
🤔 서두
우리는 Spring Batch (2) - Hello, Spring Batch✨ (실습)에서 Job Bean, Step Bean을 생성만 했는데, 배치 처리가 됨을 볼 수 있었다.
그러면 어떻게 배치 처리 프로세스가 이뤄지는지, Spring Batch 아키텍처를 통해 알아보고자 한다.
⚔️ Spring Batch의 아키텍처
우선 이 사진은 Spring Batch를 이루고 있는 객체들의 전반적인 아키텍처이다.
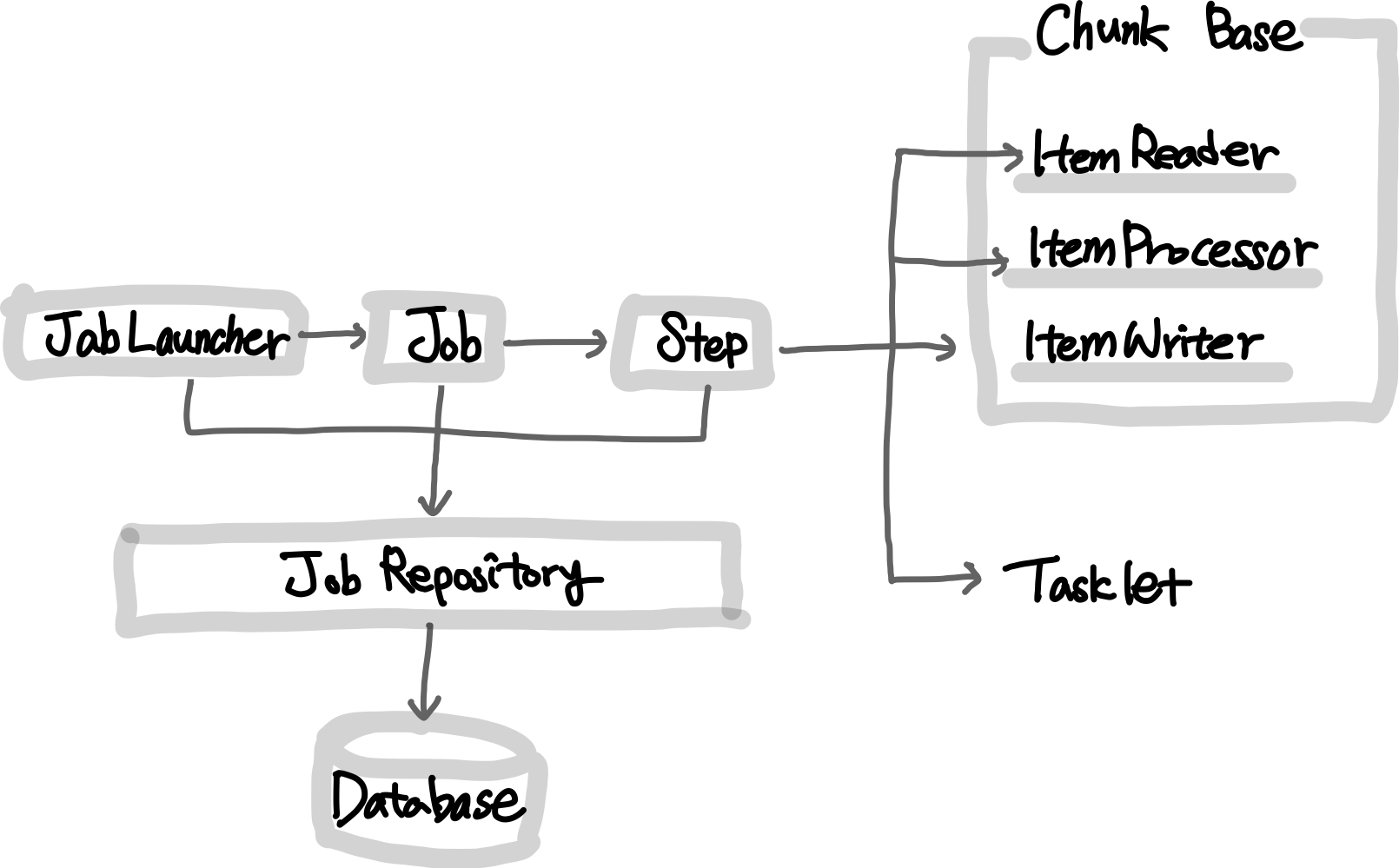
Spring Batch는 Job 타입의 Bean이 생성되면, JobLauncher 객체에 의해서 Job 을 실행한다.
