버는 클라이언트의 요청이 많아지면 서버 호스트를 늘려야 한다.
-
-
P2P 구조 (Peer-to-Peer)
-
서버에 거의 의존하지 않는다.
-
peer 라는 간헐적으로 연결된 호스트 쌍이 서로 직접 통신한다.
-
서비스 제공자는 peer를 소유하지 않고, 대부분의 사용자들이 peer 가 된다.
-
peer 들은 자신의 파일을 다른 peer 들에게 분배함으로써 시스템의 서비스 능력을 증진시킨다.
- self-scalability (자가 확장성)
-
프로세스간 통신
-
호스트에서 실행되는 프로그램 = 프로세스
-
네트워크에서 서로 통신하는 주체는 서로 다른 호스트에 위치한 프로세스들이다.
- 프로세스간 메시지를 교환하며 서로 통신한다.
-
프로세스는 소켓을 통해 네트워크로 메시지를 주고 받는다.
-
소켓은 트랜스포트 계층과 애플리케이션 계층간의 인터페이스이다.
-
애플리케이션은 소켓을 사용하여 트랜스포트 계층에서 제공하는 서비스들을 사용할 수 있다.
-
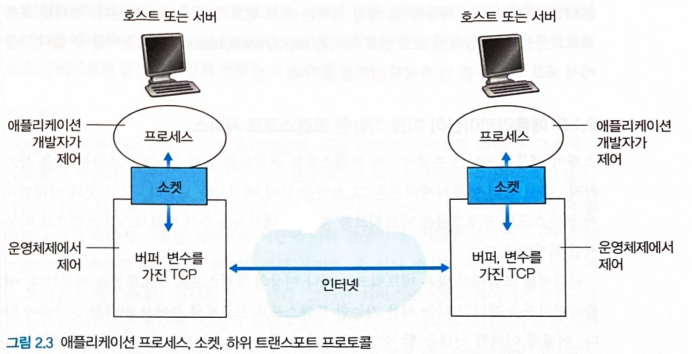
애플리케이션이 사용할 수 있는 트랜스포트 프로토콜
-
트랜스포트 계층은 송신 프로세스가 소켓을 통해 보낸 메시지를 수신 프로세스의 소켓으로 이동시킬 책임이 있다.
-
이러한 책임을 수행하기 위한 대표적인 프로토콜은 TCP와 UDP 이다.
-
TCP (Transmission Control Protocol)
-
연결지향형 서비스
- TCP 3-way handshaking 을 통해 두 프로세스의 소켓을 연결한다.
-
신뢰적인 데이터 전송 서비스
- 통신 프로세스간의 모든 데이터를 오류없이 올바른 순서로 전달한다.
-
-
UDP (User Datagram Protocol)
-
최소의 서비스 모델을 가진 간단한 프로토콜
-
비 연결형 서비스
- handshaking X
-
비 신뢰적인 데이터 전송 서비스
- 통신 프로세스간의 메시지의 도착, 올바른 순서를 보장하지 않는다.
-
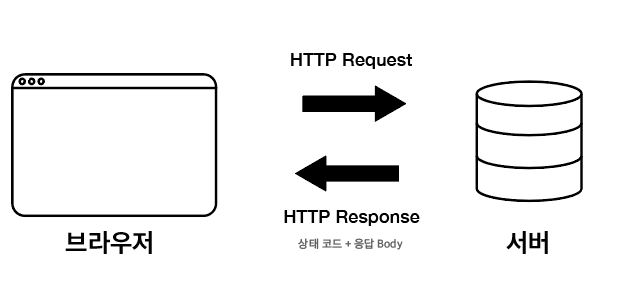
HTTP
-
HyperText Transfer Protocol
-
대표적인 애플리케이션 계층 프로토콜
-
HTTP 클라이언트는 서버에게 웹 페이지를 이루는 객체들을 요청하고, HTTP 서버는 객체들을 제공한다.
-
HTTP 서버는 클라이언트에 대한 정보를 유지하지 않는다.
- stateless protocol
HTTP 비지속 연결 vs 지속 연결
-
HTTP 는 비지속 연결과 지속 연결 모두 사용할 수 있다.
- HTTP 1.1 의 기본설정은 지속 연결이다.
-
비지속 연결
-
모든 요구/응답 쌍이 분리된 TCP 연결을 통해 보내진다.
-
클라이언트가 서버의 index.html (10개의 이미지로 구성된) 을 HTTP 요청한다고 가정하면
-
클라이언트와 서버는 총 11개의 객체에 대해
-
TCP 연결을 맺는 TCP 3-way handshaking 과
-
TCP 연결을 끊는 TCP 4-way handshaking 을 반복 수행해야 한다.
-
-
모든 요청 객체에 대해 TCP 커넥션을 열고 닫는 시간적 비용이 생기는 단점이 있다.
-
모든 요청 객체에 대해 새로운 TCP 커넥션을 만들어야 하므로 서버에 많은 TCP 변수가 만들어지는 부담이 있다.
-
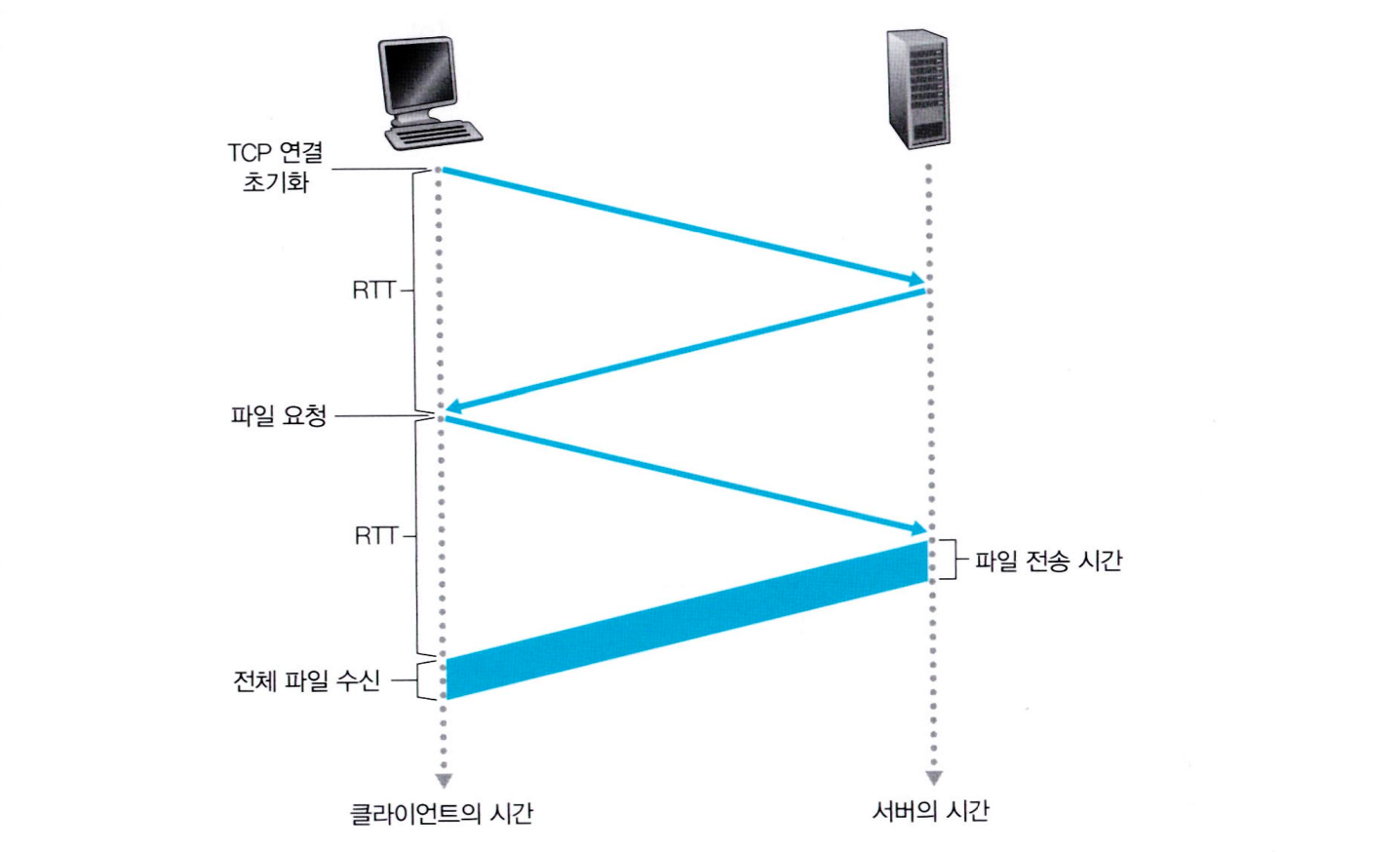
- 가장 처음 3개의 화살표는 TCP 연결을 맺는 TCP 3-way handshaking 이다.
- 클라이언트는 TCP 3-way handshaking 의 마지막 과정에서 요청 메시지를 같이 실어 보낼 수 있다.
-
지속 연결
-
모든 요구/응답 쌍이 같은 TCP 연결을 통해 보내진다.
-
HTTP/1.1 에서 지원하는 기능
-
클라이언트가 서버의 index.html (10개의 이미지로 구성된) 을 HTTP 요청한다고 가정하면
-
처음에만 TCP 3-way handshaking 을 통해 클라이언트와 서버간의 TCP 연결을 맺고
-
11개의 객체의 요구/응답을 해당 TCP 커넥션에서 모두 처리한다.
-
이후, 일정 시간동안 클라이언트가 요구를 하지 않으면 서버는 TCP 커넥션을 닫는다.
-
-
비지속 연결 대비 효율적이다.
-
HTTP 메시지 포멧
- HTTP 요청 메시지
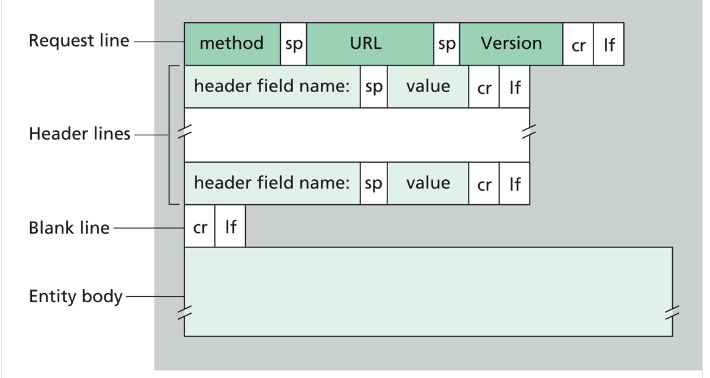
- ASCII 텍스트로 쓰여있다.
- 각 줄은 CRLF 로 구별된다.
- request line, header-line, entity body 로 이루어져 있다.
- entity body 는 주로 POST 방식에서 사용된다.
GET /hello.htm HTTP/1.1
Host: www.tutorialspoint.com
Connection: close
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3)
Accept-Language: fr
GET /hello.htm HTTP/1.1
- 해당 URL 의 객체를 GET 방식으로 요청한다.
- 브라우저는 HTTP/1.1 버전을 구현한다.
Host: www.tutorialspoint.com
- 요청하는 객체가 존재하는 호스트를 명시한다.
Connection: close
- 브라우저는 서버에게 지속 연결 사용을 원하지 않는다고 명시한다.
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3)
- 브라우저 타입을 명시한다.
Accept-Language: en-us
- 객체의 프랑스어 버전을 원하고 있음을 알리는 콘텐츠 협상 헤더
- HTTP 응답 메시지
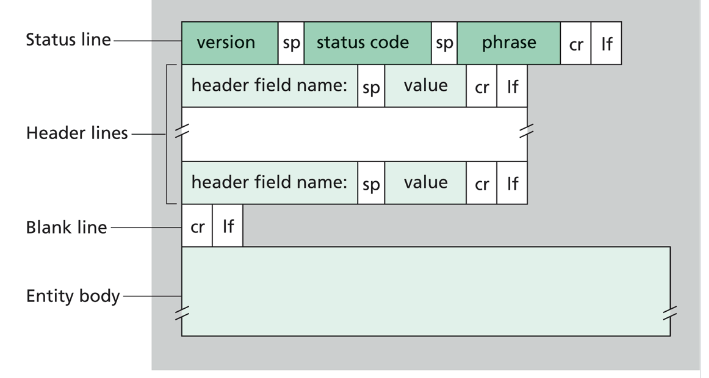
- ASCII 텍스트로 쓰여있다.
- 각 줄은 CRLF 로 구별된다.
- status line, header-line, entity body 로 이루어져 있다.
- entity body 는 요청 객체로 이루어진다.
HTTP/1.1 200 OK
Connection: close
Date: Mon, 27 Jul 2009 12:28:53 GMT
Server: Apache/2.2.14 (Win32)
Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT
Content-Length: 88
Content-Type: text/html
(데이터 ...)
HTTP/1.1 200 OK- 서버가 HTTP/1.1 을 사용하고, 클라이언트의 요청을 성공적으로 처리했음을 의미한다.
Connection: close
- 클라이언트에게 메시지를 보낸 후 TCP 연결을 닫는다.
Date: Mon, 27 Jul 2009 12:28:53 GMT
- HTTP 응답 메시지가 서버에 의해 생성된 날짜와 시간을 나타낸다.
Server: Apache/2.2.14 (Win32)
- 웹 서버의 정보를 나타낸다.
Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT
- 객체가 생성되거나 마지막으로 수정된 시간과 날짜를 나타낸다.
- 캐싱에서 필수적인 정보이다.
Content-Length: 88
- 송신되는 객체의 바이트 수
Content-Type: text/html
- 송신되는 객체가 HTML 텍스트임을 나타낸다.
- 송신되는 객체 타입은 파일 확장자가 아니라 Content-Type 헤더로 나타내야 한다.
쿠키
-
HTTP 는 stateless 프로토콜이기 때문에 서버 설계를 간편하게 한다.
-
그러나 서버가 사용자를 식별하고 추적해야 하는 상황이 있을 수 있다.
-
이 경우 HTTP 는 쿠키를 사용한다.
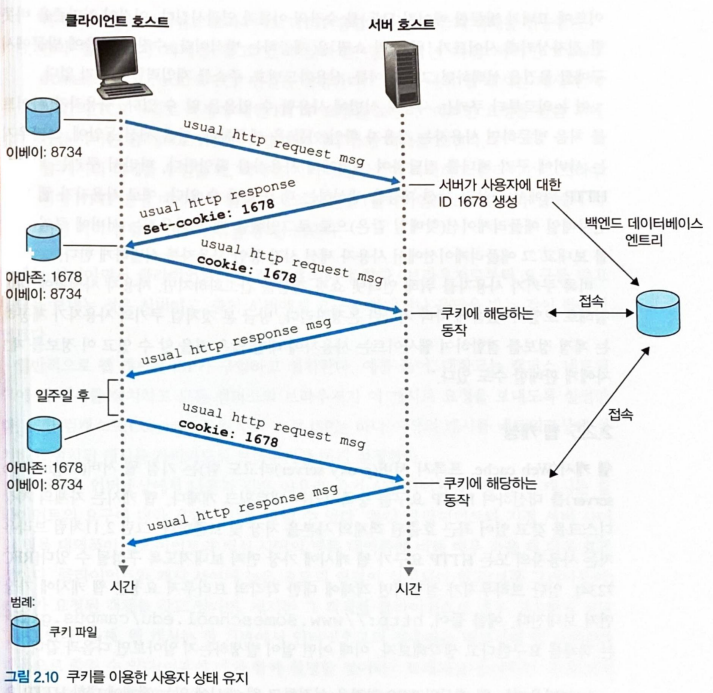
- 서버는 식별하고 싶은 클라이언트에게
Set-cookie헤더를 붙여 쿠키를 만들어 보낸다.- 클라이언트 (브라우저) 는 요청하는 호스트에서 사용하는 쿠키가 있는지 조사하고, 있다면
cookie헤더를 붙여 받은 쿠키를 보낸다.- 이러한 방식을 통해 서버는
1678 쿠키를 사용하는 사용자를 추적, 식별할 수 있다.
웹 캐싱
-
Cache Server 는 origin server 를 대신하여 클라이언트의 HTTP 요구를 충족시키는 Proxy Server
-
Cache Server 는 다른 클라이언트가 최근에 호출한 객체의 사본을 저장한다.
-
클라이언트는 Cache Server 와 TCP 연결을 맺고 객체를 요청한다.
-
만약 Cache Server 가 요청 객체를 갖고 있다면, 요청 객체를 반납한다.
-
만약 Cache Server 가 요청 객체를 갖고있지 않다면, origin server 에게 클라이언트의 요청 객체를 요청하여 클라이언트의 요청 객체를 origin server 로 부터 받는다.
-
받은 요청 객체를 Cache Server 의 로컬 저장장치에 저장하고
-
클라이언트에게 반환한다.
-
-
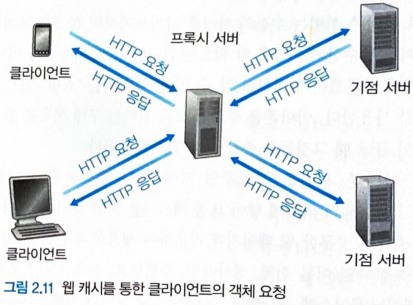
-
Cache Server 를 통해 클라이언트 요구에 대한 응답시간을 줄일 수 있다.
-
클라이언트 <-> origin server 사이 병목 대역폭이 작고
-
클라이언트 <-> Cache Server 사이 병목 대역폭이 큰 경우 더욱 효과적으로 응답시간을 줄일 수 있다.
-
일반적으로 Cache Server는 클라이언트와 가까이 위치하기 때문에 이 경우에 해당한다.
-
-
Cache Server 를 사용하면 origin server 로 접속하는 링크상의 트래픽을 줄일 수 있다.
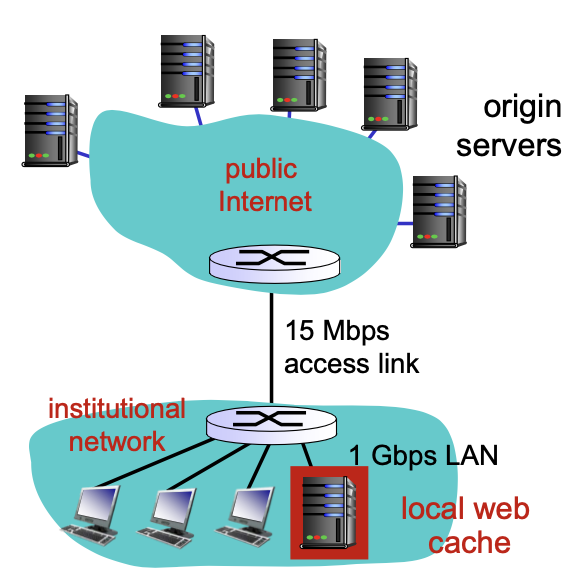
- 대부분의 클라이언트 요청이 고속 LAN 에 위치한 기관 캐시 서버에 의해 처리되므로, 접속 회선을 확장하지 않고 사용자의 평균 지연 시간을 줄일 수 있다.
- 접속회선 확장 비용 > Cache Server 설치 비용
-
Cache Server 에 있는 객체 사본과 origin server 에 있는 객체 원본이 다를 수 있다.
-
객체가 Cache Server 에 캐싱된 이후에, origin server 의 객체가 갱신되었을 수 있다.
-
이를 해결하기 위해 조건부 GET 을 사용한다.
-
Last-Modified: Wed, 9 Sep 2015 19:15:56 GMTCache Server 와 브라우저가 해당 날짜에 최종적으로 갱신된 /fruit/kiwi.gif 객체를 갖고 있다고 가정한다.
GET /fruit/kiwi.gif HTTP/1.1
Host: www.exotinquecuisine.com
If-modified-since: Wed, 9 Sep 2015 19:15:56 GMT
- 브라우저는
If-modified-since헤더를 붙여 조건부 GET으로 Cache Server 에게 객체를 요청한다.- Cache Server 역시
If-modified-since헤더를 붙여 조건부 GET으로 origin server 에게 객체를 요청한다.
HTTP/1.1 304 Not Modified
Date: Sat, 10 Oct 2015 15:39:56 GMT
Server: Apache/1.3.0 (Unix)
(빈 개체몸체)
- Cache Server 가 붙인
If-modified-since헤더의 날짜 이후로 갱신되지 않았다면 origin server 는 304 응답만을 보낸다.
- 객체를 엔티티 바디에 담아 다시 보내지 않기 때문에 효율적이다.
- 만약, 날짜 이후로 갱신되었다면 origin server 는
Last-Modified: 변경된 최신 날짜헤더를 붙여 갱신된 객체와 함께 Cache Server 에게 응답 메시지를 보낸다.
- Cache Server 는 origin server 로 부터 받은 응답을 바탕으로 브라우저에게도 304 빈 객체 응답을 보내거나, 200 객체와
Last-Modified헤더를 포함한 응답을 보낸다.
HTTP/2
-
HTTP/1.1 은 하나의 지속적인 TCP 연결을 사용하는 경우 HOL 블로킹 문제가 발생할 수 있다.
- Head of Line 블로킹이란 비디오와 같은 크기가 큰 객체 때문에, 덩치 큰 객체의 뒤에 있는 많은 수의 작은 객체들이 기다리게 되는 것을 말한다.
-
HTTP/1.1 은 HOL 블로킹 문제를 해결하기 위해 여러개의 병렬 TCP 연결을 열었다.
-
이를 통해 하나의 웹 페이지에 있는 객체들이 브라우저로 병렬적으로 전송된다.
-
크기가 작은 객체들도 덩치가 큰 객체뒤에서 기다리지 않고 빠르게 전달되었다.
-
-
그러나 여러개의 병렬 TCP 연결은 인터넷상의 불공정성을 야기한다.
-
TCP 혼잡 제어는 모든 개별적인 TCP 연결이 대역폭을 공평하게 갖도록 나눠주는데
-
하나의 클라이언트가 여러개의 TCP 연결을 사용하면 공평하지 않다.
-
-
HTTP/2 의 주요 목표는 하나의 웹 페이지를 전송하기 위한 병렬 TCP 연결을 제거하는데 있다.
- 이를 통해 목표한대로 TCP 혼잡 제어를 할 수 있다.
-
오직 하나의 TCP 연결만을 사용하면서도 HOL 블로킹을 피하기 위해서
-
각 객체를 작은 프레임으로 나누고
-
하나의 TCP 연결을 통해 객체들을 이루는 작은 프레임을 객체별로 한 개씩 보낸다.
-
ex)
video 객체 = 1000 프레임,작은 객체 = 2프레임이라 가정-
기존 HTTP/1.1 방식에서 작은 객체는 1002 프레임이 보내져야 전송이 완료된다.
-
HTTP/2 방식에서 작은 객체는 4 프레임이 보내지면 전송이 완료된다.
-
-
-
즉 HTTP/2 핵심 기능은 HTTP 메시지를 독립된 프레임들로 쪼개 골고루 보내고, 받는 쪽에선 프레임들을 재조립하는 기능이다.
- 각 프레임들은 바이너리 인코딩 된다.
-
추가적으로 요청에 상대적 우선 순위를 정할 수 있고, 클라이언트 요청 없이 서버에서 객체를 push 할 수 있다.
DNS
-
호스트를 식별하는 방법은 호스트 이름과 IP 주소다.
-
사람은 호스트 이름을 좋아한다.
-
라우터는 IP 주소를 좋아한다.
-
이러한 선호차이를 절충하기 위해 호스트 이름을 IP 주소로 변환해주는 시스템이 필요하다.
-
이 시스템에 DNS (Domain Name System) 이다.
-
-
DNS 는 DNS 서버들의 계층 구조로 구현된 분산 데이터베이스이다.
-
중앙 집중 데이터베이스는 서버가 고장날 경우 위험하고,
-
트래픽 양이 너무 많아지고
-
유지 관리가 어렵고
-
형평성때문에 지역 선정의 어려움이 있다.
-
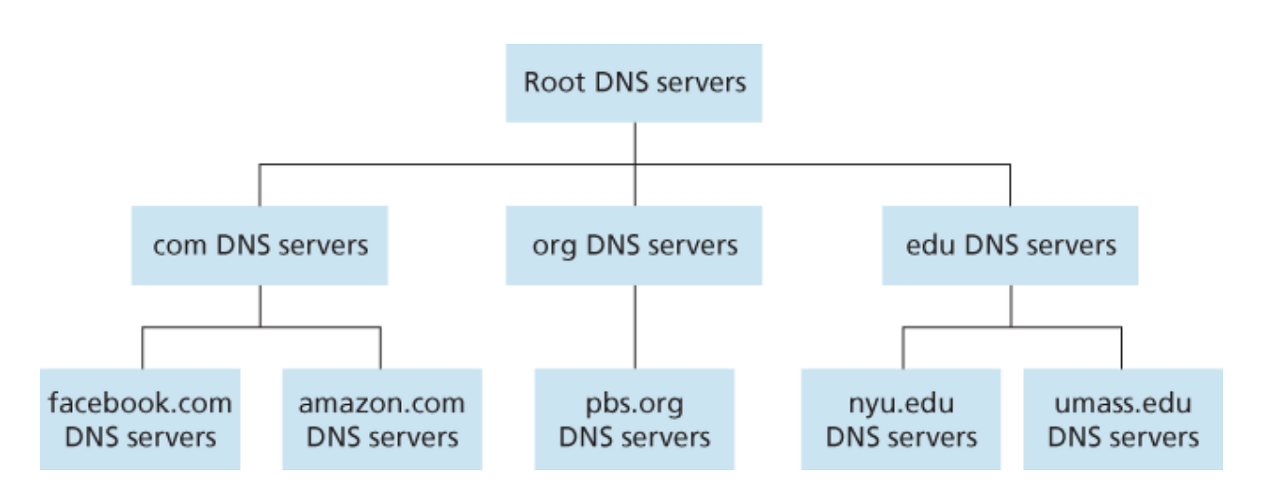
DNS 서버 계층 구조의 일부
- 루트 DNS 서버
- 13 개의 루트 DNS 서버 주소가 있다.
- 실제 루트 서버 개수는 훨씬 많지만 13개의 루트서버의 복사본이다.
- TLD 서버의 IP 주소를 제공한다.
- TLD 서버
- com, org, net, edu, gov, kr, uk, fr 같은 최상위 레벨 도메인에 대한 서버이다.
- Authoritative DNS 서버에 대한 IP 주소를 제공한다.
- Authoritative DNS 서버
- 웹 서버와 같은 호스트에 대한 IP 주소를 제공한다.
