공부 키워드
User mode vs Kernel mode
User mode
- 한정된 권한: 보안과 안정성을 위해 유저 모드에서는 실행 중인 프로그램이 시스템 리소스에 직접 접근할 수 있는 권한이 제한되어 있다.
- 응용 프로그램 실행: 주로 응용프로그램은 응용 프로그램에서 실행된다. 사용자가 작성한 프로그램도 유저모드에서 동작한다.
- 시스템 콜 호출: 유저 모드에서 커널모드로의 전환은 exception(인터럽트, 폴트, 트랩핑 시스템 콜과 같은)을 통해 이루어진다. 사용자 프로그램이 커널의 서비스를 필요로 할 때, 시스템콜을 호출하여 커널모드로 전환하고 필요한 작업을 커널에서 수행하고 다시 유저모드로 돌아온다.
이 부분에 대한 책에 나와있는 내용은 이렇다.
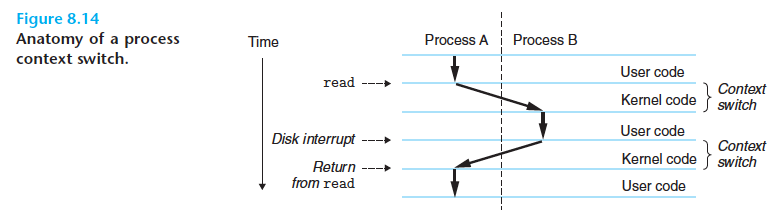
Exception이 발생하고 control이 exception handler한테 전달될 때, 프로세서는 유저모드에서 커널모드로 바꾼다. 그리고 나서 어플리케이션 코드로 돌아왔을 때 프로세서는 모드를 커널모드에서 다시 유저모드로 변경한다.(csapp p.761)
Kernel Mode
- 전체 권한: 커널 모드에서 실행중인 코드는 시스템의 모든 자원에 대한 완전한 권한을 갖는다.
- 운영 체제 수행: 운영체제의 핵심 부분인
커널은 커널모드에서 동작한다. 커널은 하드웨어 리소스를 관리하고 다양한 프로세스 간의 스케줄링 및 통신을 담당한다.이 부분에 대한 책에 나와있는 내용은 이렇다.
커널은 각 프로세스마다context를 유지한다.context는 선점된 프로세스를 다시 시작하기 위해 커널이 필요로 하는 상태이다. 이context는 아래와 같은 값의 오브젝트로 구성되어 있다.
general-purpose registers, the floating-point registers, the
program counter, user’s stack, status registers, kernel’s stack, and various kernel
data structures such as a page table and a file table(csapp p.762) - 인터럽트 및 예외 처리: 커널 모드에서는 하드웨어 인터럽트 및 예외를 처리할 수 있다. 이는 운영 체제가 하드웨어 이벤트에 반응하고 시스템을 안정적으로 유지하기 위해 필요한 기능이다.
🙋🏻quick question: 커널이 실행되고 있는 동안 문맥교환이 발생할 수 있을까?
정답은 "있다"
-> 커널은 유저를 대신해서 시스템콜을 실행해서 context switch를 일어나게 할 수 있다. 대표적으로sleep시스템콜이 있다.
시스템은 일반적으로 주기적인 타이머 인터럽트를 생성하는 메커니즘을 가지고 있고 이 인터럽트는 일반적으로 1ms 또는 10ms마다 발생한다. 타이머 인터럽트가 발생할 때마다 커널은 현재 프로세스가 충분히 실행되었다고 판단하고 새로운 프로세스로 전환할 수 있다.
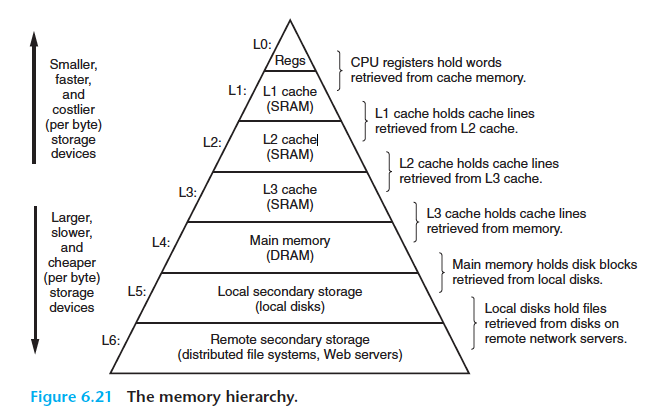
Register vs Memory
공통점
- 데이터 저장: Register와 Memory는 모두 데이터를 저장하는 용도
- CPU와 상호작용: CPU와 직접적으로 상호 작용하여 데이터 처리 및 프로그램 실행에 기여함
- 핵심적 하드웨어 구성 요소: 둘 다 컴퓨터 시스템의 핵심 하드웨어 구성 요소임
차이점
-
저장 용량과 속도: Register와 Memory는 모두 데이터를 저장하는 용도
-
용도: register는 주로 CPU의 연산 및 제어 목적으로 사용되고, Memory는 데이터와 프로그램 코드를 저장하는데 사용됨. (메모리는 주 기억장치(메인메모리)와 보조 기억장치로 나뉨)
- 주 기억장치 (Main Memory 또는 RAM):
주로 현재 실행 중인 프로그램 및 데이터를 임시로 저장하는 용도로 사용됩니다.
