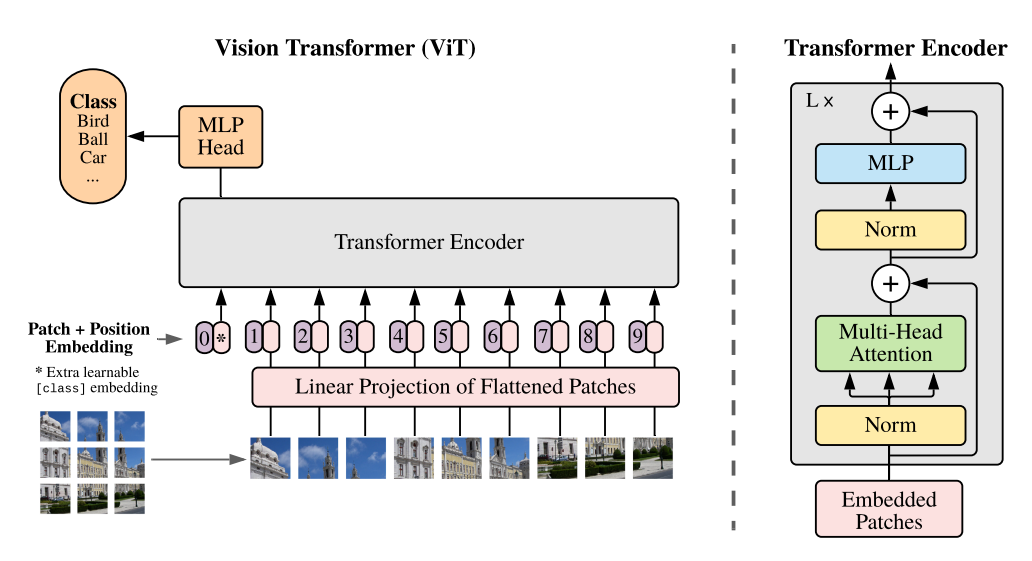
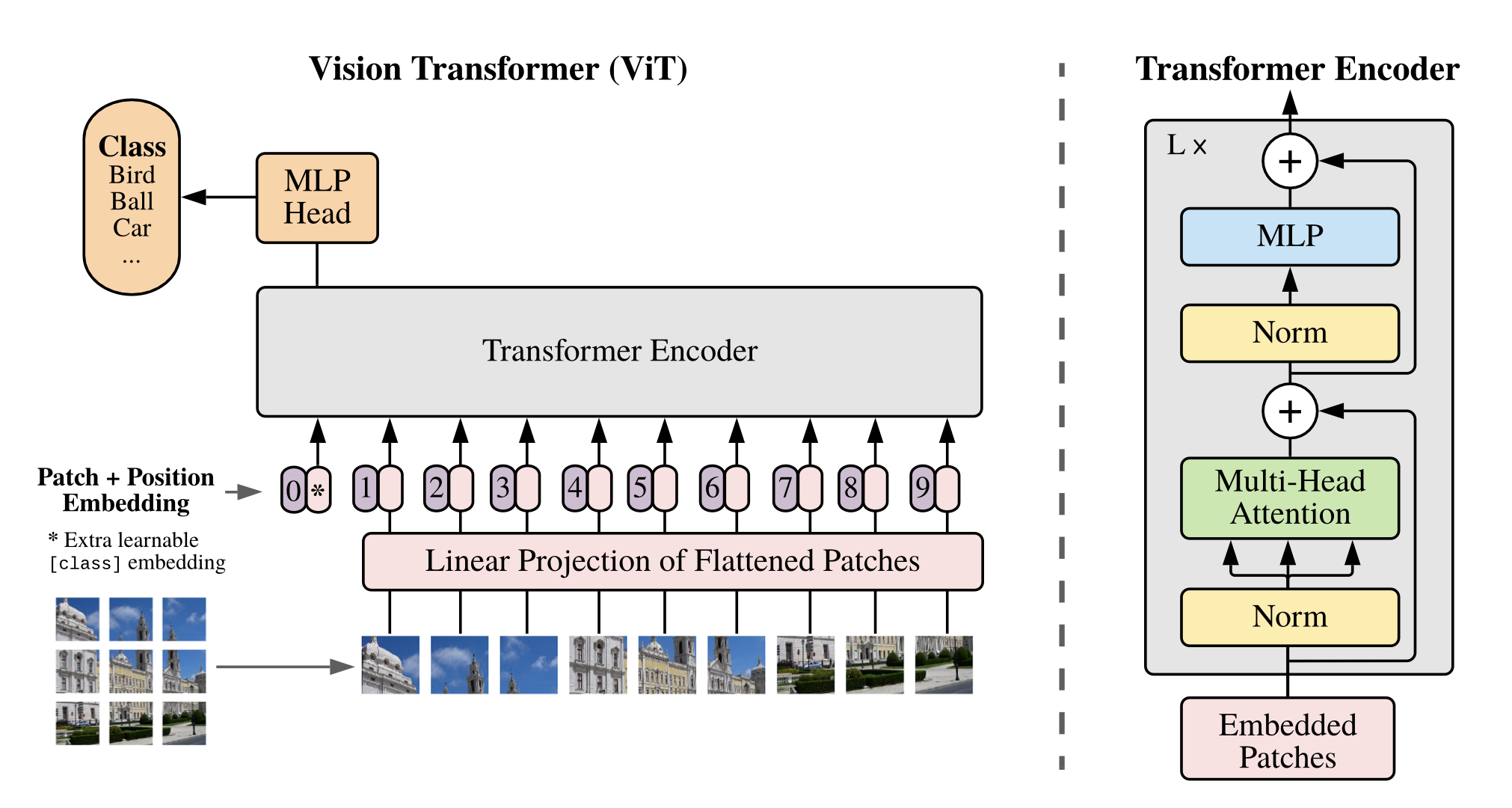
ViT 모델 구조
📌Positional Embedding
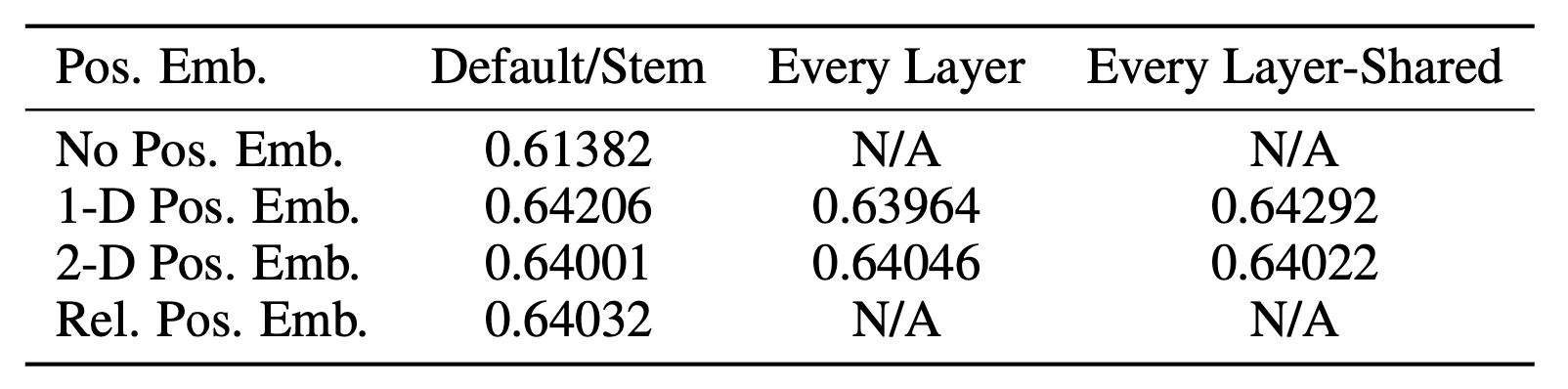
ViT에서는 아래 4가지 position 임베딩을 시도한 후 최종적으로 가장 효과가 좋은 1D position embedding을 ViT에 사용함
No pos Emb.(No positional Embedding)
patch 임베딩만 넣음. Position embedding 없이!
1-D Pos. Emb.(1 Dimension positional Embedding) 1차원.
