
모니터링의 중요성
서비스 가용성 확보를 위함
장애가 발생한 후 조치하는 것은 비용이 크므로, 사전 경고 지표를 통해 선제적으로 대응할 수 있어야 함.
성능 병목 지점 탐지를 위함
CPU, 메모리, 디스크, 네트워크 지표를 지속적으로 확인함으로써 시스템 병목이나 비효율적인 쿼리의 징후를 조기에 파악할 수 있음.
리소스 최적화 및 비용 효율화
실제 사용량 대비 과도한 인스턴스 스펙을 사용 중이라면 낭비되는 비용을 줄이고, 반대로 부족하다면 스케일 업의 근거를 마련할 수 있음.
보안 및 이상 징후 감지를 위함
비정상적인 커넥션 증가나 네트워크 급증, 로그인 실패 등의 지표를 통해 보안 위협에 대한 빠른 대응이 가능함.
CloudWatch 지표 활용 방법
대시보드 구성
핵심 지표를 실시간으로 모니터링할 수 있는 CloudWatch Dashboard를 구성하여 운영 상황을 직관적으로 파악할 수 있음.
알람 설정
기준 수치를 넘는 경우 SNS 또는 이메일을 통해 자동으로 알람을 수신하여 즉각적인 대응 체계를 갖출 수 있음.
장애 원인 분석
장애가 발생했을 때 지표 로그를 통해 당시의 시스템 상태를 되짚어 봄으로써 정확한 원인 분석과 재발 방지가 가능함.
리소스 자동 확장과 연계
일부 지표는 Auto Scaling 정책의 조건으로도 활용할 수 있어, 자동화된 자원 할당이 가능함.
모니터링 기준
모니터링의 시작은 베이스라인설정
일부 지표는 정량적 기준이 있음
- CPU 사용량: 80% 이하
- Memory 사용량: 80% 이하
- Disk Queue: 10 이하
하지만 서버의 사양, 서비스 종류에 따라 달라질 수 있음 그래서, 각 서버 및 서비스에 따른 베이스라인이 중요함
서버 4대 자원
CPU
SQL 쿼리 실행, 정렬, 연산, 조인 등 모든 처리 작업의 중심
- 복잡한 쿼리나 많은 트랜잭션이 동시에 처리될 경우 CPU 사용량 급증
- CPU 사용률이 높으면 전체 처리 속도 저하
모니터링 포인트:
- CPU 사용률(%)
- CPU 사용이 집중되는 시간대
Memory
