
파이썬 알고리즘 인터뷰를 읽고
- 책을 읽으며 중요하다고 생각되는 내용들을 정리하였다.
정리한 Chapter
-
6장 문자열 조작
-
7장 배열
-
8장 연결 리스트
-
9장 스택, 큐
-
10장 데크, 우선순위 큐
-
11장 해시 테이블
-
12장 그래프
-
13장 최단 경로 문제
-
14장 트리
-
15장 힙
-
16장 트라이
-
17장 정렬
-
18장 이진 검색
-
19장 비트 조작
-
20장 슬라이딩 윈도우
-
21장 그리디 알고리즘
-
23장 다이나믹 프로그래밍
문자열 조작
lambda 를 사용한 정렬
key=lambda를 사용하여 다중 정렬 조건을 설정할 수 있다.
s = [(2, 'A'), (1, 'B'), (4, 'C'), (1, 'A')]
sorted_s = sorted(s, key=lambda x: (x[1], x[0]))
x는 정렬하려는 리스트의 각각의 요소를 의미x[1]을 첫 번재 정렬기준으로 설정
- 각 튜플에서 두 번째 요소 (알파벳)
x[1]이 같은 경우x[0]을 두 번째 정렬기준으로 설정
- 각 튜플에서 첫 번째 요소 (정수)
정렬결과
[(1, 'A'), (2, 'A'), (1, 'B'), (4, 'C')]기본값이 자동으로 부여되는 defaultdict(자료형) 딕셔너리
-
처음
key값을 넣을 때key값의value를 기본값으로 자동 부여한다. -
collections모듈 임포트 필요
counts = collections.defaultdict(int)
# counts = {}
counts['hi'] += 1
# counts = {'hi' : 1}
- 처음 넣는
key값의value는int의 기본값인 0으로 초기화된다.
- 그러므로
+=1이 가능하다.
49번 문제, 그룹 애너그램
- https://leetcode.com/problems/group-anagrams/
실패이유: 시간초과
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
anagrams = collections.defaultdict(list)
for word in strs:
anagrams[''.join(sorted(word))].append(word)
return list(anagrams.values())
''.join(sorted(word))를 통해 같은 애너그램 단어들을 하나의 key 값으로 묶을 수 있다.
aen,ena,nae는 모두aen이 된다.- 동일한
key값 (aen) 은value로 실제 단어aen,ena,nae를 담는다.
5번 문제, 가장 긴 팰린드롬 부분 문자열
class Solution:
def longestPalindrome(self, s: str) -> str:
def expand(left, right):
while left >= 0 and right < len(s) and s[left] == s[right]:
left -= 1
right += 1
return s[left+1: right]
if len(s) < 2 or s == s[::-1]: # 해당 조건의 경우 무조건 팰린드롬이므로 for 문 돌지않고 바로 종료
return s
ans = ""
for i in range(len(s)):
ans = max(ans, expand(i, i+1), expand(i, i+2), key=len) # 문자열의 길이 기준으로 max 값을 정한다.
return ans
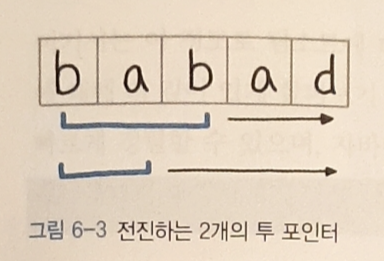
expand메서드는 가운데 위치에서 투포인터로 좌우로 벌려가며 팰린드롬인지 체크한다.
expand(i, i+1)은 짝수 길이 팰린드롬 문자열 체크expand(i, i+2)은 홀수 길이 팰린드롬 문자열 체크- 팰린드롬 검사를 시작하는 위치를
for i in range(len(s))를 통해 처음부터 끝까지 옮긴다.

배열
-
메모리 공간 기반의 연속 방식
-
변수의 집합으로 구성된 구조
-
인덱스로 식별된다.
- 어느 위치에나
O(1)에 조회 가능하다.
- 어느 위치에나
1번 문제, 두 수의 합
-
O(NlogN) 풀이 (내 풀이)
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
nums = [(num, idx) for idx, num in enumerate(nums)]
sorted_nums = sorted(nums, key=lambda x: x[0])
front = 0
rear = len(sorted_nums) - 1
while front < rear:
if target > sorted_nums[front][0] + sorted_nums[rear][0]:
front += 1
elif target < sorted_nums[front][0] + sorted_nums[rear][0]:
rear -= 1
else:
return [sorted_nums[front][1], sorted_nums[rear][1]]원래 인덱스를 튜플로 갖도록 하고, 정렬하여 투 포인터를 사용하였다.
O(N) 풀이 (책 풀이)
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
nums_dic = {num: idx for idx, num in enumerate(nums)}
for idx, num in enumerate(nums):
if target - num in nums_dic and nums_dic[target - num] != idx:
return [idx, nums_dic[target - num]]
key가 숫자이고,value가 인덱스인 딕셔너리를 만든다.- 똑같은 숫자가 여러개 있어도 상관없다.
- 가장 뒤에 위치한 숫자와 인덱스가 저장된다.
target - num이 딕셔너리에 위치하고, 해당 숫자의 인덱스가 현재 인덱스와 다른경우
- 두 인덱스가 정답이 된다.
42번 문제, 빗물 트래핑
-
O(N) 풀이 (내 풀이)
class Solution:
def trap(self, height: List[int]) -> int:
if len(height) <= 1:
return 0
water = 0
left = 0
while height[left] <= 0:
left += 1
while left < len(height):
right = left + 1
while right < len(height) and height[left] > height[right]:
right += 1
if right >= len(height):
break
water += height[left] * (right-left - 1) - sum(height[left+1:right])
left = right
right = len(height) - 1
while height[right] <= 0:
right -= 1
while right >= 0:
left = right - 1
while left >= 0 and height[left] <= height[right]:
left -= 1
if left < 0:
break
water += height[right] * (right-left - 1) - sum(height[left+1:right])
right = left
return water
- 왼쪽부터 오른쪽으로 가면서 오른쪽이 높거나 같은 경우 빗물 계산
- 오른쪽부터 왼쪽으록 가면서 왼쪽이 높은 경우 빗물 계산
- 이렇게 두번 계산한 빗물들을 더해 총합을 구한다.
O(N) 풀이 (책 풀이)
class Solution:
def trap(self, height: List[int]) -> int:
if not height:
return 0
water = 0
left, right = 0, len(height) - 1
left_max, right_max = height[left], height[right]
while left < right:
left_max, right_max = max(height[left], left_max), max(height[right], right_max)
if left_max <= right_max: # 투 포인터가 가장 높은 곳을 향해 간다
water += left_max - height[left] # left_max, right_max 는 증가밖에 안하므로, 다음과 같이 간단하게 물을 계산할 수 있다.
left += 1
else:
water += right_max - height[right]
right -= 1
return water
- 가장 높은 곳을 향해가는 투 포인터를 사용한다.
- 왼쪽, 오른쪽의 최대값은 높은 곳을 향해가기 때문에 증가밖에 안한다.
- 따라서
left_max - height[left]와 같이 간단하게 물 양을 계산할 수 있다.
15번 문제, 세 수의 합
-
실패이유: 시간초과O(N^3)풀이로 풀면 안된다.- 투 포인터를 활용해
O(N^2)풀이로 풀 수 있다.
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
ans = []
nums.sort()
for i in range(len(nums) - 2):
if i > 0 and nums[i] == nums[i - 1]: # 만약 이전 값과 숫자가 같다면 로직 스킵
continue
left, right = i + 1, len(nums) - 1
while left < right:
total = nums[i] + nums[left] + nums[right]
if total < 0:
left += 1
elif total > 0:
right -= 1
else:
ans.append([nums[i], nums[left], nums[right]])
while left < right and nums[left] == nums[left+1]: # 만약 현재 왼쪽 포인터가 가리키는 숫자가, 이전 숫자와 같다면 인덱스를 늘려 로직 스킵
left += 1
while left < right and nums[right] == nums[right-1]: # 만약 현재 오른쪽 포인터가 가리키는 숫자가, 이전 숫자와 같다면 인덱스를 줄여 로직 스킵
right -= 1
left += 1
right -= 1
return ans
- 숫자를 정렬
- 첫 숫자를 앞에서부터 차례로 정한다.
nums[i]- 두 번째, 세 번째 숫자는 투 포인터가 가리키는 숫자이다.
nums[left],nums[right]- 세 수의 합과 0을 대소 비교해 포인터를 움직인다.
- 세 수의 합이 0이 되는 경우엔, 투 포인터를 모두 움직인다.
- 숫자의 중복을 직접 제거한다.
- 첫 숫자가 이전 숫자와 중복되는 경우엔
continue,- 두 번째, 세 번째 숫자가 이전 숫자와 중복되는 경우엔
while문을 사용하여 중복을 제거
238번 문제, 자신을 제외한 배열의 곱
-
실패이유: 구현실패제약사항: 나누기를 사용하지 않고,O(N)에 풀 것
class Solution:
def productExceptSelf(self, nums: List[int]) -> List[int]:
ans = []
p = 1
for i in range(0, len(nums)): # 왼쪽부터 오른쪽으로 누적곱
ans.append(p) # 가장 오른쪽 값을 누적곱한 값은 ans 에 들어가지 않는다.
p *= nums[i]
p = 1
for i in range(len(nums)-1, -1, -1): # 오른쪽부터 왼쪽으로 누적곱
ans[i] *= p # 가장 왼쪽 값을 누적곱한 값은 ans 에 들어가지 않는다.
p *= nums[i]
return ans
현재 인덱스를 제외한 나머지의 곱은
현재 인덱스 이전까지의 누적 곱 x 현재 인덱스 이후부터의 누적 곱- 시작지점은 1
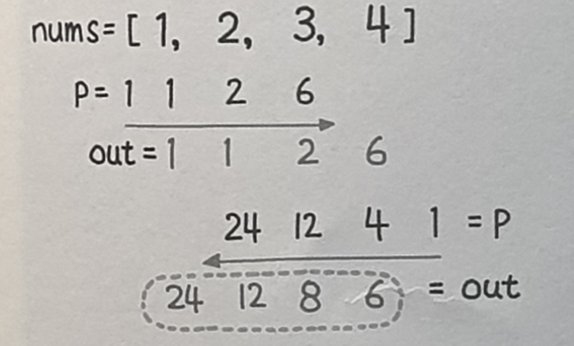
연결 리스트 (링크드 리스트)
-
데이터 요소의 선형 집합
-
데이터의 순서가 메모리에 물리적인 순서대로 저장되지 않는다.
-
특정 인덱스에 접근하기 위해서는 전체를 순서대로 읽어야 한다.
O(n)시간 복잡도
-
데이터를 추가하거나 삭제, 추출하는 경우
O(1)시간 복잡도
234번 문제, 팰린드롬 연결 리스트
-
링크드 리스트를 활용한 풀이 (책 풀이)러너(Runner)기법 활용
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
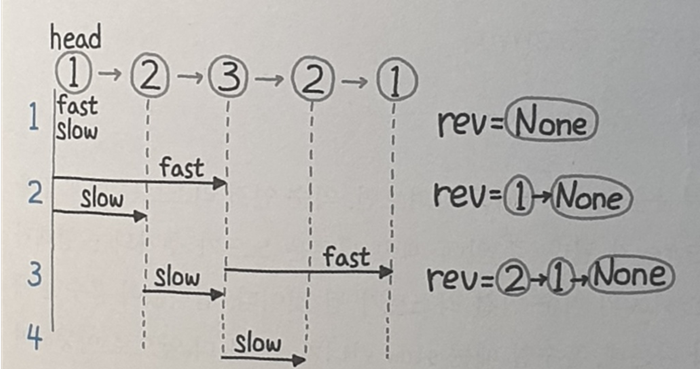
class Solution:
def isPalindrome(self, head: Optional[ListNode]) -> bool:
slow = fast = head
prev = rev_head = None
while fast and fast.next:
rev_head = slow # 앞에서 rev_head = slow 를 하는 이유는, fast가 끝났을 때 rev_head는 slow 이전을 가리켜야 하기 때문
fast = fast.next.next
slow = slow.next # slow 가 다음 노드 위치를 저장하는 temp 역할
rev_head.next = prev # 역순으로 연결 변경
prev = rev_head
if fast:
slow = slow.next
while rev_head and rev_head.val == slow.val:
slow = slow.next
rev_head = rev_head.next
return not rev_head
- 한 칸씩 움직이는
slow와 두 칸씩 움직이는fast를 사용하여 팰린드롬을 체크
- 참조대입에 주의하면서 푼다.
- 역순으로 연결순서가 바뀐
rev_head와 올바른 순서인slow를 하나씩 이동하며 팰린드롬을 체크한다.
rev_head = slow를while문 시작할 때 사용
fast가 끝났을 때,rev_head와slow가 다른 위치를 가리켜야 하기 때문- 만약
slow = slow.next이후에rev_head = slow를 하게 되면,
- 결과적으로
rev_head와slow는 같은 곳을 가리킨다.- 그러면 팰린드롬 체크가 불가능
21번 문제, 두 정렬 리스트의 병합
-
링크드 리스트를 활용한 풀이 (책 풀이)재귀사용
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def mergeTwoLists(self, list1: Optional[ListNode], list2: Optional[ListNode]) -> Optional[ListNode]:
if (not list1) or (list2 and list1.val > list2.val): # list1 이 가리키는 노드는 무조건 작은 값이다.
list1, list2 = list2, list1
if list1: # 재귀 종료조건 : list1 이 None인 경우 재귀함수의 호출이 끝난다.
list1.next = self.mergeTwoLists(list1.next, list2) # list1.next를 재귀적으로 정한다.
return list1 # 현재 list1 이 가리키는 (작은 값) 노드를 반환한다.
- 현재 함수에서 정하는 건,
list1포인터이다.
- 따라서, 현재 함수에서 가장 작은 값을 가진 노드를 가리키는
list1이 정해진다.
list1이None을 가리키게 되거나,list1이 가리키는 노드 값이list2가 가리키는 노드값보다 크면list1과list2를 바꾼다.- 재귀함수에서 정하는 건,
list1.next포인터이다.
206번 문제, 역순 연결 리스트
-
링크드 리스트를 활용한 풀이 (책 풀이)반복사용
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def reverseList(self, head: Optional[ListNode]) -> Optional[ListNode]:
prev = None
cur = head
while cur:
next_node = cur.next # 다음 노드를 저장
cur.next = prev # 역순으로 연결 변경
prev = cur # 이전 노드를 현재 노드 위치로 이동
cur = next_node # 현재 노드를 다음 노드 위치로 이동
return prev
- 연결 순서를 바꾸면 (
cur.next = prev) 다음 노드에 접근할 수 없게 되기 때문에
next_node = cur.next로 미리 다음 노드 참조를 저장한다.- 반복문이 끝나면
cur은None이기 때문에,prev를 반환해주어야 한다.
정수 리스트를 링크드 리스트로 바꾸기
# Definition for singly-linked list.
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
# 노드값 출력 함수
def print_nodes(head):
while head:
print(str(head.val) + " -> ", end="")
head = head.next
print(None)
### 정수 리스트를 링크드 리스트로 바꾸는 법
# 정수 리스트 : [1, 2, 3]
given = [1, 2, 3]
# 링크드 리스트 : <1, 2, 3>
head = cur = ListNode(given[0])
for num in given[1:]:
cur.next = ListNode(num)
cur = cur.next
print_nodes(head)
# 역순 링크드 리스트 : <3, 2, 1>
prev = cur = None
for num in given:
cur = ListNode(num)
cur.next = prev
prev = cur
print_nodes(cur)출력결과
1 -> 2 -> 3 -> None 3 -> 2 -> 1 -> None
24번 문제, 페어의 노드 스왑
-
링크드 리스트를 활용한 풀이 (책 풀이)반복사용
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def swapPairs(self, head: Optional[ListNode]) -> Optional[ListNode]:
root = prev = ListNode(None) # 시작할 때 빈 prev 노드를 만든다.
prev.next = a = head
while a and a.next: # a 노드는 홀수번째 노드, b 노드는 짝수번째 노드
b = a.next
a.next = b.next # a 노드를 b 다음 노드와 연결
b.next = a # b 노드는 a 노드와 연결 (연결 순서 뒤집기)
prev.next = b # 앞선 노드를 b 노드와 연결
a = a.next # 다음 페어로 이동
prev = prev.next.next
return root.next # 시작할 때 빈 노드를 만들었으므로 그 다음 노드가 제대로 된 head 이다.
