ResNet
ResNet은 우측의 그림처럼 skip-connection을 주어 residual을 학습할 수 있기 때문에 ResNet이라는 이름이 붙었습니다.
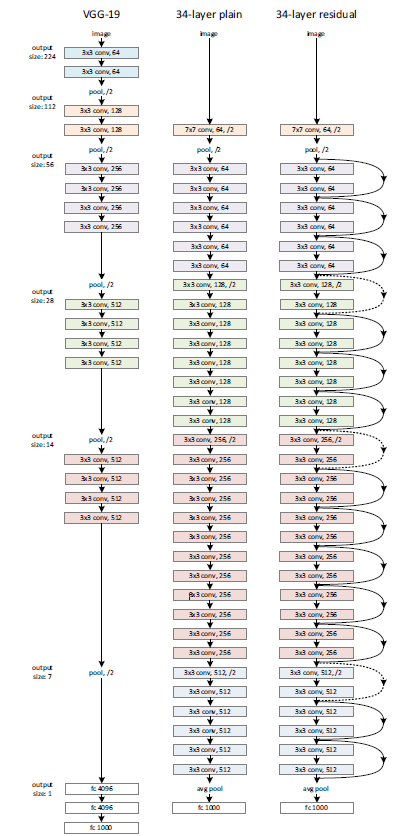
(ResNet34의 layer)
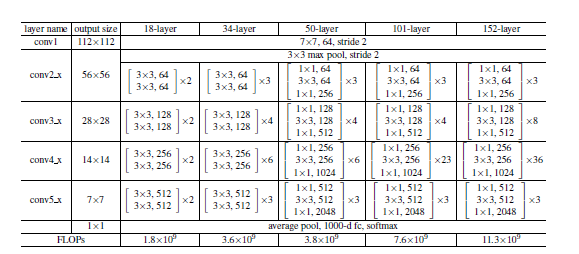
(ResNet34, ResNet50)의 구조
Implementation
1. ResBlock
ResNet50, ResNet101, ResNet152를 위한 layer block 클래스를 구현합니다.
1x1 convolution으로 channel depth를 줄이는 bottleneck 이후 3x3 convolution을 실시하고, 다시 1x1 convolution을 취하는 구조로 이루어져 있습니다.
블럭 내에서 channel depth는 in_channels reduction_channels(1x1 convolution의 결과) reduction_channels(3x3 convolution의 결과) out_channels (1x1 convolution의 결과)로 변화합니다. 예를 들어 conv3_x를 이루는 block의 경우 in_channels = 256, red_channels = 128, out_channels = 512입니다.
Block 마다 skip connection이 존재하는데, 만약 in_channels와 out_channels가 같다면 입력을 변환 없이 (nn.Identity()) 출력에 더하면 되지만, in_channels와 out_channels가 다른 경우도 존재하므로 고려해 주어야 합니다. 1x1 convolution으로 channel depth를 변경하게 됩니다. skip connection을 self.iden으로 저장합니다.
layer(conv2_x, conv3_x, ..., conv5_x)의 가장 첫 블록에서 in_channels와 out_channels가 다른 경우가 발생합니다. 같은 layer 내에서는 직전 block의 out_channels가 현재 block의 in_channels가 되고, 두 block의 구조는 동일하기 때문입니다.
layer마다 output tensor의 H, W는 직전 layer의 절반인 채로 일정하므로, conv2_x를 제외한 각 layer의 가장 첫 sublayer에서 stride=2로 H와 W를 줄이는 연산을 추가합니다.
conv2_x의 경우 input tensor의 H, W와 output tensor의 H, W는 같습니다.
따라서 정리하면 다음과 같습니다.
-
in_channels가 64가 아니고(conv3_x, conv4_x, ..),in_channels와out_channels가 다르다면, block의 첫 sublayer에 stride=2를 준다. self.iden 역시 stride=2인 1x1 convolution이다. -
in_channels가 64가 아니고(conv3_x, conv4_x, ..),in_channels와out_channels가 같다면 self.iden은 항등변환이다. -
in_channels가 64라면(conv2_x), self.iden은 channel depth를in_channels에서out_channels로 바꾸는 1x1 convolution이다.
is_plain을 인자로 주어 Plain_Block 역시 구현할 수 있도록 합니다.