쿼리 캐시, 버퍼 캐시, 정렬 공간, 임시 테이블 등으로 사용
- 부족하면 스왑 발생 → 디스크 접근 증가 → 심각한 성능 저하
모니터링 포인트:
- 전체 메모리 사용량
- 스왑(swap) 사용 여부
- 버퍼 캐시 히트율(Buffer Cache Hit Ratio)
예시
- 쿼리가 메모리 부족으로 임시 디스크 공간을 사용하게 되면 속도가 급격히 떨어짐
- 대용량 정렬, 복잡한 Group by, hash join, window function, nested query
Disk (Storage I/O)
데이터 파일, 트랜잭션 로그, 백업, 임시파일 저장소
- 모든 데이터의 물리적 저장 위치
- 디스크 속도가 느리면 DB 전체 성능에 병목 발생
모니터링 포인트:
- 디스크 IOPS(초당 입출력 횟수)
- 읽기/쓰기 지연 시간(Latency)
- 디스크 사용률 및 여유 공간
예시
로그 파일 쓰기 속도가 느려지면 트랜잭션 커밋도 느려짐
Network
클라이언트와 DB 서버 간의 통신, 복제/백업 전송, API 연동 등
- 대용량 데이터 송수신 시 병목이 발생할 수 있음 - RDS 등 클라우드 기반 DB는 네트워크 지연이 더 민감
모니터링 포인트:
- 송수신 속도 (Throughput)
- 패킷 손실률, 지연 시간(Latency)
- 연결 수(Connection count)
예시
네트워크 지연으로 인해 애플리케이션에서 "DB 응답 없음" 문제가 발생할 수 있음
RDS 모니터링
- 각 인스턴스 하단 메뉴>모니터링 선택
- 모니터링 윈도우 및 주기 선택
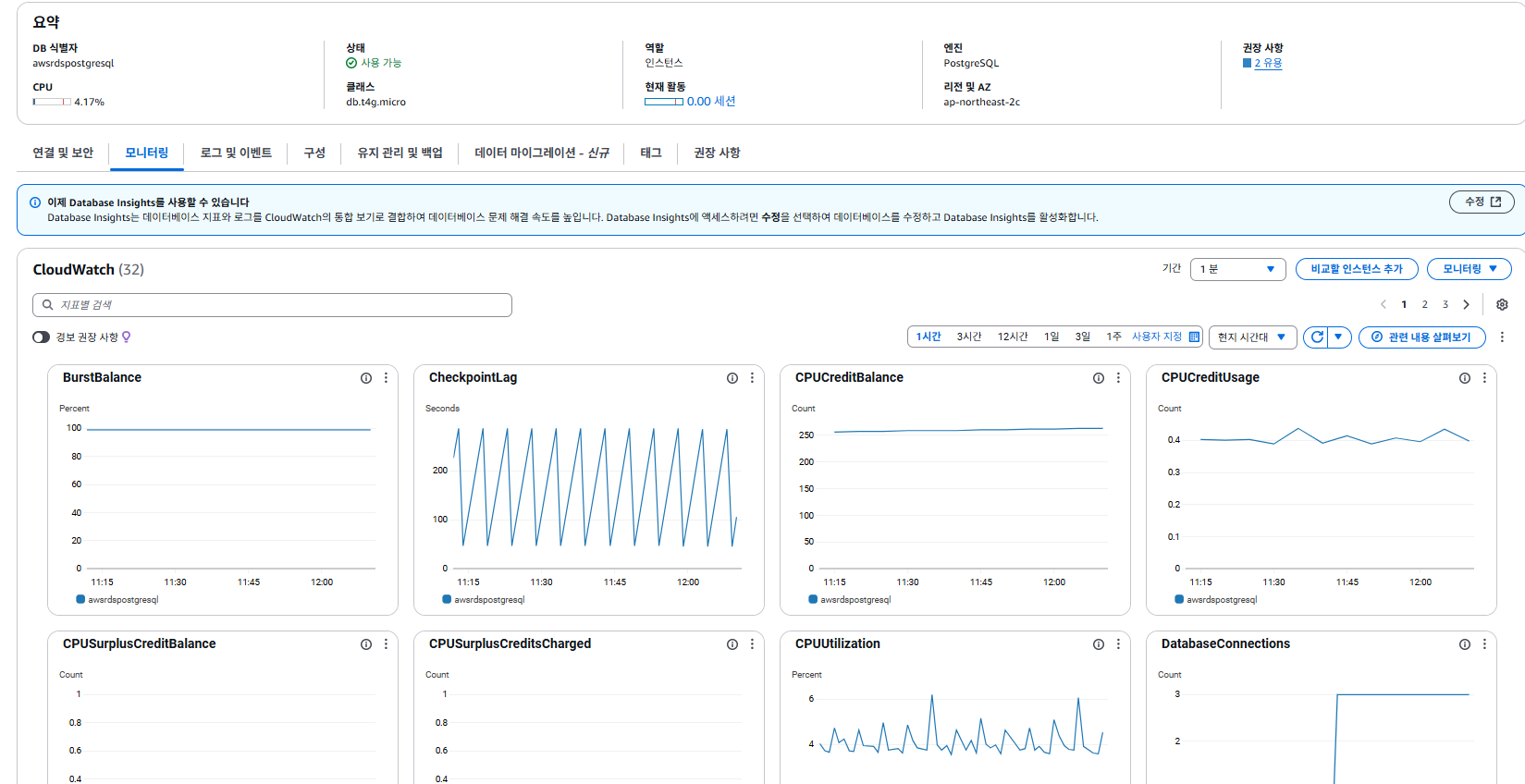
CPUUtilization
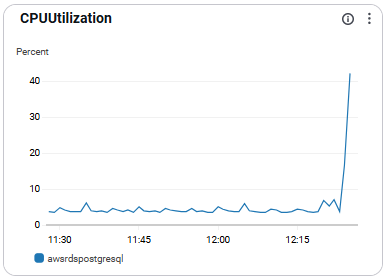
- 인스턴스의 CPU 사용률을 나타 냄.
- 병목 탐지와 성능 진단에 중요 함
- 권장 수치: 80% 이상 지속 시 리소스 증가 또는 쿼리 최적화 권장
FreeableMemory
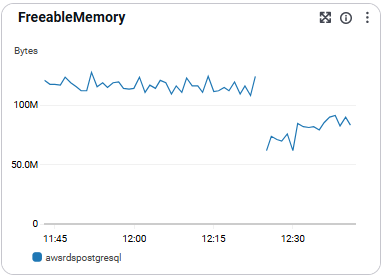
- 남은 메모리 용량을 의미함.
