
쿠버네티스를 배우기로 한 당신의 결정은 정말 멋진 거에요! Docker로 서버를 관리하다가 "이거 다 합쳐서 한 번에 관리하면 얼마나 좋을까?"라고 생각한 순간부터 쿠버네티스와의 인연이 시작된 거죠. 그리고 네, 구글이 똑같은 고민을 해서 탄생시킨 게 바로 쿠버네티스랍니다. YouTube 같은 거대한 서비스를 관리하면서 그들도 "이걸 어떻게 한 번에 잘 관리하지?"라는 질문을 했었고요.
쿠버네티스를 공부하기 전에 그 역사를 알고 싶다는 당신의 접근 방식은 정말 인상적이에요. 무언가의 배경을 이해하면 그것을 더 깊게 이해할 수 있으니까요. Borg라는 구글의 내부 시스템에서 발전된 쿠버네티스! 정말 흥미롭죠?
이제 쿠버네티스의 구성 요소를 살펴볼 시간이에요. 공식 문서를 뒤져보면 정말 친절하게 설명되어 있는데, 그걸 좀 더 친근하고 재미있게 풀어볼게요.
구성도를 일단 볼까요??
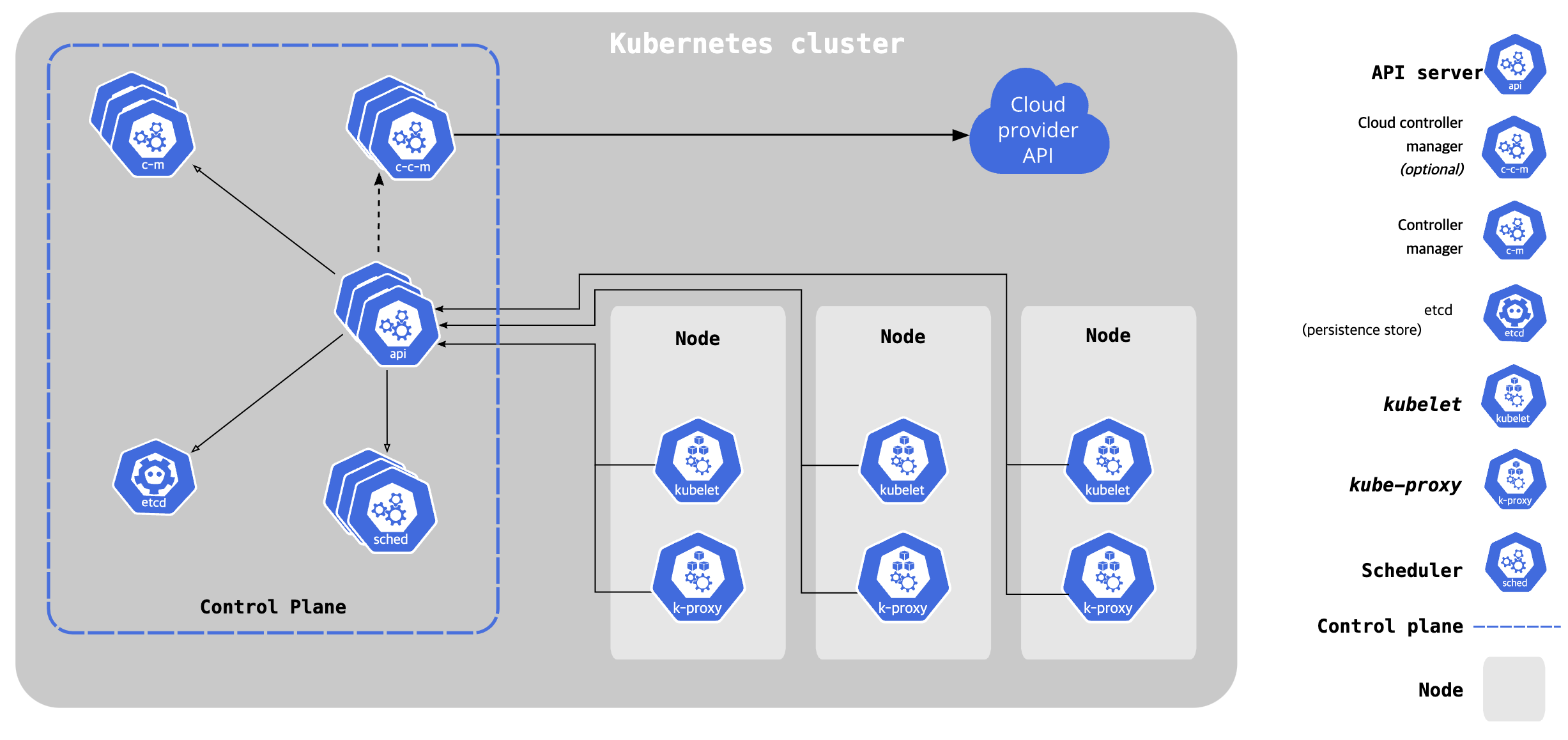
API 서버 (kube-apiserver)
이론 : 쿠버네티스 API의 중심이 되는 컴포넌트입니다. 모든 내부 컴포넌트들은 이 API 서버를 통해 통신합니다. 사용자, 외부 시스템, 클러스터 내부의 다른 컴포넌트들은 모두 이 API 서버를 통해 클러스터와 상호작용합니다.
현실: 마치 공장의 사무실 같아요. 여기서 모든 일이 결정되고, 모든 정보가 오가죠. 클러스터의 두뇌와도 같은 곳이에요.
etcd
이론: 쿠버네티스 클러스터의 모든 상태 정보를 저장하는 분산 키-값 저장소입니다. 클러스터의 중요 정보를 저장하고, 각종 설정, 상태, 메타데이터를 관리합니다.
현실: 이건 마치 공장의 안전 금고라고 할 수 있어요. 모든 중요한 문서, 설계도, 레시피가 여기에 잘 보관되어 있죠.