- 시작할 때 빈
prev노드를 만든다.
- 이를 통해 시작부분인지 체크하는 예외처리 없이, 일반적으로
prev,ab연결 로직을 수행할 수 있다.
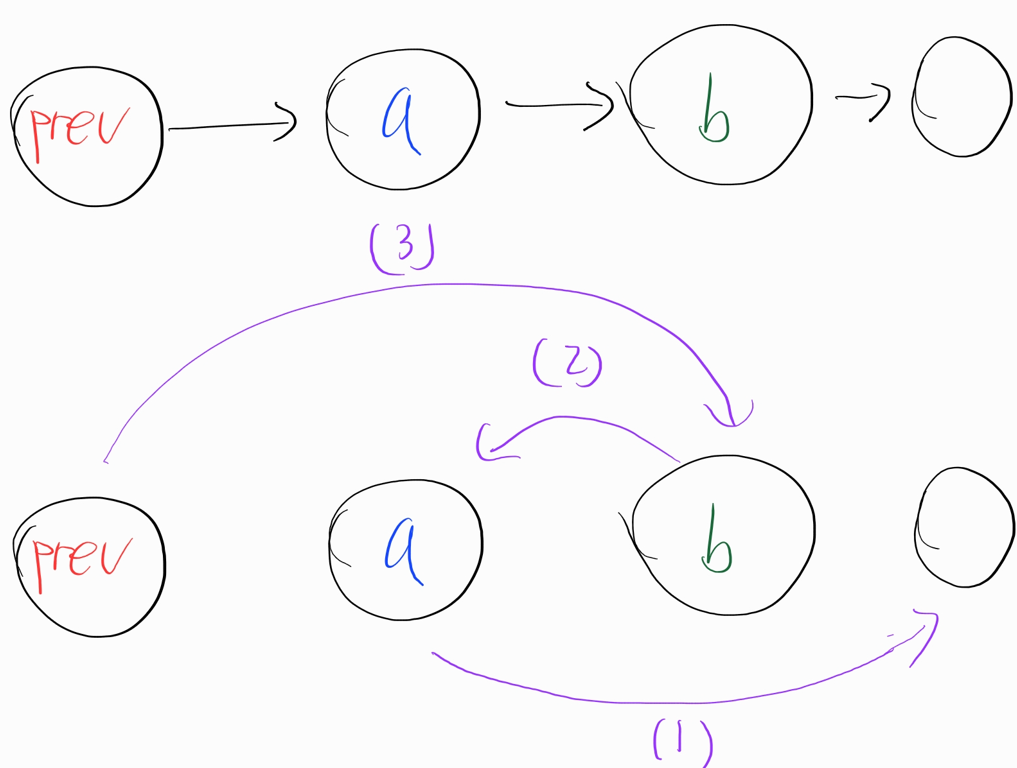
a노드는 홀수번째 노드,b노드는 짝수번째 노드를 의미한다.- 둘은 하나의 페어로,
a = a.next를 통해 다음 페어로 이동한다.
- 둘은 하나의 페어로,
- 시작할 때 빈
prev노드를 만들었으므로, 정답을 반환할 땐,root.next를 통해 다음 노드를 반환해야 한다.
92번 문제, 역순 연결 리스트 II
-
링크드 리스트를 활용한 풀이 (책 풀이)반복사용
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def reverseBetween(self, head: Optional[ListNode], left: int, right: int) -> Optional:
if not head or left == right:
return head
root = start = ListNode()
root.next = head
for _ in range(left - 1):
start = start.next # start 는 left_node 바로 앞 부분
end = start.next # end 는 right_node 부분, 변경되는 부분의 가장 끝 노드
for _ in range(right-left): # start 와 end 사이, (정확히는 start 바로 뒤에) 에 하나씩 end 다음 노드를 삽입
tmp = start.next # 이전에 삽입된 중간 노드
start.next = end.next # end 다음 노드를 start 뒤로 삽입
end.next = end.next.next # end 다음 노드를 다음다음 노드로 변경
start.next.next = tmp # 이전에 삽입된 중간 노드를 한 칸 뒤로 이동
return root.next
left가 1인 경우를 대비해 시작 부분에 빈 노드를 넣어준다.
start는 변경되지 않는 시작부분으로,left_node의 바로 앞 부분이어야 되기 때문end는right_node부분으로, 변경되는 부분의 가장 끝 노드start와end사이,start바로 뒤에 하나씩end.next노드를 삽입한다.
right - left만큼 반복- 이전에 중간 삽인된
start.next노드는 한 칸 뒤로 밀려난다.
스택, 큐
-
스택
- FIFO 구조
-
큐
-
LIFO 구조
-
많은 문제에서
front,rear포인터를 통해 설명하곤 하는데,-
front가 데이터를 뱉는 곳이고 (poll) -
rear가 데이터가 들어가는 곳이다. (offer,add) -
큐는 데이터를 똥구멍으로 넣어서 입으로 뱉는다.
-
-
316번 문제, 중복 문자 제거
-
실패이유: 구현실패스택을 이용하여 책 풀이
class Solution:
def removeDuplicateLetters(self, s: str) -> str:
counter, seen, stack = collections.Counter(s), set(), []
for ch in s:
counter[ch] -= 1
if ch in seen: # 만약 이미 스택에 있는, 이미 본 문자열인 경우 스택에 추가하지 않고 로직을 건너뛴다.
continue
while stack and ch < stack[-1] and counter[stack[-1]] > 0: # 스택 top 문자가 현재 문자보다 사전적으로 뒤에 있는 문자이고, 아직 뒤에 존재하는 문자인 경우
seen.remove(stack.pop()) # 조건 만족 시, 스택에서 제거 및, 이미 본 문자열 set 에서 제거
stack.append(ch)
seen.add(ch)
return ''.join(stack)
counter를 통해 주어진 문자열의 문자 개수를 센다.
for문에서 문자 하나씩 움직일 때 마다,counter에서 문자 개수를 빼준다.
counter[ch] -= 1seen은 이미 본 문자를 의미한다.
- 해당 문자는 정답
stack에 존재한다.if ch in seen: continue
- 만약 스택에 있는, 이미 본 문자는 로직을 수행하지 않고 건너뛴다.
- 이를 통해, 문자가 중복해서 들어가지 않는다.
stack에 들어간 문자들을 순서대로 조합하면 정답이 된다.while stack and ch < stack[-1] and counter[stack[-1]] > 0:
- 스택에 값이 존재하고,
- 스택의
top문자가 현재 문자보다 사전적으로 뒤에 위치하며,- 스택의
top문자가 아직 뒤에 존재하는 경우seen.remove(stack.pop())
- 스택의
top문자를 꺼내고, 이미 본 문자에서 제거한다.- 그 후, 스택과 이미 본 문자
set에 현재 문자(ch)를 추가한다.
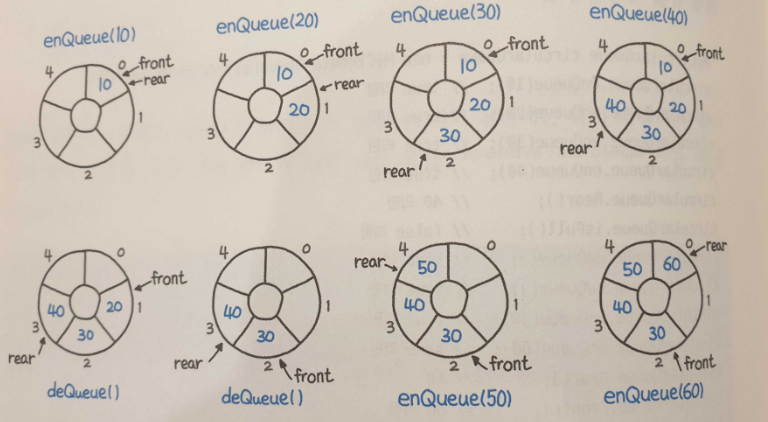
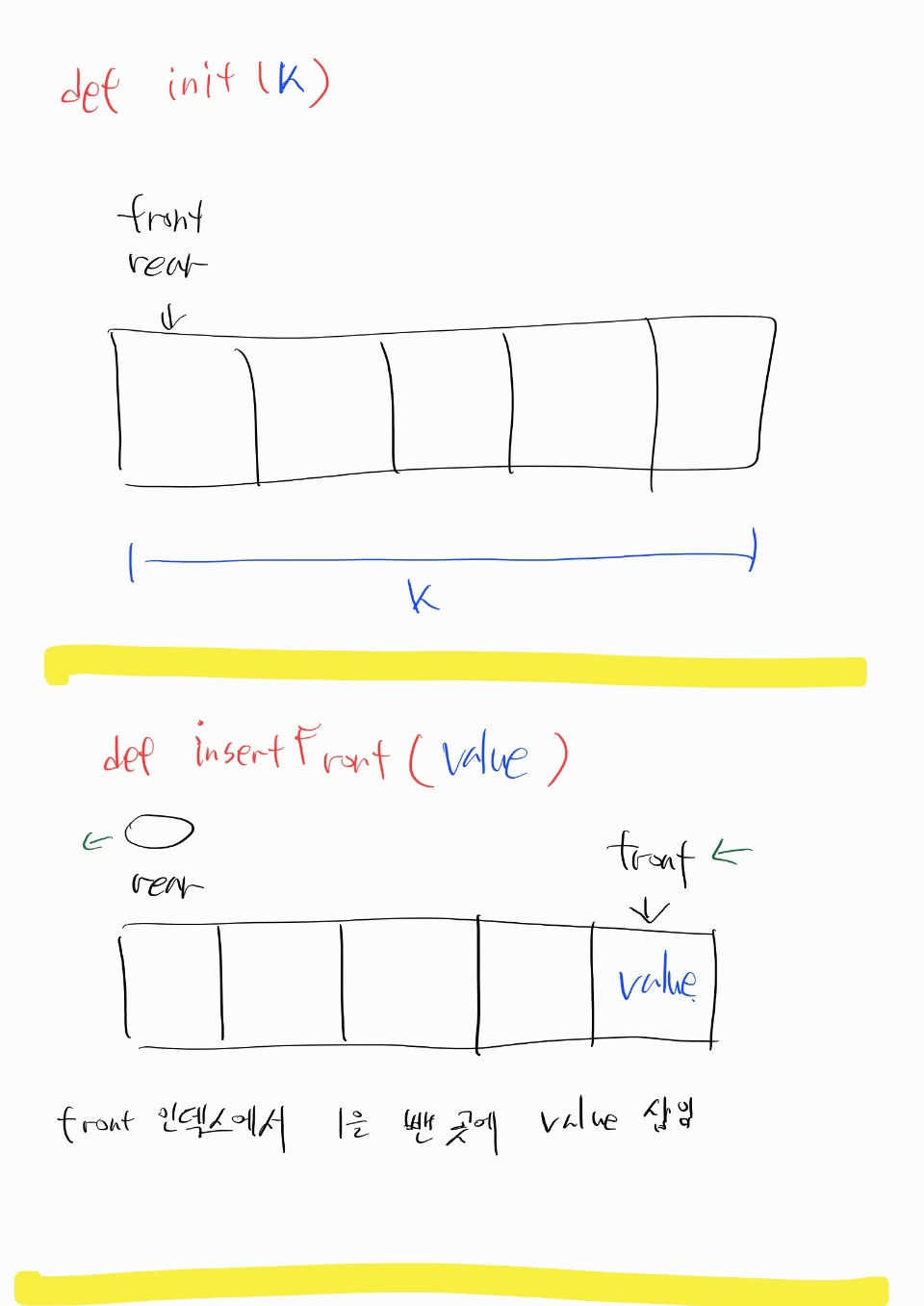
622번 문제, 원형 큐 디자인
데이터 삽입은 rear로, 데이터 추출은 front 로 한다.
원형 큐 Circular Queue- 일반적으로 큐는 포인터가 계속해서 올라간다.
- 공간을 재활용하지 못한다.
- 일반적으로 큐는 포인터가 계속해서 올라간다.
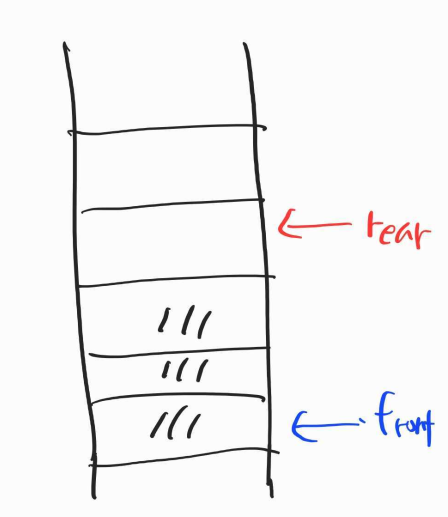
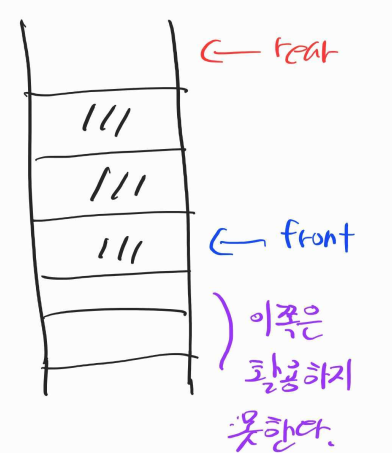
- 공간을 재활용 가능하도록 동그랗게 연결한 큐
- 투 포인터가 빙글빙글 돌면서 공간을 재활용
실패이유: 구현실패
class MyCircularQueue:
def __init__(self, k: int):
self.front = self.rear = 0
self.q = [None] * k
self.max_len = k
def enQueue(self, value: int) -> bool:
if self.isFull():
return False
self.q[self.rear] = value
self.rear = (self.rear + 1) % self.max_len
return True
def deQueue(self) -> bool:
if self.isEmpty():
return False
self.q[self.front] = None
self.front = (self.front + 1) % self.max_len
return True
def Front(self) -> int:
if self.isEmpty():
return -1
return self.q[self.front]
def Rear(self) -> int:
if self.isEmpty():
return -1
return self.q[self.rear - 1]
def isEmpty(self) -> bool:
return self.front == self.rear and self.q[self.front] is None
def isFull(self) -> bool:
return self.front == self.rear and self.q[self.front] is not None
# Your MyCircularQueue object will be instantiated and called as such:
# obj = MyCircularQueue(k)
# param_1 = obj.enQueue(value)
# param_2 = obj.deQueue()
# param_3 = obj.Front()
# param_4 = obj.Rear()
# param_5 = obj.isEmpty()
# param_6 = obj.isFull()
rear가 가리키는 곳은, 데이터를 집어넣을 빈 칸
enQueue동작 시, 데이터를 집어넣은 후 다음칸으로 이동front가 가리키는 곳은, 데이터가 들어있는 맨 앞칸
deQueue()동작 시, 데이터를None으로 만든 후, 다음칸으로 이동isEmpty()조건
front,rear가 같고, 해당 위치에 값이 없는 경우isFull()조건
front,rear가 같고, 해당 위치에 값이 있는 경우def Rear()의 반환 값은 현재rear가 가리키는 칸의 이전칸이다.
rear가 가리키는 곳은 데이터를 집어넣을 빈칸이기 때문이다.rear가 0인 경우, -1 인덱스로 해당 배열에 마지막 위치를 의미한다.
python이므로 가능한 표현식- 만약
python이 아니라면,(max_len + rear - 1) % max_len가 반환 인덱스가 되어야 한다.
