Partition
Partition이란 MySQL Server에서는 데이터를 별도의 테이블로 분리해서 저장하지만 사용자는 여전히 하나의 테이블로 읽기와 쓰기를 할 수 있게 해주는 솔루션이다.
Partition은 DBMS 하나의 서버에서 테이블을 분산하는 것이다.
원격 서버 간에 분산을 지원하는 것은 아님
MySQL 5.1부터 제공되는 파티션 기능은 MyISAM과 InnoDB 테이블 등 대부분의 스토리지 엔진에서 사용 가능하다.
MySQL에서 Partition은 Range, List, Hash, Key 이렇게 총 네 가지방법이 존재한다.
이외에 서브 파티셔닝 기능까지 사용 가능
테이블의 데이터가 많아진다고 해서 무조건 파티션을 적용하는 것이 효율적인 방법은 아니다.
Partition을 사용하는 대표적인 예는 아래와 같다.
-
하나의 테이블이 너무 커서 인덱스의 크기가 물리적인 메모리보다 훨씬 큰 경우
-
데이터 특성상 주기적인 삭제 작업이 필요한 경우
이를 좀 더 자세히 살펴보면 아래와 같다.
Partition을 사용하는 이유
단일 INSERT, 단일 SELECT, 범위 SELECT의 빠른 처리
인덱스는 일반적으로 SELECT를 위한 것으로 보이지만 UPDATE와 DELETE, 그리고 INSERT 쿼리를 위해 필요한 때도 많다.
레코드를 변경하는 쿼리를 실행하면 인덱스의 변경을 위한 부가적인 작업이 발생하긴 하지만 UPDATE나 DELETE 처리를 위해 대상 레코드를 검색하려면 인덱스가 필수적이다.
하지만 이 인덱스가 커지면 커질수록 SELECT는 말할 것도 없고, INSERT나 UPDATE, 그리고 DELETE 작업도 당연히 느려진다.
특히 한 테이블의 인덱스 크기가 물리적으로 MySQL이 사용 가능한 메모리 공간보다 크다면 그 영향은 더 심각해진다.
테이블의 데이터는 실질적인 물리 메모리보다 큰 것이 일반적이겠지만 인덱스의 워킹 셋(Working set)이 실질적인 물리 메모리보다 크다면 쿼리 처리가 상당히 느려진다.
활발하게 사용되는 데이터를 워킹 셋이라고 표현
테이블의 데이터를 워킹 셋과 그렇지 않은 부류로 파티셔닝할 수 있다면 상당히 효과적으로 성능을 개선할 수 있다.
큰 테이블을 파티셔닝하지 않고 그냥 사용할 때와 작은 파티션으로 나눠서 워킹 셋의 크기를 줄였을 때 인덱스의 워킹 셋이 물리적인 메모리를 어떻게 사용하는지는 아래 그림을 통해서 확인할 수 있다.
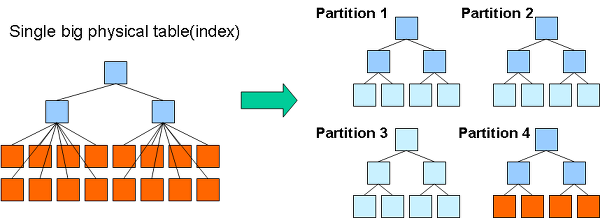
파티셔닝하지 않고 하나의 큰 테이블로 사용하면 인덱스도 커지고 그만큼 물리적인 메모리 공간도 많이 필요해진다.
결과적으로 파티션은 데이터와 인덱스를 조각화해서 물리적 메모리를 효율적으로 사용할 수 있게 만들어 준다.
데이터의 물리적인 저장소를 분리
데이터 파일이나 인덱스 파일이 파일 시스템에서 차지하는 공간이 크다면 그만큼 백업이나 관리 작업이 어려워진다.
더욱이 테이블의 데이터나 인덱스를 파일 단위로 관리하고 있는 MySQL에서 더 치명적인 문제가 될 수도 있다.
이러한 문제는 파티션을 통해 파일의 크기를 조절하거나 각 파티션별 파일들이 저장될 위치나 디스크를 구분, 지정해서 해결 가능하다.
