정규 표현식은 문자열의 규칙을 표현하는 검색 패턴으로 주로 문자열 검색과 치환에 사용된다.
기본 문법
가. POSIX 연산자
. : 모든 문자와 일치(newline 제외)
| : 대체 문자를 구분
\ : 다음 문자를 일반 문자로 취급
SELECT REGEXP_SUBSTR('aab', 'a.b') AS C1
, REGEXP_SUBSTR('abb', 'a.b') AS C2
, REGEXP_SUBSTR('acb', 'a.b') AS C3
, REGEXP_SUBSTR('adc', 'a.b') AS C4
FROM DUAL;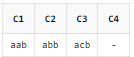
SELECT REGEXP_SUBSTR('a', 'a|b') AS C1
, REGEXP_SUBSTR('b', 'a|b') AS C2
, REGEXP_SUBSTR('c', 'a|b') AS C3
, REGEXP_SUBSTR('ab', 'ab|cd') AS C4
, REGEXP_SUBSTR('cd', 'ab|cd') AS C5
, REGEXP_SUBSTR('bc', 'ab|cd') AS C6
, REGEXP_SUBSTR('aa', 'a|aa') AS C7
, REGEXP_SUBSTR('aa', 'aa|a') AS C8
FROM DUAl;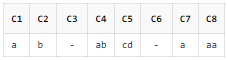
SELECT REGEXP_SUBSTR('a|b', 'a|b') AS C1
, REGEXP_SUBSTR('a|b', 'a\|b') AS C2
FROM DUAL;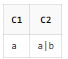
앵커는 검색 패턴의 시작과 끝을 지정한다.
^ : 문자열의 시작
$ : 문자열의 끝
SELECT REGEXP_SUBSTR('ab' || CHR(10) || 'cd', '^.', 1, 1) AS C1
, REGEXP_SUBSTR('ab' || CHR(10) || 'cd', '^.', 1, 2) AS C2
, REGEXP_SUBSTR('ab' || CHR(10) || 'cd', '.$', 1, 1) AS C3
, REGEXP_SUBSTR('ab' || CHR(10) || 'cd', '.$', 1, 2) AS C4
FROM DUAL;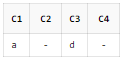
수량사는 선행 표현식의 일치 횟수를 지정한다. 패턴을 최대로 일치시키는 탐욕적 방식으로 동작한다.
? : 0회 또는 1회 일치
* : 0회 또는 그 이상의 횟수로 일치
+ : 1회 또는 그 이상의 횟수로 일치
{m} : m회 일치
{m,} : 최소 m회 일치
{,m} : 최대 m회 일치
{m,n} : 최소 m회, 최대 n회 일치
SELECT REGEXP_SUBSTR('ac', 'ab?c') AS C1
, REGEXP_SUBSTR('abc', 'ab?c') AS C2
, REGEXP_SUBSTR('abbc', 'ab?c') AS C3
, REGEXP_SUBSTR('ac', 'ab*c') AS C4
, REGEXP_SUBSTR('abc', 'ab*c') AS C5
, REGEXP_SUBSTR('abbc', 'ab*c') AS C6
, REGEXP_SUBSTR('ac', 'ab+c') AS C7
, REGEXP_SUBSTR('abc', 'ab+c') AS C8
, REGEXP_SUBSTR('abbc', 'ab+c') AS C9
FROM DUAl;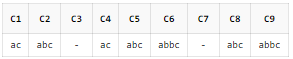
SELECT REGEXP_SUBSTR('ab', 'a{2}') AS C1
, REGEXP_SUBSTR('aab', 'a{2}') AS C2
, REGEXP_SUBSTR('aab', 'a{3,}') AS C3
, REGEXP_SUBSTR('aaab', 'a{3,}') AS C4
, REGEXP_SUBSTR('aaab', 'a{4,5}') AS C5
, REGEXP_SUBSTR('aaaab', 'a{4,5}') AS C6
FROM DUAl;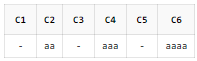
(expr) : 괄호 안의 표현식을 하나의 단위로 취급
SELECT REGEXP_SUBSTR('ababc', '(ab)+c') AS C1
