
인덱스
데이터베이스에서 검색 속도를 높이기 위한 자료구조
- 테이블의 특정 컬럼에 대해 키(key)와 해당 행의 위치를 쌍으로 저장해 두고 검색 시 활용함.
- 이를 통해 전체 테이블을 훑지 않고도 원하는 데이터를 빠르게 찾을 수 있음.
- 다만 인덱스를 유지관리하기 위한 추가 공간과 시간이 들기 때문에, 읽기 성능 향상과 쓰기 부하 증가 사이의 균형을 고려해야 함.
특징
- 인덱스는 하나의 테이블에 한 개 이상의 인덱스를 생성할 수 있음. 즉, 하나 또는 여러 개의 열에
생성할 수 있음. - 해당 열의 데이터를 정렬한 후 별도의 메모리 공간에 열의 값과 물리적 주소를 저장함.
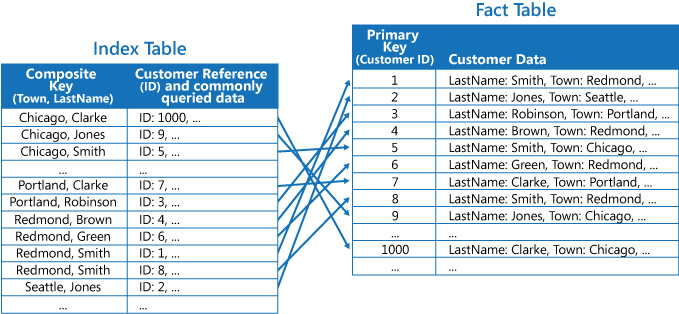
- 그림과 같이 고객 ID가 기본 키인 테이블에서 고객 주소와 성 열을 인덱스로 생성하면 좌측 하단과 같이 복합 키를 기준으로 정렬된 인덱스 테이블이 생성됨.
- 예를 들어 Chicago에 사는 성이 Clarke인 고객의 데이터를 찾으려면 기존 Fact Table에서는 데이터가 고객 ID로 정렬되어있기 때문에 1000번째 까지 순차적으로 스캔(Sequential Scan)을 해야함.
- 인덱스를 이용하면 Town과 LastName 기준으로 정렬되어 있기 때문에 Town이 Chicago인 대상들을 찾고, 거기서 다시 LastName이 Clarke인 대상을 찾으면 한번에 데이터를 찾을 수 있음.
- 즉, 주로 검색하는 기준에 따라 미리 데이터를 정렬해 놓으면 빠르게 원하는 행을 찾을 수 있게 됨.
장단점
- 인덱스는 대용량 데이터에서 쿼리 응답속도를 향상시킬 수 있는 좋은 도구이지만 적합하지 않은 인덱스는 오히려 속도나 느려질 수 있음.
- 인덱스 생성시 테이블 크기에 따라 10%정도의 저장 공간이 추가로 필요하기에 공간 낭비가 초래될 수 있음.
인덱스 종류 및 생성 방법
1.B-tree 인덱스 (기본값)
정의: Balanced Tree(균형 트리)를 이용한 가장 일반적인 인덱스.
특징
- 범위 검색(range queries), 등가 검색(equality queries)에 적합.
- 데이터의 정렬된 순서를 유지.
- 대부분의 데이터 타입에서 사용 가능.
- PostgreSQL의 기본 인덱스 타입.
적합 용도:
- 날짜, 숫자, 문자열과 같은 정렬 가능한 데이터 유형에 적합.
- 범위 조건 (>, <, BETWEEN) 쿼리에 적합.
-- 기본형식
CREATE INDEX idx_customer_last_name ON
customer (last_name);2.Hash 인덱스
정의: 해시 함수를 이용하여 키 값에 직접 접근하는 방식.
특징
- 등가 검색(=)에만 효과적이고, 범위 검색은 지원x
- 인덱스 크기가 상대적으로 작음.
