code review
코드리뷰를 했는데 신기하게 작성하신 부분이 있었다.
이 부분을
if (!strcasecmp(method, "GET") == 0 || strcasecmp(method, "HEAD" == 0
아래와 같이 작성하셨다.
if (strcasecmp(method,"GET") && strcasecmp(method, "HEAD"))
처음엔 && 연산자라 참이 되려면 method가 GET이면서 HEAD여야 하는 것 아닌가라고 생각했는데 내 생각은 틀렸었다.
만약에 'POST'가 메소드로 들어오면 && 연산자 앞에도 참, 뒤에도 참이 되어 조건문이 돌아가게 된다.
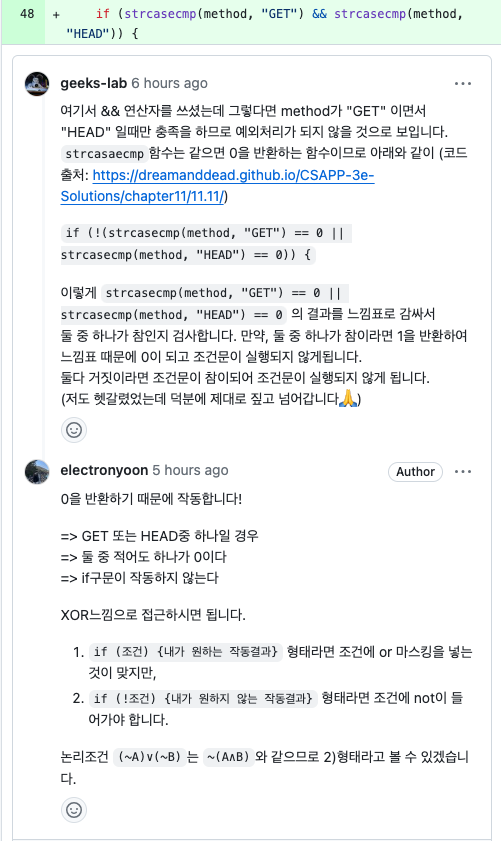
그런데 논리조건 (~A)v(~B)는 ~(A^B)이므로 !(A|B) = A&B 이라는게 조금 이해되지 않는 부분이 있다. 뒷 부분이 !(A&B)가 아니라 A&B여도 가능하다는게 의아하다.
과제 introduction 읽기
https://casys-kaist.github.io/pintos-kaist/project1/introduction.html
[한국어 번역]
https://yjohdev.notion.site/PROJECT-1-THREADS-cf2a6ae9d6294141b48c8608f118e89c
[요약]
- 쓰레드가 생성될 때 스케줄링의 대상이 되는 새로운 context가 생성된다.
- 이 문맥에서 어떤 함수를 실행하고자 하는 경우 thread_create()의 인자로 실행하고자 하는 함수를 넣으면 된다.
csapp
Application-level concurrency is useful in many ways
Concurrency: 여러 계산을 동시에 수행하는 시스템 특성
- Accessing slow I/O devices - 애플리케이션이 디스크와 같이 느린 I/O 장치로부터 데이터를 기다릴 때, 커널은 다른 프로세스를 실행해서 CPU를 바쁘게 유지한다.
- Interacting with humans - 문서를 인쇄하는 동안 창의 크기를 조절하는 것.
- Reducing latency by deferring work - 때로 애플리케이션은 어떤 특정 연산의 지연 속도를 줄이기 위해 병행성을 사용할 수 있다.
- Servicing multiple network clients - concurrent server를 통해 한번에 여러 클라이언트를 서비스 할 수 있는 서버를 구축할 수 있다. 서버는 각 클라이언트에 대해 각각의 로지컬한 플로우를 생성한다.
- Computing in parallel on multi-core machines - concurrent 플로우로 분할된 애플리케이션은 종종 단일 코어 프로세서의 머신보다 멀티코어 머신에서 훨씬 빠르게 실행됨.
Three basic approaches for building concurrent programs
-
Processes
concurrent 프로그램을 만들기 위한 프로세스 접근방식은 논리적 제어 흐름이 커널에 의해 예약/유지 되기 때문에 프로세스는 별도의 가상주소 공간을 가진다. 따라서, 서로 통신하기 위해서는 명시적인interprocess communication (IPC)메카니즘을 사용해야만 한다. -
I/O multiplexing
이 접근 방식은 애플리케이션이 싱글 프로세스에서 각 로지컬 플로우를 명시적으로 스케줄하는 방식이다. 프로그램이 하나의 프로세스이기 때문에 모든 flow는 동일한 주소 공간을 공유한다. -
Threads
스레드는 커널에 의해 스케줄되고 하나의 프로세스 컨텍스트에서 실행된다. I/O 다중화처럼 동일한 가상 주소 공간을 공유한다.
