데이터 분석 개요
ANSI/ISO SQL 표준은 데이터 분석을 위해서 다음의 세 가지 함수를 정의하고 있다.
- AGGREGATE FUNCTION
- GROUP FUNCTION
- WINDOW FUNCTION
AGGREGATE FUNCTION
GRUOP FUNCTION의 한 부분으로 분류할 수 있다.
COUNT, SUM, AVG, MAX, MIN 외 각종 집계 함수들이 포함돼 있다.
GROUP FUNCTION
소계, 중계, 합계, 총합계 등 여러 레벨의 결산 보고서를 만드는 것은 중요 업무 중 하나이며, 이를 가능하게 한다.
ROLLUP, CUBE, GROUPING SETS가 있으며 정렬이 필요한 경우 ORDER BY 절에 정렬 칼럼을 명시해야 한다.
ROLLUP은 GROUP BY의 확장된 형태로 사용하기 쉬우며, 병렬로 수행할 수 있어 매우 효과적이며, 시간 및 지역처럼 계층적 분류를 포함하고 있는 데이터의 집계에 적합하다.
CUBE는 결합 가능한 모든 값에 대해 다차원적인 집계를 생성하게 되므로 ROLLUP에 비해 다양한 데이터를 얻는 장점이 있는 반면, 시스템 부하를 많이 주는 단점이 있다.
GROUPING SETS는 원하는 부분의 소계만 손쉽게 추출할 수 있는 장점이 있다.
WINDOW FUNCTION
분석함수나 순위 함수로도 알려진 윈도우 함수는 데이터 웨어 하우스에서 발전한 기능이다.
ROLLUP 함수
ROLLUP에 지정된 Grouping Columns의 List는 Subtotal을 생성하기 위해 사용되며, Grouping Columns의 수를 N이라고 했을 때 N+1 Level의 Subtotal이 생성된다.
중요한 것은, ROLLUP의 인수는 계층 구조이므로 인수 순서가 바뀌면 수행 결과도 바뀌게 되므로 인수의 순서에도 주의해야 한다.
일반적인 GROUP BY 절 사용
SELECT B.DNAME, A.JOB
, COUNT (*) AS EMP_CNT
, SUM (A.SAL) AS SAL_SUM
FROM EMP A, DEPT B
WHERE B.DEPTNO = A.DEPTNO
GROUP BY B.DNAME, A.JOB;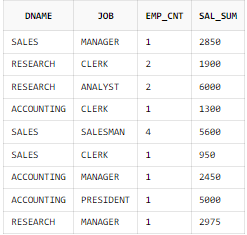
GROUP BY 절 + ORDER BY 절 사용
SELECT B.DNAME, A.JOB
, COUNT(*) AS EMP_CNT
, SUM(A.SAL) AS SAL_SUM
FROM EMP A, DEPT B
WHERE B.DEPTNO = A.DEPTNO
GROUP BY B.DNAME, A.JOB
ORDER BY B.DNAME, A.JOB;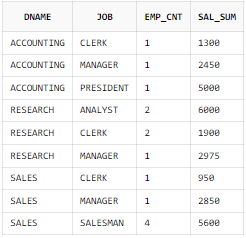
ROLLUP 함수 사용
SELECT B.DNAME, A.JOB
, COUNT(*) AS EMP_CNT
, SUM(A.SAL) AS SAL_SUM
FROM EMP A, DEPT B
WHERE B.DEPTNO = A.DEPTNO
GROUP BY ROLLUP(B.DNAME, A.JOB);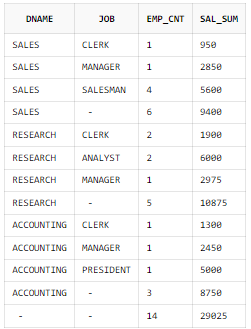
계층 내 정렬을 위해서는 별도의 ORDER BY 절을 사용해야 한다.
