6. 딕셔너리와 해시
1) 딕셔너리?
: [키, 값] 쌍을 담아두는 자료구조이다.
: 키는 원소를 찾기 위한 식별자이다.
: 딕셔너리와 해시는 유일한 값(반복되지 않는 값)만 저장한다.
2) 딕셔너리 만들기
: 딕셔너리 클래스는 아래와 같다.
function Dictionary(){
var items = {};
}(1) 딕셔너리 구현시 필수 메소드
-
set(key, value): 딕셔너리에 원소를 추가한다. -
remove(key): 키에 해당하는 원소를 삭제한다. -
has(key): 키에 해당하는 원소가 딕셔너리에 있으면 true를 반환한다. -
get(key): 키에 해당하는 원소의 값을 반환한다. -
clear(): 모든 원소를 삭제한다. -
size(): 원소의 개수를 반환한다. -
keys(): 딕셔너리의 모든 키를 배열로 반환한다. -
values(): 딕셔너리의 모든 값을 배열로 반환한다.
(2) has와 set()
- has()의 경우, 자바스크립트 in 연산자를 이용한다.
this.has = function(key){
return key in items;
}
this.set = function(key, value){
items[key] = value;
}(2) remove()
- key로 원소를 찾아 삭제한다.
this.remove = function(key){
if(this.has(key){
delete items[key];
return true;
}
return false;
};(3) get과 values()
- 딕셔너리에서 어떤 원소를 찾아 그 값을 알고자 할 때 get(key)을 쓴다.
this.get = function(key){
return this.has(key) ? items[key] : undefined;
};- values()는 딕셔너리 전체 원소의 값을 배열로 반환한다.
this.values = function(){
var values = [];
for(var k in items){ //items원소를 순회
if(this.has(k)){ //만약 key에 해당하는 값이 있다면
values.push(items[k]); //values배열에 그 값을 넣음
}
}
}3) 해쉬테이블
(1) 해쉬테이블이란?
사진클릭시 이미지 출처로 이동합니다.
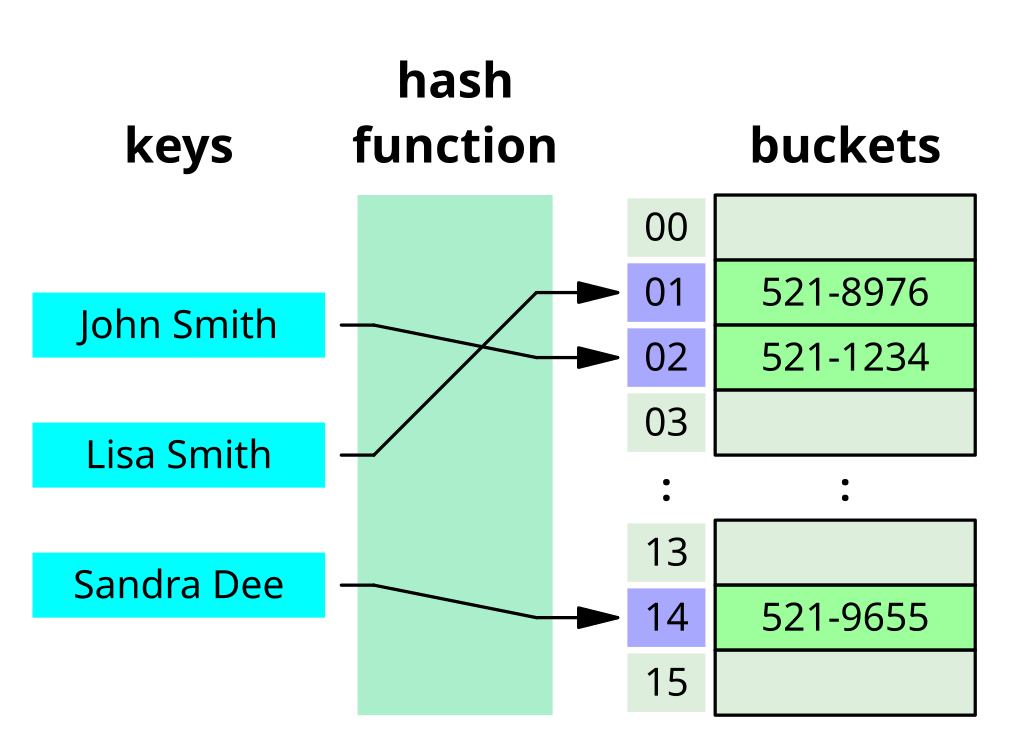
-
해시테이블 클래스는 Dictionary 클래스의 해시 구현이다.
-
해싱은, 자료구조에서 특정 값을 가장 신속하게 찾는 방법이다.