OSTEP
4. Processes
- 프로세스 : 프로그램이 실행되는 상태. 하나의 프로그램에서 여러개의 프로세스 생성 가능. 코드는 스택자료구조.
- 시분할 기법 : 자원 공유를 OS가 사용하는 가장 기본 기법 중 하나. 소수의 CPU로 여러 개의 가상 CPU가 존재하는 듯한 효과를 냄으로써 원하는 수 만큼 프로세스를 동시에 실행할 수 있게 한다. -> CPU를 공유하기 때문에 각 프로세스의 성능은 낮아지게 된다.
- 매커니즘 : 필요한 기능을 구현하는 방법이나 규칙을 의미한다. OS에서 CPU 가상화를 잘 구현하기 위해 사용하는 저수준 도구.
- 하드웨어 상태: 프로그램이 실행되는 동안 하드웨어 상태를 읽거나 갱신할 수 있다.
- 프로세스의 하드웨어 상태 중 가장 중요한 구성요소는 메모리. 명령어도 데이터도 메모리에 저장된다. 프로세스가 접근할 수 있는 메모리 is called 주소 공간(address space)
- 프로세스의 하드웨어 상태의 다른 구성요소 is register. 특별한 registers : 프로그램 카운터(PC, 프로그램의 어느 명령어가 실행 중인지 알려줌. aka 명령어 포인터(IP))
- 프로그램은 영구 저장장치에 접근하기도 한다.
[프로세스 기본 기능]
- 생성 : 운영체제는 새로운 프로세스를 생성할 수 있는 방법을 제공해야 함.
- 제거 : 강제로 제거할 수 있는 인터페이스도 제공해야함.
- 대기 : 때로 어떤 프로세스의 실행 중지를 기다릴 필요가 있기 때문에 여러 종류의 대기 인터페이스 제공해야함.
- 각종 제어(Miscellaneous Conrol) : 일시정지/재개 기능.
- 상태 : 프로세스 상태 정보를 얻어내는 인터페이스 제공 해야함(상태정보에 얼마동안 실행되었는지 프로세스가 어떤 상태에 있는지 등).
4.3 process 생성
OS가 프로세스 생성할 때 해줘야 하는 작업들
-
코드와 정적데이터를 메모리의 프로세스 주소 공간에 load
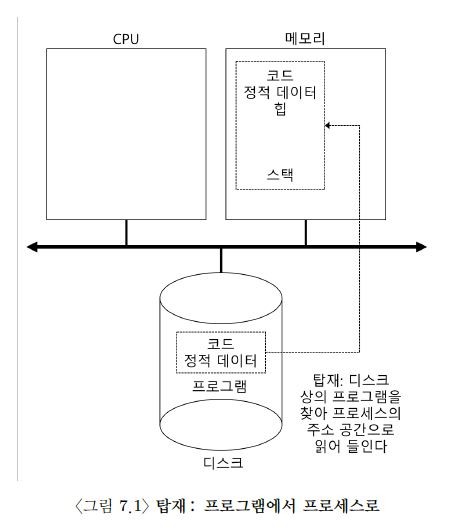
초기 OS들은 프로그램 실행 전에 코드와 데이터를 모두 메모리에 직접 load하였지만 현대 OS들은 이 작업을 늦춘다. 즉, 프로그램을 실행하면서 필요한 부분만 필요할 때 메모리에 탑재한다. 이와 관련 된 기법이 paging과 swapping이다. -
OS allocates stack memery for 정적 데이터 and heap memory for 동적 할당
-
입출력 셋업
OS initializes File Descriptor for I/O tasks. 파일 디스크립터는 표준 입력, 표준 출력, 표준 에러를 기본적으로 가짐.