이 Job은 Step을 실행한다.
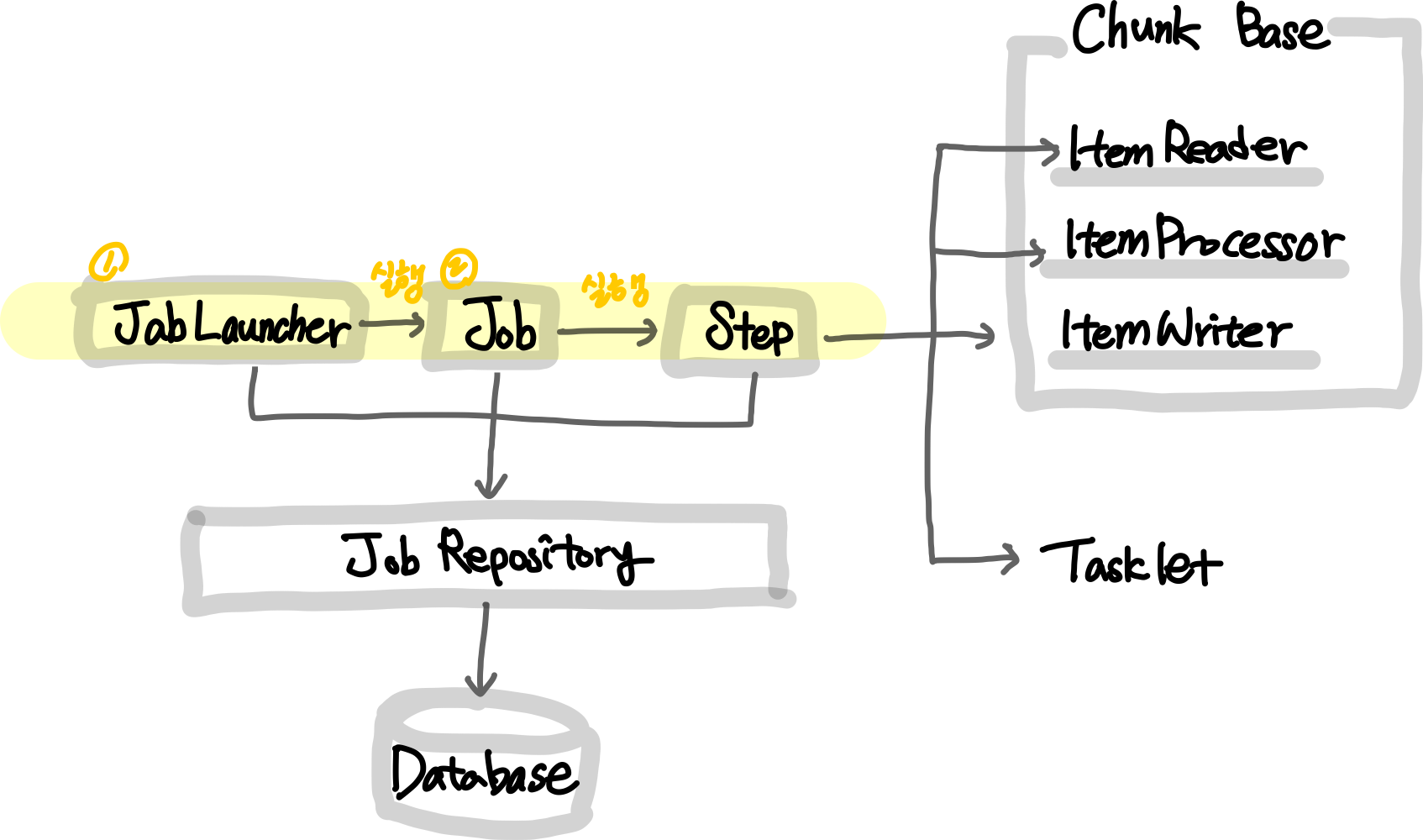
✅ Job
- Job은 JobLauncher에 의해 실행
- Job은 배치의 실행 단위를 의미
- Job은 N개의 Step을 실행가능
- Step들의 흐름(flow) 관리
- EX. a step 실행 후, 조건에 따라 b 또는 c step 실행 설정
✅ Step
- Step은 Job의 세부 실행 단위, N개가 등록되어 실행
Step의 실행 단위
1️⃣ Chunk : 하나의 큰 덩어리를 n개씩 나눠서 실행
Chunk 기반의 Step : ItemReader, ItemProcessor, ItemWriter (Item : 배치 처리 대상 의미)