하지만 MySQL에서는 테이블의 파티션 단위로 인덱스를 순차적으로 생성하는 방법은 아직 허용되지 않는다.
이력 데이터의 효율적인 관리
로그라는 이력 데이터는 단기간에 대량으로 누적됨과 동시에 일정 기간이 지나면 쓸모가 없어진다.
로그 데이터는 결국 시간이 지나면 별도로 아카이빙하거나 백업한 후에 삭제해버리는 것이 일반적이며, 특히 다른 데이터에 비해 라이프 사이클이 상당히 짧은 것이 특징이다.
로그 테이블에서 불필요해진 데이터를 백업하거나 삭제하는 작업은 일반 테이블에서는 상당히 고부하의 작업에 속한다.
대량의 데이터가 저장된 로그 테이블을 기간 단위로 삭제한다면 MySQL 서버에 전체적으로 미치는 부하뿐 아니라 로그 테이블 자체의 동시성에도 영향을 미칠 수 있다.
파티션을 이용하면 이러한 문제를 대폭 줄일 수 있다.
하지만 로그 테이블을 파티션 테이블로 관리한다면 불필요한 데이터 삭제 작업은 단순히 파티션을 추가하거나 삭제하는 방식으로 간단하고 빠르게 해결할 수 있다.
ex) 202011 처럼 '년월' 이름으로 파티셔닝해서 파티셔닝을 지우는 방법
MySQL Partition 내부 동작
Partition이 적용된 테이블에서 레코드의 INSERT와 UPDATE, 그리고 SELECT가 어떻게 처리되는지 확인해보기 위해 아래 임시 테이블을 생성하였다.
CREATE TABLE tb_gillog (
id INT NOT NULL,
write_date DATETIME NOT NULL,
...
PRIMARY KEY(id)
)
PARTITION BY RANGE ( YEAR(write_date) ) (
PARTITION p2018 VALUES LESS THAN (2019),
PARTITION p2019 VALUES LESS THAN (2020),
PARTITION p2020 VALUES LESS THAN MAXVALUE
);여기서 write_date에서 연도 부분은 파티션 키로서 해당 레코드가 어느 파티션에 저장될지를 결정하는 중요한 역할을 담당하게 된다.
tb_gillog에 대해 INSERT, UPDATE, SELECT 쿼리 등이 어떻게 처리되는지 살펴보면 아래와 같다.
Partition Table Record INSERT
INSERT 쿼리가 실행되는 MySQL 서버는 INSERT되는 컬럼 값 중에서 파티션 키인 write_date 컬럼 값을 이용해 파티션 표현식을 평가 하고, 그 결과를 이용해 레코드가 저장될 적절한 파티션을 결정한다.
새로 INSERT되는 레코드를 위한 파티션이 결정되면 나머지 과정은 파티션되지 않은 일반 테이블과 마찬가지로 처리된다.
Partition Table UPDATE
UPDATE 쿼리를 실행하려면 변경 대상 레코드가 어느 파티션에 저장돼 있는지 찾아야 한다.
이때 UPDATE 쿼리의 WHERE 조건에 파티션 키 컬럼이 조건으로 존재한다면 그 값을 이용해 레코드가 저장된 파티션에서 빠르게 대상 레코드를 검색할 수 있다.
하지만 WHERE 조건에서 파티션 키 컬럼의 조건이 명시되지 않았다면 MySQL 서버는 변경 대상 레코드를 찾기 위해 테이블의 모든 파티션을 검색해야 한다.
그리고 실제 레코드의 컬럼을 변경하는 작업의 절차는 UPDATE 쿼리가 어떤 컬럼의 값을 변경하는지에 따라 큰 차이가 생긴다.
-
파티션 키 이외의 컬럼만 변경될 때는 파티션이 적용되지 않은 일반 테이블과 마찬가지로 컬럼 값만 변경한다.
-
파티션 키 컬럼이 변경될 때는 아래 동작을 수행 한다.
2.1 PARTITION_2019에서 해당 레코드 삭제
2.2 대상 레코드를 PARTITION_2020로 복사
2.3 write_date 컬럼을 '2020-02-10'로 변경
Partition Table 검색
SQL이 수행되기 위해 파티션 테이블을 검색할 때 성능에 크게 영향을 미치는 조건은 아래와 같다.