, REGEXP_SUBSTR('ababc', 'ab+c') AS C2
, REGEXP_SUBSTR('abd', 'a(b|c)d') AS C3
, REGEXP_SUBSTR('abd', 'ab|cd') AS C4
FROM DUAL;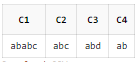
\n : n번째 서브 표현식과 일치, n은 1에서 9 사이의 정수
SELECT REGEXP_SUBSTR('abxab', '(ab|cd)x\1') AS C1
, REGEXP_SUBSTR('cdxcd', '(ab|cd)x\1') AS C2
, REGEXP_SUBSTR('abxef', '(ab|cd)x\1') AS C3
, REGEXP_SUBSTR('ababab', '(.*)\1+') AS C4
, REGEXP_SUBSTR('abcabc', '(.*)\1+') AS C5
, REGEXP_SUBSTR('abcabd', '(.*)\1+') AS C6
FROM DUAL; 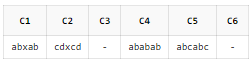
[char...] : 문자 리스트 중 한 문자와 일치
[^char...] : 문자 리스트에 포함되지 않은 한 문자와 일치
SELECT REGEXP_SUBSTR('1a', '[0-9][a-z]') AS C1
, REGEXP_SUBSTR('9z', '[0-9][a-z]') AS C2
, REGEXP_SUBSTR('aA', '[^0-9][^a-z]') AS C3
, REGEXP_SUBSTR('Aa', '[^0-9][^a-z]') AS C4
FROM DUAL;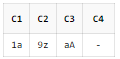
[:digit:] : 숫자, [0-9][:lower:] : 소문자, [a-z][:upper:] : 대문자, [A-Z][:alpha:] : 영문자, [a-zA-Z][:alnum:] : 영문자와 숫자, [0-9a-zA-Z][:xdigit:] : 16진수, [0-9a-fA-F][:punct:] : 구두점 기호, [^[:alnum:][:cntrl:]][:blank:] : 공백 문자
[:space:] : 공간 문자(space, enter, tab)
SELECT REGEXP_SUBSTR('gF1', '[[:digit:]]') AS C1
, REGEXP_SUBSTR('gF1', '[[:alpha:]]') AS C2
, REGEXP_SUBSTR('gF1', '[[:lower:]]') AS C3
, REGEXP_SUBSTR('gF1', '[[:upper:]]') AS C4
, REGEXP_SUBSTR('gF1', '[[:alnum:]]') AS C5
, REGEXP_SUBSTR('gF1', '[[:xdigit:]]') AS C6
, REGEXP_SUBSTR('gF1', '[[:punct:]]') AS C7
FROM DUAL;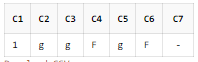
PERL 정규 표현식 연산자
PERL 정규 표현식 연산자는 POSIX 문자 클래스와 유사하게 동작한다.
\d : 숫자, [[:digit:]]
\D : 숫자가 아닌 모든 문자, [^[:digit:]]
\w : 숫자와 영문자(underbar 포함), [[:alnum:]]
\W : 숫자와 영문자가 아닌 모든 문자(underbar 제외, [[:alnum:]]
\s : 공백 문자, [[:space:]]
\S : 공백 문자가 아닌 모든 문자, [^[:space:]]
SELECT REGEXP_SUBSTR('(650) 555-0100', '^\(\d{3}\) \d{3}-\d{4}$') AS C1
, REGEXP_SUBSTR('555-0100', '^\(\d{3}\) \d{3}-\d{4}$') AS C2
, REGEXP_SUBSTR('b2b', '\w\d\D') AS C3
, REGEXP_SUBSTR('b2_', '\w\d\D') AS C4
, REGEXP_SUBSTR('b22', '\w\d\D') AS C5
FROM DUAL;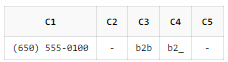
다음은 PERL 정규 표현식 연산자는 수량사와 유사하게 동작한다. 최소로 일치시키는 비탐욕적 방식으로 동작한다.
