문자인코딩
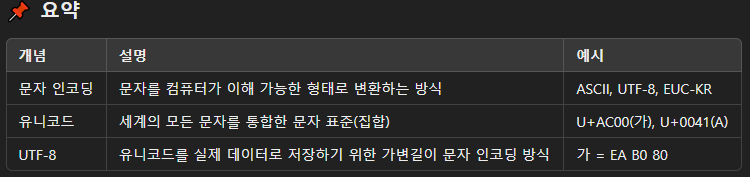
문자 인코딩(Character Encoding)은 컴퓨터가 문자를 이해하고 저장할 수 있도록 문자를 이진 데이터(0과 1)로 변환하는 방식을 뜻합니다.
쉽게 말해,
- 사람이 보는: 문자: 안녕하세요
- 컴퓨터가 보는: 이진수: 10101010 11101011 ...
위와 같이 문자타입은 컴퓨터가 볼수 있는 이진수로 해석해야 된다.
유니코드
유니코드는 세계 모든 언어의 문자를 하나의 공통된 문자집합으로 표현하기 위한 국제 표준입니다.
- 전 세계의 거의 모든 문자(한글, 한자, 영문자, 특수문자 등)를 하나의 표준으로 통합
- 각 문자에 고유한 번호(코드 포인트, Code Point)를 부여합니다.
- 유니코드에서 문자는 U+XXXX 형태로 표현됩니다.
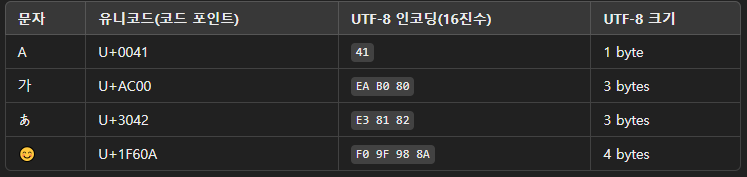
예시)
- 가: U+AC00
- A: U+0041
- あ: U+3042
- 😊: U+1F60A
유니코드는 그 자체로 인코딩 방식이 아니라, 문자에 번호를 부여하는 일종의 표준 체계입니다.
UTF-8
UTF-8(Unicode Transformation Format - 8 bit)은 유니코드를 실제로 컴퓨터가 저장하고 처리하기 위한 인코딩 방식 중 하나입니다.
특징)
- 가변 길이 인코딩 방식으로, 문자마다 다른 바이트 수를 사용합니다.
- 영어 알파벳, 숫자 등 ASCII 문자는 1바이트(8비트),
한글, 한자 등은 일반적으로 3바이트,
이모지 같은 문자는 4바이트로 저장됩니다. - UTF-8은 전 세계에서 가장 많이 사용되는 문자 인코딩으로, 현재 인터넷과 프로그램에서 가장 표준적인 인코딩입니다.
흔한 질문
왜 UTF-8을 가장 많이 사용하나요?
- UTF-8은 ASCII 문자(영어 알파벳, 숫자 등)를 그대로 1바이트로 표현하므로 기존 시스템과 호환성이 뛰어나며, 다양한 언어와 특수문자까지 효율적으로 저장하고 처리할 수 있기 때문입니다.
유니코드가 UTF-8 말고도 다른 형태가 있나요?
- 네, 대표적으로 UTF-16과 UTF-32가 존재합니다.
- UTF-16: 최소 2바이트로 저장, 문자에 따라 2~4바이트 사용 (Windows 내부 문자열 등)
- UTF-32: 모든 문자를 무조건 4바이트로 표현 (거의 사용 안 함, 낭비 큼)
하지만 웹 및 소프트웨어 개발 환경에서는 UTF-8이 사실상 표준입니다.
결론:
문자 인코딩은 문자를 이진 데이터로 변환하는 규칙이며, 유니코드는 전 세계 모든 문자를 하나의 번호로 표준화한 체계, UTF-8은 유니코드를 실제 데이터로 저장하는 가장 널리 쓰이는 인코딩 방식입니다.

처음이라서 그래 가본적 없던 길에