1 2 3
4 5 6
7 8 9
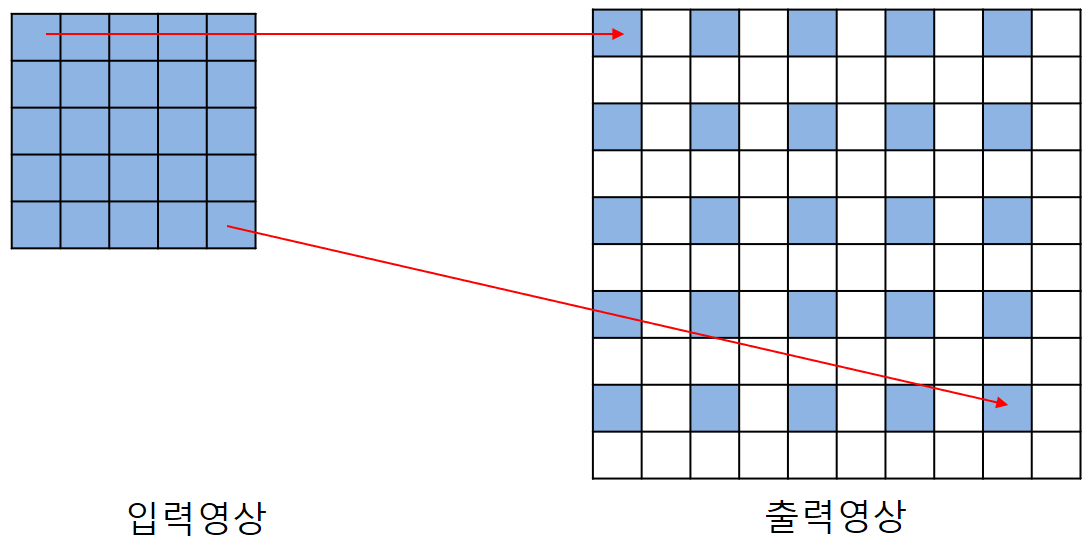
- Raster : 모니터, 카메라 센서, 이미지 처리에서 쓰이는 격자(grid) 방식
TV 화면이나 이미지가 왼쪽 위 → 오른쪽으로 한 줄씩 읽고 → 다시 다음 줄로 내려가는 방식으로 스캔되는 걸 말함
📍Raster order : 데이터를 이미지의 래스터 스캔 순서대로(위→아래, 왼→오) 처리하는 것
예: 픽셀을 저장할 때 (row, col) 순서대로 넣는 방식
비디오 인코딩이나 하드웨어 처리, 이미지 압축에서 자주 언급됨
2-D Pos. Emb.(2 Dimension positional Embedding) 2차원. x축 y축
(1,1) (1,2) (1,3)
(2,1) (2,2) (2,3)
(3,1) (3,2) (3,3)
Rel. Pos. Emb.(Relative Positional embedding)
패치들 사이의 상대적인 거리를 사용한 Positional embedding
총 4가지를 실행 했을 때, 1-d Pos.Emb.가 가장 좋은 성능을 내는 것을 확인.
📌Transformer Encoder
ViT는 Multi-Head Self-attention(MAS)와 MLP block으로 구성되어 있음
MLP는 2개의 layer를 가지며, GELU activation function을 사용함
각 block의 앞에는 Layer Norm(LN)을 적용하고, 각 block 뒤에는 residual connection을 적용함
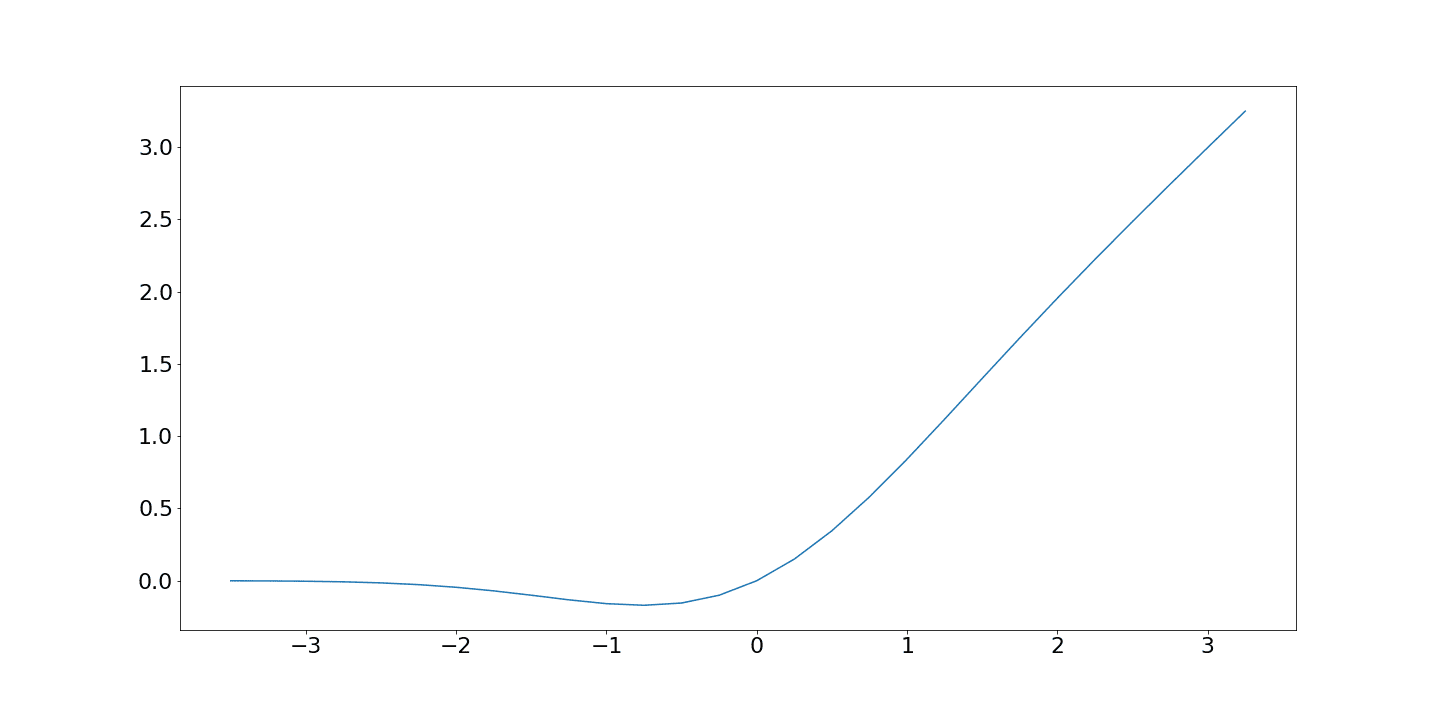
* GELU activation function
BERT, GPT, ViT 모델에서는 인코더 블락 안의 2-layer MLP 구조의 활성화 함수로 ReLU가 아닌 GELU (Gaussian Error Linear Unit) 함수가 사용된다
📍GELU : 입력값 x를 그대로 사용할지, 아니면 줄일지를 확률적으로 매끄럽게 조절하는 활성화 함수
GELU(x)=x⋅Φ(x)
ReLU: 음수면 0, 양수면 그대로 → 딱 잘라내는 방식 (hard gating)
Sigmoid: 0~1 사이 확률로 변환 → 모든 값이 부드럽게 스케일됨