스케줄러 (kube-scheduler)
이론: 새로 생성된 파드를 감지하고, 실행할 노드를 선택하는 컴포넌트입니다. 스케줄러는 파드의 요구 사항, 각 노드의 자원 사용량, 정책 제약 조건 등을 고려하여 파드를 배치합니다.
현실: "너는 A 공장 가! 너는 B 라인으로!" 하며 작업자들을 지휘하는 공장의 작업 배치 담당자 같은 역할이에요.
컨트롤러 매니저 (kube-controller-manager)
현실: 이건 마치 공장의 품질 관리팀이에요. 모든 게 잘 돌아가고 있는지, 문제가 생기면 바로바로 대응하죠.
kubelet
이론: 각 노드에서 실행되는 에이전트로, API 서버로부터 파드를 할당받고, 해당 파드의 컨테이너가 정상적으로 실행되고 있는지 관리합니다. 컨테이너의 생명주기 관리, 볼륨 마운트, 네트워크 설정 등을 담당합니다.
현실 :각 노드(공장의 작업 부서)에 있는 똑똑한 관리자에요. 지시받은 작업을 잘 수행하는지, 뭔가 필요한 건 없는지 늘 체크하죠.
네트워크 프록시 (kube-proxy)
이론: 각 노드에서 실행되는 네트워크 프록시로, 서비스의 네트워크 통신을 처리합니다. 서비스의 IP 주소와 포트를 사용하여 파드 간 또는 외부 네트워크와의 통신을 가능하게 합니다.
현실 :공장 내의 전화 교환원 같은 역할이에요. 데이터가 필요한 곳으로 잘 전달되도록 돕죠.
이 모든 걸 좀 더 인간적이고 재미있게 생각해보면, 쿠버네티스가 그리 어렵지 않다는 걸 깨달을 수 있어요. 쿠버네티스는 마치 잘 조직된 공장처럼 각기 다른 부품들이 모여 완벽한 시스템을 이루는 거랍니다. 이제 당신도 이 멋진 시스템의 일부가 될 준비가 된 거죠!