데크, 우선순위 큐
Deque
-
Double-Ended Queue -
양쪽 끝을 모두 추출할 수 있는 자료구조
- 일반적으로 이중 연결 리스트로 구현
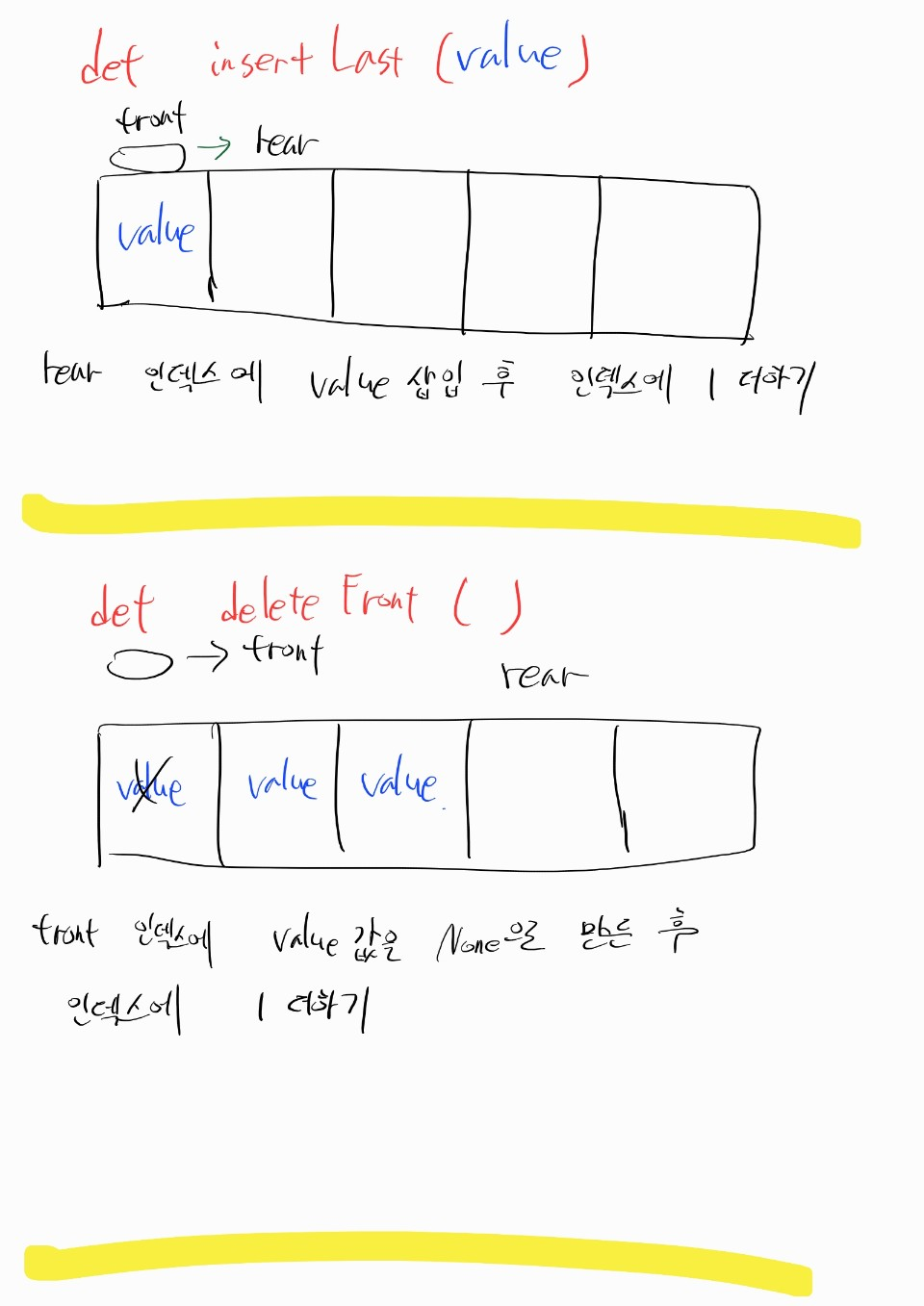
641번 문제, 원형 데크 디자인
-
내 풀이
- 원형으로 구현하기 위해 정적인 배열을 이용
class MyCircularDeque:
def __init__(self, k: int): # 초기 사이즈 설정
self.q = [None] * k
self.front = self.rear = 0
self.max_size = k
def insertFront(self, value: int) -> bool: # 앞에 value 넣고 성공 시 true 반환
if self.isFull():
return False
next_front_idx = (self.max_size + self.front - 1) % self.max_size
self.q[next_front_idx] = value
self.front = next_front_idx
return True
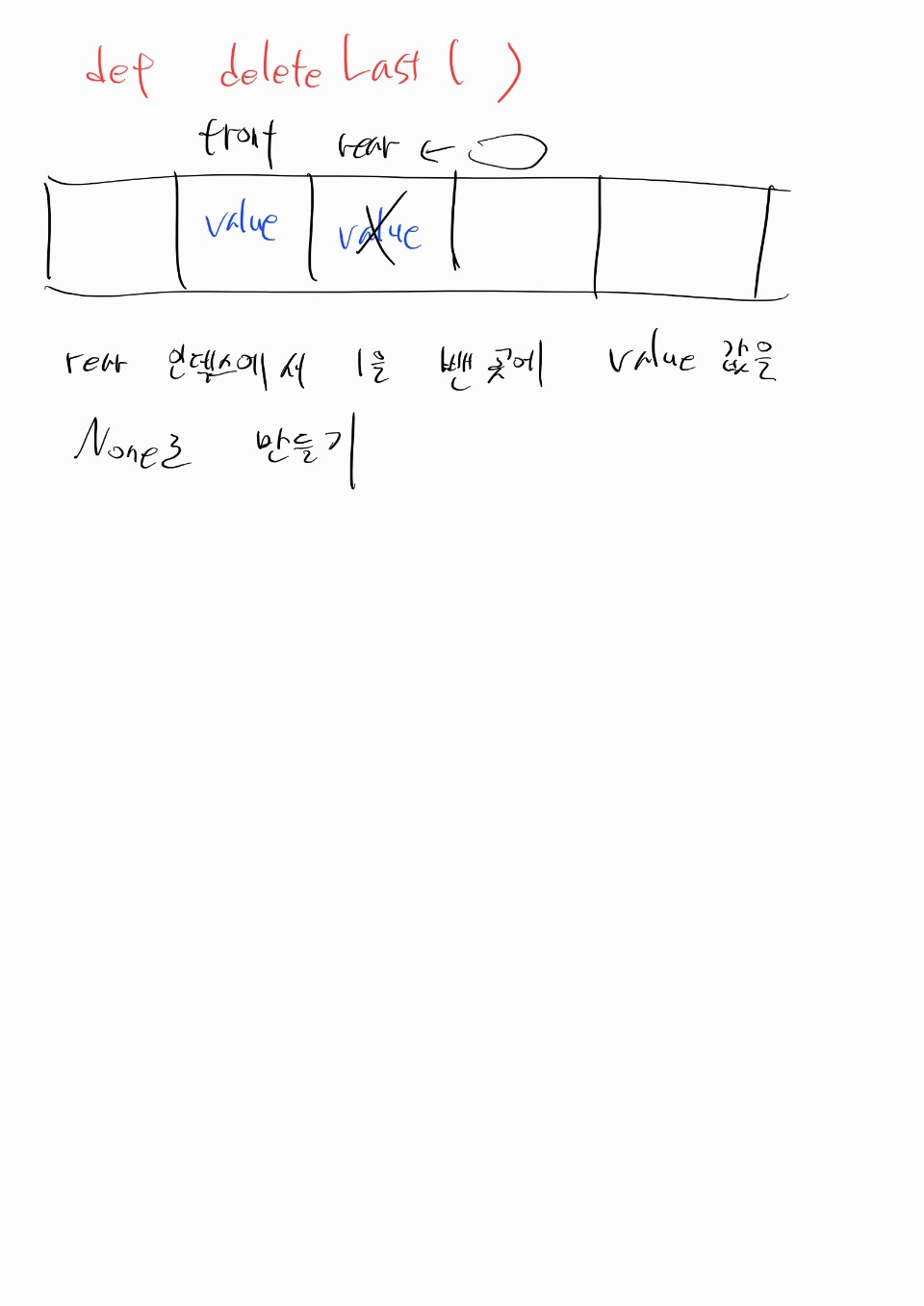
def insertLast(self, value: int) -> bool: # 뒤에 value 넣고 성공 시 true 반환
if self.isFull():
return False
self.q[self.rear] = value
self.rear = (self.rear + 1) % self.max_size
return True
def deleteFront(self) -> bool: # 앞에서 value 빼고 성공 시 true 반환
if self.isEmpty():
return False
self.q[self.front] = None
self.front = (self.front + 1) % self.max_size
return True
def deleteLast(self) -> bool: # 뒤에서 value 빼고 성공 시 true 반환
if self.isEmpty():
return False
next_rear_idx = (self.max_size + self.rear - 1) % self.max_size
self.q[next_rear_idx] = None
self.rear = next_rear_idx
return True
def getFront(self) -> int: # 첫 번째 value 반환 , 없을 시 -1
if self.isEmpty():
return -1
return self.q[self.front]
def getRear(self) -> int: # 맨 뒤 value 반환 , 없을 시 -1
if self.isEmpty():
return -1
return self.q[self.rear - 1]
def isEmpty(self) -> bool:
return (self.front == self.rear and self.q[self.front] == None)
def isFull(self) -> bool:
return (self.front == self.rear and self.q[self.front] != None)
# Your MyCircularDeque object will be instantiated and called as such:
# obj = MyCircularDeque(k)
# param_1 = obj.insertFront(value)
# param_2 = obj.insertLast(value)
# param_3 = obj.deleteFront()
# param_4 = obj.deleteLast()
# param_5 = obj.getFront()
# param_6 = obj.getRear()
# param_7 = obj.isEmpty()
# param_8 = obj.isFull()
front인덱스는 뺄 값을 가리키고,rear인덱스는 값을 넣을 빈 칸을 가리킨다.
우선순위 큐
- 어떤 특정 조건에 따라 우선순위가 가장 높은 요소가 추출되는 자료구조
heapq 모듈
- 최소 힙을 지원하는 모듈
from heapq import *
heap = []
heappush(heap, 4)
heappush(heap, 5)
heappush(heap, 3)
while heap:
print(heappop(heap)) # pop을 할 때, 우선순위가 가장 높은 요소가 추출된다. (최소값)
# 3 -> 4 -> 5 추출
heap이 정렬되어 있는 것은 아니다.heappop(heap)을 하면서
- 우선순위가 가장 높은 값을 추출하고,
- 우선순위가 다음으로 높은 값이 맨 앞으로 온다.
- 최소값이 낮을수록 우선순위가 높다.
from heapq import *
heap = []
heappush(heap, (4, 1, 3))
heappush(heap, (4, 1, 4))
heappush(heap, (4, 0, 5))
while heap:
print(heappop(heap))
# (4, 0, 5) -> (4, 1, 3) -> (4, 1, 4)
- 다음과 같이 튜플로 넣을 수 있다.
- 튜플 순서가 우선순위 정렬 기준이 된다.
- 첫 번째 값이 정렬 기준이 된다.
- 첫 번재 값이 같으면, 두 번째 값이 정렬기준이 된다.
- 첫 번째, 두 번째 값이 같으면 세 번째 값이 정렬기준이 된다.
해시 테이블
-
키를 값에 매핑하는 구조의 자료구조
-
해시 함수- 임의 크기 데이터를 고정 크기 값의 키로 변환하는 함수
ABC -> A1
1324BC -> CB
AF32B -> D5
- 데이터(키) -> 해시
- 여기서
->(화살표)가 바로해시 함수이다.
-
해시 테이블을 인덱싱하기 위해 해시 함수를 사용하는 것을
해싱이라 한다.해싱의 결과를해시라 한다.
좋은 해시 함수
-
해시 함수 값 충돌의 최소화
- 서로 다른 키의 해싱 결과 값이 같은 경우를
충돌이라 한다.
- 서로 다른 키의 해싱 결과 값이 같은 경우를
-
쉽고 빠른 연산
-
해시 테이블 전체에 해시값이 균일하게 분포
-
사용할 키(데이터)의 모든 정보를 이용하여 해싱
로드 팩터
-
해시 테이블에 저장된 데이터 개수
n을 버킷 개수k로 나눈 것-
버킷 개수는 테이블의 크기를 말한다.
-
-
-
로드 팩터 비율에 따라 해시 함수를 수정하거나, 해시 테이블 크기를 조정한다.
-
자바 10 에서 디폴트 로드 팩터는 0.75 이다.
-
로드 팩터가 증가하면 해시 테이블 성능은 감소한다.
해시 테이블 구현 방식
-
개별 체이닝
-
충돌 발생 시, 링크드 리스트로 데이터를 연결한다.
-
전통적인 방식으로 구현이 간단하다.
-
버킷 수와 상관없이 데이터를 무한정 넣을 수 있다.
-
일반적으로
O(1)의 탐색이지만, 모든 데이터가 해시 충돌이 발생한 경우O(N)탐색이 된다. -
C++,자바,GO가 사용한다.
-
-
오픈 어드레싱
-
충돌 발생 시, 탐사를 통해 빈 공간을 찾아나서는 방식
-
모든 원소가 반드시 자신의 해시값과 일치하는 주소에 저장된다는 보장이 없다.
-
오픈 어드레싱도 여러 방식이 있다.
- 선형 탐사의 경우, 충돌이 발생할 경우 해당 위치부터 순차적으로 탐사를 해 빈공간을 찾는다.
- 선형 탐사의 경우, 해시 테이블에 저장되는 데이터들이 고르게 분포되지 않고 뭉치는 경향이 있다.
- 이 경우, 탐색 성능이 떨어진다.
-
버킷 수를 넘어가는 경우, 데이터를 넣을 수 없다.
-
Python,루비가 사용한다.
-
파이썬의 체이닝 방식 vs 오픈 어드레싱 (선형 탐사)
-
Python의 경우, 링크드 리스트를 만드는malloc의 오버헤드가 높아 오픈 어드레싱 방식을 사용 -
대신, 디폴트 로드 팩터를 개별 체이닝 방식보다 낮게 잡는다. (0.66)
3번 문제, 중복 문자 없는 가장 긴 부분 문자열
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
used = {} # 문자와 인덱스를 저장
max_length = start = 0 # start 인덱스부터 현재 인덱스까지의 길이를 세어 최대길이를 구한다.
for index, char in enumerate(s):
if char in used and start <= used[char]: # 만약 한번 나온적 있는 중복문자이고 start 인덱스보다 뒤에 나온 경우 start 인덱스를 갱신
start = used[char] + 1
else: # 중복 문자가 아닌 경우, 최대길이를 갱신한다
max_length = max(max_length, index - start + 1)
used[char] = index # 현재 문자를 딕셔너리에 저장
return max_length
start인덱스부터index(현재) 인덱스까지의 길이를 세어 최대길이를 갱신한다.if char in used and start <= used[char]:
char in used
- 한번 나온적 있는 중복 문자인 경우
start <= used[char]
- 최대 길이를 세고 있는
start인덱스 뒤에 나온 중복문자인 경우start = used[char] + 1
start인덱스를 갱신한다.- 이전에 나온 중복문자 위치 바로 다음부터 다시 센다.
