ViT: 이미지 분할(patch)부터 Transformer 적용까지 — 논문 리딩 노트
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
이 글은 ViT 원본 논문을 읽고 핵심 아이디어, 아키텍처, 실험결과, 구현/재현 계획을 정리한 글입니다.
컴퓨터 비전 연구실에서 첫 논문 읽기..
시작합니다😇
해당 논문 정리본들-논문 읽으며 함께 읽고 참고함
1. Transformer와 Self-Attention
ViT의 핵심은 이미지를 “단어 시퀀스”처럼 보고 Transformer를 적용한다는 점입니다.
1.1 Self-Attention 개념
Attention이란 문맥에 따라 집중할 단어를 결정하는 방식을 의미합니다.
아이디어: 입력 토큰(단어/이미지 패치)들이 서로의 중요도를 계산해 정보를 섞는 방법.
🧐 예시
“고양이가 잔다” → “고양이”와 “잔다”는 강하게 연결, “고양이”와 “가”는 약하게 연결.
이미지에서는 각 패치가 다른 패치의 특징을 참고해 더 풍부한 표현을 만든다고 보면 됩니다.
1.2 동작 원리
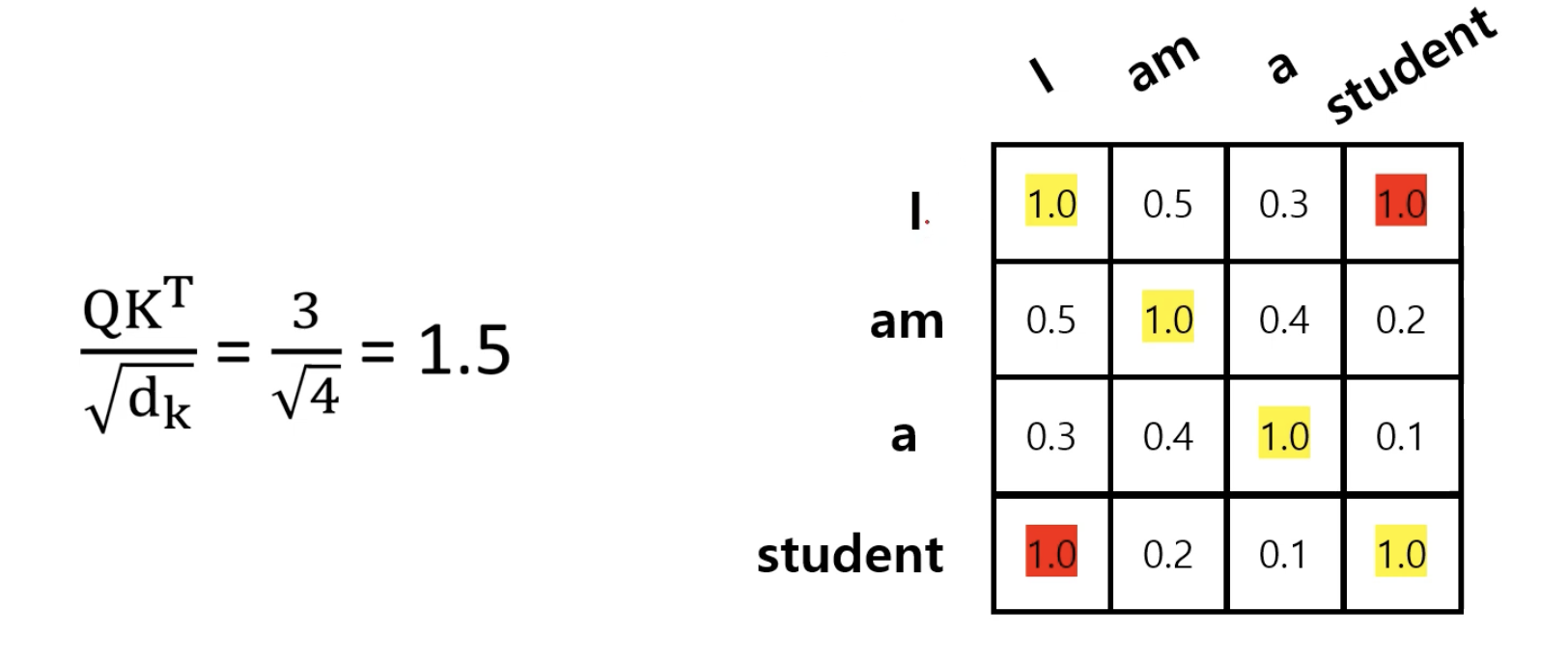
입력 토큰 → Query(Q), Key(K), Value(V) 3개 벡터로 변환
유사도 계산
Attention Score = Q × Kᵀ (내적)
→ 얼마나 관련 있는지 측정
정규화: Softmax로 중요도 비율화
정보 합치기: 중요도 × Value(V) → 새로운 토큰 표현
💡 장점: CNN처럼 국소적인 영역만 보는 게 아니라, 이미지 전체에서 장거리 의존성(long-range dependency)를 한 번에 파악 가능.