- ItemReader : 배치 처리 대상을 읽고 ItemProcessor/ItemWriter에 전달
- ItemProcessor : input 객체를 output 객체로 필터링/processing 해서 ItemWriter에 전달
- 얘가 하는 일은 ItemReader/ItemWriter가 대신 할 수 있음 (하지만 명확히 책임을 나누기 위해서 사용하는 거라 생각) - ItemWriter : 배치 처리 대상 객체를 처리
- Ex. DB에 내용 업데이트를 하거나, 처리 대상 사용자들에게 알림 보내기
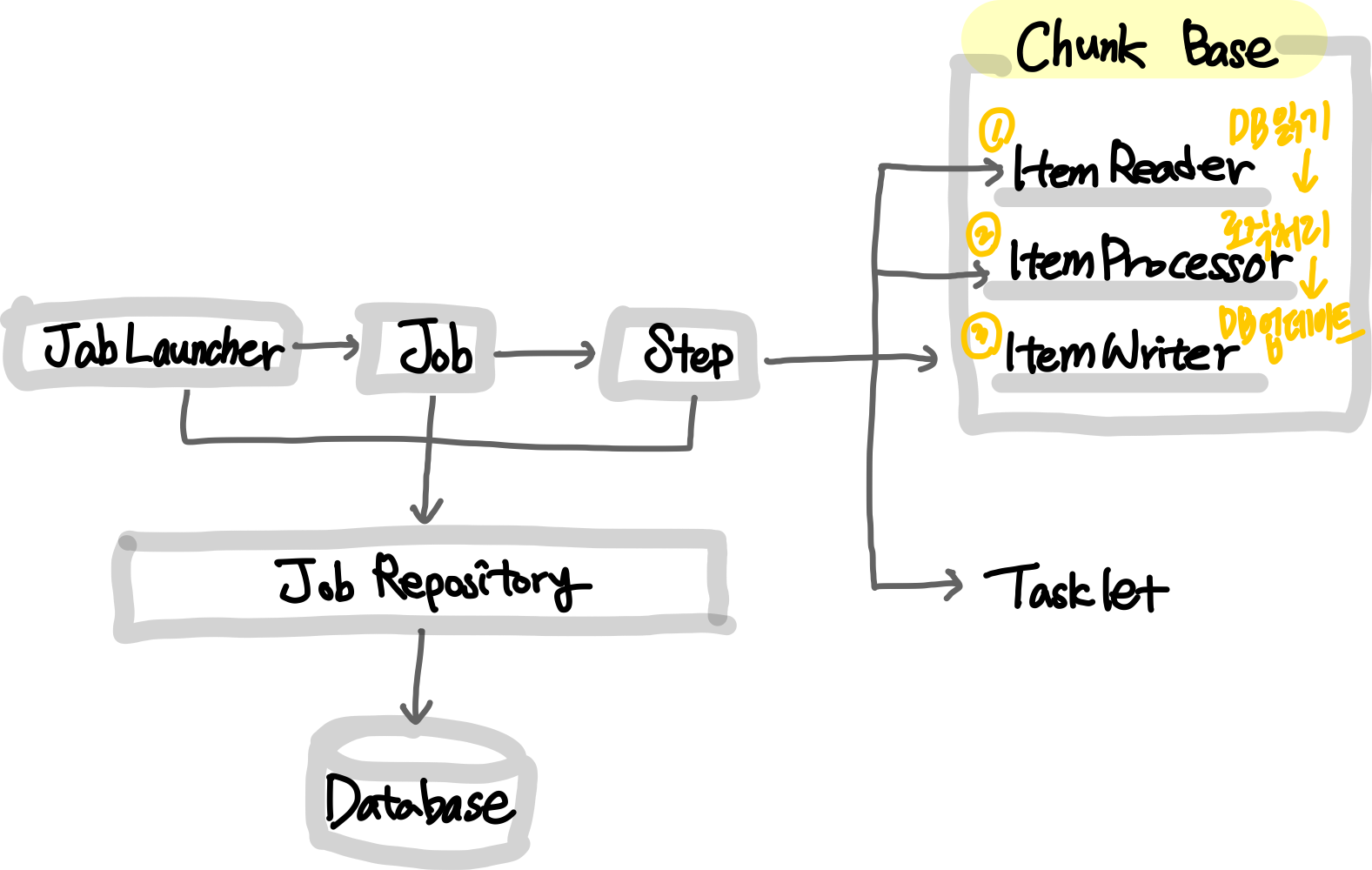
2️⃣ Task : 하나의 작업 기반으로 실행
그렇다면 언제 어떤걸 사용?
