깃헙 링크에서 자연어 전처리와 추론을 중점으로 정리한 글입니다. 깃헙의 목차를 따라가겠습니다
텍스트 요약
상대적으로 긴 문장으로 짧은 문장으로 변환하는 기법을 텍스트 요약이라고 합니다. Ex 10에서는 뉴스 요약을 해보겠습니다.
텍스트 요약에는 두 가지 방법, Extractive Summarization, Abstractive Summarization이 있습니다. Extractive의 경우 가장 의미있는 문장을 원문 안에서 추출해 내는 방식이고, Abstractive는 원문을 요약하는 새로운 문장을 만들어내는 방식입니다.
이 프로젝트에서는 원문과 그에 해당하는 요약문을 주고(지도학습) seq2seq와 Attention을 사용하여 원문 -> 요약문으로의 Abstractive Summarization을 실시하겠습니다. 이는 일반적인 번역과 매우 유사한 과정을 거치는 것입니다.
load data
import nltk
import numpy as np
import pandas as pd
import os
import re
import matplotlib.pyplot as plt
from nltk.corpus import stopwords
from bs4 import BeautifulSoup
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import urllib.request
urllib.request.urlretrieve("https://raw.githubusercontent.com/sunnysai12345/News_Summary/master/news_summary_more.csv", filename="news_summary_more.csv")
data = pd.read_csv('news_summary_more.csv', encoding='iso-8859-1')
data.rename(columns = {'text': 'Text', 'headlines': 'Summary'}, inplace = True)
# Text(원문)와 Summary(요약문)로 column name을 바꾸어줍니다.preprocess data (2)
자연어 데이터의 문제를 완화하는 전처리를 시도합니다. "you're"과 "you are "은 같은 말이고, "너는"과 "넌" 역시 같은 말입니다. 또한, '.........'과 '...............' 을 서로 다른 단어으로 생각할 것인지, '.'라는 단어가 여러 개 나열 된 것은 동일하지만 그 개수에서 차이를 보인다고 생각할 것인지에 대해 명확한 규정이 존재하지 않으므로, 어떤 판단기준으로 단어를 선정할 것인지는 엔지니어에 달려 있습니다. 모델이 학습할 때 혼란을 덜어줄 것 같은 전처리를 직관적이지만, 가장 효율적인지 알 수 없는(hueristic) 방법으로 진행하겠습니다.
1. 정규화
축약된 표현은 정규 표현으로 변환합니다.
# 정규화 사전 - 축약어를 분해할 때 사용합니다
contractions = {"ain't": "is not", "aren't": "are not","can't": "cannot", "'cause": "because", "could've": "could have", "couldn't": "could not",
"didn't": "did not", "doesn't": "does not", "don't": "do not", "hadn't": "had not", "hasn't": "has not", "haven't": "have not",
"he'd": "he would","he'll": "he will", "he's": "he is", "how'd": "how did", "how'd'y": "how do you", "how'll": "how will", "how's": "how is",
"I'd": "I would", "I'd've": "I would have", "I'll": "I will", "I'll've": "I will have","I'm": "I am", "I've": "I have", "i'd": "i would",
"i'd've": "i would have", "i'll": "i will", "i'll've": "i will have","i'm": "i am", "i've": "i have", "isn't": "is not", "it'd": "it would",
"it'd've": "it would have", "it'll": "it will", "it'll've": "it will have","it's": "it is", "let's": "let us", "ma'am": "madam",
"mayn't": "may not", "might've": "might have","mightn't": "might not","mightn't've": "might not have", "must've": "must have",
"mustn't": "must not", "mustn't've": "must not have", "needn't": "need not", "needn't've": "need not have","o'clock": "of the clock",
"oughtn't": "ought not", "oughtn't've": "ought not have", "shan't": "shall not", "sha'n't": "shall not", "shan't've": "shall not have",
"she'd": "she would", "she'd've": "she would have", "she'll": "she will", "she'll've": "she will have", "she's": "she is",
"should've": "should have", "shouldn't": "should not", "shouldn't've": "should not have", "so've": "so have","so's": "so as",
"this's": "this is","that'd": "that would", "that'd've": "that would have", "that's": "that is", "there'd": "there would",