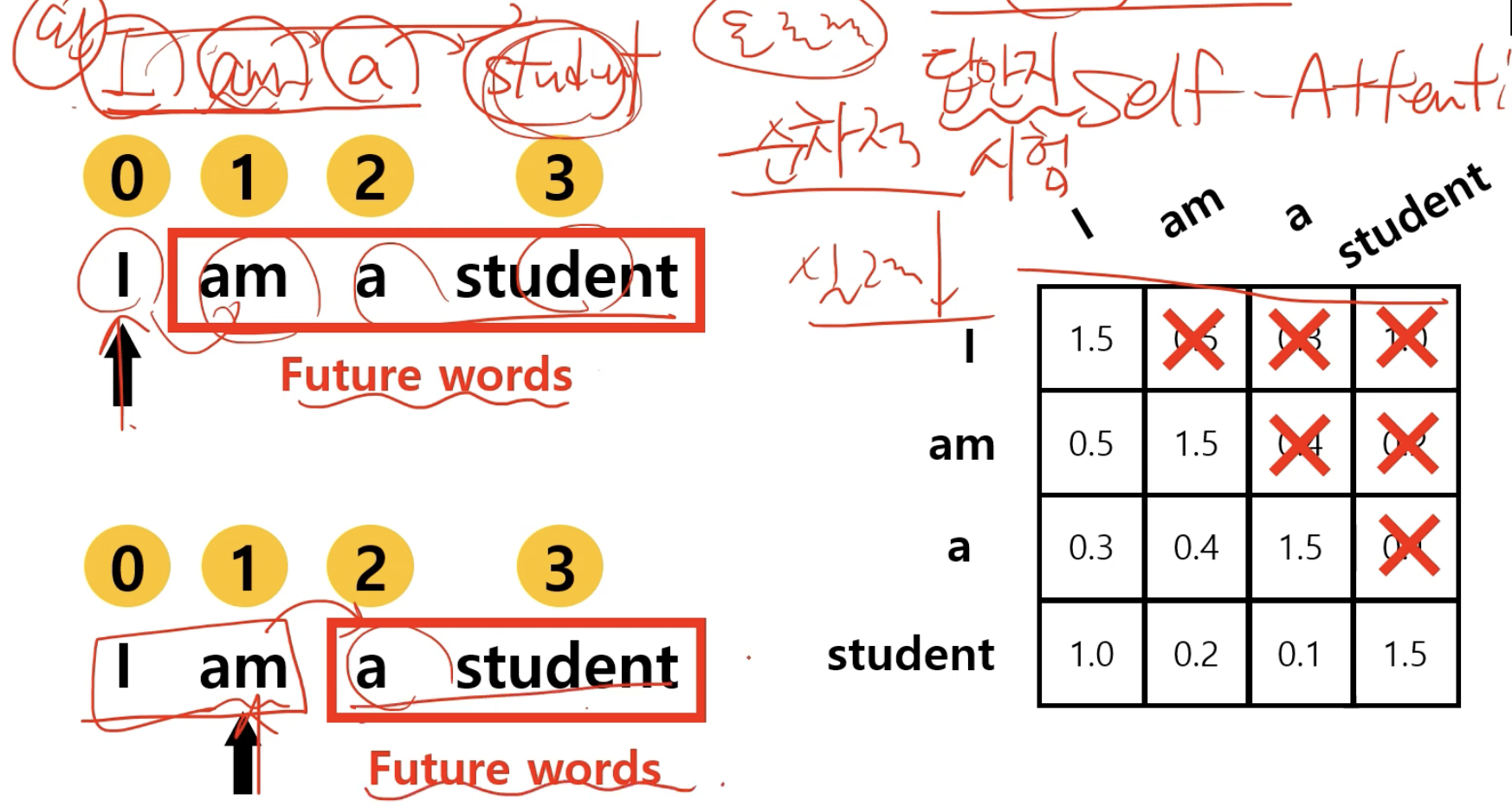
Self-attantion
masked multi head attantion
2) Position Encording(위치 정보 인코딩)
Transformer 는 토큰 순서를 모르는 구조라서 위치 정보를 따로 넣어줘야 합니다.