- 중복 문자가 아닌 경우
- 최대 길이를 계속해서 센다
그래프
-
객체의 일부 쌍들이 연관되어있는 객체 집합 구조
-
그래프 탐색 방법
- DFS
- Depth-First Search
- 깊이 우선 탐색
- 재귀나 스택으로 구현
- BFS
- Breadth-First Search
- 너비 우선 탐색
- 큐로 구현
- DFS
-
그래프 표현 방법
-
인접 행렬 (Adjacency Matrix)
-
인접 리스트 (Adjacency List)
-
332번 문제, 일정 재구성
class Solution:
def findItinerary(self, tickets: List[List[str]]) -> List[str]:
graph = collections.defaultdict(list)
for a, b in sorted(tickets, reverse=True):
graph[a].append(b)
route = []
def dfs(node):
while graph[node]:
dfs(graph[node].pop())
route.append(node)
dfs('JFK')
return route[::-1]
- 입력 예시 :
tickets = [["JFK","KUL"],["JFK","NRT"],["NRT","JFK"]]sorted(tickets, reverse=True)를 통해 딕셔너리에 저장되는value(list) 요소들을 역순으로 저장할 수 있다.
{'JFK' : ['NRT', 'KUL'], 'NRT' : ['JFK'] }


207번 문제, 코스 스케줄
class Solution:
def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool:
graph = collections.defaultdict(list)
for x, y in prerequisites:
graph[x].append(y)
traced = set() # 방문한 노드들
no_circle_nodes = set() # 이미 검사를 마쳐 순환하지 않음이 증명된 말단 노드들
def dfs(i):
if i in traced: # 만약 현재 노드를 이미 방문했을 경우
return False
if i in no_circle_nodes: # 만약 현재 노드가 순환하지 않는 말단 노드인 경우
return True
traced.add(i) # 방문노드에 저장
for y in graph[i]: # 연결된 노드들 재귀 탐색
if not dfs(y): # 만약 순환 발견 시, False 줄줄이 반환
return False
traced.remove(i) # 현재 노드 검사가 끝난 경우, 방문 노드에서 제거
no_circle_nodes.add(i) # 현재 노드는 순환하지 않는 말단 노드
return True
for x in list(graph): # 모든 노드에 대해 검사
if not dfs(x):
return False
return True
- 그래프에 순환이 존재하는지 찾는 문제
- 순환하지 않음이 증명된 말단노드 부터
no_circle_nodes에 저장된다.- 방문한 노드들은
traced에 저장된다.- 현재 노드에 대한 검사가 끝나면
traced에선 제거하고,no_circle_nodes에 넣는다.- 만약 재귀탐색을 하다 방문한 노드가
no_circle_nodes안에 있는 경우
- 해당 노드에서 모든 탐색은 순환하지 않으므로,
- 재귀 탐색을 종료하고
True반환- 만약 재귀탐색을 하다 방문한 노드가
traced안에 있는 경우
- 순환이 발견되었으므로,
- 해당 노드에서 재귀 탐색을 종료하고
False반환
최단 경로 문제
-
한 지점에서 다른 지점으로 갈 때 가장 빠른 길을 찾는 문제
-
대표적으로 다익스트라 알고리즘이 있다.
다익스트라 알고리즘
-
BFS 를 이용한다.
-
가중치가 음수인 경우엔 사용할 수 없다.
- 이 경우엔 벨만-포드 (Bellman-Ford) 알고리즘을 사용한다.
-
최초 구현시엔 시간 복잡도가
O(V^2)이었다.-
현재는 BFS 탐색 시, 우선순위 큐를 적용하여 가장 가까운 순서를 찾는다.
-
이를 통해
O(E logE)시간 복잡도를 가지게 된다.
-
743번 문제, 네트워크 딜레이 타임
-
내 풀이-
우선순위 큐를 사용하지 않은 풀이
-
이미 방문한 노드더라도 반복검사가 발생한다.
-
노드의 개수가 많아지면 비효율적
-
class Solution:
def networkDelayTime(self, times: List[List[int]], n: int, k: int) -> int:
MAX = 100000
graph = [[] for _ in range(n+1)]
dist = [MAX] * (n+1)
for start, end, weight in times:
graph[start].append((end, weight))
queue = collections.deque([(k, 0)])
dist[k] = 0
count = 0
while queue:
node, weight = queue.popleft()
count += 1
for next_node, edge_weight in graph[node]:
if dist[next_node] > edge_weight + weight: # k 노드에서 next_node 노드까지의 거리를 최소값으로 항상 갱신
dist[next_node] = edge_weight + weight
queue.append((next_node, edge_weight + weight))
if count < n: # 모든 노드에 이동할 수 없다면 -1 반환
return -1
return max(dist[1:]) -
책 풀이-
우선순위 큐를 사용한 풀이
-
이미 방문한 노드는 최단거리임이 확정되므로, 다시 검사할 필요 없다.
-
노드의 개수가 적고, 간선의 개수가 많으면 비효율적이다.
-
class Solution:
def networkDelayTime(self, times: List[List[int]], n: int, k: int) -> int:
graph = [[] for _ in range(n+1)]
dist = collections.defaultdict(int)
for start, end, weight in times:
graph[start].append((end, weight))
queue = [(0, k)] # heap의 정렬 순서는 오름차순이고, 튜플로 넣을 경우 앞의 원소가 우선순위가 높으므로
# (weight, 노드 번호) 로 튜플을 구성
while queue:
weight, node = heapq.heappop(queue)
if node not in dist: # 노드의 방문조건을 체크하는 시점이 다른 BFS와 다르다.
# 우선순위 큐에 노드가 남아있더라도, 이미 방문했을 경우 최단거리를 갱신하지 못하므로 이를 무시하기 위해 if 조건이 위에 있다.
dist[node] = weight # 해당 노드를 방문하지 않았을 경우에만 최단거리 갱신
for next_node, edge_weight in graph[node]:
heapq.heappush(queue, (edge_weight + weight, next_node))
if len(dist) < n:
return -1
return max(dist.values())
- 우선순위 큐에 들어가는 정보는 간선
(가중치, 다음 노드)이므로 이미 방문한 노드가 다시 들어갈 수 있다.- 주어진 문제는 노드 개수가 100개로 적은편이므로, 우선순위 큐를 사용하지 않고 푸는 게 더 빠르다.
787번 문제, K 경유지 내 가장 저렴한 항공권
-
https://leetcode.com/problems/cheapest-flights-within-k-stops/
-
내 풀이- 우선순위 큐를 사용하지 않은 풀이
class Solution:
def findCheapestPrice(self, n: int, flights: List[List[int]], src: int, dst: int, k: int) -> int:
NOT_VISIT = 10 ** 6 + 1
graph = [[] for _ in range(n)]
dist = [NOT_VISIT] * n
for start, end, cost in flights:
graph[start].append((end, cost))
queue = collections.deque([(src, 0, 0)])
dist[src] = 0
while queue:
node, cost, count = queue.popleft()
for next_node, edge_cost in graph[node]:
if count <= k and dist[next_node] > cost + edge_cost:
dist[next_node] = cost + edge_cost
queue.append((next_node, cost + edge_cost, count + 1))
return dist[dst] if dist[dst] != NOT_VISIT else -1
count를 추가하여 경유횟수 조건을 처리하였다.
-
책 풀이-
우선순위 큐를 사용한 풀이
-
시간초과로 풀리지 않는다.
-
이 문제는 경유횟수라는 조건이 있다.
-
해당 조건때문에, 갱신한 방문 노드를 더 이상 방문하지 않는 방식으로 우선순위 큐를 활용하면 문제를 풀 수 없다.
-
만약 경유횟수를 큰 효율적인 루트가 있어 해당 노드를 방문해버리면,
-
그 다음 노드를 방문하는데, 경유 횟수 제한에 영향을 줘, 방문할 수 있는 거리를 방문하지 못한다고 할 수 있다.
-
따라서 그냥 모든 노드에 대해 방문 수행하기 때문에 우선순위 큐의 이점을 살리지 못하고, 우선순위 큐의 삽입, 삭제 시간복잡도가 곱해져 시간초과 발생
-
-
-
class Solution:
def findCheapestPrice(self, n: int, flights: List[List[int]], src: int, dst: int, k: int) -> int:
graph = collections.defaultdict(list)
for u, v, w in flights:
graph[u].append((v, w))
Q = [(0, src, k)]
while Q:
price, node, stop_cnt = heapq.heappop(Q)
if node == dst:
return price
if stop_cnt >= 0:
for v, w in graph[node]:
alt = price + w
heapq.heappush(Q, (alt, v, stop_cnt-1))
return -1책 풀이대로 하면 시간 초과 발생
트리
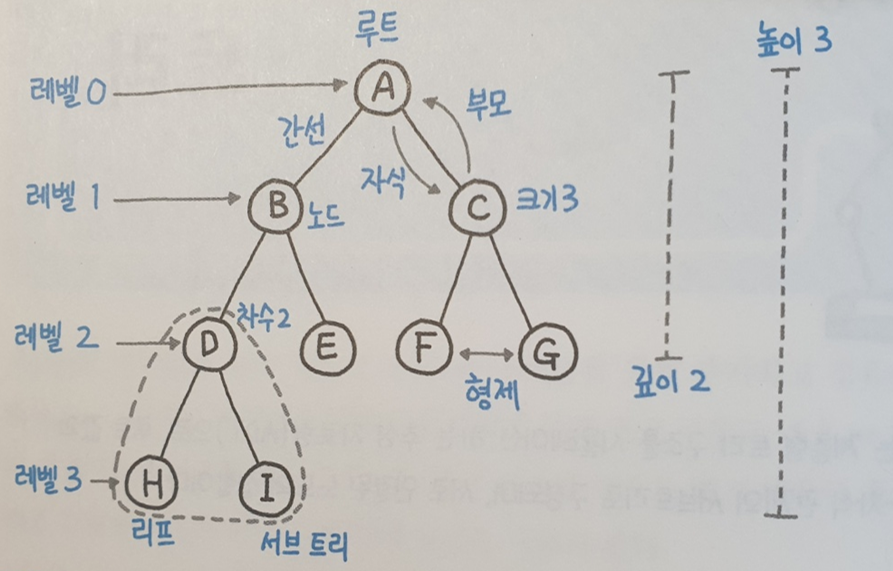
용어 정리
-
루트(Root): 트리의 시작 지점
-
차수(Degree): 해당 노드에서의 자식 노드 개수
B 노드차수 = 2
-
크기(Size): 자신을 포함한 해당 노드에서의 모든 자식 노드 개수
B 노드크기 = 5
트리의 정의
-
트리는 특수한 형태의 그래프의 일종이다.
-
트리는 순환 구조(cyclic)를 갖지 않는 그래프
-
한번 연결된 노드가 다시 연결될 수 없다.
-
부모 노드가 자식 노드를 가리키는 단방향 뿐이다.
-
-
트리는 하나의 부모 노드를 갖는다.
- 루트 또한 하나이다.
이진 트리의 정의
-
모든 노드의 차수가 2 이하
-
왼쪽, 오른쪽 최대 2개의 자식을 갖는 단순한 형태
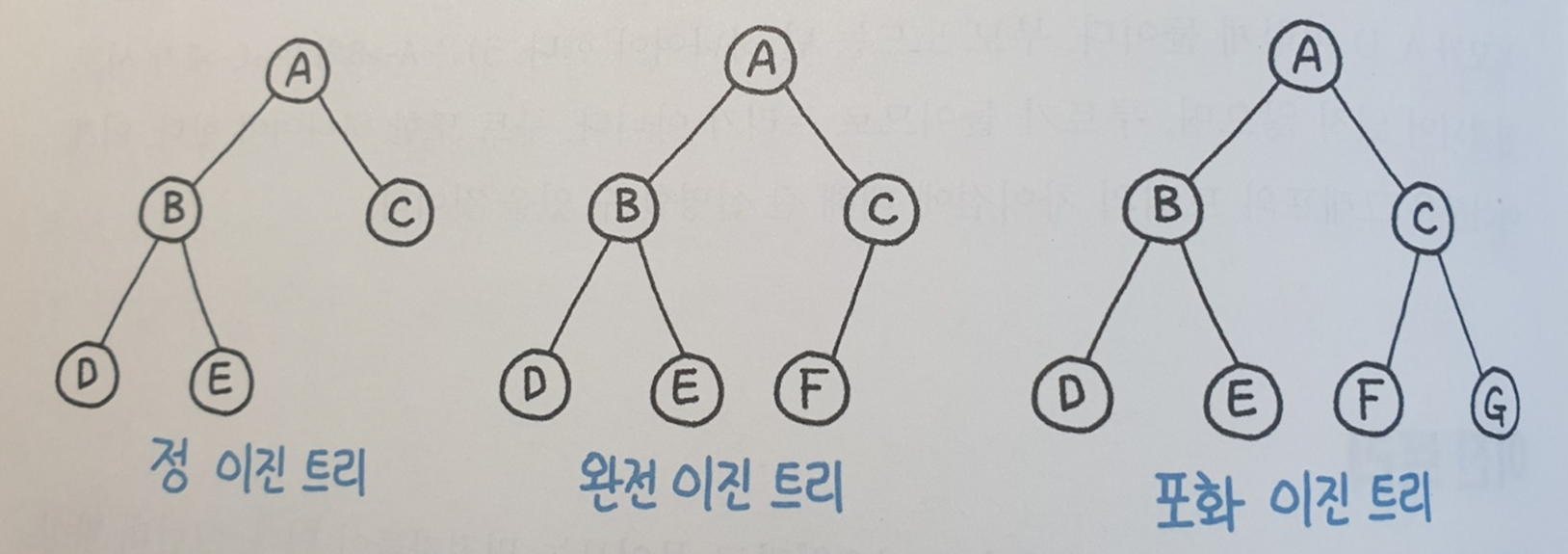
- 정 이진 트리 (Full Binary Tree)
- 모든 노드가 0개 또는 2개의 자식 노드를 갖는다.
- 완전 이진 트리 (Complete Binary Tree)
- 마지막 레벨을 제외하고 모든 레벨이 완전히 채워져 있다.
- 마지막 레벨의 모든 노드는 가장 왼쪽부터 채워져 있다.
- 포화 이진 트리 (Perfect Binary Tree)
- 모든 노드가 2개의 자식 노드를 갖는다.
- 모든 리프 노드가 동일한 레벨을 갖는다.
543번 문제, 이진 트리의 직경
-
내 풀이-
풀리긴 풀리는 데 시간이 오래걸리고, 코드가 지저분하다.
-
모든 노드에 대해 반복해서 해당 노드의 지름을 계산한다.
-
O(N^2)시간 복잡도
-
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def diameterOfBinaryTree(self, root: Optional[TreeNode]) -> int:
def find(node, cnt):
max_value = cnt
if node.left:
max_value = max(find(node.left, cnt + 1), max_value)
if node.right:
max_value = max(find(node.right, cnt + 1), max_value)
return max_value
current = root
ans = 0
queue = collections.deque([current])
while queue:
current = queue.popleft()
left_dia = right_dia = 0
if current.left:
left_dia = find(current.left, 1)
queue.append(current.left)
if current.right:
right_dia = find(current.right, 1)
queue.append(current.right)
ans = max(ans, left_dia + right_dia)
return ans-
책 풀이-
한 번에, 모든 노드의 지름을 계산한다.