"there'd've": "there would have", "there's": "there is", "here's": "here is","they'd": "they would", "they'd've": "they would have",
"they'll": "they will", "they'll've": "they will have", "they're": "they are", "they've": "they have", "to've": "to have",
"wasn't": "was not", "we'd": "we would", "we'd've": "we would have", "we'll": "we will", "we'll've": "we will have", "we're": "we are",
"we've": "we have", "weren't": "were not", "what'll": "what will", "what'll've": "what will have", "what're": "what are",
"what's": "what is", "what've": "what have", "when's": "when is", "when've": "when have", "where'd": "where did", "where's": "where is",
"where've": "where have", "who'll": "who will", "who'll've": "who will have", "who's": "who is", "who've": "who have",
"why's": "why is", "why've": "why have", "will've": "will have", "won't": "will not", "won't've": "will not have",
"would've": "would have", "wouldn't": "would not", "wouldn't've": "would not have", "y'all": "you all",
"y'all'd": "you all would","y'all'd've": "you all would have","y'all're": "you all are","y'all've": "you all have",
"you'd": "you would", "you'd've": "you would have", "you'll": "you will", "you'll've": "you will have",
"you're": "you are", "you've": "you have"}
print("정규화 사전의 수: ", len(contractions))2. 불용어
문맥에 관계없이 너무 자주 나오는 표현은 모델을 혼란시키지 않기 위해 훈련에 사용하지 않고 없는 단어로 처리합니다. 이때, nltk에서 주어진 불용어 중 뉴스의 의미를 파악하는 데 도움이 되는 단어는 훈련에서 사용하기 위해 불용어에서 제외시킵니다.
selection = ['but', 'no', 'not', 'nor', 'only', 'while', 'before', 'after', 'under', \
'again', 'further'] # 불용어에서 제외할 단어들
my_stopwords = list(
filter(lambda word: word not in selection,
stopwords.words('english')
)
)
>>> print('사용자화 불용어 개수: ', len(my_stopwords))
>>> print(my_stopwords)사용자화 불용어 개수: 168
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'if', 'or', 'because', 'as', 'until', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'in', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
3. 전처리 함수 preprocess_sentence()
불용어 처리와 정규화, 문장부호를 처리하는 함수입니다.
def preprocess_sentence(sentence, remove_stopwords=True):
sentence = sentence.lower() # 텍스트 소문자화
sentence = BeautifulSoup(sentence, "lxml").text # <br />, <a href = ...> 등의 html 태그 제거
sentence = re.sub(r'\([^)]*\)', '', sentence) # 괄호로 닫힌 문자열 (...) 제거 Ex) my husband (and myself!) for => my husband for
sentence = re.sub('"','', sentence) # 쌍따옴표 " 제거
sentence = ' '.join([contractions[t] if t in contractions else t for t in sentence.split(" ")]) # 약어 정규화
sentence = re.sub(r"'s\b","", sentence) # 소유격 제거. Ex) roland's -> roland
sentence = re.sub(r"[^a-zA-Z?]+", " ", sentence) # 영어 외 문자(숫자, 특수문자 등) 공백으로 변환
sentence = re.sub('[m]{3,}', 'm', sentence) # Ex) ummmmmmm yeah -> um mm yeah
sentence = re.sub('[o]{3,}', 'o', sentence)
####
sentence = re.sub(r'[?]{1,}', r' ?? ', sentence)
sentence = re.sub(r'[" "]+', r' ', sentence)
####
# 불용어 제거 (Text)
if remove_stopwords:
tokens = ' '.join(word for word in sentence.split() if not word in my_stopwords if len(word) > 1)
# 불용어 미제거 (Summary)
else:
tokens = ' '.join(word for word in sentence.split() if len(word) > 1)
return tokenspreprocess data (3)
Text column에는 preprocess_sentence()를 통과시킨 Text를 넣었습니다.