GELU: 입력값이 음수냐 양수냐를 단순히 나누지 않고, 확률적으로 입력을 남길지 줄일지 결정
작은 음수는 약간만 죽이고, 큰 음수는 거의 0으로.
작은 양수는 약간만 통과시키고, 큰 양수는 거의 그대로 통과함!
그래서 학습 과정에서 더 매끄러운 gradient 흐름을 주어 성능이 좋아지는 경우가 많다
📍 *Layer Norm(LN)
Layer Norm: 각 training case별로 한 레이어의 모든 뉴런에 대한 summed input의 평균과 분산을 구해 정규화를 시키는 방법
| 구분 | Batch Normalization | Layer Normalization |
|---|---|---|
| 평균·분산 계산 단위 | 미니배치(batch) 단위에서 특성(feature) 별 | 한 데이터 샘플(sample) 단위에서 모든 feature |
| 적용하기 좋은 상황 | 이미지 처리 (CNN)처럼 배치 크기 크고 독립적인 데이터 | 시계열, RNN, Transformer처럼 순차적 데이터 |
| 공식 | (배치 평균) | (특정 샘플의 feature 평균) |
비유하면..
BN: 교실에서 "전체 학생"의 키 평균과 분산을 구해서, 학생 키를 정규화. → 전체 집단 기준.
LN: "한 학생"이 가진 과목별 점수(수학, 영어, 과학 등)의 평균과 분산을 구해서, 그 학생 점수를 정규화. → 개인 기준.
⁉️ Transformer에서는 LN이 더 적합할까?
RNN/Transformer에서는 입력이 시간 순서를 가진다.
BN은 "배치 단위 평균"을 쓰기 때문에 시점마다 분포가 달라지면 학습이 불안정해짐.
LN은 "각 시점, 각 샘플 독립적으로 정규화"하므로 시간적 일관성을 유지할 수 있음.
그래서 Transformer 구조에서 기본 normalization은 Layer Normalization임.
📌 Residual Connection(잔차 연결)이란?
Residual Connection: 입력을 그대로 다음 층에 더해주는 연결 방식
원래 입력(블록의 입력)과, 블록 내부 연산 결과(예: Multi-Head Attention의 출력)를 더해서 다음으로 넘김.