- 로컬 DNS 서버
- DNS 서버 계층 구조에는 속하지 않는다.
- 주로 ISP 들이 로컬 DNS 서버를 갖는다.
- 호스트와 근거리에 위치한다.
- 호스트가 DNS 질의를 보내면 프록시로 동작하는 로컬 DNS 서버가 이를 받아 직접 처리하거나 DNS 서버 계층으로 질의를 전달한다.
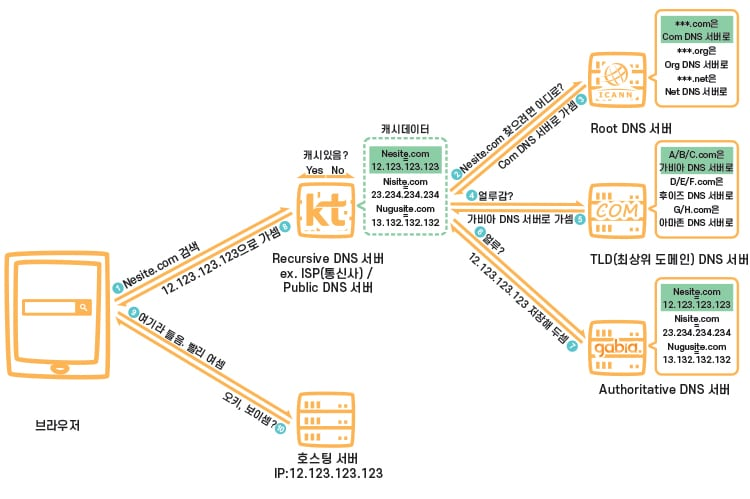
- 실제로는 TLD DNS 서버가 원하는 호스트의 IP 주소를 갖고 있는 Authoritative DNS 서버를 알고 있지는 않다.
- Authoritative DNS 서버를 알고 있는 중간 DNS 서버를 알고 있어, 계층적으로 더 깊어진다.
- 호스트의 DNS 질의를 로컬 DNS 서버가 가로채서, DNS 서버 계층에 반복적으로 질의하고 최종적인 IP 주소 결과를 반환한다.
- 호스트 입장에서 로컬 DNS 서버는 재귀적인 동작을 하므로, Recursive DNS 서버라고도 불린다.
- 로컬 DNS 서버는 DNS 서버 계층의 DNS 서버로부터 DNS 응답을 받았을 때 로컬 메모리에 응답에 대한 정보를 저장할 수 있다.
- 다른 호스트가 로컬 메모리에 존재하는 호스트 이름에 대해 DNS 질의를 하면 DNS 서버 계층에 질의하지 않고 바로 IP 주소를 응답할 수 있다.
- 이러한 캐싱을 통해 지연 성능 향상 및 네트워크 DNS 메시지 수를 줄일 수 있다.
-
브라우저가 사용하는 애플리케이션 계층 프로토콜이다.
- UDP 위에서 수행된다.
-
DNS는 별칭 호스트 이름에 대한 정식 호스트 이름을 얻기 위해 사용되기도 한다.
-
DNS 는 부하 분산을 위해 사용되기도 한다.
-
규모가 큰 웹사이트는 하나의 호스트 명에 여러개의 서버가 연결되어 있다.
-
즉, 하나의 호스트 명의 여러개의 IP 주소 집합을 갖는다.
-
DNS 는 DNS 질의의 결과인 IP 주소 집합을 각 응답마다 순서를 바꿔가며 순환식으로 보낸다.
-
클라이언트는 주로 IP 주소 집합의 첫 번째 IP 주소로 요청을 보낸다.
-
따라서 트래픽이 분산되는 효과가 있다.
-
-
-
DNS 서버들은 호스트 이름을 IP 주소로 매핑하기 위한 DNS 레코드를 저장한다.
-
각 DNS 서버는 DNS 레코드를 메시지에 담아 응답한다.
-
(Name, Value, Type, TTL)로 구성된다.-
TTL 은 DNS 레코드의 생존기간으로 TTL 이 지나면 캐시에서 제거된다.
-
Type=A 는 호스트 이름에 대한 IP 주소 매핑을 제공한다.
-
따라서 Name 은 호스트 이름
-
Value 는 IP 주소이다.
-
ex)
(relay1.bar.foo.com, 145.37.93.126, A)
-
-
Type=NS 는 호스트 이름에 대한 IP 주소를 얻을 수 있는 방법을 아는 하위 DNS 서버의 호스트 이름을 제공한다.
-
따라서 Name 은 호스트 이름의 부분 집합
-
Value 는 하위 DNS 서버의 이름이다.
-
ex)
(foo.com, dns.foo.com, NS)
-
-
-
Authoritative DNS 서버라면, 찾는 호스트 이름에 대한 Type A 레코드를 갖는다.
-
Authoritative DNS 서버가 아니라면,
-
찾는 호스트 이름의 부분집합을 Name 으로 하고, 찾는 호스트의 IP 주소를 얻을 수 있는 방법을 아는 하위 DNS 서버 이름을 Value 로 하는 Type NS 레코드와
-
하위 DNS 서버 이름에 대한 Type A 레코드를 갖는다.
-
-
인터넷 비디오
-
스트리밍 비디오는 전체 인터넷 트래픽의 80% 를 차지한다.
-
비디오는 압축을 통해 원하는 비트 전송률로 전송할 수 있다.
-
비트 전송률이 클 수록 비디오 품질이 좋다.
-
초고속 인터넷 연결의 사용자는 3Mbps 버전의 비디오를 요청할 수 있다.
-
3G 인터넷 연결의 사용자는 300kbps 버전의 비디오를 요청할 수 있다.
-
-
클라이언트가 요청한 비디오 파일은 트래픽 조건이 허용하는대로 서버측에서 전송한다.
-
비디오 파일은 클라이언트 버퍼에 저장된다.
-
서버측 전송속도보다 클라이언트 측 소비속도가 빠르면 클라이언트 버퍼가 비게 된다.
- 버퍼가 채워질때까지 기다리는 행동이 버퍼링이다.
-
DASH
-
Dynamic Adaptive Streaming over HTTP
-
클라이언트가 동일한 품질의 비디오 파일을 요청하면 네트워크 환경에 따라 버퍼링이 자주 발생할 수 있다.
-
버퍼링은 사용자 만족도를 크게 떨어뜨린다.
-
이를 줄이기 위해 DASH 를 사용한다.
-
-
클라이언트가 비디오를 요청하면 서버는 제일 먼저 비트율에 따라 구분되는 다양한 품질의 비디오 URL 정보를 갖는 manifest file 을 전송한다.
-
클라이언트는 비디오를 몇 초 길이의 청크 단위로 요청한다.
-
네트워크 환경이 좋거나 버퍼에 비디오 파일이 충분하면 높은 비트율의 비디오 버전을 요청
-
네트워크 환경이 나쁘거나 버퍼에 비디오 파일이 부족하다면 낮은 비트율의 비디오 버전을 요청
-
manifest file 을 참고하여 상황에 맞는 비디오 버전을 요청한다.
-
CDN
-
Content Distribution Network
-
엄청난 양의 콘텐츠를 분배하기 위해 전세계에 위치한 분산 서버들을 연결한 네트워크
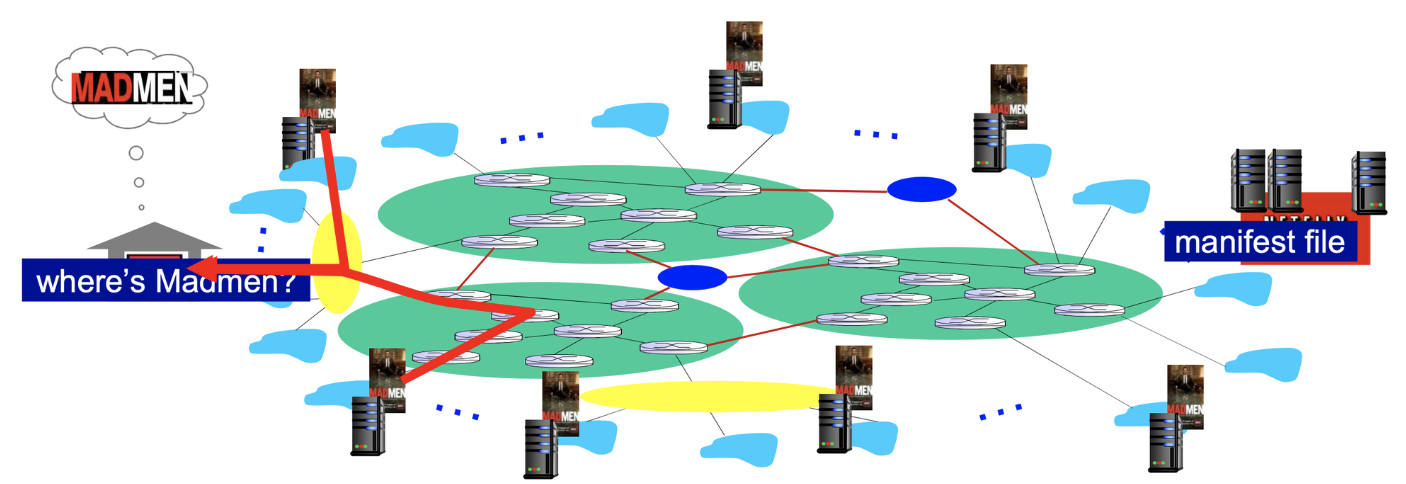
- enter deep 방식
- 클라이언트 ISP 네트워크안에 CDN 서버를 만든다.
- 그림에서 하늘색 구름에 CDN 서버 배치
- 클라이언트 입장에서 더 빠르고, 많은 구축 비용이 든다.
- bring home 방식
- ISP 네트워크와 ISP 네트워크를 연결한 IXP 지점에 CDN 서버를 만든다.
- 그림에서 파란색 원에 CDN 서버 배치
- 클라이언트 입장에서 더 느리고, 적은 구축 비용이 든다.
-
사용자는 중앙 서버대신 지리적으로 가까운 CDN 서버에 콘텐츠 데이터를 요청함으로써 지연 시간을 단축한다.
-
클라이언트가 가까운 CDN 서버에 존재하지 않는 콘텐츠를 요청하면 해당 CDN 서버는 다른 CDN 서버나 중앙 서버로부터 콘텐츠를 가져와 저장한다.
-
캐시 서버와 유사하게 동작한다.
-
-
또한 트래픽을 분산시킬 수 있다.
-
CDN 은 DNS를 활용하여 동작한다.
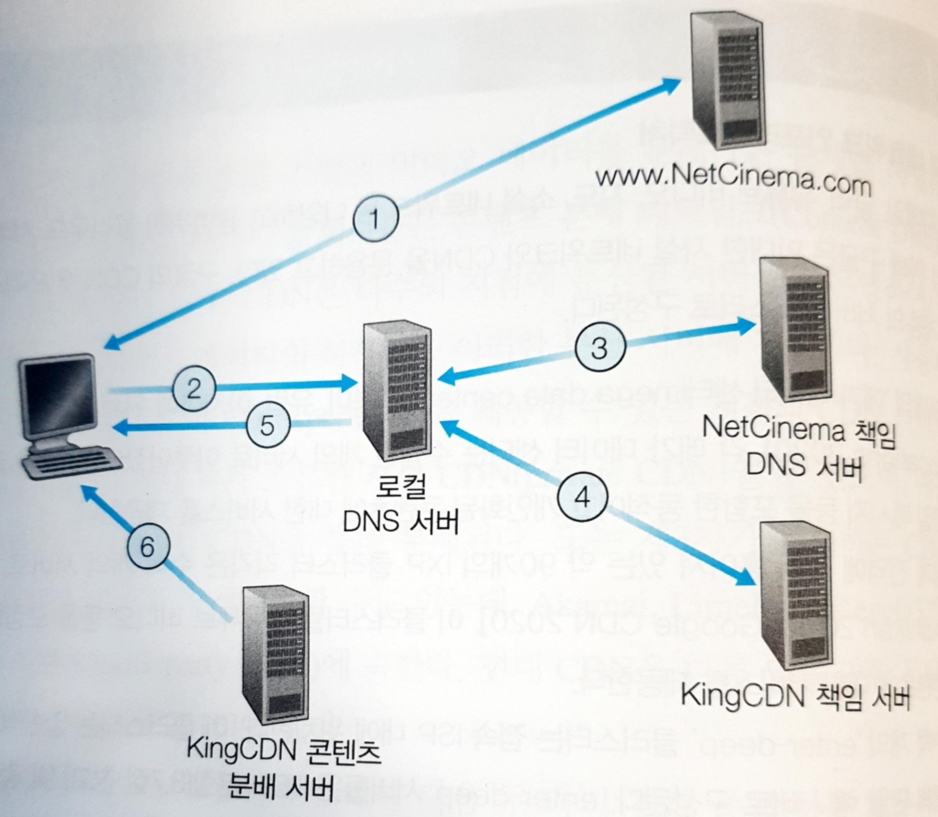
비디오 URL 을 눌렀을 때의 DNS 과정
- 요청 URL 에 대한 Authoritative DNS 서버는 호스트의 IP 주소 대신 적절한 CDN 서버의 IP 주소를 갖는 Authoritative DNS 서버의 호스트 이름을 알려준다.
- CND 서버에 대한 Authoritative DNS 서버는 CDN 서버의 IP 주소를 반환한다.
- 결과적으로 LDNS (로컬 DNS 서버) 는 적절한 CDN 서버의 IP 주소를 클라이언트에게 반환한다.
- 클라이언트는 적절한 CDN 서버에게 콘텐츠를 요청하게 된다.
-
적절한 CDN 서버를 선택하는 클러스터 선택 정책은
-
LDNS 와 지리적으로 가장 가까운 CDN 서버를 할당하는 방법과
-
네트워크 트래픽의 실시간 측정을 통해 가장 최선의 CDN 서버를 할당하는 방식이 있다.
-
UDP 소켓 프로그래밍
- 두 프로세스간의 통신은 소켓에 메시지를 보냄으로써 이루어진다.
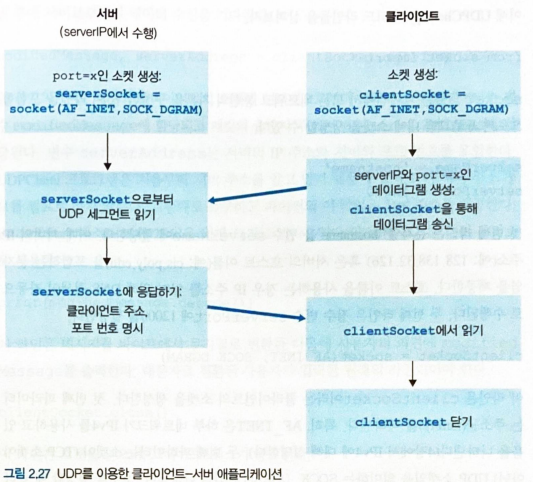
목적지 IP와 목적지 포트를 지정해주면 해당 위치의 소켓에게 메시지를 보낼 수 있다.
TCP 소켓 프로그래밍
-
두 프로세스간 통신을 하기전에 TCP 연결을 설정해야 한다. (TCP 3-way handshaking)
-
서버는 클라이언트의 초기 접속에 응대할 수 있는 welcome 소켓이 필요하다.
-
클라이언트는 서버의 IP 주소와 welcome 소켓의 포트 번호로 메시지를 보내 TCP 3-way handshaking 을 수행한다.
-
TCP 3-way handshaking 이 끝나면 해당 클라이언트에게 지정되는 새로운 소켓을 생성한다.
-
클라이언트 소켓과 새로 생성된 서버 소켓은 서로 연결되어 신뢰적 서비스를 제공한다.
-
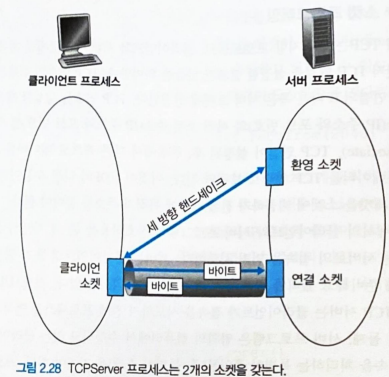
welcome 소켓과 새로 생성된 서버 소켓 (연결 소켓) 은 다르다.
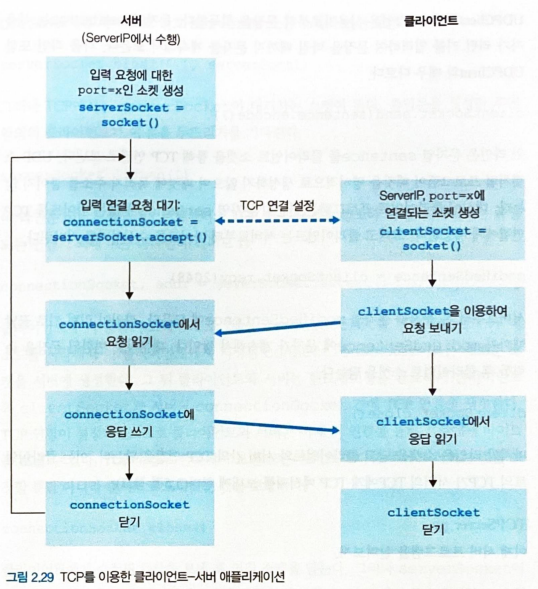
- 클라이언트 소켓은 서버의 welcome 소켓과 TCP 3-way handshaking 을 수행한 뒤
- 서버에서 새로 생성된 연결 소켓과 통신한다.
트랜스포트 계층
-
각기 다른 호스트에서 동작하는 애플리케이션 프로세스 간에 논리적인 통신 서비스를 제공하는 계층
- 이를 통해 애플리케이션 관점에서 두 호스트의 프로세스들이 직접 연결된 것처럼 보인다.
-
네트워크 계층이 호스트들 사이에 논리적인 통신을 제공하는 것과는 차이가 있다.
-
애플리케이션 계층처럼 종단 시스템에서 구현된다.
-
애플리케이션 계층의 메시지를 트랜스포트 계층의 세그먼트로 변환하여 송수신한다.
-
대표적으로 TCP 와 UDP 프로토콜이 있다.
트랜스포트 계층의 개요
-
인터넷 네트워크 계층 프로토콜, IP 는 호스트들 간에 논리적 통신을 제공한다.
-
그러나 통신하는 호스트들 간의 데이터 전달이 잘 되었는지, 순서는 지켜졌는지를 보장하지는 않는다.
-
또한 데이터 무결성을 보장하지 않는다.
-
따라서 IP를 비신뢰적인 서비스라 부른다.
-
-
UDP, TCP 는 호스트들간의 IP 전달 서비스를 두 프로세스간의 전달 서비스로 확장한다.
- 호스트 대 호스트 전달을 프로세스 대 프로세스 전달로 확장하는 것을 트랜스포트 계층의 multiplexing 과 demultiplexing 이라 한다.
-
UDP, TCP 는 헤더에 오류 검출 필드를 포함시켜 무결성 검사를 제공한다.
-
UDP 는 이렇게 두 가지 서비스만을 제공하는 비신뢰적인 서비스다.
- 특정 프로세스가 보낸 데이터가 목적지 프로세스에 제대로 도착했는지는 보장하지 않는다.
-
-
TCP 는 애플리케이션에 몇 가지 추가적인 서비스를 제공한다.
-
reliable data transfer (신뢰적인 데이터 전송)
-
congestion control (혼잡 제어)
-
트랜스포트 계층에서의 multiplexing & demultiplexing
-
네트워크 계층이 제공하는 호스트 대 호스트 전달 서비스를 프로세스 대 프로세스 전달 서비스로 확장하는 것을 의미한다.
-
프로세스는 소켓을 통해 네트워크에서 프로세스로 데이터를 전달받고, 프로세스의 데이터를 네트워크로 전달한다.
-
각각의 소켓은 유일한 식별자로 구분된다.
-
각각의 소켓은 프로세스의 포트 번호를 할당 받는다.
-
-
네트워크 계층을 통해 전달받은 트랜스포트 계층 세그먼트의 헤더를 읽고, 세그먼트의 데이터를 적절한 수신 소켓으로 전달하는 작업을 demultiplexing (역다중화) 라 한다.
-
애플리케이션이 소켓에 전달한 데이터를 모아, 적절한 헤더를 붙여 세그먼트로 캡슐화한 것을 네트워크 계층으로 전달하는 작업을 multiplexing (다중화) 라 한다.
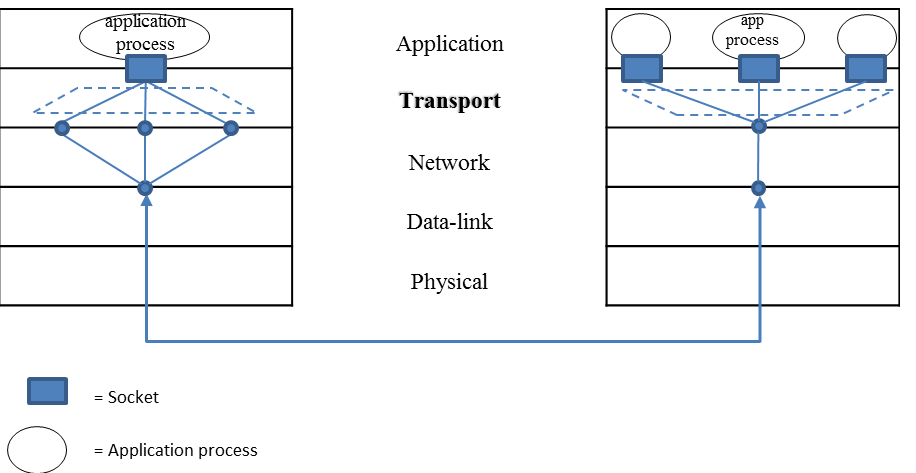
- 왼쪽처럼 프로세스의 데이터를 적절한 크기로 쪼갠 뒤, 헤더를 붙여 세그먼트로 만들어 네트워크 계층에 전달하는 작업이 multiplexing
- 오른쪽처럼 네트워크 계층으로부터 전달받은 세그먼트의 헤더를 조사하여, 적절한 프로세스의 소켓으로 세그먼트의 데이터를 보내는 작업이 demultiplexing
UDP 의 multiplexing & demultiplexing
-
UDP 에서 각 소켓의 식별자는
(호스트 IP, 프로세스의 포트 번호)튜플이다. -
multiplexing 과정에선 출발지 포트 번호와 목적지 포트 번호를 포함하는 세그먼트를 만들어 네트워크 계층에 전달한다.

- demultiplexing 과정에선 수신 호스트가 세그먼트 안의 목적지 포트 번호를 검사한 뒤, 해당 세그먼트의 데이터를 목적지 포트 번호를 가진 소켓으로 전달한다.
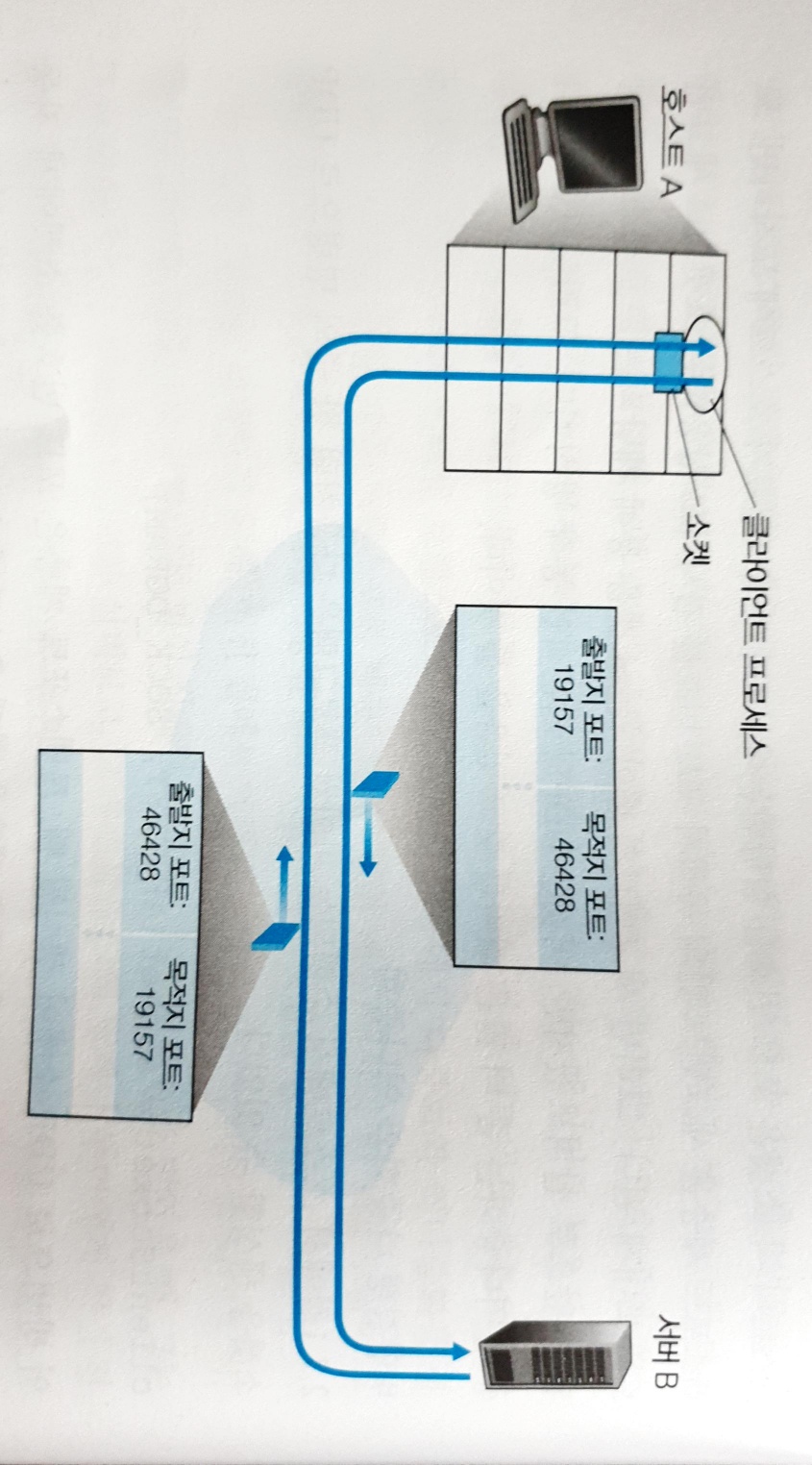
- 출발지 IP 주소가 다른 2개의 호스트가 같은
(목적지 IP, 목적지 포트번호)로 데이터를 보낸다면, 두 세그먼트의 데이터는 목적지의 같은 소켓으로 전달된다.