적합 용도:
- 정확한 일치 조건에 매우 효율적(예: 이메일, ID 검색 등).
- 범위 검색이 필요 없는 데이터에 최적.
-- hash 인덱스 설정
CREATE INDEX idx_customer_email ON
customer USING hash (email);3.GiST (Generalized Search Tree) 인덱스
정의: 다목적 데이터 구조를 위한 인덱스로, 지리정보(지형 데이터), 전체 텍스트 검색, 다차원 데이터 검색 등에 사용됨.
특징
- 다차원 데이터 및 특수 데이터 형식을 지원.
- 중복된 값을 가진 데이터와 범위 검색에도 적합.
적합 용도:
- 지리공간 데이터(geometry, geography 등)
- IP 주소 범위
- 전체 텍스트 검색(FTS).
-- GIS 데이터 (geometry) 인덱스 생성
CREATE INDEX idx_location ON
places USING gist(location);4.GIN (Generalized Inverted Index) 인덱스
정의: 여러 값이 있는 데이터(배열, JSONB, 전체 텍스트 검색 등)를 빠르게 처리하는 데 사용되는 역인덱스 방식
특징:
- 배열 및 JSONB 필드의 효율적 탐색.
- 전체 텍스트 검색을 위한 빠른 검색 속도 지원.
- 데이터 삽입 및 갱신 시 성능 저하 가능성 존재.
적합 용도:
- 배열
- JSONB 데이터
- 전체 텍스트 검색(FTS)
- 여러 키워드 및 태그 검색
--.JSONB 컬럼 인덱스 생성
CREATE INDEX idx_jsonb_data ON
documents USING gin (jsonb_data);5.BRIN (Block Range Index) 인덱스
정의: 테이블 블록(block)의 최소/최대 값을 저장하여 큰 테이블의 데이터 탐색을 빠르게 하는 압축 인덱스
특징:
- 매우 큰 테이블에 적합하며 인덱스 크기가 작음.
- 대략적인 데이터 위치만을 알려줘 정확한 검색보다 테이블 스캔 축소 목적.
- 대량 데이터 로딩 및 빠른 INSERT 성능 유지 가능.
적합 용도:
- 로그, 이벤트 등 연속적 데이터를 시간별로 대량 저장하는 대형 테이블에 적합.
-- BRIN 인덱스 설정
CREATE INDEX idx_large_table_date
ON large_table USING brin(created_date);테이블의 인덱스 조회
Select *
from pg_indexes
where tablename=‘테이블이름’실행 계획 확인하기(Explain)
쿼리 수행 시 Planner가 어떤 인덱스를 사용했는지 확인하는 명령어
사용법:
Explain SQL 문
어떻게 실행될지 실행 계획을 출력
Explain analyze SQL 문
SQL문을 실행 한 후 실제 실행 계획과 비용,
소요시간 추력

EXPLAIN SELECT * FROM 테이블 WHERE 조건;
EXPLAIN ANALYZE SELECT * FROM 테이블 WHERE 조건;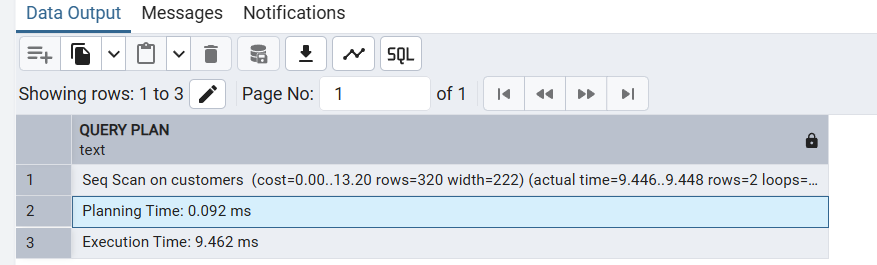
주요 인덱스 스캔
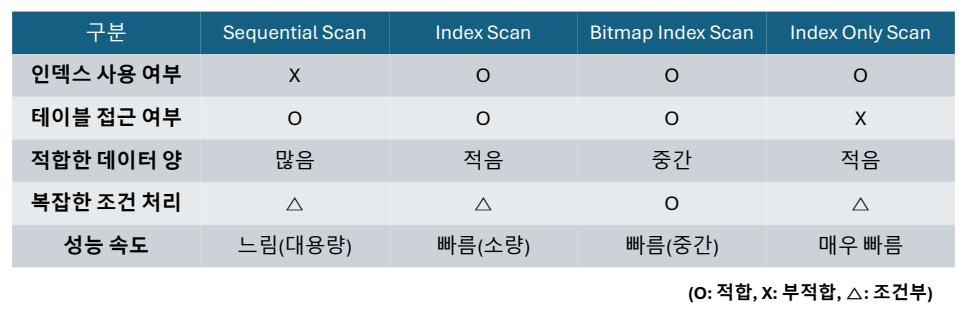
1. Sequential Scan (순차 스캔)
인덱스를 사용하지 않고 테이블의 모든 데이터를 처음부터 끝까지 순차적으로 탐색합니다.