인공지능 모델에게 이 데이터를 먹이려면, 자연어 형태가 아닌 정수로 이루어진 numpy ndarray 형태로 바꾸어 주어야 합니다. ndarray는 모든 행의 차원(길이)가 같아야 하므로, 긴 문장이든 짧은 문장이든 특정한 길이로 바꿔주어야 합니다. 이때, 긴 문장의 경우 제외를 할 수도 있고, 앞이나 뒤를 잘라 특정 길이로 바꿔 줄 수도 있습니다. 짧은 문장의 경우에도, 제외를 하거나 앞 뒤에 의미없는 표시(padding)을 넣어줍니다
단어로 분해 후에는 각 단어를 출현 빈도순으로 정리하여 {단어: 출현 빈도 순위} 인 딕셔너리와 {출현 빈도 순위: 단어}인 딕셔너리를 만듭니다. 이때 출현한 모든 단어를 저장하는 대신, '사전'의 길이를 조정합니다. 이를 통해서 분해된 문장을 정수로 인코딩할 수 있습니다.
길이의 분포를 출력해봅니다
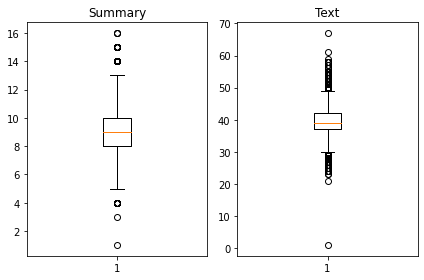
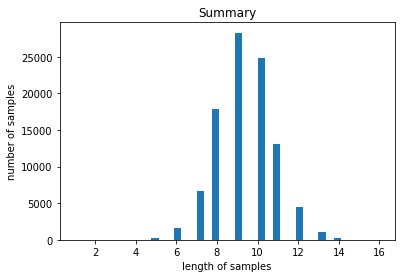
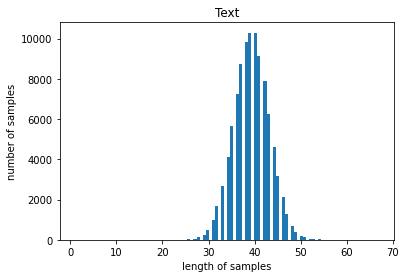
데이터의 분포가 넓게 퍼져있음을 알 수 있습니다. 이 프로젝트의 목표는 긍정/부정 분석이 아니고, 뉴스를 요약하는 것이며, 짧은 Text의 경우, padding을 pre로 주게 된다면, 해당 단어가 연이은 padding 뒤에 나와 그에 연관된 context vector가 희석 없이 decoder로 넘어가게 되어 오히려 너무 강한 영향력을 행사할 것 같습니다. 따라서 짧은 텍스트에서 얻을 수 있는 정보는 모두 긴 Text에서 충분히 얻을 수 있다고 가정하고 너무 짧거나 긴 Text를 갖는 데이터포인트를 제거하겠습니다
# 최소, 최대 사이에 있는 샘플을 골라 냅니다.
def bandpass_len(min_len, max_len, nested_list):
cnt = 0
for s in nested_list:
if(len(s.split()) <= max_len) and (len(s.split()) >= min_len):
cnt = cnt + 1
print(f'전체 샘플 중 길이가 {min_len} 이상,{max_len} 이하인 샘플의 비율:{cnt / len(nested_list)}')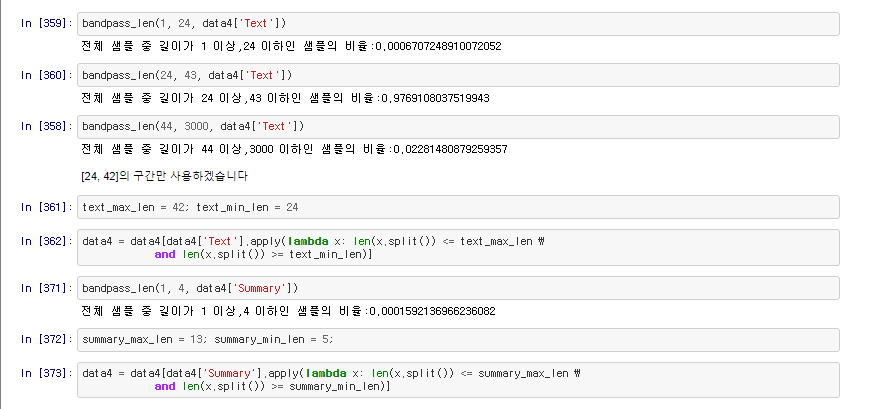
적절한 길이의 문장만 남깁니다.