-
WHERE 절의 조건으로 검색해야 할 파티션을 선택할 수 있는가?
-
WHERE 절의 조건이 인덱스를 효율적으로 사용(인덱스 레인지 스캔)할 수 있는가?
파티션되지 않은 일반 테이블의 검색 성능에도 똑같이 영향을 미친다.
파티션 테이블에서는 첫 번째 선택사항의 결과에 의해 두 번째 선택사항의 작업 내용이 달라질 수 있다.
두 가지 주요 선택사항의 조합이 어떻게 실행되는지 살펴보면 아래와 같다.
파티션 선택 가능 + 인덱스 효율적 사용 가능
두 선택사항이 모두 사용 가능할 때 쿼리가 가장 효율적으로 처리 될 수 있다.
이때는 파티션의 개수에 관계없이 검색을 위해 꼭 필요한 파티션의 인덱스만 레인지 스캔합니다.
파티션 선택 불가 + 인덱스 효율적 사용 가능
WHERE 조건에 일치하는 레코드가 저장된 파티션을 걸러낼 수 없기 때문에 우선 테이블의 모든 파티션을 대상으로 검색해야 한다.
하지만 각 파티션에 대해서는 인덱스 레인지 스캔을 사용할 수 있기 때문에 최종적으로 테이블에 존재하는 모든 파티션의 개수만큼 인덱스 레인지 스캔을 수행해서 검색하게 된다.
이 작업은 파티션 개수만큼의 테이블에 대해 인덱스 레인지 스캔을 한 다음 결과를 병합해서 가져오는 것과 같다.
파티션 선택 가능 + 인덱스 효율적 사용 불가
검색하려는 레코드가 저장된 파티션을 선별할 수 있기 때문에 파티션 개수에 관계없이 검색을 위해 필요한 파티션만 읽으면 된다.
하지만 인덱스는 이용할 수 없기 때문에 대상 파티션에 대해 풀 테이블 스캔을 한다.
이는 각 파티션의 레코드 건수가 많다면 상당히 느리게 처리된다.
파티션 선택 불가 + 인덱스 효율적 사용 불가
WHERE 조건에 일치하는 파티션을 선택할 수가 없기 때문에 테이블의 모든 파티션을 검색해야 한다.
각 파티션을 검색하는 작업 자체도 인덱스 레인지 스캔을 사용할 수 없기 때문에 풀 테이블 스캔을 수행한다.
앞서 살펴본 네 가지 방식 중 파티션 선택 가능 + 인덱스 효율적 사용 불가, 파티션 선택 불가 + 인덱스 효율적 사용 불가 방식은 가능하다면 피하는 것이 좋다.
그리고 파티션 선택 불가 + 인덱스 효율적 사용 가능 방식 또한 하나의 테이블에 파티션의 개수가 많을 때는 MySQL 서버의 부하도 높아지고 처리 시간도 많이 느려지므로 주의가 필요하다.
Partition Table 인덱스 스캔과 정렬
MySQL의 파티션 테이블에서 인덱스는 전부 로컬 인덱스에 해당한다.
모든 인덱스는 파티션 단위로 생성되며, 파티션에 관계없이 테이블 전체 단위로 글로벌하게 하나의 통합된 인덱스는 지원하지 않는다는 것을 의미한다.
파티션되지 않은 테이블에서는 인덱스를 순서대로 읽으면 그 컬럼으로 정렬된 결과가 출력되지만, 파티션된 테이블에서는 그렇지 않다.
인덱스 레인지 스캔을 수행하는 쿼리가 여러개의 파티션을 읽어야 할 때 그 결과는 인덱스 컬럼으로 정렬이 될지 살펴 보면 아래와 같다.
SELECT * FROM tb_gillog
WHERE id BETWEEN 'gil' AND 'log'
ORDER BY id;위 쿼리의 EXPLAIN을 확인해보면 Extra 컬럼에 별도의 정렬 작업을 의미하는 "Using filesort" 코멘트가 표시되지 않는다.