- 인덱스가 없거나 쿼리 조건의 선택도가 낮을 때.
- 테이블의 행 수가 적거나 대부분의 데이터를 읽어야 할 때.
- 장점: 인덱스 관리가 불필요하고, 데이터 대부분을 읽을 때 효율적.
- 단점: 데이터가 많을 경우 성능 저하가 발생할 수 있음.
-- 인덱스가 없는 상태에서 전체 테이블 탐색
SELECT *
FROM customer
WHERE last_name = 'Smith';2. Index Scan
인덱스를 사용하여 데이터를 빠르게 찾고 접근합니다.
- 조건에 해당하는 데이터가 적을 때
(선택도가 높을 때). - 인덱스 컬럼으로 조건이 명확히 지정될 때.
- 장점: 소량의 데이터를 빠르게 접근 가능.
- 단점: 대량 데이터를 조회할 때는 성능이 떨어질 수 있음.
-- 인덱스를 사용한 데이터 탐색 SELECT *
FROM customer WHERE customer_id = 5;3. Bitmap Index Scan
여러 인덱스 조건을 결합할 때 각 조건의 결과를 비트맵 형태로 구성하여 효율적으로 처리합니다.
- 복수 조건을 가진 쿼리일 때.
- 중간 정도의 선택도를 가진 쿼리에서 효과적.
- 장점: 여러 조건이 결합된 복잡한 쿼리에서 효율적.
- 단점: 단일 조건의 간단한 쿼리에선 오히려 비효율적일 수 있음.
-- 다중 조건으로 검색 시 비트맵 인덱스 활용
SELECT *
FROM film
WHERE rental_rate = 4.99 AND rating = 'PG-13';4. 4. Index Only Scan (인덱스 온리 스캔)
쿼리에서 요구하는 컬럼이 모두 인덱스에 포함되어 있는 경우, 테이블 접근 없이 인덱스만으로 결과를
반환합니다.
- SELECT 문에서 사용하는 모든 컬럼이 인덱스에 포함된 경우.
- 장점: 실제 테이블을 읽지 않기 때문에 빠른 성능을 제공.
- 단점: 인덱스가 비대해지면 유지 비용이 증가.
-- 인덱스만으로 데이터를 읽는 경우 -- (last_name과 first_name이 복합 인덱스로 생성된 경우)
SELECT first_name, last_name FROM customer
WHERE last_name = 'Smith';주요 인덱스 스캔(정리)

인덱스 실습
인덱스 추가 전후 비교 항목
1. Execution Time
- 가장 직관적인 비교 지표임
- 쿼리 전체를 실행하는 데 걸린 실제 시간.
- 단순히 이 값만 보면 "인덱스 추가 후 빨라졌는지"를 알 수 있음.
