문제 정의
dev 환경에서 SELECT DISTINCT + ORDER BY 쿼리 실행 시 오류 발생
운영 환경에서 정상적으로 동작하던 "암장 색상 조회 API"가 개발 환경에서는 다음과 같은 MySQL 오류를 발생시키며 실패했다
Expression #1 of ORDER BY clause is not in SELECT list; this is incompatible with DISTINCT해당 API 내부의 JPQL은 다음과 같은 형태였다:
SELECT DISTINCT c
FROM StoryEntity s
JOIN s.problems p
JOIN p.grade g
JOIN g.color c
WHERE s.userId = :userId
AND (:cursor IS NULL OR c.id < :cursor)
ORDER BY g.id DESC처음에는 MySQL 버전 차이에 따른 호환성 문제를 의심했다.
문제 진단
문제 진단 과정: 버전 차이일까?
문제 발생 직후 가장 먼저 떠올린 가설은 MySQL 버전 차이였다.
MySQL 5.7부터 ONLY_FULL_GROUP_BY가 기본으로 활성화되므로, 개발 환경이 8.x 버전이라 해당 모드가 켜져 있고, 운영 환경은 5.6 이하라 꺼져 있을 것이라 판단했다.
이를 확인하기 위해 각 환경에서 다음 쿼리로 버전을 조회했다:
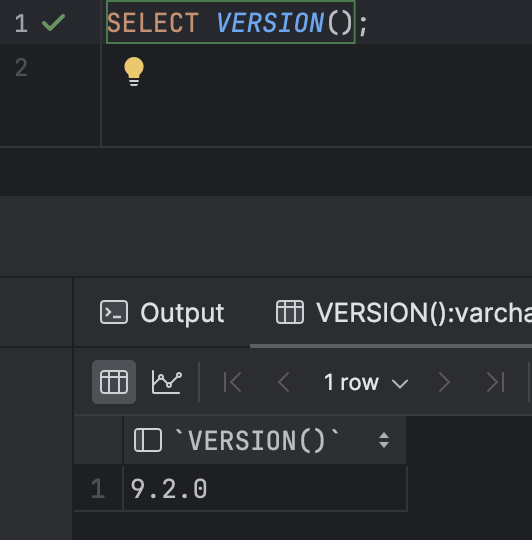
SELECT VERSION();- 개발 환경(dev):
9.2.0
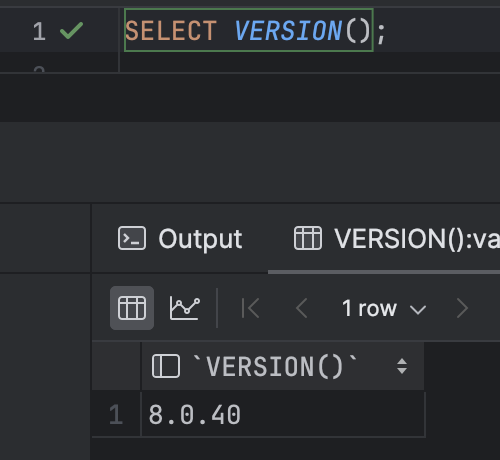
- 운영 환경(prod):
8.0.40
버전 차이는 없었다.
운영 서버도 MySQL 8.x를 사용 중이라는 점에서, 단순히 "버전 차이"만으로는 쿼리 실패를 설명할 수 없었다.
따라서, 문제의 원인은 버전이 아닌 다른 설정 차이일 가능성을 고려해야 했다.
→ 이후 SQL 모드 설정을 확인한 결과, ONLY_FULL_GROUP_BY의 활성 여부가 문제의 핵심임을 파악했다.
문제 원인: SQL 모드 ONLY_FULL_GROUP_BY의 차이
MySQL 5.7 이상부터는 ONLY_FULL_GROUP_BY 모드가 기본으로 활성화되어 있다. 이 모드는 SELECT DISTINCT 구문이 ORDER BY 대상 컬럼을 SELECT 목록에 포함하지 않으면 오류를 발생시킨다.
두 환경의 SQL 모드 차이는 다음과 같았다:
- dev 환경 (9.2.0)
ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION
- prod 환경 (8.0.40)
STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION
즉, 운영 서버에서는 ONLY_FULL_GROUP_BY가 꺼져 있어서 쿼리가 통과됐고, 개발 서버에서는 해당 모드가 켜져 있어서 오류가 발생했다.
실제로 dev SQL 모드를 prod환경과 동일하게 변경하니 문제가 해결되었다.
해결 방법
쿼리 리팩토링으로 SQL 모드에 독립적인 방식 적용
일단 dev SQL 모드에 ONLY_FULL_GROUP_BY를 끄니 동작은 하지만, 보다 안전하고 범용적으로 작동하도록 쿼리를 수정하도록 하자.
쿼리 수정
SELECT c.id, MAX(g.id) as maxGradeId
FROM StoryEntity s
JOIN s.problems p
JOIN p.grade g
JOIN g.color c
WHERE s.userId = :userId
AND (:cursor IS NULL OR c.id < :cursor)
GROUP BY c.id
ORDER BY maxGradeId DESCDISTINCT→GROUP BY대체ORDER BY g.id→ORDER BY MAX(g.id)로 정렬 컬럼 변경
이 방식은 ONLY_FULL_GROUP_BY가 켜져 있어도 무조건 통과된다.
교훈...
1. SQL 모드는 단순한 옵션이 아니다.
ONLY_FULL_GROUP_BY처럼 SQL 모드는 쿼리 실행 방식 자체를 바꾼다. 단순히 문법 문제가 아니라 데이터 정확성과 연관된 정책이기 때문에, 환경마다 동작이 달라질 수 있다.- 특히
DISTINCT,GROUP BY,ORDER BY,HAVING같이 집계와 정렬이 엮인 쿼리는 모드 설정에 매우 민감하다.
2. dev/prod 환경은 DB 설정까지 동일하게 맞추자. 제발!!
- 버전만 같다고 끝이 아니다.
@@sql_mode,collation,character_set,time_zone,innodb_strict_mode같은 설정 차이도 오류 유발 요소다.
3. 쿼리는 명확하게 작성하자.
-
DISTINCT + ORDER BY는 해석이 모호할 수 있다. 그럴 땐GROUP BY + 집계 함수(MAX, MIN, ANY_VALUE)구조로 명시적으로 처리하는 게 가장 안전하다. -
쿼리는 되도록 "명확하게 읽히도록" 작성해야 하며, DBMS의 내부 최적화에 의존하는 방식은 위험하다.