2.1 왜 필요한가?
이미지 패치 순서가 바뀌면 의미가 달라집니다.
🧐 얼굴 사진 → 눈이 아래쪽에 오면 이상함!
Self-Attention만 쓰면 순서 무시 → 구조적 의미 사라짐.
2.2 종류
1) Sinusoidal Encoding (고정형)
수학적 사인/코사인 패턴으로 위치를 표현
모든 위치의 상대적 차이를 모델이 유추 가능
2) Learnable Position Embedding (학습형) ← ViT 사용
위치를 나타내는 벡터를 모델이 직접 학습
패치 순서에 따라 고유한 위치 벡터를 추가
🧐 모델이 스스로 “위쪽 패치는 이런 느낌, 아래쪽 패치는 저런 느낌”을 학습하는 것.
💡 ViT에서는 각 패치에 Patch Embedding + Position Embedding을 더해 Transformer로 보냄.
3) CNN
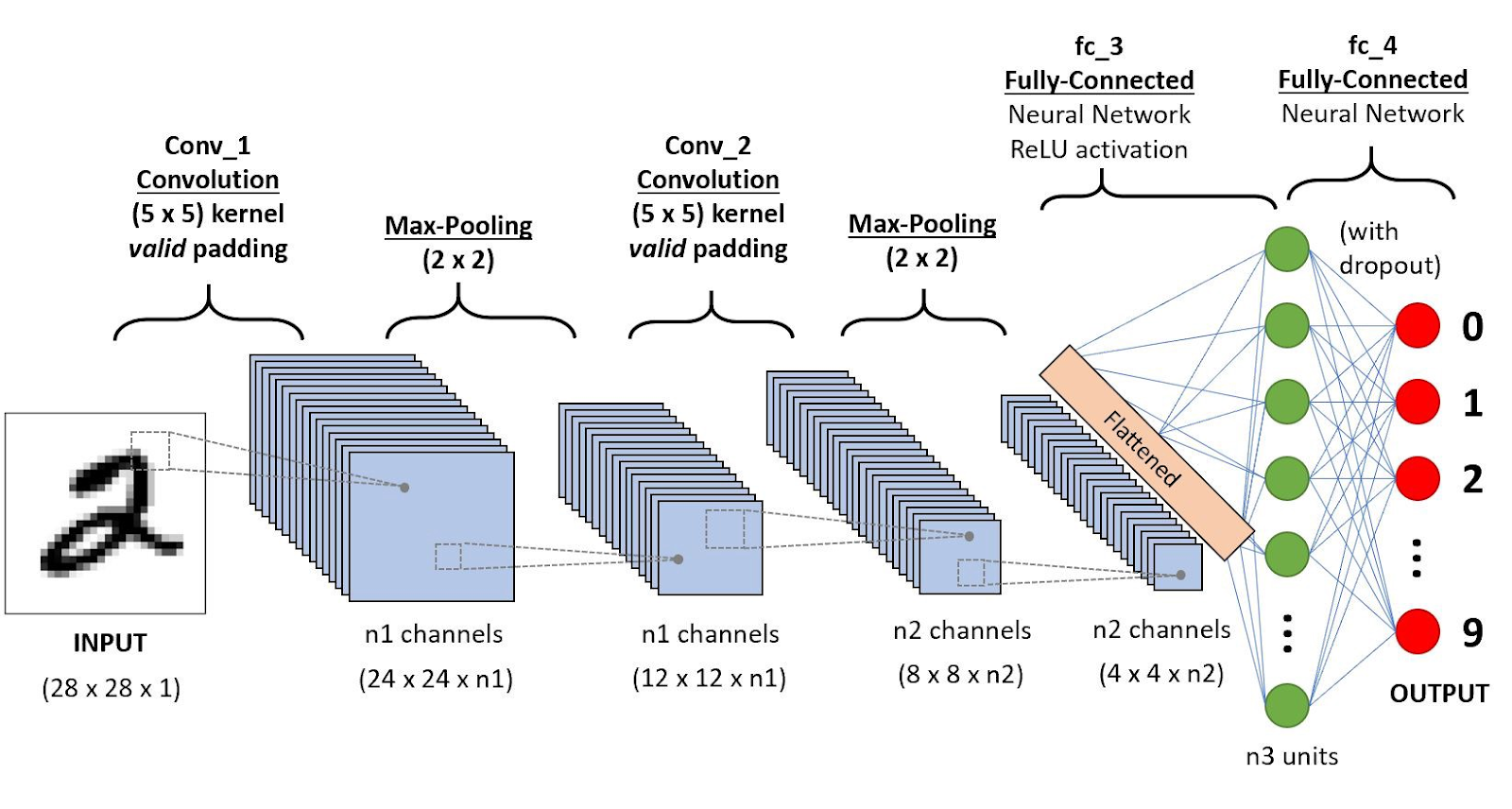
3.1 CNN 핵심 아이디어
Conv 연산: 작은 필터(커널)로 이미지를 조금씩 훑으며 특징 추출
지역적 패턴 인식(Locality)에 강함
예: 고양이 귀, 눈, 코 → 점점 합쳐서 “고양이” 판단
공간적 구조 보존: 이미지 형태 유지
3.2 CNN의 장점
Inductive Bias
근처 픽셀끼리 더 관련 있다는 전제(Locality)
패턴이 이미지 어디에 있든 동일하게 인식(Translation Invariance)