- 장애 예방 및 병목 탐지에 유용 함
- 권장 수치: 100MB 이하로 유지 되면 스왑 사용 가능성 높아짐
SwapUsage
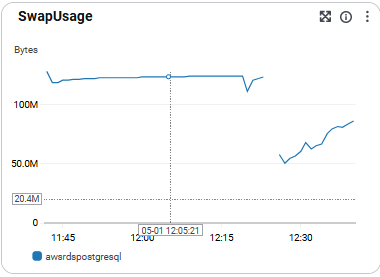
- 스왑 메모리 사용량 을 의미함.
- 병목 탐지와 성능 진단에 활용 됨
- 권장 수치: 0에 가까운 값 유지 권장
FreeStorageSpace
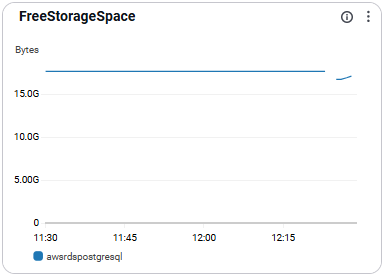
- 남은 디스크 용량을 의미함.
- 장애 예방 관점에서 반드시 모니터링해야 함
- 권장 수치: 디스크 용량의 10~15% 이상 여유 유지 권장
DiskQueueDepth
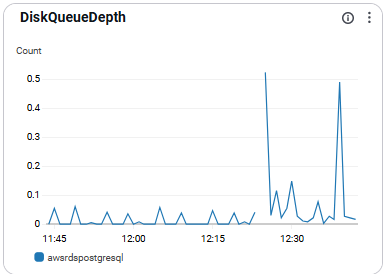
- 디스크 I/O 대기열 수를 나타냄.
- 병목 탐지에 매우 효과적임
- 권장 수치: 10 이상이면 병목 발생 가능성 높음
- Disk의 종류에 따라 이 지표는 달라질 수 있음
ReadLatency
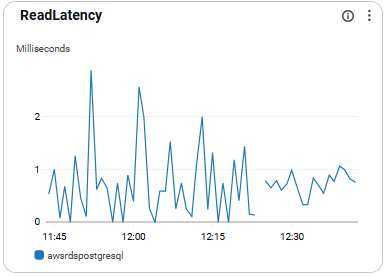
- 읽기 작업의 지연 시간을 의미함.
- 성능 진단에 활용됨
- 권장 수치: 0.01초(10ms) 이하 유지 권장
WriteLatency
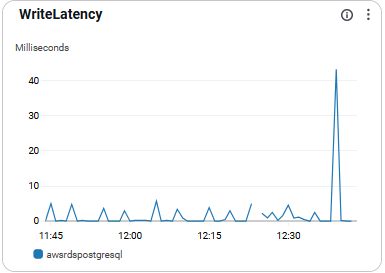
- 쓰기 작업의 지연 시간을 의미함.
- 병목 탐지 및 성능 진단 목적에 유용함
- 권장 수치: 0.01초(10ms) 이하 유지 권장
DatabaseConnections
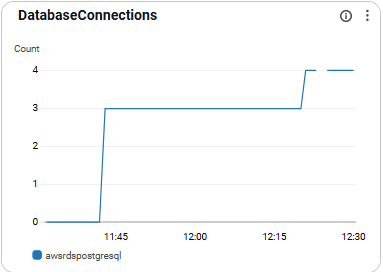
- 현재 열린 DB 연결 수를 의미함.
- 운영 이상 징후 탐지에 유용함
- 최대 연결 수의 80% 이하로 유지 권장
- 이 수치의 트랜드를 관찰
- SHOW max_connections;
ReadIOPS(Read Input/Output Operations Per Second)
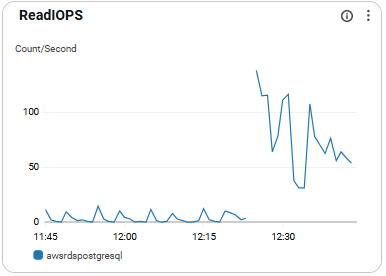
- 초당 읽기 I/O 횟수를 의미함.
- 성능 진단에 활용됨
- 시스템 패턴에 따라 권장 수치 다름.