- 10,000개의 데이터를 한 번에 처리 하거나 처리 대상이 한 번에 실행되어도 컴퓨터 자원에 문제가 없으면 Tasklet 사용
- 10,000개의 데이터를 10번에 나눠, 1,000개씩 10번으로 페이징 처리하고자하면 Chunk 사용
- Tasklet도 페이징 처리할 수 있긴 하지만 Chunk가 더 활용성 높고, 책임을 나눌 수 있기때문에 이 경우엔 주로 Chunk사용
✅ JobRepository
이 클래스는 DB나 메모리에 Spring Batch가 실행할 수 있도록 배치의 메타 데이터를 관리한다 ➡️ Spring Batch의 전반적인 데이터를 관리하는 클래스
메타 테이블 : 배치 실행, 배치 실행결과인 메타 데이터를 저장
-
Batch_job_instance : Job이 실행되는 최상위 계층 테이블로서, job_name, job_key 기준으로 하나의 row 생성 ➡️ 같은 job_name, job_key 저장 불가
- JobInstance와 매핑
JobInstance 생성 기준은 JobParameters 중복 여부에 따라 생성-
다른 parameter로 Job이 실행되면, JobInstance가 생성
같은 parameter로 Job이 실행되면, 이미 생성된 JobInstance가 실행 -
Ex.
처음 Job 실행 시, date parameter가 6월 23일이라면 1번 Job Instance 생성
다음 Job 실행 시, date parameter가 6월 24일이라면 2번 Job Instance 생성
다음 Job 실행 시, date parameter가 6월 24일이라면 2번 Job Instance 재실행 -
Job은 먼저 조회하고, 중복되는게 없다면 생성됨 ➡️ 조회시, 중복되는게 있다면 재실행 ➡️ 하지만 Job이 재실행 대상이 아니면 에러 발생
-
따라서. Job을 항상 새로운 JobInstance가 실행될 수 있도록 RunIdIncrementer을 사용한다. ➡️ RunIdIncrementer는 항상 다른 run.id를 parameter로 설정