이렇게 하면 정보 손실을 줄이고, 기울기 소실(vanishing gradient) 문제를 완화할 수 있음
위의 내용의 transformer encoder를 식으로 변환하면 다음과 같음.
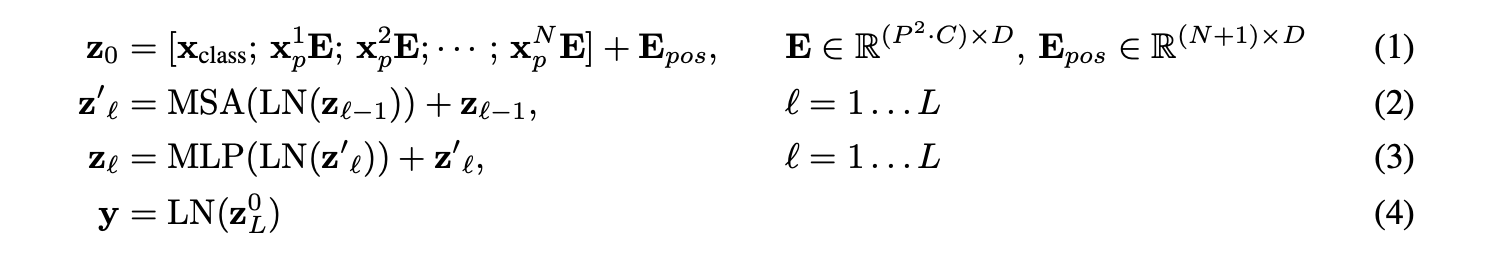
📌 Inductive Bias
MLP(Multi-Layer perceptron)은 locality와 translation equivariance가 있지만
MSA(Multi Self-attention)는 global하기 때문에 CNN보다 image-specific inductive bias가 낮음.
⁉️ locality / inductive bias가 낮음
CNN
locality(국소성): convolution은 작은 receptive field에서만 정보를 보니, 자연스럽게 "인접한 픽셀끼리 관련이 있다"라는 bias가 있음
translation equivariance(평행 이동에 불변 ): 이미지가 살짝 움직여도 동일한 특징을 잘 잡음ViT
MSA(Multi-Head Self Attention)는 global하게 모든 patch끼리 attention을 주고받을 수 있음
→ BUT! 강력하지만 이미지의 국소성이나 평행이동 불변성을 자동으로 가정하지 않음
따라서 CNN보다 image-specific inductive bias가 낮음 (이미지 특화된 규칙을 덜 가지고 있음 → 데이터가 많아야 성능이 잘 나옴)
ViT에서는 모델이 아래 두 가지 방법을 사용하여 inductive bias의 주입을 시도함
1) Patch extraction(locality 부여)
이미지를 잘게 잘라서 패치 단위 토큰으로 변환
각 패치를 하나의 "단어"처럼 처리 → 이는 "인접한 픽셀끼리 모아놓는다"라는 국소적 bias를 일부 제공
CNN처럼 convolution은 아니지만, 픽셀 단위가 아니라 patch 단위의 locality를 부여하는 셈
Resolution(해상도) adjustment(조정): adjusting the position embeddings for images of different resolution at fine-tuning
2) Resolution adjustment (position embedding 보정)
ViT는 patch 순서를 구분하기 위해 position embedding(위치 정보)을 추가함
그런데 학습할 때와 추론할 때 이미지 해상도가 다르면 → 패치 개수가 달라짐 → 위치 임베딩이 안 맞음
이를 해결하기 위해, 위치 임베딩을 interpolation(보간)해서 해상도 변화에도 대응할 수 있게 만듦
이렇게 하면 모델이 공간적 구조(이미지의 배치나 비율)를 더 잘 일반화할 수 있음
Translation invariance
번역 불변성(Translation invariance)은 어떤 함수의 입력이 공간적으로 이동(translation)해도 함수의 출력 결과가 변하지 않는 성질을 의미합니다. 다시 말해, 입력 데이터의 위치 변화에 관계없이 함수의 결과가 동일하게 유지되는 것을 뜻함
📌Hybrid Architecture
- Raw image가 아닌 CNN으로 추출한 raw image의 feature map을 활용하는 hybrid architecture로도 사용할 수 있음
- Feature map은 이미 raw image의 공간적 정보를 포함하고 있으므로
hybrid architecture는 패치 크기를 1x1로 설정해도 됨
-> 1x1 크기의 패치를 사용할 경우 feature map의 공간 차원을 flatten하여 각 vector에 linear projection을 적용하면 됨
📌Fine-tuning and Higher Resolution(어떻게 하면 pre-train데이터와 크기가 다른 데이터에 문제 없이 적용해 fine-tuning 할 수 있을까)
실제로 image reconization을 해야할 때>>
Large scale로 ViT를 pre-training한 후
-> 해당 모델을 downstream task에 fine-tuning하여 사용할 수 있음
-> ViT를 fine-tuning 할 때, ViT의 pre-trained prediction head를 zero-initalized feedforward layer로 대체함
-> pre-training과 동일한 패치의 크기를 사용하기 때문에 고해상도의 이미지로 (문제점!)fine-tuning하면 sequence 길이가 더 길어짐
ViT는 가변적 길이의 패치들을 처리할 수는 있지만
pre-trained position embedding은 의미가 사라지므로
-> pre-trained position embedding을 원본 이미지 위치에 따라 2D interpolation하여 사용함
Large-scale pre-training: 일반적인 feature 학습
Fine-tuning: downstream task에 맞춰 head 교체 + 추가 학습
고해상도 입력 문제: patch 개수가 늘어나면서 position embedding mismatch 발생
해결책: pre-trained position embedding을 2D interpolation으로 보정해서 사용!