-
해시함수는 어떤 키에 해당하는 값의 주소를 테이블에서 찾아주는 함수이다.(조회속도 빠름)
(2) 해시 테이블 만들기
: 해시테이블의 기본 골격은 아래와 같다.
function HashTable(){
var table = [];
}: 아래는 해시 테이블의 기본 메소드이다.
-
push(key, value): 원소를 추가한다.(혹은 기본 원소를 수정한다) -
remove(key): 키에 해당하는 원소를 찾아 삭제한다. -
get(key): 키에 해당하는 원소를 찾아 그 값을 반환한다.
(3) loseloseHashCode()
: HashTable의 프라이빗 메소드이다.
: key를 구성하는 각 문자열의 아스키 값을 합하는 해시함수이다.
var loseloseHashCode = function(key){
var hash = 0; //결과값을 저장할 변수
for(var i=0; i<key.length; i++){ //key문자열길이만큼 반복
hash += key.charCodeAt(i); //문자별아스키값에 hash를 더함
}
return hash%37; //hash를 임의의 값으로 나눔
}(4) put()
- 인자 key를 해시 함수에 넣고 반환된 결과값으로 테이블에 값을 추가한다.
this.put = function(key, value){
var position = loseloseHashCode(key);
console.log(position + '-' + key);
table[position] = value;
}(5) remove()
-
HashTable 인스턴스에서 어떤 원소를 삭제하려면 인덱스를 찾아 table배열의 값을 undefined로 바꿔준다.
-
HashTable은 ArrayList처럼 table 배열의 원소 자체를 삭제할 필요가 없다.
-
배열 전체에 원소들이 고루 분포되어 있으므로 어떤 인덱스엔 값이 할당되지 않은 채 기본 값 undefined만 들어 있다.
this.remove = function(key){
table[loseloseTableCode(key)] = undefined;
};4) 해시 테이블 간 충돌 해결
(0) 분명히 키는 다른데 값이 똑같은 경우가 있다!
: HashTable 인스턴스에서 동일한 인덱스에는 다른 값이 들어 있어야 하기에 이를 충돌이라 한다.
: 값이 중복된다고 하여 중복값을 삭제할 수 없으므로 이를 해결한 처리방법을 사용한다.
: 처리 방법에는 체이닝, 선형탐색, 이중해싱이 있는데 여기서는 체이닝, 선형탐색에 대해 알아본다.
(1) 체이닝
체이닝이란?
: 테이블의 인덱스별로 연결 리스트를 생성해 그안에 원소를 저장하는 기법이다.
: 구현이 간단하다는 점에서 장점이지만, HashTable인스턴스 외 추가의 메모리를 소요한다는 단점이 있다.
사진 클릭시 이미지 출처로 이동합니다.
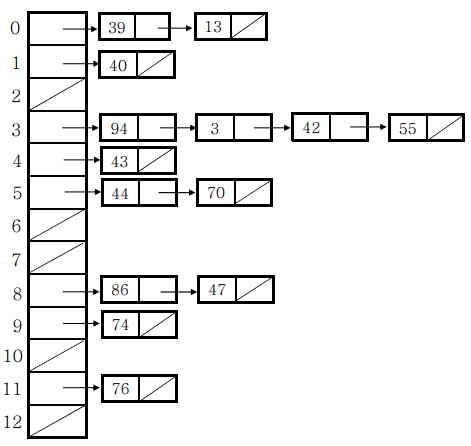
체이닝 구현
: 체이닝을 구현하려면 먼저 LinkedList에서 원소를 새로운 헬퍼 클래스로 표현해야한다.
: ValuePair는 객체에 key, value를 저장하는 역할을 하며 toString을 재정의한다.
var ValuePair = function(key, value){
this.key = key;
this.value = value;
this.toString = function(){
return "[" + this.key + "-" + this.value + "]";
}
}put()
: put()은 새로운 원소를 넣는 메소드로 아래 코드와 같다.
[1] 새 원소가 들어갈 위치를 이미 다른 원소가 차지하고 있는지 확인하고 비어 있으면 새로운 연결리스트를 생성한다.
[2] 만약 해당 위치에 원소가 들어있으면 append()를 사용해 해당 리스트에 들어간다.
this.put = function(key, value){
var position = loseloseHashCode(key);
if(table[position] == undefined){ //[1]
table[position] = new LinkedList();
}
table[position].append(new ValuePair(key, value)); //[2]
}get()
: get()은 키로 값을 조회하는 메소드로 코드는 아래와 같다.
[1] 원소의 존재여부를 확인한다. 만약 존재하지 않는 원소이면 [7]undefiend를 반환한다.
[2]&[3] 만약 원소가 있다면 먼저 리스트의 헤드를 current에 담고 원소를 찾을 때까지 리스트를 순회한다.
[4]&[5] 만약 찾으려는 키 값을 찾았다면 해당 키값의 value를 반환한다.