CPU가 직접 액세스할 수 있는 공간이며, 빠른 속도로 데이터에 접근할 수 있습니다. 전원이 꺼지면 저장된 데이터가 소멸된다.
* 보조 기억장치 (Secondary Storage):
데이터의 영구 저장을 담당하며, 주로 하드 디스크, SSD, 광 디스크 등이 포함됩니다.
주로 대용량 데이터와 프로그램이 저장되어, 전원이 꺼져도 데이터가 보존됩니다.
- 주 기억장치 (Main Memory 또는 RAM):
-
접근방식: Register는 직접적인 연산 및 명령어 수행에 사용되므로 CPU 내부에서 직접적으로 접근된다. Memory는 CPU가 주소를 통해 간접적으로 access한다.
User Stack
힙과 마찬가지로 유저 스택은 프로그램 실행 중에 동적으로 확장 및 축소된다. 함수를 호출할 때마다 스택이 확장되고, 함수에서 반환할 때마다 축소된다.
유저스택은 가장 큰 유효한 사용자 주소(2^48-1) 아래에서 시작해서 작은 메모리 주소 방향으로 즉, 아래로 자란다.
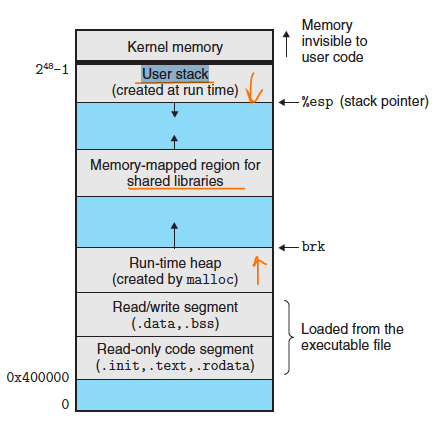
여기서 스택을 break down 해보면 아래와 같다.
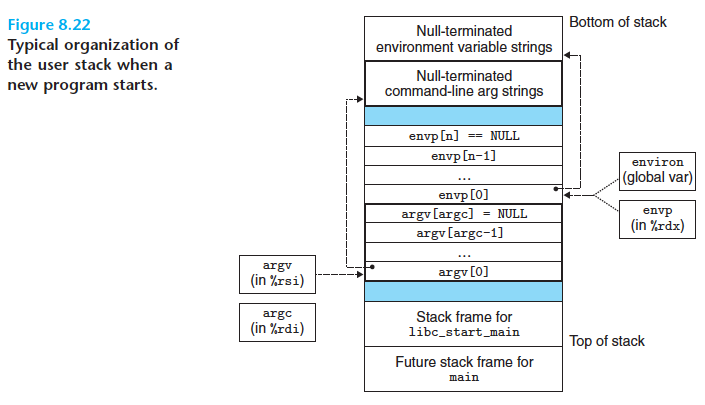
(스택의 가장 밑바닥부터 - 윗윗 그림에서는 맨위, 바로 위 그림에서는 맨 아래칸부터)
스택 프레임스택의 맨 밑에는 system start-up function,libc_start_main이라는 스택프레임이 있다.argv- argv[0], ... argv[argc-1], argv[argc] = NULLargv라는 포인터 변수는 각각 인자 문자열을 가리키는 포인터로 이루어진 null로 끝나는 배열을 가르키고 있다.- 유저-레벨 어플리케이션은
%rdi,%rsi,%rdx,%rcx,%r8,%r9시퀀스들을 전달하기 위해 정수 레지스터를 사용합니다.(리턴값이 있다면 %rax에 저장됨) %rsi를 argv 주소(argv[0]의 주소)를 가리키게,%rdi를 argc 로 설정합니다.
envp- envp[0], ... envp[n-1], envp[n] == NULLenvp포인터 변수는 null로 끝나는 포인터 배열을 가르키며 각 포인터는 환경변수 문자열을 가르키고 있다. (각 문자열은 name=value 형식의 name-value의 쌍으로 구성된다)
argc와argv의 차이
1.argc(Argument Count):
argc는 명령행 인자의 개수를 나타냅니다.- 프로그램을 실행할 때 명령행에 전달되는 인자의 총 개수가 여기에 저장됩니다.