이미지 처리에 최적화되어 학습 데이터가 적어도 잘 작동
3.3 CNN의 한계
장거리 의존성(Long-range relationship)을 잡기 어려움
→ 이미지의 멀리 떨어진 부분을 연결해 이해하는 데 제한
깊어질수록 receptive field 넓어지지만, 정보 손실 가능
receptive field인공 신경망에서 특정 뉴런이 입력 데이터의 어느 영역에 영향을 받는지 나타내는 공간적인 범위
💡 ViT는 CNN의 이런 한계를 Self-Attention으로 보완
→ 한 번의 Attention에서 전역 정보(Global context) 참조 가능
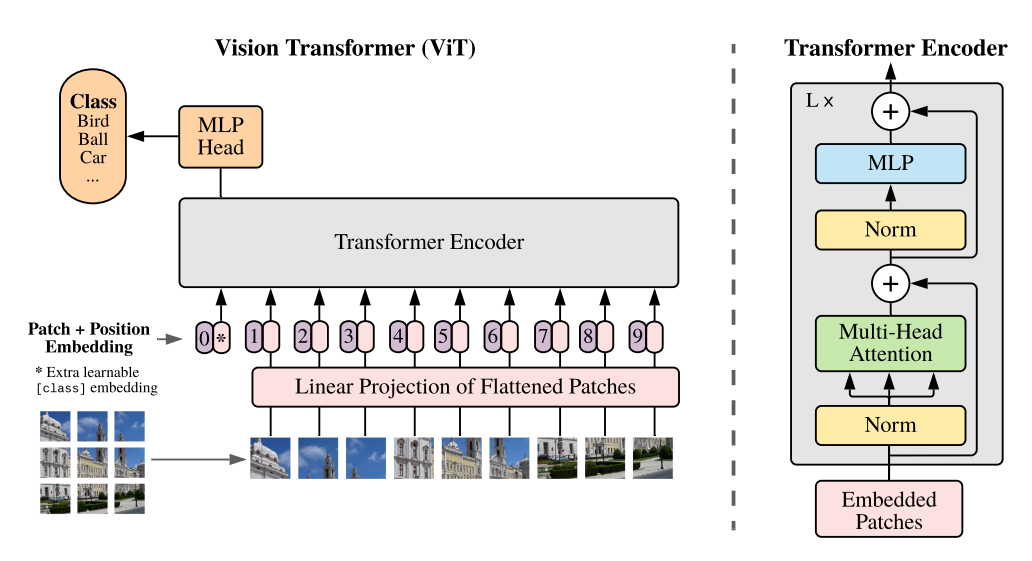
4. ViT에서 이 개념들이 어떻게 쓰일까?
이미지
→ 16×16 패치로 자르기
→ 각 패치를 벡터로 변환 (Patch Embedding)
→ 위치 정보 더하기 (Position Embedding)
→ Transformer Encoder(Self-Attention)로 패치 간 전역 정보 교환
→ [CLS] 토큰이 모든 정보 요약
→ MLP Head(분류기)에 넣어 최종 클래스 예측
📌 Patch Embedding (패치 임베딩)
문장에서 단어를 숫자로 바꾸는 과정과 비슷
각 패치(예: 16×16 픽셀)는 그냥 RGB 숫자 덩어리 → 이걸 하나의 고정 길이 벡터로 변환
방법: Linear Projection(일종의 곱셈 변환)