- 출발지 IP 주소가 같고 포트 번호가 다른 2개의 프로세스가 같은
(목적지 IP, 목적지 포트번호)로 데이터를 보낸다면, 두 세그먼트의 데이터는 목적지의 같은 소켓으로 전달된다.
- 출발지 포트 번호는 demultiplexing 과정에서 사용되진 않지만 수신 프로세스가 발신 프로세스에게 응답하기 위해 캡슐화된다.
TCP 의 multiplexing & demultiplexing
-
TCP 에서 각 소켓의 식별자는
(출발지 IP 주소, 출발지 포트번호, 목적지 IP 주소, 목적지 포트번호)튜플 이다. -
TCP 서버 애플리케이션은 환영 소켓 (listening socket) 을 통해 클라이언트의 소켓과 3-way handshaking 을 수행한다.
-
3-way handshaking 이 끝나면 서버는 새로운 연결 소켓을 만들어 클라이언트 소켓과 연결한다.
-
이때 생성된 새로운 연결 소켓은 환영 소켓과 같은 포트번호를 가지므로, TCP 에서는
(호스트 IP 주소, 포트번호)튜플로 소켓을 식별할 수 없다. -
따라서
(출발지 IP 주소, 출발지 포트번호, 목적지 IP 주소, 목적지 포트번호)의 4가지 정보를 모두 사용하여 소켓을 식별한다.
-
-
multiplexing 과정에선 UDP 와 동일하게 출발지 포트번호와 목적지 포트번호를 포함하는 세그먼트를 만들어 네트워크 계층에 전달한다.
-
demultiplexing 과정에선 수신 호스트가 세그먼트 안의 출발지 포트번호, 목적지 포트번호, IP 패킷 안의 출발지 IP 주소, 목적지 IP 주소를 모두 검사한 뒤 해당 세그먼트의 데이터를 식별된 소켓으로 전달한다.
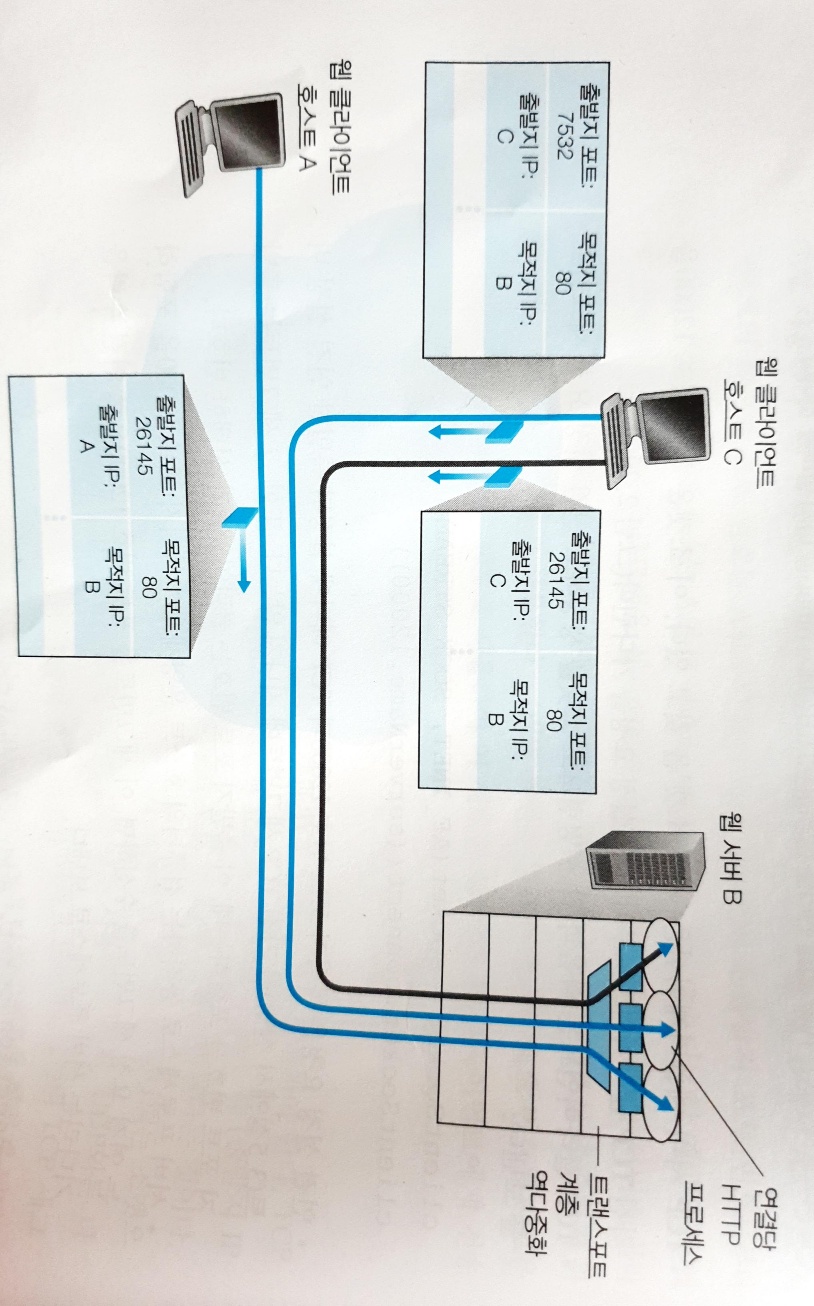
- 출발지 IP 주소가 다른 2개의 호스트가 같은
(목적지 IP, 목적지 포트번호)로 데이터를 보낸다면, 두 세그먼트의 데이터는 2개의 다른 연결 소켓으로 전달된다.
- 목적지 IP 주소는 동일하다.
- TCP 3-way handshaking 을 수행하는 환영 소켓은 하나다.
UDP
-
트랜스포트 계층이 해야하는 최소한의 역할인 multiplexing & demultiplexing 과 간단한 오류 검사 기능 이외엔 특별한 기능을 제공하지 않는다.
-
송수신하는 트랜스포트 계층 개체들간의 handshake 를 수행하지 않는다.
- 비연결형
-
DNS 는 UDP 위에서 동작한다.
-
TCP는 링크가 복잡한 경우 혼잡 제어 메커니즘에 의해 전송률이 제어되지만, UDP 는 이러한 영향을 받지 않는다.
-
TCP 는 수신자가 데이터를 잘 받아 ACK를 보낼때까지 계속해서 재전송을 한다.
- 그러나 조금의 데이터 손실을 허용할 수 있는 애플리케이션은 UDP를 사용하는 것이 성능상 유리하다.
-
TCP는 데이터 전송 전에 3-way handshaking 을 수행하지만, UDP는 어떠한 지연도 없다.
-
TCP는 호스트들이 연결 상태를 유지하는데 반해, UDP는 연결 상태를 유지하지 않는다.
- UDP 기반 애플리케이션은 TCP 기반 애플리케이션보다 더 많은 클라이언트를 수용할 수 있다.
-
일반적으로 TCP 세그먼트는 20 바이트 헤더를 갖지만 UDP 세그먼트는 8바이트 헤더를 갖는다.
-
따라서 UDP는 TCP 대비 빠르고 자유도가 높다.
- 애플리케이션 레벨에서 데이터에 대한 정교한 제어를 하고 싶은 경우에 주로 사용한다.
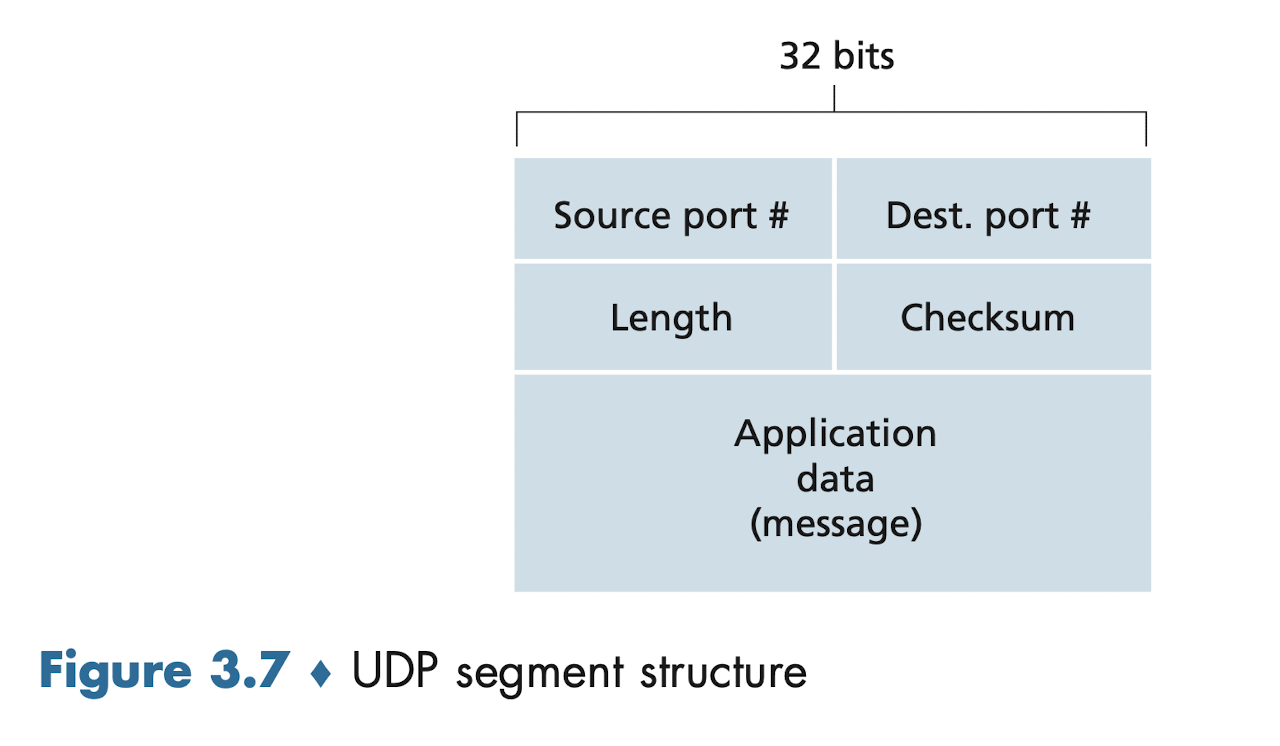
UDP 세그먼트 구조
- Checksum field 는 세그먼트에 오류가 있는지 검출하기 위한 필드이다.
- 오류 검출은 가능하나 오류를 회복하기 위한 어떤 일도 하지 않는다.
Reliable Data Transfer Protocol
-
신뢰적인 데이터 전송 프로토콜
-
전송된 데이터는 손상되거나 손실되지 않는다.
-
모든 데이터는 전송된 순서 그대로 전달받는다.
-
-
rdt 1.0
-
완벽하게 신뢰적인 채널상에서의 신뢰적인 데이터 전송
-
송신측은 수신측에 데이터를 전달한다.
-
수신측은 송신측에게 어떤 피드백도 제공할 필요가 없다.
-
-
rdt 2.0
-
전송되는 데이터의 비트들이 손상될 수 있는 환경에서의 신뢰적인 데이터 전송
-
송신측
-
수신측에 데이터를 전달한다.
-
수신측으로부터 보낸 데이터에 대한 피드백 (ACK, NAK) 을 기다린다.
-
ACK 를 받으면 다음 데이터 전송
-
NAK 를 받으면 방금 보낸 데이터 재전송
-
-
-
수신측
-
데이터의 비트 오류를 검사한다.
-
데이터 상태에 따라 ACK, NAK 로 송신측에게 응답한다.
-
-
rdt 2.0 은 ACK, NAK 패킷이 손상될 수 있다는 가능성을 고려하지 않아 제대로 동작하지 않는다.
-
-
rdt 2.1
-
rdt 2.0 에서 ACK, NAK 패킷의 손상 가능성을 고려
-
송신측에서 데이터를 보낼 때 데이터 패킷에 sequence number 를 삽입한다.
- 만약 수신측에서 이미 갖고있는 sequence number 패킷을 다시 받는다면 해당 패킷을 버린다.
-
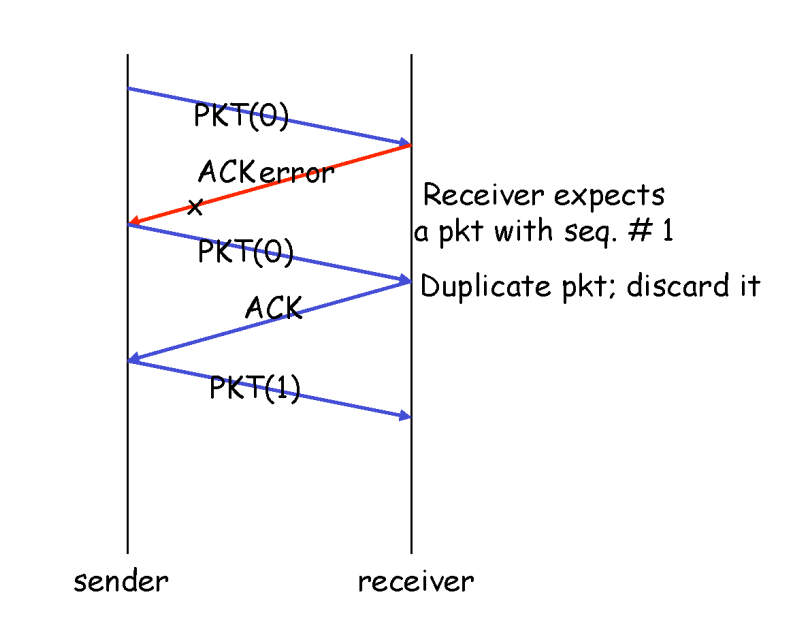
-
rdt 2.2
-
rdt 2.1 에서 NAK 을 제거한 프로토콜
-
수신측이 손상된 패킷을 받으면 NAK 대신 가장 최근에 정확하게 수신된 패킷의 sequence number 를 ACK 에 담아 보낸다.
- 송신측은 ACK 의 sequence number 를 보고, 그 다음 패킷이 제대로 수신되지 않았음을 알 수 있다.
-
수신측은 반드시 ACK 에 정확히 수신된 패킷 sequence number 를 담아 보내야 한다.
-
-
rdt 3.0
-
전송되는 데이터의 비트들이 손상되거나 손실될 수 있는 환경에서의 신뢰적인 데이터 전송
- 오늘날 컴퓨터 네트워크의 환경
-
패킷 손실이 일어난 경우, 송신측은 수신측으로부터 어떠한 응답도 받지 못한다.
- 따라서 송신측은 자신이 보낸 데이터에 대한 응답이 오랜시간동안 안오면 패킷 손실이 일어났다고 판단한다.- 데이터를 보낼때 타이머를 시작한다. - 패킷 손실을 판단한 경우 해당 데이터를 다시 재전송한다.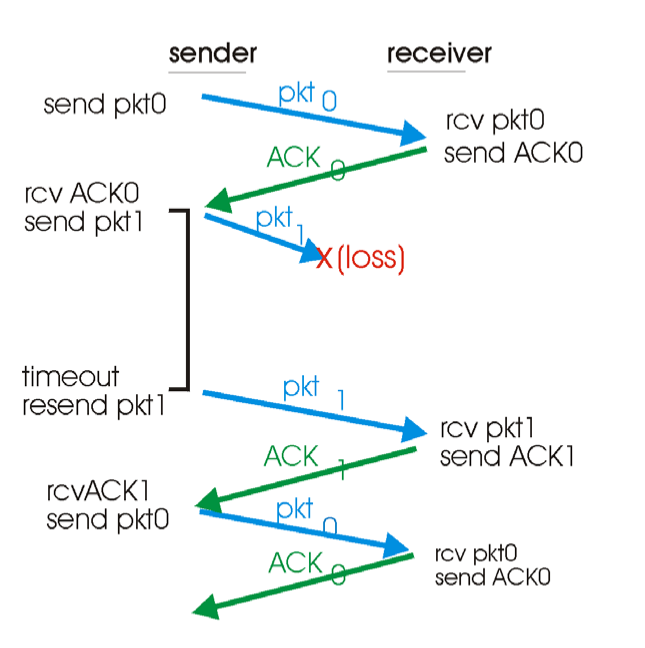
-
파이프라이닝 된 rdt
-
rdt 3.0 은 잘 동작하는 stop-and-wait 프로토콜이다.
- 그러나 송신측은 데이터를 보낸 뒤 수신측의 응답을 기다리며 대부분의 시간을 보내기에 네트워크 이용률이 떨어져 비효율적이다.
-
따라서 송신측이 수신측의 확인 응답을 기다리지 않고 여러개의 패킷을 전송하는 파이프라이닝 방식을 사용해 송신측의 네트워크 이용률을 높일 수 있다.
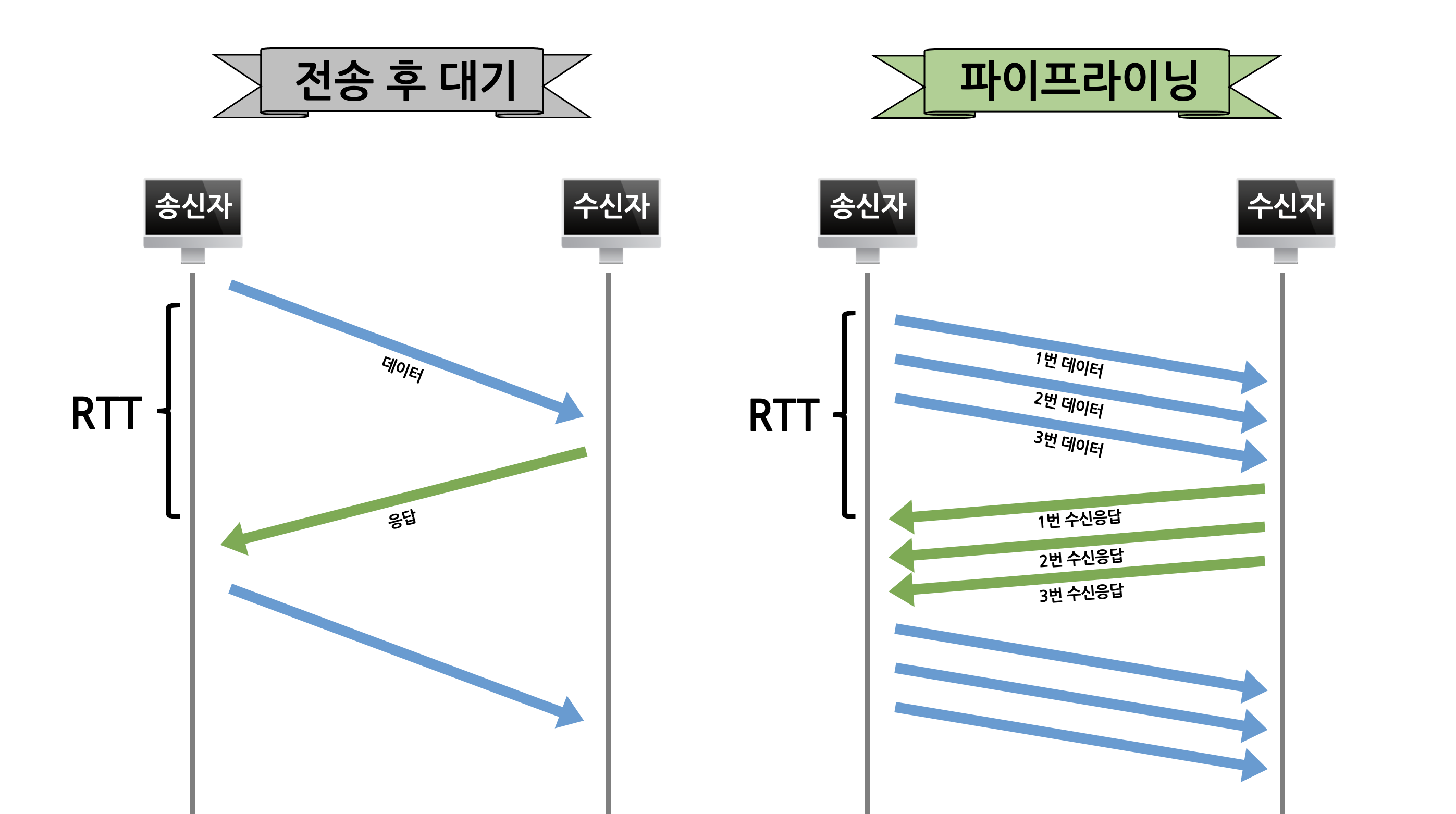
- 파이프라이닝 된 rdt 방식에는 GBN(Go-Back-N) 프로토콜 과 Selective Repeat 프로토콜 이 있다.
Go-Back-N 프로토콜
- N 개의 윈도우 크기를 가진다.
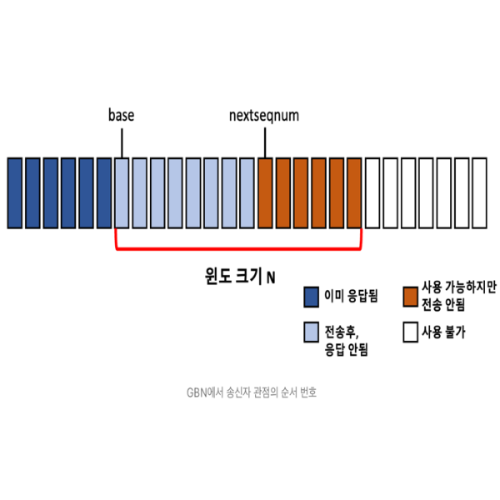
-
송신측
-
윈도우안에 패킷들을 모두 전송한다.
-
#n-1번까지 모두 ACK를 받은 상태에서#n번 ACK 를 받으면 슬라이딩 윈도우의 시작 지점을#n+1로 이동시킨다. -
타임아웃이 발생하면 슬라이딩 윈도우 내의 모든 패킷들을 재전송한다.
-
-
수신측
-
#n-1번 패킷까지 모두 잘 받은 상태에서#n번 패킷을 잘 받으면ACK #n으로 응답한다. -
#n-1번 패킷까지 모두 잘 받은 상태가 아니라면#n번 패킷을 잘 받아도#n번 패킷을 버리고, 가장 최근에 제대로 수신된 패킷에 대한 ACK를 재전송한다.
-
-
수신측 버퍼링이 간단하다.
- 수신측은 순서가 잘못된 패킷에 대한 버퍼링을 하지 않아도 된다.
-
하나의 오류때문에 올바르게 수신된 다수의 패킷을 버리기에 많은 재전송이 발생할 수 있다.
-
윈도우의 첫 번째 인덱스 (base) 에 위치한 패킷의 타임아웃을 검사하는 타이머 한 개만 있으면 된다.
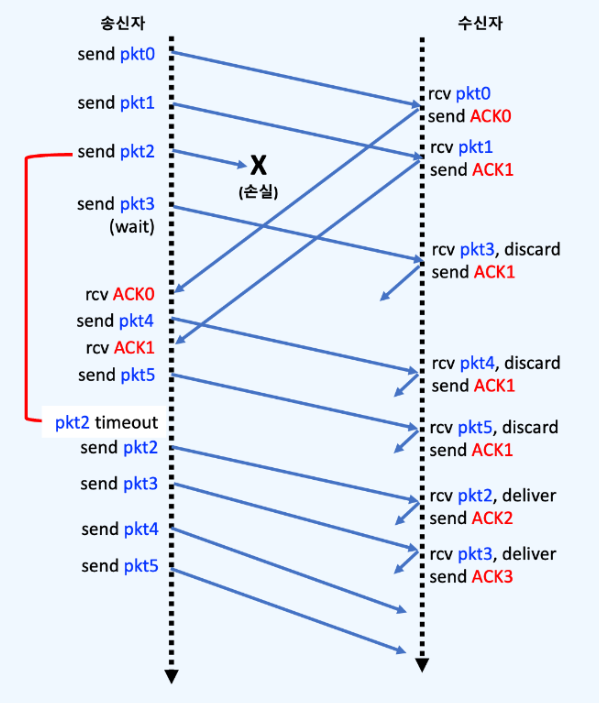
pkt2손실이 발생하여, 수신측은pkt3,pkt4,pkt5는 버리고 ACK 1 만을 보낸다.pkt2의 타임아웃이 발생하면 하나의 슬라이드에 있는[pkt2, pkt3, pkt4, pkt5]를 모두 재전송한다.
Selective Repeat 프로토콜
-
N 개의 윈도우 크기를 가진다.
-
송신측
-
#n-1번까지 모두 ACK를 받은 상태에서#n번 ACK 를 받으면 슬라이딩 윈도우의 시작 지점을#n+1로 이동시킨다. -
윈도우 내에서 전송 오류가 발생했다고 의심되는 패킷만을 재전송한다.
-
-
수신측
-
#n-1번 패킷까지 모두 잘 받은 상태에서#n번 패킷을 잘 받으면 ACK#n으로 응답한다. -
#n번 패킷을 잘못받았더라도#n+1, ...,#n+a번 패킷을 잘 받았다면ACK #n+1, ...,ACK #n+a를 전송하고, 패킷들은 수신 버퍼에 저장한다.- 이후에 송신측 재전송으로
#n번 패킷을 잘 받으면ACK #n으로 응답한다.
- 이후에 송신측 재전송으로
-
-
GBN 과 달리 타임아웃시에 전송 오류가 발생한 하나의 패킷만 재전송해야하므로, 윈도우 내의 모든 패킷은 자신만의 타이머가 필요하다.
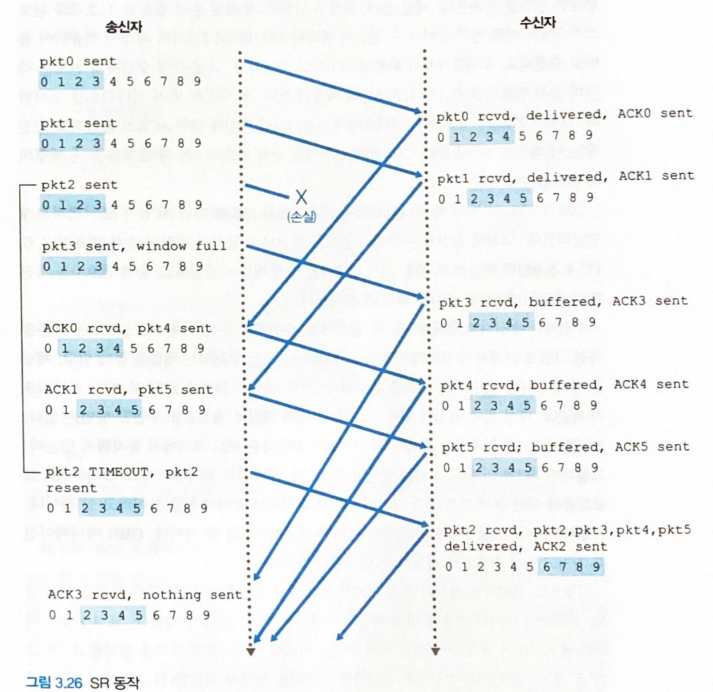
pkt2가 손실되어도 잘 받은pkt3,pkt4,pkt5는 수신측 버퍼에 저장한다.