여기까지 하면 운영체제는 프로그램 실행을 위한 준비를 마침 -> main() 루틴으로 분기함 -> OS는 CPU를 새로 생성된 프로세스에게 넘김 -> 프로세스 시작
4.4 process 상태
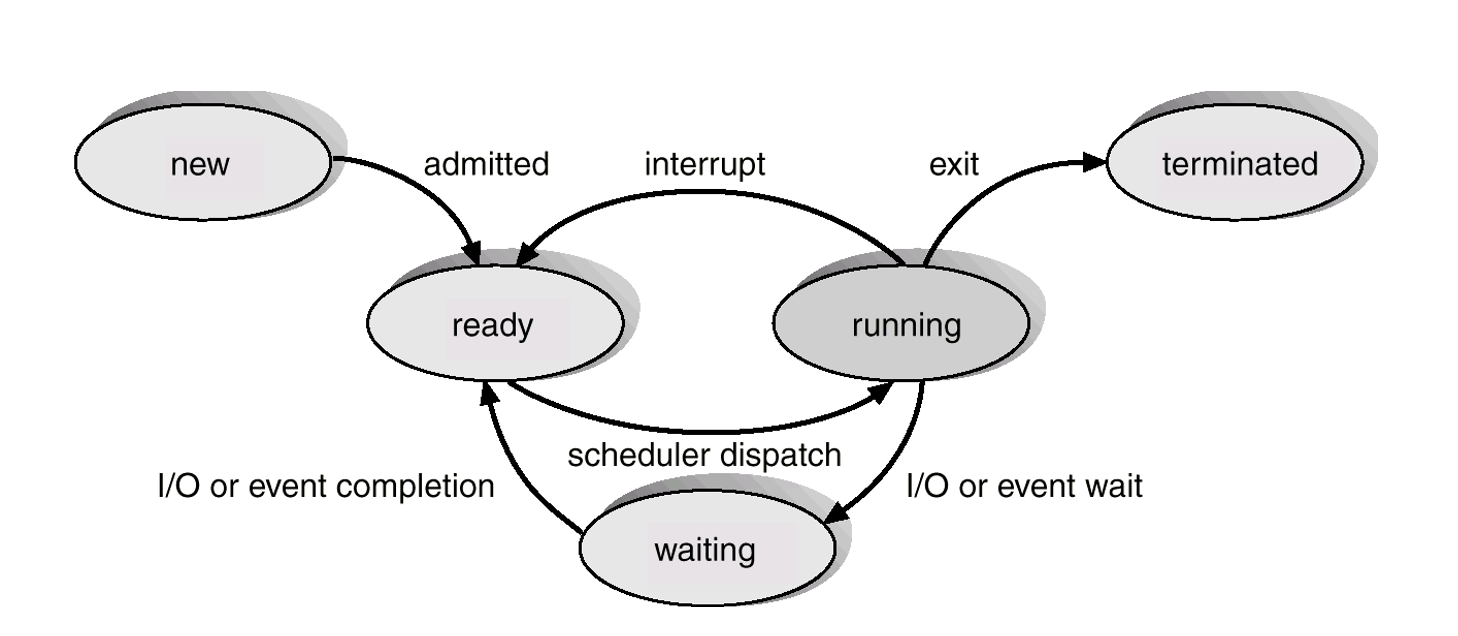
- 신규 new - 프로세스가 생성 중
- 준비 ready - 프로세스가 설정되어 대기 중
- 실행 running - 프로세스 실행 중
- 대기 waiting - 프로세스가 이벤트 발생을 대기 중
- 종료 terminated - 프로세스가 실행을 종료
4.5 process의 자료구조

- 프로세스 리스트 for each 실행중인 프로세스, 준비중인 프로세스, 대기중인 프로세스.
- 레지스터 자료구조는 프로세스가 중단되었을 때 해당 프로세스의 레지스터 값들을 저장함. 나중에 다시 재개할 때는 이 레지스터의 값들을 복원하는데 이를 문맥 교환(context switch)라 함.
4.6 프로세스 제어 블록(PCB)
- 특정 프로세스에 대한 변화하는 모든 정보를 가진 데이터 블록
- 프로세스가 문맥 교환을 할 때에 프로세스의 상태를 프로세스 제어 블럭(process control block, PCB) 에 저장함

위의 그림에 나와있는 구성 외에도 우선순위를 위한 스케줄링 정보도 PCB에 있다.