-
O(N)시간 복잡도
-
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
longest = 0
def diameterOfBinaryTree(self, root: Optional[TreeNode]) -> int:
def dfs(node):
if not node:
return -1 # 만약 노드가 존재하지 않는다면, 이 부분과 연결된 부모 노드 간선을 끊어줘야 하므로 -1 반환
left = dfs(node.left)
right = dfs(node.right)
self.longest = max(self.longest, left + right + 2) # 왼쪽 길이 + 오른쪽 길이 + 현재 노드의 왼쪽 오른쪽 연결 간선 (2개)
return max(left, right) + 1 # 왼쪽, 오른쪽 중 긴 곳의 길이 + 1을 반환
dfs(root)
return self.longest
DFS와 클래스 변수를 사용하여 처리
687번 문제, 가장 긴 동일 값의 경로
-
내 풀이- 풀리긴 풀리는 데 시간이 오래걸리고, 코드가 지저분하다.
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
longest = 0
def longestUnivaluePath(self, root: Optional[TreeNode]) -> int:
def find(root, prev, diameter):
if not root:
return 0
if root.val != prev:
find(root, root.val, 0)
return 0
left = find(root.left, root.val, diameter)
right = find(root.right, root.val, diameter)
diameter = max(left + right, diameter)
self.longest = max(self.longest, diameter)
return max(left, right) + 1
if not root:
return 0
find(root, root.val, 0)
return self.longest만약 자식 노드 값(
prev) 과 현재 노드 값(root)이 다르면 현재 재귀는 종료하고, 새로운 재귀를 만드는 방식으로 풀었다.
-
책 풀이를 좀 더 깔끔하고 일관성있게 변경- 훨씬 빠르고 직관적이다.
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
longest = 0
def longestUnivaluePath(self, root: Optional[TreeNode]) -> int:
def dfs(node):
if node is None:
return -1
left = dfs(node.left)
right = dfs(node.right)
if node.left and node.left.val != node.val: # 만약 현재노드값과 왼쪽 자식노드 값이 다르면, -1로 연결을 끊어낸다.
left = -1
if node.right and node.right.val != node.val: # 만약 현재노드 값과 오른쪽 자식노드 값이 다르면, -1로 연결을 끊어낸다.
right = -1
self.longest = max(self.longest, left + right + 2)
return max(left, right) + 1
dfs(root)
return self.longest 내 생각엔 이 방식이 불필요한 재귀함수가 많이 발생하지 않아 빠른 것 같다. (정확하진 않음)
617번 문제, 두 이진 트리 병합
-
내 풀이- 풀리긴 풀리는 데 코드가 지저분하고 유사한 구조가 많다.
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def mergeTrees(self, root1: Optional[TreeNode], root2: Optional[TreeNode]) -> Optional[TreeNode]:
if not root1:
return root2
if not root2:
return root1
if not root1 and root2:
return None
root = TreeNode(root1.val + root2.val)
queue = collections.deque([(root, root1, root2)])
while queue:
node, node1, node2 = queue.popleft()
if (node1 and node1.left) or (node2 and node2.left):
val = 0
left_elements = collections.deque()
if node1 and node1.left:
val += node1.left.val
left_elements.append(node1.left)
else:
left_elements.append(None)
if node2 and node2.left:
val += node2.left.val
left_elements.append(node2.left)
else:
left_elements.append(None)
node.left = TreeNode(val)
left_elements.appendleft(node.left)
queue.append(tuple(left_elements))
if (node1 and node1.right) or (node2 and node2.right):
val = 0
right_elements = collections.deque()
if node1 and node1.right:
val += node1.right.val
right_elements.append(node1.right)
else:
right_elements.append(None)
if node2 and node2.right:
val += node2.right.val
right_elements.append(node2.right)
else:
right_elements.append(None)
node.right = TreeNode(val)
right_elements.appendleft(node.right)
queue.append(tuple(right_elements))
return root
- 큐를 사용하여 풀이
- 분기가 너무 많고, 유사한 구조가 반복된다.
책 풀이- 재귀를 사용하여 깔끔하게 풀이
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def mergeTrees(self, root1: Optional[TreeNode], root2: Optional[TreeNode]) -> Optional[TreeNode]:
if root1 and root2: # 두 노드가 존재하는 경우, 두 노드의 val을 병합
node = TreeNode(root1.val + root2.val)
node.left = self.mergeTrees(root1.left, root2.left)
node.right = self.mergeTrees(root1.right, root2.right)
return node
else: # 만약 두 노드가 존재하지 않는 경우, 병합하지 않고 존재하는 한쪽 노드만 반환
return root1 or root2
- 재귀를 사용하여 풀이
- 코드가 짧고 직관적이다.
297번 문제, 이진 트리 직렬화 & 역직렬화
-
https://leetcode.com/problems/serialize-and-deserialize-binary-tree/
-
실패 이유: 구현 실패 -
이진 트리데이터 구조는 논리적으로 존재하는 구조이다.- 파일이나 디스크에 저장하기 위해서는 물리적인 형태로 바꿔야 한다.
- 이를
직렬화라 한다. - 반대 과정을
역직렬화라 한다.
-
이진 트리는 배열로 표현할 수 있다.
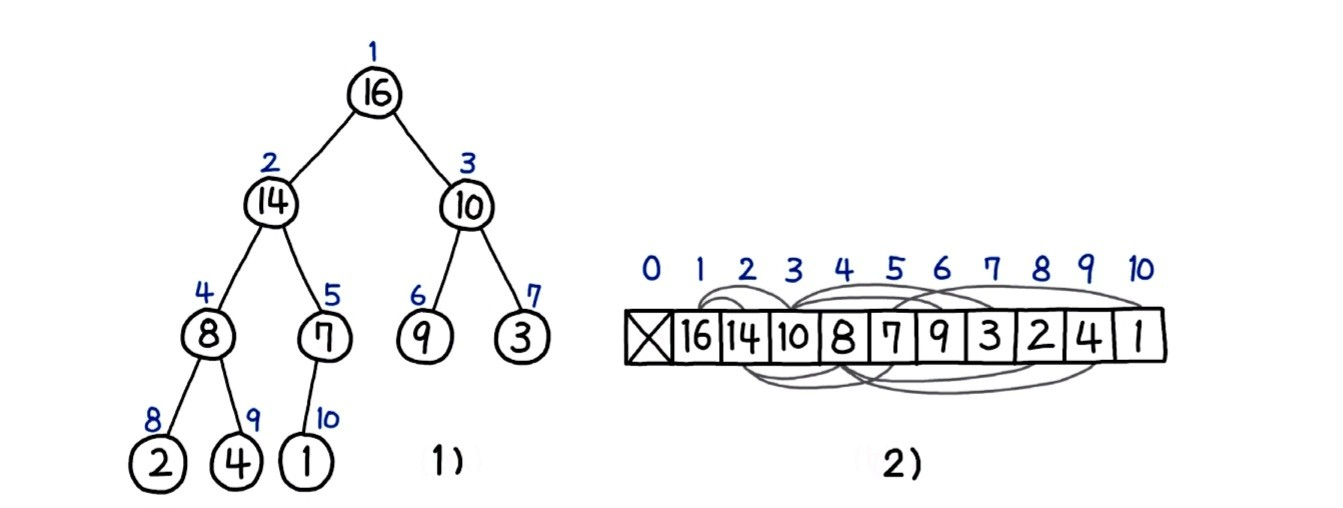
이진 트리를 배열로 직렬화
인덱스는1부터 시작- 부모 노드 위치를
i/2, 왼쪽 자식 위치를2i, 오른쪽 자식 위치를2i + 1로 간단하게 계산하기 위해
- 부모 노드 위치를
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Codec:
def serialize(self, root):
queue = collections.deque([root])
result = ['#']
while queue:
node = queue.popleft()
if node:
queue.append(node.left)
queue.append(node.right)
result.append(str(node.val))
else:
result.append('#')
return ' '.join(result)
def deserialize(self, data):
if data == '# #':
return None
nodes = data.split()
root = TreeNode(int(nodes[1]))
queue = collections.deque([root])
index = 2
while queue:
node = queue.popleft()
if nodes[index] != '#': # 왼쪽 자식에 대한 역직렬화
node.left = TreeNode(int(nodes[index]))
queue.append(node.left)
index += 1
if nodes[index] != '#': # 오른쪽 자식에 대한 역직렬화
node.right = TreeNode(int(nodes[index]))
queue.append(node.right)
index += 1
return root
# Your Codec object will be instantiated and called as such:
# ser = Codec()
# deser = Codec()
# ans = deser.deserialize(ser.serialize(root))해당 위치에 노드가 없는 경우엔
#을 배열에 저장한다.
110번 문제, 균형 이진 트리
-
실패 이유: 구현 실패
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def isBalanced(self, root: Optional[TreeNode]) -> bool:
def dfs(node):
if not node:
return 0
left = dfs(node.left)
right = dfs(node.right)
if left == -1 or right == -1 or abs(left - right) > 1:
return -1 # 만약 왼쪽 오른쪽 노드의 높이가 1이상 차이나거나, 이미 이전 부분에서 높이 차이가 판별된 경우, -1 반환
return max(left, right) + 1
return dfs(root) != -1 # 루트 노드의 값이 -1인 경우 False 반환
post order방식으로 트리의 높이 계산- 만약 왼쪽 오른쪽 노드의 높이가 1이상 차이나는 경우, 해당 루트 노드의 높이를 -1로 변경
- 이를 통해 -1을 상위로 전파시킬 수 있다.
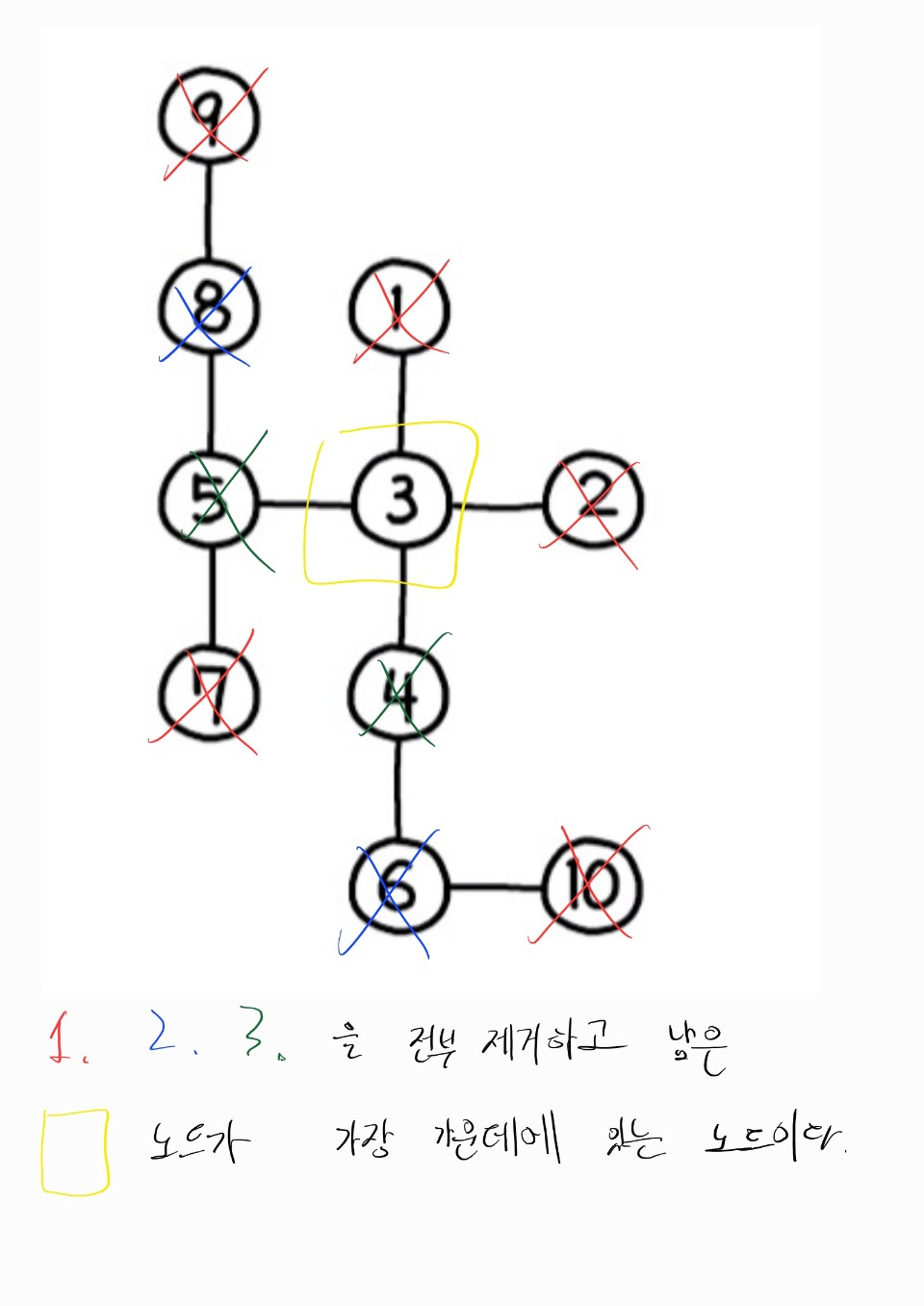
310번 문제, 최소 높이 트리
-
실패 이유: 구현 실패
class Solution:
def findMinHeightTrees(self, n: int, edges: List[List[int]]) -> List[int]:
if n <= 1:
return [0]
graph = collections.defaultdict(list)
for i, j in edges:
graph[i].append(j)
graph[j].append(i)
leaves = [] # 말단에 있는 leaf 노드들을 저장하기 위한 리스트
for i in range(n):
if len(graph[i]) == 1: # 간선이 1개인 leaf 노드들을 저장
leaves.append(i)
while n > 2: # 남아있는 노드가 2개 이하인 경우 남아있는 노드들이 최소 높이 트리의 루트가 된다.
n -= len(leaves)
new_leaves = []
for leaf in leaves:
neighbor = graph[leaf].pop() # 그래프에서 leaf 노드들 제거
graph[neighbor].remove(leaf) # leaf 노드와 연결된 이웃노드에서 leaf 노드 제거 (양방향 그래프기 때문)
if len(graph[neighbor]) == 1: # 만약 이웃노드의 간선 개수가 1개인 경우, 새로운 leaf 노드로 추가
new_leaves.append(neighbor)
leaves = new_leaves # leaf 노드 리스트 업데이트
return leaves
- 최소 높이를 만들려면, 그래프에서 가장 가운데에 있는 값이 루트여야 한다.
- 최소 높이를 구성하기 위해서,
edge가 1개인leaf 노드들을 계속해서 제거한다.- 남아있는 노드가 2개 이하인 경우, 해당 노드들이 최소 트리를 만드는 루트 노드들이다.
이진 탐색 트리 (BST)
-
Binary Search Tree
-
정렬된 이진 트리
- 현재 노드 기준으로 왼쪽 노드는 작은 값, 오른쪽 노드는 큰 값
-
탐색 시 시간 복잡도가
O(log n)-
균형이 잘 맞지 않는 경우엔 최악의 경우
O(n)시간 복잡도 -
따라서 균형이 잘 맞도록 하는 것이 중요하다.
- 높이 균형을 맞추는 자가 균형 이진 탐색 트리로는
RB 트리,AVL 트리가 있다.
- 높이 균형을 맞추는 자가 균형 이진 탐색 트리로는
-
1038번 문제, 이진 탐색 트리를 더 큰 수 합계 트리로
-
https://leetcode.com/problems/binary-search-tree-to-greater-sum-tree/
-
내 풀이-
탐색을 하면서 바로 값을 더해주지 않고, 값을 모두 추출한 뒤 누계하여 값을 변경한다.
-
탐색을 하면서, 누계를 위한
for문을 돌기 때문에 결과적으로O(N^2)시간 복잡도이다.
-
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def bstToGst(self, root: TreeNode) -> TreeNode:
node_values = []
def inorder(node):
if not node:
return
inorder(node.left)
for idx, _ in enumerate(node_values):
node_values[idx] += node.val
node_values.append(node.val)
inorder(node.right)
inorder(root)
global order
order = 0
def change_val(node):
if not node:
return
global order
change_val(node.left)
node.val = node_values[order]
order += 1
change_val(node.right)
change_val(root)
return root-
책 풀이-
탐색을 하면서 바로 값을 더해준다.