# Conv_block
# activation = relu
# y = relu(BN(conv(x)))
class Conv_block(nn.Module):
def __init__(self, in_channels, out_channels, activation=True, **kwargs) -> None:
super(Conv_block, self).__init__()
self.relu = nn.ReLU()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs) # kernel size = ...
self.batchnorm = nn.BatchNorm2d(out_channels)
self.activation = activation
def forward(self, x):
if not self.activation:
return self.batchnorm(self.conv(x))
return self.relu(self.batchnorm(self.conv(x))class Res_block(nn.Module):
def __init__(self, in_channels, red_channels, out_channels, is_plain=False):
super(Res_block,self).__init__()
self.relu = nn.ReLU()
self.is_plain = is_plain
if in_channels==64:
self.convseq = nn.Sequential(
Conv_block(in_channels, red_channels, kernel_size=1, padding=0),
Conv_block(red_channels, red_channels, kernel_size=3, padding=1),
Conv_block(red_channels, out_channels, activation=False, kernel_size=1, padding=0)
)
self.iden = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1)
elif in_channels == out_channels:
self.convseq = nn.Sequential(
Conv_block(in_channels, red_channels, kernel_size=1, padding=0),
Conv_block(red_channels, red_channels, kernel_size=3, padding=1),
Conv_block(red_channels, out_channels, activation=False, kernel_size=1, padding=0)
)
self.iden = nn.Identity()
else:
self.convseq = nn.Sequential(
Conv_block(in_channels, red_channels, kernel_size=1, padding=0, stride=2),
Conv_block(red_channels, red_channels, kernel_size=3, padding=1),
Conv_block(red_channels, out_channels, activation=False, kernel_size=1, padding=0)
)
self.iden = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=2)
def forward(self, x):
y = self.convseq(x)
if self.is_plain:
x = y
else:
x = y + self.iden(x)
x = self.relu(x) # relu(skip connection)
return x2. ResNet
Block을 모아 하나로 합친 클래스입니다. num_classes와 is_plain, in_channels를 인자로 받습니다.
class ResNet(nn.Module):
def __init__(self, in_channels=3 , num_classes=1000, is_plain=False):
self.num_classes = num_classes
super(ResNet, self).__init__()
self.conv1 = Conv_block(in_channels=in_channels, out_channels=64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.conv2_x = nn.Sequential(
Res_block(64, 64, 256, is_plain),
Res_block(256, 64, 256, is_plain),
Res_block(256, 64, 256, is_plain)
)
self.conv3_x = nn.Sequential(
Res_block(256, 128, 512, is_plain),
Res_block(512, 128, 512, is_plain),
Res_block(512, 128, 512, is_plain),
Res_block(512, 128, 512, is_plain)
)
self.conv4_x = nn.Sequential(
Res_block(512, 256, 1024, is_plain),
Res_block(1024, 256, 1024, is_plain),
Res_block(1024, 256, 1024, is_plain),
Res_block(1024, 256, 1024, is_plain),
Res_block(1024, 256, 1024, is_plain),
Res_block(1024, 256, 1024, is_plain)
)
self.conv5_x = nn.Sequential(
Res_block(1024, 512, 2048, is_plain),
Res_block(2048, 512, 2048, is_plain),
Res_block(2048, 512, 2048, is_plain),
)
self.avgpool = nn.AvgPool2d(kernel_size=7, stride=1)
self.fc = nn.Linear(2048,num_classes)
def forward(self,x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2_x(x)
x = self.conv3_x(x)
x = self.conv4_x(x)
x = self.conv5_x(x)
x = self.avgpool(x)
x = x.reshape(x.shape[0], -1)
x = self.fc(x)
return x3. build_resnet
실제로 Resnet을 만들고, summary를 출력해 보겠습니다. gpu를 사용할 수 있는 환경에서 device = 'cuda' 를 입력 후 실행합니다. build_resnet은 1000개의 분류 클래스를 갖는 ResNet50을 만들어냅니다. 그러나 **kwargs 인자를 주었기에 num_classes인자를 원하는대로 넣을 수 있습니다.
summary를 출력하기 위해서는 torchsummary라는 module이 필요합니다.