-
- Batch_job_excution : job이 실행되는 시작/종료 시간, job 상태 관리 - JobExecution과 매핑
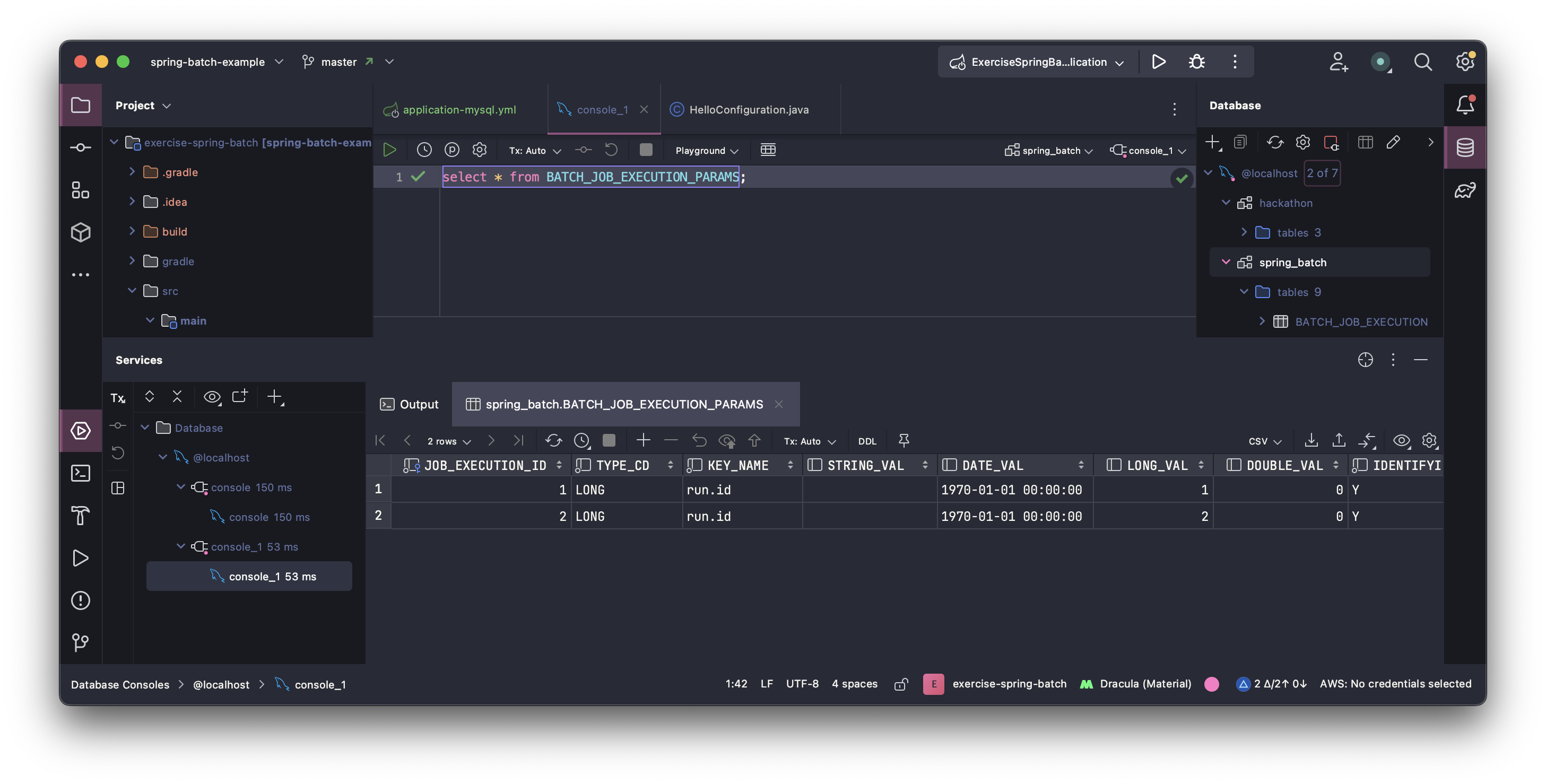
- Batch_job_excution_params : Job을 실행하기 위해 주입된 parameter 정보 저장 - JobParameters와 매핑
- Batch_job_excution_context : Job이 실행되며 공유해야할 데이터를 직렬화해 저장 - ExecutionContext와 매핑
- Batch_step_excution : step이 실행되는 동안 필요한 데이터/실행된 결과 저장 - StepExecution과 매핑
- Batch_step_excution_context : step이 실행되는 동안 데이터를 직렬화해 저장, 하나의 step이 실행되는 동안 공유할 데이터들 저장 - ExecutionContext와 매핑(Job, Step의 Context를 관리하는 객체)