Tokenize, Encode, Model, Train
LSTM 과 attention을 이용하여 훈련합니다.
Model: "model_17"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_21 (InputLayer) [(None, 42)] 0
__________________________________________________________________________________________________
embedding_8 (Embedding) (None, 42, 160) 2482240 input_21[0][0]
__________________________________________________________________________________________________
lstm_16 (LSTM) [(None, 42, 320), (N 615680 embedding_8[0][0]
__________________________________________________________________________________________________
input_22 (InputLayer) [(None, None)] 0
__________________________________________________________________________________________________
lstm_17 (LSTM) [(None, 42, 320), (N 820480 lstm_16[0][0]
__________________________________________________________________________________________________
embedding_9 (Embedding) (None, None, 160) 1060160 input_22[0][0]
__________________________________________________________________________________________________
lstm_18 (LSTM) [(None, 42, 320), (N 820480 lstm_17[0][0]
__________________________________________________________________________________________________
lstm_19 (LSTM) [(None, None, 320), 615680 embedding_9[0][0]
lstm_18[0][1]
lstm_18[0][2]
__________________________________________________________________________________________________
attention_layer (AttentionLayer ((None, None, 320), 205120 lstm_18[0][0]
lstm_19[0][0]
__________________________________________________________________________________________________
concat_layer (Concatenate) (None, None, 640) 0 lstm_19[0][0]
attention_layer[0][0]
__________________________________________________________________________________________________
dense_9 (Dense) (None, None, 6626) 4247266 concat_layer[0][0]
==================================================================================================
Total params: 10,867,106
Trainable params: 10,867,106
Non-trainable params: 0
__________________________________________________________________________________________________Epoch 20/50
294/294 [==============================] - 212s 722ms/step - loss: 2.2720 - val_loss: 3.0752
Epoch 21/50
294/294 [==============================] - 211s 719ms/step - loss: 2.2385 - val_loss: 3.0756
Epoch 22/50
294/294 [==============================] - 212s 720ms/step - loss: 2.2065 - val_loss: 3.0711
Epoch 23/50
294/294 [==============================] - 212s 721ms/step - loss: 2.1612 - val_loss: 3.0766
Epoch 24/50
294/294 [==============================] - 211s 719ms/step - loss: 2.1313 - val_loss: 3.0730
Epoch 00024: early stopping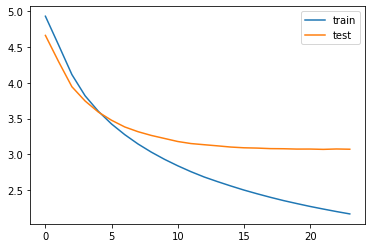
3.07의 validation loss를 얻었습니다.