4.7 프로세스 스케줄링
- 스케줄링 큐 : 스케줄링을 위해서 PCB들이 연결되는 큐가 필요함
큐의 종류
* 작업 큐(job queue) : 프로세스가 시스템에 들어가면 작업 큐에 입력
* 준비 큐(ready queue) : 주기억 장치에 상주하면서 준비 상태에서 실행을 기다리는 프로세스들로 구성
* 장치 큐(device queue) : 특정 입출력 장치를 대기하는 프로세스들의 리스트4.8 프로세스간 통신(IPC)
-
프로세스들간의 관계는 독립적이거나 또는 협동적임
- 독립적인 경우 다른 프로세스의 영향을 받지 않음/주어진 초기 치에 대해 항상 같은 결과를 도출
- 협동적인 경우 다른 프로세스에게 영향을 주거나 받음
-
협동 프로세스가 필요한 이유: 정보 공유, 연산속도 증가, 모듈성
-
협동 프로세스는 프로세스간 통신과 동기화 매커니즘 필요
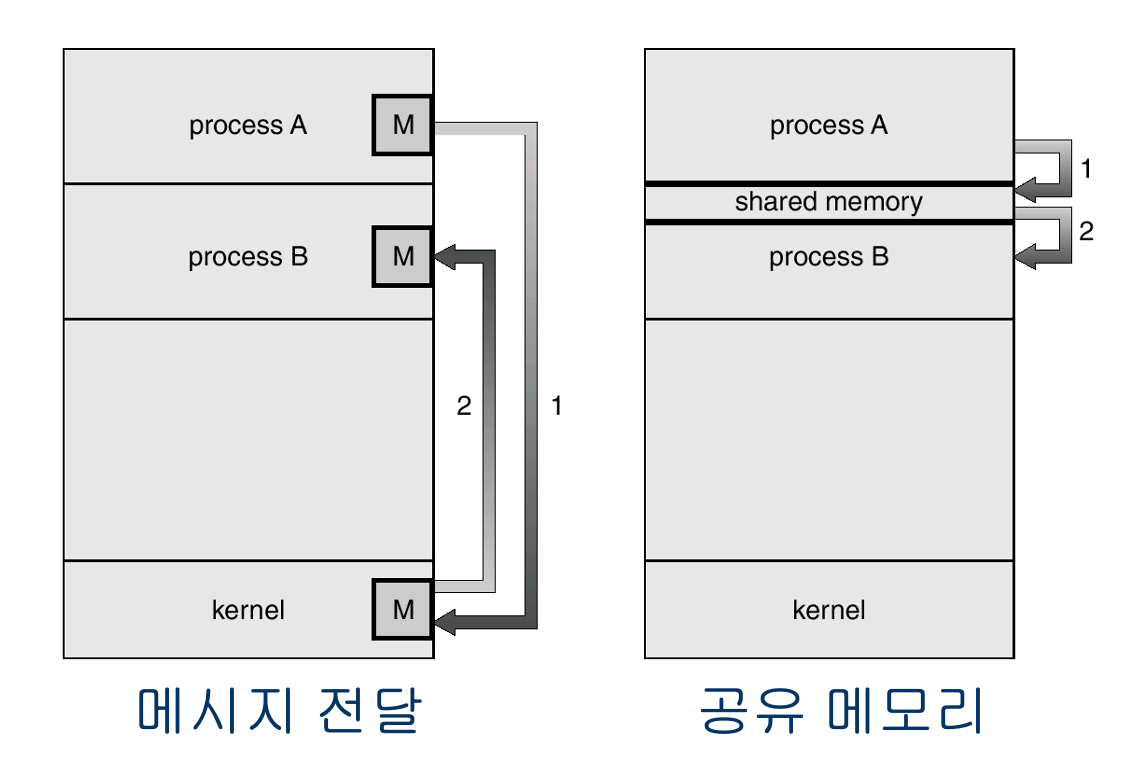
-
메세지 전달 시스템의 기본 구조
- 두 가지 연산 : send/receive
- 통신 연결을 설정하고 send/receive를 통해 메세지 교환
4.9 공유 메모리 시스템
- 통신을 위해 프로세스 사이의 공유 메모리 영역 구축
- 일반적으로 OS는 한 프로세스가 다른 프로세스의 메모리에 접근하는 것을 금지
- 둘 이상의 프로세스가 위의 제약 조건을 제거하는 것에 동의
- 여러 개의 프로세스 들이 동시에 동일한 위치에 쓰지 않도록 관리(임계영역 문제)
- 생산자/소비자 문제(e.g. 입력기/출력기)
- 생산자의 속도와 소비자의 속도는 서로 독립적이므로 버퍼가 필요
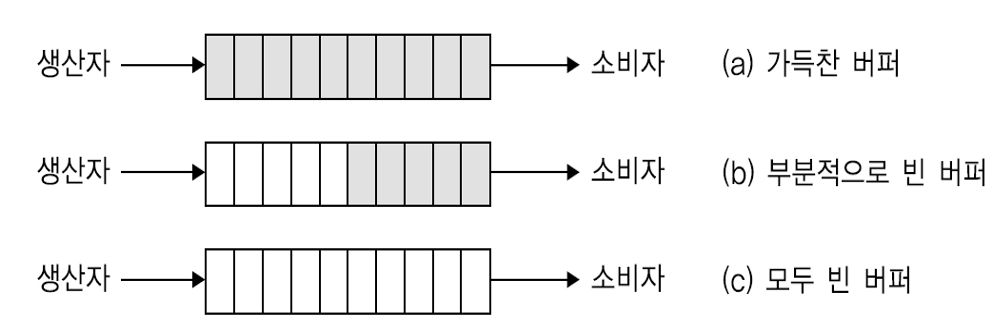
- 여기서 발생하는 또다른 문제는 (a)일 때 생산자가 채우려하거나 (c)일때 소비자가 꺼내려 할 때이다.