👩🏻💻 직접 확인해보자
-
spring-batch-core 의 schema-mysql.sql
-
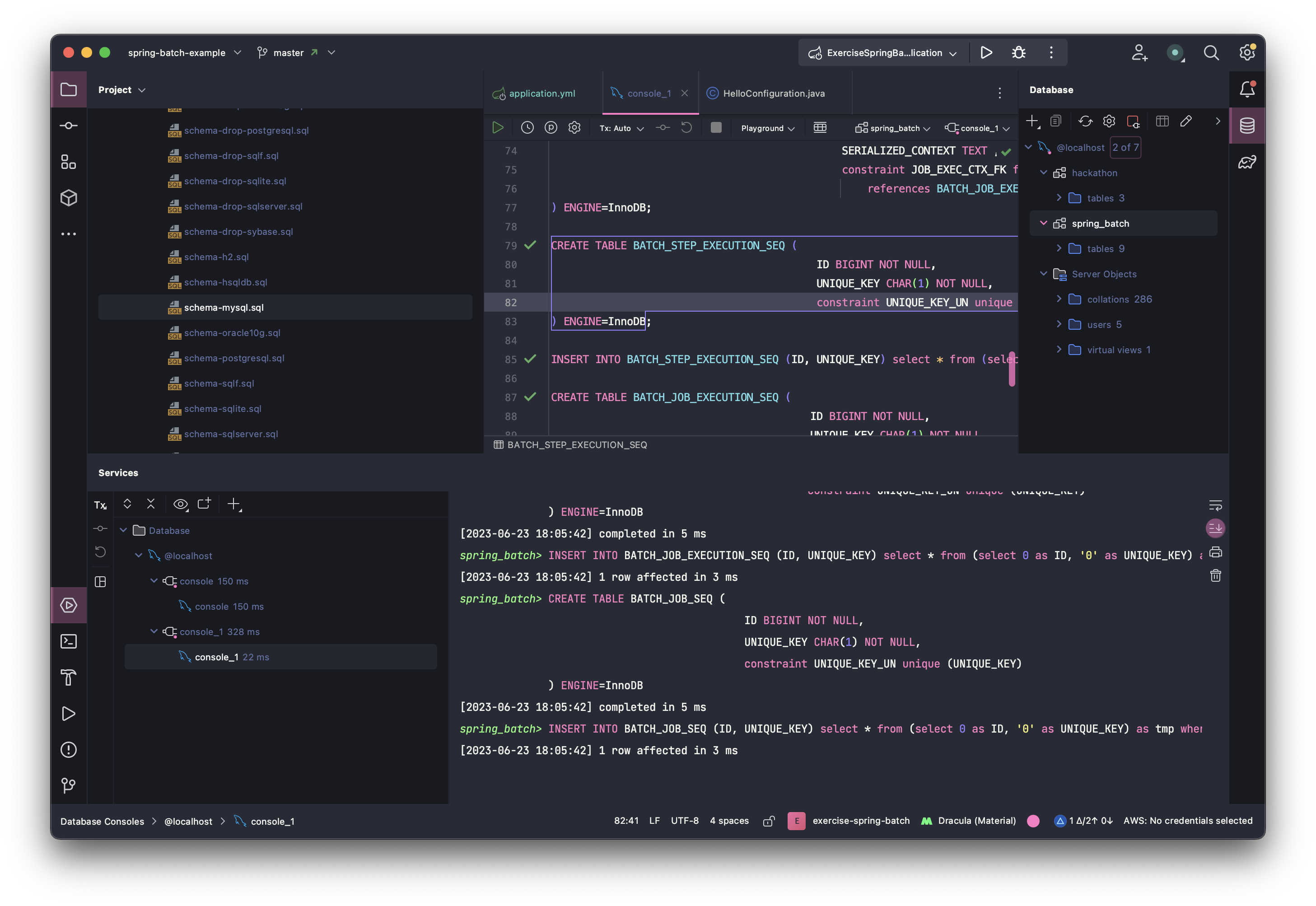
(1)에서 생성해놨던 database에 create table을 해준다
-
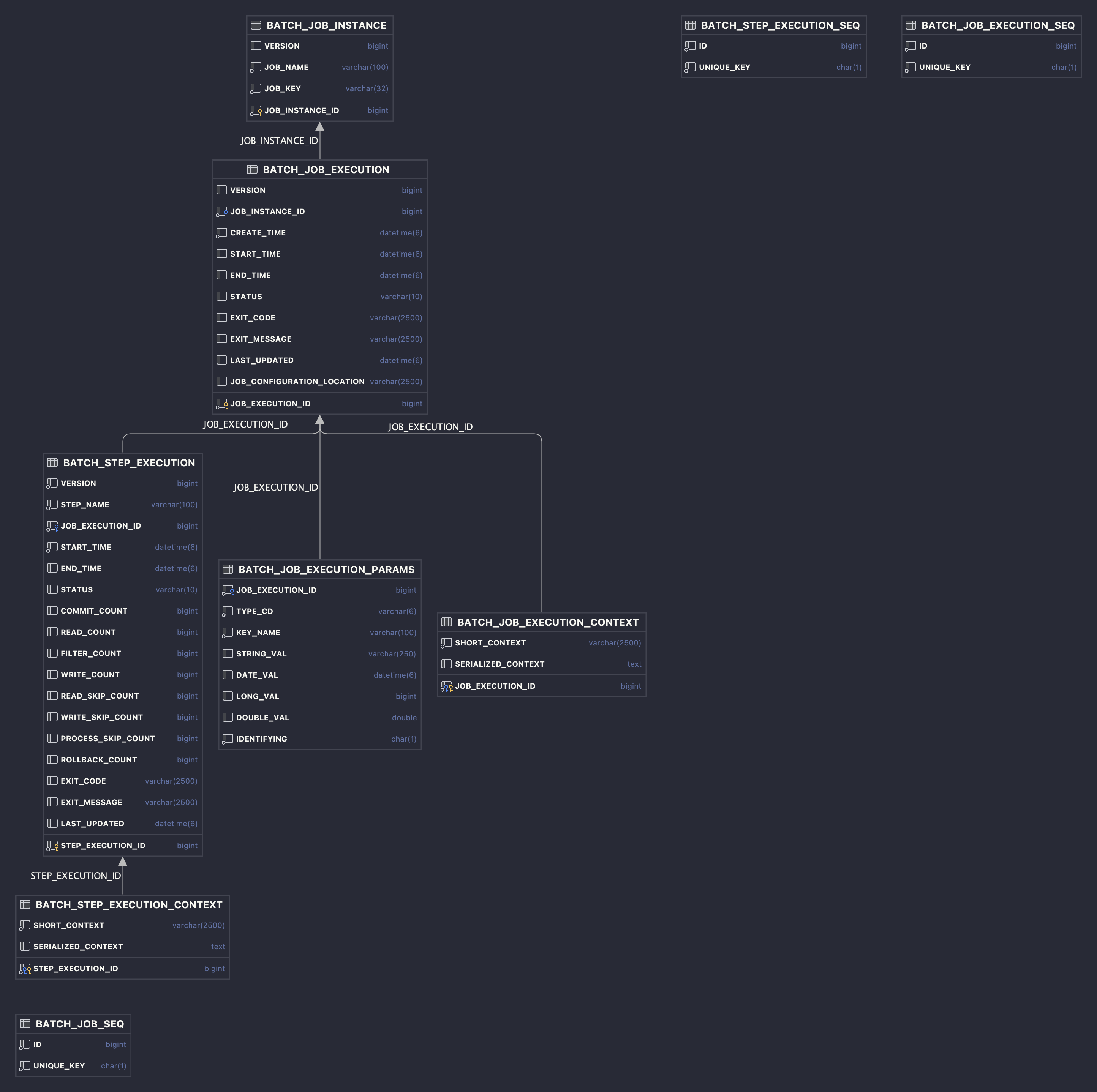
생성한 테이블 ERD
-
application-mysql.yml 작성
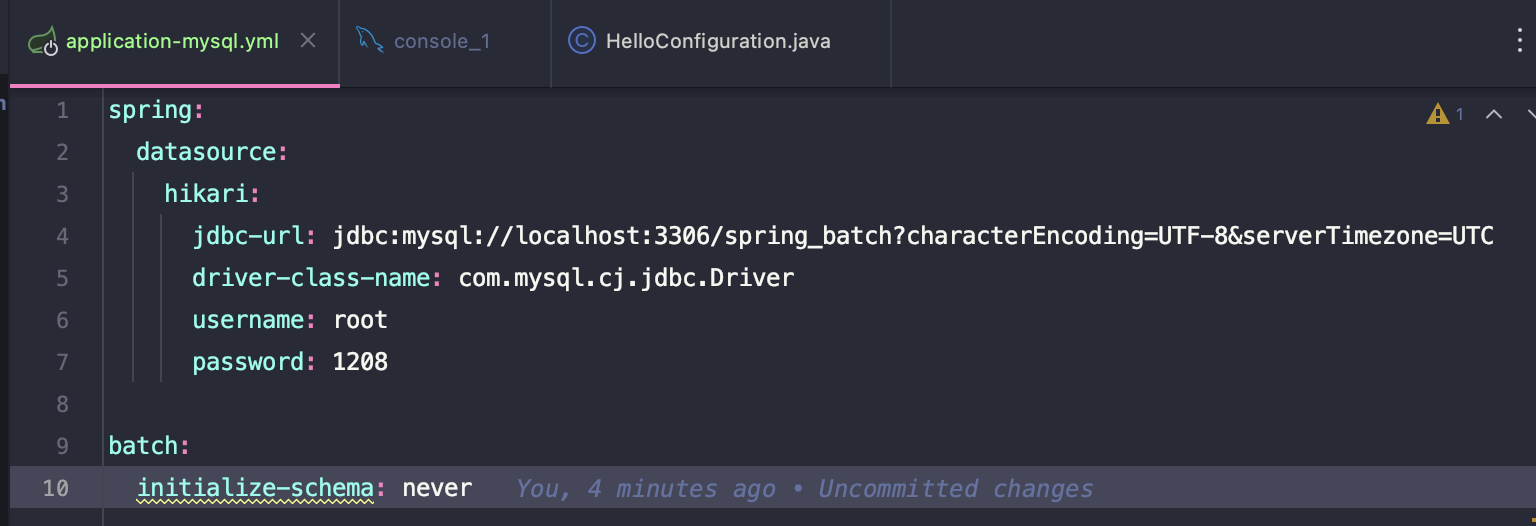
spring:
datasource:
hikari:
jdbc-url: jdbc:mysql://localhost:3306/spring_batch?characterEncoding=UTF-8&serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