- 급증 추세 모니터링 필요
WriteIOPS
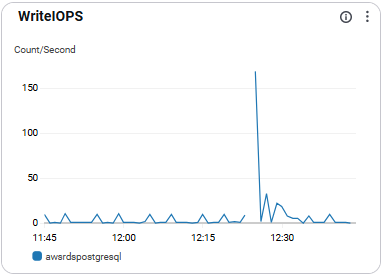
- 초당 쓰기 I/O 횟수를 의미함.
- 성능 진단 및 병목 탐지에 유용함
- 지속적인 증가 시 트랜잭션 병목 우려 있음
TransactionLogsDiskUsage
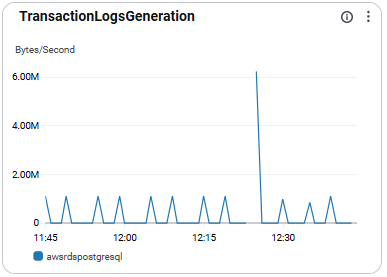
- 트랜잭션 로그사용량을 의미함.
- 장애 예방 측면에서 중요함
- 권장 수치: 사용량이 80% 이상이면 로그 정리 또는 증설 필요임
WriteThroughput
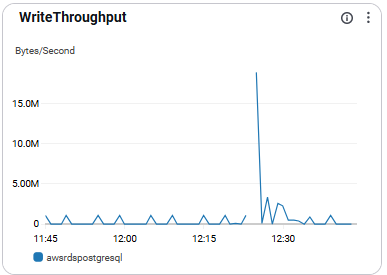
- 단위 시간당 쓰기 처리량을 의미함.
- 성능 진단 및 트랜잭션 처리 상태 확인에 유용함
- 권장 수치: 업무량 기준으로 베이스라인 설정 필요
NetworkTransmitThroughput
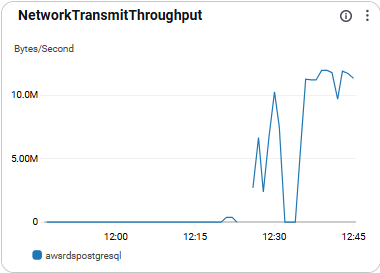
- 인스턴스에서 외부로 나가는 네트워크
트래픽을 의미함. - 운영 이상 징후 파악에 활용됨
- 급증 시 백업, ETL, 복제 병목 의심
NetworkReceiveThroughput
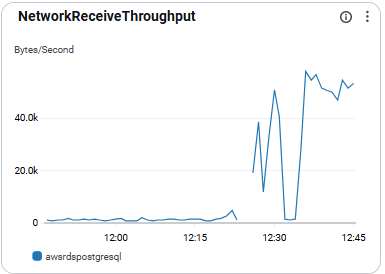
- 인스턴스로 들어오는 네트워크 트래픽을 의미함.
- 성능 진단 및 입력 지연 확인에 활용됨
- 정상 입력 대비 급감하면 네트워크 이슈 의심 가능
DBLoad
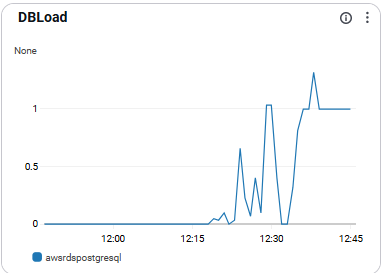
- DB의 총 부하 수준을 나타냄 (활동 세션 기준). 병목 탐지에 매우 효과적임
- vCPU 수 이상이면 과부하 가능성 있음
DBLoadCPU
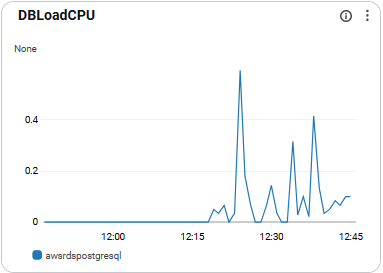
- CPU 사용과 연관된 DB 부하량을 의미함.
- 병목 탐지에 활용됨
- DBLoad 대비 낮으면 비CPU병목 추정 가능
비CPU
디스크 I/O, 네트워크 지연, 메모리 부족 등 다양한 원인으로 발생
데이터베이스 성능 이슈 대처
- 베이스라인 대비 이상치 여부
- 예정에 없는 서비스 테스트 등이 있는지 확인
- 보안적인 문제 생각
- 하드웨어(인스턴스)의 scale up 이 만병통치는 아님 쿼리의 실행계획이 중요
- 잘 짜여진 쿼리 필요