- 타임아웃이 발생한
손실 pkt2에 대해서만 송신측에서 재전송한다.
- 송신자 윈도우와 수신자 윈도우가 다를 수 있다.
-
송신자 윈도우와 수신자 윈도우가 다를 수 있기에 순서 번호의 범위를 고려해 윈도우 사이즈를 결정해야 한다.
- 윈도우 사이즈는 순서 번호 범위의 절반 이하여야 한다.
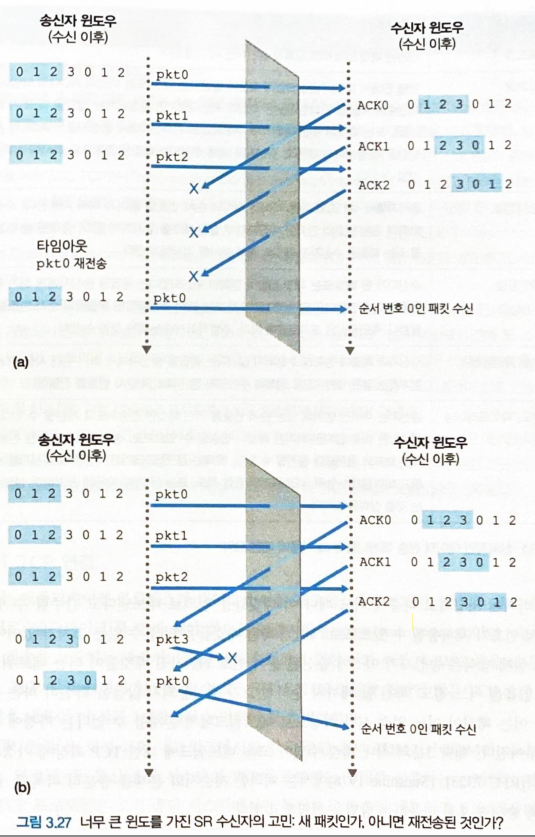
순서 범호 범위 (4) 의 절반보다 큰 윈도우 사이즈 (3) 사용 시
- 수신측 입장에서는
(a)상황에서 전송된pkt 0과(b)상황에서 전송된pkt 0을 적절한 순서로 수신 버퍼에 저장할 수 없다.
TCP
-
두 프로세스는 데이터를 보내기 전 3-way handshake 를 해야한다.
- 연결 지향형 (connection-oriented)
-
full-duplex service 를 제공한다.
- 두 프로세스는 양방향 통신한다.
-
point-to-point 통신이다.
- 한 송신자가 여러 수신자에게 데이터를 전송하는 multi casting 불가
-
이더넷 프로토콜이 1500 바이트의 MTU (maximum transmission unit) 을 가지므로
-
TCP/IP 헤더 길이 40 바이트를 제외하면
-
세그먼트에 담을 수 있는 최대 데이터의 양 MSS (maximum segment size) 는 일반적으로 1460 바이트이다.
- MSS 는 헤더를 포함한 TCP 세그먼트의 최대크기가 아니라 데이터에 대한 최대크기이다.
-
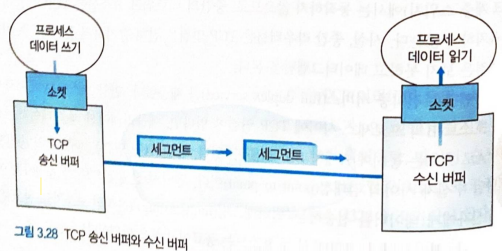
- 송신측 애플리케이션은 TCP 송신 버퍼로 데이터를 보낸다.
- 송신 버퍼에 쌓인 데이터는 원하는 시간에 TCP 세그먼트가 되어 전송된다.
- 수신측에선 TCP 세그먼트의 데이터를 TCP 수신 버퍼에 담는다.
- 수신측 애플리케이션은 수신 버퍼의 데이터 스트림을 읽는다.
TCP 세그먼트 구조
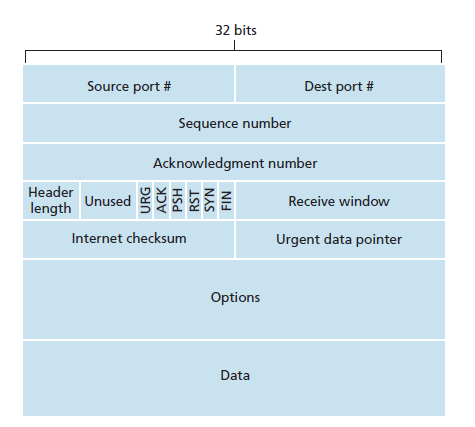
-
TCP 세그먼트는 일반적으로 20바이트 짜리 TCP 헤더와, 데이터로 이루어진다.
- MSS 를 넘는 데이터는 쪼개서 전송한다.
-
다중화와 역다중화에 필요한 출발지, 목적지 포트번호를 갖는다.
-
32비트 sequence number 필드와 acknowledgement number 를 사용해 신뢰적인 데이터 전송 서비스를 구현한다.
-
receive window 필드는 수신자가 받아들일 수 있는 바이트의 크기를 나타낸다.
- 흐름 제어에 사용된다.
-
Options 필드는 선택사항으로 가변 길이를 갖는다.
-
성능을 최적화하기 위해 사용한다.
-
TCP 헤더의 길이를 20바이트로 맞추게 되면, Options 필드는 사용하지 않는다.
-
-
플래그 필드는 총 6비트로 TCP 세그먼트의 특성을 나타낸다.
TCP - Sequence number 필드와 Acknowledgement number 필드
-
TCP 의 신뢰적 데이터 전송 서비스에서 가장 중요한 부분
-
TCP sequence number
-
TCP 는 데이터를 정렬된 바이트 스트림으로 간주한다.
-
TCP 의 sequence number 는 세그먼트 안의 첫 번째 바이트의 바이트 스트림 번호이다.
-
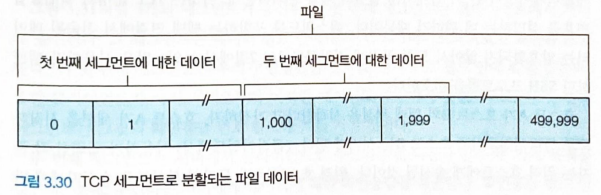
- 첫 번째 세그먼트의 sequence number 는 0번
- 두 번째 세그먼트의 sequence number 는 1000번
-
TCP acknowledgement number
-
수신측 호스트는 송신측 호스트로부터 받기를 기대하는 다음 세그먼트의 sequence number 를 acknowledgement number 필드에 담아 응답 segment 를 전송한다.
-
수신측이
seq #500 segment까지 잘 받았다면ack #501을 응답 segment에 담아 보낸다. -
누적 확인 응답 (cumulative acknowledgement) 을 제공한다.
-
수신측이
seq #0 segment (0 ~ 500 byte),seq #1001 segment (1001 ~ 1500 byte)은 잘 받았는데seq #501 segment (501 ~ 1000 byte)는 받지 못했다면 -
수신측은
ack #501을 응답 segment 에 담아 보낸다. -
송신측이
seq #501 segment를 재전송하여 수신측이 잘 받으면ack #1501을 응답 segment 에 담아 보낸다.
-
-
-
시작 sequence number 는 (ISN, Initial Sequence Number) 각 호스트마다 랜덤으로 선택한다.
-
이를 통해 두 호스트간 연결이 종료된 상태에서
-
전송되고 있던 세그먼트가 있는데
-
같은 두 호스트간의 (포트번호도 같은) 새로운 나중 연결에서
-
전송되고 있던 세그먼트를 유효한 세그먼트로 오인하지 않도록 한다.
-
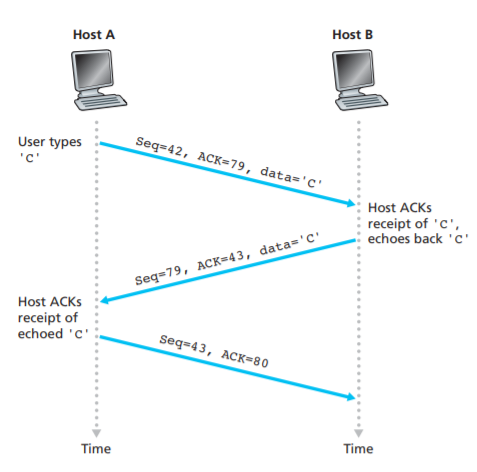
Seq = 42,ACK = 43,data = 'C'
- 다음과 같이 데이터를 운반하는 세그먼트의 Acknowledgement number 필드에 값을 넣어 응답 segment 역할을 동시에 할 수 있다.
- 이렇게 확인 응답을 데이터 세그먼트에 piggyback 함으로써 네트워크 대역폭을 효율적으로 사용할 수 있다.
TCP - RTT 예측과 타임아웃
-
타임아웃 주기는 세그먼트가 전송된 시간부터 ACK를 받을때까지의 시간인 RTT (round-trip time) 보다 조금 커야한다.
-
송신측은 특정 시점마다 임의의 세그먼트의 RTT를 측정하여 Sample RTT를 얻는다.
- Sample RTT 들의 가중 평균값을 고려하여 타임아웃 주기를 결정한다.
-
만약 송신측이 타임아웃 주기가 되지 않았더라도, 특정 패킷에 대해 세 번의 중복된 ACK를 받으면
- 해당 패킷이 손실되었다고 판단하고, 바로 재전송한다.
-
Sample RTT가 없는 초기에는 타임아웃 주기를 1초부터 2배씩 늘려간다.
- Sample RTT 가 생기는 순간부터 타임아웃 주기를 수정한다.
TCP - 신뢰적인 데이터 전송
-
GBN과 SR에서 Acknowledgement number 는 수신측이 제대로 받은 패킷의 Sequence number 였다면
-
TCP 에서의 Acknowledgement number 는 이전 Sequence number 세그먼트들은 잘 받았고 수신측이 앞으로 받아야하는 세그먼트의 Sequence number 이다.
-
TCP는 단일 재전송 타이머를 사용한다.
-
Selective Repeat 처럼 윈도우 내의 모든 세그먼트들이 개별적인 타이머를 갖지 않는다.
- 많은 타이머 = 오버헤드
-
ACK 세그먼트를 받지 못한 가장 오래된 세그먼트가 타이머를 사용하고 있다.
-
만약 타이머가 오래된 세그먼트에 대해 실행중이 아니면, TCP는 현재 세그먼트를 전송하며 타이머를 새로 시작한다.
-
-
TCP는 누적 확인 응답을 사용한다.
-
수신측은 제대로 받지 못한 세그먼트 중 가장 작은 Sequence number 를 Acknowledgement number 로 담아 보낸다.
-
송신측은 Acknowledgement number 와 일치하는 Sequence number 세그먼트 만을 재전송한다.
-
-
TCP는
-
누적 확인 응답과 단일 재전송 타이머를 사용하는 GBN 의 특징과
-
재전송이 필요한 패킷만 선택적으로 재전송하는 SR의 특징을 모두 가진다.
-
따라서 TCP 는 SR 과 GBN 의 혼합형이다.
-
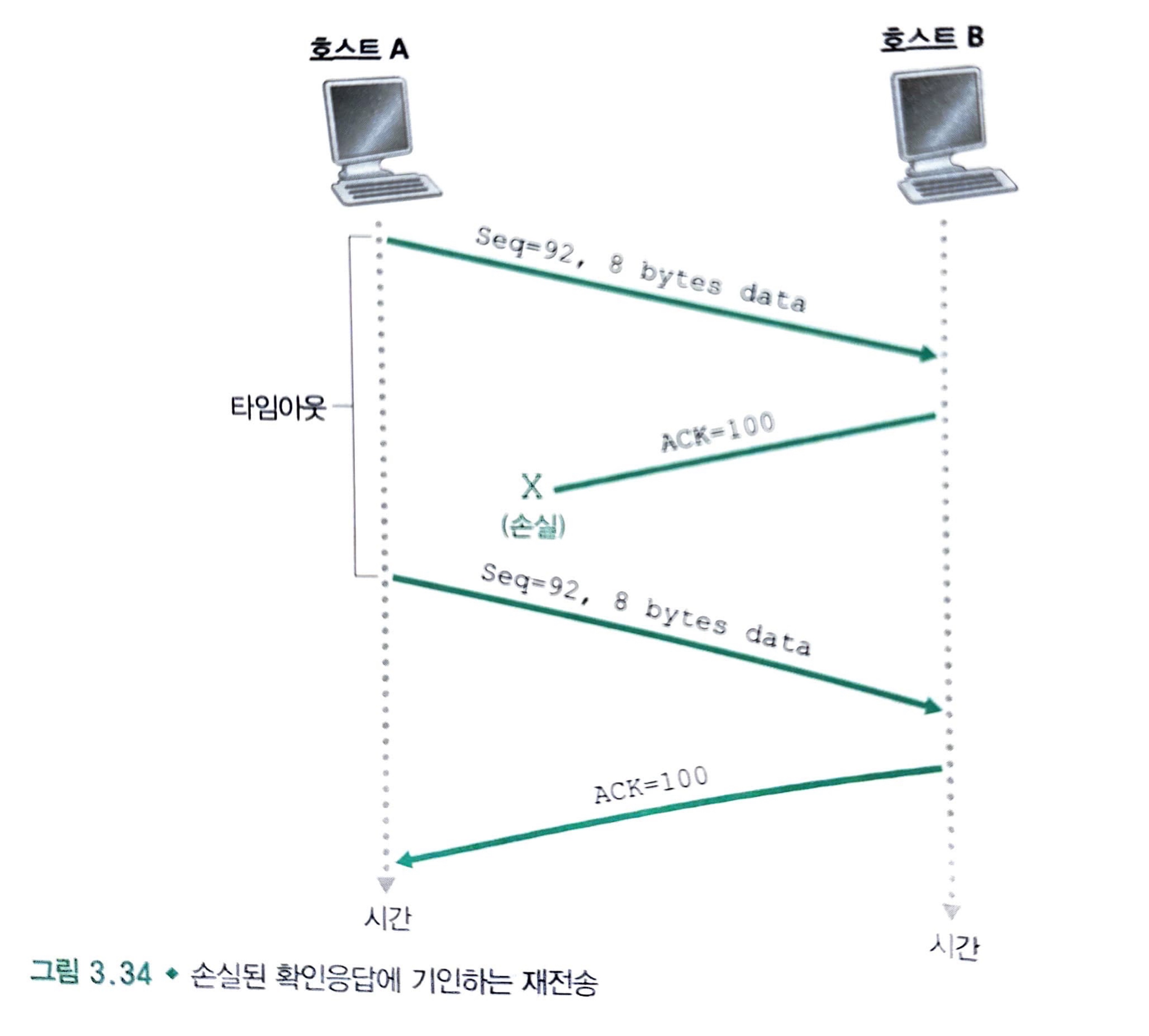
타임아웃 발생 예시
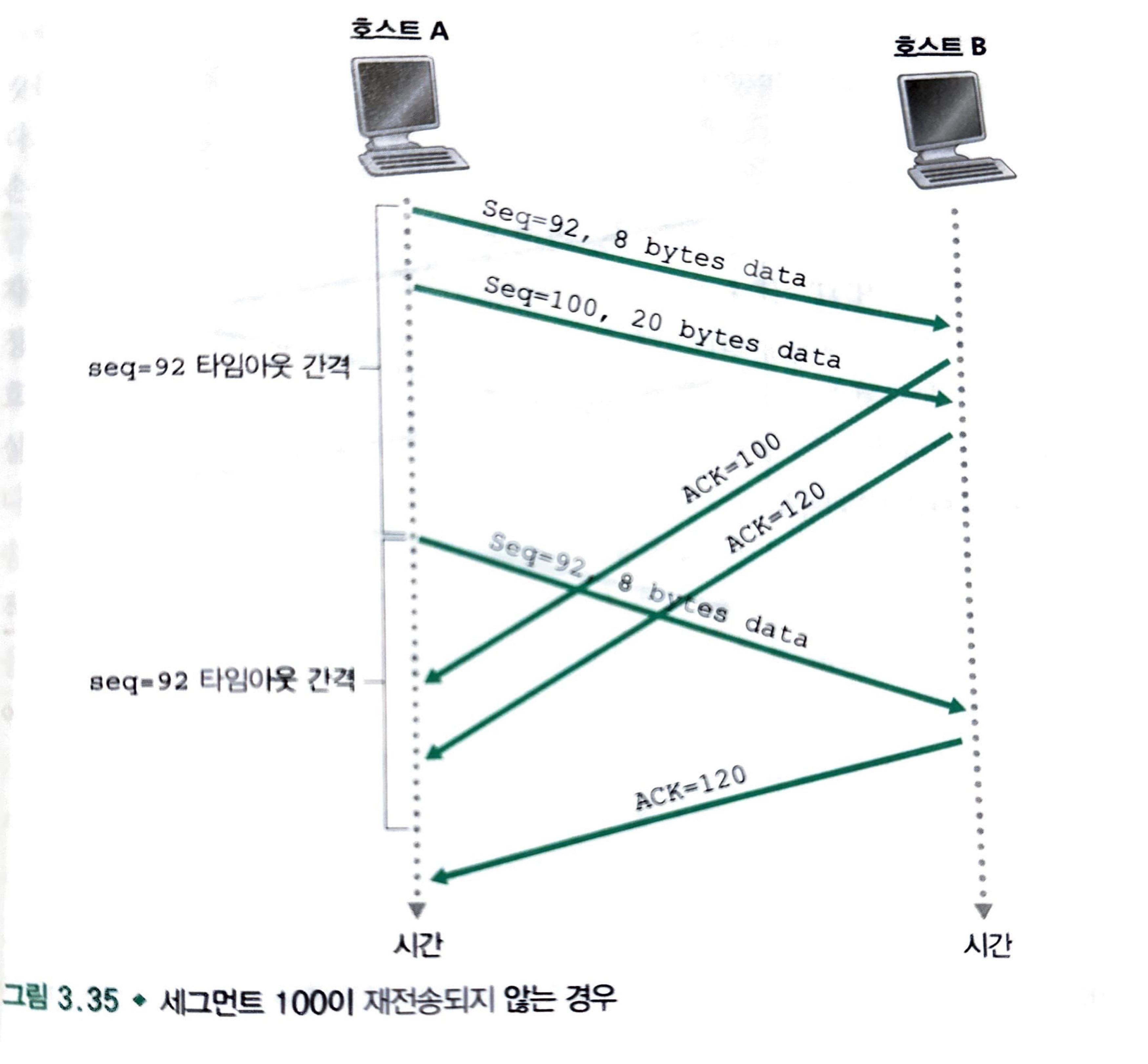
타임아웃 주기 내에서
ACK = 120을 받았으므로 호스트 A는Seq = 120세그먼트를 보내며 새로운 타이머를 시작할 것이다.
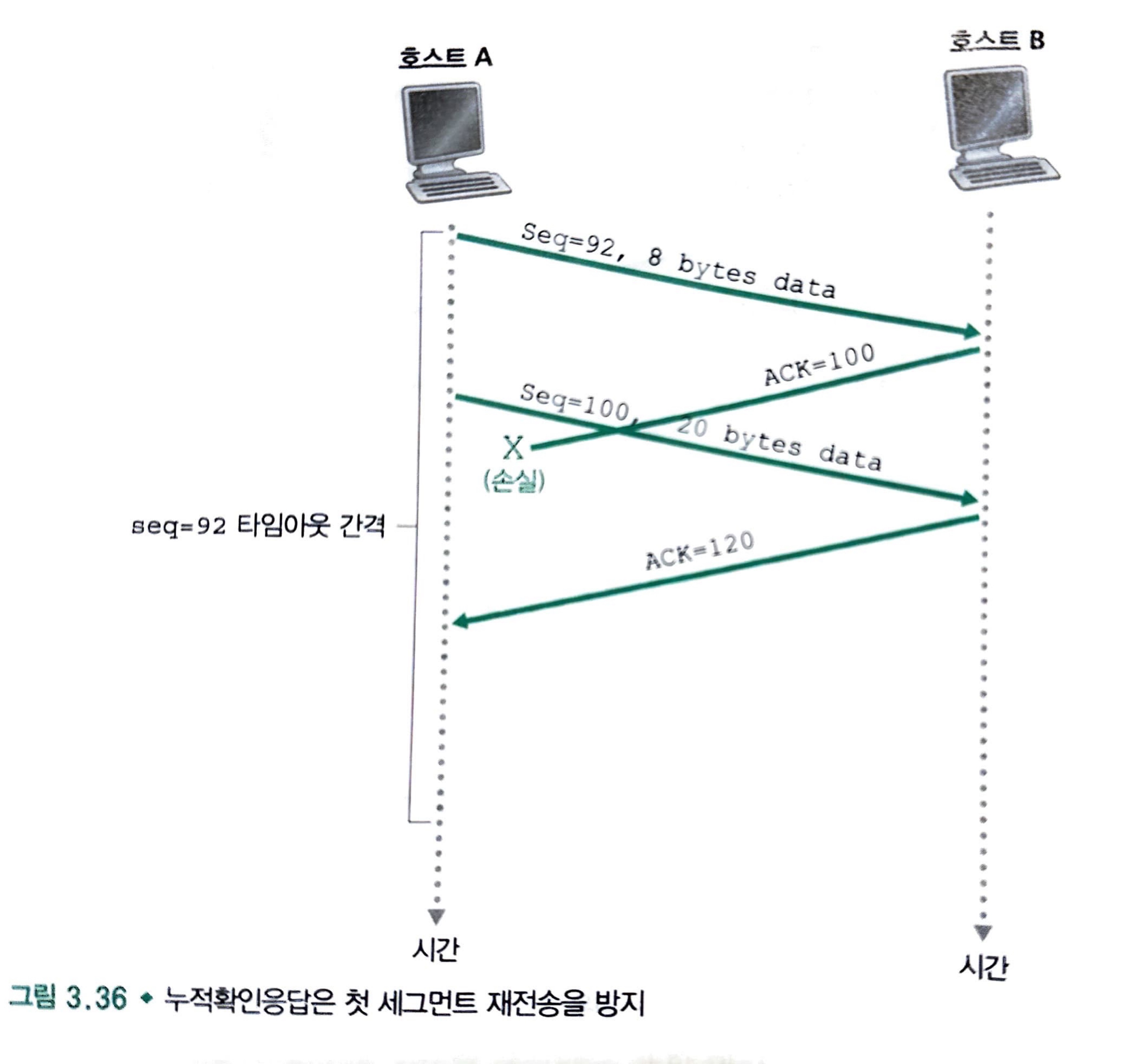
ACK = 100을 못받았더라도ACK = 120을 받았으므로, 호스트 A는Seq = 92세그먼트를 재전송하지 않는다.
TCP - Flow Control
-
수신측의 애플리케이션이 TCP 수신 버퍼의 데이터를 읽는 속도보다, TCP 수신 버퍼에 데이터가 쌓이는 속도가 빠르면 overflow 가 발생한다.
-
TCP 는 송신자가 수신자의 버퍼를 overflow 시키지 않도록 흐름 제어 서비스를 제공한다.
-
수신측 애플리케이션은 TCP 수신 버퍼로부터 데이터를 읽으며 TCP 수신 버퍼의 여유공간을 계산한다.
여유공간 = TCP 수신 버퍼 크기 - 읽지 않고 쌓여있는 데이터 크기
-
수신측 호스트에서 응답 세그먼트의 receive window 필드에 여유 공간 크기를 넣어 반환한다.
-
송신측 호스트는 수신측 호스트의 응답 세그먼트 내의 receive window 필드를 확인하여, 여유공간을 넘지 않도록 송신 데이터의 양을 조절한다.
-
-
만약 수신측 호스트의 TCP 수신 버퍼가 가득찬다면
-
수신측은 receive window 필드값을 0으로 설정해 응답 세그먼트를 보낸다.
-
송신측은 언제 수신버퍼가 비는지 알기 위해 receive window 의 변화를 확인하기 위한 1바이트 데이터를 수신측에 지속적으로 보낸다.
-
수신측 응답 세그먼트에 담긴 receive window 에 여유가 생기면 송신측은 데이터 전송을 재개한다.
-
-
UDP 는 흐름 제어를 제공하지 않기에 수신 버퍼 overflow 가 발생하면 데이터는 유실된다.
TCP 연결 관리
- TCP 연결 수립 (3-way handshake)
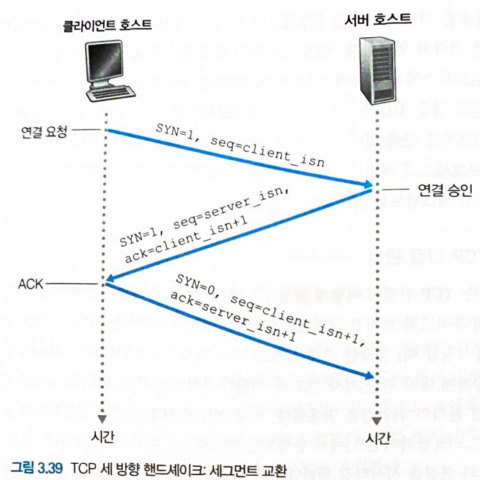
- 1단계: TCP 클라이언트는 TCP 서버로 SYN 세그먼트를 보낸다.
- SYN 플래그 비트가 1이고 애플리케이션 계층 데이터를 포함하지 않는 특별한 세그먼트이다.
client_isn(클라이언트의 초기 순서 번호) 는 임의로 정해 sequence number 필드에 넣는다.
- 2단계: TCP 서버는 SYN 세그먼트를 받으면 TCP 클라이언트로 SYNACK 세그먼트를 보낸다.
- 연결 승인 세그먼트인 SYNACK 세그먼트 역시 애플리케이션 계층 데이터를 포함하지 않는다.
- SYN 플래그비트는 1이다.
- acknowledgement number 필드는 클라이언트 초기 순서 번호 + 1 로 설정된다.
server_isn(서버 초기 순서 번호) 는 임의로 정해 sequence number field 에 넣는다.