username: [로컬mysql username]
password: [로컬mysql password]
batch:
initialize-schema: never5.intelliJ Configuration 설정
- Active profiles : mysql
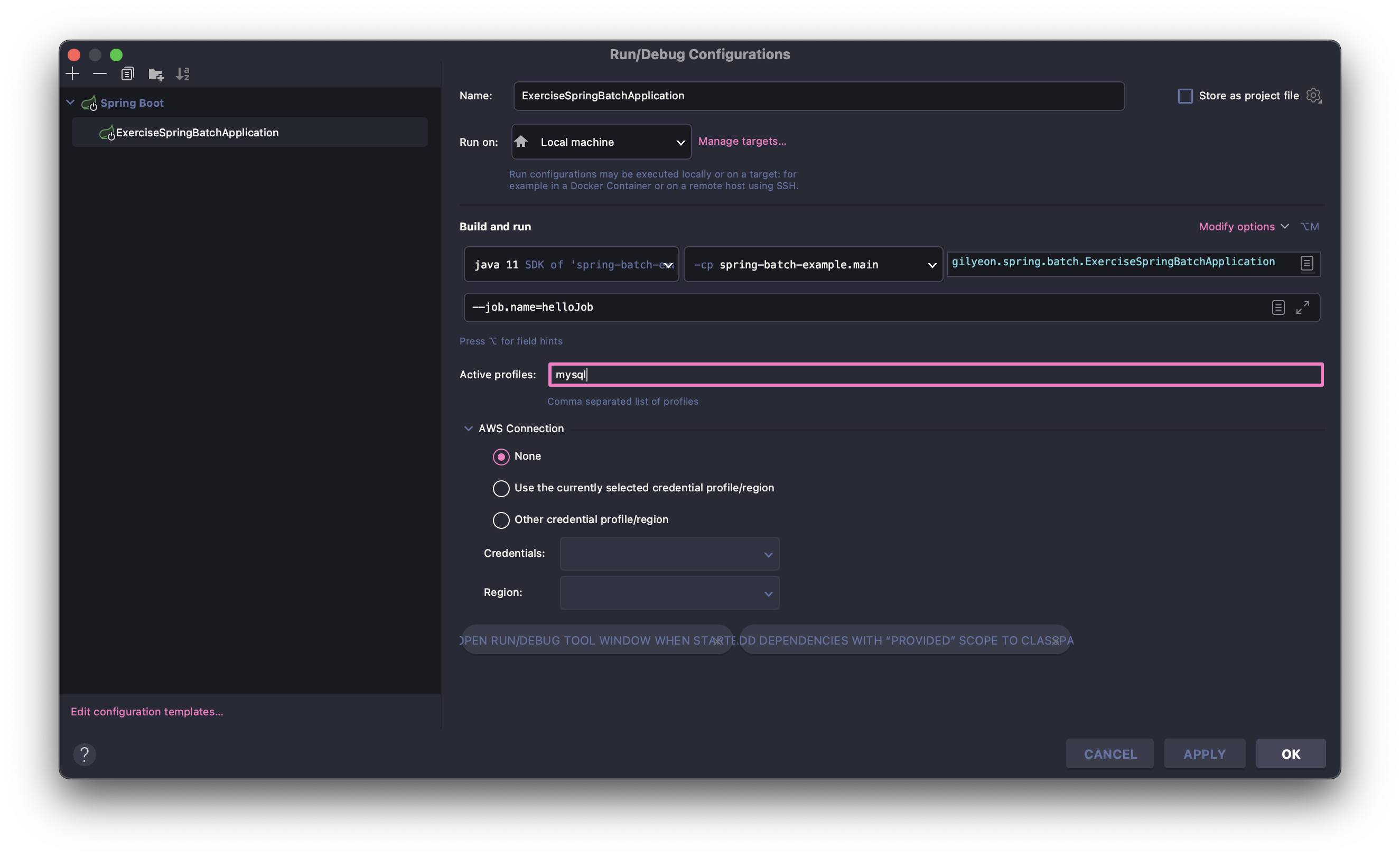
- application 실행 후, 확인
스크립트 생성 시점 설정
- 선택지 : always, embedded, never
- 개발환경에서는 always, embedded 상관없음
애플리케이션 초기 실행시, build.gradle에 설정해놓은 db에 batch 관련 테이블들이 create 되지 않았다면, always로 설정해두고 실행해야 관련 테이블이 create됨 - 운영환경에선 never , 스크립트 직접 생성해서 관리해야함
운영환경에서 스프링 배치에 의해 스크립트가 자동으로 생성된다는 의미
= sql의 ddl이 운영 db에 직접 실행