간단히 생각해보면 PARTITION_2019와 PARTITION_2020으로부터 WHERE 조건에 일치하는 레코드를 가져온 후, 각 파티션의 결과를 병합하고 id 컬럼의 값으로 다시 한번 정렬해야 될 것처럼 보인다.
하지만 쿼리의 실행 계획에는 별도의 정렬을 수행했다는 메시지는 표시되지 않는다.
실제 MySQL 서버는 여러 파티션에 대해 인덱스 스캔을 수행할 때, 각 파티션으로부터 조건에 일치하는 레코드를 정렬된 순서대로 읽으면서 우선순위 큐(Priority Queue)에 임시로 저장한다.
그 후 우선순위 큐에서 다시 필요한 순서(인덱스의 정렬 순서)대로 데이터를 가져간다.
이는 각 파티션에서 읽은 데이터가 이미 정렬돼 있는 상태라서 가능한 방법입니다.
결론적으로 파티션 테이블에서 인덱스 스캔을 통해 레코드를 읽을 때 MySQL 서버가 별도의 정렬 작업을 수행하지 않는다.
일반 테이블의 인덱스 스캔처럼 결과를 바로 반환하는 것이 아니라 내부적으로 큐 처리가 한번 필요한 것이다.
Partition Pruning
파티션 프루닝(Partition pruning)은 최적화 단계에서 필요한 파티션만 골라내고 불필요한 것들은 실행 계획에서 배제하는 것이다.
옵티마이저에 의해 3개의 파티션 가운데 2개만 읽어도 된다고 판단되면 불필요한 파티션에는 전혀 접근하지 않는다.
파티션 프루닝 정보는 실행 계획을 확인해보면 옵티마이저가 어떤 파티션만 접근하는지 알 수 있다.
파티션 푸르닝에 관련된 실행 계획을 확인할 때는 "EXPLAIN PARTITIONS" 명령을 사용해야 한다.
Partition 제약 사항
Partition은 MySQL 5.1 버전부터 도입됐지만 아직 많은 제약을 지니고 있다.
MySQL 5.5 버전에서 해결된 문제도 있지만 자세한 제약사항을 살펴보면 아래와 같다.
1. 숫자값(INTEGER 타입 컬럼 또는 INTEGER 타입을 반환하는 함수 및 표현식)에 의해서만 파티션이 가능하다.
MySQL 5.5 부터는 숫자 타입뿐 아니라 문자열이나 날짜 타입 모두 사용할 수 있다.
2. 키 파티션은 해시 함수를 MySQL이 직접 선택하기 때문에 컬럼 타입 제한이 없다.
3. 최대 1024개의 파티션을 가질 수 있다.
서브 파티션까지 포함한다.
파티션 테이블은 파티션 갯수 * 2 ~ 3개의 파일을 가진다.
예를 들어 1024개의 파티션을 가진 테이블을 프루닝으로 2개의 파티션에만 접근해도, 일반적으로 1024개의 모든 파티션의 데이터 파일이 오픈되어야 한다.
그래서 파티션을 크게 쓰는 경우에 OPEN-FILES-LIMIT를 적절히 크게 설정해야한다.
MySQL 5.6 기본 : 5000
4. 스토어드 루틴이나 UDF 그리고 사용자 변수 등을 파티션 함수나 식에 사용할 수 없다.
5. 파티션 생성 이후 MySQL 서버의 sql_mode 파라미터 변경은 추천되지 않는다.
6. 파티션 테이블에서는 외래키 사용이 불가능하다.
7. 파티션 테이블은 전문 검색 인덱스 생성이 불가능하다.
8. 공간 확장 기능에서 제공되는 컬럼 타입(POINT, GEOMETRY, ..)은 파티션 테이블에서 사용이 불가능하다.
9. 임시 테이블(Temporary table)은 파티션 기능 사용 불가능 하다.
10. MyISAM 파티션 테이블의 경우 키 캐시를 사용할 수 없다.
MySQL 5.5 부터 이 버그는 보완되었다.
11. 파티션 키의 표현식은 일반적으로 컬럼 그 자체 또는 MySQL 내장 함수를 사용할 수 있는데, 여기서 MySQL 내장 함수를 모두 사용할 수 있는 것이 아니라 일부만 사용할 수 있다.