- 다수 수행 후 평균값 (예, 5회, 10회 수행의 결과 평균)
2. Node Type (연산 방법)
- 사용 스캔방법 비교
- Seq Scan에서 Index Scan으로 변경되었는지 확인
3. Heap Fetch 발생여부
- 인덱스를 만들었지만 결국 Heap Fetch(테이블 블록 읽기) 가 많이 발생하면 성능 향상은 어려움.
- 예) Heap Blocks: exact=73
- 인덱스로만 해결되면 Heap Fetch가 없음.
4. Cost 비교
- cost=Start..End 로 되어 있는 부분도 확인.
- 실제 실행시간과는 다르지만, PostgreSQL이 생각하는 "예상 비용" 임.
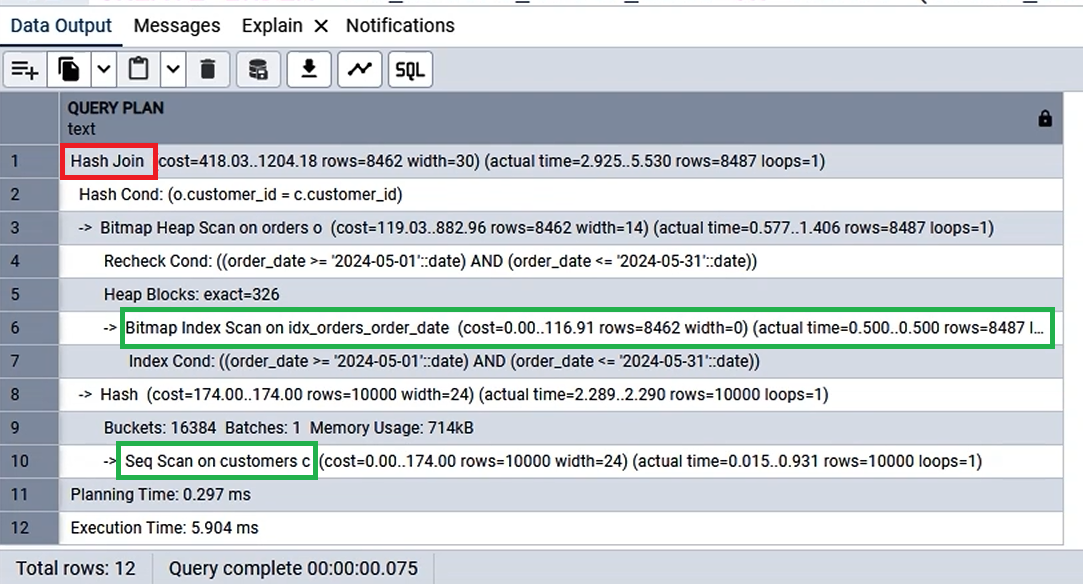
- 예) Hash Join (cost=85.48..1985.09 rows=1000 width=24)
▪ Start Cost: 첫 데이터를 가져오는데 필요한 예상 비용
▪ End Cost: 결과를 모두 가져오는데 필요한 예상 비용
▪ End Cost가 낮으면 더 성능이 좋아진 것.
조인 방식,선택되는 주된 조건,주요 특징
- 해시 조인 (Hash Join)
- "조인 테이블이 대규모이고 정렬되지 않은 상태일 때, 등가 비교(=) 조건일 때."
- "대용량 데이터 처리 속도가 빠르며, 메모리 사용량이 높음."
- 머지 조인 (Merge Join)
- "조인 키가 이미 정렬되어 있거나, 정렬 비용을 공유할 수 있을 때."
- 정렬된 데이터를 순차적으로 병합(Merge)하여 처리함.
- 네스티드 루프 조인 (Nested Loop Join)
- "외부 테이블의 크기가 매우 작고, 내부 테이블에 효율적인 인덱스가 있어 랜덤 액세스가 빠를 때."
- "반복적인 중첩 루프 검색 방식, 랜덤 액세스가 많아지면 비효율적임."

행복한 하루 보내세요