ROLLUP 함수 + ORDER BY 절 사용
SELECT B.DNAME, A.JOB
, COUNT(*) AS EMP_CNT
, SUM(A.SAL) AS SAL_SUM
FROM EMP A, DEPT B
WHERE B.DEPTNO = A.DEPTNO
GROUP BY ROLLUP(B.DNAME, A.JOB)
ORDER BY B.DNAME, A.JOB;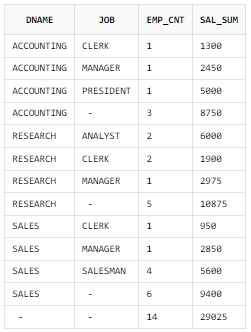
GROUPING 함수 사용
ROLLUP, CUBE, GROUPING SETS 등 새로운 그룹 함수를 지원하기 위해 추가된 함수다.
- ROLLUP이나 CUBE에 의한 소계가 계산된 결과에는 GROUPING(EXPR) = 1 이 표시된다.
- 그 외의 결과에는 GROUPING(EXRP) = 0이 표시된다.
GROUPING 함수와 CASE/DECODE를 이용해, 소계를 나타내는 필드에 원하는 문자열을 지정할 수 있어서 보고서 작성 시 유용하게 사용할 수 있다.
SELECT B.DNAME
, GROUPING(B.DNAME) AS DNAME_GRP
, A.JOB
, GROUPING(A.JOB) AS JOB_GRP
, COUNT(*) AS EMP_CNT
, SUM(A.SAL) AS SAL_SUM
FROM EMP A, DEPT B
WHERE B.DEPTNO = A.DEPTNO
GROUP BY ROLLUP(B.DNAME, A.JOB)
ORDER BY B.DNAME, A.JOB;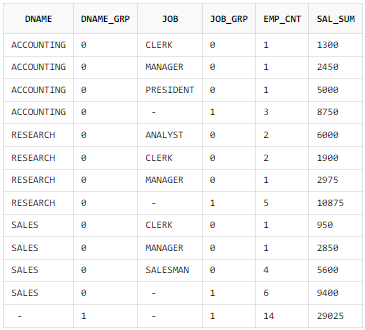
부서별, 업무별과 전체 집계를 표시한 레코드에서 GROUPING 함수가 1을 반환한 것을 확인할 수 있다. 그리고 전체 합계를 나타내는 결과 라인에서는 부서별, 업무별 GROUPING 함수가 둘 다 1이다.
GROUPING 함수 + CASE 사용
SELECT CASE GROUPING(B.DNAME)
WHEN 1
THEN 'ALL DEPT'
ELSE B.DNAME
END AS DNAME
, CASE GROUPING(A.JOB)
WHEN 1
THEN 'ALL JOB'
ELSE A.JOB
END AS JOB
, COUNT(*) AS EMP_CNT
, SUM(A.SAL) AS SAL_SUM
FROM EMP A, DEPT B
WHERE B.DEPTNO = A.DEPTNO
GROUP BY ROLLUP(B.DNAME, A.JOB)
ORDER BY B.DNAME, A.JOB;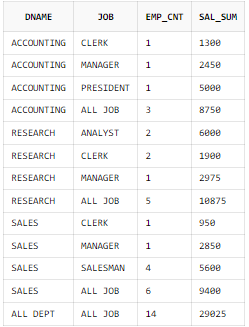
GROUPING 함수 + DECODE 함수
SELECT DECODE(GROUPING(B.DNAME)
, 1, 'ALL DEPT'
, B.DNAME) AS DNAME
, DECODE(GROUPING(A.JOB)
, 1, 'ALL DEPT'
,A.JOB) AS JOB
, COUNT(*) AS EMP_CNT
, SUM(A.SAL) AS SAL_SUM
FROM EMP A, DEPT B
WHERE B.DEPTNO = A.DEPTNO
GROUP BY ROLLUP(B.DNAME, A.JOB)
ORDER BY B.DNAME, A.JOB;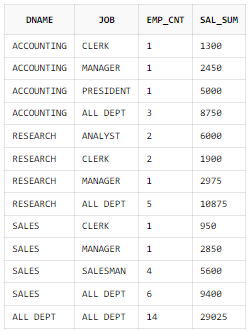
ROLLUP 함수 결합 컬럼 사용
SELECT B.DNAME, A.JOB, A.MGR
, COUNT(*) AS EMP_CNT
, SUM(A.SAL) AS SAL_SUM
FROM EMP A, DEPT B
WHERE B.DEPTNO = A.DEPTNO
GROUP BY ROLLUP(B.DNAME, (A.JOB, A.MGR))
ORDER BY B.DNAME, A.JOB, A.MGR;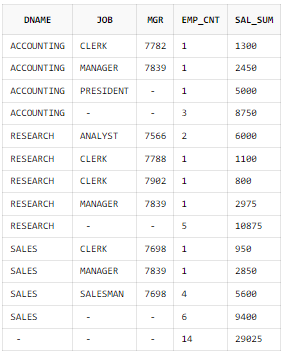
괄호로 묶은 JOB과 MGR의 경우 하나의 집합 칼럼으로 간주해 괄호 내 칼럼별 집계를 구하지 않는다.