- 클래스 변수를 활용하였다.
-
탐색을 하면서 값을 바로 더해주기 때문에
O(N)시간 복잡도이다.
-
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
val = 0
def bstToGst(self, root: TreeNode) -> TreeNode:
if root:
self.bstToGst(root.right)
self.val += root.val
root.val = self.val
self.bstToGst(root.left)
return root
938번 문제, 이진 탐색 트리 합의 범위
-
내 풀이low,high범위를 넘어가는 노드들도 일단은 방문한다.- 방문 후, 범위를 넘어가면
nums에 추가하지 않는다.
- 방문 후, 범위를 넘어가면
- 모든 노드를 방문하므로 비효율적이다.
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def rangeSumBST(self, root: Optional[TreeNode], low: int, high: int) -> int:
nums = []
def inorder(node):
if not node:
return
inorder(node.left)
if low <= node.val <= high:
nums.append(node.val)
inorder(node.right)
inorder(root)
return sum(nums)-
책 풀이-
low,high범위를 넘어가는 노드들은 더 이상 방문하지 않는다.- 현재 노드 값이 범위를 벗어나면, 의미 없는 노드로의
dfs탐색을 더 이상 진행하지 않는다.
- 현재 노드 값이 범위를 벗어나면, 의미 없는 노드로의
-
범위를 벗어나는 게 확실한 의미 없는 노드들은 검사하지 않으므로 효율적이다.
-
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def rangeSumBST(self, root: Optional[TreeNode], low: int, high: int) -> int:
def dfs(node):
if not node:
return 0
if node.val < low: # 현재 노드 값이 low 보다 작으면, 오른쪽 노드만 dfs 탐색한다.
return dfs(node.right)
elif node.val > high: # 현재 노드 값이 high 보다 크면, 왼쪽 노드만 dfs 탐색한다.
return dfs(node.left)
return node.val + dfs(node.left) + dfs(node.right)
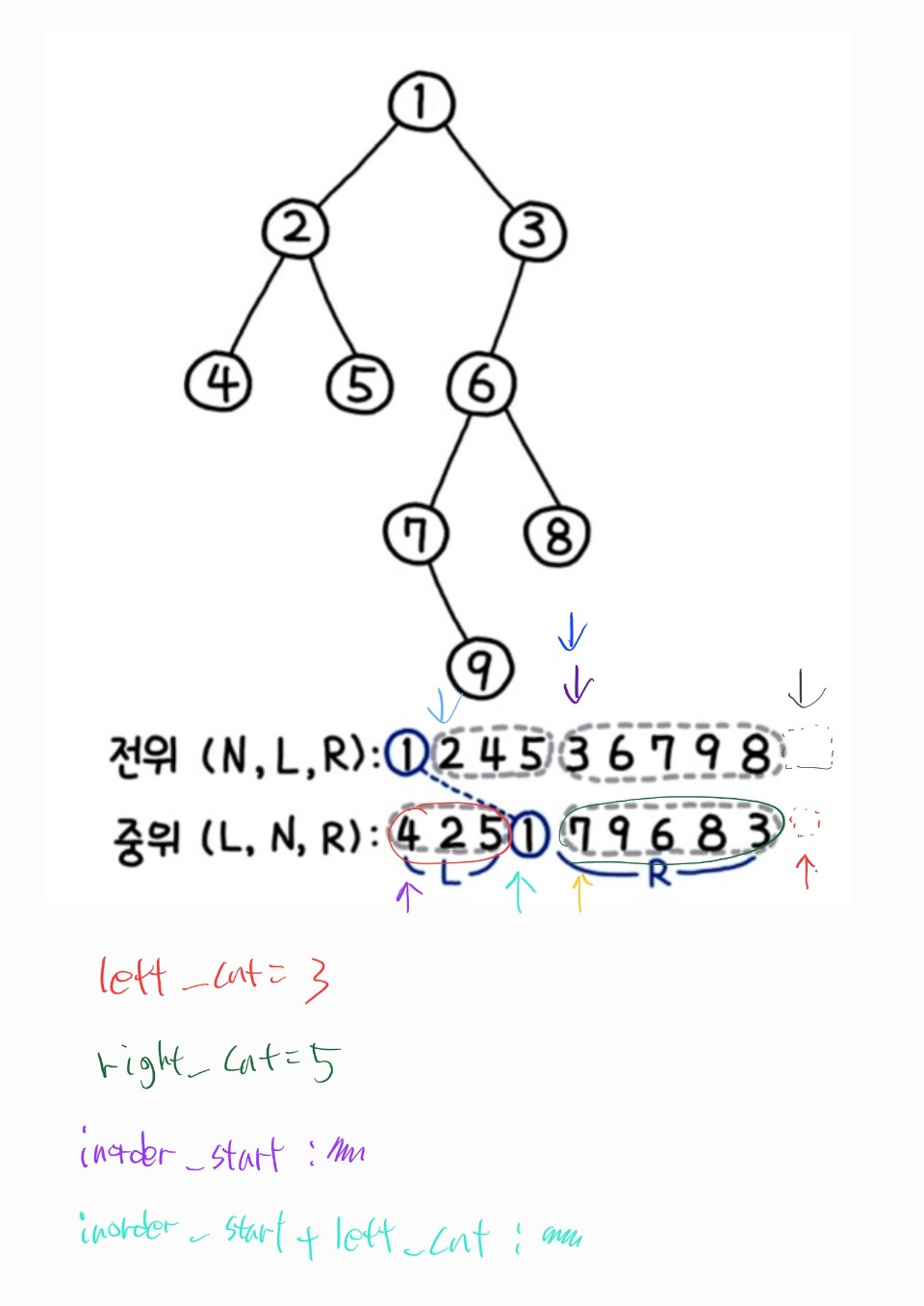
return dfs(root)105번 문제, 전위, 중위 순회 결과로 이진 트리 구축
-
https://leetcode.com/problems/construct-binary-tree-from-preorder-and-inorder-traversal/
-
책 풀이-
재귀와 슬라이싱을 사용하여 서브 리스트를 매개변수로 넘겨주는 방식으로 풀이
-
코드가 짧아지고 직관적이다.
-
그러나 많은 메모리를 사용하게 된다.
-
pop(0)을 사용했기에 시간 복잡도도 좋지 않다.
-
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def buildTree(self, preorder: List[int], inorder: List[int]) -> Optional[TreeNode]:
if inorder:
index = inorder.index(preorder.pop(0))
node = TreeNode(inorder[index])
node.left = self.buildTree(preorder, inorder[0:index])
node.right = self.buildTree(preorder, inorder[index + 1:])
return node -
책 풀이-
재귀와 인덱스를 넘겨주는 방식으로 풀이
-
서브 리스트를 넘기지 않으므로, 메모리를 아낄 수 있다.
-
코드가 다소 길고 복잡하다.
-
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def buildTree(self, preorder: List[int], inorder: List[int]) -> Optional[TreeNode]:
sub_cnt = {i:idx for idx, i in enumerate(inorder)} # inorder 를 활용하여, 현재 노드보다 작은 노드 개수를 딕셔너리에 저장
def find(inorder_start, inorder_end, preorder_start, preorder_end): # inorder 의 시작 인덱스, 끝 인덱스, preorder의 시작 인덱스, 끝 인덱스를 매개변수로 넘겨준다.
if preorder_end == preorder_start: # 만약 시작 인덱스와 끝 인덱스가 같으면 빈 서브 리스트와 같으므로, 노드를 생성하지 못하고 None 반환
return None
root_idx = preorder[preorder_start]
root = TreeNode(root_idx)
if preorder_end - preorder_start <= 1: # 만약 시작 인덱스 + 1 이 끝 인덱스인 경우, 한 개짜리 서브 리스트와 같으므로, 더 이상 divide 하지 않고 leaf 노드만 반환
return root
left_cnt = sub_cnt[root_idx] - inorder_start
right_cnt = inorder_end - sub_cnt[root_idx] - 1 # 현재 노드 기준으로 왼쪽 노드 개수와 오른쪽 노드 개수를 구한다.
root.left = find(inorder_start, inorder_start + left_cnt, preorder_start + 1, preorder_start + 1 + left_cnt) # 왼쪽 노드 생성
root.right = find(inorder_end - right_cnt, inorder_end, preorder_end - right_cnt, preorder_end) # 오른쪽 노드 생성
return root
return find(0, len(inorder), 0, len(preorder))
start인덱스는 서브 리스트의 시작 부분end인덱스는 서브 리스트의 길이 (마지막 부분 + 1)
- 슬라이싱 방식과 유사

힙
-
항상 균형을 유지한다.
-
부모 자식 간의 관계만 정의하고, 좌우에 대한 관계는 정의하지 않는다.
- 최소 힙의 경우, 부모는 자식보다 작다.
힙 연산 (최소 힙 기준)
- 삽입
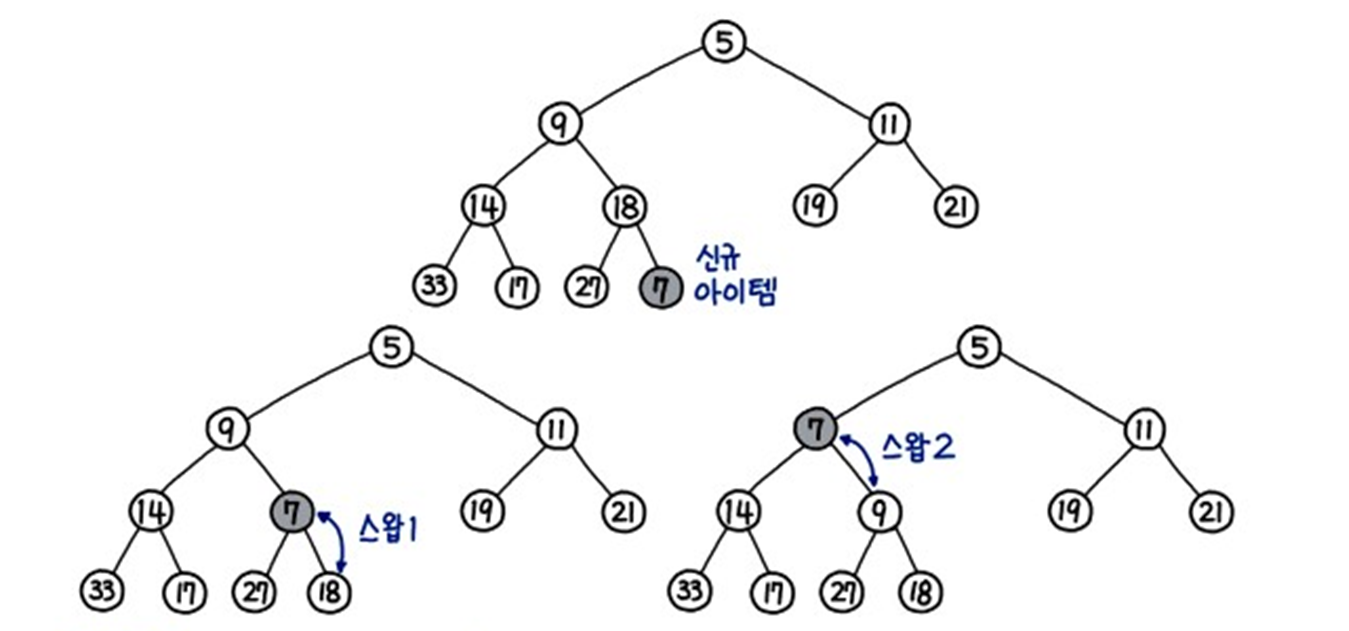
- 트리의 하위 레벨의 최대한 왼쪽으로 삽입한다.
- 부모 자식 간의 관계를 유지하기 위해,
Up-Heap연산을 수행O(log n)시간 복잡도
- 추출
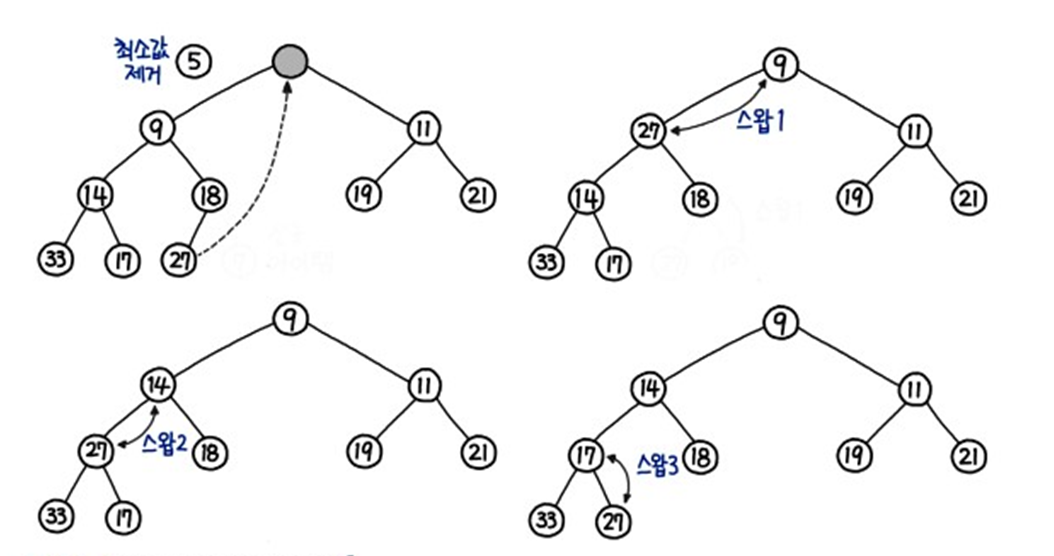
- 루트를 추출한다.
- 트리의 하위 레벨의 가장 오른쪽 요소 (가장 마지막 요소) 를 루트로 올린다.
- 부모 자식 간의 관계를 유지하기 위해,
Down-Heap연산을 수행O(log n)시간 복잡도
트라이
-
키가 문자열인 정렬된 트리 자료구조
-
각각의 문자 단위로 색인을 구축한다.
- 문자 개수만큼 노드가 필요하기 때문에 저장공간의 크기가 크다.
-
존재하는 단어 개수와 상관없이, 트라이 탐색은 찾는 문자열의 길이만큼만 탐색하면 된다.
트라이 구현
class Node:
def __init__(self, key, data=None):
self.key = key
self.data = data
self.children = {}
class Trie:
def __init__(self):
self.head = Node(None)
# 문자열 삽입
def insert(self, string):
curr_node = self.head
for char in string:
# 자식Node들 중 같은 문자가 없으면 Node 새로 생성
if char not in curr_node.children:
curr_node.children[char] = Node(char)
# 같음 문자가 있으면 노드를 따로 생성하지 않고, 해당 노드로 이동
curr_node = curr_node.children[char]
# 문자열이 끝난 지점의 노드의 data값에 해당 문자열을 표시
curr_node.data = string
# 문자열이 존재하는지 탐색
def search(self, string):
# 가장 아래에 있는 노드에서부터 탐색 시작한다.
curr_node = self.head
for char in string:
if char in curr_node.children:
curr_node = curr_node.children[char]
else:
return False
# 탐색이 끝난 후에 해당 노드의 data값이 존재한다면
# 문자가 포함되어있다는 뜻이다!
if curr_node.data:
return True
- https://velog.io/@kimdukbae/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%ED%8A%B8%EB%9D%BC%EC%9D%B4-Trie#%ED%8A%B8%EB%9D%BC%EC%9D%B4trie-%EC%9E%A5%EB%8B%A8%EC%A0%90
(박지훈 님 블로그 글) 을 참고하였습니다.