- 3단계: TCP 클라이언트가 TCP 서버의 SYNACK 세그먼트를 받으면, TCP 서버의 SYNACK 세그먼트에 대한 ACK 세그먼트를 보낸다.
- 연결은 수립되었기에 SYN 플래그 비트는 0이다.
- acknowledgement number 필드는 서버 초기 순서 번호 + 1 로 설정된다.
- 클라이언트는 ACK 세그먼트에 애플리케이션 데이터를 같이 실어 보낼 수 있다.
위의 세 단계가 완료되면 두 호스트는 서로에게 데이터를 포함한 세그먼트를 주고 받을 수 있다.
-
TCP 연결 해제 (4-way handshake)
- TCP 연결을 끝냄으로써 호스트가 연결하며 사용했던 자원 (버퍼, 변수) 을 반납한다.
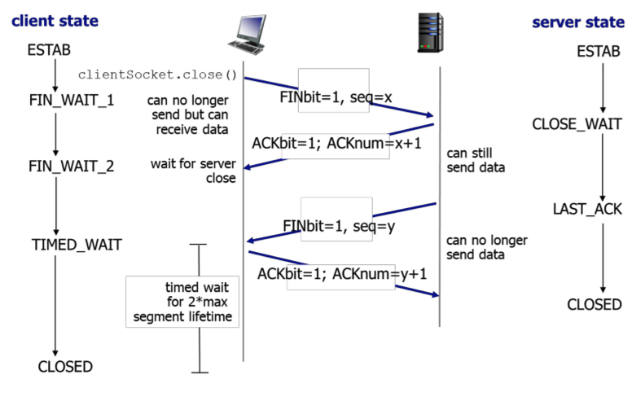
- 1단계: TCP 클라이언트는 TCP 서버에게 FIN 플래그비트가 1인 종료 요청 세그먼트를 보낸다.
- 2단계: TCP 서버는 TCP 클라이언트의 종료 요청 세그먼트에 대한 ACK 세그먼트를 보낸다.
- 3단계: TCP 서버는 TCP 클라이언트에게 FIN 플래그비트가 1인 종료 요청 세그먼트를 보낸다.
- 4단계: TCP 클라이언트는 TCP 서버의 종료 요청 세그먼트에 대한 ACK 세그먼트를 보낸다.
- 서버는 ACK 를 받으면 연결을 종료하고, 클라이언트도 일정 시간 대기 후 연결을 종료한다.
- TCP 서버가 FIN 세그먼트보다 일찍 보낸 데이터 세그먼트가, TCP 클라이언트에 FIN 세그먼트보다 늦게 도착할 수 있기 때문에
- TCP 클라이언트는 TCP 서버에 ACK 를 보내고도 일정시간 대기후에 연결을 종료한다.
SYN flood attack
-
고전적인 TCP 연결 수립 (3-way handshake) 과정에서는
-
TCP 클라이언트가 1단계에서 보낸 SYN 세그먼트를 TCP 서버가 받는 시점에
-
TCP 서버내에 연결 변수와 버퍼를 할당한다.
- TCP 클라이언트가 보낸 SYN 세그먼트 관련 정보를 저장
-
이후 TCP 클라이언트가 3단계에서 보낸 ACK 세그먼트를 받으면 미리 저장한 SYN 세그먼트 관련 정보를 조회하여, 정상적인 연결인지 판별한 뒤, 연결을 맺는다.
-
만약 TCP 클라이언트가 3단계에서 보낼 ACK 세그먼트를 일정시간동안 보내지 않으면, TCP 서버는 할당된 자원을 회수하고 연결을 종료한다.
-
-
SYN flood attack 은 이러한 TCP 연결 관리 방식을 악용한다.
-
공격자는 TCP 3-way handshake 의 3단계를 완료하지 않고, 무수히 많은 SYN 세그먼트 (1단계) 만을 보낸다.
-
TCP 서버는 전혀 사용되지 않는 할당 자원들을 무수히 많은 반쪽짜리 연결에 할당한다.
-
TCP 서버의 연결 자원이 소진되어 정상적인 TCP 클라이언트의 서비스 이용이 제한된다.
-
-
이러한 SYN flood attack 을 막기 위해 SYN 쿠키를 사용한다.
-
TCP 서버는 TCP 클라이언트가 보낸 SYN 세그먼트의 출발지, 목적지 IP 주소, 포트번호들과 서버의 비밀번호를 해시함수에 넣는다.
-
해시값을 TCP 서버의 SYNACK 패킷의 초기 sequence number 로 설정하여 전송한다.
-
TCP 서버는 TCP 클라이언트가 보낸 SYN 세그먼트 관련 어떤 정보도 저장하지 않는다.
- TCP 서버는 TCP 클라이언트로부터 SYN 세그먼트를 받아도 자원을 할당하지 않는다.
-
이후, 정상적인 클라이언트로부터 ACK 세그먼트를 받으면 해당 세그먼트의 출발지, 목적지 IP 주소, 포트번호들과 서버의 비밀번호를 해시함수에 넣어 해시값을 얻어낸다.
-
이렇게 얻은
해시값 + 1이 ACK 세그먼트의 acknowledgement number 필드와 같다면 올바른 응답으로 판단하고 자원을 할당하여 연결을 맺는다. -
즉, TCP 클라이언트가 보낸 SYN 세그먼트의 정보를 바탕으로 SYN 쿠키 (해시값) 를 만듦으로써 SYN flood attack 을 막는다.
-
Congestion Control
-
네트워크가 혼잡해짐에 따라 다양한 비용이 발생한다.
-
네트워크 라우터의 큐잉 지연이 커진다.
-
송신자는 버퍼 overflow 때문에 버려진 패킷을 다시 재전송해야한다.
- 송신자의 재전송은 네트워크의 혼잡을 심화한다.
-
-
따라서 네트워크 혼잡을 일으키는 송신자들을 억제하는 메커니즘이 필요하다.
-
종단 간의 혼잡 제어 방식
-
네트워크 혼잡의 정도와 유무를 각 호스트가 추측하는 방식
-
전통적인 TCP 가 채택한 방식
-
-
네트워크 지원 혼잡 제어
- 네트워크 안의 라우터들이 송수신자 모두에게 네트워크 혼잡도에 대한 직접적인 피드백을 제공한다.
-
TCP - Congestion Control
-
전통적인 TCP는 종단간의 혼잡 제어 방식을 채택한다.
-
송신자는 네트워크 혼잡 정도에 따라 전송률을 조정한다.
-
송신측은 congestion window (혼잡 윈도우) 변수를 갖는다.
-
송신측의 전송률은
min(congestion window, receive window)이하이다.- 즉, 전송률은 흐름 제어용 수신 윈도우 크기와 혼잡 제어 윈도우 크기의 최소값보다 작아야 한다.
-
송신측은 손실 이벤트 (3개의 중복된 ACK, 타임아웃) 가 발생하면 네트워크가 혼잡하다고 판단하여 congestion window 크기를 줄인다.
-
송신측은 확인 응답이 제대로 도착하면 네트워크가 쾌적하다고 판단하여 congestion window 크기를 증가시킨다.
-
-
TCP 는 혼잡 제어 알고리즘을 사용하여 송신측의 자세한 전송률을 결정한다.
TCP 혼잡 제어 알고리즘
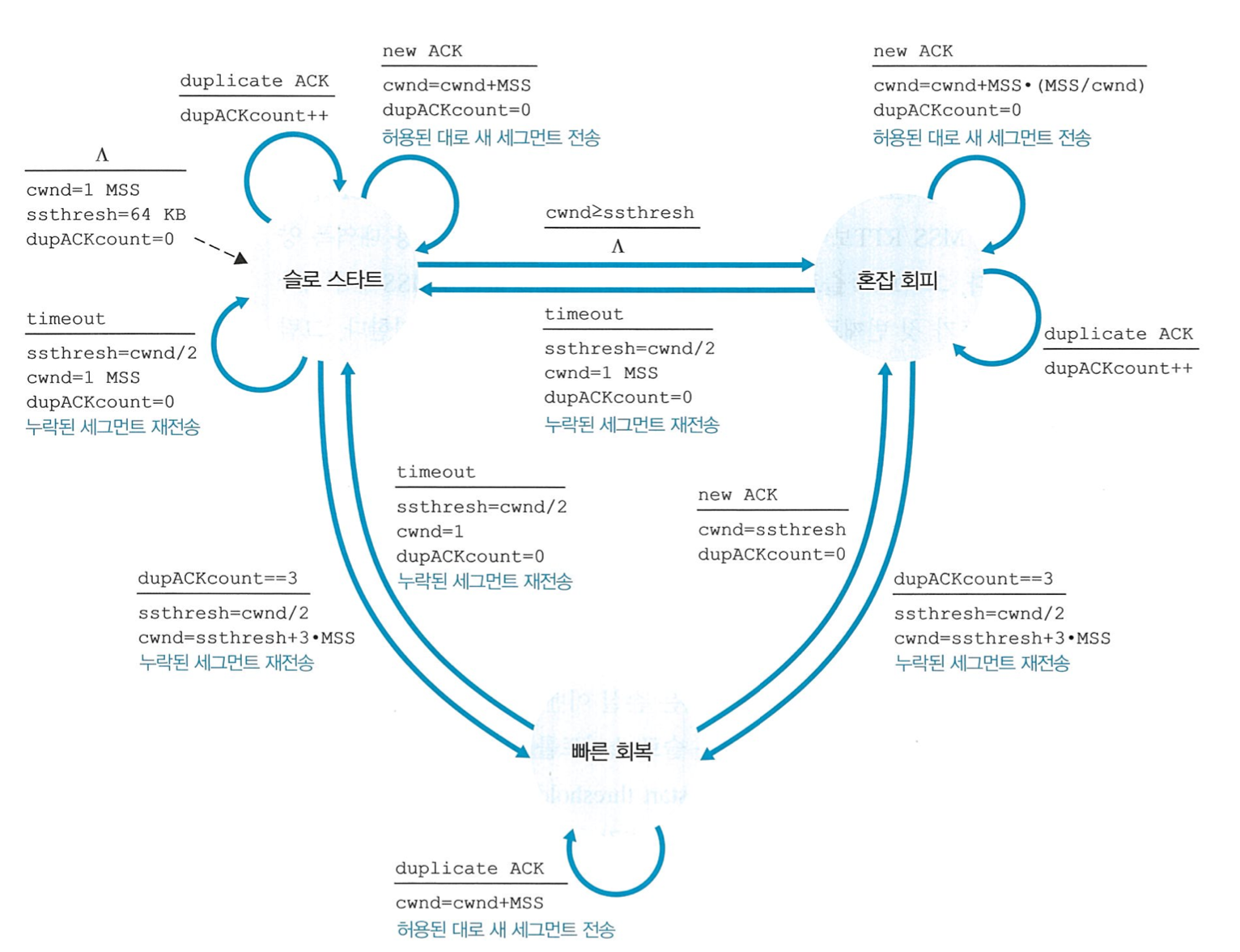
TCP 혼잡제어 알고리즘 FSM
-
slow start
-
congestion window 크기를 일반적으로 1 MSS 에서 시작한다.
-
앞서 보낸 1개의 세그먼트의 ACK 를 받으면 congestion window 크기를 2 MSS 로 늘린다.
-
앞서 보낸 n개의 세그먼트들의 ACK 를 받으면 congestion window 크기를 2n MSS 로 늘린다.
-
TCP 전송률이 작은 값으로 시작하여 지수적으로 증가한다.
-
slow start 종료 조건
-
타임아웃 발생 시
-
slow start threshold 를 타임아웃 발생 시점의
congestion window 크기 / 2로 설정한다. -
이후 congestion window 크기를 1 MSS 로 설정하고 다시 새로운 slow start 를 시작한다.
-
-
현재 congestion window 크기가 slow start threshold 값을 넘는 경우
- slow start 대신 혼잡 회피 모드로 전환하여 더 조심스럽게 congestion window 크기를 증가시킨다.
-
3개 이상의 중복 ACK 검출 시
- slow start threshold 를 손실 세그먼트 발생 판단 시점의
congestion window 크기 / 2로 줄인 뒤, 빠른 회복 상태로 전환한다.
- slow start threshold 를 손실 세그먼트 발생 판단 시점의
-
-
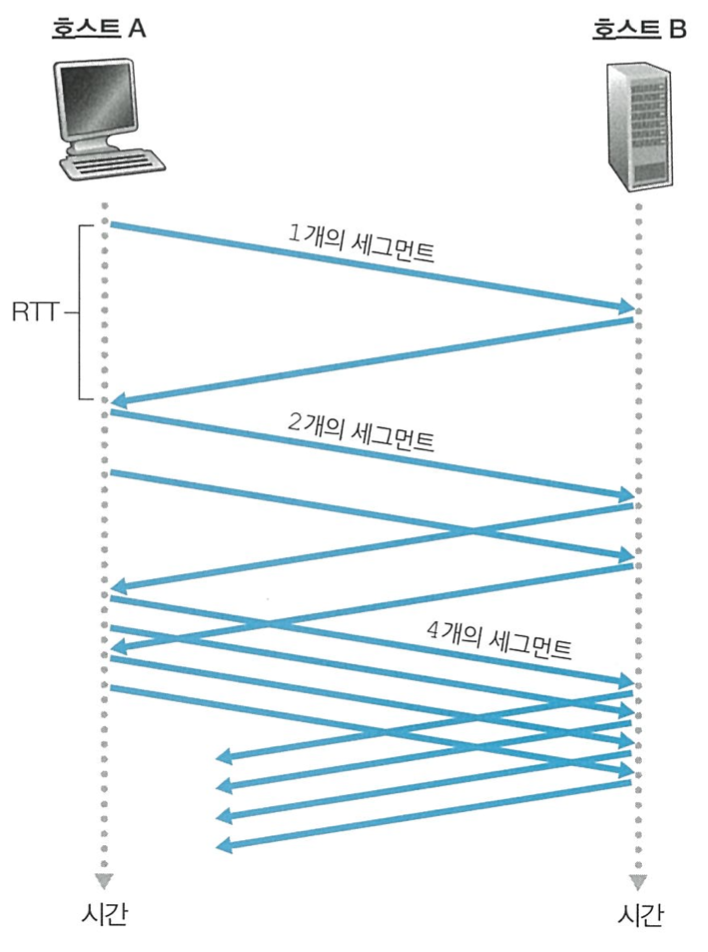
slow start 모드 내에서는 세그먼트의 응답을 받을때마다, 2개의 세그먼트를 보낸다.
-
혼잡 회피
-
혼잡이 마지막으로 발견된 시점 (타임아웃) 에서 congestion window 크기를 반으로 줄이고 시작한다.
-
매 RTT 마다 congestion window 크기를 1 MSS 만큼만 증가시킨다.
-
TCP 전송률이 선형적으로 증가한다.
-
혼잡 회피 종료 조건
-
타임 아웃 발생 시
-
slow start threshold 를 타임아웃 발생 시점의
congestion window 크기 / 2로 설정한다. -
이후 congestion window 크기를 1 MSS 로 설정하고 slow start 를 시작한다.
-
-
3개 이상의 중복 ACK 검출 시
- slow start threshold 를 손실 세그먼트 발생 판단 시점의
congestion window 크기 / 2로 줄인 뒤, 빠른 회복 상태로 전환한다.
- slow start threshold 를 손실 세그먼트 발생 판단 시점의
-
-
MSS = 1460Byte, cwnd = 14600Byte 라 가정하면, 10개의 세그먼트가 한 RTT내에 전송된다. 따라서 하나의 RTT에서 cwnd 를 1 MSS 만큼 증가시키려면, 한 개의 ACK 세그먼트를 받을 때마다 cwnd 를 1/10 MSS 만큼 증가시키면 된다.
-
빠른 회복
-
TCP 혼잡 제어 알고리즘에서 필수사항은 아니다.
-
반으로 줄어든 congestion window 크기에다가 손실된 세그먼트 발생 판단의 근거가 된
중복 ACK 개수 * 1 MSS만큼을 더한다.- ex)
cwnd = 반토막 난 cwnd + 3 MSS
- ex)
-
이후 매 RTT 마다 congestion window 크기를 1 MSS 만큼만 선형 증가시킨다.
-
빠른 회복 종료 조건
- 타임아웃 발생 시 빠른 회복을 종료하고 다른 알고리즘과 똑같이 동작한다.
-
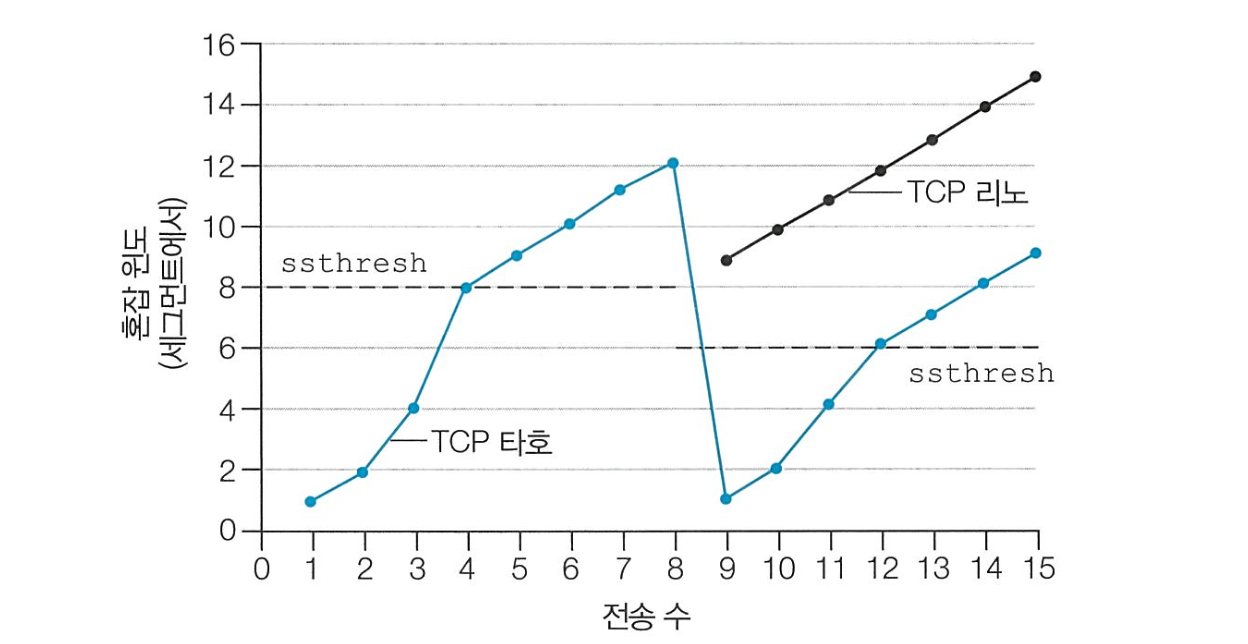
8번째 RTT에서 3개의 중복 ACK 가 발생한 경우
- TCP 타호는 구버전으로 빠른 회복이 없다.
- 3개의 중복 ACK 발생 시 타임아웃 발생과 똑같이 처리한다.
- TCP 리노는 빠른 회복을 사용한다.
- 3개의 중복 ACK 발생 시
cwnd = 반으로 줄어든 cwnd + 3 MSScw = 6 + 3 = 9
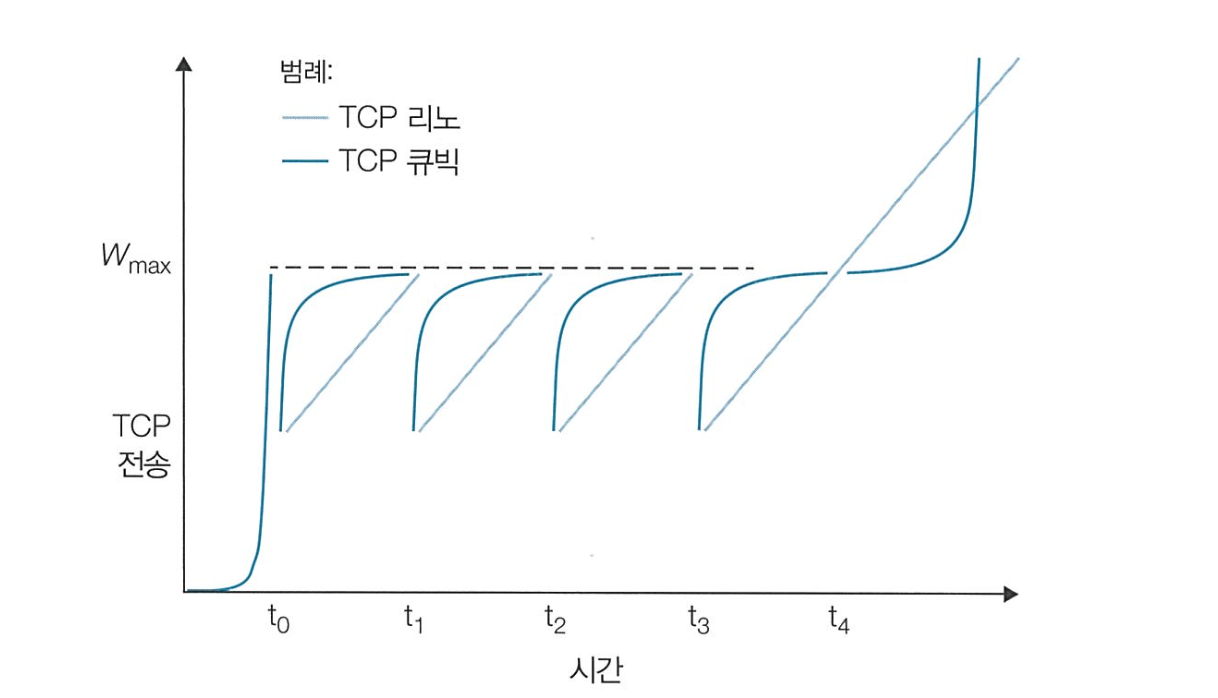
- TCP 리노는 혼잡 회피 단계에서 congestion window 크기를 선형 증가 시킨다.
- TCP 큐빅은 손실이 마지막으로 감지된 congestion window 크기인 W_max 에 가까워질 때까진 congestion window 크기를 급격하게 증가시키다가, W_max 에 가까워지면 조심스럽게 증가시킨다.
- 따라서 TCP 리노 대비 더 많은 전체 처리량을 갖는다.
- 현재는 TCP 큐빅을 많이 사용한다.
TCP 와 형평성
-
서로 다른 TCP 연결이 서로 다른 링크 이용률을 초기에 갖고 있더라도, TCP 혼잡제어 알고리즘에 의해 모든 TCP 연결은 공평한 링크 이용률로 수렴한다.
-
예를 들어, 전송 링크의 병목 링크 대역폭이 100, TCP 연결 A가 30의 전송률, TCP 연결 B가 70의 전송률을 갖는다고 가정 (혼잡 회피 모드로만 동작한다고 가정한다.)
-
A: 30, B: 70 에서 혼잡을 감지하여 두 연결 모두 전송률을 반으로 줄인다.
- A: 15, B: 35 의 전송률을 갖게 된다.
-
전송률을 1씩 증가시키다 보면, A: 40, B: 60 에서 혼잡을 감지하여 두 연결 모두 전송률을 반으로 줄인다.
- A: 20, B: 30 의 전송률을 갖게 된다.
-
전송률을 1씩 증가시키다 보면, A: 45, B: 55 에서 혼잡을 감지하여 두 연결 모두 전송률을 반으로 줄인다.
-
이처럼 결국에는 50:50 으로 수렴하게 된다.
-
-
그러나 TCP 기반 애플리케이션의 다중 병렬 연결에 의해 공평성 문제는 완전히 해결되지 못한다.
- A 애플리케이션이 7 개의 다중 병렬 TCP 연결을 보내고, B 애플리케이션이 3 개의 다중 병렬 TCP 연결을 보낸다면, 각각의 TCP 연결들은 링크 이용률을 공평하게 나누더라도 애플리케이션 측면에서는 7:3 으로 공평하지 않다.
네트워크 계층
네트워크 계층
-
네트워크 계층은 트랜스포트 계층으로부터 세그먼트를 받아 데이터그램으로 캡슐화하여 인접한 라우터에게 전달한다.
-
수신 호스트의 네트워크 계층은 데이터그램안에서 세그먼트를 추출하여 트랜스포트 계층으로 보낸다.
-
즉, 네트워크 계층의 근본적인 역할은 송신 호스트에서 수신 호스트로 패킷을 전달하는 것이다.
-
네트워크 계층의 중요한 기능 2가지
-
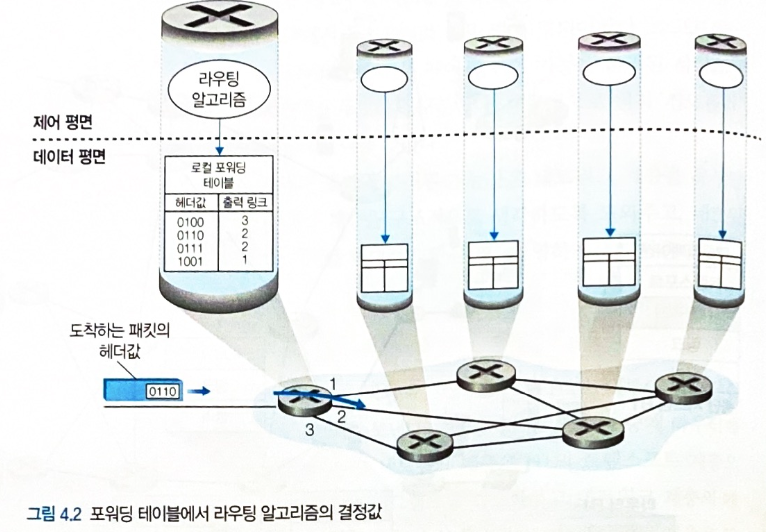
포워딩
-
패킷이 라우터의 입력 링크로 들어오면, 해당 패킷을 적절한 출력 링크로 이동시키는 것
-
매우 짧은 시간 동안, 하드웨어적으로 실행된다.
-
-
라우팅
-
송신자가 수신자에게 패킷을 전송할 때 최적의 패킷 이동 경로를 결정하는 것
-
상대적으로 긴 시간을 갖고 소프트웨어적으로 실행된다.