결과: "패치 A는 768차원 벡터, 패치 B도 768차원 벡터" 이런 식으로 맞춰줌.
📌 CLS 토큰
CLS = Classification Token
패치들과 똑같이 Transformer에 들어가지만, 오로지 분류 결과를 요약하기 위해 존재
비유: 회의에서 한 명이 모든 대화를 들으며 “결론 메모”만 하는 역할..
📌 MLP Head(분류기)
MLP = Multi-Layer Perceptron (다층 퍼셉트론)
Head = 모델 맨 마지막에 붙어서 최종 결과를 내는 부분
즉, MLP Head = 마지막 분류기 역할을 하는 작은 신경망
in ViT
[CLS] 토큰 → MLP Head → 최종 클래스 확률
Transformer Encoder가 만든 [CLS] 토큰에는 이미지 전체의 요약 정보가 들어있습니다.
MLP Head는 이 벡터를 받아서 "이건 고양이? 강아지?" 같은 최종 결정을 내립니다.
⁉️ 왜 MLP를 쓰나?
단순히 1개의 선형 레이어(Linear Layer)만 쓰면 모델이 복잡한 패턴을 잘 못 잡을 수 있음.
그래서 Linear → 활성화(ReLU) → Linear 같은 2~3층짜리 작은 신경망(MLP)을 붙여서,
더 비선형적인 분류 경계(Non-linear Decision Boundary)를 만들도록 함
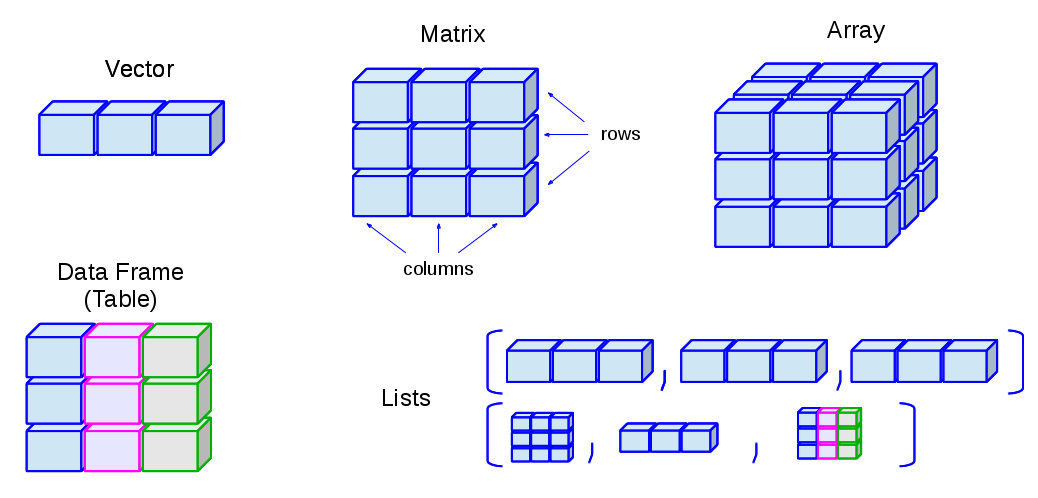
📌 차원별 데이터 구조
1차 선형 데이터 vector
2차 Matrix
3차 Array