- 프로그램 실행 시 최소한 1이며, 프로그램 이름 자체도 하나의 인자로 간주됩니다.
argv(Argument Vector):
argv는 명령행 인자의 배열이며, 각 요소는 문자열로서 하나의 명령행 인자를 나타냅니다.argv[0]은 프로그램의 이름을 가리킵니다.argv[1],argv[2], ... 등은 추가적인 명령행 인자를 가리킵니다.
Null-terminated environment variable strings
(null-terminated array of pointers, which points to an envrionment variable string on the stack.environ이라는 전역변수가 해당 포인터들의 첫번째 요소를 가르킨다(envp[0])).Null-terminated command-line arg strings
System Call
csapp p.756
exception 두가지
- external device hw exception=interrupt
- user로 부터의 sw exception=fault, trap, abort
File Descriptor
개념 복습
파일 디스크립터 in terms of File I/O : 파일을 열거나 읽거나 쓸 때 시스템은 각 파일에 대해 고유한 파일 디스크립터를 할당한다.
이 file descriptor는 파일에 대한 이후 모든 작업에서 사용됨
커널은 열린 파일에 대한 모든 정보를 추적. 애플리케이션은 디스크립터만 추적.
리눅스 쉘에 의해 생성된 프로세스는 세 개의 열린 파일을 가진다.
- 표준 입력 - descriptor 0
- 표준 출력 - descriptor 1
- 표준 에러 - descriptor 2
open 함수는 파일 이름을 파일 디스크립터로 변환하고 해당 디스크립터 번호를 반환합니다. 반환된 디스크립터는 항상 프로세스에서 현재 열려 있지 않은 가장 작은 디스크립터입니다. flags 인자는 프로세스가 파일에 접근할 의도를 나타냅니다.
Cache
1. 캐시의 동작 원리:
Locality (지역성): 프로그램이 특정 데이터나 명령어에 접근할 때, 이와 주변에 있는 데이터에 대한 접근이 높은 확률이 있습니다. 캐시는 이러한 지역성을 활용하여 주로 사용되는 데이터를 저장합니다.
캐시 블록과 세트: 캐시는 일정 크기의 블록으로 데이터를 저장하며, 이러한 블록들을 셋(set)으로 구성합니다. 블록은 일반적으로 메모리에서 연속된 주소 공간을 차지하며, 각 블록은 캐시의 한 셋에 속합니다.
캐시 태그: 캐시에 저장된 데이터가 메모리에서 어디에 위치하는지를 나타내기 위해 태그(tag)라는 정보를 사용합니다. 캐시에 저장된 데이터에 접근할 때, 태그와 비교하여 원하는 데이터를 찾습니다.
캐시 미스(Cache Miss)와 비용: 캐시에 데이터가 없어서 메모리에서 가져와야 할 때, 이를 캐시 미스라고 합니다. 캐시 미스는 비용이 높은 작업으로 간주되며, 메모리로부터 데이터를 읽어와 캐시에 적재합니다.
2. 캐시 메모리의 설계와 최적화:
적절한 크기와 조직: 캐시의 크기와 조직은 성능에 큰 영향을 미칩니다. 적절한 캐시 크기와 구조를 선택하여 데이터 지역성을 잘 활용하는 것이 중요합니다.
캐시 지역성 활용: 시간 지역성(특정 데이터가 재사용되는 경향)과 공간 지역성(한 번에 여러 데이터가 사용되는 경향)을 활용하여 캐시의 효율을 높일 수 있습니다.
3. 캐시 미스(Cache Miss)의 비용:
Cold Miss: 처음 발생하는 캐시 미스. 초기화되지 않은 데이터에 접근할 때 발생하며, 초기 비용이 높을 수 있습니다.
Conflict Miss: 캐시의 한 셋에 여러 데이터가 들어가 있는 경우 발생하는 미스. 캐시의 셋 수를 늘리거나 다양한 방법으로 충돌을 해결해야 합니다.
Capacity Miss: 캐시가 꽉 차서 새로운 데이터를 적재할 수 없는 경우 발생하는 미스. 캐시 크기를 늘리거나 교체 알고리즘을 최적화하여 해결할 수 있습니다.
4. 캐시 지역성:
시간 지역성(Time Locality): 특정 데이터에 한 번 접근하면 가까운 시간 내에 다시 접근할 확률이 높음.
공간 지역성(Spatial Locality): 특정 데이터에 접근하면 그 주변의 데이터에도 접근할 확률이 높음.