이렇게 그냥 크기 키워서 그 위치에 맞는 Patch에 locality를 부여하는것!
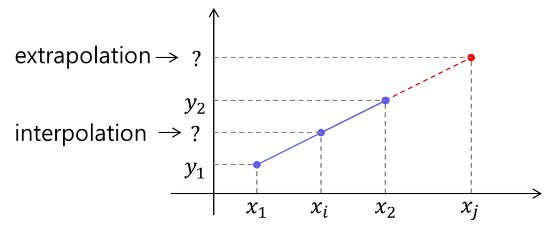
*Downstream task: 최종적으로 이루고자 하는 task
위의 내용을 더 풀어서 설명해보자.
1) Pre-training → Fine-tuning
Pre-training:
ViT는 보통 ImageNet-21k 같은 거대한 데이터셋에서 사전 학습(pre-training)함 → 일반적인 이미지 특징(feature)을 잘 배우도록.
Fine-tuning:
이후 우리가 원하는 특정 task (예: 고양이/강아지 분류, 의료 영상 인식 등)에 맞게 모델을 추가 학습시킴.
2) Prediction Head 교체
Pre-training 시 ViT는 거대한 데이터셋 클래스(예: 21k 클래스)에 맞춘 prediction head (classification layer)를 학습함.
Downstream task에서는 class 개수가 달라짐 (e.g. "고양이 vs 강아지"는 2개만 필요).
따라서 Fine-tuning 시에는
Pre-trained head 버리고
새로운 Feedforward Layer (zero-initialized)를 붙여서 학습시킴.
👉 이렇게 해야 task에 맞는 새로운 분류기로 학습 가능.
3) Patch 크기와 해상도의 문제
Pre-training 시 예를 들어:
224×224 이미지를 16×16 patch로 잘라 학습 → 총 14×14 = 196개 토큰
Fine-tuning 시 고해상도 이미지를 넣으면:
384×384 이미지를 동일한 patch 크기(16×16)로 자름 → 총 24×24 = 576개 토큰 (이러면 196개보다 훨씬 크죠?)
👉 즉, patch 크기는 그대로지만 sequence 길이가 훨씬 길어짐
(마치 문장에서 단어 개수가 갑자기 늘어난 것처럼 Transformer의 입력 길이가 늘어남)
4) 📍문제: Pre-trained Position Embedding 불일치
Pre-training 때 학습된 position embedding: [196 × D] (14×14 grid)
Fine-tuning 시 필요한 position embedding: [576 × D] (24×24 grid)
-> 이 경우 단순히 "붙여쓰기" 할 수 없음 → 의미가 깨짐
5) 📍해결: 2D Interpolation of Position Embeddings
Pre-trained 14×14 grid를 2D 공간으로 해석
이를 24×24 grid로 bilinear interpolation해서 확장
새로운 위치에 맞는 embedding을 자연스럽게 만들어낼 수 있음
👉 이렇게 하면
기존 학습된 "위치 정보"를 최대한 보존하면서
고해상도 입력(더 많은 patch)에도 대응이 가능해짐!
Zero-initialized: 딥러닝 모델의 가중치 초기화 방법 중 하나이고, 가중치와 편향값의 초기 값을 모두 0으로 설정한다
Bilinear Interpolation