-
-
네트워크 계층이 제공 가능한 서비스
-
패킷이 출발지 호스트로부터 목적지 호스트까지 도착하는 것을 보장
-
패킷이 출발지 호스트로부터 목적지 호스트까지 특정 시간 이내에 도착하는 것을 보장
-
패킷이 목적지에 송신 순서대로 도착하는 것을 보장
-
최소 대역폭을 보장
-
암호화를 통한 보안 서비스 제공
그러나 인터넷 네트워크 계층은 패킷의 통신 순서대로 수신됨을 보장하지 않고, 패킷이 목적지에 도착하는 것도 보장하지 않으며, 보장된 최소 대역폭도 없는 최선형 서비스를 제공한다. (best-effort service)
라우터의 구조
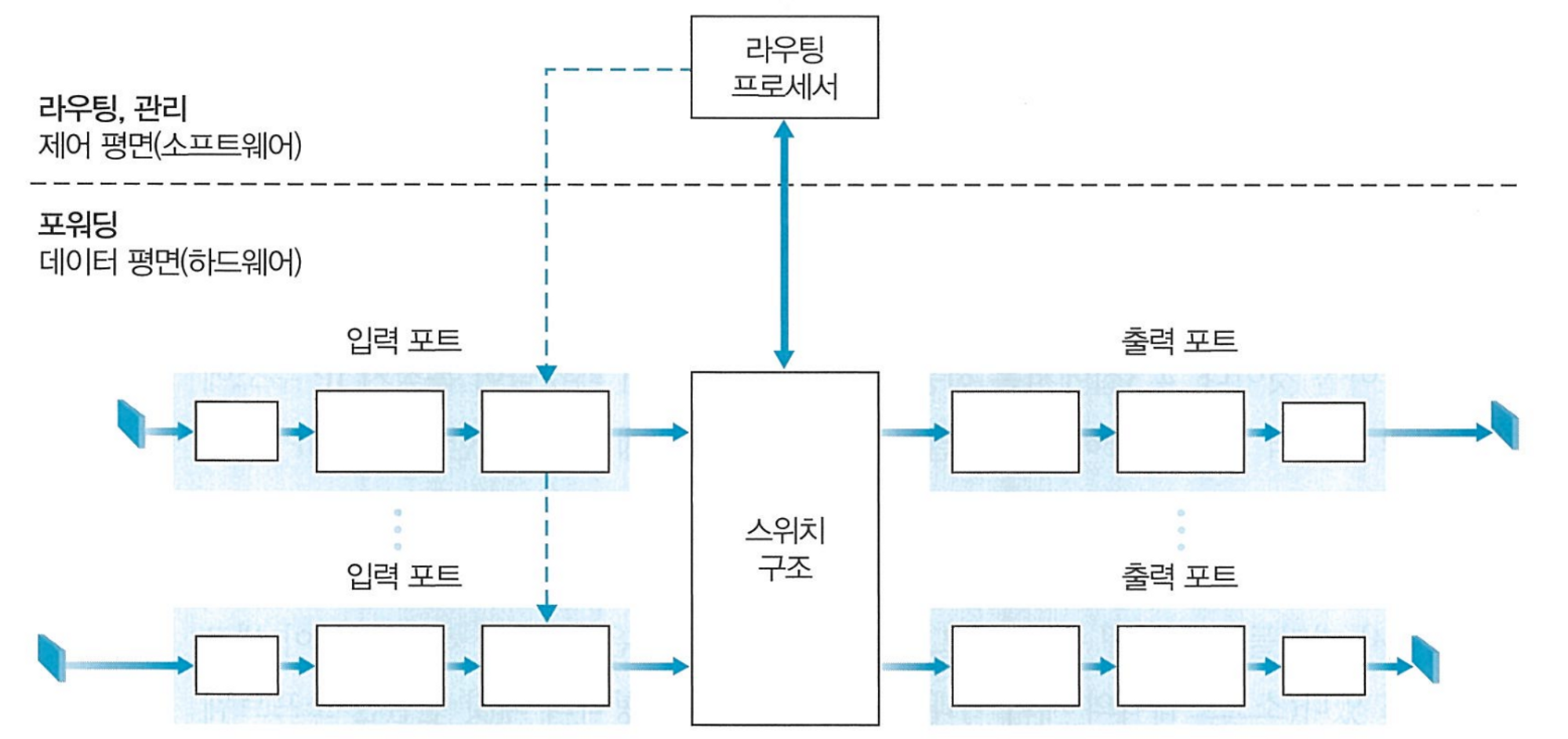
-
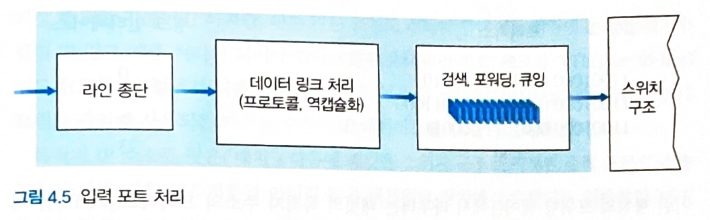
입력 포트
-
외부로부터 패킷을 입력받는다.
- 물리 및 링크 계층 처리 수행
-
검색을 통해 들어온 패킷의 출력 포트를 결정한다.
-
들어온 패킷의 목적지 주소의 prefix 를 라우터내의 포워딩 테이블의 엔트리들과 비교한다.
-
매치되는 엔트리가 있다면 해당 패킷을 연관된 링크 인터페이스로 보낸다.
-
다수의 매치가 있을때는 longest prefix matching rule 에 따라 가장 긴 매치 엔트리의 링크 인터페이스로 패킷을 보낸다.
-
-
패킷 버전 번호, 체크섬 TTL 등을 확인한다.
-
-
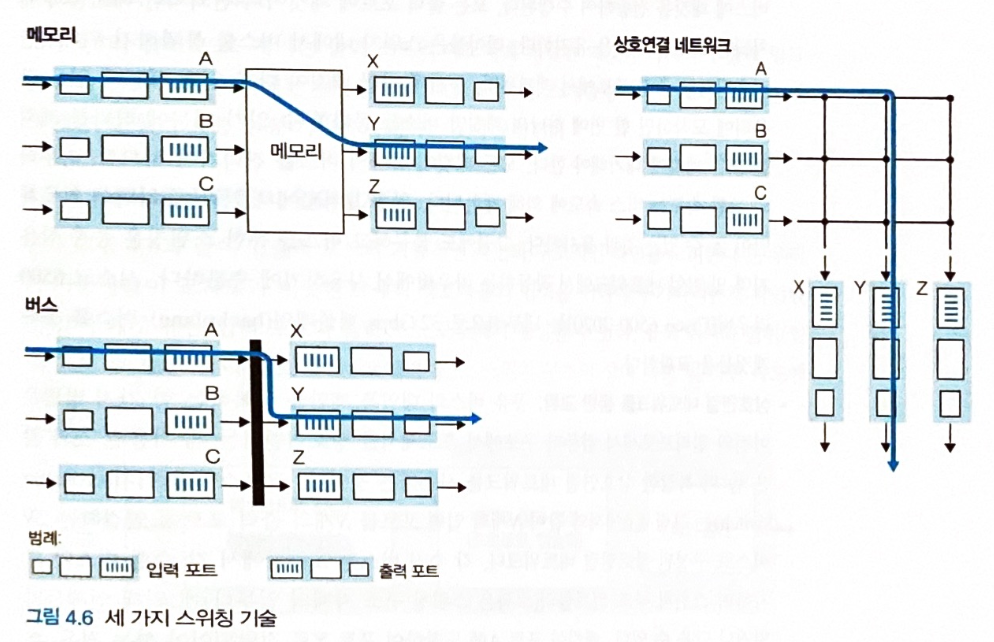
스위치 구조
-
라우터의 입력 포트와 출력 포트를 연결한다.
-
다양한 방식으로 스위칭을 수행한다.
-
-
출력 포트
-
스위치 구조에서 수신한 패킷을 저장 후 출력 링크로 패킷을 전송한다.
- 물리 및 링크 계층 처리 수행
-
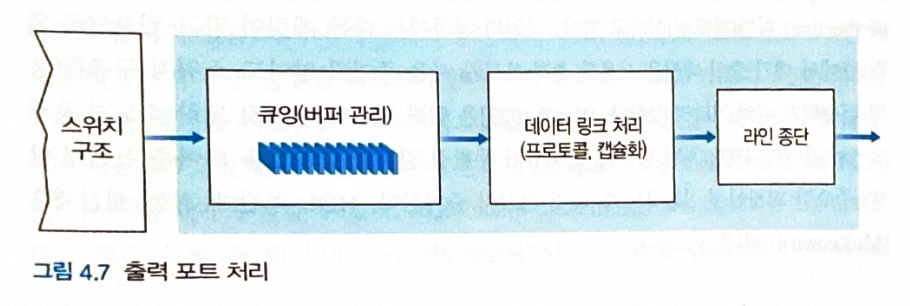
-
라우팅 프로세서
-
라우팅 프로토콜 실행
-
라우팅 테이블 상태 정보를 유지 관리
-
포워딩 테이블을 계산한다.
-
라우터의 큐잉
-
큐잉은 입력 포트, 출력 포트 모두에서 형성될 수 있다.
-
큐가 커지면 라우터의 메모리를 초과해 패킷 손실이 발생할 수 있다.
-
입력 큐잉
-
입력 포트에 패킷이 쌓이는 속도가 스위치 구조의 처리속도보다 빠르면 발생
-
출력 포트가 경쟁이 없는 상태더라도 스위치 구조에서의 HOL blocking (Head-Of-the-Line) 때문에 대기가 발생할 수 있다.
- 즉, 다른 출력 포트로 이동하는 패킷때문에 대기가 발생할 수 있다.
-
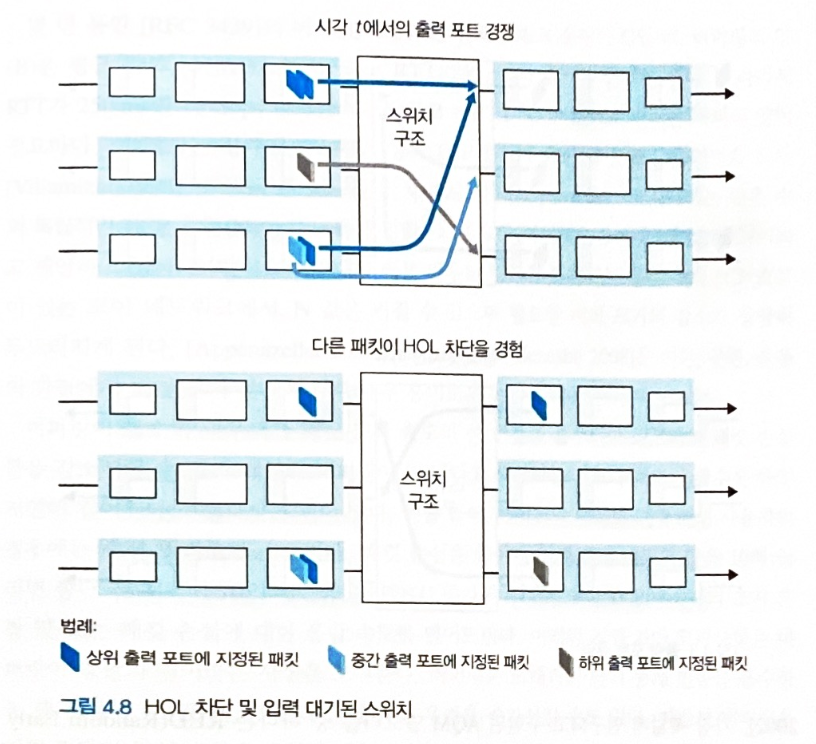
중간 출력 포트로 가야하는 패킷은, 중간 출력 포트가 경쟁이 없는 상태더라도 다른 출력 포트로 이동하는 패킷때문에 대기가 발생한다.
-
출력 큐잉
- 출력 포트가 출력 링크로 패킷을 내보내는 속도가 스위치 구조의 처리속도보다 느리면 발생
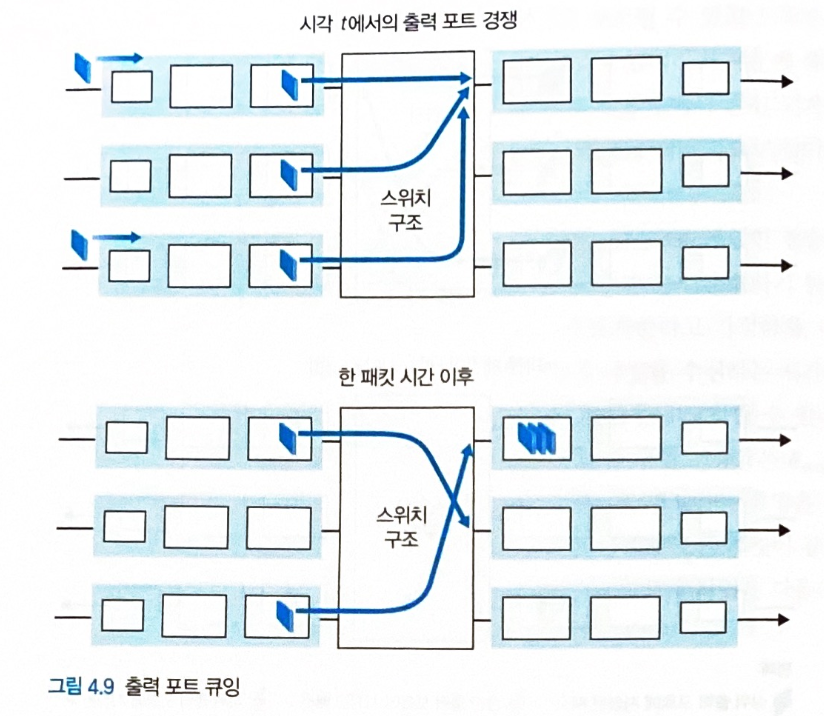
-
버퍼의 크기
-
버퍼 크기가 클수록 패킷 도착 속도의 변동을 흡수하고 패킷 손실률을 감소시킬 수 있다.
-
그러나 버퍼가 클수록 큐잉 지연은 길어진다.
-
만약 버퍼의 양을 10배 키우면, 종단 간 지연은 10배 증가한다.
-
이는 TCP 송신자의 초기 혼잡 제어의 속도를 크게 늦춘다.
-
-
따라서 적절한 버퍼 크기를 사용하는것이 좋다.
-
일반적으로 버퍼크기는 RTT와 링크 용량에 비례하고, TCP 연결수에 반비례한다.
-
패킷 스케줄링
-
큐에 있는 패킷이 출력 링크로 전송되는 순서를 결정하는 방법
-
다양한 스케줄링 방식이 있다.
-
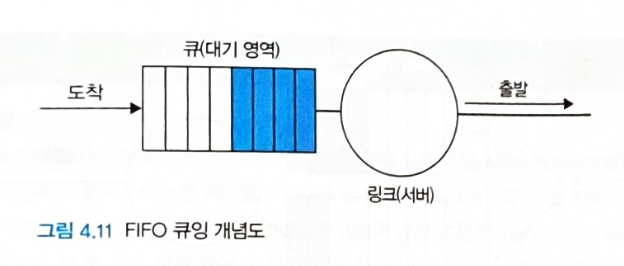
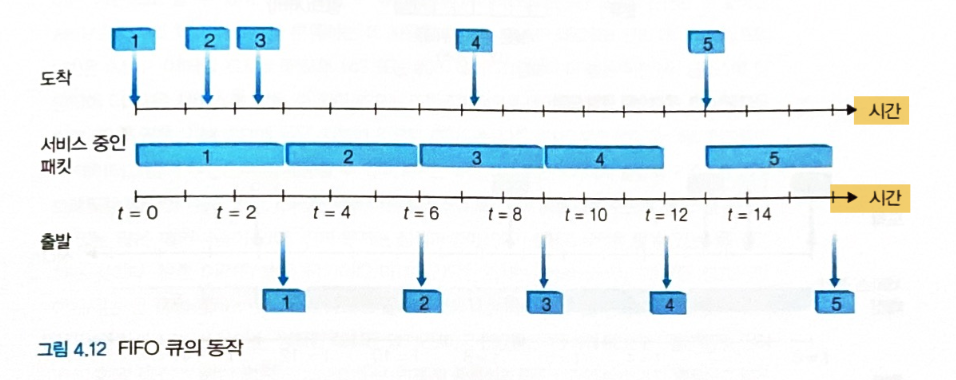
FIFO
- 출력 링크 큐에 도착한 순서대로 출력 링크로 패킷을 전송한다.
-
우선순위 큐잉
-
출력 포트에 도착한 패킷을 우선순위 기준으로 분류하여 각각의 우선순위 큐에 저장한다.
-
가장 높은 우선순위 큐에 대기하는 패킷부터 출력 링크로 전송한다.
-
우선순위가 동일한 패킷들은 일반적으로 FIFO 방식으로 처리된다.
-
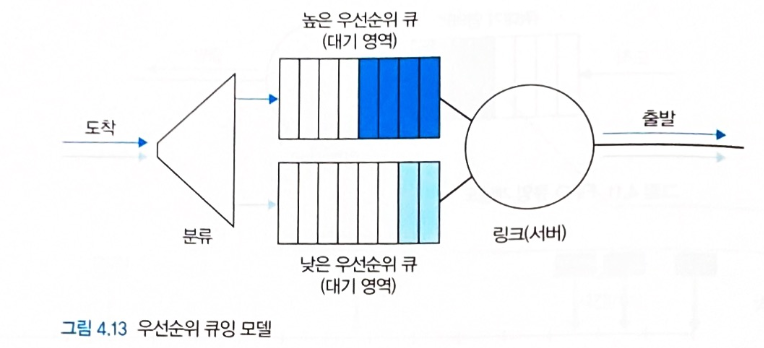
-
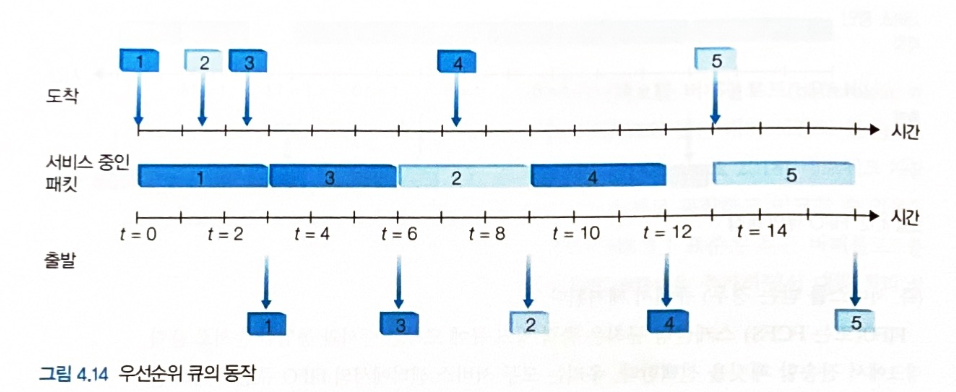
라운드 로빈
-
출력 포트에 도착한 패킷을 기준별로 분류하여 각각의 큐에 저장한다.
-
각 큐에 대기하는 패킷들을 큐마다 하나씩 번갈아가며 출력 링크로 전송한다.
-
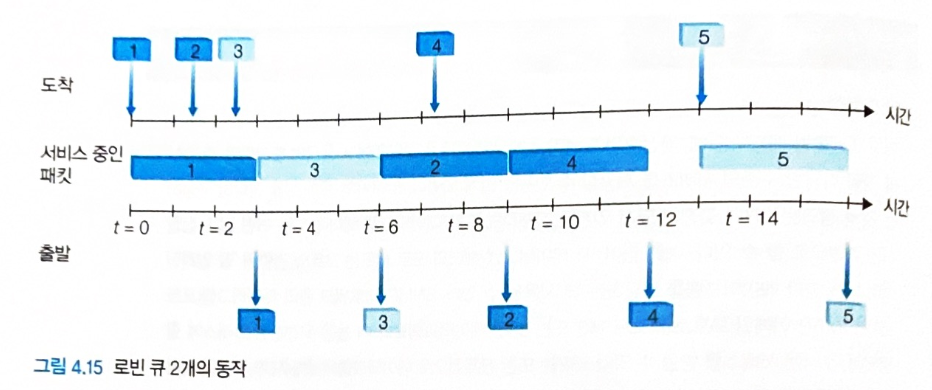
다른 큐에서 대기하는 패킷이 없다면 방금 패킷을 전송한 큐에서 다시 보낼 수 있다.
-
WFQ
-
Weighted Fair Queuing
-
RR 방식 처럼 분류된 클래스 큐가 순환 방식으로 전송된다.
-
RR과의 차이점은 각 클래스 큐마다 다른 양의 서비스 시간을 부여받는 점이다.
-
IPv4 데이터그램
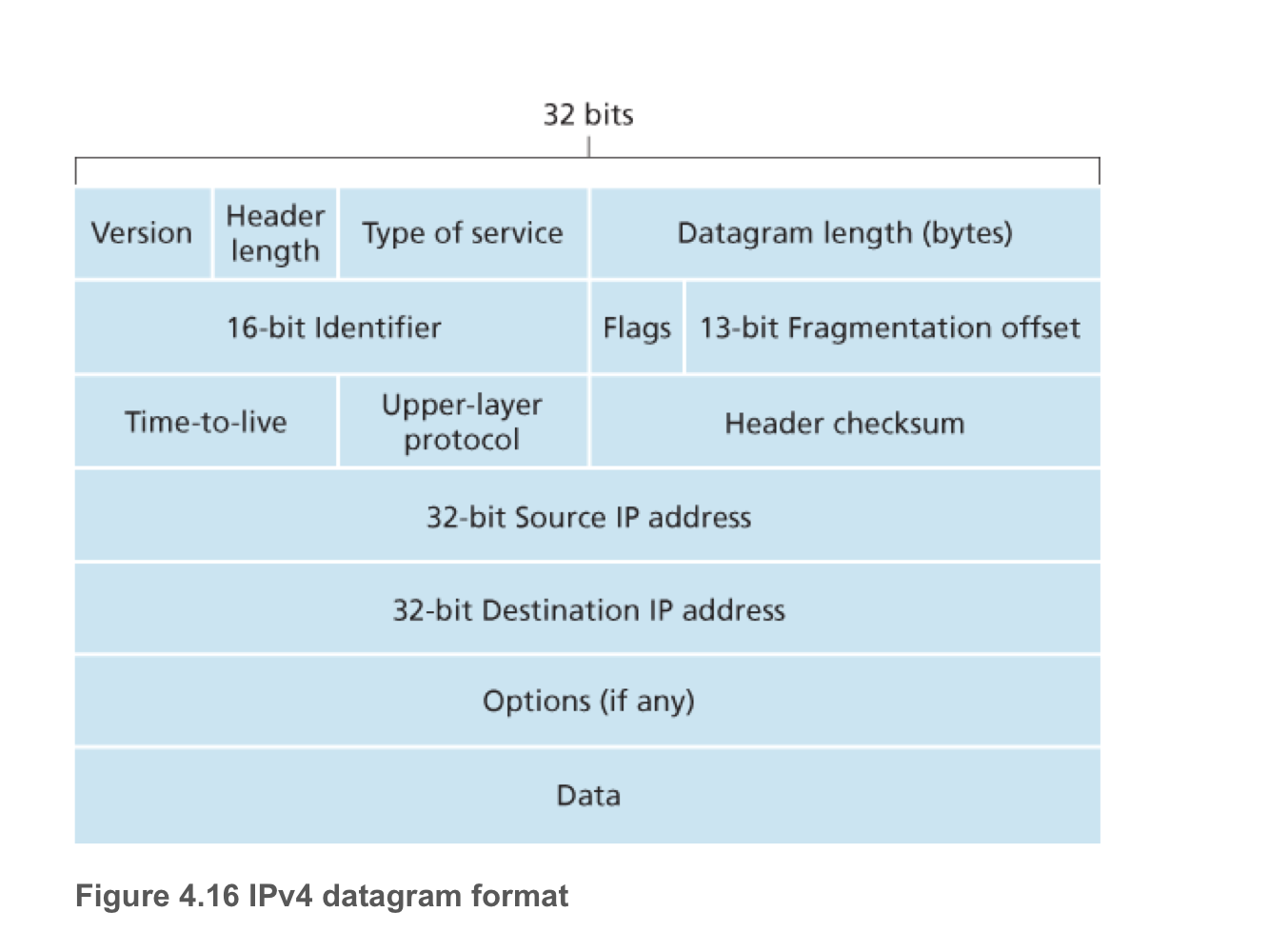
인터넷 프로토콜 버전 4의 데이터그램 구조
-
Version
- 데이터그램의 IP 프로토콜 버전을 명시한다.
-
Header length
-
데이터그램의 헤더 길이를 나타낸다.
-
일반적으로 헤더의 옵션 필드를 사용하지 않고 20바이트로 사용한다.
-
-
Type of service
-
IP 데이터그램의 유형을 구분한다.
-
ex) 실시간 데이터그램과 비실시간 데이터그램을 구분한다.
-
-
Datagram length
-
Byte 단위로 계산한 데이터그램 (헤더 + 데이터) 의 전체길이
-
데이터그램의 이론상 최대길이는 2^16 - 1 바이트이지만, 일반적으로는 1500 바이트 길이를 갖는다.
-
-
Identifier, Flags, Fragmentation offset
-
큰 IP 데이터그램은 여러개의 작은 IP 데이터그램으로 분할하여 전달한다.
-
분할된 작은 데이터는 트랜스포트 계층에 전달되기전에 합쳐진다.
-
이때 사용하는 헤더 필드이다.
-
-
Time-to-live (TTL)
-
라우터가 데이터그램을 처리할 때마다 1씩 감소한다.
-
TTL 필드가 0이 되면 라우터가 해당 데이터그램을 폐기한다.
- 이를 통해 데이터그램이 네트워크에서 무한히 순환하지 않도록 한다.
-
-
Upper-layer protocol
-
IP 데이터그램의 데이터부분이 전달될 목적지의 트랜스포트 계층의 프로토콜을 명시한다.
-
ex) TCP = 6, UDP = 17
-
-
Header checksum
- IP 데이터그램의 비트 오류 탐지
-
출발지와 목적지 IP 주소
- 데이터그램을 생성할 때, 생성자는 자신의 IP 주소를 출발지 IP 주소 필드에 삽입하고, 목적지 IP 주소를 목적지 IP 주소 필드에 삽입한다.
-
Options
- IP 헤더 확장에 사용되나, 일반적으로 사용되지 않는다.
IPv4 주소체계
-
호스트가 데이터그램을 보내려면 링크를 통해 보낸다.
- 이때, 호스트와 링크 사이의 경계를 인터페이스라 한다.
-
라우터가 데이터그램을 받으려면 한 링크를 통해 받는다.