CUBE 함수
ROLLUP에서는 단지 가능한 Subtotal만을 생성하지만, CUBE는 결합 가능한 모든 값에 대해 다차원 집계를 생성한다.
CUBE 함수의 경우 표시된 인수들에 대한 계층별 집계를 구할 수 있으며, 이때 표시된 인수 간에는 계층 구조인 ROLLUP과는 달리 평등한 관계이므로 인수의 순서가 바뀌는 경우 행간에 정렬 순서는 바뀔 수 있어도 데이터 결과는 같다.
CUBE 함수 이용
SELECT CASE GROUPING(B.DNAME)
WHEN 1
THEN 'ALL DEPT'
ELSE B.DNAME
END AS DNAME
, CASE GROUPING(A.JOB)
WHEN 1
THEN 'ALL DEPT'
ELSE A.JOB
END AS JOB
, COUNT(*) AS EMP_CNT
, SUM(A.SAL) AS SAL_SUM
FROM EMP A, DEPT B
WHERE B.DEPTNO = A.DEPTNO
GROUP BY CUBE(B.DNAME, A.JOB)
ORDER BY B.DNAME, A.JOB;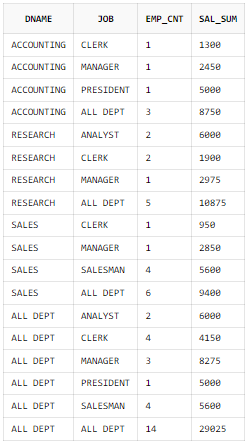
CUBE는 GROUPING 칼럼이 가질 수 있는 모든 경우의 수에 대해 Subtotal을 생성하므로 GROUPING COLUMNS의 수가 N이라고 가정하면, 2의 N승 LEVEL의 Subtotal을 생성한다.
UNION ALL 사용 SQL
SELECT DNAME
, JOB
, COUNT(*) AS EMP_CNT
, SUM(SAL) AS SAL_SUM
FROM EMP A, DEPT B
WHERE B.DEPTNO = A.DEPTNO
GROUP BY DNAME, JOB
UNION ALL
SELECT DNAME
, 'ALL JOB' AS JOB
, COUNT(*) AS EMP_CNT
, SUM(SAL) AS SAL_SUM
FROM EMP A, DEPT B
WHERE B.DEPTNO = A.DEPTNO
GROUP BY DNAME
UNION ALL
SELECT 'ALL DEPT' AS DNAME
, JOB
, COUNT(*) AS EMP_CNT
, SUM(SAL) AS SAL_SUM
FROM EMP A, DEPT B
WHERE B.DEPTNO = A.DEPTNO
GROUP BY JOB
UNION ALL
SELECT 'ALL DEPT' AS DNAME
, 'ALL JOB' AS JOB
, COUNT(*) AS EMP_CNT
, SUM(SAL) AS SAL_SUM
FROM EMP A, DEPT B
WHERE B.DEPTNO = A.DEPTNO;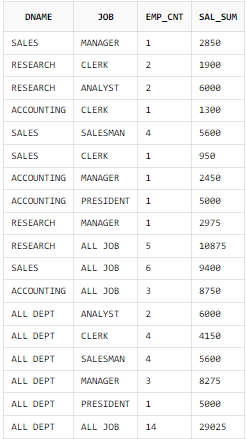
CUBE 함수를 사용하면 기존에 같은 테이블을 네 번 액세스 하는 이유가 됐던 부서와 업무별 소계와 총계 부분을 CUBE 함수를 사용함으로써 한번의 액세스만으로 구현한다.