Test Model
id: 1684
원문 : india not awarded five runs despite sri lankan captain dinesh chandimal breaking fake fielding law india innings first test saturday chandimal pretended throw ball even though nowhere near but umpires not signal penalty virat kohli seen gesturing five run penalty dressing room
실제 요약 : india denied runs after sri lanka fake fields in test
예측 요약 : india sl sl sl sl sl players get sl for sl #동어반복
id: 1685
원문 : japanese journalist held hostage syria islamist militants released after three years japan foreign minister said believed held hostage al qaeda affiliated al gone missing june after travelling turkey syria report civil war country
실제 요약 : japanese journalist held hostage in syria freed after yrs
예측 요약 : japan journalist killed in syria after attack on syria
id: 1686
원문 : former india captain sunil gavaskar said suspension hardik pandya kl rahul drama caused taken huge achievement india first ever test series victory australia instead indian team glory efforts pushed background added
실제 요약 : pandya rahul india test series victory gavaskar
예측 요약 : gavaskar hardik pandya to be india
id: 1687
원문 : year old oxford student uganda got married mock wedding ceremony get rid continuous pressure parents settle revealed wedding cost only got married nd birthday one person certain take care wrote
실제 요약 : oxford student marries herself to get of pressure
예측 요약 : yr old girl marries at wedding ceremony
id: 1688
원문 : survey conducted unicef among indian children revealed children wanted amitabh bachchan attend birthday party while respondents named prime minister narendra modi preference survey further showed children believed opinions appreciated families children believed teachers appreciated opinions
실제 요약 : amitabh bachchan more popular than pm modi among kids study
예측 요약 : kids in india was born on day of srk
id: 1689
원문 : shah rukh khan tweeted picture while posing poster featuring katrina kaif captioned tweet also wrote not eat ice cream real worked hard reminds katrina srk starring together aanand rai directorial zero
실제 요약 : love you srk on scene from
예측 요약 : you are not my tweets user on katrina pic
id: 1690
원문 : three year old girl only survivor plane crash killed six people russia wednesday girl survived non life threatening injuries including fractures aircraft belonged regional carrier airlines crashed while trying land small airport near village
실제 요약 : year old girl survives plane crash that killed in russia
예측 요약 : year old killed as plane hits her plane in china
id: 1691
원문 : wwe wrestler triple congratulated mumbai indians ipl win tweeting surprise store past wwe sent custom title belts sportspersons wins sending one serena williams australian open victory former chelsea captain john terry premier league triumph year
실제 요약 : triple hints at surprise for mumbai indians post ipl win
예측 요약 : wwe yuvraj singh yadav win with wwe
id: 1692
원문 : apple reportedly working headset support augmented reality virtual reality technologies headset feature displays eye would not need computer smartphone work reports claimed project internally codenamed still early stages expected release
실제 요약 : apple vr ar to release in report
예측 요약 : apple working on ios to let users report
id: 1693
원문 : first researchers uk newcastle university printed human layer eye significant shortage million people worldwide requiring prevent blindness said researchers donor stem cells mixed create solution could provide unlimited supply
실제 요약 : first human printed in the uk for cure
예측 요약 : uk researchers develop world first ever
id: 1694
원문 : switzerland born jacques jointly nobel prize chemistry mentions cv conceived parents no longer scared dark age four scientist work electron involves observing high resolution rapid freezing shape
실제 요약 : nobel laureate has no longer scared of dark on his
예측 요약 : why is the of the nobel prize ??
id: 1695
원문 : speaking breakup home alone actor said horrible breakup first admit added further said got single said genuinely need know
실제 요약 : up on with home alone actor
예측 요약 : my first choice to be held for the same time
id: 1696
원문 : army chief general bipin rawat wednesday said kartarpur corridor initiative seen isolation not linked anybody else unilateral decision no links things added earlier day external affairs minister sushma swaraj ruled dialogue pakistan unless stopped terrorism
실제 요약 : kartarpur should be seen in general rawat
예측 요약 : no proposal to draft banking system army chief
id: 1697
원문 : responding larry co founder cto oracle dig amazon web services amazon monday said sounds like larry larry further said statements no facts wild claims lots sunday while announcing oracle automated database said amazon cloud not
실제 요약 : no facts wild claims takes dig on oracle co founder
예측 요약 : amazon is not amazon amazon co founder # 동어반복
id: 1698
원문 : congress candidate sunil elections punjab gurdaspur constituency defeating bjp rival margin lakh votes seat earlier held bjp fell vacant april following mp vinod khanna death while bjp candidate second aap candidate major general suresh came third
실제 요약 : congress sunil wins by polls by votes
예측 요약 : cong candidate to contest seats in himachal pradesh
id: 1699
원문 : russia ready relations cooperate major global issues us russian foreign minister sergei lavrov told us state secretary rex tillerson phone call friday lavrov further said russia decision cut us diplomatic staff country prompted number hostile steps us nn
실제 요약 : we are ready to ties with us russia
예측 요약 : russia is no longer us russia to us state secy결과 분석
모델을 훈련시키고 나서 테스트를 하면, 동어반복이 자주 일어난다는 점이 눈에 띕니다.
이유.
