📌 Java Persistence Framework란 무엇인가?
Java Persistence Framework는 데이터를 영속적으로 관리하는 역할을 한다.
이를 이해하기 위해 먼저 Persistence와 Persistence Framework가 무엇인지, 그리고 그 배경에 있는 Layered Architecture 개념을 알아보자.
📌 Persistence(영속성)이란?
Persistence는 프로그램이 종료되더라도 사라지지 않고 유지되는 데이터의 특성을 의미한다.
쉽게 말해, 휘발되지 않고 저장소에 계속 남아있는 데이터를 가리킨다.
ex) 파일 시스템, 데이터베이스 등에 저장된 데이터
이러한 데이터를 다루기 위해 우리는 Persistence Layer를 사용한다.
Persistence Layer는 데이터를 영속적으로 저장, 관리하는 계층이다.
하지만 이를 직접 구현하려면 JDBC 같은 복잡한 기술을 사용해야 한다.
💡 이러한 복잡함을 해결하고 개발을 더 쉽게 하기 위해 등장한 것이 바로 Persistence Framework다.
📌 Persistence Framework란?
Persistence Framework는 데이터를 영속적으로 다루는 작업을 쉽게 하기 위해 등장한 프레임워크다.
JDBC 프로그래밍의 복잡함을 피하고, 더 간단하고 빠르게 데이터베이스와 연동하는 시스템을 개발할 수 있도록 돕는다.
내부적으로는 JDBC API를 사용하지만, 더 간단한 방법으로 데이터베이스와 상호작용할 수 있다.
📃 Persistence Framework는 두 가지로 구분된다:
- SQL Mapper
- ORM (Object-Relational Mapping)
이 두 가지 방식의 차이점과 특성에 대해 아래에서 살펴보자.
📌 SQL Mapper vs ORM
SQL Mapper
- SQL 문장과 객체 필드를 매핑하는 방식이다.
- SQL을 명시적으로 작성하여 데이터베이스 데이터를 다룬다.
- 데이터를 처리할 때마다 SQL을 작성해야 한다.
ex) MyBatis, JdbcTemplate.
ORM (Object-Relational Mapping)
- 데이터베이스의 테이블과 객체를 매핑한다.
- 객체 간의 관계를 기반으로 SQL을 자동 생성한다.
- 객체를 이용해 데이터베이스를 간접적으로 조작하며, SQL을 직접 작성하지 않아도 된다.
- 관계형 데이터베이스의 관계를 객체 모델에 반영하는 것이 목적이다.
ex) JPA, Hibernate.
SQL Mapper vs ORM 요약
ORM은 객체와 관계형 데이터베이스 간의 관계를 자동으로 처리해주는 반면, SQL Mapper는 SQL 문장을 직접 작성하여 매핑한다.
ORM은 직관적인 코드로 데이터베이스를 조작할 수 있어 생산성이 높지만, SQL Mapper는 더 세밀하게 제어할 수 있다는 차이가 있다.
📌 Layered Architecture
이제 Persistence Framework가 등장하는 배경인 Layered Architecture를 이해해 보자.
Layered Architecture는 소프트웨어 개발에서 자주 사용되는 구조로, 관심사의 분리를 통해 시스템을 계층화한다.
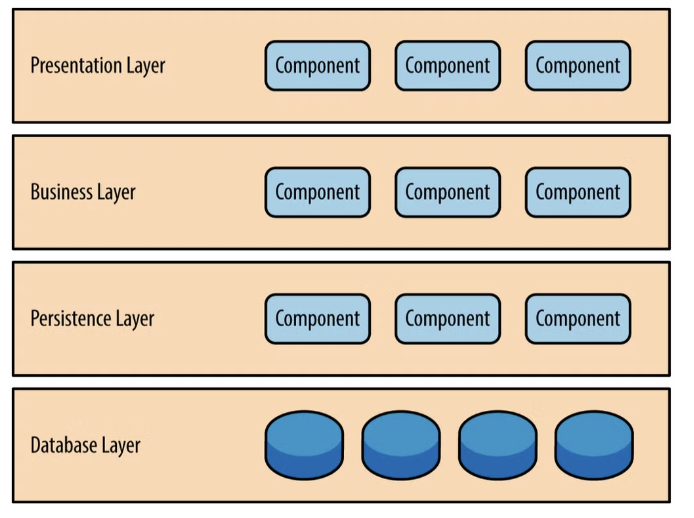
4-Tier Layered Architecture
Persistence Framework를 이해하려면 4-Tier Layered Architecture를 알아두면 좋다.
이 구조에서 가장 하단에 위치한 Database Layer에 영속성을 부여하는 것이 Persistence Layer이며, 이 Persistence Layer에 속하는 도구가 Persistence Framework다.
💡 Layered Architecture 요약
각 계층이 특정 역할만을 수행하도록 설계되어 응집도는 높이고, 결합도는 낮추는 구조를 만든다.
이로 인해 각 계층을 독립적으로 개발하고 유지보수하기 쉬우며, 테스트도 간편해진다.
📌 Java Persistence Framework의 장점
Java에서 Persistence Framework는 데이터베이스와의 연동을 단순화하고, 영속성을 관리하는 데 핵심적인 역할을 한다.
즉,
- 데이터베이스 관련 작업의 복잡성을 줄일 수 있고,
- 코드의 유지보수성이 높아지며,
- 객체 중심의 데이터베이스 관리가 가능하다.