Atomic Operation
개념 복습
원자적 연산은 다른 스레드나 프로세스의 동시적인 접근에 대해 불변성을 보장하는 연산입니다. 이는 연산이 전체적으로 완전히 실행되거나 전혀 실행되지 않는 것을 의미합니다. 즉, 다른 연산이 중간에 끼어들거나 일부만 실행되지 않습니다.
원자적 연산은 다중 스레드 환경에서 공유 자원에 안전하게 접근하기 위해 사용됩니다. 여러 스레드가 동시에 같은 자원에 접근하는 경우, 원자적 연산을 사용하면 경쟁 조건(Race Condition)과 같은 문제를 방지할 수 있습니다.
pintos project 에서의 원자적 연산
인터럽트 비활성화 및 활성화:
intr_disable() 및 intr_enable() 함수를 사용하여 인터럽트를 비활성화하고 활성화합니다. 이러한 함수는 인터럽트를 원자적으로 다루어 공유 자원에 대한 안전한 접근을 보장합니다.
임계 영역 진입 및 이탈:
lock_acquire() 및 lock_release() 함수를 사용하여 임계 영역에 진입하고 이를 이탈합니다. 이 함수들은 락(lock)을 원자적으로 획득하고 해제하여 여러 스레드 간의 동기화를 제어합니다.
Condition Variable 조작:
cond_wait(), cond_signal(), cond_broadcast() 함수를 사용하여 condition variable을 조작합니다. 이러한 함수들은 스레드 간의 신호 전달 및 대기를 원자적으로 처리합니다.
세마포어 조작:
sema_down() 및 sema_up() 함수를 사용하여 세마포어를 조작합니다. 세마포어는 스레드 간의 상호 배제와 동기화를 위해 사용되며, 이러한 함수들은 세마포어를 원자적으로 다룹니다.
페이지 테이블 조작:
페이지 테이블에 접근할 때 원자적으로 조작해야 합니다. 페이지 테이블 업데이트와 관련된 연산들은 스레드 간의 메모리 관리에서 중요한 부분이기 때문입니다.
파일 디스크립터 관리:
파일 디스크립터를 할당하거나 해제할 때 원자적으로 조작해야 합니다. 파일 디스크립터를 관리하는 동안 스레드 간의 충돌을 피하기 위해 특히 주의해야 합니다.
rax register
rax 레지스터는 x86 아키텍처에서 사용되는 64비트 레지스터 중 하나입니다. 이 레지스터는 다양한 목적으로 사용되며, 그 중 일부는 다음과 같습니다:
-
함수 반환 값: 함수가 값을 반환할 때, 보통
rax레지스터에 반환값이 저장됩니다. 이 규칙은 x86_64 아키텍처에서 cdecl 호출 규약을 따르는 경우에 해당합니다. -
시스템 호출 인터페이스 (System Call Interface): x86_64 리눅스에서는 시스템 호출 시
rax레지스터에 시스템 호출 번호가 저장됩니다. 시스템 호출의 종류를 나타내는 중요한 정보를 포함합니다. -
산술 연산:
rax레지스터는 일반적인 산술 연산에 사용됩니다. 산술 연산 결과가 여기에 저장됩니다. -
임시 데이터 저장: 함수나 루틴에서 임시로 데이터를 저장하는 데 사용될 수 있습니다.
-
부울 플래그 반환: 어셈블리 레벨에서는 일부 명령이 실행 후 상태에 따라
rax레지스터에 부울 플래그 값을 저장할 수 있습니다. -
메모리 주소 저장: 포인터나 메모리 주소를 저장하는 데도 사용될 수 있습니다.
이외에도 다양한 용도로 rax 레지스터가 활용될 수 있습니다. 프로그램이나 컨텍스트에 따라서 그 목적이 달라집니다.
32 bit OS vs 64 bit OS
| 특성 | 32비트 운영 체제 | 64비트 운영 체제 |
|---|---|---|
| 주소 공간 (가상 메모리) | 4GB (2^32 바이트) | 18.4 million TB (2^64 바이트) |
| 레지스터 크기 | 32비트 | 64비트 |
| 주소 버스 크기 | 32비트 | 64비트 |
| 물리 메모리 크기 | 4GB | 16EB (Exabyte, 2^60 바이트) |
| 포인터 크기 | 32비트 | 64비트 |
| 레지스터의 갯수 | 적은 수 | 더 많은 수 |
| 성능 향상 | 64비트 아키텍처에 최적화 | 더 큰 레지스터, 물리 메모리 지원 |
| 소프트웨어 호환성 | 32비트 소프트웨어 지원 | 32비트 및 64비트 소프트웨어 모두 지원 |
| 운영 체제 및 응용 프로그램 | 일반적으로 32비트 | 64비트로 제작된 운영 체제 및 응용 프로그램 |