[6] 만약 찾지 못했다면 다음으로 넘아간다.
this.get = function(key){
var position = loseloseHashCode(key);
if(table[position] !== undefined){ //[1]
//키,값을 찾기위해 순회한다.
var current = table[position].getHead(); //[2]
while(current.next){ //[3]
if(current.element.key === key){ //[4]
return current.element.value; //[5]
}
current = current.next; //[6]
}
//처음이나 마지막 원소일 경우
if(current.element.key == key){
return current.element.value;
}
}
return undefined; //[7]
};remove()
: remove()는 LinkedList에서 특정 원소를 지워야 한다.
[1] LinkedList 인스턴스를 순회하면서 current가 우리가 찾는 원소라면 [2]remove로 삭제한다.
[3] 만약 이렇게 지운 연결리스트가 비어있다면, [4]position 인덱스 자리를 undefined로 바꾼다.
this.remove = function(key{
var position = loseloseHashCode(key);
if(table[position] == undefined){
var current = table[position].getHead();
while(current.next){
if(current.element.key === key){ //[1]
table[position].remove(current.element); //[2]
if(table[position].isEmpty()){ //[3]
table[position] = undefined; //[4]
}
return true;
}
current = current.next;
}
//처음이나 마지막 원소일 경우
if(current.element.key === key){
table[position].remove(current.element);
if(table[position].isEmpty()){
table[position] = undefined;
}
return true;
}
}
return false;
};(2) 선형탐색법
선형탐색법이란?
: 새 원소 추가시 인덱스가 이미 점유된 경우, 인덱스+1을 찾아보고 인덱스+1도 점유되었다면 인덱스+2를 찾는 방법이다.
사진 클릭시 이미지 출처로 이동합니다.
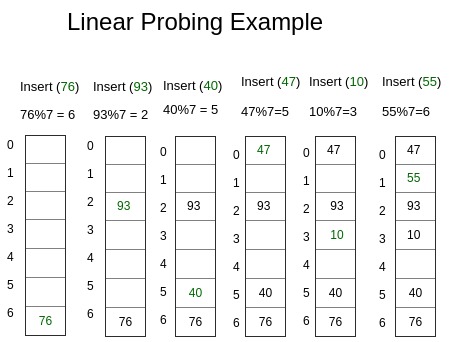
put()
[1] 해시함수로 인덱스를 찾는다.
[2] 해당 인덱스에 다른 원소가 있는지 체크한다.(다른 원소가 있으면 else로 감)
[3] 다른 원소가 없다면, ValuePair의 인스턴스를 생성해 넣는다.
[4] 다른 원소가 이미 들어간 상태이면 비어있는 인덱스를 찾기위해 index변수를 만들어 position+1을 할당한다.
[5] 다시 이 위치에 다른 원소가 있는지 점검하고, 만약 있으면 [6]index를 계속 하나씩 증가시켜 반복한다.
[7] 결국 찾게 된 인덱스에 값을 세팅한다.
this.put = function(key, value){
var position = loseloseHashCode(key); //[1]
if(table[position] == undefined){ //[2]
table[position] = new ValuePair(key, value); //[3]
}else{
var index = ++position; //[4]
while(table[index] != undefined){ //[5]
index++; //[6]
}
table[index] = new ValuePair(key, value); //[7]
}
};get()
[1] 키의 존재여부를 확인한다. 존재하지 않으면 [7]undefined를 반환한다.
[1] 키가 존재한다면 [2]찾는 테이블의 해당 인덱스와 키가 동일한지 보고 [3]동일하면 그 값을 반환한다.
[4] 동일하지 않다면, HashTable 인스턴스의 다음 위치를 반복하여 뒤져본다.
[5] 그리고 원소가 맞는지 다시 한 번 확인해서 [6]그 값을 반환한다.
this.get = function(key){
var position = loseloseHashCode(key);
if(table[position] !== undefined){ //[1]
if(table[position].key === key){ //[2]
return table[position].value; //[3]
}else{
var index = ++position;
while(table[index] === undefined || table[index].key !== key){ //[4]
index++;
}
if(table[index].key === key){ //[5]
return table[index].value; //[6]
}
}
}
return undefined; //[7]
};5) 해시 함수 개선
-
좋은 해시함수라면 원소 삽입과 조회 속도가 빠르고 충돌 확률이 낮아야 한다.
-
결국, 더 좋은 성능의 해시함수를 사용한다면 충돌을 위해 여분의 메모리가 필요치 않게 된다.
-
아래 코드는 충돌이 적은 해시함수이다.
var djb2HashCode = function(key){
var hash = 5381;
for(var i=0; i<key.length; i++){
hash = hash*33 + key.charCodeAt(i);
}
return hash % 1013;
}