이 함수 중에서도 정상적으로 파티션 프루닝(Pruning)을 지원하는 함수는 YEAR()와 TO_DAYS(), TO_SECONDS()밖에 없으므로 제대로 파티션의 기능을 이용하려고 한다면 INTEGER 타입의 컬럼 그 자체 또는 이 3가지 내장 함수를 사용한 표현식을 파티션 키로 사용할 것을 권장한다.
TO_SECONDS 함수는 MySQL 5.5부터 지원된다.
MySQL 5.1 이상의 버전에서 파티션 표현식에 사용할 수 있는 함수 리스트는 아래와 같다.
ABS(), CELING(), DAY(), DAYOFMONTH(), DAYOFWEEK(),
DAYOFYEAR(), DATEDIFF(), EXTRACT(), FLOOR(), HOUR(),
MICROSECOND(), MINUTE(), MOD(), MONTH(), QUARTER(),
SECOND(), TIME_TO_SEC(), TO_DAYS(), WEEKDAY(), YEAR(), YEARWEEK()12. MySQL의 파티션에서 인덱스는 로컬이나 글로벌의 의미가 없이 모두 로컬 인덱스이며, 같은 테이블에 소속돼 있는 모든 파티션은 같은 구조의 인덱스만 가질 수 있다.
즉 파티션 단위로 인덱스를 변경하거나 추가할 수 없다.
13. 하나의 테이블에 소속된 파티션은 다른 종류의 스토리지 엔진으로 구성하는 것을 추천하지 않는다.
14. 파티션 테이블 성능이 일반 테이블보다 더 떨어질 수 있다.
파티션을 선별하는 파티션 프루닝은 쿼리 최적화 단계에서 수행되어서 알 수 있다.
쿼리 최적화는 '테이블 잠금' 이후에 수행된다.
즉, 테이블 잠금에서는 프루닝을 알 수 없기 때문에 모든 테이블의 파티션이 잠금상태가 된다.
그래서 파티션 갯수가 많을 수록 '열고' '잠금'하는 작업이 많아져서 더 느려질 수 있다.
MySQL 5.1v, MySQL 5.5v에서 발생.
MySQL 5.6.6 에서는 처리됨 MySQL 5.6.6 implements partition lock pruning
하지만 InnoDB 테이블에서 테이블 락은 큰 역할은 아니다.
파티션이 많은 테이블에 INSERT, DELETE하려면 처음부터 LOCK TABLES 명령을 사용하는게 추천된다.
앞서 살펴본 제약사항을 고려해 보면 MySQL 5.1에서는 INTEGER 컬럼과 DATE(또는 DATETIME) 타입의 컬럼으로 파티션된 테이블만 제대로 된 기능(파티션 생성 및 파티션 프루닝)을 활용할 수 있을 것으로 보인다.
MySQL Partition Table 사용하기
MySQL 서버에서 Partition이 사용 가능한지 확인해 보려면 variables와 plugins의 Partition 정보를 확인해야 한다.
SHOW variables LIKE '%partition%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| have_partitioning | YES |
+-------------------+-------+
SHOW plugins;
+--------------------------+----------+--------------------+---------+---------+
| Name | Status | Type | Library | License |
+--------------------------+----------+--------------------+---------+---------+
| partition | ACTIVE | STORAGE ENGINE | NULL | GPL |
+--------------------------+----------+--------------------+---------+---------+MySQL에서 지원되는 Partition은 Range, List, Hash, Key 네 가지이다.
Range Partition
Range Partition은 파티션 키의 연속된 범위로 파티션을 정의한다.
Range Partition은 일반적으로 아래와 같은 상황에서 사용된다.
- 날짜 기반 데이터가 누적되고 년도, 월,일 단위로 분석, 삭제 할 경우
- 범위 기반으로 데이터를 여러 파티션에 균등하게 나눌 수 있을 경우
- 파티션 키 위조로 검색이 자주 실행 될 경우
- 대량의 과거 데이터 삭제시
Range Partition에서 Null 은 어떤 값보다 작은 값으로 취급된다.
hired 컬럼이 Null 인 데이터가 insert 된다면 가장 작은 값을 저장하는 p0에 저장된다.
하지만 파티션 지정시 PARTITION p0 VALUES LESS THAN (NULL) 과 같이 지정할 수는 없다.