- 생산자의 속도와 소비자의 속도는 서로 독립적이므로 버퍼가 필요
26. Concurrency and Threads
프로세스가 문맥 교환을 할 때에 프로세스의 상태를 프로세스 제어 블럭(process control block, PCB) 에 저장하듯이 프로세스의 쓰레드들의 상태를 저장하기 위해서는 하나 이상의 쓰레드 제어 블럭(TCB)이 필요함
차이점은 프로세스 경우와 달리 쓰레드 간의 문맥 교환에서는 주소 공간을 그대로 사용한다는 것이다.(사용하던 페이지 테이블을 그대로 사용함)
- 단일 쓰레드 프로세스에서는 스택이 하만 존재함 but 멀티 쓰레드 프로세스에서는 쓰레드마다 스택이 할당되어 있음
(각 쓰레드가 독립적으로 실행됨)
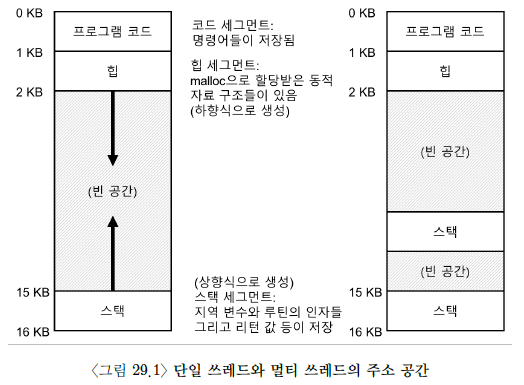
왼쪽은 싱글 쓰레드, 오른쪽은 멀티 쓰레드
병행성과 관련된 용어
임계 영역(critical section) : 보통 변수나 자료구조와 같은 공유자원을 접근하는 코드의 일부분을 말한다.경쟁조건(race condition) : 멀티쓰레드가 거의 동시에 임계 영역을 실행하려고 할 때 발생한다. 공유 자료 구조를 모두가 갱신하려고 시도한다면 깜짝 놀랄 의도하지 않은 결과를 만든다.비결정적(indeterminate) : 프로그램의 결과가 실행할 때마다 다르다. 왜냐하면 프로그램 경쟁조건을 포함하여 각 쓰레드가 실행된 시점에 의존하기 때문이다.- 비결정적인 문제를 회피하기 위해
상호배제라는 기법을 사용해서 하나의 쓰레드만이 임계 영역에 진입할 수 있도록 보장한다.
쓰레드
모든 프로세스가 쓰레드를 포함하는 것은 아니다. 프로세스는 경량 프로세스와 중량 프로세스로 나뉜다.
- 프로세스에서 실행 제어만 분리한 실행 단위 : 경량 프로세스
- 쓰레드를 포함하는 프로세스 : 중량 프로세스
쓰레드가 왜 필요한가? 문맥 교환이 용이하지 않은 자원들을 공유하기 위해서 !
메모리 및 일부 주변 장치는 문맥 교환에 과다한 시간을 소비하기 때문에 쓰레드를 이용하여 문맥 전환에 용이하다.
쓰레드는 결국 자원을 공유하기 위함이라서 한 프로세스에서 다른 프로세스로 제어가 넘어가면 이들의 자원이 바뀌므로 초기화된다.
쓰레드의 장점
- 사용자에 대한 응답성 증가
- 자원과 메모리 공유 가능(IPC 프로그램 용이)
- 경제성 - 자원 할당 개수를 줄이고 문맥교환 오버헤드를 줄인다
- 다중 프로세서 구조 활용 가능