- 노드의
data안에 값이 들어있으면, 해당 단어가 트라이 내부에 존재함을 의미
정렬
- 목록의 요소를 특정 순서대로 넣는 알고리즘
퀵 정렬
-
피벗을 기준으로 좌우를 나눈다.
-
피벗보다 작으면 왼쪽, 피벗보다 크면 오른쪽으로 옮기는 파티션 교환 정렬이다.
-
이미 정렬된 배열이 입력으로 들어오는 경우, 파티셔닝이 효율적으로 이뤄지지 않는다.
-
최악의 경우이다.
-
피벗 한개와 나머지로 반복해서 파티셔닝 된다.
-
n 번에 걸쳐 모든 값을 비교하므로
O(n^2)시간 복잡도를 갖는다.
-
def quick_sort(arr, start, end):
if end - start < 1: # 종료 조건, 데이터의 길이가 1이하
return
pivot = arr[end] # 가장 오른쪽 값이 피벗
left = start
right = end - 1
while True:
while arr[left] < pivot: # 왼쪽부터 탐색, 피벗보다 큰 값이 있으면 stop
left += 1
while arr[right] > pivot: # 오른쪽부터 탐색, 피벗보다 작은 값이 있으면 stop
right -= 1
if left >= right: # 왼쪽, 오른쪽 투 포인터가 같아지면 반복문 탈출
break
arr[left], arr[right] = arr[right], arr[left]
left += 1
right -= 1 # 교환이 끝났으므로 투 포인터를 한 칸씩 이동
arr[left], arr[end] = arr[end], arr[left] # 마지막으로 피벗과 (현재 라운드에서 피벗보다 작거나 같은 값 중 가장 큰 값)을 교환
quick_sort(arr, start, left - 1) # 피벗값의 좌측을 다시 퀵정렬
quick_sort(arr, left + 1, end) # 피벗값의 우측을 다시 퀵정렬
numbers = [9, 4, -80, 1, 172, 13, 9, 39, -99, 2054, 10, -10, 3, 67, -28]
quick_sort(numbers, 0, len(numbers) - 1)
print(numbers)
- 가장 오른쪽 값이 피벗이 된다.
- 정렬된 리스트가 입력으로 들어오면
O(n^2)시간 복잡도를 갖게 된다.
- 랜덤 인덱스 값을 피벗으로 설정함으로써 이를 해결할 수 있다.
import random
def quick_sort(arr, start, end):
if end - start < 1:
return
rand = random.randrange(start, end + 1)
pivot = arr[rand]
arr[rand], arr[end] = arr[end], arr[rand] # 피벗을 랜덤으로 정한 뒤, 맨 끝으로 이동
left = start
right = end - 1
while True:
while arr[left] < pivot:
left += 1
while arr[right] > pivot:
right -= 1
if left >= right:
break
arr[left], arr[right] = arr[right], arr[left]
left += 1
right -= 1
arr[left], arr[end] = arr[end], arr[left]
quick_sort(arr, start, left - 1)
quick_sort(arr, left + 1, end)
numbers = [9, 4, -80, 1, 172, 13, 9, 39, -99, 2054, 10, -10, 3, 67, -28]
quick_sort(numbers, 0, len(numbers) - 1)
print(numbers)랜덤 피벗을 정함으로써, 퀵 정렬을 개선할 수 있다.
-
추가적인 메모리 공간을 필요로 하지 않는다.
-
불안정 정렬이다.
-
안정 정렬 : 중복된 값을 입력 순서와 동일하게 정렬한다.
-
불안정 정렬 : 중복된 값의 정렬이 입력 순서와 동일함을 보장하지 않는다.
-
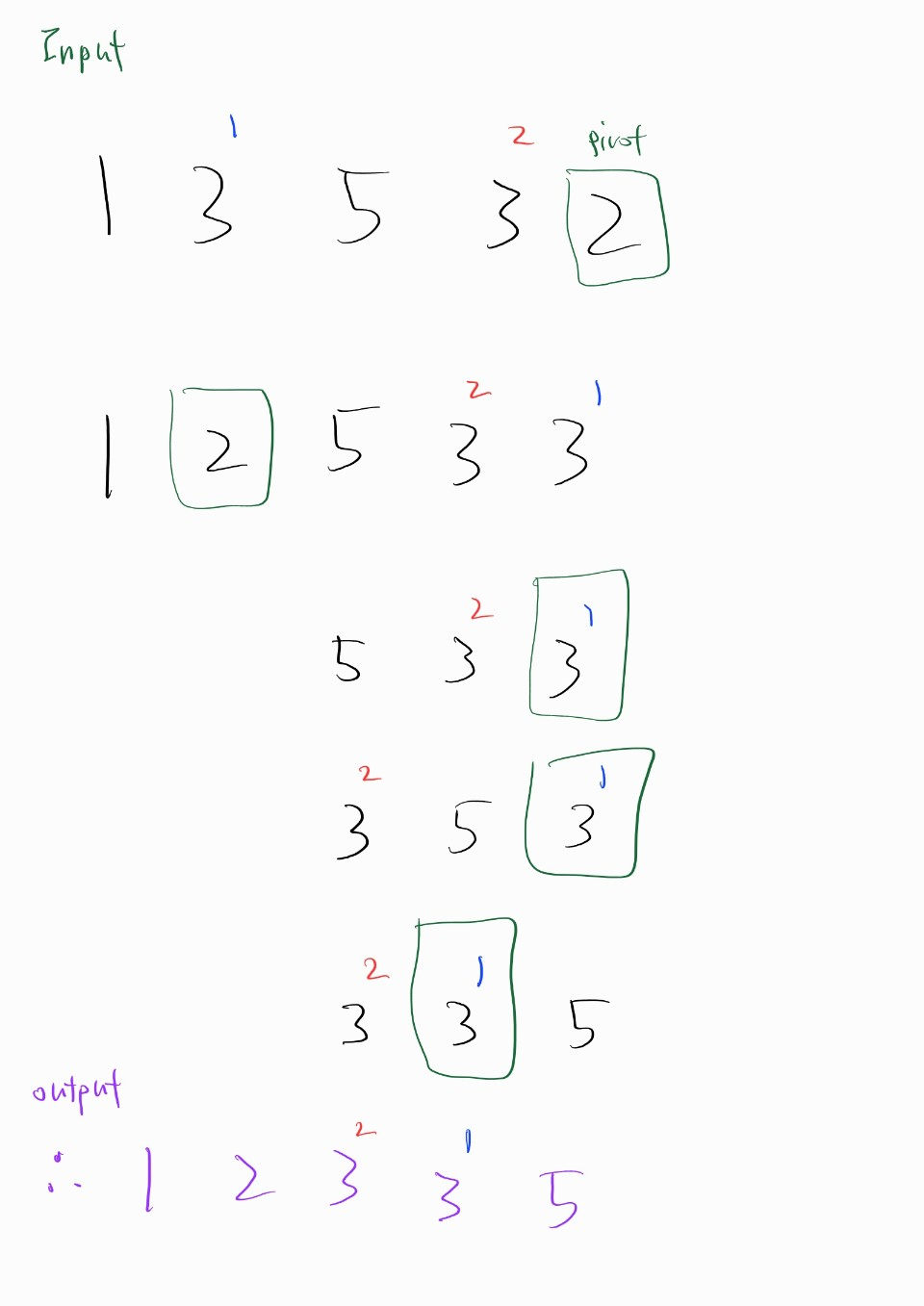
입력과 출력에서 3 이 처음의 입력순서를 유지하지 않음을 확인할 수 있다.
병합 정렬
-
더 이상 쪼갤 수 없을 때까지 분할한다.
-
분할이 끝나면 정렬하면서 정복한다.
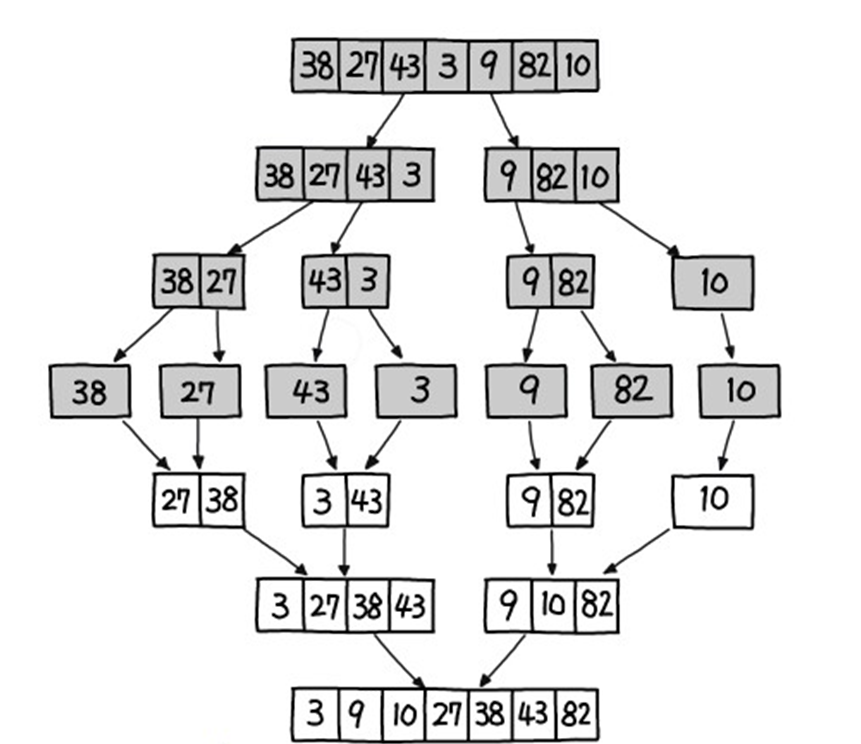
-
최선과 최악 모두
O(nlogn)이다. -
안정 정렬이다.
-
O(n)메모리가 추가적으로 필요하다.
def merge_sort(arr):
if len(arr) < 2: # 리스트 길이가 1 이하인 경우, 더 이상 쪼갤 수 없으므로 재귀 종료
return arr
mid = len(arr) // 2
left_arr = merge_sort(arr[:mid]) # 가운데를 기준으로 왼쪽 분할
right_arr = merge_sort(arr[mid:]) # 가운데를 기준으로 오른쪽 분할
sorted_list = []
left = right = 0
while left < len(left_arr) and right < len(right_arr): # 분할된 두 리스트를 정렬하며 합치기
if left_arr[left] < right_arr[right]:
sorted_list.append(left_arr[left])
left += 1
else:
sorted_list.append(right_arr[right])
right += 1
while left < len(left_arr):
sorted_list.append(left_arr[left])
left += 1
# sorted_list += left_arr[left:] 로 대체가능
while right < len(right_arr):
sorted_list.append(right_arr[right])
right += 1
# sorted_list += right_arr[right:] 로 대체가능
return sorted_list # 합쳐진 (정렬된) 리스트를 반환
numbers = [9, 4, -80, 1, 172, 13, 9, 39, -99, 2054, 10, -10, 3, 67, -28]
print(merge_sort(numbers))148번 문제, 리스트 정렬
-
링크드 리스트를 활용한 풀이
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def sortList(self, head: Optional[ListNode]) -> Optional[ListNode]:
if not (head and head.next):
return head
half, slow, fast = None, head, head # 주어진 리스트의 가운데 부분을 찾는 로직
while fast and fast.next:
half, slow, fast = slow, slow.next, fast.next.next
half.next = None # 가운데 부분을 끊어낸다.
l1 = self.sortList(head)
l2 = self.sortList(slow) # 분할
return self.mergeTwoLists(l1, l2) # 정렬하며 병합
def mergeTwoLists(self, l1, l2): # 정렬하며 병합한다.
if l1 and l2:
if l1.val > l2.val:
l1, l2 = l2, l1
l1.next = self.mergeTwoLists(l1.next, l2)
return l1 or l2 # 만약 l1을 다 붙여서 비어버리면, l2를 그대로 반환하여 l1의 꼬리에 l2를 붙인다.
- 병합정렬 사용
half는 첫 번째 링크드 리스트 묶음의 마지막 꼬리slow는 두 번째 링크드 리스트 묶음의 첫 번째 머리
179번 문제, 가장 큰 수
-
실패 이유: 구현 실패
class Solution:
def largestNumber(self, nums: List[int]) -> str:
def compare(n1, n2):
return str(n1) + str(n2) < str(n2) + str(n1) # 문자열의 크기 비교
for i in range(1, len(nums)):
j = i
fivot = nums[i]
while j > 0 and compare(nums[j-1], fivot):
nums[j] = nums[j-1]
j -= 1
nums[j] = fivot
return str(int(''.join(map(str, nums))))
insertion sort를 활용하여 풀이compare(n1, n2)메서드는 두 문자열의 순서에 따른 크기를 비교한다.- 두 수 중 큰 수를 나타내는 문자열이 되도록
insertion sort를 반복 수행하면, 종합적으로 가장 큰 수를 나타내는 문자열이 된다.
75번 문제, 색 정렬
-
네덜란드 국기 알고리즘을 사용하여 풀이
class Solution:
def sortColors(self, nums: List[int]) -> None:
"""
Do not return anything, modify nums in-place instead.
"""
start, mid, end = 0, 0, len(nums) - 1
while mid <= end:
if nums[mid] < 1:
nums[start], nums[mid] = nums[mid], nums[start]
mid += 1
start += 1
elif nums[mid] > 1:
nums[mid], nums[end] = nums[end], nums[mid]
end -= 1
else:
mid += 1
- 정렬할 요소가 3가지라면, 네덜란드 국기 알고리즘을 사용하여 정렬할 수 있다.
- 투 포인터에 가운데 포인터가 추가된 형태
start는 0에서 가장 가까운 1을 가리킨다.mid는 1을 가리킨다.end는 2를 가리킨다.mid위치가end를 넘을 경우 종료
이진 검색
-
Binary Search
-
정렬된 배열에서 타겟을 찾는 검색 알고리즘
-
배열의 요소들의 범위를 반씩 좁혀가며 타겟을 찾는다.
-
O(log n)시간 복잡도
class Solution:
def search(self, nums: List[int], target: int) -> int:
start = 0
end = len(nums) - 1
while start <= end: # start 가 end 를 넘어가면 종료
mid = (end + start) // 2
if nums[mid] < target: # mid 가 가리키는 값이 target 보다 큰 경우, 오른쪽 반으로 수색 범위를 줄인다.
start = mid + 1
elif nums[mid] > target: # mid 가 가리키는 값이 target 보다 작은 경우, 왼쪽 반으로 수색 범위를 줄인다.
end = mid - 1
else: # target 값을 찾은 경우
return mid
return -1 # target 값이 없는 경우이진 검색 알고리즘
33번 문제, 회전 정렬된 배열 검색
class Solution:
def search(self, nums: List[int], target: int) -> int:
def correct_nums(): # 돌아간 숫자 배열을 오름차순으로 정렬하고, 시작 지점의 실제 위치를 offset 으로 같이 반환
start = 0
end = len(nums) - 1
while start < end: # 같은 경우, 탈출해야 한다. <= 조건의 경우 start = end 에서 무한 반복한다.
mid = (start + end) // 2
if nums[mid] > nums[end]: # 만약 중간값이 맨 오른쪽값보다 크다면, 우측에 가장 작은 값이 있다.
start = mid + 1
else: # 만약 중간값이 맨 오른쪽값보다 작다면, 중간값을 포함한 좌측에 가장 작은값이 있다.
end = mid
return nums[start:] + nums[:start], start # 정렬된 배열과 가장 작은 값의 인덱스 위치를 offset으로 반환
def bin_search(target, offset): # 이진 검색 수행
start = 0
end = len(nums) - 1
while start <= end:
mid = (start + end) // 2
if nums[mid] > target:
end = mid - 1
elif nums[mid] < target:
start = mid + 1
else:
return (offset + mid) % len(nums) # 현재 인덱스 값에 offset 값을 더해주어야 실제 돌아간 배열에서의 target 위치가 나온다.
return -1
nums, offset = correct_nums()
return bin_search(target, offset)
correct_nums()메서드는 가장 작은 값을 이진 검색으로 찾고, 다시 정렬된 리스트와 가장 작은 값의 위치값을 반환한다.