날짜 컬럼에 대한 Range 파티션 적용시 YEAR(), TO_DAYS() 함수만 사용하길 권장한다.
두 함수는 MySQL 서버 내부적으로 파티션 프루닝처리가 되어 성능상의 문제가 발생하지 않지만 그 외의 함수는 파티션 프루닝이 제대로 작동하지 않을 수도 있다.
UNIX_TIMESTAMP()를 이용한 변환식, 날짜를 문자열로 포매팅한 형태('2012-02-12')등의 형태는 사용하지 않는 것이 권장된다.
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
) PARTITION BY RANGE (YEAR(hired)) (
PARTITION p0 VALUES LESS THAN (2010) ,
PARTITION p1 VALUES LESS THAN (2011) ,
PARTITION p2 VALUES LESS THAN (2012) ,
PARTITION p3 VALUES LESS THAN MAXVALUE
);일자 단위 파티션 생성 : TO_DAYS함수 사용
CREATE TABLE raw_log_2011_4 (
id bigint(20) NOT NULL AUTO_INCREMENT,
logid char(16) NOT NULL,
tid char(16) NOT NULL,
reporterip char(46) DEFAULT NULL,
ftime datetime DEFAULT NULL,
KEY id (id)
) ENGINE=InnoDB AUTO_INCREMENT=286802795 DEFAULT CHARSET=utf8
PARTITION BY RANGE( TO_DAYS(ftime) ) (
PARTITION p20110401 VALUES LESS THAN (TO_DAYS('2011-04-02')),
PARTITION p20110402 VALUES LESS THAN (TO_DAYS('2011-04-03')),
PARTITION p20110403 VALUES LESS THAN (TO_DAYS('2011-04-04')),
PARTITION p20110404 VALUES LESS THAN (TO_DAYS('2011-04-05')),
PARTITION p20110426 VALUES LESS THAN (TO_DAYS('2011-04-27')),
PARTITION p20110427 VALUES LESS THAN (TO_DAYS('2011-04-28')),
PARTITION p20110428 VALUES LESS THAN (TO_DAYS('2011-04-29')),
PARTITION p20110429 VALUES LESS THAN (TO_DAYS('2011-04-30')),
PARTITION future VALUES LESS THAN MAXVALUE
);
create index raw_log_2011_4_idx01 on raw_log_2011_4(ftime)
explain partitions select * from raw_log_2011_4 where ftime >= '2011-04-13' and ftime <= '2011-04-15'
|id|select_type|table|partitions|type|possible_keys|key|key_len|ref|rows|Extra| |
|'1'|'SIMPLE'|'raw_log_2011_4'|'p20110401`|`p20110426'|'range'|'raw_log_2011_4_idx01'|'raw_log_2011_4_idx01'|'9'|NULL|'4'|'Using where'|파티션 추가
ALTER TABLE employees ADD PARTITION(PARTITION p4 VALUES LESS THAN (2009));파티션 삭제
ALTER TABLE employees DROP PARTITION p4;기존 파티션의 분리
ALTER TABLE employees
REORGIANIZE PARTITION p3 INTO (
PARTITION p3 VALUES LESS THAN (2013),
PARTITION p4 VALUES LESS THAN MAXVALUE
);기존 파티션의 병합
ALTER TABLE employees
REORGANIZE PARTITION p2,p3 INTO (
PARTITION p23 VALUES LESS THAN (2012)
);List Partition
List Partition은 Range Partition과 비슷하다.
List Partition은 아래와 같은 상황에서 일반적으로 사용된다.
- 파티션 키 값이 코드 값이나 카테고리와 같이 고정 값일 경우
- 키 값이 연속적이지 않고 정렬순서와 관계없이 파티션을 해야 할 경우
- 파티션 키 값을 기준으로 레코드 건수가 균일하고 검색 조건에 파티션 키가 자주 사용 될 때
List Partition은 Range Partition과 달리 Null 을 명시할 수 있으며, MaxValue 를 지정할 수는 없다.
MySQL V5.5 부터는 파티션 키 값에 정수형 값 이외에 문자열 타입도 사용 가능하다.