LSTM 에서 inference mode에서는 다른 구조를 만들어주어야 한다는 말이 있습니다. 훈련 시에는 매 토큰마다 다음 상태에 무엇이 나올지 알고 있으므로, 다음 단계를 유추할 때 필요한 히든 스테이트, 셀 스테이트를 버려도 된다는 내용과 함께 나오는데, decoder_input (정수 인코딩한 headline) 을 알고 있기 때문에 가능한 일입니다. 요약문의 전체 내용을 알고 있으니 처음부터 생성할 필요가 없고, 모델에게 직전 단어를 주었을 때, 다음 단어를 잘 예측하는지 평가만 하면 됩니다.
그러나 inference mode에서는 답을 알지 못하고, 히든 스테이트, 셀 스테이트로부터 토큰을 하나하나 만들어 가야 합니다. 이때, 다음 토큰으로는 가장 정답일 확률이 높다고 예측된 토큰을 추출합니다. 그리고 선택한 토큰으로부터 다시 다음 후보 중 가장 가능성 있는 토큰을 선택합니다.
decode_sequence()를 보겠습니다.
이 함수는 전 토큰으로부터 모종의 과정을 통해 다음 토큰을 선정하고 다시 그 토큰으로 부터 그 다음 토큰을 선정하는 함수입니다.
def decode_sequence(input_seq):
# 입력으로부터 인코더의 상태를 얻음
e_out, e_h, e_c = encoder_model.predict(input_seq)
# <SOS>에 해당하는 토큰 생성
target_seq = np.zeros((1,1))
target_seq[0, 0] = tar_word_to_index['sostoken']
stop_condition = False
decoded_sentence = ''
while not stop_condition: # stop_condition이 True가 될 때까지 루프 반복
output_tokens, h, c = decoder_model.predict([target_seq] + [e_out, e_h, e_c])
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_token = tar_index_to_word[sampled_token_index]
if (sampled_token!='eostoken'):
decoded_sentence += ' '+sampled_token
# <eos>에 도달하거나 최대 길이를 넘으면 중단.
if (sampled_token == 'eostoken' or len(decoded_sentence.split()) >= (summary_max_len-1)):
stop_condition = True
# 길이가 1인 타겟 시퀀스를 업데이트
target_seq = np.zeros((1,1))
target_seq[0, 0] = sampled_token_index
# 상태를 업데이트 합니다.
e_h, e_c = h, c
return decoded_sentence여기서 눈여겨봐야 할 부분은 np.argmax(output_tokens[0, -1, :])입니다.
:로 되어 있는 부분 중 가장 큰 값을 갖는 index를 뽑아온다는 것으로,
만일 두 토큰이 강하게 연관되어 있거나, 스스로를 계속 추천한다면
(유튜브 뮤직에서 두 노래가 서로를 다음 곡으로 추천하는 경우를 생각해 주세요)
문장이 끝날 때까지 apple apple apple apple apple apple apple apple을 반복하게 됩니다.
해결책.
아까와 같이 요약문 생성 작업을 계속합니다. 다만, 만약 다음 단어로 지목된 토큰이 이미 뽑힌 전력이 있다면, 그 토큰에 대한 점수를 일정 비율로 차감한 후 다시 평가하여 가장 높은 점수를 얻은 토큰을 선정합니다. 페널티를 주는 방식입니다
예를 들어 [0.8, 0.93, 0.95, 1.0] 인 선택지에서 argmax는 3(인덱스) 이지만, 3은 이미 선택된 적이 있는 토큰이라고 가정합니다. 차감 비율을 10%로 설정했을 때, 다시 계산된 점수는 [0.8, 0.93, 0.95, 0.9]로서,
argmax는 2(인덱스)를 반환하여 기존과는 다른 단어를 선택하게 됩니다.