- 가장 작은 값의 위치값은
offset으로 사용된다.bin_search()메서드는 이진 검색을 수행하여target의 위치를 찾는다.
- 실제 찾은
target인덱스에offset을 더해주어야 돌아간 리스트에서의 실제 위치이다.
240번 문제, 2D 행렬 검색 2
-
https://leetcode.com/problems/search-in-rotated-sorted-array/
-
이진 검색을 이용한 풀이O(n logn)시간 복잡도
class Solution:
def searchMatrix(self, matrix: List[List[int]], target: int) -> bool:
def bin_search(nums: list, target: int):
start, end = 0, len(nums) - 1
while start <= end:
mid = (start + end) // 2
if nums[mid] > target:
end = mid - 1
elif nums[mid] < target:
start = mid + 1
else:
return True
return False
for row in matrix:
if bin_search(row, target):
return True
return False
matrix의 한 row 씩target을 찾는 이진 검색 수행
-
이진 검색 없이 풀이-
O(n)시간 복잡도 -
첫 행의 가장 오른쪽 값에서 부터 탐색을 시작한다.
matrix의 오른쪽 맨 위
-
class Solution:
def searchMatrix(self, matrix: List[List[int]], target: int) -> bool:
if not matrix:
return False
x = len(matrix[0]) - 1
y = 0
while x >= 0 and y < len(matrix):
if target == matrix[y][x]:
return True
elif target < matrix[y][x]: # target 보다 현재 값이 크면, 왼쪽으로 이동
x -= 1
elif target > matrix[y][x]: # target 보다 현재 값이 작으면, 아래쪽으로 이동
y += 1
return False최악의 경우가 왼쪽 아래끝으로 대각 이동을 하는 경우이므로
O(2n) = O(n)시간 복잡도이다.
비트 조작
파이썬의 진법 변환
bin(십진수)- 10진수 ➔ 2진수
bin(4) # 0b100
type(bin(4)) # <class 'str'>스트링으로 반환한다.
int(2진수 문자열, 2)- 2진수 ➔ 10진수
int('0b100', 2) # 4파이썬의 음수 표현
-
파이썬은 비트연산을 하기 전엔, 음수 값을 2의 보수 값으로 보여주지 않는다.
- 그냥 - 를 붙여 표현한다.
bin(-1) # -0b1
bin(-1 & 0xFF) # 0b11111111비트연산을 한 경우에만 (
bin(-1 & 0xFF)) 2의 보수 값을 보여준다.
-
파이썬의 2의 보수 (음수) 를 양수로 변환
-
~(양수) + 1 = (음수) -
양수 = ~((음수) - 1) -
그런데 파이썬의
~은 예상대로 동작하지 않는다.- 비트수가 정해져있지 않기 때문
ex) ~4 = -4 - 1 = -5
-
따라서 현재 비트들을 뒤집기 위해서는
~대신,111...1 마스크와xor을 수행하여 뒤집는다.
-
neg = (-1 & 0xFF) # -1 (2의 보수 표현, 0b11111111)
pos = 0xFF ^ (neg - 1) # 1 (0b00000001)371번 문제, 두 정수의 합
class Solution:
def getSum(self, a: int, b: int) -> int:
MASK = 0xFFFFFFFF
INT_MAX = 0x7FFFFFFF
sum = (a ^ b) & MASK # 두 수의 합
carry = ((a & b) << 1) & MASK # 두 수의 합에 의해 발생한 캐리
while carry != 0: # 캐리가 0이 될 때까지 반복
sum, carry = (sum ^ carry) & MASK, ((sum & carry) << 1) & MASK
if sum > INT_MAX: # 최상위 비트가 1이므로, sum 이 음수인 경우
sum = ~(sum ^ MASK) # ~ 을 두번한 것과 같은 맥락
return sum
- 파이썬에서 음수표현은 비트연산을 하기 전, 2의 보수가 아닌
-0bxx표현이므로, 모든 연산 결과값들은MASK와 비트 연산을 해주어야 한다.sum은 두 수의 합,carry는 두 수의 합에 의해 발생한 올림수이다.
sum = ~(sum ^ MASK)
- 파이썬은 최상위비트가 1이라고 음수처리해주지 않는다.
- 따라서
(sum ^ MASK)로 주어진 비트내에서~연산을 한번하고,- 실질적인
~연산을 다시 수행해서 파이썬에서의 음수로 변환한다.

393번 문제, UTF-8 검증
class Solution:
def validUtf8(self, data: List[int]) -> bool:
def check(size):
for i in range(start + 1, start + size + 1):
if i >= len(data) or (data[i] >> 6) != 0b10:
return False
return True
start = 0
while start < len(data):
first = data[start]
if (first >> 3) == 0b11110 and check(3):
start += 4
elif (first >> 4) == 0b1110 and check(2):
start += 3
elif (first >> 5) == 0b110 and check(1):
start += 2
elif (first >> 7) == 0:
start += 1
else:
return False
return True각 비트의 앞 부분을 검사하여, 몇 바이트짜리 UTF-8인지 확인하고, 그 뒤에 오는 비트들이 정상적인지 검증한다.
0b11110이렇게 문자열이 아닌 형식으로 표현하면, 정수 처리된다.
슬라이딩 윈도우
239번, 최대 슬라이딩 윈도우
class Solution:
def maxSlidingWindow(self, nums: List[int], k: int) -> List[int]:
result = []
window = deque()
for i in range(k): # 첫 번째 슬라이딩 윈도우 (시작 부분)
while window and nums[window[-1]] < nums[i]: # 만약 window의 마지막 값이 현재 값보다 작다면 pop
window.pop()
window.append(i) # window 에 현재 값을 넣는다.
result.append(nums[window[0]]) # window 에 가장 앞에 있는 값이 첫 번쨰 슬라이딩 윈도우의 최대값이므로, 결과 result에 추가
for i in range(k, len(nums)): # 첫 번째 이후 슬라이딩 윈도우
if window and window[0] < i - k + 1: # 만약 window 에 존재하는 가장 큰 값이 슬라이딩 윈도우를 벗어났다면 제거
window.popleft()
while window and nums[window[-1]] < nums[i]: # 만약 window의 마지막 값이 현재 값보다 작다면 pop
window.pop()
window.append(i) # window 에 현재 값을 넣는다.
result.append(nums[window[0]]) # 현재 슬라이딩 윈도우의 가장 큰 값을 result에 넣는다.
return result
window에는 현재 슬라이딩 윈도우의 큰 값이 0 인덱스에 위치하고, 가장 작은 값이 맨 뒤에 존재한다.
- 만약 현재 값이
window의 맨 뒤의 값보다 크다면 제거한뒤 현재값을 넣는다.
- 따라서
window에 존재하는 값들은 현재 값보다 크거나 같은 값들이다.if window and window[0] < i - k + 1:
- 만약
window의 가장 큰 값을 가리키는 인덱스가 슬라이딩 윈도우를 벗어났다면window에서 제거한다.
76번, 부분 문자열이 포함된 최소 윈도우
-
실패이유: 시간초과O(n)으로 풀어야 한다.
class Solution:
def minWindow(self, s: str, t: str) -> str:
need = collections.Counter(t)
missing = len(t)
left = start = end = 0
# 오른쪽 포인터 이동
for right, char in enumerate(s, 1): # right 인덱스가 1부터 시작하는 이유는 right - left 가 길이가 되도록 하기 위함이다.
missing -= need[char] > 0 # 현재 문자가 필요한 문자이고, 필요한 문자들이 남아있는 경우에만 missing 값을 1 감소
need[char] -= 1
# 필요 문자가 0이면 왼쪽 포인터 이동 판단
if missing == 0:
while need[s[left]] < 0: # missing 0을 유지하면서 left 증가
need[s[left]] += 1
left += 1
if not end or right - left <= end - start: # 처음 찾거나, 더 짧은 길이 발견
start, end = left, right
need[s[left]] += 1 # 이제 고의로 missing 을 만족하는 상태를 깨뜨리고, 다음 substring 을 찾는다.
missing += 1
left += 1
return s[start:end]
need: 필요한 문자열들의 개수를 카운터로 미리 만들어놓는다.
- 이후, 필요하지 않은 문자의 경우엔
need의 value에 음수가 기록되고,- 필요한 문자의 경우, 필요 개수를 만족하면
need의 value가 0이 된다.
- 필요 개수를 넘어가면
need의 value가 음수가 된다.missing이 0이 될 때까지right포인터를 이동- 만약
missing이 0이 되면left포인터를 이동한다.- 가장 짧은 길이의 투포인터가
start,end가 된다.right인덱스는 1부터 시작한다.
right-left가 길이가 되도록 하기 위함
424번, 가장 긴 반복 문자 대체
class Solution:
def characterReplacement(self, s: str, k: int) -> int:
left = right = 0
counts = collections.Counter()
for right in range(1, len(s) + 1): # right - left 가 길이가 되도록, right 는 1부터 시작한다.
counts[s[right - 1]] += 1 # 현재 문자를 카운팅
max_char_n = counts.most_common(1)[0][1] # 가장 많이 등장하는 문자 탐색
if right - left - max_char_n > k: # 길이 - 가장 많이 나온 문자열 > k (교체 가능 횟수) 일 시, 교체 가능 횟수를 초과하므로
counts[s[left]] -= 1 # left 포인터 한 칸 이동
left += 1
return right - left # right 과 left 는 최대길이에서 벌어지고, 만약 교체 횟수를 만족하지 않는 경우엔 left가 right와 함께 그냥 1씩 증가한다.
# 따라서 right 가 종료되는 시점에 right - left 가 문자열의 최대길이이다.
if right - left - max_char_n > k:
길이-가장 많이 나온 문자열>k는 교체 가능 횟수를 넘음을 의미한다.- 따라서 이 경우
left포인터도 한 칸 이동한다.right가 증가하면서 가능한 최대길이가 될 때까지left는 움직이지 않는다.
- 가능한 최대길이가 넘으면, 그땐
left도right와 함께 움직인다.- 만약 이전에 구한 최대길이를 넘는 최대길이가 이후에 나오지 않는다면,
left와right는right가len(s)까지 갈 때까지 함께 이동한다.- 따라서 마지막에
right-left가 최대길이이다.
그리디 알고리즘
-
눈 앞의 이익만을 좇는 알고리즘
- 로컬 최적해를 연속해서 찾는 것이 전역 최적해가 된다.
-
탐욕 선택 속성과 최적 부분 구조를 갖는 문제들이 그리디 알고리즘으로 잘 풀린다.
-
탐욕 선택 속성
- 앞의 선택이 이후 선택에 영향을 주지 않는 것
-
최적 부분 구조
- 문제의 최적 해결 방법이 부분 문제의 최적 해결 방법들의 합으로 구성되어 있다.
-
406번, 키에 따른 대기열 재구성
class Solution:
def reconstructQueue(self, people: List[List[int]]) -> List[List[int]]:
people.sort(key=lambda x:(-x[0], x[1])) # 키는 내림차순으로, 자신보다 크거나 같은 사람 수는 오름차순으로 정렬
ans = []
for person in people: # 키가 크고, 앞에 크거나 같은 사람 수가 적은 사람부터 차례로 삽입
ans.insert(person[1], person) # 자신보다 크거나 같은 사람 수가 삽입 인덱스가 된다.
return ans
given:[[7,0],[4,4],[7,1],[5,0],[6,1],[5,2]]sort 결과:[[7,0], [7,1], [6,1], [5,0], [5,2], [4,4]]
- 키가 크고, 상대적으로 앞에 크거나 같은 사람 수가 적은 사람이 앞에 위치한다.
- 앞에 크거나 같은 사람 수는 삽입 인덱스가 된다.
- 해당 번째에 집어 넣으면 앞에 해당 하는 사람 수가 존재하게 되니까 로컬 최적해에 해당한다.
리스트.insert(삽입할 인덱스, 삽입할 요소)
- 만약 해당 인덱스에 요소가 존재하면, 해당 요소를 뒤로 밀어낸다.
621번, 태스크 스케줄러
class Solution:
def leastInterval(self, tasks: List[str], n: int) -> int:
counter = collections.Counter(tasks)
ans = 0
while True:
sub_count = 0
for task, _ in counter.most_common(n+1): # 가장 오랜 시간이 걸리는 task 순으로 n+1개 가져온다.
sub_count += 1 # 실제 가져온 task 개수
ans += 1
counter[task] -= 1
counter += collections.Counter() # 빈 카운터를 더하면, 0 이하인 아이템들을 목록에서 제거한다.
if not counter: # 모든 작업 완료
break
ans += n + 1 - sub_count # 현재 가져온 task 들이 n+1 개 보다 작다면 idle 을 더해준다.
return ans
- 가장 오랜 시간이 걸리는
taskn+1개를 각n+1cycle 마다 구해서 작업을 반복한다.
- 그래야
idle을 최소화하며 작업을 수행할 수 있다.- 만약 가져온
task들이n+1개보다 작다면, 작은 만큼idle을 더해준다.counter += collections.Counter()
- 빈 카운터를 더하면, 0 이하인 아이템들이 목록에서 제거된다.
134번, 주유소
-
실패이유: 시간초과-
O(n^2)으로 풀면 시간초과 발생 -
O(n)으로 풀어야 한다.
-
class Solution:
def canCompleteCircuit(self, gas: List[int], cost: List[int]) -> int:
if sum(gas) < sum(cost): # 만약 비용의 총합이 주유량보다 크다면 모두 방문할 수 없다.
return -1
start = 0 # circuit 의 시작점
i = 0
fuel = 0
while i < len(gas): # 만약 현재 지점때문에 전체 방문을 할 수 없다면 현재 지점 다음부터 다시 검사한다.
if fuel + gas[i] - cost[i] < 0: # 방문할 수 없는 경우
start = i + 1
fuel = 0
else: # 방문할 수 있는 경우
fuel += gas[i] - cost[i]
i += 1
return start
- 원을 절대 돌 수 없는 경우
if sum(gas) < sum(cost):에 걸린다.- 원을 돌 수 있는 경우
if sum(gas) < sum(cost):를 통과하면, 무조건 정답이 1개 있다.- 따라서 현재 지점을 방문할 수 있는지 여부를 계속해서 체크한다.
- 방문할 수 없다면, 현재 지점의 다음 지점이 circuit의 시작점이 된다.
다이나믹 프로그래밍
-
최적 부분 구조 + 중복된 하위 문제 의 특징을 가진다.
-
최적 부분 구조
- 각각의 부분 문제의 해결 방법들의 합이, 전체 문제의 해결 방법이 된다.
-
중복된 하위 문제
-
큰 문제를 풀기 위해 동일한 하위 문제들이 발생한다.
-
따라서 중복된 하위 문제들의 정답을 저장 후, 큰 문제의 결과를 구할 때 사용한다.
-
-

-
그리디 알고리즘과의 차이점은
-
그리디 알고리즘은 항상 그 순간에 최적이라고 생각되는 것을 선택하면서 풀이하는데 반해
-
다이나믹 프로그래밍은 하위 문제들을 차례로 모두 풀이한다.
-
-
분할 정복 알고리즘과의 차이점은
-
분할 정복 알고리즘은 중복된 하위 문제들을 풀지 않는다.
-
다이나믹 프로그래밍은 중복된 하위 문제들을 푼다.
-

와 배운 거 까먹어도 이것만 보면 되겠다~!