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
) PARTITION BY LIST (job_code) (
PARTITION p0 VALUES IN (3) ,
PARTITION p1 VALUES IN (1 , 9) ,
PARTITION p2 VALUES IN (2 , 6 , 7) ,
PARTITION p3 VALUES IN (4 , 5 , 8 , NULL)
);//Range 파티션과 동일(VALUES LESS THAN ==> VALUES IN 사용)
PARTITION BY List (job_code) (
PARTITION p0 VALUES IN ('sports'),
PARTITION p1 VALUES IN ('teacher'),
PARTITION p2 VALUES IN ('student'),
PARTITION p3 VALUES IN ('banker',null)
);
파티션 추가
ALTER TABLE employees ADD PARTITION(PARTITION p4 VALUES IN (3,10));파티션 삭제
ALTER TABLE employees DROP PARTITION p4;기존 파티션의 분리
ALTER TABLE employees
REORGIANIZE PARTITION p3 INTO (
PARTITION p3 VALUES IN (2,6),
PARTITION p4 VALUES IN (7)
);기존 파티션의 병합
ALTER TABLE employees
REORGANIZE PARTITION p2,p3 INTO (
PARTITION p23 VALUES IN (2,6,7,4,5,8,NULL)
);Hash Partition
Hash Partition은 HASH 함수에 의해 레코드가 저장될 파티션을 결정하는 방식이다.
Hash Partition은 보통 아래와 같은 상황에서 사용된다.
- Range, List 로 데이터를 균등하게 나누는 것이 어려울 때
- 테이블의 모든 레코드가 비슷한 사용빈도를 보이지만 너무 커서 파티션 적용이 필요한 경우
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
) PARTITION BY HASH (id)
PARTITIONS 4;
//또는
CREATE TABLE employees ( id INT NOT NULL, fname VARCHAR(30),
lname VARCHAR(30), hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL, store_id INT NOT NULL
) PARTITION BY HASH (id)
PARTITIONS 4
(
PARTITION p0 ENGINE = INNODB,
PARTITION p1 ENGINE = INNODB,
PARTITION p2 ENGINE = INNODB,
PARTITION p3 ENGINE = INNODB
);파티션 추가
파티션의 갯수로 MOD 연산한 결과에 따라 각 레코드를 저장할 파티션을 결정하므로 새로이 파티션이 추가될 경우 파티션에 저장된 모든 레코드는 재배치 되어야 하므로 많은 부하가 발생한다.
//파티션 이름을 부여하는 경우
ALTER TABLE employees ADD PARTITION(PARTITION p5 ENGINE = INNODB);
//별도의 이름 없이 3개의 파티션을 추가하는 경우
ALTER TABLE employees ADD PARTITION PARTITIONS 3;파티션 삭제
파티션 키 값을 이용하여 데이터를 각 파티션으로 분산한 것이므로 각 파티션에 저장된 레코드의 부류를 사용자가 예측할 수 없기에 해시나 키를 이용한 파티션에서는 파티션단위의 삭제는 불가하다.
파티션 분할
특정 파티션을 분할하는 것이 불가하면, 파티션 추가만 가능하다.
파티션 병합
2개이상의 파티션을 하나로 합치는 기능은 제공하지 않는다.
다만 파티션의 갯수를 줄이는 것은 가능하다.
//기존 파티션의 갯수에서 1개를 뺀 수 만큼 파티션을 재배치 한다.(4개에서 3개로 재구성)
ALTER TABLE employees COALESCE PARTITION 1; Key Partition
Key Partition은 Hash Partiton과 거의 동일하다.
해시값을 계산하는 방법을 사용자가 지정 가능하다.
Key Partition은 선정된 파티션 키값에 대하여 내부적으로 MD5()를 이용하여 해시값을 계산하고, 그 값에 MOD를 적용하여 저장할 파티션을 결정한다.
🙆♂️ 참고사이트 🙇♂️
[MySQL] MySQL 파티션 개요[길은 가면, 뒤에 있다.]
[MySQL] MySQL 파티션 제약사항[길은 가면, 뒤에 있다.]

Range Partition 에서 ftime 컬럼으로 파티션을 구성하는데 ftime이게 PK에 속해 있지 않아도 성능에 상관없나요?