!pip install torchsummary
from torchsummary import summary as summary_ 로 summary를 import합니다
def build_resnet(input_shape=(3, 224, 224), is_50=True, is_plain=False, **kwargs):
x = torch.randn(2, *input_shape).to(device)
if is_50:
model = ResNet(is_plain=is_plain, **kwargs).to(device)
assert model(x).shape == torch.Size([2, model.num_classes])
if is_plain == False:
print("ResNet50 Created")
if is_plain == True:
print("PlainNet50 Created")
print(summary_(model, (3, 224, 224), batch_size=2))
return model
model = ResNet_34(is_plain=is_plain).to(device)
assert model(x).shape == torch.Size([2, model.num_classes])
if is_plain == False:
print("ResNet34 Created")
if is_plain == True:
print("PlainNet34 Created")
print(summary_(model, (3, 224, 224), batch_size=2))
return model4. torchsummary
torchsummary의 결과로 구현의 오류는 없었는지 살펴 볼 수 있습니다.


5. Training
ResNet50를 optimizer를 tuning 하며 학습시킵니다.
시도한 하이퍼파라미터는 다음과 같습니다.
-
Trial 1: lr = 0.0025, momentum=0.9, no weight decay
best val acc = 0.49로, 학습이 이뤄지지 않았습니다.
-
Trial 2: lr = 0.01, momentum, weight decay
역시 학습이 이뤄지지 않았습니다. -
Trial 3: lr = 0.0001, momentum, weight decay
어느 정도 안정적인 학습이 진행되었습니다
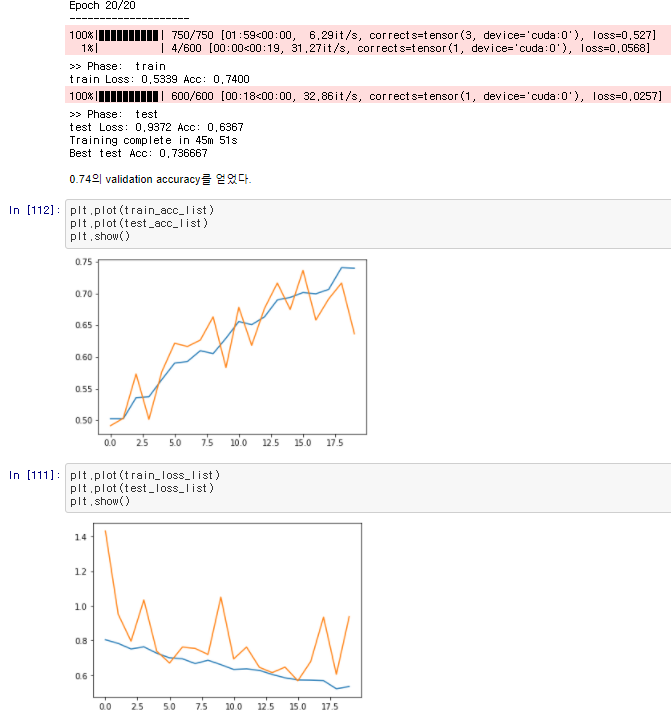
6. Train Result
cat vs dog (Train set 25000장)의 일부를 추출한 데이터셋과 dataloader를 구현해(Train/Val: 3000/600)으로 20 epoch 학습시켰을 때,
validation 기준, ResNet50는 최고 73%의 정답률, PlainNet50는 같은 하이퍼파라미터에서 최고 53%의 정답률을 보였습니다.
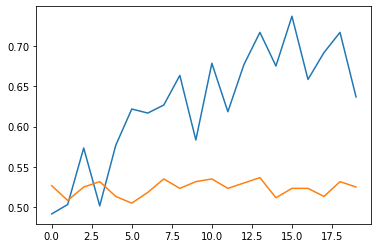
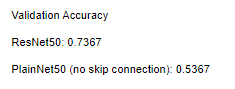
7. 과정 분석
초기에 선택한 learning rate의 1/25인 경우에야 학습이 안정적으로 진행되었고, 불안정한 경우 PlainNet과 ResNet은 큰 차이를 보이지 못했습니다. 그러나 적절한 hyperparameter를 선택했을 때, ResNet이 PlainNet을 크게 압도했으며, 이는 skip-connection의 유용성을 보여주고, 구현 역시 성공적이었다는 것을 알려 줍니다.

안녕하세요, 올려주신 글 내용 잘 봤습니다. 혹시 코드는 직접 짜신 걸까요? 괜찮으시다면 깃허브 링크같은 것 공유해주신다면 도움이 많이 될 것 같습니다. 감사합니다