def decode_sequence_penalty(input_seq):
# 입력으로부터 인코더의 상태를 얻음
e_out, e_h, e_c = encoder_model.predict(input_seq)
# <SOS>에 해당하는 토큰 생성
target_seq = np.zeros((1,1))
target_seq[0, 0] = tar_word_to_index['sostoken']
#### 이미 나온 단어를 기록하는 set을 만듭니다.
token_bag = set()
####
stop_condition = False
decoded_sentence = ''
while not stop_condition: # stop_condition이 True가 될 때까지 루프 반복
output_tokens, h, c = decoder_model.predict([target_seq] + [e_out, e_h, e_c])
sampled_token_index = np.argmax(output_tokens[0, -1, :])
#### 만일 예측된 단어가 이미 나온 단어라면, 그 예측치를 15%로 삭감해 다른 토큰이 선택될 수 있도록 합니다
if sampled_token_index in token_bag:
output_tokens[0, -1, sampled_token_index] *= 0.15
sampled_token_index = np.argmax(output_tokens[0, -1, :]) # 재계산된 점수에서 다시 선택합니다
####
sampled_token = tar_index_to_word[sampled_token_index]
#### 현재까지 나온 단어를 기록합니다.
token_bag.add(sampled_token_index)
####
if (sampled_token!='eostoken'):
decoded_sentence += ' '+sampled_token
# <eos>에 도달하거나 최대 길이를 넘으면 중단.
if (sampled_token == 'eostoken' or len(decoded_sentence.split()) >= (summary_max_len-1)):
stop_condition = True
# 길이가 1인 타겟 시퀀스를 업데이트
target_seq = np.zeros((1,1))
target_seq[0, 0] = sampled_token_index
# 상태를 업데이트 합니다.
e_h, e_c = h, c
return decoded_sentence결과
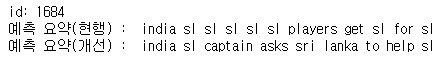

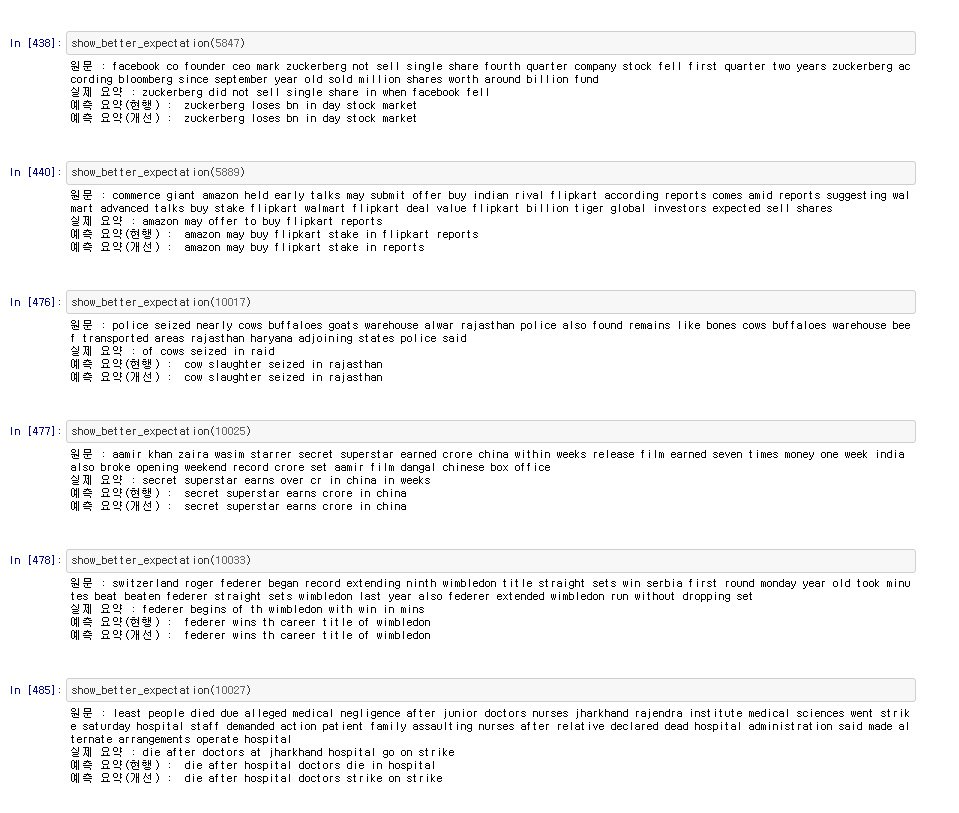
동어반복이 제거된 것을 볼 수 있습니다
참고