?? : 0회 또는 1회 일치
*? : 0회 또는 그 이상의 횟수로 일치
+? : 1회 또는 그 이상의 횟수로 일치
{m}? : m회 일치
{m,}? : 최소 m회 일치
{,m}? : 최대 m회 일치
{m,n}? : 최소 m회, 최대 n회 일치
SELECT REGEXP_SUBSTR('aaaa', 'a??aa') AS C1 -- nogreedy 방식
, REGEXP_SUBSTR('aaaa', 'a?aa') AS C2 -- greedy 방식
, REGEXP_SUBSTR('xaxbxc', '\w*?x\w') AS C3
, REGEXP_SUBSTR('aaaa', 'a{2}?') AS C4 -- nogreedy 방식
, REGEXP_SUBSTR('aaaa', 'a{2}') AS C5 -- greedy 방식
, REGEXP_SUBSTR('aaaa', 'a{2,4}') AS C6
FROM DUAL;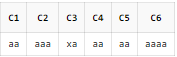
정규 표현식 조건과 함수
가. REGEXP_LIKE 조건
REGEXP_LIKE 조건은 source_char가 pattern과 일치하면 TRUE, 아니면 FALSE 반환
REGEXP_LIKE(source_char, pattern [, match_param])
source_char는 검색 문자열 지정
pattern은 검색 패턴을 지정
match_param은 일치 옵션을 지정(i: 대소문자 무시, c: 대소문자 구분, n: dot(.)를 개행 문자와 일치, m: 다중 행 모드, x:검색 패턴의 공백 문자를 무시, 기본값은 c다. icnmx 형식으로 다수의 옵션을 함께 지정 가능)
SELECT ENAME
FROM EMP
WHERE REGEXP_LIKE(ENAME, 'BL(A|E)KE$');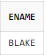
나. REGEXP_REPLACE 함수
REGEXP_REPLACE 조건은 source_char에서 일치한 pattern을 replace_string으로 변경한 문자 값을 반환한다.
REGEXP_REPLACE(source_char, pattern[, replace_string [, position [, occurrence [, match_param]]]])
replace_string은 변경 문자열 지정
position 검색 시작 위치를 지정 (기본값은 1).
occurrence 패턴 일치 횟수를 지정한다 (기본값은 1).
SELECT
REGEXP_REPLACE('010.123.4567'
, '([[:digit:]]{3})\.([[:digit:]]{3})\.([[:digit:]]{4})', '(\1) \2-\3') AS C1
FROM DUAL;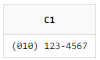
다. REGEXP_SUBSTR 함수
REGEXP_SUBSTR 함수는 source_char에서 일치한 pattern을 반환한다.
REGEXP_SUBSTR(source_char, pattern [, position [, occurrence [, match_param [, subexpr]]]])
subexpr은 서브 표현식을 지정한다 (0은 전체 패턴, 1 이상은 서브 표현식, 기본값은 0)
SELECT
REGEXP_SUBSTR('http://www.example.com/products'
, 'http://([[:alnum:]]+\.?){3,4}/?') AS C1
FROM DUAL;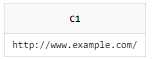
라. REGEXP_INSTR 함수
REGEXP_INSTR 함수는 source_char에서 일치한 pattern의 시작 위치를 정수로 반환한다.
REGEXP_INSTR(source_char, pattern [, position [, occurrence [, return_opt [, match_param [, subexpr]]]]])
return_opt은 반환 옵션을 지정한다.(0은 시작 위치, 1은 다음 위치, 기본값은 0).
SELECT REGEXP_INSTR('1234567890', '(123)(4(56)(78))', 1, 1, 0, 'i', 1) AS C1
, REGEXP_INSTR('1234567890', '(123)(4(56)(78))', 1, 1, 0, 'i', 2) AS C2
, REGEXP_INSTR('1234567890', '(123)(4(56)(78))', 1, 1, 0, 'i', 3) AS C3
FROM DUAL;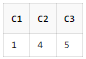
마. REGEXP_COUNT 함수
REGEXP_COUNT 함수는 source_char에서 일치한 pattern의 횟수를 반환한다.
REGEXP_COUNT(source_char, pattern [, position [, match_param]])
SELECT REGEXP_COUNT('123123123123123', '123', 1) AS C1
, REGEXP_COUNT('123123123123', '123', 3) AS C2
FROM DUAL;