결과적으로 수행속도 및 자원 사용률을 개선할 수 있으며, SQL 문장도 더 짧아졌으므로 가독성도 높아졌다.
GROUPING SETS 함수
이를 이용해 더욱 다양한 소계 집합을 만들 수 있는데, GROUP BY SQL 문장을 여러 번 반복하지 않아도 원하는 결과를 쉽게 얻을 수 있다.
GROUPING SETS에 표시된 인수들에 대한 개별 집계를 구할 수 있으며, 이때 표시된 인수 간에는 계층 구조인 ROLLUP과 달리 평등한 관계이므로 인수의 순서가 바뀌어도 결과는 같다.
일반 그룹 함수를 이용한 SQL
SELECT DNAME
, 'ALL JOB' AS JOB
, COUNT(*) AS EMP_CNT
, SUM(SAL) AS SAL_SUM
FROM EMP A, DEPT B
WHERE B.DEPTNO = A.DEPTNO
GROUP BY DNAME
UNION ALL
SELECT 'ALL DEPT' AS DNAME
, JOB
, COUNT(*) AS EMP_CNT
, SUM(SAL) AS SAL_SUM
FROM EMP A, DEPT B
WHERE B.DEPTNO = A.DEPTNO
GROUP BY JOB;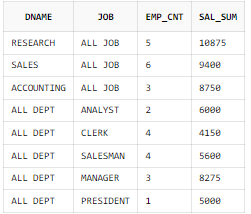
GROUPING SETS 사용 SQL
SELECT CASE GROUPING(B.DNAME)
WHEN 1
THEN 'ALL DEPT'
ELSE B.DNAME
END AS DNAME
, CASE GROUPING(A.JOB)
WHEN 1
THEN 'ALL JOB'
ELSE B.DNAME
END AS JOB
, COUNT(*) AS EMP_CNT
, SUM(A.SAL) AS SAL_SUM
FROM EMP A, DEPT B
WHERE B.DEPTNO = A.DEPTNO
GROUP BY GROUPING SETS(B.DNAME, A.JOB)
ORDER BY B.DNAME, A.JOB;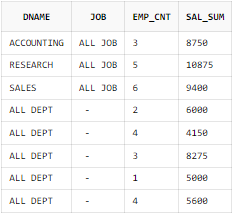
GROUPING SETS 함수 사용 시 UNION ALL을 사용한 일반 그룹 함수를 사용한 SQL과 같은 결과를 얻을 수 있으며, 괄호로 묶은 집합 별로 집계를 구할 수 있다.
3개의 인수를 이용한 GROUPING SETS 이용
SELECT B.DNAME
, A.JOB
, A.MGR
, COUNT(*) AS EMP_CNT
, SUM(A.SAL) AS SAL_SUM
FROM EMP A, DEPT B
WHERE B.DEPTNO = A.DEPTNO
GROUP BY GROUPING SETS((B.DNAME, A.JOB, A.MGR)
, (B.DNAME, A.JOB)
, (A.JOB, A.MGR));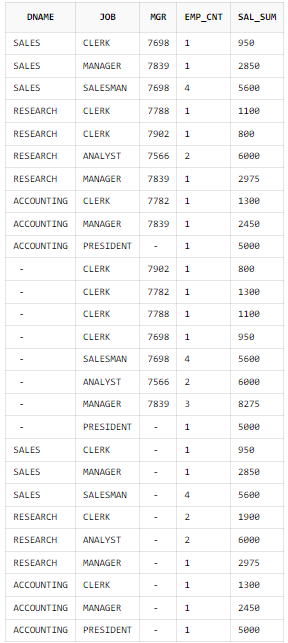
각 (DNAME+JOB+MGR) 기준의 집계, (DNAME+JOB) 기준의 집계, (JOB+MGR) 기준의 집계이다.