-
이때 라우터와 링크 사이의 경계역시 인터페이스라 한다.
-
라우터는 한 링크로부터 받은 데이터를 다른 링크로 전달해야 하므로 최소 2개이상의 연결된 링크를 갖는다.
-
-
IP 주소는 인터페이스를 식별하는 주소이다.
- 즉, 라우터 하나는 연결된 링크 개수 (인터페이스 개수) 만큼 IP 주소를 갖는다.
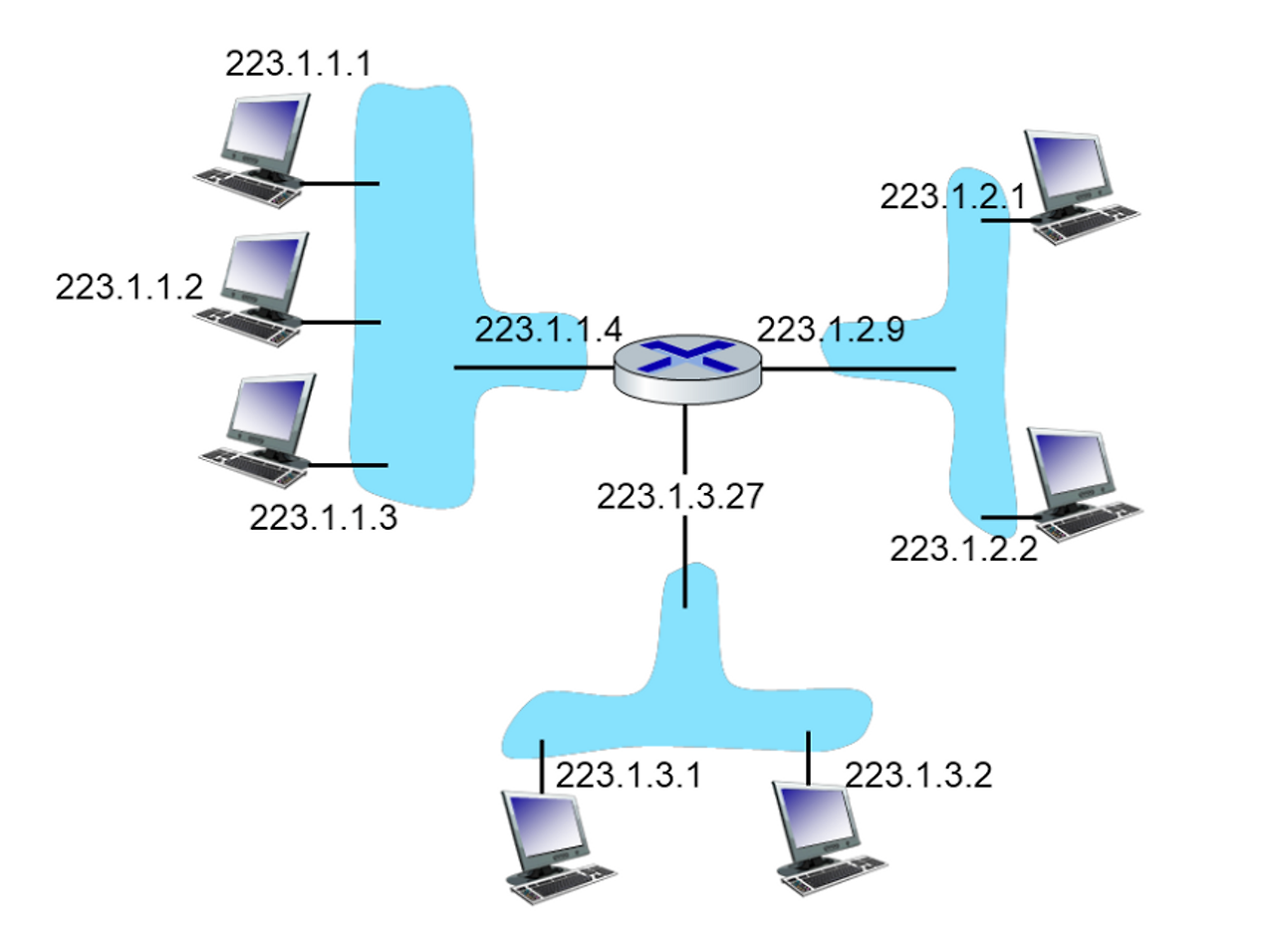
그림의 라우터는 3개의 IP 주소를 갖는다.
-
IP 주소 길이는 32 비트 (4 바이트) 이고, 일반적으로 각 바이트 (8 비트) 를 . 으로 끊은 뒤 십진수로 표기한다.
- ex) 193.32.216.9
-
중간 라우터 없이 호스트 인터페이스들이 라우터 인터페이스와 연결되거나, 라우터 인터페이스와 라우터 인터페이스가 연결된 고립된 네트워크를 서브넷이라 한다.
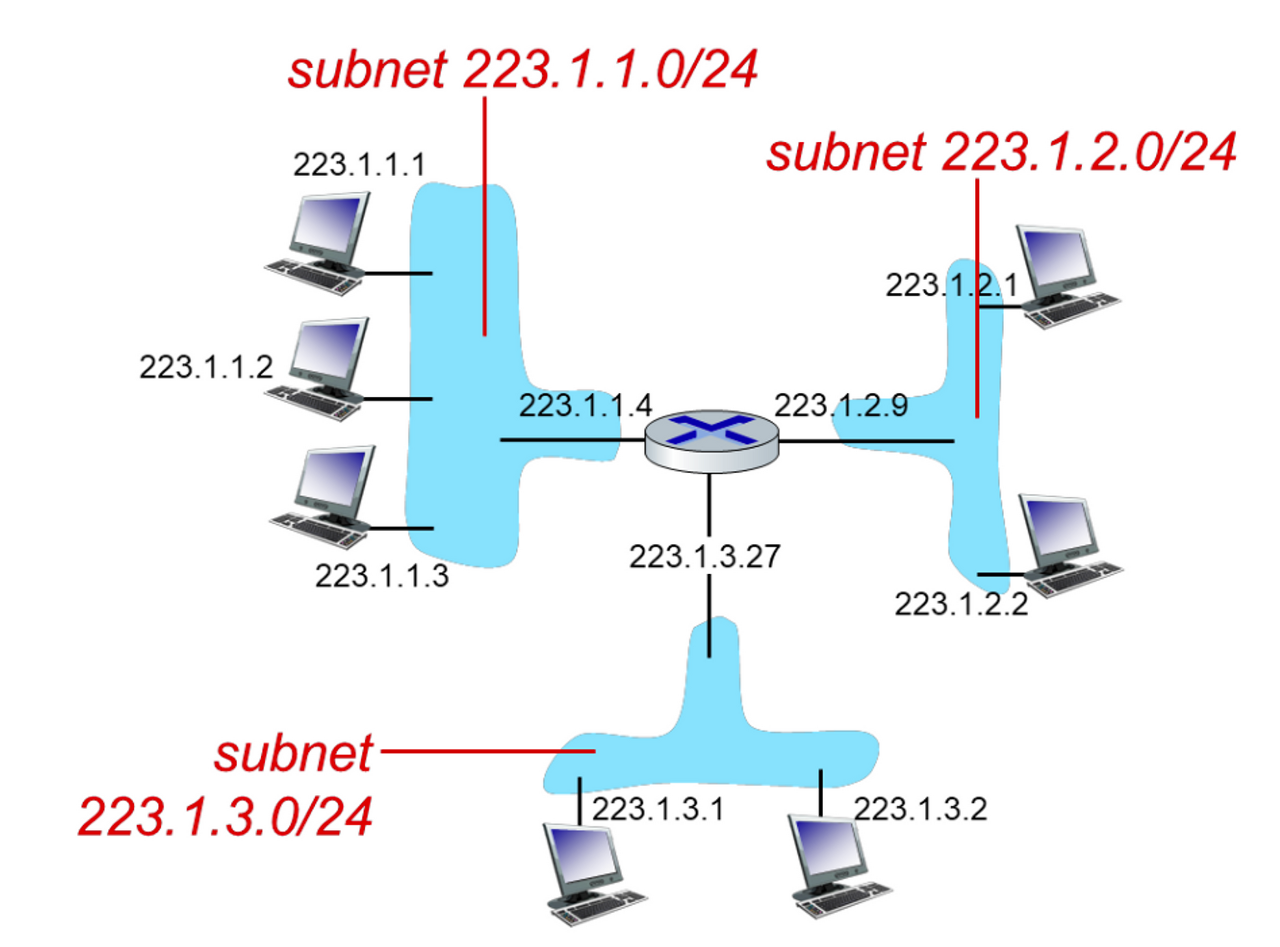
- 223.1.1.0/24 는 서브넷 주소이다.
- IP 주소의 왼쪽 24비트가 서브넷 주소임을 의미한다.
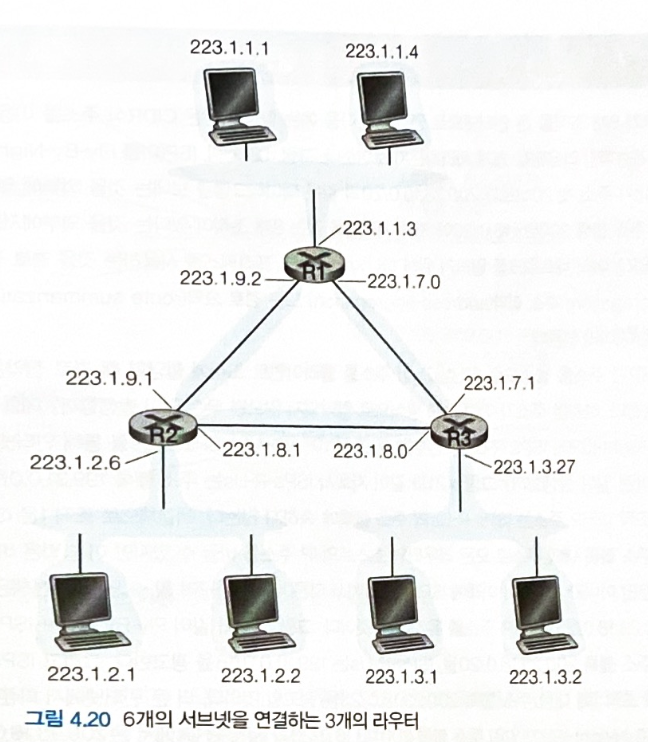
라우터간의 연결된 네트워크도 서브넷으로, 위 그림에는 총 6개의 서브넷이 있다.
-
인터넷 주소 할당 방식 중 CIDR (Classless Inter Domain Routing) 은 서브넷 주소 체계이다.
-
a.b.c.d/n 형식을 가진다.
- n 은 prefix 라 부르며 서브넷 주소 길이이다.
-
한 기관은 공통 prefix 를 갖는 연속된 IP 주소 블록을 할당받는다.
- 만약 한 기관이 24 bit prefix 의 주소 블록을 가진다면, 2^8 - 2 개의 연속된 IP 주소들을 갖게 된다.
-
외부의 라우터는 특정 기관 내부 IP로 데이터그램을 전달할 때, 특정 기관의 서브넷 주소만 고려하여 패킷을 전달한다. (prefix matching)
- 외부 라우터의 포워딩 테이블 크기가 절약된다.
-
서브넷 주소이하의 비트들 (32-n 비트들) 은 기관 내부의 호스트들을 식별하는데 사용된다.
- 기관 내부의 라우터에서 포워딩한다.
-
기관에 할당된 서브넷 내부에서 추가적인 서브넷 구조를 가질수도 있다.
- 서브넷 내부의 추가적인 서브넷 주소들은 prefix 길이가 더 길다.
-
-
CIDR 이전에는 classfull addressing 이 있었다.
-
서브넷 주소의 prefix 를 8, 16, 24 비트로 제한한 A, B, C 클래스 네트워크를 기관에 할당하는 방식
-
기관에게 다양한 규모의 네트워크를 할당할 수 없기에 효율성이 떨어진다.
-
-
서브넷 주소를 제외한 기관내의 IP 주소 필드가 전부 1인 목적지 주소를 갖는 데이터그램을 보내면
-
같은 서브넷에 있는 모든 호스트에게 전달된다.
-
이를 브로트캐스트 주소라 한다.
-
DHCP
-
Dynamic Host Configuration Protocol
-
호스트가 ISP로부터 개별 IP 주소를 동적으로 할당받는 방법
-
호스트에 IP 주소를 수동으로 할당할 수도 있지만 일반적으로는 동적으로 할당한다.
-
DHCP 를 통해 호스트는 IP 주소 할당뿐아니라 서브넷 마스크, 첫 번째 홉 라우터 주소 (default gate way IP), 로컬 DNS 서버 주소같은 네트워크 정보를 얻는다.
-
호스트가 빈번하게 접속하고 떠나는 네트워크 환경에서 유용하다.
-
DHCP 는 클라이언트-서버 프로토콜이다.
-
서브넷내에 DHCP 서버가 존재한다.
-
방금 네트워크에 새롭게 접속한 호스트가 클라이언트이다.
-
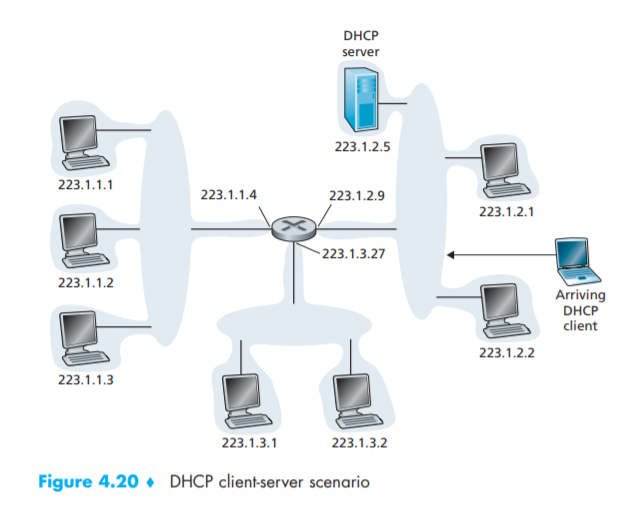
- DHCP 동작 과정
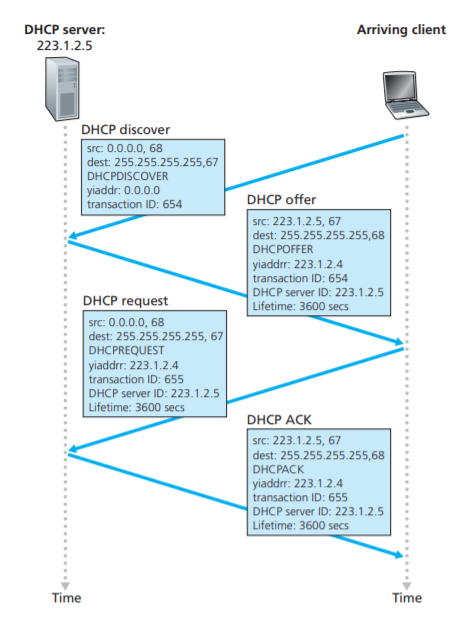
- DHCP discover message
- 새롭게 도착한 호스트는 포트 67번으로 UDP 패킷을 서브넷에 broadcast 로 보낸다.
- DHCP offser message
- DHCP discover message 를 받은 DHCP 서버는, 호스트에게 제공할 IP 주소, IP 주소 임대 기간, 서브넷 마스크, DHCP 서버 IP, DHCP discover message 의 트랜잭션 ID를 포함한 offer message 를 서브넷에 broadcast 로 보낸다.
- DHCP request message
- 호스트는 하나이상의 DHCP offer message 중 적절한 것을 선택한 뒤, 최적의 제안을 한 DHCP 서버주소를 포함한 응답 메시지를 서브넷에 broadcast 로 보낸다.
- 이를 통해 다른 DHCP 서버들은 자신의 제안이 거절되었음을 알 수 있다.
- DHCP ACK message
- DHCP 서버는 DHCP 요청 메시지를 확인한 후 응답 메시지를 서브넷에 broadcast 로 보낸다.
- 호스트(클라이언트)가 DHCP ACK message 를 받으면, 호스트는 서버가 제안한 IP 주소를 임대기간동안 사용할 수 있다.
- 구현 방식에 따라 DHCP 서버가 DHCP 클라이언트에게 보내는 모든 메시지는 Unicast 로 전달될 수 있다.
- 이때 srcIP 는 DHCP 서버 IP, dstIP 는 클라이언트에게 제안한 IP 인 yiaddr 이 된다.
- DHCP 서버는 클라이언트의 MAC 주소를 알기에 Unicast 로 보낼 수 있다.
NAT
-
Network Address Translation
-
IPv4 주소 고갈 문제를 대처하기 위해 도입한 주소 할당 방식
- private network 의 여러대의 호스트가 외부로 드러나는 하나의 public IP 를 갖도록 한다.
-
10.0.0.0/8 은 private network 를 위해 예약된 IP 주소 공간 중 하나이다.
-
따라서 세상에 수많은 private network 내의 수많은 10.x.x.x/n 호스트들이 있다.
- IP 주소가 유일하게 식별되지 않는다.
-
즉, 10.x.x.x/n 주소들은 private network 내부에서만 의미있다.
-
private network 내의 호스트들이 글로벌 인터넷과 통신하기위해 NAT를 사용한다.
-
-
NAT 가능 라우터는 여러대의 호스트들이 있는 private network 와 외부로의 네트워크를 연결한다.
-
NAT 가능 라우터는 외부 세계에선 라우터처럼 보이지 않고 하나의 IP 주소를 갖는 장비로 동작한다.
-
private network 내의 호스트의 요청은 NAT 가능 라우터가 갖는 유일한 public IP로 변환되어 외부 네트워크로 전송된다.
- 외부 네트워크에서 온 응답은 NAT 가능 라우터가 받아 private network 내의 호스트에게 전달한다.
-
이러한 NAT 를 통해 외부세계는 private network 의 상세한 사항을 알 수 없다.
-
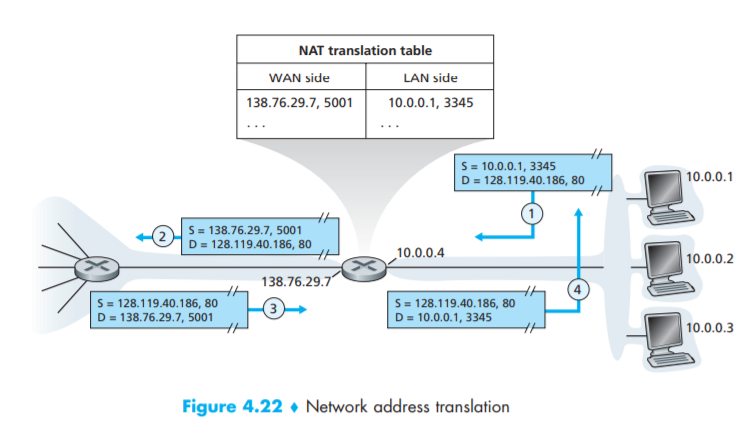
1: 10.0.0.1 호스트가 외부 세계의 서버에 요청을 날린다.
- NAT 가능 라우터는 해당 요청을 받으면 임의의 포트번호를 생성한 뒤, 자신의 public IP와 생성한 포트번호 쌍을 key로 하여 NAT 변환 테이블에 호스트의 요청을 저장한다.
- 호스트의 요청은 호스트 IP와 호스트 포트번호 쌍으로 저장한다.
2: 앞서 생성한 포트번호와 자신의 public IP를 사용하여 외부 세계의 서버에 요청을 날린다.
3: 서버는 NAT 가능 라우터에게 응답 메시지를 보낸다.
4: NAT 가능 라우터는 NAT 변환 테이블을 참조하여 응답 메시지의 목적지 포트번호와 매핑되는 호스트를 찾고, 해당 호스트에게 응답 메시지를 보낸다.
- NAT 가능 라우터와 private network 의 호스트들의 IP 역시 DHCP 를 통해 결정된다.
- NAT 가능 라우터가 가장 먼저 ISP 의 DHCP 서버로부터 public IP 주소를 받고
- NAT 가능 라우터가 private network 내에서 DHCP 서버를 실행하여 호스트들에게 IP 주소를 제공한다.
-
NAT는 폭넓게 사용하지만 반대 주장도 있다.
-
3계층 device 인 NAT 라우터가 호스트가 보낸 메시지의 port 번호를 확인하고 조작하므로 layer violation 이다.
-
또한, 포트 번호가 프로세스 식별이 아닌 호스트의 IP 주소를 찾는데 사용되기 때문이다.
-
IPv6 데이터그램
-
32비트의 IPv4 주소 공간의 고갈을 대비하여 만든 프로토콜이 IPv6 이다.
-
IPv4 와의 차이점
-
확장된 주소
- IPv6 는 IP 주소 크기를 32비트에서 128비트로 확장하였다.
-
40바이트 헤더
-
IPv4 헤더의 많은 필드를 생략하여 간소화된 헤더를 갖게되었다.
- 주소 길이가 길어 헤더 크기 자체는 IPv4 보다 크다 (20바이트) .
-
-
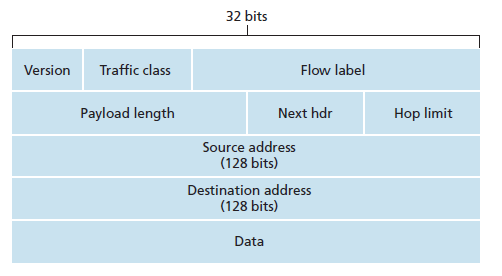
-
Version
-
IP 버전 번호를 나타낸다.
-
IPv6의 필드값은 6이다.
-
-
Traffic class
- 특정 애플리케이션의 데이터그램에 우선순위를 부여하기 위해 사용한다.
-
Flow label
- 데이터그램의 흐름을 인식하는데 사용한다.
-
Payload length
- 40바이트 패킷 헤더뒤에 나오는 데이터의 길이 (바이트 단위)
-
Next header
-
데이터그램의 데이터가 전달될 트랜스포트 계층 프로토콜을 지정한다.
-
ex) TCP, UDP
-
-
Hop limit
-
라우터가 데이터그램을 전달할 때마다 1씩 감소한다.
-
홉 제한수가 0보다 작아지면 라우터는 해당 데이터그램을 버린다.
-
-
출발지와 목적지 주소
- 128 비트의 주소이다.
-
단편화를 위한 필드들은 제거되었다.
-
패킷의 단편화와 재결합은 출발지와 목적지만 수행한다.
- 단편화와 재결합을 종단 시스템에서만 진행함으로써 네트워크의 IP 전달속도가 증가한다.
-
라우터는 IPv6 데이터그램이 너무 크면, 데이터그램을 폐기하고 송신자에게 오류메시지를 보낸다.
-
-
헤더 체크섬 필드는 제거되었다.
-
트랜스포트 계층 프로토콜이 체크섬을 수행하므로 생략되었다.
-
라우터의 체크섬 시간이 사라져 네트워크의 IP 전달속도가 증가한다.
-
-
옵션 필드는 제거되었다.
-
IPv6 의 next header 필드에 옵션을 추가할 수 있다.
-
옵션 필드가 사라짐으로써 고정 길이의 40바이트 헤더를 갖게 되었다.
-
IPv4 에서 IPv6 로의 전환
-
IPv6 라우터는 IPv4 데이터그램을 처리할 수 있지만, 이미 구축된 IPv4 라우터는 IPv6 데이터그램을 처리할 수 없다.
- 이를 해결하기 위한 방법은 다음과 같다.
-
flag day
-
모든 인터넷 장비를 끄고 IPv4 에서 IPv6로 업그레이드 할 날을 정하는 것
-
현실적으로 불가능하다.
-
-
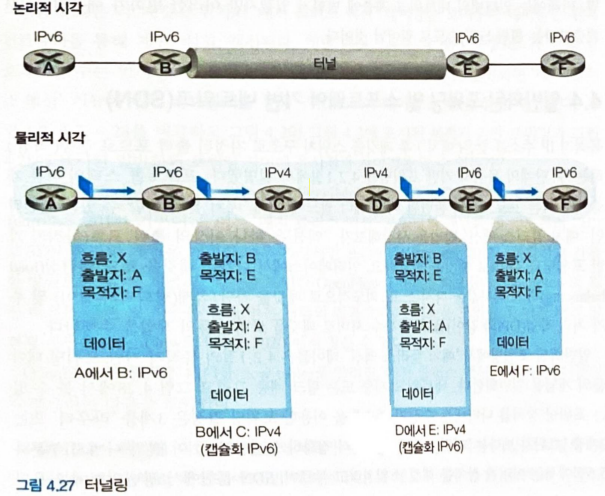
터널링
-
IPv6 라우터들 사이에 있는 IPv4 라우터들을 터널이라 한다.
-
IPv6 라우터가 IPv4 라우터에 데이터그램을 보낼때는, IPv6 데이터그램을 IPv4 데이터그램의 데이터 필드안에 통째로 넣은 IPv4 데이터그램을 만들어 보낸다.
-
IPv4 라우터가 보낸 데이터그램을 IPv6가 받게되면 데이터그램의 프로토콜 버전 필드를 확인한다.
- 프로토콜 버전 필드가 41이라면 IPv4 데이터그램의 데이터가 IPv6 데이터그램임을 의미한다.
-
IPv6 데이터그램이 데이터로 들어있는 IPv4 데이터그램이었다면 IPv6 데이터그램으로 만들어 다음 IPv6 라우터에 전달한다.
-
포워딩 테이블을 만드는 2가지 방법
-
라우터별 제어
-
모든 라우터 각각에서 라우팅 알고리즘이 동작하여 포워딩 테이블을 작성
- 각 라우터가 다른 라우터와 통신하여 포워딩 테이블 값을 계산한다.
-
포워딩과 라우팅을 개별 라우터에서 모두 수행
-
전통적이고, 융통성 없는 방식
-
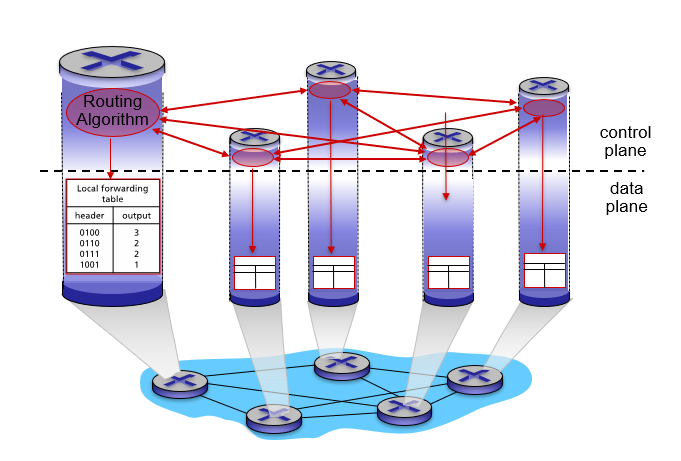
-
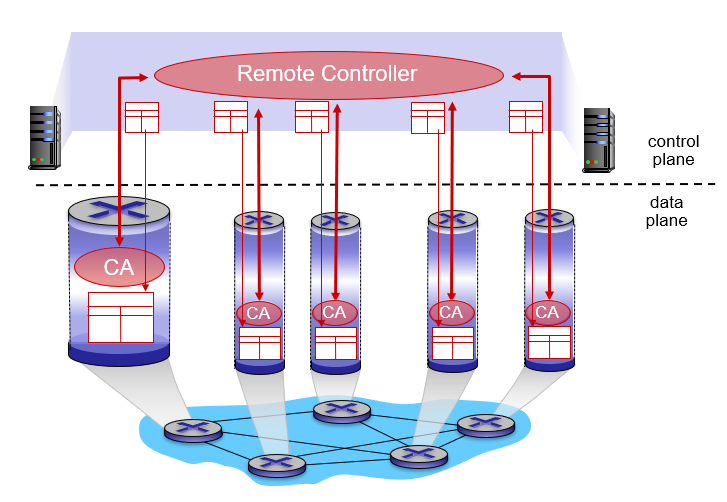
SDN
-
Software-Defined Networking
-
데이터 평면 (포워딩) 과 제어 평면 (라우팅) 을 명확히 분리
-
중앙 집중형 컨트롤러가 포워딩 테이블을 작성하고, 모든 개별 라우터가 사용할 수 있도록 배포한다.
-
라우터는 단순한 포워딩만 수행한다.
- 라우터끼리 통신하지 않고 포워딩 테이블을 계산하지도 않는다.
-
요즘 대세
-
라우팅 알고리즘
-
라우팅 알고리즘의 목표는 송신자부터 수신자까지의 최적의 네트워크 경로를 찾는 것이다.
- 최적의 경로란 일반적으로 최소 비용 경로이나 여러가지 현실적인 문제가 반영될 수 있다.
-
라우팅 문제는 그래프를 사용해 표현한다.
-
노드는 라우터
-
에지는 라우터간의 물리 링크를 의미한다.
-
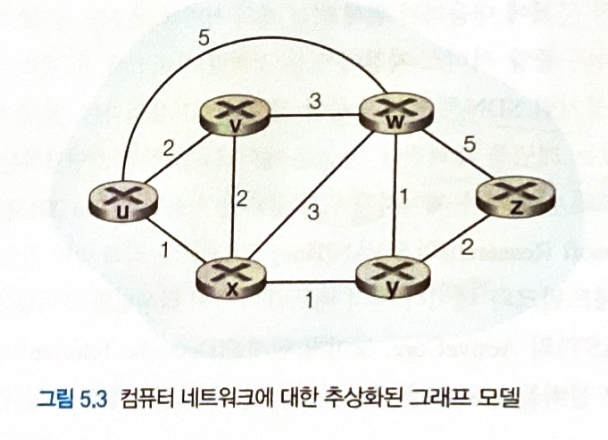
- 라우팅 알고리즘은 중앙 집중형인지, 분산형인지에 따라 분류할 수 있다.
-
중앙 집중형 라우팅 알고리즘
-
centralized routing algorithm
-
네트워크 전체에 대한 완전한 정보를 가지고 출발지와 목적지 사이 최소 비용 경로를 계산한다.
-
-
분산 라우팅 알고리즘
-
decentralized routing algorithm
-
각 라우터들에 의해 반복적이고 분산된 방식으로 최소 비용 경로를 계산한다.
-
각 노드는 자신에게 직접 연결된 링크에 대한 비용 정보만을 가지고 시작한다.
-
반복된 계산과 이웃 노드와의 정보 교환을 통해 점진적으로 목적지까지의 최소 비용 경로를 계산한다.
-
-
링크 상태 라우팅 알고리즘
-
Link-State (LS) 알고리즘
-
중앙 집중형 라우팅 알고리즘
-
각 노드가 자신과 직접 연결된 링크의 비용과 이웃 노드 정보를 담은 링크 상태 패킷을 네트워크상의 다른 모든 노드로 broadcast 한다.
- 이를 통해 모든 노드는 네트워크에 대해 동일하고 완벽하게 알게 된다.
-
Dijkstra 알고리즘을 사용해 네트워크내의 최소 비용 경로를 계산할 수 있다.
- 하나의 노드에서 다른 모든 노드로의 최소 비용 경로를 계산한다. (1-to-all)
-
발생할 수 있는 문제점
-
링크 비용이란 링크를 통과하는 트래픽 부하와 비례한다.
-
따라서 이웃한 노드가 서로 동일한 트래픽을 보내지 않는 한 링크 비용 그래프는 단방향 그래프이다.
-
또한 트래픽 부하의 변동에 따라 링크 비용이 변한다.
-
이러한 특징들로 인해 LS 알고리즘에서는 oscillation 문제가 발생할 수 있다.
-
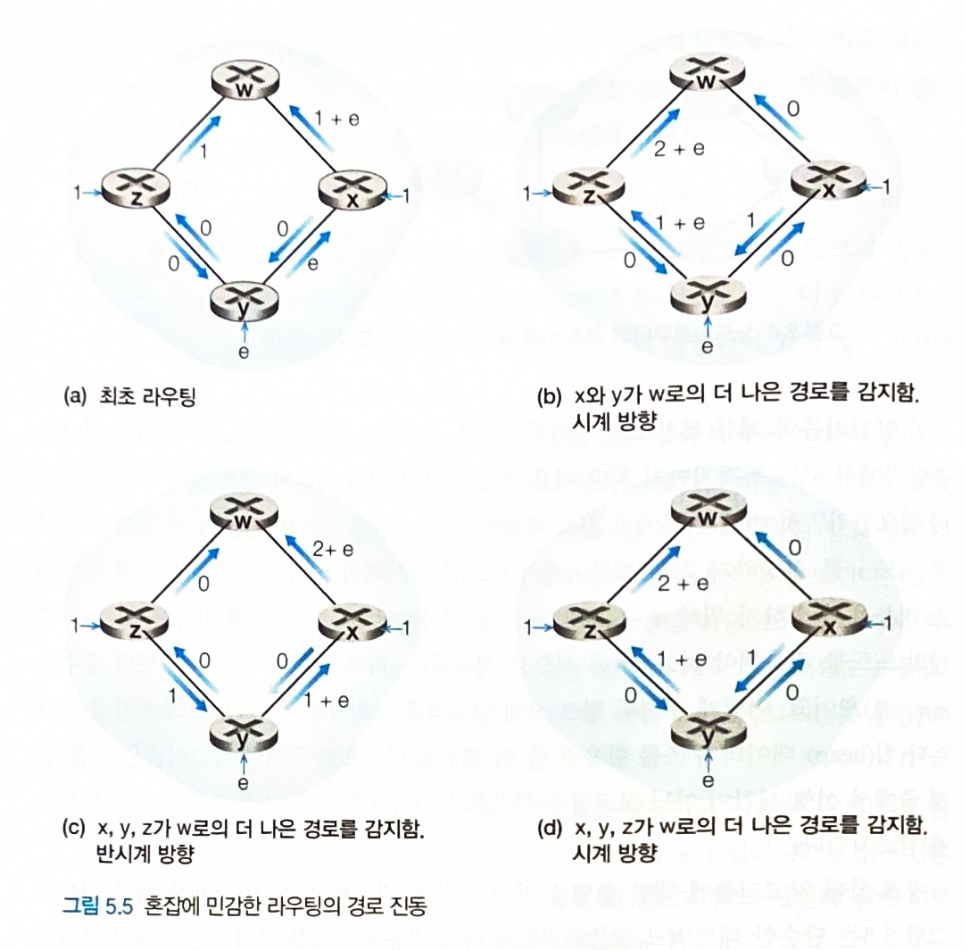
- x, z 는 w를 목적지로 하는 1 트래픽을 전달하고, y 는 w를 목적지로 하는 e 트래픽을 전달하는 상황
- 매 시점에서 최적화된 경로로 트래픽을 보내려다보니 트래픽이 골고루 분산되지 않고 한쪽으로만 몰리는 현상이 발생한다.
- w로 들어가는 링크의 트래픽이 1, 1+e 로 나누어지는 것이 좋은데,
- 2+e, 0 으로 자꾸 한쪽으로만 몰린다.
- 이를 해결하기 위해서 모든 라우터가 동시에 LS 알고리즘을 실행하지 못하도록 하면된다.
- 그러나 라우터들은 점진적으로 서로 동기화하여 동시에 LS 알고리즘을 실행하려는 성질이 있으므로
- 각 라우터의 LS 알고리즘 실행시작 시간을 다르게 하기 보다는
- 각 라우터가 네트워크 정보를 broadcast 하는 시간을 임의로 결정하게 함으로써 회피하는 것이 좋다.
거리 벡터 라우팅 알고리즘
-
Distance-Vector (DV) 알고리즘
-
분산 라우팅 알고리즘
-
각 노드는 이웃 노드로부터 정보를 받고 계산을 수행한 뒤 계산된 결과를 이웃 노드에게 배포한다.
- 분산적
-
이웃 노드와 더이상 정보를 교환하지 않을때가지 프로세스가 지속된다.
- 반복적
-
모든 노드가 동시에 동작할 필요 없다.
- 비동기적
-
각 라우터는 자신
x로부터 인접한 이웃 노드v까지의 경로 비용을C(x, v)라 하고, 이웃 노드v에서 도착지y까지의 경로 비용 추정치를D_v(y)라 한다.- 각 라우터에서 도착지까지의 최소 비용은
min(C(x, v) + D_v(y))이고, 이를 거리 벡터라 한다.
- 각 라우터에서 도착지까지의 최소 비용은
-
각 라우터는 이웃 노드로부터 갱신된 거리 벡터에 대한 정보를 받을때마다 자신의 거리 벡터를 갱신한다.
-
자신의 거리 벡터가 갱신 되었다면, 자신의 거리 벡터를 이웃 노드에 보낸다.
-
자신의 거리 벡터가 갱신되지 않았다면, 아무런 메시지도 보내지 않는다.
-
이러한 거리 벡터 갱신과 정보 교환의 반복을 통해 각 라우터의 거리 벡터 값은 최소 비용으로 수렴한다.
-
더이상 이웃 노드로부터 정보를 받지 않아 거리 벡터 갱신이 끝날 때, 그때의 거리 벡터가 결정된 최소 비용이다.
-
-
최소 비용의 거리 벡터를 알아냄으로써 각 라우터는 목적지까지 가기 위한 이웃 노드를 고를 수 있다.
- 목적지까지의 모든 경로는 알아낼 수 없지만, 최소한 이웃 노드 어디로 가야할지는 구할 수 있다.
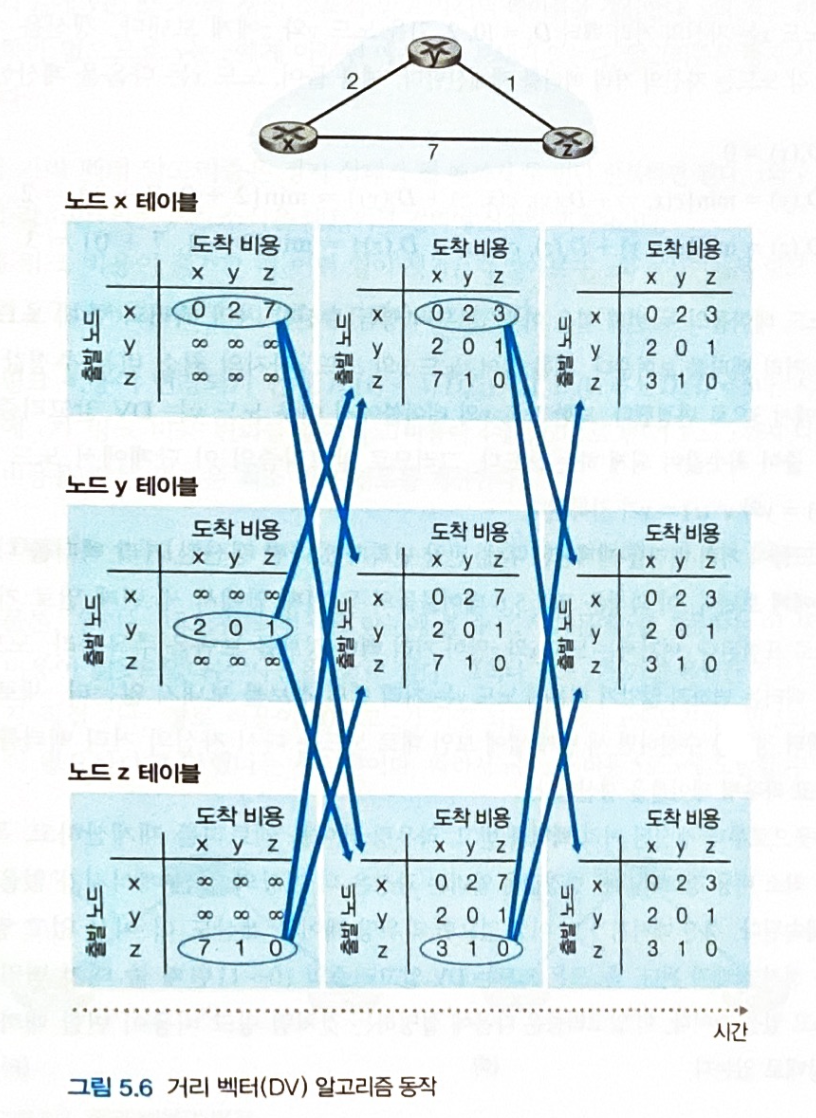
- 노드 x에서 노드 z로 가는 최소 비용 경로를 구하고 싶다고 가정한다.
- 노드 x는 이웃 노드 정보를 가지고 최초로 거리 벡터를 갱신한다.
x -> z의 거리 벡터는min(C(x, y) + D_y(z), C(x, z) + D_z(z))= min(2 + ∞, 7 + 0)= 7이다.- 최초에는 y 노드에서 z로 갈 수 있는지 모르기에 ∞ 의 거리 벡터 값을 갖는다.
- 이후 노드 y로부터 거리 벡터 정보를 받는다.
- 이를 바탕으로 다시 노드 x의 거리 벡터를 갱신한다.
x -> z의 거리 벡터는min(C(x, y) + D_y(z), C(x, z) + D_z(z))= min(2 + 1, 7 + 0)= 3이다.- y의 거리 벡터 정보
D_y(z)가 1임을 알았기에 다음과 같이 갱신된다.
- 모든 라우터들의 정보교환이 끝나고 결과적으로
C(x, y) + D_y(z)가 거리 벡터임을 알았으니, 노드 x 는 노드 y로 패킷을 보내면 된다.
DV 알고리즘의 링크 비용 변경
- 링크 비용 감소 시
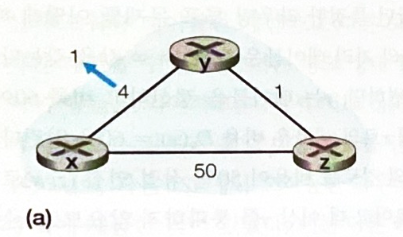
- y 노드가 링크 비용 변화를 감지하고 자신의 거리 벡터를 갱신해 이웃에게 알린다.
- z 노드와 x 노드는 갱신 정보를 바탕으로 자신의 거리벡터들을 갱신 후, 이웃에게 알린다.
z -> x비용과x -> z비용은 5에서 2로 감소한다.
- 정보를 받은 y 노드는 거리 벡터의 변화가 없으므로 아무런 메시지도 보내지 않는다.
- 링크 비용이 감소 되었다는 정보는 신속히 네트워크 전역으로 퍼져나가고 알고리즘은 금방 정지 상태가 된다.
- 링크 비용 증가 시
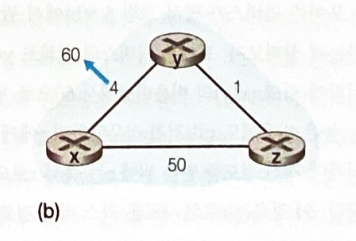
- y 노드는 링크 비용 변화를 감지하고 x 노드까지의 새로운 최소 비용 경로를 계산 후, 이웃에게 알린다.
- 링크 비용 변경 전에
D_z(x) = 5로 y 노드의 테이블에 저장되어있다.D_y(x) = min(C(y, x) + D_x(x), C(y, z) + D_z(x))= min(60 + 0, 1 + 5)= 6
- z 노드는 갱신 정보를 바탕으로 자신의 거리 벡터를 수정 후 이웃에게 알린다.
D_z(x) = min(C(z, x) + D_x(x), C(z, y) + D_y(x))= min(50 + 0, 1 + 6)= 7
- 이러한 반복이 계속되어 y 노드는
D_y(x) = 8이 되고,D_z(x) = 9가 되고 ...
- 이런식으로 오랜시간 반복하다가
D_z(x) = 50,D_y(x) = 51이 될 때 반복 갱신이 멈춘다.
- 링크 비용의 증가는 굉장히 천천히 비효율적으로 알려진다.
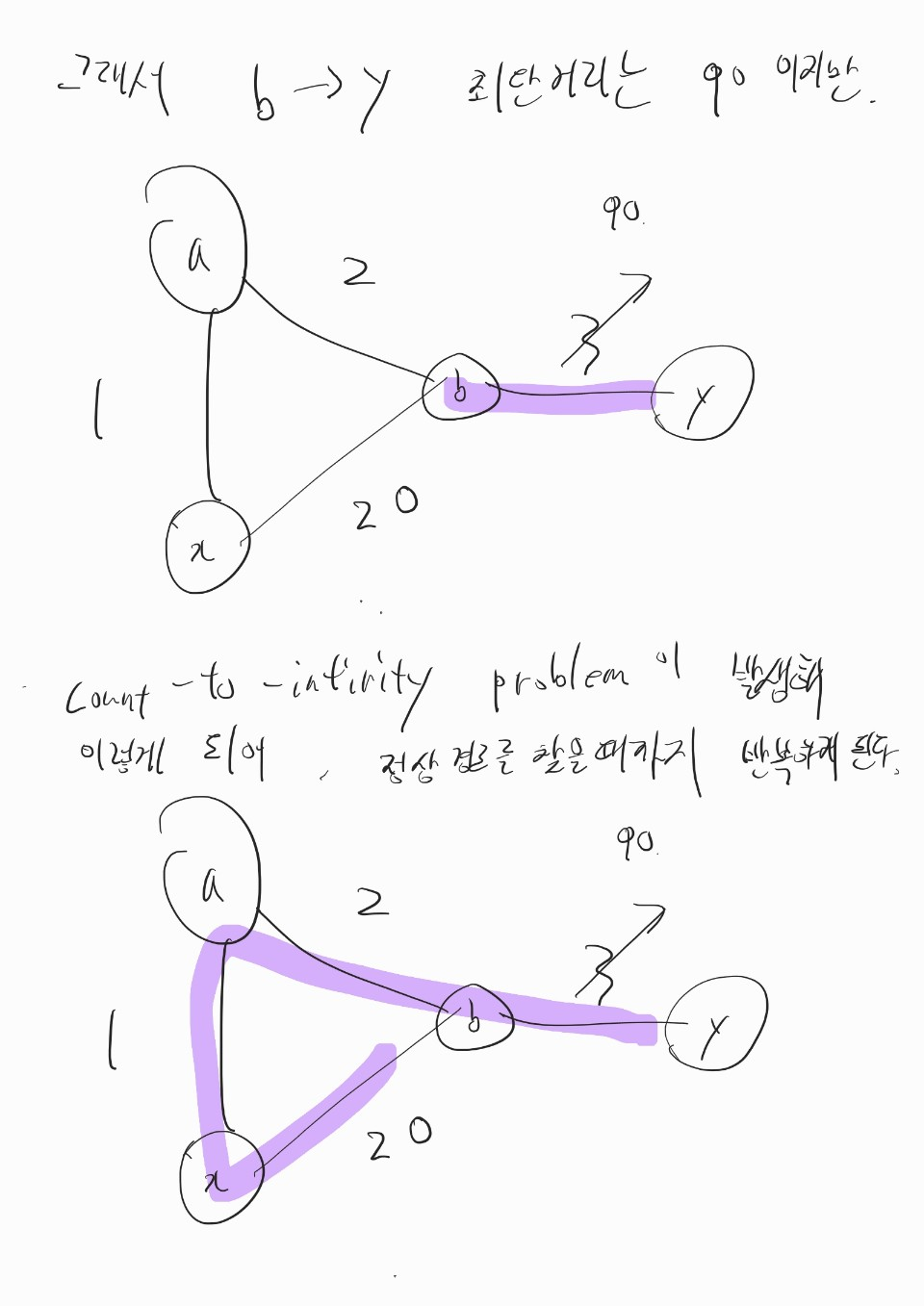
- 이를 count-to-infinity problem 이라 한다.
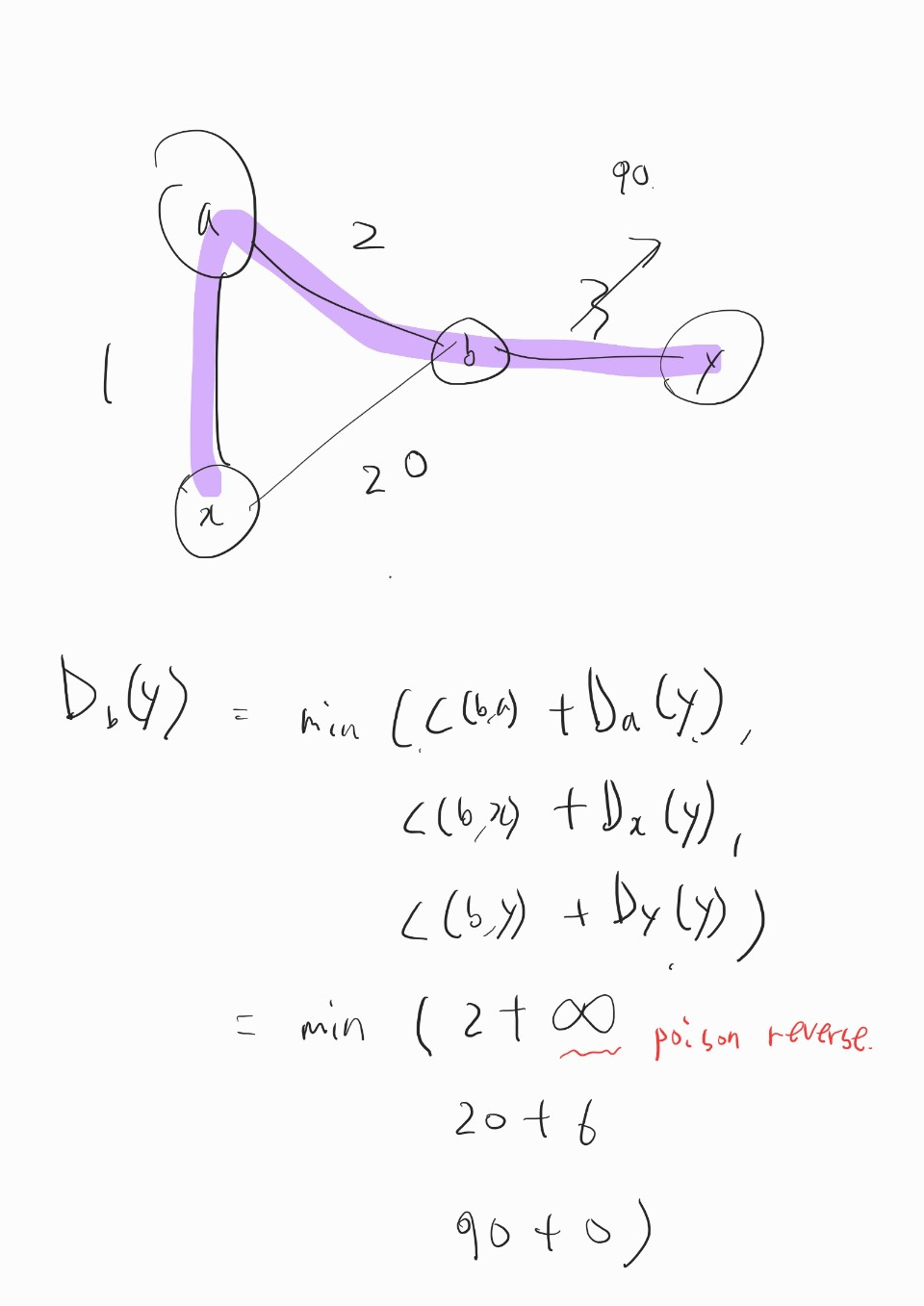
- 링크 비용 증가 시 발생하는 count-to-infinity problem 은 poisoned reverse 방법을 사용해 방지할 수 있다.
- 만약 z가 y를 통해 x로 가는 것이 최단거리라면, z는 y노드에게만
D_z(x) = ∞이라고 거짓말한다.
- y노드는 z에서 x로 가는 경로가 없다고 착각한다.
- 따라서 y노드는 z를 통해 x로 가는 경로를 선택하지 않는다.
- 링크 비용이 4 -> 60 으로 변경되면 y노드는 거리 벡터 갱신 후 이웃에게 알린다.
D_y(x) = min(C(y, x) + D_x(x), C(y, z) + D_z(x))= min(60 + 0, 1 + ∞)= 60
- y노드로부터 정보를 받은 z노드는 x로의 거리 벡터를 비용이 50인
C(z, x) + D_x(x)직접 연결로 바꾼다.
- 이제 z노드는 y노드를 통해 x로 가지 않기 때문에 갱신된 거리 벡터
D_z(x) = 50을 y노드에게 알린다.
- z노드로부터 정보를 받은 y노드는 다시
D_y(x)를 갱신한다.
D_y(x) = min(C(y, x) + D_x(x), C(y, z) + D_z(x))= min(60 + 0, 1 + 50)= 51
- 이처럼 포이즌 리버스를 사용해 이웃을 2개만 가지는 노드로 이루어진 루프의 무한 계수 문제를 해결할 수 있다.
- 이웃을 3개 이상 가지는 노드를 포함한 루프는 포이즌 리버스로 문제를 해결할 수 없다.
출처


저도 네트워킹 하향식접근 보면서 정리하고 있었는데 이미 하신 분이 계셨군요.
너무 감사합니다..!